VLA 模型说到底就是缺乏对物理世界的理解!英伟达给出了解决方案~
DreamZero 的核心价值不仅在于性能突破,更在于重构了机器人学习的技术范式——从 “依赖重复演示的特化学习” 转向 “学习物理规律的通用化学习”。其通过世界动作模型(WAM)实现了三大跨越:**泛化能力:**零样本应对未见过的任务与环境,平均性能超 SOTA VLA 模型 2×;**数据效率:**多样化非重复数据即可训练,跨模态迁移仅需 10-20 分钟纯视频数据;**部署实用性:**38×
在机器人从 “专项工具” 迈向 “通用助手” 的赛道上,传统视觉-语言-动作(VLA)模型始终受困于 “只会模仿、不会推理” 的瓶颈——能执行训练过的动作,却无法应对未见过的任务与环境。NVIDIA 推出的 DreamZero 框架,创新性地构建了 “世界动作模型(WAM)”,通过视频扩散模型的预训练优势,实现了 “预测未来视频 + 生成对应动作” 的端到端协同,在零样本泛化、跨机器人适配、实时部署三大核心维度实现突破,为通用型机器人操作提供了全新技术路径。
痛点直击:传统 VLA 模型的三大能力短板
现有 VLA 模型虽能衔接视觉语义与机器人动作,但距离真实世界的复杂需求仍有显著差距,核心痛点集中在三方面:
| 痛点类型 | 具体表现 | 核心影响 |
|---|---|---|
| 泛化能力局限 | 依赖大量重复演示数据,仅能在语义层面泛化(如识别不同物体),无法应对全新动作技能(如系鞋带)与未知环境 | 难以适配开放世界场景,每类任务都需单独收集数据 |
| 数据效率低下 | 复杂动作需专家级重复演示,异质化、非重复性数据难以被有效利用,数据收集成本极高 | 规模化落地受限,无法快速覆盖多场景任务需求 |
| 实时性不足 | 大参数模型推理延迟高,视频扩散类模型的迭代去噪过程进一步加剧 latency,难以满足闭环控制需求 | 动态环境中易卡顿,硬件损耗风险高,无法实现灵巧操作 |
这些问题的本质是:VLA 模型缺乏对物理世界动力学的理解,仅建立 “视觉-动作” 的直接映射,而非 “理解场景-预测结果-规划动作” 的完整逻辑链。
硬核拆解:DreamZero 的四大核心创新
DreamZero 围绕 “架构-数据-优化-迁移” 形成全链路突破,每个模块都精准破解传统方案短板,其整体框架实现了从 “模仿学习” 到 “预测学习” 的范式转变。其核心突破在于重构了机器人决策的范式,通过 “预测未来视觉状态 + 对齐动作序列” 的双目标设计,让模型具备物理世界理解能力,而非单纯的动作模仿。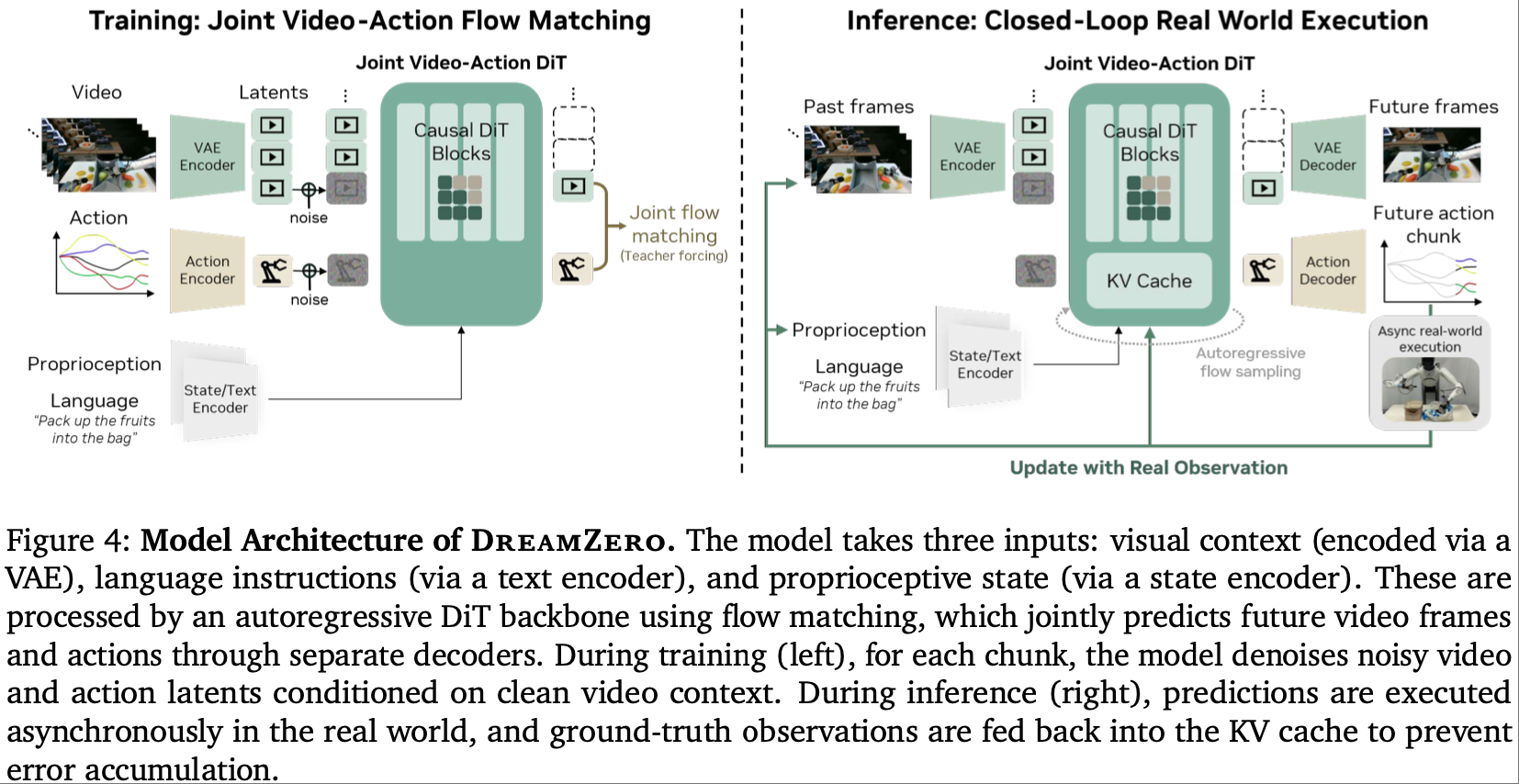
核心架构:三输入-双输出的端到端联合预测范式
DreamZero 摒弃了 VLA 模型 “视觉-动作” 的直接映射逻辑,构建了以 “世界建模” 为核心的 WAM 架构,实现动作与视觉未来的深度绑定:
-
输入模态融合:同时接收三类关键信息,形成完整的决策上下文:
视觉上下文:当前及历史图像经 VAE 编码为 latent 特征,保留空间细节与时序关联;
语言指令:通过文本编码器解析自然语言意图(如 “解鞋带”“握手”),生成语义嵌入;
