PolySim:通过多模拟器动力学随机化跨越仿真到真实的鸿沟
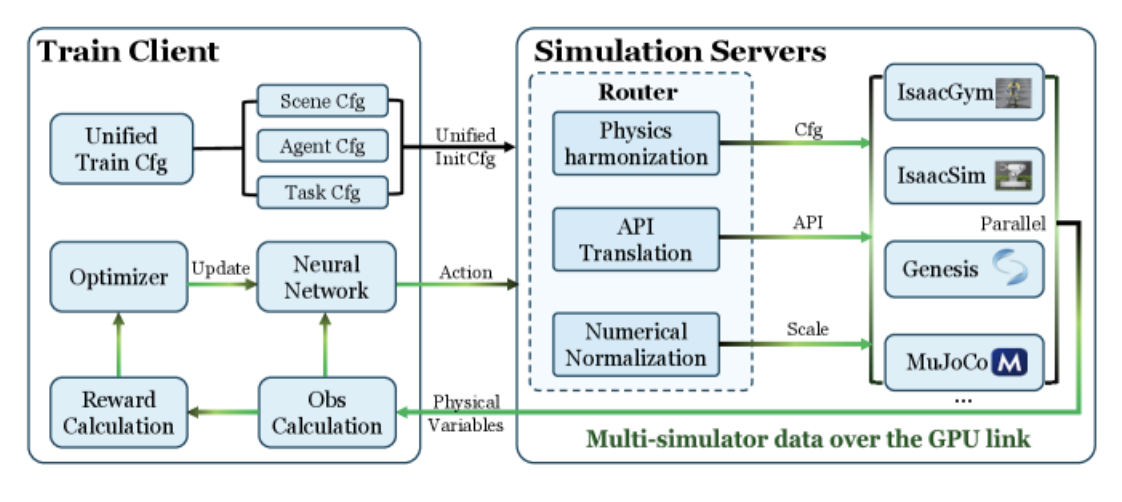
多物理引擎协同训练的人形机器人控制方法 本文提出了一种创新的PolySim框架,通过在多物理引擎上并行训练来解决人形机器人控制中的"仿真到真实"迁移问题。传统方法依赖于单一模拟器训练控制策略,而PolySim同时在IsaacGym、IsaacSim、Genesis和MuJoCo等异构物理引擎上进行训练,能够捕获超越任何单一模拟器假设的通用动力学规律。 系统采用客户端-服务器架构
0. 引言
人形机器人全身控制是当前机器人学领域最具挑战性的研究方向之一。传统的强化学习方法依赖于在单一物理引擎中训练控制策略,然而这些策略在迁移到真实机器人时往往表现不佳。这种现象被称为"仿真到真实"的鸿沟,其根源在于每个物理模拟器都存在固有的归纳偏差。这些偏差源自模拟器在刚体动力学、接触建模、时间积分和执行器建模等方面的特定假设和简化。
PolySim项目提出了一个革命性的解决方案:不再依赖单一模拟器,而是同时在多个异构物理引擎上进行并行训练。这种方法从根本上改变了传统的领域随机化范式,将随机化从参数层面提升到了动力学层面。通过让策略在IsaacGym、IsaacSim、Genesis和MuJoCo等不同物理引擎的混合环境中学习,PolySim能够捕获超越任何单一模拟器假设的通用动力学规律。
1. 问题分析:仿真器归纳偏差的本质
每个物理模拟器在设计时都会做出特定的工程权衡。IsaacGym针对GPU并行优化了接触求解器,Genesis强调可微分物理,MuJoCo专注于高保真度的关节动力学,而IsaacSim则追求逼真的渲染和传感器模拟。这些不同的设计理念导致了各自独特的动力学特性。
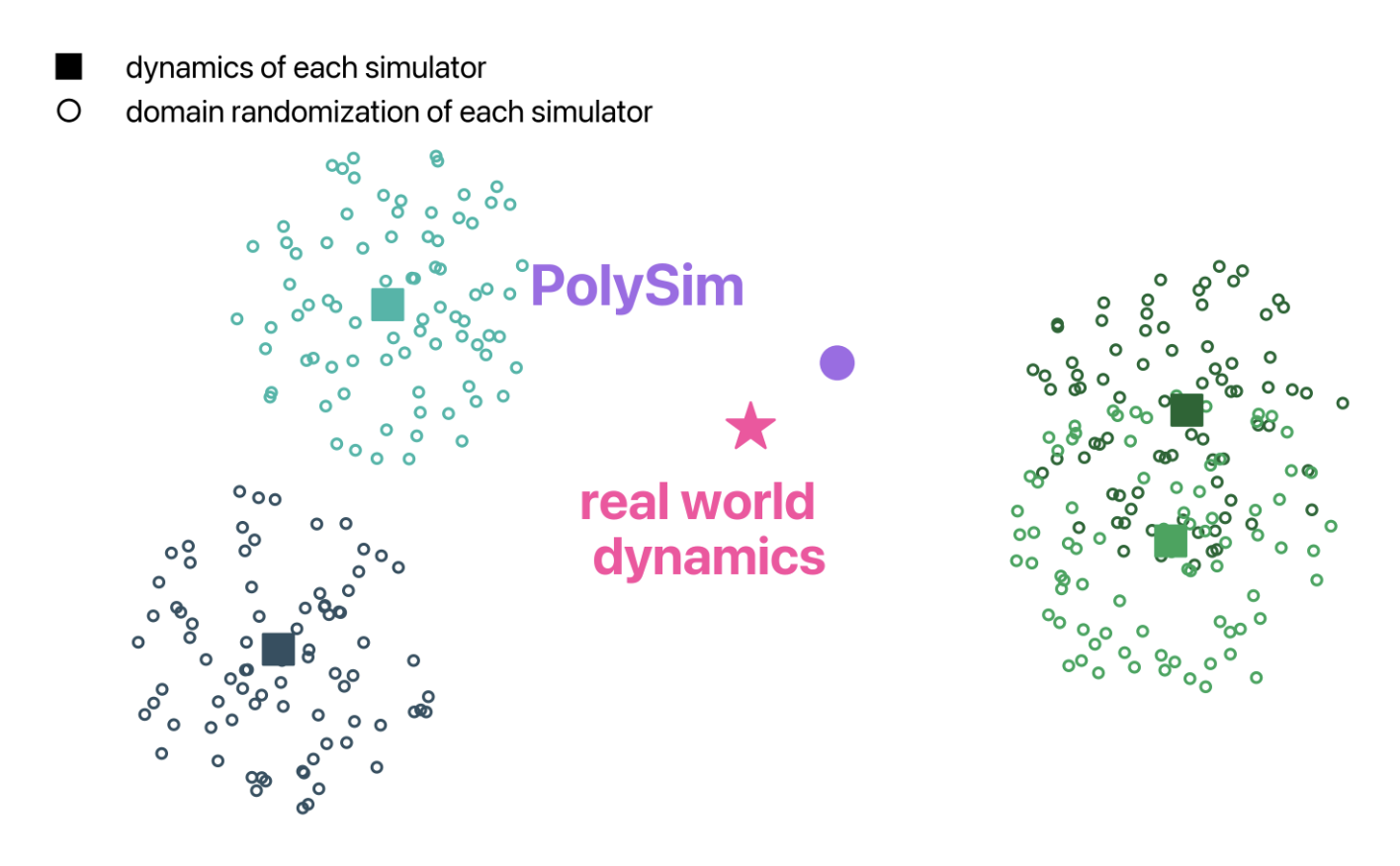
在动力学空间中,真实世界的物理规律可以被视为一个特定的点。每个模拟器由于其内在的建模假设,实际上占据了该空间中的不同位置。传统的参数级域随机化虽然能在单一模拟器周围产生变化,但这些变化仍然受限于该模拟器的转移模型。相比之下,PolySim通过多模拟器混合训练,能够探索这些不同模拟器张成的凸包空间,从而更接近真实世界的动力学分布。
理论分析表明,PolySim的仿真到真实误差上界显著低于单一模拟器训练。具体而言,如果用1-Wasserstein距离度量转移核之间的差异,PolySim的误差上界可以表示为混合转移核与真实转移核之间的距离,而这一距离严格小于任何单一模拟器的对应距离。这一理论保证为PolySim的实践成功提供了坚实的数学基础。
2. 系统架构设计
PolySim的架构设计遵循三个核心原则:训练与仿真解耦、统一的模拟器接口、高效的GPU直连通信。这种设计不仅保证了系统的可扩展性和容错性,还最大化了并行训练的效率。
2.1 训练仿真分离架构
传统的强化学习训练框架采用单体式设计,将环境实例化和策略更新集中在一个进程中。这种设计虽然简单,但存在严重的资源竞争问题。GPU需要同时处理物理仿真的前向计算和策略网络的反向传播,导致利用率下降。更重要的是,这种紧耦合使得集成多个异构模拟器变得极为困难。
