Survey:VLA模型强化学习在机器人操作中的研究综述
本文是对论文《A Survey on Reinforcement Learning of Vision-Language-Action Models for Robotic Manipulation》的深度解读。在机器人操作领域,预训练视觉 - 语言 - 动作模型(VLAs)受限于模仿学习,在分布外场景泛化不足。该综述首次构建 RL-VLA 完整分类体系,从架构、训练范式、真实部署及基准测试四大维
引言:从模仿到自主的机器人操作革命
在机器人学与人工智能领域,构建能在非结构化环境中完成多样化操作任务的通用机器人系统始终是核心目标。近年来,视觉 - 语言 - 动作模型(VLAs)通过大规模预训练和模仿学习,在跨物体类别、任务变体和机器人形态的零样本与少样本泛化方面取得了突破性进展,彻底改变了传统任务特定型策略主导的机器人学习范式。
然而,依赖模仿学习的 VLAs 存在固有局限:受限于预训练数据集的状态与动作覆盖范围,在分布外(OOD)场景中表现不佳;缺乏故障恢复演示导致鲁棒性不足;纯粹的模仿目标阻碍了对未见过的更优策略的探索。为解决这些问题,强化学习(RL)凭借自探索和结果驱动的优化特性,成为增强 VLA 泛化能力的关键技术。
本文精读的《A Survey on Reinforcement Learning of Vision-Language-Action Models for Robotic Manipulation》一文,首次系统性梳理了 RL-VLA 这一新兴领域,构建了涵盖 "架构 - 训练范式 - 实际部署 - 基准测试" 的完整分类体系,为研究者提供了从预训练 VLA 到稳健部署系统的清晰路径。

代码链接:无
沐小含持续分享前沿算法论文,欢迎关注...
一、研究背景与问题定义
1.1 VLA 模型:视觉 - 语言 - 动作的端到端统一
VLA 模型代表了机器人学习的新范式,将视觉感知、语言理解和动作生成整合到单一端到端框架中,彻底改变了传统机器人系统中感知、规划与控制模块分离的架构。其核心组件包括:
- 视觉编码器:处理多视角 RGB 图像或深度信息,转化为视觉 Token;
- 语言编码器:将任务指令嵌入为语义表征;
- 策略解码器:将融合后的视觉 - 语言表征映射为连续或离散的机器人动作。
典型模型如基于 Transformer 架构的 RT-1(离散动作预测)、支持互联网级知识迁移的 RT-2、开源模型 OpenVLA(基于 Llama 2 与 DINOv2/SigLIP 视觉特征融合),以及采用流匹配架构的 π0 系列(支持复杂灵巧操作)。这些模型通过大规模数据收集、预训练和后训练,展现出强大的跨任务泛化能力。
VLA 的主流训练范式为模仿学习(IL),主要以监督微调(SFT)或行为克隆(BC)形式实现,核心目标是学习最大化专家动作似然的策略。但该范式严重依赖演示数据的质量和覆盖范围,在领域迁移场景中面临巨大挑战,亟需与 RL 技术融合以提升适应性和鲁棒性。
1.2 RL-VLA 的问题形式化定义
论文将机器人操作任务形式化为马尔可夫决策过程(MDP),定义为元组![]() ,其中:
,其中:
- 状态空间
:多模态高维空间,
=
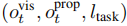 ,包含视觉观测(RGB 图像、点云)、本体感受信息(关节角度、末端执行器姿态)和语言指令;
,包含视觉观测(RGB 图像、点云)、本体感受信息(关节角度、末端执行器姿态)和语言指令; - 动作空间
:
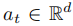 ,由 VLA 解码器生成,通常以动作块
,由 VLA 解码器生成,通常以动作块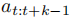 形式输出(基于扩散解码器或动作Tokenizers);
形式输出(基于扩散解码器或动作Tokenizers); - 奖励函数
:结合任务成功的稀疏二元信号与过程型稠密奖励(如目标距离),提供丰富学习信号;
- 转移模型
:
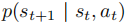 ,在仿真中显式定义或由真实机器人的物理交互隐式确定;
,在仿真中显式定义或由真实机器人的物理交互隐式确定; - 目标函数:学习策略
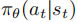 ,最大化期望折扣回报:
,最大化期望折扣回报:
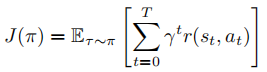
RL 算法主要分为三类:基于价值的方法(如 DQN)、策略梯度方法(如 PPO)和演员 - 评论家方法(如 SAC),进一步可分为模型无关型 / 模型基型、在线型 / 离线型。将 RL 与 VLA 融合的核心挑战在于处理多模态高维状态、动作块生成机制、奖励稀疏性及物理环境动态性。
1.3 RL 与 VLA 的协同价值