本体感知状态(Proprioception):机器人关节姿态、夹爪开合度等物理状态数据,确保动作符合运动学约束。
-
联合预测目标:通过自回归扩散 Transformer(DiT)骨干网络,同步输出两部分核心结果,公式表达为:
π 0 ( o l : l + H , a l : l + H ∣ o 0 : l , c , q l ) ⏟ DREAMZERO = π 0 ( o l : l + H ∣ o 0 : l , c , q l ) ⏟ video prediction π 0 ( a l : l + H ∣ o 0 : l + H , q l ) ⏟ IDM \underbrace{\pi_0\left(\mathbf{o}_{l:l+H}, \mathbf{a}_{l:l+H} \mid \mathbf{o}_{0:l}, \mathbf{c}, \mathbf{q}_l\right)}_{\text{DREAMZERO}} = \underbrace{\pi_0\left(\mathbf{o}_{l:l+H} \mid \mathbf{o}_{0:l}, \mathbf{c}, \mathbf{q}_l\right)}_{\text{video prediction}} \underbrace{\pi_0\left(\mathbf{a}_{l:l+H} \mid \mathbf{o}_{0:l+H}, \mathbf{q}_l\right)}_{\text{IDM}} DREAMZERO π0(ol:l+H,al:l+H∣o0:l,c,ql)=video prediction π0(ol:l+H∣o0:l,c,ql)IDM π0(al:l+H∣o0:l+H,ql)
其中:
-
前半部分 π 0 ( o l : l + H ∣ o 0 : l , c , q l ) \pi_0\left(\mathbf{o}_{l:l+H} \mid \mathbf{o}_{0:l}, \mathbf{c}, \mathbf{q}_l\right) π0(ol:l+H∣o0:l,c,ql)为视频预测分支,基于历史视觉、语言指令和本体状态,生成未来 H 帧的环境演变视频,本质是 “视觉规划”;
-
后半部分 π 0 ( a l : l + H ∣ o 0 : l + H , q l ) \pi_0\left(\mathbf{a}_{l:l+H} \mid \mathbf{o}_{0:l+H}, \mathbf{q}_l\right) π0(al:l+H∣o0:l+H,ql)为逆动力学(IDM)动作分支,根据预测的未来视频,反推实现该视觉结果所需的连续动作序列。
两分支共享骨干网络参数,确保动作与视觉结果在物理时空上完全对齐——例如预测 “握手” 的未来视频后,动作分支会生成符合人体工学的手臂抬起、握持、上下摆动序列。
- 自回归(AR)设计优势:相比双向扩散架构,自回归模式通过 KV 缓存机制支持任意长度的上下文输入,保留原生帧率(避免视频下采样导致的动作错位),同时让模型能利用历史视觉信息修正决策,动作更平滑。此外,AR 架构仅对视频模态进行自回归建模,避免了动作预测的误差累积,提升闭环控制稳定性。
训练目标:流匹配与教师强制的双优化策略
