7篇标志性成果,看透机器人模仿学习8年关键突破
现在还得人类指定任务目标(比如“移动到目标位置”),未来是否能让机器人自己发现任务,比如“看到地面垃圾→自主捡起”。机器人的奖励分两部分:“任务分”(比如跑够速度)和“风格分”(鉴赏家给的评分),不用抄每一步,只要整体像人就行。:给机器人配个“风格鉴赏家”(对抗训练的判别器),专门对比机器人动作和人类动捕数据的“整体感觉”。,但具身智能的终极目标是“自主行动”——从“学人类动”到“为目标而动”,还

机器人运控圈的流行语:跑步绕不开AMP,跳舞绕不开DeepMimic
——模仿学习8年深耕
目录
(2018)DeepMimic:机器人的“逐帧抄作业课”(跳舞/武术)
(2021)AMP:机器人的“风格鉴赏课”(跑步/步态底盘)
(2022)ASE:机器人的“技能预训练+按需调用课”(通用场景)
MimicKit:机器人运动控制的“工程化”(填平落地鸿沟)
五年前,人形机器人的运动控制仍处于机械且不自然的阶段,动作僵硬、稳定性有限;如今,我们已看到其完成流畅的后空翻、转体乃至复杂的街舞动作。
这一跃迁的背后,并非完全依赖层出不穷的新模型,而更多得益于一套持续演进的“模仿学习”范式——它构成了众多先进运动控制系统的共同基础。
而站在这条进化路正中央的,正是以Xue Bin Peng(西蒙弗雷泽大学助理教授&英伟达研究科学家)为代表的研究团队8年来持续输出的关键工作——今天要介绍的“6篇核心论文+1个工具箱”。
这篇文章将和大家一起浅析“机器人模仿学习”的核心脉络——不堆公式,只聊真问题、真思路,还得说说这些技术的“高光”与“软肋”。
毕竟没有完美的算法,只有适配的场景。
从 DeepMimic 的手动奖励工程,到 AMP 的对抗性运动先验,再到 ASE 的可复用技能嵌入、ADD 的多目标自动平衡,直至 PARC、TWIST 的进阶优化,最后 MimicKit 的工程化落地——
这套横跨八年的技术发展,远不止简单的线性迭代,而是针对行业五大核心痛点的系统性破局,每个技术都给机器人“上了一课”。
下面,我们就逐一拆解这七项工作。
01 技术拆解
(2018)DeepMimic:机器人的“逐帧抄作业课”(跳舞/武术)
核心问题:怎么让机器人精准复刻复杂动作?
比如街舞、武术这种差一帧就变“群魔乱舞”的场景。
核心思路:给一段人类动捕数据当“标准答案”,让机器人在仿真里“逐帧抄”,还加了两个“小技巧”:
随机从参考动作里选起点(避免只会跳开头)、跳错就重来(不浪费训练资源)。
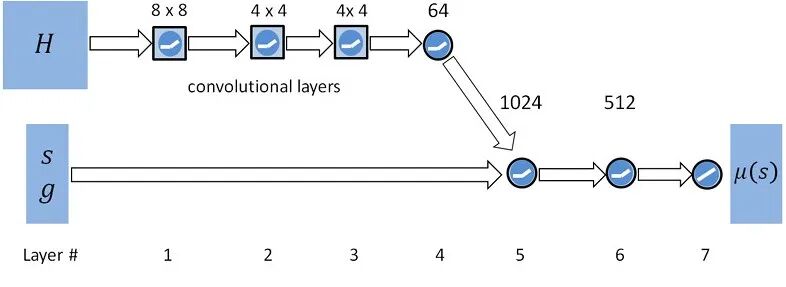
▲图1| 视觉运动策略网络的结构示意图
适用场景:需要精准动作编排的场景(机器人跳舞、武术表演、影视特效角色)。

▲图2| 基于动作捕捉模仿习得的高动态技能 —— 物理模拟角色的动作演示
它的精准度是“双刃剑”——
能把动作复刻到几乎以假乱真,但也绑死了灵活性。
比如跳舞时被碰一下,机器人就容易“卡壳”,不会自己纠偏;而且长动作里的高难片段会“偏科”:简单段落学得超像,难的部分就糊弄过去,像极了学生抄作业只挑简单题做。
(2021)AMP:机器人的“风格鉴赏课”(跑步/步态底盘)
核心问题:不用逐帧复刻,怎么让机器人的动作“整体像人”?
比如跑步,不用和参考帧完全一致,但步态得自然,不能像机械臂甩动。
核心思路:给机器人配个“风格鉴赏家”(对抗训练的判别器),专门对比机器人动作和人类动捕数据的“整体感觉”。
机器人的奖励分两部分:“任务分”(比如跑够速度)和“风格分”(鉴赏家给的评分),不用抄每一步,只要整体像人就行。
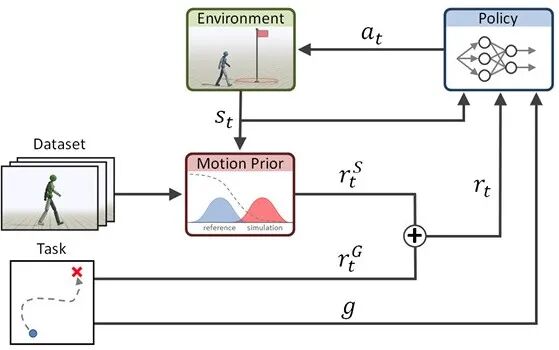
▲图3| AMP 基于动作数据集的运动先验与任务奖励融合的策略训练系统
适用场景:需要自然步态的场景(机器人跑步、日常行走、工业巡检底盘)。