RL 与 VLA 的融合呈现显著协同效应:VLA 提供丰富的多模态表征,大幅提升 RL 的样本效率;RL 则使 VLA 突破次优预训练行为的限制,实现策略优化。实证表明,RL 优化的 VLA 模型在基准测试中表现显著优于单纯 SFT 训练的模型,且覆盖离线 RL、在线 RL 和测试时 RL 等多种范式。
当前学术界缺乏针对 RL-VLA 的系统性综述,现有研究要么聚焦 RL 在 LLM 或机器人学的单一应用,要么局限于 VLA 的模仿学习范式,这正是本文的核心贡献切入点。
二、RL-VLA 架构设计:动作、奖励与转移建模
RL-VLA 架构的核心是通过闭环优化过程,将 VLA 的开环推理转化为受在线反馈驱动的自适应系统。其设计围绕动作表征、奖励设计和转移建模三大核心组件展开,各组件的设计选择直接影响感知、决策与环境动态建模的联合优化效果。
2.1 动作建模:从 Token 到序列的优化范式
动作模型是视觉观测与物理交互的桥梁,RL 通过不同层级的监督的优化,提升 VLA 的动作生成泛化能力。论文将动作建模分为三类范式,其优化逻辑如图 2 所示:
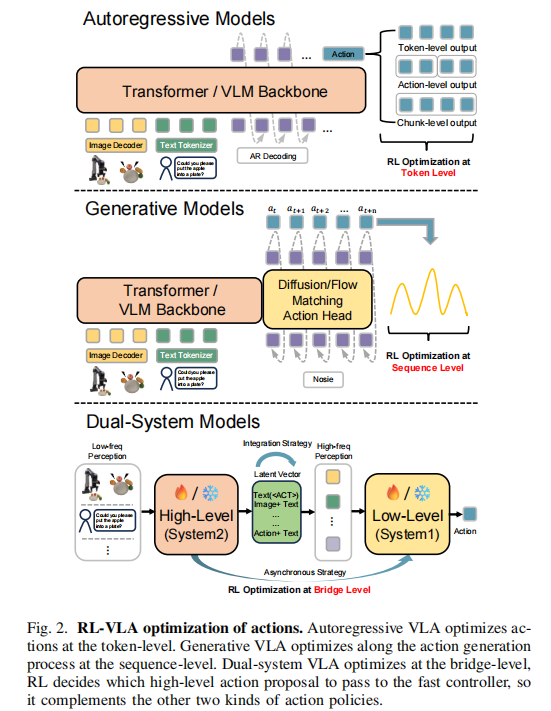
(1)自回归模型(Autoregressive Models)
遵循语言建模范式,将机器人操作视为离散 token 空间的序列决策过程,通过 next-token 预测逐步生成动作。RL 可直接利用自回归 VLA 输出的 token 预测概率,通过 token 级监督和奖励驱动机制实现稳定的策略优化。
代表性工作包括:
- TGRPO:将策略梯度目标重写为优势加权的 token 级交叉熵损失,实现 VLA 动作生成的稳定 RL 微调;
- CO-RFT:利用动作概率的时空动态特性,解决自回归 VLA 离散动作预测中的轨迹一致性问题。
挑战:离散动作 token 导致灵巧操作困难 —— 粗粒度 token 设计丢失精细控制能力,细粒度 token 化则降低动作 token 间的区分度,增加预测难度。
(2)生成式动作 VLA(Generative Action VLAs)
为解决离散动作预测的时间一致性问题,采用基于扩散(diffusion-based)或流匹配(flow-matching)的动作头直接生成动作轨迹。由于生成式动作头无法提供显式动作预测概率,需通过重参数化输出近似概率分布以适配 RL 监督。
代表性工作包括:
- πRL:采用 Flow-SDE 或 Flow-Noise 干预进行去噪,生成动作分配的近似概率,与现有 RL 策略更新对齐;
- FPO:利用每个样本的变化替代动作概率,缩小流匹配头与 RL 更新策略的差距,提升收敛稳定性;
- ARFM:提出动态缩放因子调整策略,优化样本权重分配,提高样本利用率和训练稳定性。
挑战:生成式 VLA 依赖仅在高奖励区域调优的近似密度或基于损失的智能体,更新受局部采样的不完美信号驱动,而非全局动作分布,导致小偏差在多步生成和迭代更新中累积,最终扭曲原始动作分布。
(3)双系统模型(Dual-system Model)
针对长视野任务和人类指令理解需求,设计高低两级架构:高层任务规划 VLM 理解人类意图并生成分步子任务,低层动作控制 VLA 提供操作轨迹。RL 的核心作用是促进两系统间的双向价值对齐,确保 VLM 生成的子任务可被 VLA 执行。
代表性工作:Hume 通过 RL 训练高层任务规划系统,从多个采样动作中选择最优解,显著提升低层控制的可行性。
挑战:高层 VLM 规划器与低层 VLA 控制器的异质表征和时间尺度差异,导致语言规划的价值估计与控制级回报不一致,引发联合 RL 训练不稳定和协调次优问题。
2.2 奖励建模:内在与外在的信号协同
奖励是 RL 的核心学习信号,决定策略的梯度方差、收敛效率和学习动态。针对 VLA 面临的奖励稀疏性和延迟问题,论文将奖励建模分为内在奖励和外在奖励两大类,通过构建稠密且信息丰富的奖励信号引导策略优化。
(1)内在奖励(Intrinsic Rewards)
基于数据集或智能体 - 环境交互的规则型自监督信号,鼓励智能体探索并构建行为模式,适用于外在奖励稀疏或延迟的场景,分为两类:
-
基于势能的奖励塑造(PBRS):通过辅助势能函数修改原始奖励信号:
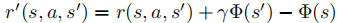
在不改变最优策略的前提下提供更稠密的反馈。势能函数可手动设计(如目标距离、能量减少)或从数据中学习(如近似价值函数、潜在进度估计器),前者具备可解释性和简洁性,后者适应性更强但可能引入塑造不稳定性。
-
探索驱动奖励(Exploration-driven Rewards):通过为探索动作分配额外内在价值,鼓励智能体探索新颖或不确定状态,避免过早收敛到次优策略。包括好奇心驱动方法(奖励高预测误差状态)、随机网络蒸馏(RND,通过固定随机网络的预测误差衡量状态熟悉度)和计数型方法(奖励未访问状态)。
挑战:缺乏与任务目标的显式对齐,可能导致奖励黑客(reward hacking)、高维空间中的奖励崩溃,或策略利用易获取的内在奖励而忽视任务进展;在长视野操作任务中效率低下,因多数新颖状态与任务无关。
(2)外在奖励(Extrinsic Rewards)