为实现视频与动作的精准对齐及高效收敛,DreamZero 设计了针对性的训练目标:
- 流匹配(Flow Matching)损失:替代传统扩散模型的 DDPM 损失,统一视频与动作的去噪时序,通过学习 “从噪声到真实样本” 的连续流场,加速训练收敛并提升生成质量。具体而言,模型需预测视频 latent 和动作序列的联合速度向量 v k = [ z 1 k − z 0 k , a 1 k − a 0 k ] v^k=[z_1^k−z_0^k,a_1^k−a_0^k] vk=[z1k−z0k,a1k−a0k],其中 z 0 k z_0^k z0k、 a 0 k a_0^k a0k 为随机噪声, z 1 k z_1^k z1k、 a 1 k a_1^k a1k 为清洁样本,损失函数定义为:
L ( θ ) = E z , a , { t k } [ 1 K ∑ k = 1 K w ( t k ) ∥ u θ ( [ z t k k , a t k k ] ; C k , c , q k , t k ) − v k ∥ 2 ] \mathcal{L}(\theta) = \mathbb{E}_{\mathbf{z}, \mathbf{a}, \{t_k\}} \left[ \frac{1}{K} \sum_{k=1}^K w(t_k) \left\| \mathbf{u}_\theta\left( [\mathbf{z}_{t_k}^k, \mathbf{a}_{t_k}^k]; \mathcal{C}_k, \mathbf{c}, \mathbf{q}_k, t_k \right) - \mathbf{v}^k \right\|^2 \right] L(θ)=Ez,a,{tk}[K1k=1∑Kw(tk) uθ([ztkk,atkk];Ck,c,qk,tk)−vk 2]
其中 w ( t k ) w(t_k) w(tk)为时序权重函数,确保不同去噪阶段的训练稳定性。
- 教师强制(Teacher Forcing)策略:训练时用清洁的历史数据(前序视频帧 + 动作)引导当前 chunk 的去噪过程,避免模型在训练初期因噪声累积导致的预测偏差,提升视频-动作对齐精度。
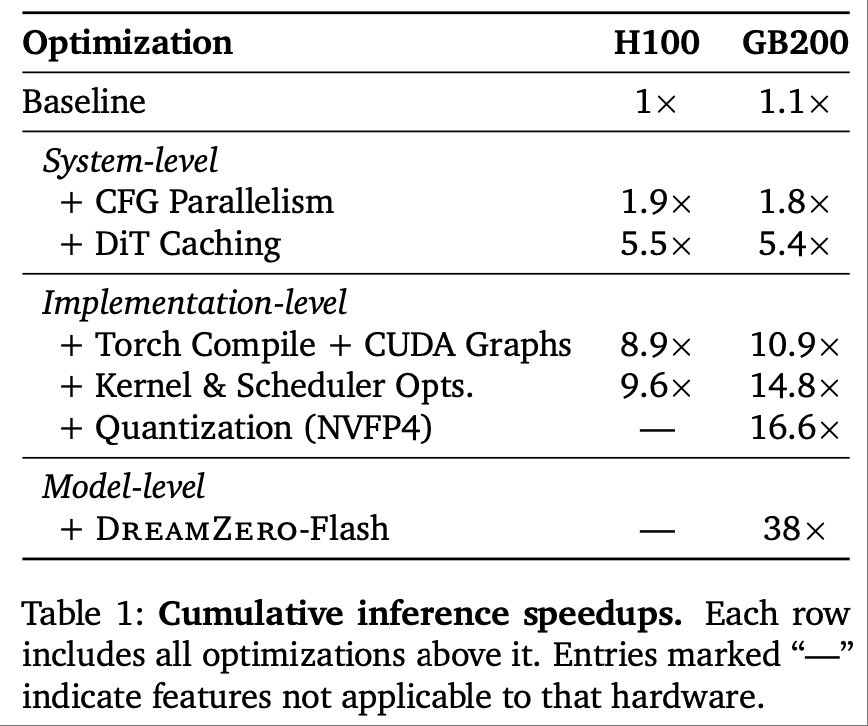
实时性优化:三级加速策略实现38×推理提速
视频扩散模型的迭代去噪过程天然存在高延迟问题,DreamZero 通过 “算法-系统-实现” 三级优化,将单动作 chunk 推理延迟从 5.7s 降至 150ms,支持 7Hz 实时闭环控制:
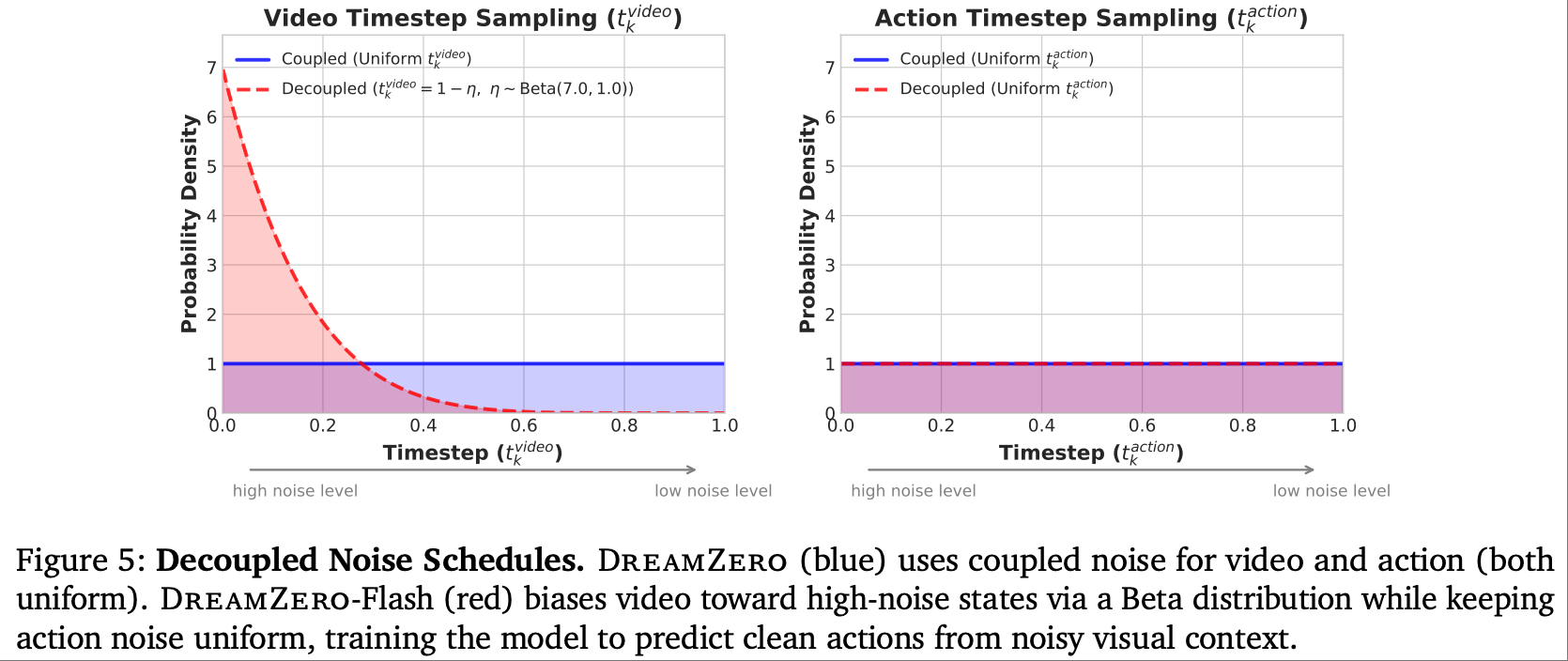
- 算法级(DreamZero-Flash)
解耦视频与动作的去噪时序,视频端偏向高噪声状态(Beta (7,1) 分布, E [ t k v i d e o ] = 0.125 \mathbb{E}[t_k^{video}]=0.125 E[tkvideo]=0.125),动作端保持均匀噪声分布。
扩散步数从 4 减至 1,速度提升 2.33×,任务进度仅下降 9%。

- 系统级
CFG 并行:双 GPU 分别执行条件 / 无条件推理,单步延迟降低 47%;