▲图4| 基于非结构化动作数据的框架 —— 物理模拟角色以风格化行为完成挑战任务
它解决了“僵硬”问题,但带来了新麻烦——风格和精准的平衡。
比如让机器人跑着去碰目标,它可能为了保持“人类风格”,宁愿慢一点,也不调整动作去精准触达;
而且“像人”的标准很主观,到底是“运动员跑”还是“普通人跑”,全看数据集,没有统一答案。
(2022)ASE:机器人的“技能预训练+按需调用课”(通用场景)
核心问题:能不能让机器人像人类一样,学会一次技能就能适配多个任务,不用每个任务从头学?
核心思路:先搞个“大规模技能库”——在海量运动数据上预训练走路、跑、跳、挥剑等技能,每个技能对应一个“隐藏代码”(latent向量);
下游任务只需要训练“高层指挥官”,根据任务目标选“隐藏代码”,底层技能直接复用。
此外,还加了“球形技能空间”(避免动作异常)和“自动恢复技能”(摔倒了自己爬起来)。
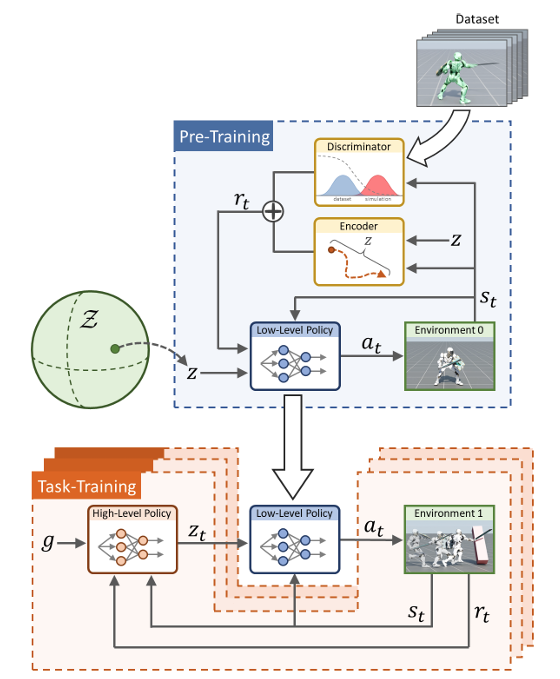
▲图 5| ASE框架
适用场景:需要快速适配新任务的场景(比如机器人既要走路又要操作工具)。

▲图6| 物理模拟角色利用习得技能完成跑向目标并推倒的任务
它虽然可以实现“技能复用”,但也依赖“海量数据投喂”——预训练技能库的多样性全看数据,没见过的动作还是不会;
而且“高层指挥官”和“底层技能”的适配,偶尔还得手动调权重,没完全实现“零干预”。
(2025)ADD:机器人的“自动调参课”
核心问题:几十种运动目标要手动调权重,那么是否能让系统自动平衡?
核心思路:用“对抗性微分判别器”当“自动教练”:
1. “打包“误差:把关节、速度、平衡等误差塞进“微分向量Δ”,理想状态Δ=0;
2. 判别器“抓重点纠错”:只认Δ=0的完美样本,先揪离谱错误(脚飘不沾地),再抠精微误差(身体旋转偏差);
3. 奖励自动化:,Δ越接近0奖励越高,全程不碰权重滑块。
实验里双金刚跳位置误差仅0.03m,远超DeepMimic的0.223m,复杂跑酷动作也能稳住。

