英伟达140亿参数的DreamZero一出,VLA玩家集体沉默?

让机器人看一眼视频就学会新技能
——VLA一夜过时?
目录
上图来自于英伟达近期重磅发布的世界动作模型(WAM)DreamZero相关演示画面。
长期以来,VLA模型作为具身智能的主流路径,虽能实现语义层面的指令跟随,却因“看-说-做”的三段式链路,陷入依赖昂贵标注数据、物理世界泛化性弱、无法应对未知任务的困境。
英伟达DreamZero的突破,在于跳出VLA框架:
它以视频扩散模型为骨干,通过联合预测未来视频帧与机器人动作,跳过语言中间层桎梏,实现视觉与动作的直接映射,从视频中自主学习物理动力学规律。
这一搭载了140亿参数的机器人基础模型,究竟藏着哪些核心技术亮点?又将如何重塑具身智能的发展路径?
01 当"语言模型思维"遇上物理世界的墙
当前机器人领域最火热的方向之一,是将大型视觉-语言模型(VLM)的能力迁移到机器人控制上,形成所谓的VLA。
这类模型继承了语言模型强大的语义理解能力,能够根据自然语言指令,识别出目标物体并规划抓取。
但问题在于,VLA的"知识"来源于静态的图文数据,它们编码的是"做什么"(what),却缺乏对"怎么做"(how)的精确空间感知——
几何对齐、动力学、运动控制,这些物理世界的核心要素,在图文预训练中几乎无法习得。
这导致了一个尴尬的现实:要让VLA实现泛化,唯一的办法似乎就是不断收集更多、更大规模的特定任务重复演示数据。
这显然不是一条可持续的路。
DreamZero的核心思路在于:与其从静态图文中学习动作,不如从动态视频中学习世界的物理规律。
DreamZero基于预训练的140亿参数图生视频扩散模型(Wan2.1-I2V-14B-480P),它不是简单地用视频模型来"看",而是让模型同时"想象"未来的画面和"推算"对应的动作,将动作学习从传统的模仿学习转变为一种逆动力学推理
——先预测世界会怎么变,再反推出让世界这样变的动作是什么。