DiT 缓存:复用方向一致的速度向量,有效 DiT 步数从 16 减至 4;
系统级优化累计提升 5.4×(GB200 平台)。
- 实现级
Torch Compile + CUDA Graphs:算子融合,消除 CPU 开销;
NVFP4 量化:权重 / 激活量化为 NVFP4,敏感操作(QKV、Softmax)保留 FP8;
内核优化:cuDNN 后端加速注意力计算,调度器操作迁移至 GPU。
H100 平台速度提升 16.6×,GB200 平台最终实现 38× 提速。
- 动作平滑补充:生成的动作 chunk 经 2× 上采样、Savitzky-Golay 滤波(窗口大小 21,多项式 3 阶)、下采样处理,抑制高频噪声,避免机械臂卡顿或抖动。
数据策略:多样化优先,打破重复演示依赖
DreamZero 颠覆了传统机器人学习对 “结构化重复数据” 的依赖,证明异质化、非重复性数据更能提升泛化能力:
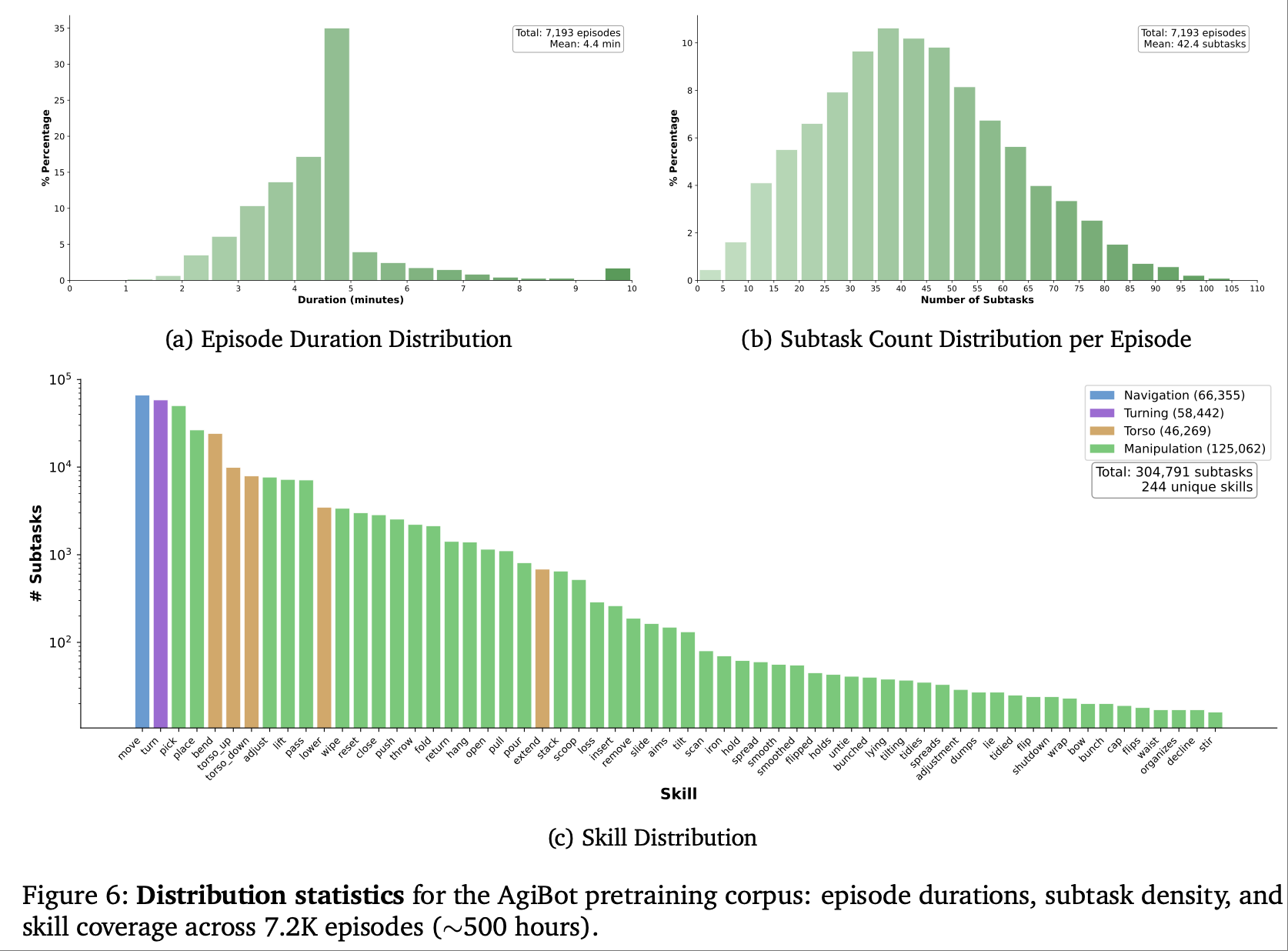
- 数据构建原则:采集 500 小时跨 22 类真实环境(家庭、餐厅、超市、办公室等)的遥操作数据,每个 episode 平均包含 42 个子任务,涵盖双臂操作、移动导航、工具使用等场景,优先保证 “任务多样性” 而非 “单任务重复次数”;
- 数据质量控制:通过 3D 一致性验证过滤异常样本——将关节 6D 姿态经相机参数投影至图像平面,计算重投影误差,剔除物理上不合理的轨迹;
- 数据效率优势:模型通过视频预测学习物理规律(如物体重力、碰撞逻辑),从多样化场景中提炼通用技能(如 “抓取-移动-放置” 的底层逻辑),无需针对单个任务重复采集数据。
实验分析:多维度验证核心能力与技术优势
DreamZero 在 AgiBot G1 双臂机器人、Franka 单臂机器人上完成全面验证,核心围绕 “泛化能力、数据效率、跨机器人迁移、实时性” 四大维度展开,实验设计严谨,对比基线涵盖当前 SOTA VLA 模型(GR00T N1.6、 π 0.5 \pi_{0.5} π0.5)。

核心实验设计:变量控制与基准设定
- 实验平台:
实机:AgiBot G1(移动双臂机器人)、Franka(单臂机器人);
基线模型:GR00T N1.6、 π 0.5 \pi_{0.5} π0.5,均设置 “从 scratch 训练”(仅用与 DreamZero 相同的 500 小时数据)和 “预训练初始化”(基于数千小时跨机器人数据预训练)两种配置,确保公平对比;
评估标准:任务进度(0-1.0 分,基于部分完成度打分)、成功率、推理延迟、动作平滑度。
-
关键变量定义:
- 见过的任务(Seen Tasks):动作模式与训练数据一致,仅物体 / 环境变化(如训练折叠红衬衫,测试折叠黑衬衫);
- 未见过的任务(Unseen Tasks):动作模式未出现在训练数据中(如解鞋带、握手、熨烫);
- 跨模态迁移:仅使用其他机器人(YAM)或人类的纯视频数据(无动作标注)进行迁移;
- 少样本形态适配:仅用 30 分钟 “玩耍数据”(无任务标注,随机交互)适配新机器人(YAM)。
核心实验结果与深度分析
Q1:WAM 能否从多样化非重复数据中高效学习?