▲图7| ADD算法流程
适用场景:精准模仿类任务(工具操作、跑酷、武术复刻)。

▲图8| 无需手动奖励工程的物理模拟角色高敏捷运动技能模仿
(2025)PARC:机器人的“数据生成外挂”
核心问题:跑酷等敏捷数据采集贵、场景少,数据不够学不会新技能?
核心思路:“生成-修正-迭代”闭环造数据:
1. 10分钟核心数据(平地走、简单跳)启动“运动生成器”;
2. 生成复杂地形动作(跳平台+攀爬),再用“物理跟踪器”修正穿模、漂浮等bug;
3. 干净数据回灌训练集,循环迭代,10分钟变100小时,动作成功率从27%涨到68%。
核心公式:生成器损失(还原+不穿模)。
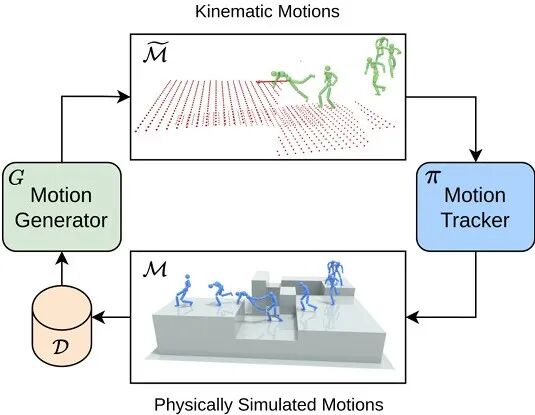
▲图9| PARC 框架
适用场景:数据稀缺的复杂场景(跑酷、山地穿越、工业工况适配)。
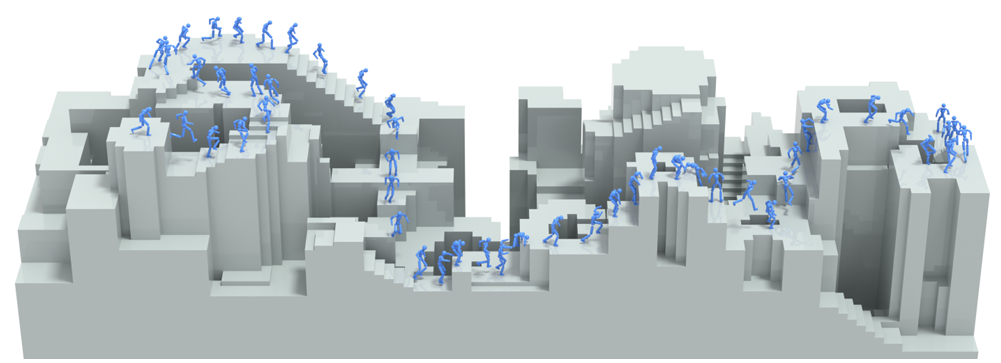
▲图10| 物理模拟角色的复杂地形跑酷技能穿越(迭代扩充框架)
AI能造动作但没创造力,只能拼基础技能,没法搞全新招式;迭代多了数据还会“撞脸”,机器人只会换皮不会创新,只能说“量够质不够”。
(2025)TWIST:机器人的“从模拟到真实通关课”
核心问题:sim-to-real之间的gap(动力学差异、噪声)如何解决?
核心思路:“动捕重定向+RL+BC混合双打”:
1. 把人类动作适配机器人形态,生成专属参考运动;
2. BC保证精准(末端定位误差<0.05m),RL练抗造(抗地面不平、轻微推力);
3. 剧透未来几帧动作,减少实时滞后。
核心公式:混合损失(精准+抗造),真实机器人能搬箱踢门、钻障碍、跳华尔兹。
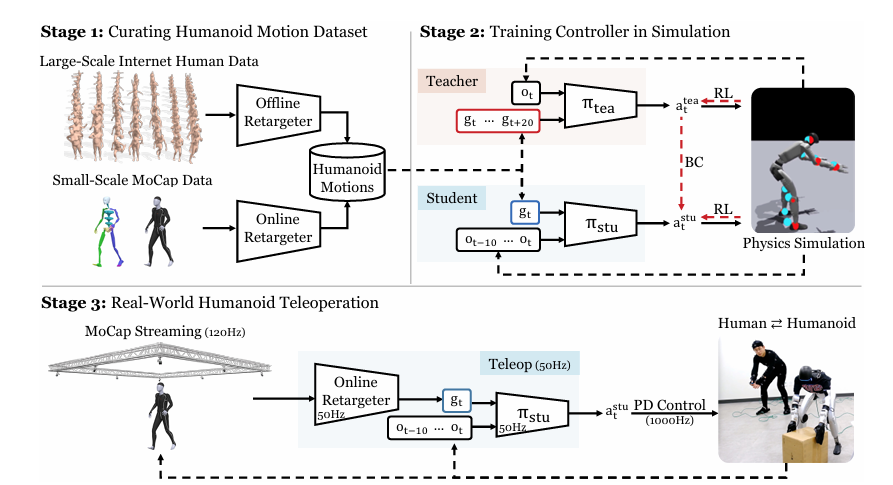
▲图11| TWIST 系统三阶段流程(动作数据集・仿真训练・实机遥操作)
适用场景:真实人形机器人全身体技能(家庭服务、工业辅助、娱乐互动)。

