具身智能避坑:如何可视化 BridgeData V2(且不搞崩 PyTorch 环境)
针对具身智能领域 TFRecord 格式数据集(如 BridgeData V2)读取难、易导致 PyTorch 环境冲突的问题,开源并拆解了一个轻量级可视化工具 Quick-Bridge-Streamer。通过纯 CPU 读取与 Rerun 引擎,实现一行代码开箱即用,支持图像与 7-DoF 曲线完美对齐、异常数据实时预警,并能自动生成 PyTorch 加载代码,用于预览机器人数据。
文中涉及的代码已经开源在 GitHub:
👉 https://github.com/kwfang/Quick-Bridge-Streamer
1. 引言:具身智能炼丹师的"环境噩梦"
这段时间在做具身智能(Embodied AI)的项目,因为是刚入门,数据用的是大名鼎鼎的 BridgeData V2,就是那个 Google 开源的、包含了 60,000+ 条机器人遥操作轨迹的数据集。
刚入门的机器人小白大概能懂我的感觉:
第一件事,打开数据文件夹,看到的不是整齐的 .mp4 和 .png,而是一堆 .tfrecord-00000-of-01024 文件。行吧,Google 祖传艺能,用 TFRecord 我能理解。
第二件事,为了看看这些数据长什么样,我习惯性地:
pip install tensorflow
然后噩梦就开始了。
我的环境是 PyTorch 2.0 + CUDA 11.8,好不容易配好的。TensorFlow 一进来,直接给我把 CUDA 驱动冲突了。libcudart.so 版本不匹配、tensorflow-gpu 试图抢显卡、PyTorch 直接报 CUDA out of memory 或者干脆找不到 GPU。
最绝的一次,我 import tensorflow 之后,torch.cuda.is_available() 直接变 False。折腾了三个小时,最后发现是 TF 把环境变量给改了。
我只是想看一眼数据长什么样,为什么要付出这么大的代价?
2. 技术解析:为什么解析 TFRecord 这么折磨人?
如果你以为 TFRecord 只是"另一种格式的视频文件",那你大概率会像我一样,在调试代码里浪费一整个下午。
2.1 盲盒结构
TFRecord 不是媒体文件,它是 Protocol Buffer 序列化后的二进制数据。打开之后,你看到的就是一团不可读的 bytes。里面具体有哪些字段?字段名叫什么?数据类型是什么?shape 是多少?
在你写代码打印之前,你根本不知道。
BridgeData V2 的数据结构长这样(我打印出来才知道的):
Episode
├── steps/action: float32[28, 7] # 7-DoF 动作(位置+旋转+夹爪)
├── steps/observation/image_0: bytes[28] # JPEG 编码的 256x256 图片
├── steps/observation/state: float32[28, 7] # 关节状态
├── steps/language_instruction: string[28] # 自然语言指令
└── episode_metadata/episode_id: int64
注意这个 steps/ 前缀,还有所有的数据都是 按 episode 存储的 Sequence,不是逐帧独立存储。这意味着你不能像读视频那样 cv2.VideoCapture,你得先解析整个 episode,再拆成 step。
2.2 时序对齐的麻烦
做模仿学习(Imitation Learning)的时候,我们不仅要看画面,还要看 Action 和 State 的时序曲线。比如:
- 机械臂在某个时刻是不是突然卡住?
- 夹爪的开启/关闭是不是和物体抓取时机对得上?
- 遥操作员有没有在某个地方发呆了几秒钟?
如果直接用 OpenCV + Matplotlib 写脚本,你得自己维护一个时间轴,手动对齐视频帧和传感器数据。写起来很烦,看起来也不直观。
3. 破局思路与技术选型
踩完这些坑之后,我在想能不能做一个轻量、独立、不污染 PyTorch 环境的数据查看工具?