利用外部感知信息(语言指令、视觉观测、人类反馈)引导智能体行为,直接编码任务目标,提升策略优化的接地性和可解释性,分为两类:
-
人类对齐奖励(Human-aligned Rewards):编码人类偏好,确保智能体通过策略更新对齐人类价值。包括基于人类反馈的强化学习(RLHF,通过行为对的人类偏好比较训练奖励模型)、交互式方法(如 DemPref 迭代查询策略生成轨迹的偏好标签)和人类在环奖励塑造(如 Sirius 允许人类在训练中优化奖励函数)。
-
模型生成奖励(Model-generated Rewards):利用预训练基础模型替代人类反馈,实现跨环境的可扩展监督。代表性方法包括:
- 语言到奖励的转换(Reward Translator 将自然语言任务描述转化为参数化奖励代码);
- LLM 驱动的奖励进化(Eureka 通过 LLM 生成奖励代码提案并结合环境反馈迭代优化);
- 视频生成模型奖励(VIPER 利用专家演示训练视频预测 Transformer,将模型似然作为奖励);
- VLM 查询奖励(RoboCLIP 直接查询 VLM 从图像观测和文本描述中生成奖励)。
挑战:可扩展性、可靠性和对齐性问题突出 —— 人类对齐奖励易受主观偏差影响,模型生成奖励存在误指定风险,且两者均面临领域迁移和感知噪声的干扰,在复杂真实场景中效果受限。
2.3 转移建模:物理仿真与数据驱动的融合
转移建模旨在刻画动作条件下的环境动态,使智能体能够推断物理后果并评估动作序列,解决传统 VLA 在长时动态推理和因果动作 - 效应关系建模中的不足。论文将转移建模分为物理基仿真器和神经世界模型两类。
(1)物理基仿真器(Physics-based Simulator)
通过精确物理建模显式复现环境动态,定义环境中每个物体的属性和交互规则,预测动作对应的状态转移。代表性工具包括 Isaac Sim 和 Gazebo,通过将真实世界场景结构和物体参数迁移到仿真中,提升 RL-VLA 策略的仿真 - 真实迁移能力。
挑战:构建高保真仿真器需要大量人力和精确物理标注,且物理基推演的计算成本高昂,难以满足数据密集型学习系统的可扩展性需求。
(2)学习型世界模型(Learning-based World Model)
数据驱动的转移建模方法,直接从大规模操作演示中学习未来状态预测,无需显式物理规则,分为三类:
-
基于状态的方法(State-based Methods):将环境编码为紧凑的潜在状态空间,高效建模转移过程,专注于长视野动态和奖励预测而非视觉重建。代表性工作包括 PlaNet(循环状态空间模型)、Dreamer 系列(增强潜在状态空间的表达能力)和 TransDreamer(采用 Transformer 架构提升长视野预测稳定性)。
-
基于观测的方法(Observation-based Methods):直接建模像素级观测转移,生成保留几何和视觉保真度的真实环境推演,使奖励与视觉预测对齐。代表性工作包括 iVideoGPT(微调预训练视频预测模型用于机器人场景)、GWM 和 iMoWM(融合多模态数据提升 3D 几何结构表征),以及 EmbodiedDreamer(通过 PhysAligner 整合物理仿真先验,VisAligner 增强观测真实感)。
-
VLA 专用方法(VLA-designed Methods):将世界模型与 VLA 框架深度融合,弥合语言条件推理与物理环境理解的鸿沟。代表性工作包括:
- VLA-RFT:基于 VLA 动作序列生成多个推演轨迹,利用 GRPO 优化框架和世界模型预测的奖励更新 VLA;
- World-Env:构建 "VLA 动作生成 - 世界模型预测 - 视觉语言语义反思 - LOOP 优化" 的完整流水线;
- WMPO:生成像素级想象轨迹,通过 GRPO 和学习型奖励模型优化策略,无需真实环境交互。
挑战:世界模型在跨场景、跨形态和跨机器人结构的泛化能力不足;数据驱动学习与物理一致性动态的平衡难度大,需整合人类知识或高保真仿真的物理先验以提升可靠性。
三、RL-VLA 训练范式:在线、离线与测试时的三维优化
训练范式是 RL-VLA 从预训练到 OOD 泛化的关键环节,论文根据智能体获取和利用环境反馈的方式,将其分为在线 RL-VLA、离线 RL-VLA 和测试时 RL-VLA 三类,各类方法的核心特性汇总于表 I。
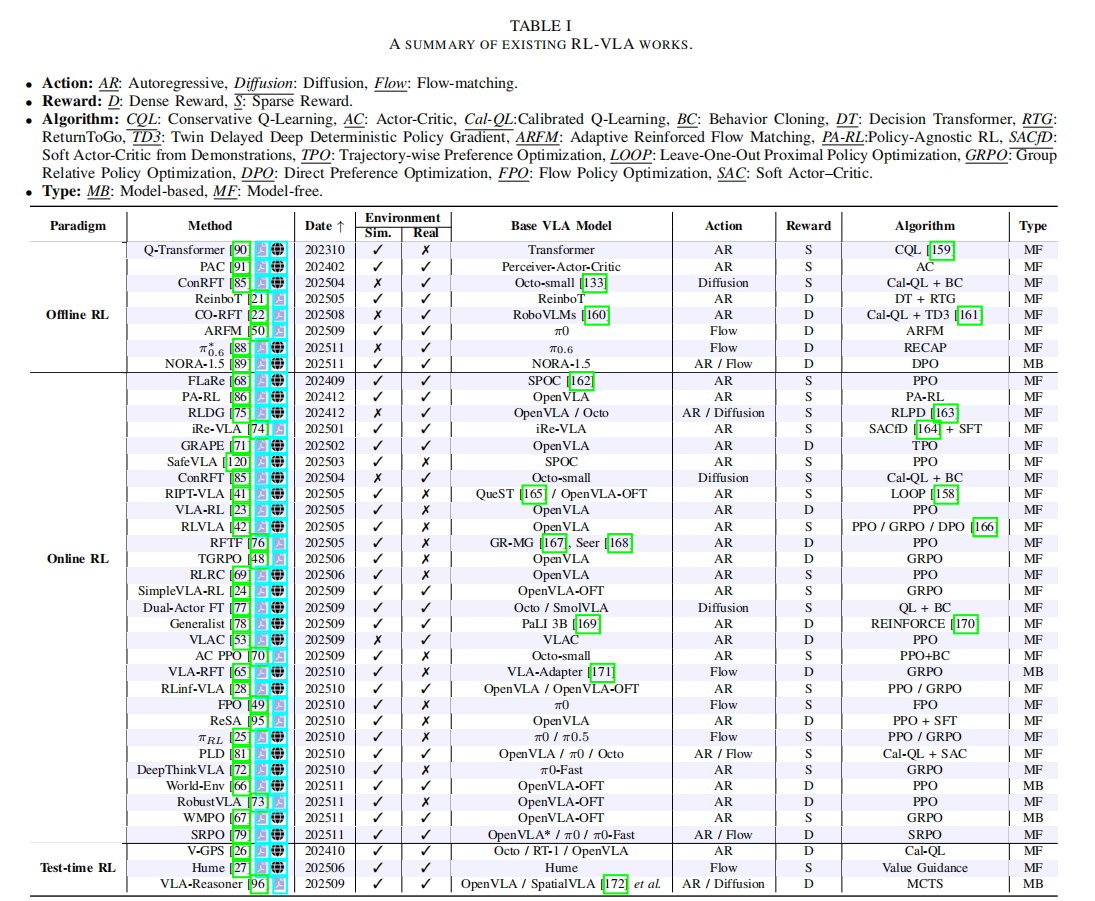
注:Action 类型中 AR = 自回归、Diffusion = 扩散型、Flow = 流匹配;Reward 类型中 D = 稠密奖励、S = 稀疏奖励;Algorithm 中包含各类 RL 算法变体;Type 中 MB = 模型基、MF = 模型无关。
3.1 在线 RL-VLA:交互驱动的闭环优化
在线 RL-VLA 通过智能体与环境的持续交互收集轨迹,基于观测奖励和状态转移更新策略,核心优势是通过试错过程赋予预训练 VLA 自适应闭环控制能力,适用于真实世界 OOD 环境。研究主要沿五个方向推进:
(1)策略优化(Policy Optimization)