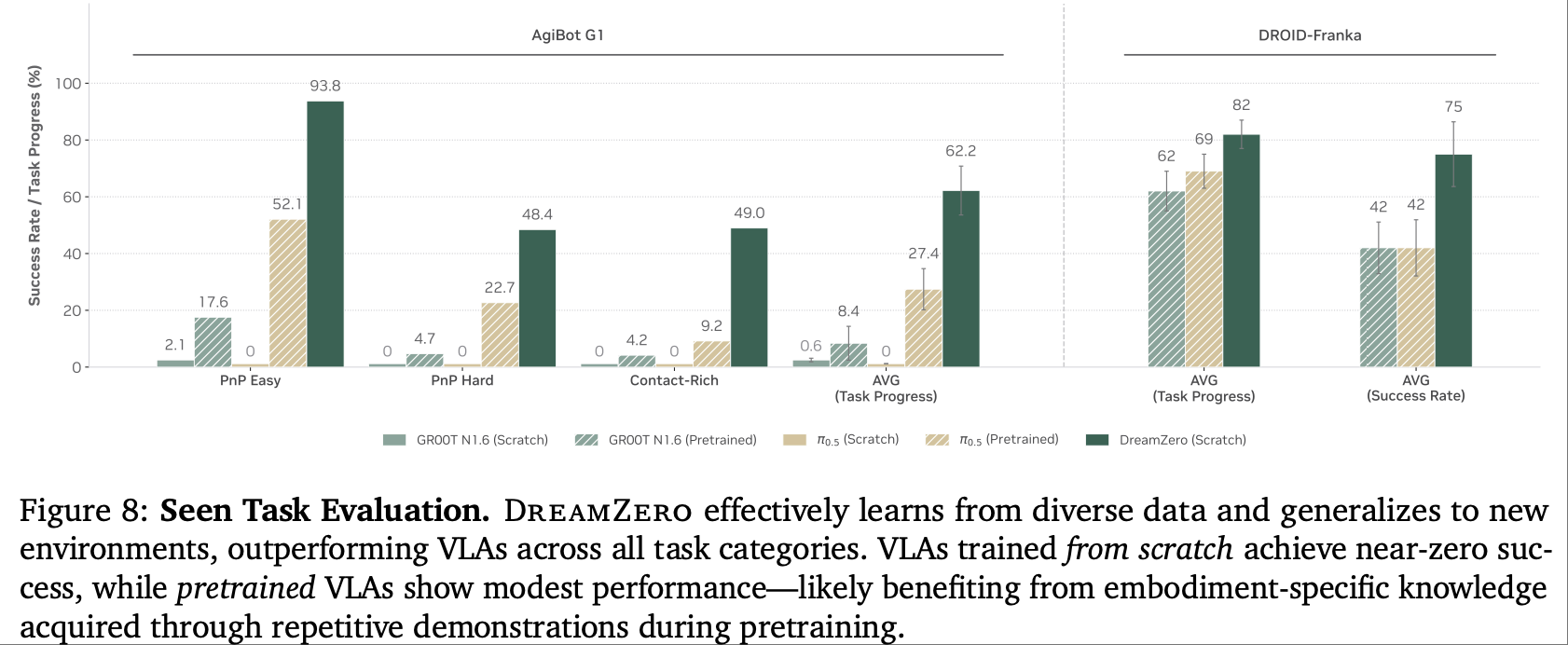
- 实验设置:在 “见过的任务 + 未知环境 + 未知物体” 场景下,对比 DreamZero 与 VLA 模型的任务进度。
- 结果:DreamZero 平均任务进度达 62.2%(AgiBot G1 平台),是最佳预训练 VLA 基线(27.4%)的 2.2 倍;Franka 平台上,仅训练 DROID 数据集的 DreamZero 同样超越基于多机器人数据预训练的 VLA 模型。
- 分析:VLA 模型依赖 “视觉-动作” 直接映射,需大量重复数据才能学习稳定关联,而 DreamZero 通过视频预测学习物理规律,从多样化数据中提炼通用技能,即使面对未知物体 / 环境,也能基于物理常识规划动作。
Q2:WAM 对未见过的任务是否具备零样本泛化能力?
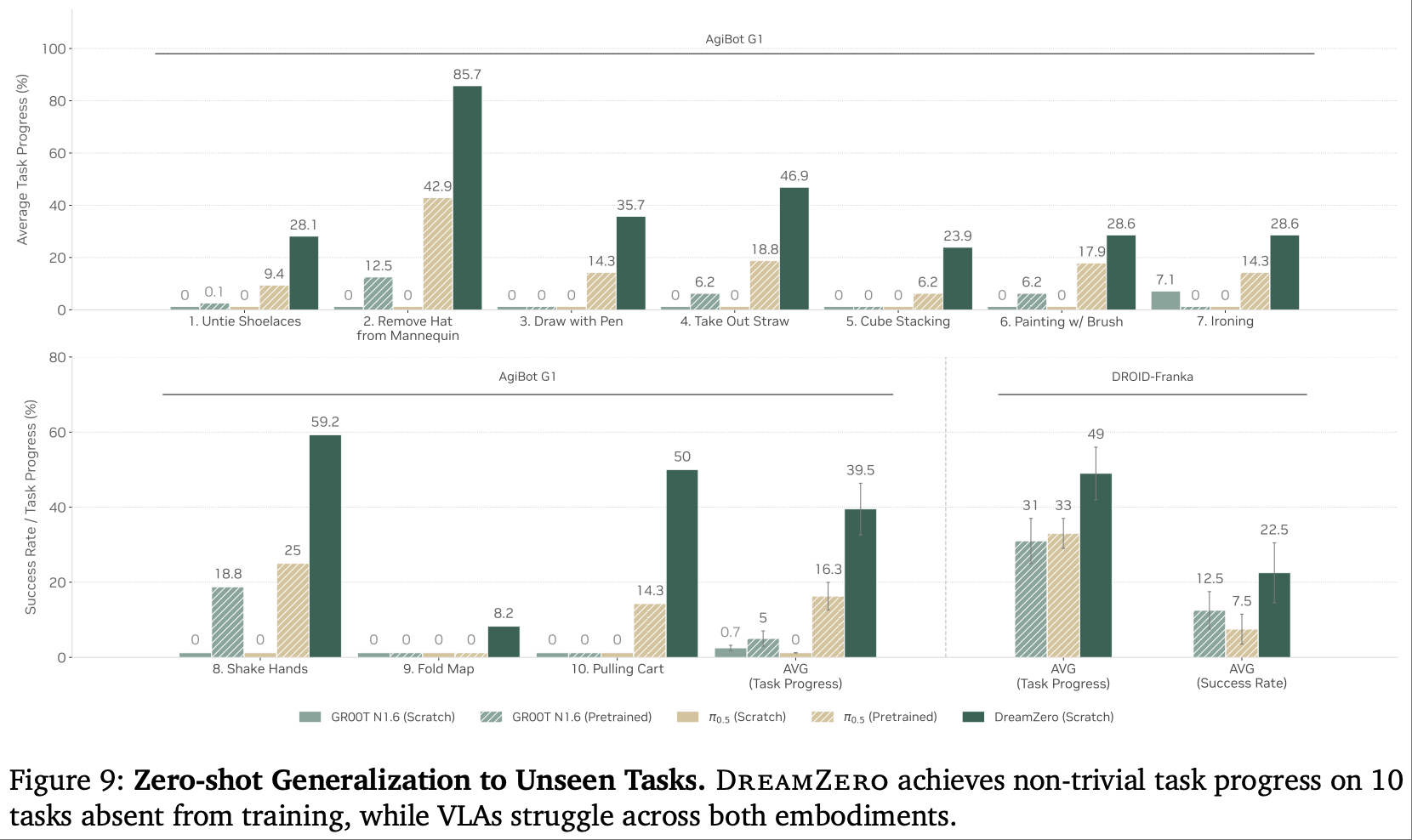
- 实验设置:评估 10 类训练中未出现的任务(解鞋带、握手、熨烫、绘画等),对比模型零样本表现。
- 结果:DreamZero 平均任务进度达 39.5%(AgiBot G1),其中 “从人体模型取帽” 成功率 85.7%,“握手” 成功率 59.2%;而从 scratch 训练的 VLA 模型任务进度不足 1%,预训练 VLA 基线仅 16.3%。
- 定性分析:VLA 模型常陷入 “抓取执念”—— 无论指令是 “握手” 还是 “熨烫”,均尝试抓取物体,体现出对任务语义的理解不足;而 DreamZero 能根据指令生成对应的视觉规划,再执行匹配动作(如 “握手” 时手臂自然抬起、握持、摆动),展现出真正的任务理解能力。
Q3:后训练后能否保留环境泛化能力?