▲图12| TWIST 系统 ——人形机器人实时全身模仿人类动作
打通模拟到真实的门槛不低——反应慢半拍(0.9秒延迟),突然遇障碍必撞;
电机5-10分钟就过热,想长时间干活得给它配风扇,工业落地还得等硬件升级!
相关阅读:斯坦福吴佳俊团队最新成果:全身协同控制新范式 TWIST,教机器人像人一样动起来!
MimicKit:机器人运动控制的“工程化”(填平落地鸿沟)
核心解决:论文算法思路易懂、落地复现调参痛点。
它并非新算法,而是一站式工程工具箱——
将DeepMimic、AMP、ADD等核心方法打包成统一代码库,标准化仿真环境、数据接口与训练流程,无需从零搭建框架、重复调试底层代码。
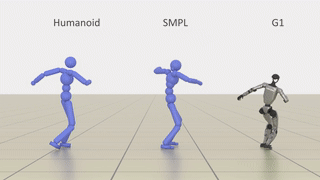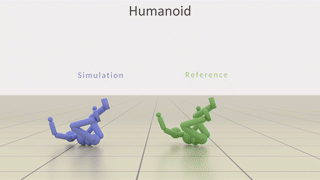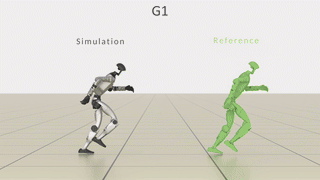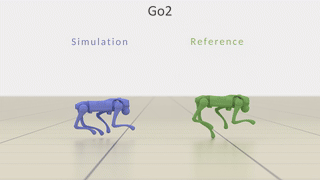
模块化调用就能快速跑通实验,填平论文思路到稳定落地的工程鸿沟。
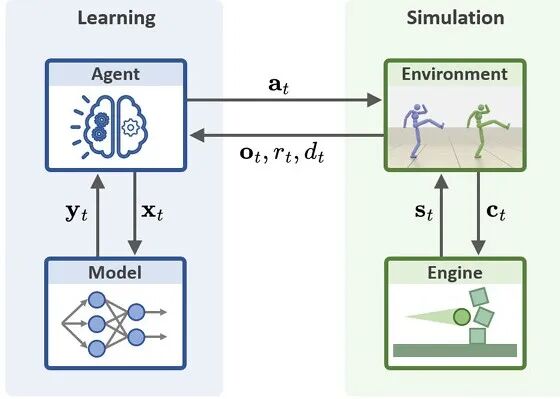
▲图13| MimicKit 框架结构概览 —— 学习与仿真模块的核心组件
02 核心进化路
梳理下来,这几项研究形成了一条清晰的机器人运动控制“升级路线”:
-
目标设计:手动调参→对抗性奖励→自动平衡多目标(ADD);
-
技能复用:单任务训练→大数据集组合→预训练+迁移(ASE);
-
数据利用:依赖真实数据→生成+物理修正(PARC);
-
场景适配:模拟验证→真实机器人落地(TWIST);
-
工程落地:论文难复现→工具箱一键调用(MimicKit)。

这套逻辑的核心就是“让机器人像人类一样高效行动”——
不用人类事事干预,能自己复用技能、自己修正数据、自己适应环境,还能让开发者轻松落地,这也是它能成为行业模板的原因。
03 未来展望
现在的技术已经能让机器人“跳得好、跑得稳、落地易”,但要达到人类的灵活度,还有两道坎:
小样本迁移:现在还需要一定规模的初始数据,未来能不能看1-2个参考动作,就学会同类技能,比如看一次跨越1m gap,就能自主跨越0.8-1.2m。
自主决策:现在还得人类指定任务目标(比如“移动到目标位置”),未来是否能让机器人自己发现任务,比如“看到地面垃圾→自主捡起”。
该系列研究搭好了“运动控制+工程落地”的双重地基,但具身智能的终极目标是“自主行动”——从“学人类动”到“为目标而动”,还有很长的路要走。
Ref
1. DeepMimic:https://arxiv.org/pdf/1804.02717
2. AMP:https://arxiv.org/pdf/2104.02180
3. ASE:https://arxiv.org/pdf/2205.01906
4. ADD:https://arxiv.org/pdf/2505.04961?
5. PARC:https://arxiv.org/pdf/2505.04002
6. TWIST:https://arxiv.org/pdf/2505.02833
7. MimicKit:https://arxiv.org/pdf/2510.13794
8. Xue Bin Peng主页:https://xbpeng.github.io/

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 12
12 0
0- 0



 已为社区贡献83条内容
已为社区贡献83条内容

所有评论(0)