3.1 数据读取端:坚决不用 tensorflow-gpu
第一个原则:只用 CPU 版的 TensorFlow,而且不通过 Keras 或高阶 API,直接用底层的 tf.data.TFRecordDataset + protobuf 解析。
这样做的好处:
tensorflow-cpu只依赖系统库,不会碰 CUDA- 手动解析 protobuf 可以按需读取,流式处理,不会把整个数据集载入内存
- 解析后直接转成 numpy array,对 PyTorch 用户友好
3.2 渲染展示端:放弃 Matplotlib,拥抱 Rerun
之前用 Matplotlib 画实时曲线,性能很差,而且不方便拖拽时间轴。后来我问了Gemini,发现了 Rerun,一个专门为机器人/自动驾驶领域设计的可视化 SDK。
它的优势:
- 原生支持时间轴拖拽,图像和曲线完美同步
- 自动启动 Web Viewer,不用装额外的 CLI 工具
- 渲染性能极好
3.3 顺手封装了一个周末小项目
基于以上思路,上周末花半天时间和人工智能一块写了个小工具,取名 Quick-Bridge-Streamer(因为主要是为 BridgeData V2 优化的,但框架可以扩展到其他 OpenX 数据集)。
这个项目的核心希望做到:零配置、纯 CPU、开箱即用。
4. Quick-Bridge-Streamer:核心功能展示
4.1 一行命令启动
git clone https://github.com/kwfang/Quick-Bridge-Streamer.git
cd Quick-Bridge-Streamer
pip install -r requirements.txt # 只有 tensorflow-cpu,放心装
python main.py data/ --limit 100
然后浏览器会自动打开 http://localhost:9090,开始播放数据:
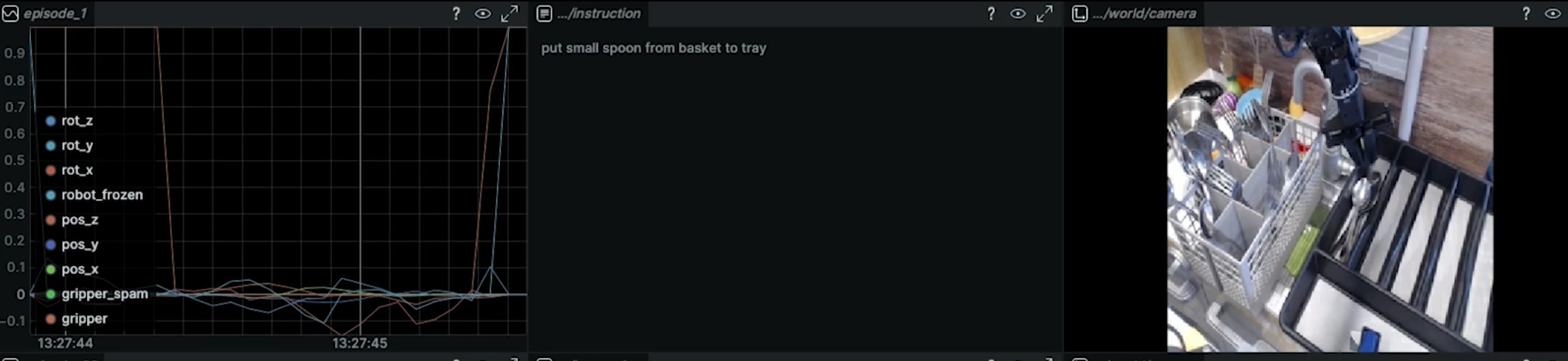
(示意图:左侧是 7-DoF Action 的实时曲线,中间是这个episode的指令,右侧是 RGB 画面)
4.2 内置脏数据检测(Analytics 功能)
这个功能是听说这个数据集里会有一些机器人冻结或者夹爪抖动的情况,于是我在这个工具内置了一个 VectorQualityRadar 模块,会实时分析每一帧数据的质量,但是写的逻辑很简单,估计漏洞很多,但是写完后懒得删了,就放在这了,之后有机会会修改一下,这个功能肯定还有些坑,大佬求别喷 🙏:
| 检测项 | 原理 | 可视化 |
|---|---|---|
| 机器人冻结 | 检测 action 的位置/旋转变化量是否低于阈值 | 红色警示条 |
| 夹爪抖动 | 检测夹爪值在短时间内高频切换 | 橙色警示条 |
| 数据统计 | 实时计算 action 的 min/max/mean | 曲线图 |
效果大概长这样:
[Episode 42] streaming...
