ETP-R1:基于强化微调的演化拓扑规划用于连续环境下的视觉-语言导航
25年12月来自浙大、华为和浙江人形机器人创新中心的论文 "ETP-R1: Evolving Topological Planning with Reinforcement Fine-tuning for Vision-Language Navigation in Continuous Environments"。连续环境中的视觉语言导航(VLN-CE)要求具身智体在连续环境中根据自然语言指令导航
25年12月来自浙大、华为和浙江人形机器人创新中心的论文 “ETP-R1: Evolving Topological Planning with Reinforcement Fine-tuning for Vision-Language Navigation in Continuous Environments”。
连续环境中的视觉语言导航(VLN-CE)要求具身智体在连续环境中根据自然语言指令导航至目标。虽然当前基于图的方法通过将环境抽象为拓扑地图并将动作空间简化为路径点选择,提供一种高效且结构化的方法,但它们在利用大规模数据和高级训练范式方面落后于基于大型视觉语言模型(LVLM)的方法。本文旨在通过引入ETP-R1框架来弥合这一差距。ETP-R1框架将数据规模化和强化微调(RFT)范式应用于基于图的VLN-CE模型。为了构建坚实的基础,首先使用Gemini API构建一个高质量的大规模预训练数据集。该数据集包含多样化的、低幻觉的拓扑轨迹指令,为基于图的策略提供丰富的监督信息,以将语言映射到拓扑路径。通过整合R2R和RxR任务的数据进行联合预训练,进一步强化这一基础。在此基础上,引入一种三阶段训练范式,最终首次将闭环在线RFT应用于基于图的VLN-CE模型,该模型由组相对策略优化(GRPO)算法驱动。
连续环境下的视觉语言导航 (VLN-CE)
为了解决 VLN-CE 任务 [2],早期方法尝试将视觉和文本输入直接映射到底层动作 [15],但其性能通常受限于低效的动作空间。路径点预测器的引入 [9]、[16] 标志着一个重要的发展,将问题从底层控制转移到高层路径点选择。这种基于路径点的范式被基于图的方法 [6] 进一步形式化,该方法将预测的路径点组织成拓扑图,并采用基于 Transformer 的规划器进行高层规划。虽然该框架下的后续工作 [7]、[8]、[11] 专注于改进前端视觉表示以辅助规划,但通过堆叠更强大的特征提取器所获得的性能提升已开始趋于平缓。
与此同时,大型语言模型 (LLM) 的快速发展激发了新的研究方向,即使用 LLM/LVLM 作为导航智体 [4]、[5]。这些模型强大的预训练权重能够更深入地理解语言指令。然而,目前基于LVLM的方法通常存在两个局限性:它们难以处理全景图像,通常依赖于单目视角;而且它们无法有效利用拓扑结构,只能依赖图像帧的历史作为环境表征。