▲图1 | DreamZero总览。
02 技术亮点
联合视频-动作预测
传统方法要么只预测动作(VLA),要么将视频生成和动作提取拆成两个独立模块。
DreamZero则不同,它用一个共享的去噪目标,让视频和动作在同一个扩散过程中被联合生成。
举个例子:模型在执行"把水果装进袋子"这个任务时,它不仅要输出机械臂的关节角度序列,还要同时"想象"出未来几帧画面中水果被抓起、放入袋子的视觉过程。
这两个输出是紧密耦合的——生成的视频充当了一个隐式的视觉规划器,引导动作生成与物理现实保持一致。
在实验中也证实了这一点:DreamZero的失败案例主要源于视频生成的错误,而非动作预测的错误。
这意味着,提升视频骨干的质量就能直接提升机器人的执行能力。
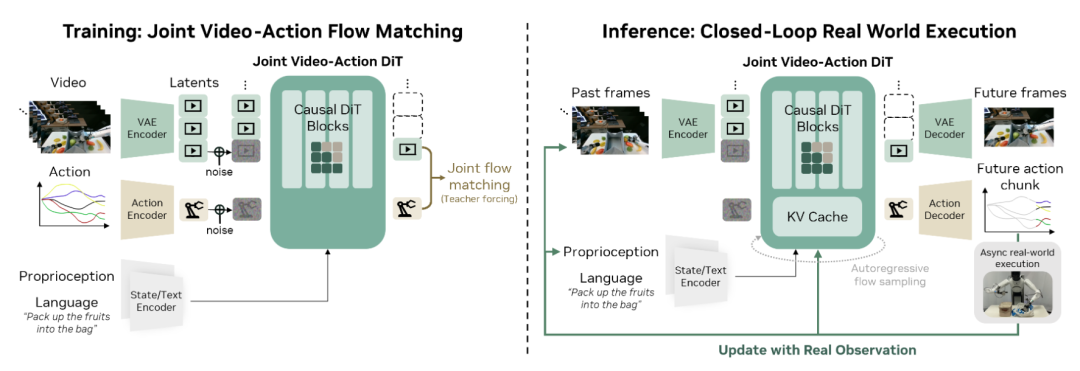
▲图2 | DreamZero模型架构。模型接收三路输入:当前看到的画面(通过VAE编码)、语言指令(通过文本编码器)以及机器人自身的关节状态(通过状态编码器)。这些信息被送入一个基于flow matching的自回归DiT骨干网络,同时预测未来的视频帧和对应的动作。训练阶段(左),模型学习从带噪声的视频和动作中还原出真实信号;推理阶段(右),模型的预测被异步发送给真实机器人执行,同时将机器人实际观测到的画面回传到模型中,确保"想象"始终被现实校准,不会越跑越偏
自回归架构
在架构选择上,DreamZero采用了自回归(Autoregressive)而非双向(Bidirectional)的生成方式。
模型以"chunk"为单位进行预测——每个chunk包含固定数量的未来视频帧和对应的动作序列。
这一设计带来了三个关键优势。
-
首先是闭环纠错:
每当一个动作chunk执行完毕,模型会用真实世界的观测替换KV缓存中之前预测的帧,然后基于最新的真实状态继续预测下一个chunk。
这种机制优雅地消除了纯视频生成中常见的误差累积问题——"想象"可能会偏,但每隔一小段就会被现实"拉回来"。
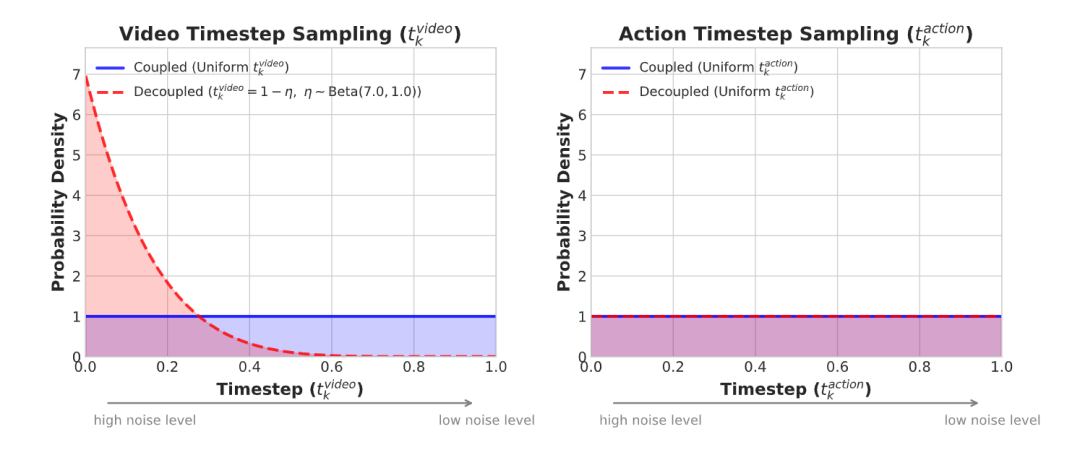
▲图3 | 解耦噪声调度策略。标准版DreamZero(蓝色)在训练时对视频和动作施加相同程度的噪声。而加速版DreamZero-Flash(红色)则"偏心"地给视频加更多噪声,同时保持动作的噪声不变。这样做的好处是:模型在训练时就习惯了从模糊的画面中推断出精确的动作,从而在推理时即使只用极少的去噪步数,也能输出高质量的控制指令
-
其次是模态对齐:
双向扩散模型通常需要处理固定长度的序列,这往往需要对视频进行下采样,可能破坏视频帧率与动作频率之间的原生对齐关系。
自回归架构则通过KV缓存天然支持任意长度的上下文,保留了原生帧率,确保视频和动作之间的精确时序对齐。
-
最后是推理效率
自回归架构天然支持KV缓存,推理速度比双向架构快3到4倍。
38倍加速:实时控制
一个140亿参数的视频扩散模型,每生成一个动作chunk需要约5.7秒——这对于需要毫秒级响应的机器人控制来说完全不可接受。
DreamZero通过三个层面的优化,实现了累计38倍的推理加速,将延迟压缩到约150毫秒,达到了7Hz的实时闭环控制频率。
最精妙的是模型层面的优化——DreamZero-Flash。