⚠️ Detected frozen robot at step 15-35 (20 frames)
⚠️ Gripper spam detected: 5 switches in 10 frames
4.3 PyTorch Dataset 代码代码功能
按 Ctrl+C 退出时,终端会自动打印一段可以直接复制使用的 PyTorch Dataset 代码:
[SUCCESS] Session ended.
Need to load this data in PyTorch? Here is your snippet:
---------------------------------------------------------
class BridgeDataV2Dataset(Dataset):
def __init__(self, data_path="...", split="train"):
...
def __getitem__(self, idx):
...
---------------------------------------------------------
Copy the above to start training!
这是我为了"懒到极致"而设计的,看完数据,确认没问题,直接复制粘贴就能开始炼丹,不需要再去翻 TFRecord 的解析文档。
5. 核心代码分享
如果只想学习核心原理,这里有两段最关键的代码:
5.1 轻量化读取 TFRecord
关键思想:不依赖 TFDS 的高层封装,直接用 protobuf 解析,流式 yield 数据:
from tensorflow.core.example import example_pb2
import tensorflow as tf
import numpy as np
def stream_episodes(tfrecord_files):
"""流式读取,内存占用极低"""
for file_path in tfrecord_files:
ds = tf.data.TFRecordDataset(file_path)
for proto in ds:
# 直接解析 protobuf,跳过 TF 的复杂封装
example = example_pb2.Example()
example.ParseFromString(proto.numpy())
# 提取 action(扁平化存储,需要 reshape)
action_flat = example.features.feature["steps/action"].float_list.value
num_steps = len(action_flat) // 7
action = np.array(action_flat, dtype=np.float32).reshape(num_steps, 7)
# 同理提取 image、state、instruction...
image_list = list(example.features.feature["steps/observation/image_0"].bytes_list.value)
# 按 step yield,而不是一次性返回整个 episode
for step_idx in range(num_steps):
yield {
"action": action[step_idx],
"image": tf.io.decode_jpeg(image_list[step_idx], channels=3).numpy(),
# ...
}
这段代码的核心是 Lazy Loading:读取一个 episode,解析完立即拆成 step yield 出去,不会把所有 episode 都载进内存。对于一个庞大的数据集来说,这是必须的。
5.2 用 Rerun 同步时间轴
关键思想:利用 Rerun 的 set_time_sequence 机制,让图像和曲线天然对齐:
import rerun as rr
# 初始化(自动启动 Web Viewer)
rr.init("BridgeData-Viewer")
rr.serve_web_viewer(open_browser=True)
# 流式发送数据
for step_idx, step_data in enumerate(stream):
# 设置当前时间轴位置
rr.set_time_sequence("step", step_idx)
# 发送图像
rr.log("world/camera", rr.Image(step_data["image"]))
# 发送 action 曲线(7 个维度)
action_labels = ["pos_x", "pos_y", "pos_z", "rot_x", "rot_y", "rot_z", "gripper"]
for label, value in zip(action_labels, step_data["action"]):
rr.log(f"action/{label}", rr.Scalar(value))
# 发送质量检测警报
rr.log("alerts/frozen", rr.Scalar(1.0 if is_frozen else 0.0))
就这么几行,Rerun 会自动:
- 把同一时间戳的图像和 Scalar 对齐显示
- 在 Web 界面提供时间轴拖拽
- 高性能渲染,不会卡顿
6. 总结与开源地址
局限与未来
目前主要针对 BridgeData V2 做了优化,解析逻辑是和它的 schema 绑定的。如果要支持其他 Open X-Embodiment 数据集,需要稍微改一下 loader.py 里的字段映射。欢迎提 PR 一起扩展!
而且目前展示的逻辑很不好,视频会重复的堆叠在一块,导致后面的视频看不见了,目前科研任务比较重,之后会抽时间修复。
代码已经开源在 GitHub:
👉 https://github.com/kwfang/Quick-Bridge-Streamer
如果你也恰好被 TFRecord 折磨过,欢迎来薅羊毛,或者提 Issue/PR 一起完善。工具刚写完,肯定还有不少坑,多多包涵 🙏

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)