除了新架构之外,预训练数据对性能至关重要。许多先前的工作训练“说话人”模型来标注指令[12]、[17]–[19]。然而,这种方法存在明显的缺陷:生成的语言在风格上局限于训练数据集的模式,并且生成的指令经常出现“幻觉”。
VLN-CE 中的强化学习 (RL)
尽管强化学习在离散型 VLN [20]、[21] 中是一种常用技术,但由于 VLN-CE 的动作空间更大、轨迹长度更长,直接应用强化学习的成本很高。Krantz [16] 首先将强化学习应用于路径点预测器。虽然这降低了学习复杂度,但智体仍然面临着生成既可导航又符合指令的路径点的双重难题。最近,基于图的 VLN [6] 进一步将路径点生成与指令跟踪解耦,这为实现强化学习提供了一个理想的框架。
同时,LVLM [14] 的训练范式表明,先进行单轮语言训练 (SFT) 再进行强化学习(称为 RFT)是一种高效的方法。Qi [5] 将 RFT 引入到基于 LVLM 的智体中。然而,由于其方法基于离线训练,RFT 仅限于微调单轮语言输出。这使得他们的 RFT 过程实际上相对于交互式导航任务而言是开环的。
ETP-R1
ETP-R1 是一个基于图的 VLN 框架,它通过强化微调来演化拓扑规划。该方法构建一个增强的预训练基础,从而为基于图的 VLN 提供一种在线 RFT 范式。为了建立强大的微调基础,首先使用 Gemini API [13] 对 Prevalent 数据集 [12] 进行重标注,以丰富语言多样性并减少幻觉。然后,将 R2R 和 RxR 的预训练统一到一个联合过程中,使模型能够学习更广泛的指令。最终得到的 0.5 亿参数模型由一个跨模态规划网络驱动,该网络采用双阶段融合Transformer (DPFT) 来有效地将语言指令与图表示对齐。在此基础上,智体通过两个连续的在线阶段进行微调。该过程首先进行在线监督微调 (SFT) 阶段,以使模型适应交互式环境。最后阶段是线上 RFT,它首次应用于基于图的 VLN 模型。该阶段由群组相对策略优化 (GRPO) 算法 [14] 驱动,允许智体通过强化更成功的轨迹,以闭环方式改进其导航策略。
如图所示对三种方法流程进行比较:工作采用联合数据集预训练,并使用 Gemini 生成新数据;利用高效的图表示;并且首次将闭环 RFT 应用于基于图的 VLN 模型。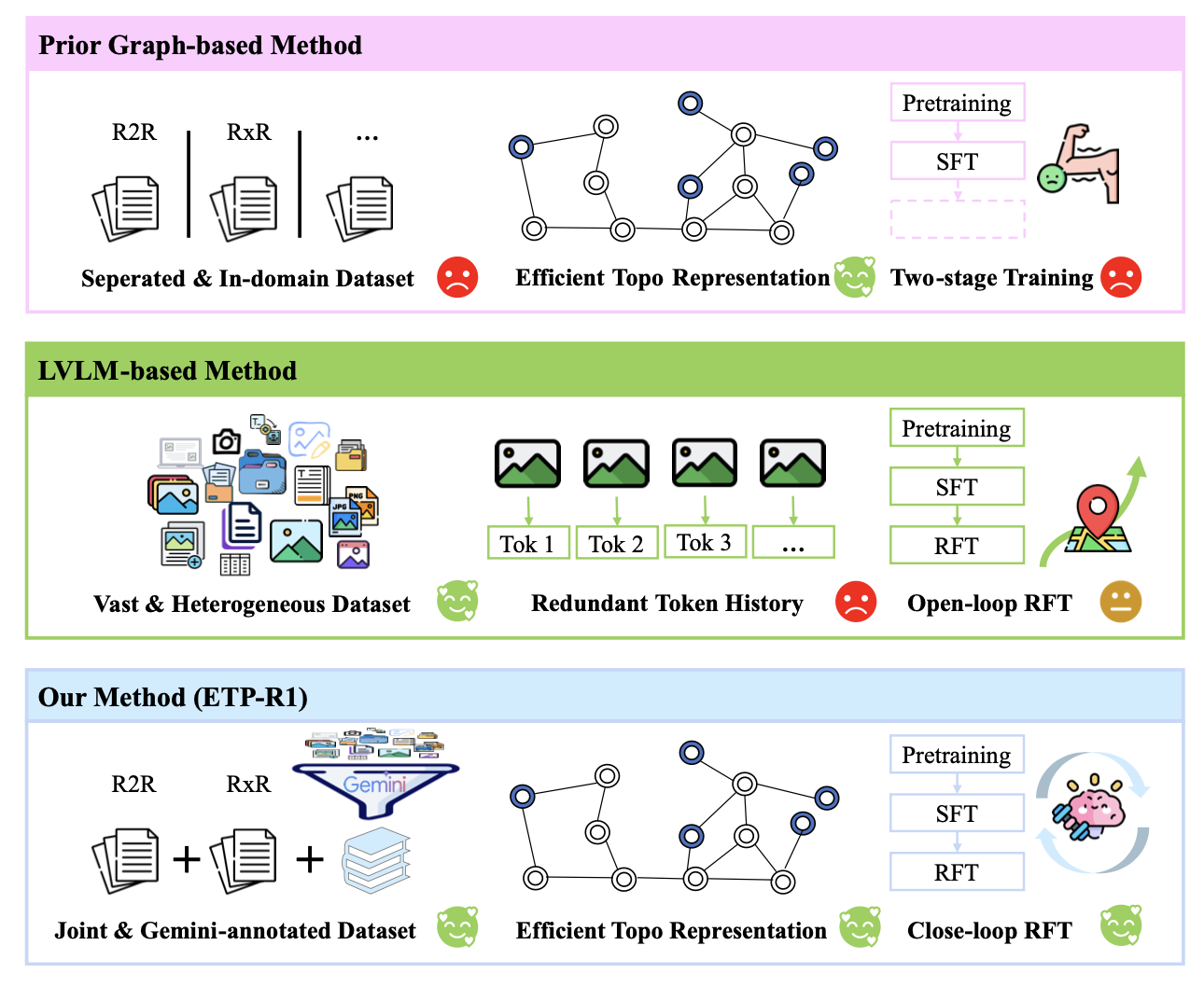
任务设置:在 VLN-CE 任务中,智体被初始化于一个未知环境中的起始位置,并被赋予一条自然语言指令 W = {w_i}。在每个时间步,智体接收一个全景观测数据 O_t,该数据由 12 个 RGBD 图像对 {Irgb_k, Id_k} 组成,均匀地采样 360° 水平视野。在指令和当前观测数据的引导下,智体通过依次执行以下四个动作之一来导航至目标位置:前进(0.25 米)、左转/右转(15°)和停止。如果智体在达到最大步数限制之前,在距离目标位置的预定义距离阈值内执行停止动作,则该回合被视为成功。