核心是平衡优化 aggressiveness 与稳定性:过度激进易导致预训练动作空间中的训练不稳定,过度保守则增加交互成本。主流方案采用 PPO 变体,代表性进展包括:
- 基础方法:FLaRe 和 RLRC 直接将 PPO 用于 VLA 后训练;
- 改进算法:RIPT-VLA 结合留一法(RLOO)优势估计与 PPO,无需奖励塑造或价值函数;VLA-RL 引入机器人过程奖励模型提供稠密奖励;SimpleVLA-RL 采用 GRPO 实现更稳定的策略更新,在 LIBERO 基准测试中显著提升;
- 实证对比:RLVLA 比较 DPO、PPO 和 GRPO,证实 RL 微调在 OOD 泛化上显著优于 SFT;
- 流匹配适配:FPO 提出流策略优化算法,通过重要性采样提升流匹配 VLA 的优化效率;πRL 设计 Flow-Noise(将去噪过程建模为离散时间 MDP)和 Flow-SDE(整合去噪与智能体 - 环境交互);
- 鲁棒性增强:GRAPE 通过生成定制成本并在轨迹级数据上优化,对齐 VLA 与偏好;RobustVLA 引入雅可比正则化和平滑正则化项,提升对扰动的鲁棒性。
挑战:真实世界任务的动态需求扩展了动作空间,非平稳动态和多模态噪声导致为仿真或静态基准设计的策略优化方法难以维持稳定可靠的更新。
(2)样本效率(Sample Efficiency)
针对在线 RL 交互成本高昂的问题,通过利用演示先验知识和设计稠密监督信号提升效率:
- 演示融合:RLDG 结合人类专家演示与在线 RL 微调,通过蒸馏通用策略知识加速新任务学习;
- 两阶段训练:iRe-VLA 先进行 SFT 预热,再执行在线 RL,减少复杂操作任务的交互次数;
- 架构优化:VLAC 在单一 VLM 中整合演员 - 评论家架构,同时生成动作、稠密进度增量和完成信号;
- 人类反馈:DAFT 引入人类反馈干预探索过程,构建语言 - 干预对数据集;
- 自监督机制:Generalist 采用 SFT + 在线 RL 自改进的多阶段流水线;SRPO 利用策略自身成功轨迹作为自参考,获取渐进奖励无需标注。
挑战:现有方法多聚焦特定任务或环境内的数据利用,难以跨多样化目标或领域转移学习行为,限制大规模 RL-VLA 利用共享经验扩展新环境学习。
(3)主动探索(Active Exploration)
设计高效探索策略,减少随机推演的冗余成本,引导智能体收集高价值样本:
- 语义引导:Plan-Seq-Learn 利用 LLM 生成高层任务规划,转化为运动规划路标,引导探索向任务相关空间;
- 模态探索:SIME 在 RL 微调阶段引入模态级探索,生成预训练策略之外的多模态交互行为;
- 流形约束:SOE 学习任务相关因子的潜在表征,将探索限制在有效动作流形内,平衡安全性、多样性和有效性;
- 系统识别:ASID 通过主动探索收集少量信息丰富的真实数据,识别环境未知物理参数,构建更精确的仿真器;
- 故障生成:RESample 自动生成挑战性 OOD 数据,通过探索性采样创建故障和恢复轨迹;PLD 采用混合推演方案,偏向基础策略频繁访问的状态,同时捕获恢复行为。
挑战:探索策略依赖高维潜在表征,易受无关噪声污染;真实场景中的安全主动探索难度大,缺乏可解释性和约束机制,可能导致环境或机器人损坏。
(4)训练稳定性(Training Stability)
核心是确保策略更新的一致性,避免振荡收敛导致的泛化性能下降,主要通过扩大样本缓冲和减少样本分布方差实现:
- 采样机制:RIPT-VLA 采用动态推演采样(拒绝采样机制),解决在线 RL 微调中推演回报的高方差问题;
- 预训练稳定:ConRFT 先进行离线 RL 预训练稳定初始策略,再通过 HIL-SERL 框架进行在线微调;PARL 提出统一框架,直接优化动作并从通用损失函数中在线微调,解耦策略改进与模型参数更新;
- 轨迹级估计:TGRPO 通过轨迹级组相对策略优化减少更新方差;
- 世界模型辅助:World-Env 和 VLA-RFT 利用学习型世界模型生成合成推演,降低真实世界交互的方差和不稳定性。
挑战:现有方法局限于简单短视野操作任务(如拾取方块),难以扩展到复杂长视野任务(如制作三明治),因长视野任务要求 VLA 维持时间序列上的一致交互,任何单一错误都可能导致任务失败。
(5)学习框架(Learning Framework)
受 RL 在 LLM/VLM 微调中的成功启发,聚焦在线 RL-VLA 的基础设施建设:
- 灵活框架:RLinf 和 RLinf-VLA 支持大规模 VLA 的高效在线 RL 微调,兼容多种策略优化算法和模型架构,整合人类反馈和安全约束;
- 跨领域适配:vLLM 和 VeRL 等 LLM-RL 框架被适配到 VLA 领域。
挑战:现有框架多绑定特定架构或优化方法,跨框架适应性差;自回归与生成式 VLA 的奖励获取差异增加了统一支持难度;多模态观测、实时控制和物理约束导致 LLM-RL 系统向 VLA 的迁移面临巨大挑战。
3.2 离线 RL-VLA:静态数据的价值挖掘