核心创新在于:当推理时只用极少的去噪步数(如1步),视频latent仍然带有大量噪声,但动作需要是干净的。标准训练中视频和动作共享相同的噪声时间步,这在少步推理时会产生训练-测试不匹配。
DreamZero-Flash通过解耦视频和动作的噪声调度来解决这一问题——训练时将视频的噪声时间步偏向高噪声状态(Beta分布),而动作的噪声时间步保持均匀分布。
这样模型在训练阶段就学会了从噪声视觉上下文中预测干净动作,完美匹配少步推理的场景。

▲图4 | DreamZero-Flash 评估。 在桌面清理任务中,不同去噪步数下的任务完成进度(± 标准误差)。可以看到,DreamZero-Flash 仅用 1 步去噪就恢复了 4 步去噪的绝大部分性能,推理效率提升显著
03 实验与表现
DreamZero在两个机器人平台上进行了全面评估:
AgiBot G1(双臂移动操作机器人)和Franka(单臂机器人)。
对比基线为当前最强的两个VLA模型——GR00T N1.6和π0.5。值得注意的是,所有评估默认在未见过的环境和未见过的物体上进行。
-
已见任务的零样本评估中
在AgiBot G1上,DreamZero的平均任务进度达到62.2%,而从头训练的VLA几乎为零(GR00T N1.6仅2.1%);
在DROID-Franka上,DreamZero同样以75%的平均任务进度领先。
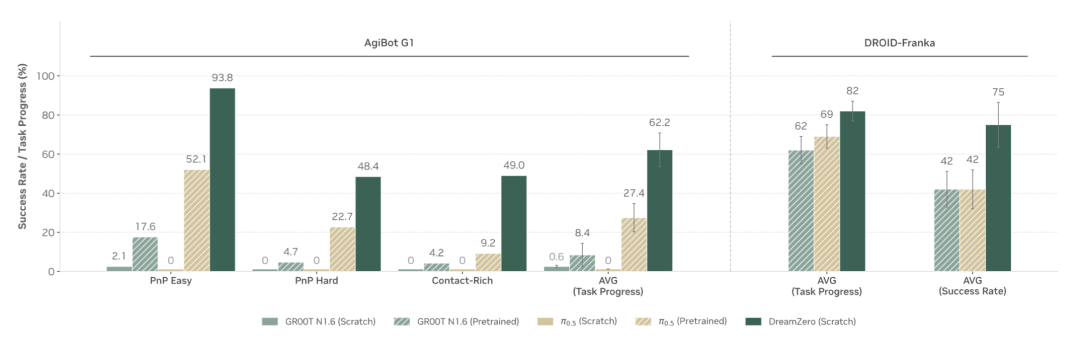
▲图5 | 已见任务评估。DreamZero从多样数据中有效学习并泛化到新环境,在所有任务类别上均优于VLA。从头训练的VLA几乎完全失败,而预训练VLA仅展示出有限的性能——这可能得益于其在预训练阶段通过重复演示获得的具身特定知识。
-
未见任务的泛化能力
在10个训练中完全不存在的任务上(如解鞋带、熨衣服、用画笔绘画、与人握手等):
DreamZero在AgiBot G1上仍达到了39.5%的平均任务进度,而从头训练的VLA不到1%,预训练VLA最好也仅16.3%;
在DROID-Franka上,DreamZero以49%的任务进度和22.5%的成功率同样大幅领先。