采用 ETPNav [6] 中已建立的拓扑映射和底层控制策略,为简洁起见,此处省略其细节。如图所示,工作围绕三阶段训练范式中的预训练和在线 RFT 阶段展开。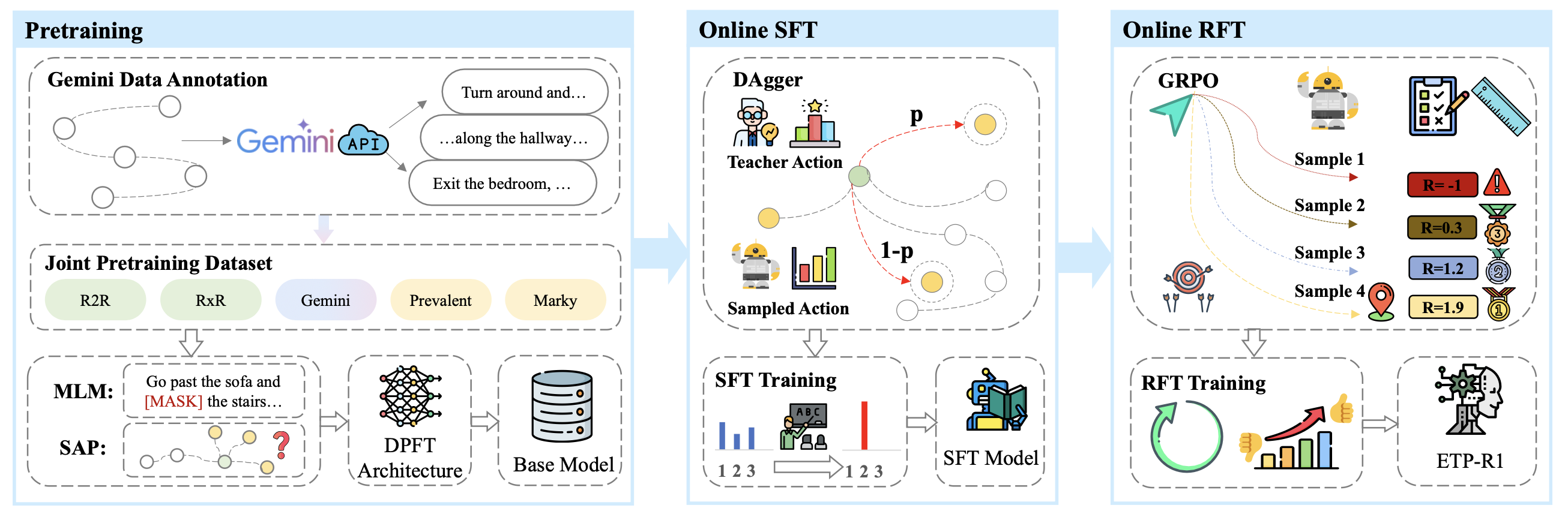
无训练预训练数据标注
为了提高质量和语言多样性,用 Gemini 2.0 Flash API [13] 对 Prevalent [12] 数据集中的指令进行重标注。输入到 Gemini 的提示由精心设计的视觉和文本组件构成。
将视觉轨迹表示为一系列有序的视点图像。序列中的每个视点都对应于预定义图 [1] 中的一个特定节点。为了避免处理全景图像,同时又能提供足够的视野,创建一幅合成图像来表示每个视点。具体来说,按顺序水平拼接左、前、右三个单目视图(每个图像的视场角均为 90°)。此外,为了明确标示行进方向,在图像上叠加一个指向下一个视点的红色箭头。如图展示输入视点图像的示例。
每个视点图像的朝向由智体的路径决定。对于任何视点 v_i>0,其朝向与前一个视点 v_i−1 的到达方向一致。起始视点 v_0 的初始方向由该回合的起始朝向决定。
按如下方式处理红色箭头超出三图组合视图范围的特殊情况:
• 在 v_0:如果第一步是后退,将初始朝向重新调整为直接面向 v_1。生成指令后,会手动在答案前添加相关命令(例如,“转身”)。
• 在 v_i>0:直接丢弃该轨迹。这种情况很少见,仅影响约 2% 的轨迹。
提示的文本组件旨在通过一次 API 调用为每条轨迹生成六条不同的指令。为了最大限度地提高这六条指令的多样性,引入一种称为轨迹分割标注的策略。
并非直接提示输入完整的轨迹,而是先对其进行预处理,随机将其分割成 1/2/3 个连续的子任务。每个提示包含三种不同的分割方案,并要求 Gemini 为每种方案中的每个子任务生成两条描述。最后,将与每种分割方案对应的描述连接起来,生成六条不同的指令。这种方法通过鼓励模型以不同的粒度级别描述同一轨迹,从而高效地生成六条各具特色的指令。
此外,为了避免限制 Gemini 的生成能力,提示特意省略所有由人工标注的 R2R 指令的少量示例。施加的主要限制是每个子任务描述的长度,使其保持在 10-25 个单词左右。
如上图所示,与原始数据集相比,Gemini 生成的指令包含的幻觉更少,语言丰富度更高。从数量上看,最终的 Prevalent Gemini Aug 数据集的平均指令长度从 31 个单词(原始 Prevalent)增加到 48 个单词。
模型架构
模型的工作流程首先将图节点的 RGBD 特征编码成一系列节点tokens。然后,DPFT 模块将这些tokens与编码后的指令进行联合处理。最后,单动作预测 (SAP) 头对 DPFT 的输出特征进行评分,选择得分最高的节点作为下一个子目标,底层控制器引导智体向该节点移动。
-