离线 RL-VLA 利用静态数据集训练,无需环境交互,适用于高风险或资源受限场景。与单纯模仿演示的 IL-VLA 不同,其核心是从多样化过往经验中优化长时奖励,提升 OOD 泛化能力。研究主要沿数据利用和目标修改两个方向推进:
(1)数据利用(Data Utilization)
在无法收集新交互数据的约束下,最大化静态数据集的价值,分为两类方法:
- 定制化表征(Customized Representation):适配数据集或奖励信号以对齐策略优化目标。ReinboT 通过修改离线数据集最大化累积奖励;π*₀.₆利用预训练价值函数提供二值化价值,同时利用失败和成功数据;NORA-1.5 引入离线直接偏好优化,通过模型生成奖励优化 VLA。
- 保守约束(Conservative Constraint):限制策略更新避免偏离离线数据集分布,减少分布偏移。ConRFT 整合行为克隆与 Cal-QL,稳定小数据集的价值估计;CO-RFT 利用 Cal-QL 的校准机制,约束策略训练在训练数据支持范围内。
挑战:数据集构建是核心瓶颈 ——VLA 策略高度依赖数据质量和结构,不平衡数据集会加剧分布偏移;未经精心构建的离线数据集存在任务覆盖不均、行为分布有偏和奖励信号不完整等问题,导致 OOD 泛化性能差。
(2)目标修改(Objective Modification)
调整 RL 目标以适配新架构或支持数据集增强:
- 架构感知目标设计(Architecture-aware Objective Design):为多样化 VLA 架构定制 RL 目标。ARFM 针对流模型设计离线 RL 目标,通过自适应平衡因子控制 RL 影响;Q-Transformer 和 PAC 验证了 Transformer 类模型的离线 RL 适配性。
- 数据驱动目标适配(Data-driven Objective Adaptation):利用 RL 目标增强离线数据集多样性和覆盖范围。RL-100 采用离线 RL 目标保守控制在线 PPO 智能体,生成高质量新数据;模型基离线 RL 利用静态数据集学习动态模型,生成合成推演。
挑战:架构感知目标增加了复杂性,缺乏统一框架导致迁移性差;数据驱动目标适配存在分布漂移风险,不准确的生成器会产生低质量样本,破坏训练缓冲并 destabilize 学习。
3.3 测试时 RL-VLA:部署阶段的轻量适配
测试时 RL-VLA 通过轻量更新或适配器模块,在部署阶段自适应调整 VLA 行为,无需全模型微调,核心优势是快速适配新颖状态,提升真实场景中的鲁棒性和泛化能力。根据适配机制分为三类:
(1)价值引导(Value Guidance)
利用预训练奖励或价值函数直接影响动作选择,无需全策略更新:
- V-GPS:通过预训练价值函数对基础策略的动作候选重排序,选择预测价值最高的动作;
- Hume:双系统架构中的 "价值引导思考" 过程,生成多个动作候选并通过专用价值查询头选择最优解。
(2)记忆缓冲引导(Memory Buffer Guidance)
利用历史经验提升探索效率和知识复用:
- STRAP:构建紧凑的时空模式库,存储历史、结构和语义信息,推理时检索与当前输入相似的轨迹片段;
- RA-DT:存储过往经验的外部记忆,仅检索相关子轨迹用于上下文决策;
- ReSA:通过内在质量评估从回放缓冲中识别并模仿高质量成功轨迹,确保对齐任务目标。
(3)规划引导适配(Planning-guided Adaptation)
显式推理未来动作序列,基于基础 VLA 的初始提案优化动作:
- VLA-Reasoner:插件式框架,利用在线蒙特卡洛树搜索(MCTS)以基础策略的动作预测为起点,通过仿真未来结果寻找更优动作;
- BGR:利用单独训练的价值函数估计完成时间,实时监测预测一致性,检测轨迹偏离并触发纠正动作。
挑战:规划引导适配需要预推理未来动作序列,计算成本高,限制实时部署;大量动作候选的评估进一步增加开销,降低动态环境中的响应性。
四、真实世界部署:从仿真到物理的落地路径
真实世界部署的核心是让 RL-VLA 模型在物理机器人上安全自主运行,面临样本效率、安全性和硬件约束三大挑战。论文将部署方案分为仿真 - 真实迁移(Sim-to-Real Transfer)和真实世界 RL(Real-world RL)两大类,形成从虚拟训练到物理落地的完整链路。
4.1 仿真 - 真实迁移:弥合虚拟与物理的鸿沟
仿真 - 真实迁移旨在将仿真中训练的 VLA 策略有效泛化到物理机器人,解决分布偏移问题,主要通过领域随机化和数字孪生两种方案实现:
(1)领域随机化(Domain Randomization)
核心思想是通过随机化仿真参数,覆盖真实世界的感知多样性,减少仿真与真实的差距。具体而言,在策略训练和数据收集阶段,随机化光照条件、背景纹理、执行器噪声等广泛参数。例如 SimpleVLA-RL 通过在多样化任务仿真中应用领域随机化,实现无需额外微调的零样本真实机器人迁移。
(2)数字孪生(Digital Twin)
构建物理系统的同步虚拟副本,实现安全可扩展的策略训练,同时缩小仿真 - 真实差距:
- 动态孪生:Real-IsSim 维持由真实传感器流持续校正的动态数字孪生,确保策略始终在熟悉的仿真域状态中运行;