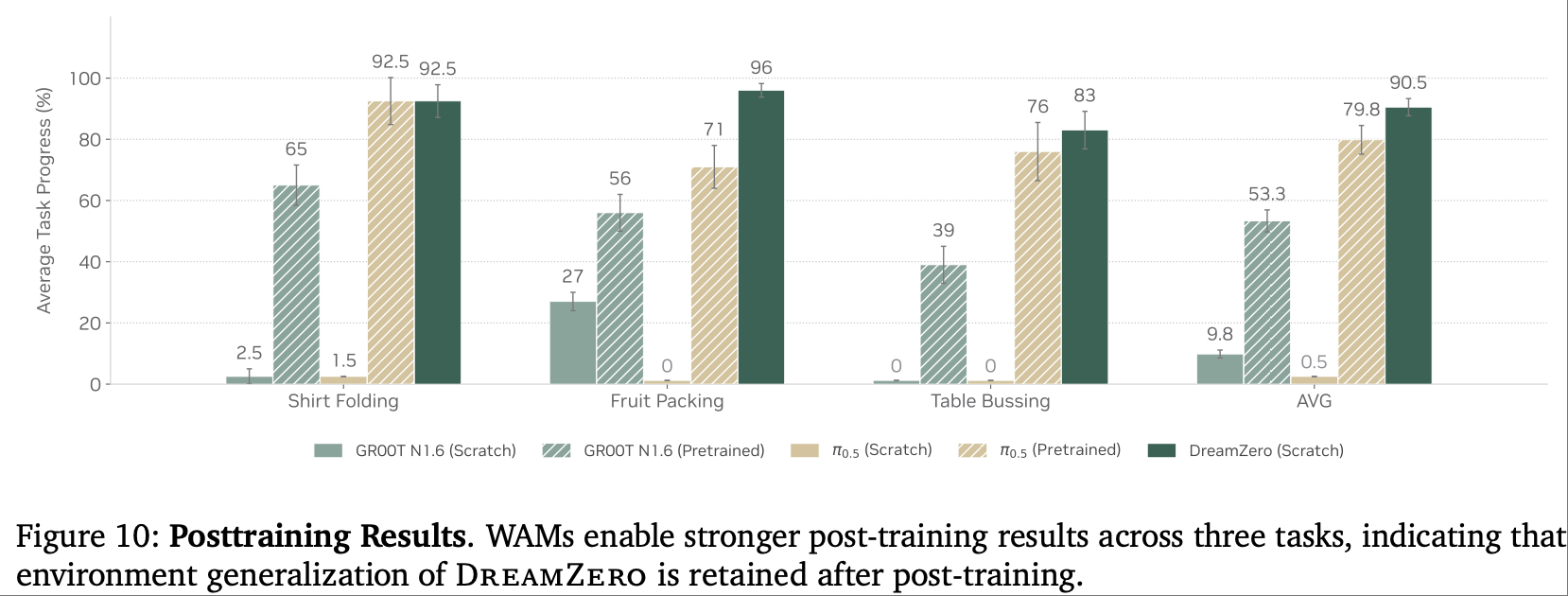
- 实验设置:针对衣物折叠(33 小时)、水果打包(12 小时)、餐桌清理(40 小时)三类任务进行后训练,在未知环境中评估任务进度。
- 结果:DreamZero 在三类任务中均匹配或超越 VLA 基线,水果打包任务表现尤为突出,平均任务进度超 VLA 基线 10%。
- 分析:VLA 模型后训练易过拟合,无法适应评估环境的桌子高度、物体位置变化;而 DreamZero 后训练仅优化任务相关细节,保留了视频预测带来的物理规律认知,因此仍能泛化到未知环境。
Q4:跨模态迁移与少样本形态适配效果如何?