文本编码器:首先对语言指令 W = {w_i} 进行token化,并将其映射到词嵌入。然后,将这些词嵌入与位置嵌入、类型嵌入以及引入的新任务嵌入相加。该任务嵌入取决于指令的来源——R2R(类型 1)、RxR(类型 2)或标注的 Gemini 数据(类型 3)——从而使模型能够在联合预训练期间处理语言变型。生成的嵌入序列随后被输入到一个多层 BERT 风格的 Transformer 编码器 [22] 中,该编码器输出最终的上下文指令特征 T={t_i}。
-
节点编码器:对于图中的每个节点,首先处理其全景观测 O_t = {Irgb_k,Id_k},方法是将每个 RGB 图像和深度图像分别输入到相应的视觉骨干网络中以提取单峰特征。然后,将这些特征与一个可学习的视角嵌入相结合。经过单独的线性层投影后,这三个特征被输入到一个多层 Transformer(全景编码器)中,以融合节点的全景上下文。当前节点和先前访问过的节点的最终节点tokens是通过对 12 个输出向量取平均值得到的。对于未访问过的节点,其特征直接继承自其父节点的对应视图特定特征。最后,每个节点token与三个附加嵌入相加:步长嵌入(编码上次访问时间)、位置嵌入(编码相对于当前节点的姿态)和任务嵌入(R2R 任务 ID 为 1,RxR 任务 ID 为 2)。所有处理后的节点特征随后被收集到最终的图token序列 G = {g_i} 中,该序列还包含一个专门用于表示“停止”动作的token。
DPFT 模块:如图所示DPFT 模块以对称跨模态融合网络开始,该网络由 L_s 个 Transformer 层组成,用于创建指令和图的相互感知表示。初始输入为文本特征 T_0 和图特征 G_0。对于从 0 到 L_s−1 的每一层 l,双向交叉注意模块,首先生成中间表示。文本特征关注图,反之亦然。与 LXMERT [23] 不同,这里采用两个交叉注意模块的非共享权重作为规模化策略。这些中间表示随后由自注意机制和前馈网络 (FFN) 处理,生成该层的输出 T_l+1 和 G_l+1。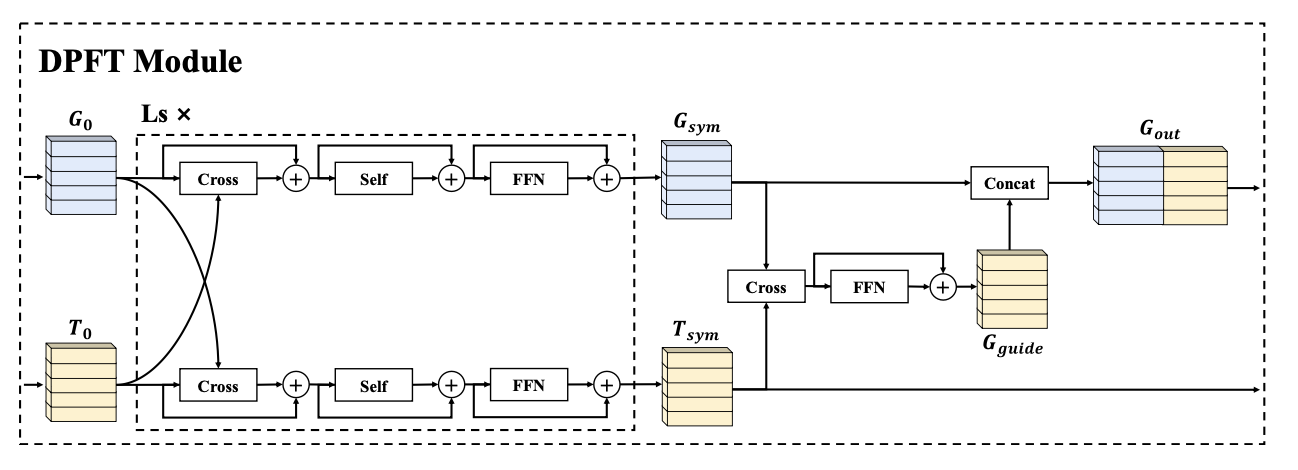
该对称阶段的输出 T_sym = T_L_s,G_sym = G_L_s 随后被输入到文本引导图细化网络。该模块通过注入从文本中提取的特定引导信息来进一步细化图表示。图特征 G_sym 查询文本特征 T_sym 以提取语言指导向量 G_guide。该向量代表每个图节点最相关的文本信息,由前馈神经网络 (FFN) 处理并与原始图特征连接,生成最终的、增强指导的图表示 G_out。整个 DPFT 模块的最终输出是上下文相关的文本特征 T_sym 和精炼后的图特征 G_out。
- 任务头:模型采用两个任务头,均以简单的前馈神经网络 (FFN) 实现。主要的单动作预测 (SAP) 头负责对图中的每个候选节点进行评分;辅助的掩码语言建模 (MLM) 头在预训练期间用于预测掩码token的词汇分布:
s_i = FFN_sap (g_i)
l_j = FFN_mlm (t_j)
其中 g_i 是从 G_out 中提取的第 i 个候选节点的特征向量。类似地,t_j 是 T_sym 中第 j 个掩码token的特征向量。
训练范式