- 即时仿真:RialTo 从少量真实数据构建即时仿真,通过逆蒸馏 RL 增强操作策略;
- 生成式孪生:RoboTwin 利用 3D 生成模型和 LLM,将单张 2D 图像转换为多样化交互数字孪生,作为双臂操作基准;
- 跨域对齐:DT-CycleGAN 结合数字孪生与 CycleGAN,最小化仿真与真实机器人的视觉和动作一致性差距,实现视觉抓取的零样本迁移;
- 高保真建模:DREAM 采用可微分高斯泼溅技术创建高保真数字孪生,同时识别物体质量和训练力感知抓取策略。
挑战:迁移策略的性能仍低于仿真水平(如 SimpleVLA-RL 在物理机器人上的成功率显著低于仿真),表明单纯仿真不足以支撑可靠的真实世界 VLA 部署。
4.2 真实世界 RL:物理环境中的直接学习
真实世界 RL 直接在物理机器人上训练操作策略,获取更真实的学习信号,但面临推演效率有限和安全风险两大核心挑战。现有方案通过人类在环 RL、可逆性与自主恢复、安全探索三大技术路径应对:
(1)人类干预 RL(Human-in-the-loop RL)
整合人类专业知识加速真实世界 RL,通过人类干预纠正动作、调度学习任务,平衡自主探索与结构化适应性:
-
人类纠正干预(Human Corrective Intervention):利用实时反馈引导机器人学习,加速技能获取并减少不安全探索:
- HIL-SERL:通过人类纠正反馈快速获取精确灵巧的操作技能;
- CR-DAgger:设计柔顺力敏感接口,利用力反馈学习残余策略,增强接触密集型操作;
- TRANSIC:从在线人类纠正中学习,实现仿真 - 真实的自适应策略迁移;
- Genie Centurion:通过 VLM 检测任务失败,跨多机器人扩展纠正干预;
- ConRFT:首次将人类在环干预整合到 VLA 的 RL 中,结合离线和在线人类纠正微调;
- DAFT:将自然语言反馈转化为语义接地的纠正动作;
- VLAC:多机器人在人类监督下探索真实环境,加速策略适配与稳定。
-
人类恢复协助(Human Recovery Assistance):在自主恢复不可靠时,人工重置机器人或环境:
- 半自动化恢复:结合人类在环与脚本化重置或运动原语,在人类监督下实现自主恢复;
- 智能体辅助:ARMADA 和 RaC 整合学习型恢复模块,在自恢复不可行时请求人类引导恢复;
- 干预最小化:Generalist 仅在机器人进入不可逆状态或长时间未完成任务时请求重置;VLAC 针对 VLA 策略的高频失败点进行手动重置。
-
人类课程任务设计(Human Curriculum Task Design):基于课程学习原则,从简单到复杂组织任务:
- 半自动化课程:CurricuLLM 利用 LLM 自动分解复杂机器人技能为分层子任务,对齐人类指定难度;
- 动态部署控制:Sirius 允许人类操作员动态设计和控制真实世界任务的部署课程;
- fleet 级优化:MT-Opt 通过优先处理低性能技能和基于性能指标控制部署阈值,实现课程任务设计的规模化;
- 仿真预研:VLA-RL 将人类课程设计原则整合到 VLA 的 RL 后训练中,但真实世界 VLA 的课程设计仍需探索。
挑战:现有方法严重依赖人类干预样本,导致劳动力成本高、可扩展性差,限制了持续训练和大规模部署。
(2)可逆性与自主恢复(Reversibility and Autonomous Recovery)
让机器人自主处理故障状态,减少人工重置,提升样本效率和长时适应性,分为三类方法:
-
无重置学习(Reset-free Learning):避免外部重置,维持智能体在可恢复状态空间内:
- 重置策略:LNT 训练目标条件重置策略,将智能体恢复到初始状态分布;MEDAL 利用演示统一引导任务和重置策略;
- 课程与多样性:VaPRL 结合课程学习处理复杂任务;LSR 通过判别器驱动方案提升技能多样性;
- 多起点训练:R3L 采用多起点训练策略,增强对探索失败的鲁棒性;
- 多任务整合:MTRF 将无重置 RL 视为多任务学习,使任务终端状态成为其他任务的有效初始状态。
-
功能可逆性(Functional Reversibility):机器人逆转动作,将环境恢复到可继续任务的状态:
- 故障处理:学习应对物体掉落、抓取滑动等常见故障的恢复技能;
- 探索引导:State Entropy Maximization 通过内在正则化鼓励多样化且可逆的探索;
- 主动预防:Recovery RL 学习恢复策略,防止进入不安全或不可逆状态;PAINT 训练分类器预测潜在故障,提前触发纠正动作或安全重置;
- 语义增强:PaLM-E 等语言条件策略从高层指令生成纠正行为。
-
语义感知恢复(Semantic-aware Recovery):推理操作的时空动态,解释故障原因并规划恢复行为:
- 故障本体:Matsuoka 等人构建含时间依赖效用的故障本体,指导滑动或位移时的恢复动作选择;
- 场景建模:DAS 利用语义场景图解释空间和关系故障上下文;
- 神经符号框架:RECOVER 结合本体、逻辑和语言模型,在线检测故障并生成可解释恢复计划;