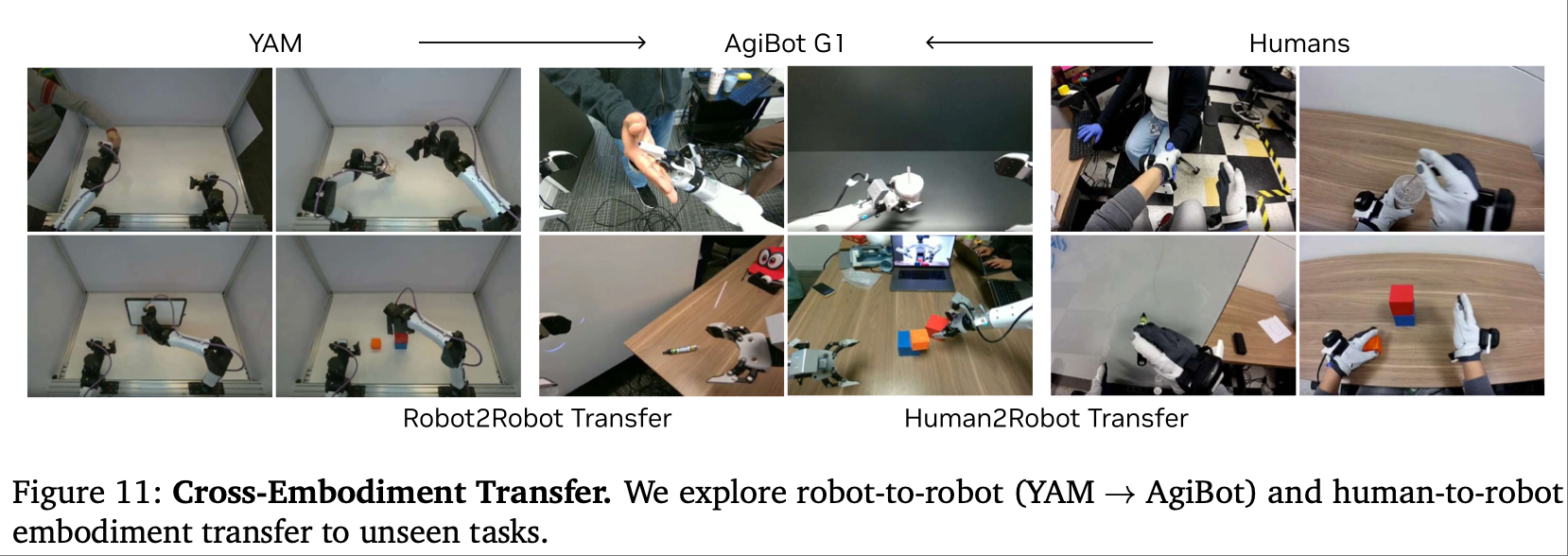
-
跨模态迁移(Robot-to-Robot/Human-to-Robot):
-
实验设置:仅使用 10-20 分钟纯视频数据(无动作标注),分别来自 YAM 机器人(20 分钟)或人类第一视角(12 分钟),与 AgiBot 预训练数据 1:1 混合微调。
-
结果:机器人跨模态迁移后任务进度从 38.3% 提升至 55.4%,人类跨模态迁移提升至 54.3%,相对提升均超 42%。
-

-
分析:WAM 仅需视觉信息即可学习任务动力学(如 “折叠” 的动作逻辑),无需动作标注,突破了 VLA 模型对 “同形态动作数据” 的依赖,为利用海量人类视频数据提供了可能。
-
少样本形态适配:
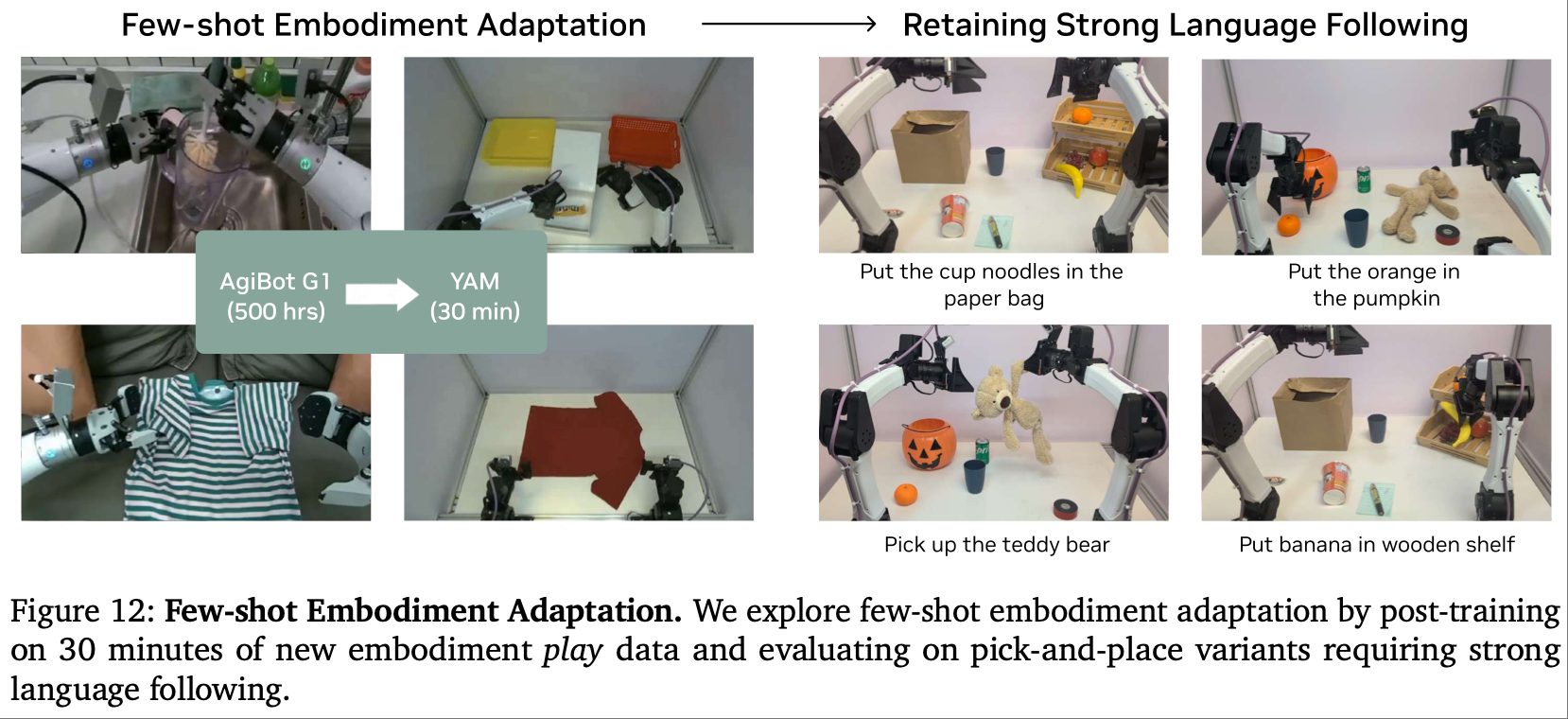
-
实验设置:预训练于 AgiBot G1 的模型,仅用 30 分钟 YAM 机器人 “玩耍数据”(55 条轨迹,11 类任务)进行后训练,评估语言跟随与未知物体操作能力。
-
结果:模型能准确执行 “将南瓜放入橙子”“把泰迪熊捡起” 等指令,即使面对训练中未见过的物体(南瓜、杯面、纸袋),仍保持 tight 视频-动作对齐。
-
分析:适配效率源于两方面:
AgiBot 与 YAM 均为双臂平行夹爪,形态相似;
WAM 学习的是 “视觉未来→动作” 映射,而非直接的 “观测→动作” 映射,只需少量数据调整形态相关参数即可适配。
Q5:模型规模、数据多样性、架构对性能的影响(消融实验)
DreamZero 通过消融实验验证了关键设计的必要性:
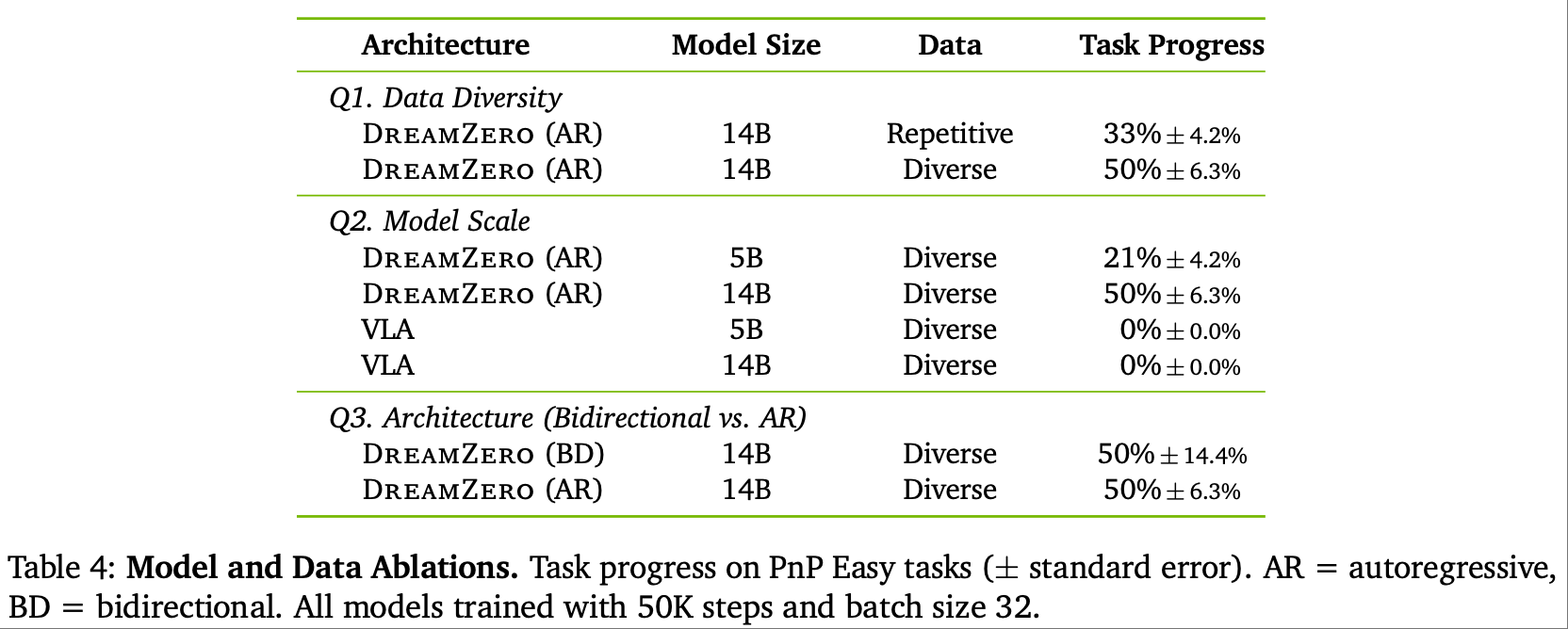
- 数据多样性:14B 模型在多样化数据上的任务进度(50%)显著高于重复数据(33%),证明 WAM 需通过多样场景学习物理规律,重复数据无法提供足够的状态覆盖;
- 模型规模:14B 模型(50%)远超 5B 模型(21%), smaller 模型易出现视觉幻觉(如预测不存在的物体运动),进而导致动作错误;而 VLA 模型即使扩大至 14B 规模,仍无法从多样化数据中学习(任务进度 0%),证明架构差异是核心瓶颈;
- 架构选择:自回归(AR)与双向(BD)架构任务进度均为 50%,但 AR 模型动作更平滑,推理速度快 3-4×,且无 FPS 失真问题,更适合闭环控制。