模型采用三阶段范式进行训练,以逐步提升其性能。首先,利用来自 R2R 和 RxR 任务的大量数据集进行离线联合预训练,得到一个基础模型。然后,使用基于 DAgger 的在线 SFT 分别针对每个任务对该基础模型进行微调,最后使用基于 GRPO 的在线 RFT 进行优化。这三个阶段的详细说明如下:
-
离线联合预训练:为了增强泛化能力,联合使用来自 R2R 和 RxR 的五个数据集对单个基础模型进行预训练:Prevalent (100 万条数据) [12]、开发的 Prevalent Gemini Aug (100 万条数据)、RxR-Marky (100 万条数据) [19] 以及较小的原始任务数据集 R2R train (1.4 万条数据) [1] 和 RxR train (8 万条数据) [10]。预训练课程包含两个比例为 1:1 的辅助任务:单动作预测 (SAP) 和掩码语言建模 (MLM)。对于 SAP,模型根据指令和部分真实轨迹预测下一个动作。对于 MLM,模型根据完整的真实轨迹重建指令中的掩码token。最佳检查点基于 R2R val unseen + RxR val unseen 验证集上 SAP 和 MLM 准确率之和的最大值来选择。
-
在线 SFT:为了提高智体的探索能力和自我纠错能力,用 DAgger 算法 [24] 执行在线 SFT。在每个步骤中,智体以概率 p 执行专家动作,并以概率 1−p 从自身策略中采样一个动作。专家动作是由全局规划器提供的最优节点,其设置与 ETPNav [6] 相同。基于最高的成功率+SPL选择R2R-CE的最终检查点,并基于各自验证集上最高的nDTW+SDTW选择RxR-CE的最终检查点。
-
在线RFT:在最后阶段,用高效的强化学习算法GRPO[14]执行闭环RFT。GRPO是PPO[25]的变型,它无需critics网络,显著降低强化学习训练的内存和计算负担。GRPO不学习值函数,而是对同一提示的G个答案进行采样,并计算每个答案相对于该组平均性能的优势。在基于图的VLN中,一个episode充当提示,一条轨迹对应于一个答案,而一个高级动作代表一个token。这种直接对应关系可以对整个episode使用简单易懂、基于结果的奖励。
奖励函数定义为:
R_R2R−CE = I (d_final < 1.5) + SPL − d_final /6
R_RxR−CE = nDTW + SDTW + gSPL − d_final /6
其中 I(·) 是成功指示函数,d_final 是智体到目标的最终测地距离。测度有路径长度加权成功率(SPL),gSPL 是 SPL 的一个变型,它使用真实路径长度而非 SPL 中的最短路径长度。这种区别对于 RxR-CE 至关重要,因为其参考轨迹通常并非最短路径。使用 SPL 会错误地激励智体为了走捷径而偏离指令。相比之下,gSPL 能够正确地奖励那些既高效又符合给定指令的路径。