- 实时推理:Ahmad 等人整合 VLM 和行为树,实现实时推理和自主纠正。
挑战:长视野训练不稳定、部分可观测性和真实世界交互的固有不可逆性,阻碍了复杂环境中可靠的故障检测、因果推理和恢复执行。
(3)安全探索(Safe Exploration)
约束策略搜索在任务相关且可逆的状态空间内,平衡有效学习与灾难性结果避免,分为三类方法:
-
保守安全评论家(Conservative Safety Critics):评估动作提案的风险,训练辅助评论家估计安全约束违反概率:
- 恢复区域:Recovery RL 定义学习恢复区域,确保机器人能从该区域安全返回正常操作;
- 行为先验:SLAC 在低保真仿真中预训练任务无关的潜在动作空间,约束真实世界探索。
-
结构化任务分解(Structured Task Decomposition):将复杂任务分解为简单子任务,便于安全检查:
- GRAPE 利用 VLM 分解复杂操作任务为可解释阶段,通过语义关键点自动推导时空安全约束;
- 约束验证:采用评论家机制概率性验证训练过程中的安全约束满足情况。
-
实时安全执行(Real-time Safety Enforcement):在执行层应用控制理论安全约束:
- 阻抗控制:带参考限制的阻抗控制器实时约束末端执行器的力和速度,防止不安全接触;
- 约束 MDP:SafeVLA 采用集成安全方法(ISA),从最小最大角度优化 VLA 以应对安全风险,平衡安全性与性能。
挑战:高层语义推理与低层安全保证的整合困难 —— 抽象语义规则(如 "小心处理易碎物体")难以转化为具体的物理约束(如特定扭矩或速度限制);分布偏移场景下,智能体遇到新颖状态时,难以同时满足语义目标和物理安全。
五、基准测试与评估:量化进展的标准体系
基准测试与评估是 RL-VLA 领域发展的关键支撑,需结合算法性能、交互保真度和真实世界部署能力。论文将现有评估体系分为仿真基准、真实世界基准和核心评估指标三类,为方法对比和进展量化提供标准框架。
5.1 仿真数据集与基准:规模化训练与验证
仿真基准通过合成场景、物理仿真和标准化任务,支持 RL-VLA 的规模化训练和可重复评估,分为单臂和双臂操作两类:
(1)单臂操作基准(Unimanual Manipulation Benchmarks)
核心优势包括并行环境加速推演收集、Gym 兼容 API 确保可重复性、GPU 加速渲染提供高保真观测,主要基准的关键特性汇总于表 II:
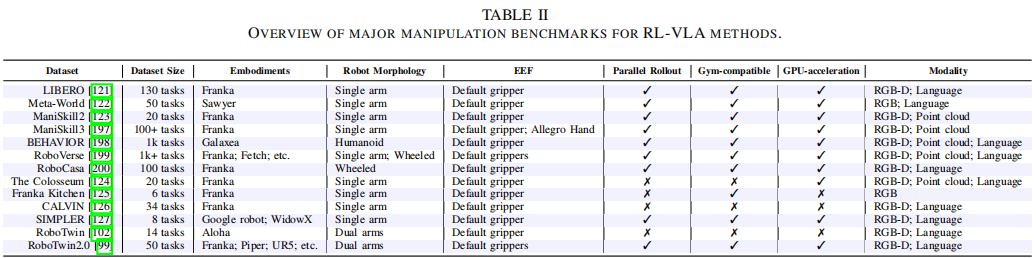
各基准的核心特色:
- LIBERO 和 Meta-World:支持多任务和长视野控制的 RL 训练;
- ManiSkill 系列:接触密集型物理精确仿真,搭配专家演示规模化 RL 数据;
- BEHAVIOR 和 RoboVerse:大规模多样化任务,支持规模化 RL 训练和挑战性测试;
- RoboCasa:聚焦家居场景,提供真实场景以学习鲁棒可迁移策略;
- The Colosseum:基于 RLBench,覆盖外观、光照等多种扰动维度;
- Franka Kitchen:采用 MuJoCo 厨房环境,通过组合原子目标(如打开烤箱、橱柜)研究长视野操作;
- CALVIN:跨场景泛化评估,在 3 个环境训练、1 个环境测试;
- SIMPLER:校准仿真环境以匹配常见机器人配置,无需完整数字孪生即可缩小仿真 - 真实差距,仿真性能与真实机器人成功率高度相关。
各RL-VLA方法在 LIBERO 基准测试中的成功率:
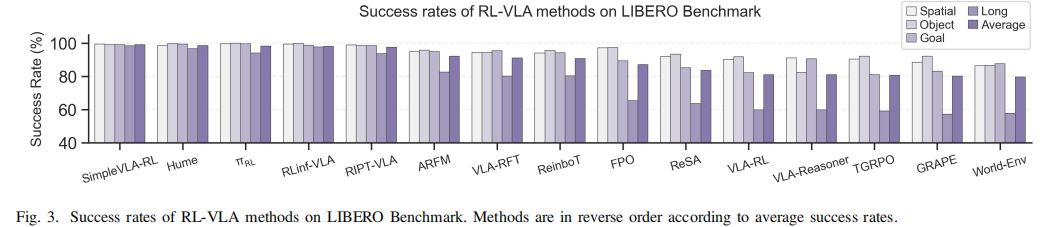
(2)双臂操作基准(Bimanual Manipulation Benchmarks)
- RoboTwin:结合真实遥操作演示与单图像生成的数字孪生场景,提供对齐的仿真 / 真实任务定义和指标;
- RoboTwin2.0:通过自动化专家数据流水线、多实例定制物体集和跨机器人形态的双臂基准,扩展平台规模;结合结构化领域随机化和多模态 LLM 增强 RL 训练鲁棒性。
5.2 真实世界数据集与基准:物理场景的落地验证
真实世界基准聚焦长视野控制、泛化能力和仿真 - 真实保真度,提供可重复的物理环境评估,分为通用 RL 套件和特定领域基准:
(1)通用 RL 套件(General-purpose RL Suite)
- LeRobot:开源通用框架,统一数据集组织、数据采集工具和训练 - 评估流水线,降低硬件实验成本;
- SERL:真实机器人 RL 套件,整合强离线策略视觉学习器与奖励指定、自动重置、安全控制等实用组件,支持 PCB 插入、电缆布线等标准化任务,验证硬件高效训练鲁棒策略的可行性。
(2)特定领域基准(Domain-specific Benchmarks)
- RoboTwin2.0:支持多双臂形态和广泛任务集的标准化机器人评估,提供生成器、多实例物体库和可重复真实世界研究协议;
- FurnitureBench:标准化家具组装任务,提供可重复硬件设置、3D 打印部件和涵盖抓取、插入、拧紧等孤立技能与完整组装的协议;