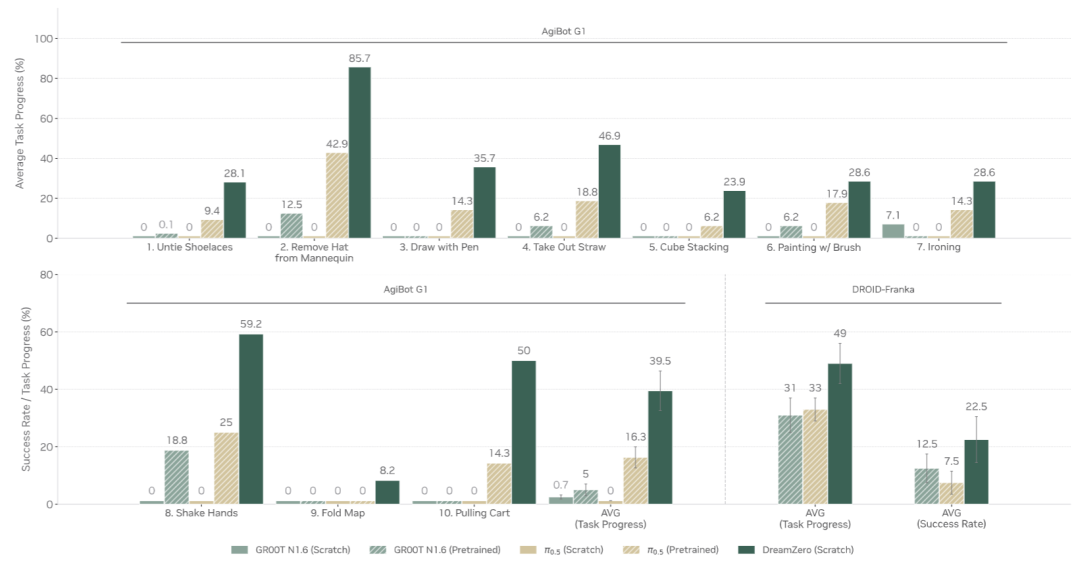
▲图6 | 未见任务的零样本泛化。DreamZero在10个训练中不存在的任务上取得了可观的任务进度,而VLA在两个机器人平台上均表现挣扎。
-
在跨具身迁移实验中
研究团队展示了WAM的另一个独特优势:
仅需10到20分钟的纯视频数据(来自另一个机器人YAM或人类第一人称视角,不包含任何动作标注),就能将未见任务的性能从38.3%提升到55.4%,相对提升超过42%。
-
更值得一提的是少样本具身适配实验:
将在AgiBot G1上预训练的DreamZero,仅用30分钟的数据(55条轨迹,11个任务)就成功适配到了一个全新的双臂机器人YAM上,并且保持了强大的语言跟随和零样本泛化能力。
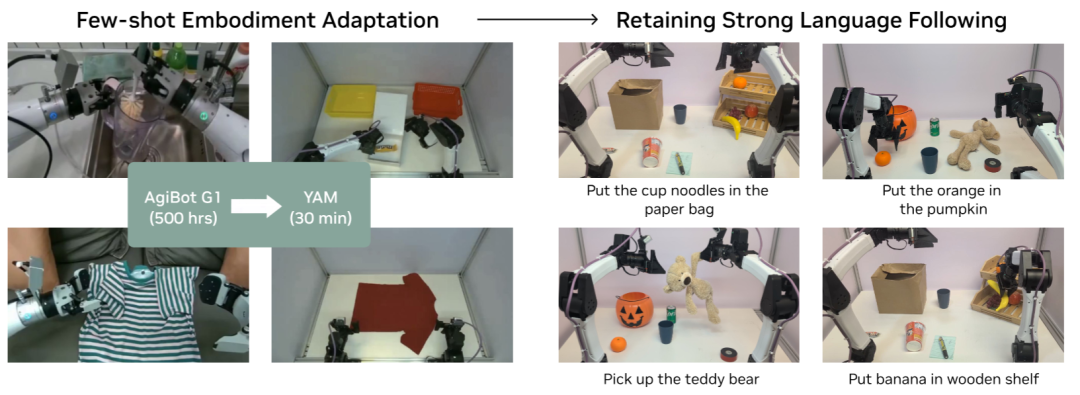
▲图7 | 少样本具身适配。通过在仅30分钟的新具身"玩耍"数据上进行后训练,DreamZero成功适配到全新的YAM机器人,并在需要强语言跟随能力的抓放任务变体上进行评估。
04 总结与延伸
DreamZero代表了从"直接学动作"转向"先理解世界,再推导动作"这一探索。
其核心价值在于,将机器人策略的能力上限与视频生成模型的能力上限绑定在了一起——而后者正在以惊人的速度进步。
当视频模型能够更准确地预测物理世界的未来时,机器人的执行能力也将水涨船高。
这项工作也揭示了一个深刻的启示:也许机器人学习的瓶颈不在于缺少动作数据,而在于缺少对世界运作方式的理解。
互联网上有海量的视频数据记录着物理世界的运行规律,而DreamZero展示了一条将这些"世界知识"转化为机器人能力的可行路径……
Ref
论文标题:World Action Models are Zero-shot Policies
论文链接:https://dreamzero0.github.io/DreamZero.pdf
项目主页:https://dreamzero0.github.io

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 14
14 0
0- 0



 已为社区贡献93条内容
已为社区贡献93条内容

所有评论(0)