对于每个episode,抽取一组 G 条轨迹,并计算它们的episode 奖励 r = {r_1, …, r_G}。然后,将这些奖励进行归一化,并将其作为第 i 条轨迹中所有高层步骤 t 的优势值 Aˆ_i,t:
GRPO 的最终优化目标与原始形式 [14] 相同,该目标通过相对于参考策略的 KL 散度项来规范策略更新。
实验设置
-
数据集:实验基于两个标准的 VLN-CE 基准数据集 R2R-CE 和 RxR-CE,它们分别改编自原始的 R2R [1] 和 RxR [10] 数据集,用于在连续的 Habitat [3] 环境中进行导航。这两个数据集在语言复杂性、路径结构和物理约束方面各有不同。R2R-CE 的指令简洁,仅包含英文,平均长度为 32 个单词,其参考路径始终是到达目的地的最短路径,平均长度为 9.89 米。相比之下,RxR-CE 提供高度描述性的多语言指令(英语、印地语和泰卢固语),平均长度为 120 个单词。其路径更长(平均 15.23 米),并且通常并非最短路径,这要求智体严格遵循详细的指令。基准测试的智体仿真参数也存在差异:R2R-CE 中的智体底盘半径较小(0.10 米),允许沿障碍物滑动;而 RxR-CE 中的智体底盘半径较大(0.18 米),碰撞后会停止移动。
-
评估指标:采用一套标准的导航指标:导航误差 (NE)、成功率 (SR)、Oracle SR (OSR)、路径长度加权成功率 (SPL)、归一化动态时间规整 (nDTW) 和 nDTW 加权成功率 (SDTW)。对于 R2R-CE 基准测试,优先考虑 SR 和 SPL 来评估成功率和路径效率。对于 RxR-CE 基准测试,由于对参考路径的保真度更为重要,重点关注 nDTW 和 SDTW。
-
实现细节:对于视觉编码器,用在 CLIP [28] 上预训练的 ViT-B/32 [27] 处理 RGB 图像,并使用在点-目标导航 [30] 上预训练的 ResNet-50 [29] 处理深度图像。对于文本编码器,采用 12 层 RoBERTa [31] 架构,并使用其预训练权重初始化模型。全景编码器和对称跨模态融合网络的层数分别设置为 2 层和 4 层。整个模型的隐藏层维度 d 设置为 768。在预训练和在线 SFT 阶段,除冻结的视觉骨干网络外,所有模型参数均进行训练。在最终的在线 RFT 阶段,仅对 DPFT 模块和 SAP 头部进行微调。
对于在线训练阶段,将数据集划分为两个不相交的集合:90% 的数据用于在线 SFT,剩余的 10% 用于在线 RFT。
为了进一步提高 RFT 的性能,实施几个特定的配置:(1)对冻结层启用 dropout;(2)在采样阶段也启用 dropout;(3)将 GRPO 更新迭代次数 μ 设置为 1。其他 GRPO 超参数包括裁剪范围 ε=0.2、KL 损失权重 β=0.04 和组大小 G=8。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 31
31 0
0- 0



 已为社区贡献211条内容
已为社区贡献211条内容

所有评论(0)