- RoboCup@Home:动态竞赛类基准,同时跟踪物理技能和高层认知能力的进展;
- FMB:聚焦 3D 打印物体的阶段式技能评估(抓取、夹具辅助重定向、精确插入),提供多视角 RGB-D 和 CAD 资产,评估未见过几何形状和放置位置的泛化能力。
5.3 评估指标(Evaluation Metrics)
需同时捕获传统 RL 目标和 RL-VLA 的多模态、具身特性,核心指标包括:
(1)成功率(Success Rate)
核心指标,衡量智能体完成目标任务的 episode 比例,定义为任务完成或与指令语义一致,适用于仿真和真实世界场景,直观反映策略整体能力。
(2)平均回合回报(Average Episodic Return)
评估每回合的期望累积奖励,反映学习效率和稳定性,是多数 RL 公式(包括视觉 - 语言条件控制)的标准目标。
(3)安全成本(Safety Cost)
由 SafeVLA 引入,量化训练和部署中的风险或约束违反程度,包括不安全动作、碰撞或可能损坏机器人 / 环境的状态转移,是真实世界部署的关键指标。
(4)周期时间(Cycle Time)
由 RLDG 和 CO-RFT 引入,衡量真实世界学习周期的时间效率,包括数据收集、策略更新和部署的完整流程,反映系统级可扩展性。
(5)回合长度(Episode Length)
作为任务鲁棒性的代理指标,反映智能体维持连贯动作序列的能力,平均长度过短通常表明策略不稳定或探索不安全。
(6)干预率(Intervention Rate)
由 ConRFT 引入,衡量人类监督者在真实世界训练或部署中的干预频率,低干预率意味着更高的自主性和更安全的探索。
挑战:现有真实世界 RL 评估过度关注任务级指标(成功率、回合回报),忽视推理延迟、运行时稳定性等系统级指标,而这些指标对具身环境中策略的高效安全运行至关重要。
六、开放挑战与未来方向
尽管 RL-VLA 已取得显著进展,但要实现动态开放物理环境中的稳健运行,仍面临五大核心挑战,对应五大未来研究方向:
6.1 长视野任务扩展(Scaling to Long-horizon Tasks)
挑战:当前 RL 仅监督最终动作,缺乏对中间推理过程的引导,导致长视野任务表现不佳。
方向:引入类思维链(chain-of-thought)监督和记忆检索机制,结合结构化推理与序列建模,帮助智能体召回过往经验并维持长轨迹的时间一致性。
6.2 模型基 RL-VLA(Model-based RL for VLA)
挑战:奖励稀疏延迟和样本效率低,过度依赖大规模仿真推演更新策略。
方向:发展预测性世界模型学习环境动态,生成信息丰富的奖励和合成状态,实现更高效可扩展的训练,减少对真实交互和仿真推演的依赖。
6.3 高效可扩展真实机器人训练(Efficient and Scalable Real-robot Training)
挑战:物理机器人训练的并行化有限,过度依赖人类监督确保安全推演和重置,成本高且效率低。方向:设计自动故障处理推理智能体、安全探索反应智能体,以及多机器人共享训练机制,结合真实 - 仿真推演提升样本效率,减少人类干预。
6.4 可靠可重复 RL-VLA(Reliable and Reproducible RL-VLA)
挑战:多模态 RL 对设计选择、超参数和环境动态高度敏感,导致优化不稳定和可重复性差。
方向:建立一致的训练流水线、受控评估环境和标准化算法设置报告机制,确保跨机器人平台的公平比较和结果可重复。
6.5 安全风险感知 RL-VLA(Safe and Risk-aware RL-VLA)
挑战:感知不完善、控制延迟和探索期间的有限监督,导致真实世界部署存在不可逆风险。
方向:融合预测性风险建模、基于约束的策略优化和语言条件安全推理,确保具身智能体在真实环境中的安全可靠部署。
七、结论:迈向通用机器人操作的范式演进
本文通过构建涵盖架构、训练范式、真实世界部署和基准测试的完整分类体系,系统性梳理了 RL-VLA 领域的研究进展。核心贡献在于:明确了 RL 在弥合预训练与真实部署差距中的关键作用;深入分析了动作、奖励和转移建模的核心权衡;提炼了在线、离线和测试时三类训练范式的算法趋势;揭示了仿真 - 真实迁移和真实世界 RL 的部署挑战;建立了标准化的评估体系。
RL-VLA 的核心价值在于实现了模仿学习到强化学习的范式升级:VLA 提供的多模态表征提升了 RL 的样本效率,RL 则突破了 VLA 的模仿局限,两者协同推动机器人操作向通用化、自主化演进。未来研究需聚焦长视野推理、模型基优化、高效真实训练、可靠可重复和安全感知五大方向,通过融合结构化推理、数据驱动与物理先验、安全约束与任务目标,最终实现真实世界中的自主通用机器人操作。
这一领域的突破不仅将推动机器人技术在工业、家居、医疗等场景的规模化应用,更将加速通用人工智能在具身智能领域的落地进程,构建人与机器人协作共生的智能生态。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 17
17 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)