失败案例分析与改进方向
- 主要失败场景:模型失败多源于视频预测错误,而非动作提取错误。例如 “用马克笔在白板画画” 任务中,视频预测分支误生成 “传递马克笔” 的画面,动作分支便执行传递动作而非画画;“烤可颂” 任务中,视频预测未包含 “打开烤箱” 步骤,导致机器人直接手持面包靠近烤箱。

- 改进启示:失败案例验证了 “视频生成质量=策略性能” 的核心逻辑,未来可通过提升视频扩散模型的长时域一致性、强化语言-视觉对齐精度,进一步降低失败率。
总结:开启机器人通用智能的 “预测时代”
DreamZero 的核心价值不仅在于性能突破,更在于重构了机器人学习的技术范式——从 “依赖重复演示的特化学习” 转向 “学习物理规律的通用化学习”。其通过世界动作模型(WAM)实现了三大跨越:
**泛化能力:**零样本应对未见过的任务与环境,平均性能超 SOTA VLA 模型 2×;
**数据效率:**多样化非重复数据即可训练,跨模态迁移仅需 10-20 分钟纯视频数据;
**部署实用性:**38× 推理提速实现 7Hz 实时控制,少样本适配新机器人仅需 30 分钟数据。
尽管目前在亚厘米级高精度任务(如钥匙插入)、超长时间域规划(如复杂装配)上仍有优化空间,但 DreamZero 已证明:视频预训练的物理动力学知识,是破解机器人 “泛化难、数据贵、部署慢” 三大痛点的关键。未来通过融合大规模人类日常视频数据、优化长时域推理能力、轻量化模型适配边缘设备,有望加速机器人在家庭服务、工业柔性生产、医疗辅助等场景的规模化应用。
具身求职内推来啦
国内最大的具身智能全栈学习社区来啦!
推荐阅读
从零部署π0,π0.5!好用,高性价比!面向具身科研领域打造的轻量级机械臂
工业级真机教程+VLA算法实战(pi0/pi0.5/GR00T/世界模型等)
具身智能算法与落地平台来啦!国内首个面向科研及工业的全栈具身智能机械臂
VLA/VLA+触觉/VLA+RL/具身世界模型等!具身大脑+小脑算法与实战全栈路线来啦~
MuJoCo具身智能实战:从零基础到强化学习与Sim2Real
Diffusion Policy在具身智能领域是怎么应用的?为什么如此重要?
1v1 科研论文辅导来啦!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 15
15 0
0- 0



 已为社区贡献106条内容
已为社区贡献106条内容

所有评论(0)