PolySim采用了客户端-服务器架构来解决这一问题。系统包含一个TrainClient和多个SimServer。每个SimServer独立运行一个物理引擎实例,负责推进仿真步长并返回观测、奖励和终止标志。TrainClient则专注于强化学习逻辑,包括优势函数计算、策略网络更新和梯度下降。
这种分离带来了多重好处。首先是故障隔离:某个模拟器的崩溃不会影响整个训练流程,其他模拟器可以继续工作。其次是资源优化:仿真和训练可以被调度到不同的GPU上,避免计算资源的争抢。最后是工具链独立:训练端可以使用最新的深度学习框架,而不受模拟器依赖库的限制。
下面的代码展示了训练客户端的初始化过程:
def create_env_client(master_port, simulator_lists, rank, world_size, num_envs_list, device_list):
"""
配置并初始化RPC客户端(EnvClient)
Args:
master_port: RPC主进程端口
simulator_lists: 模拟器名称列表,如['isaacgym', 'isaacsim']
rank: 当前客户端进程的等级
world_size: 总进程数(服务器数 + 1个客户端)
num_envs_list: 每个模拟器的环境数量列表
device_list: 所有进程的CUDA设备列表
"""
# 加载客户端基础配置
config = OmegaConf.load("humanoidverse/config/base_client.yaml")
# 根据运行时参数动态更新配置
config.num_envs = sum(num_envs_list)
config.num_envs_list = num_envs_list
config.rpc.server_names = simulator_lists
config.rpc.master_port = master_port
config.rpc.rank = rank
config.rpc.world_size = world_size
config.rpc.device = device_list[rank]
config.rpc.client_gpu = int(device_list[rank])
config.rpc.server_gpu_list = [int(device_list[i]) for i in range(len(simulator_lists))]
# 设置PyTorch分布式和RPC所需的环境变量
os.environ["MASTER_ADDR"] = "127.0.0.1"
os.environ["MASTER_PORT"] = str(master_port)
os.environ.setdefault("GLOO_SOCKET_IFNAME", "lo") # 使用本地回环接口
os.environ.setdefault("TP_SOCKET_IFNAME", "lo")
# 配置TensorPipe后端的RPC选项
opts = TensorPipeRpcBackendOptions(num_worker_threads=64, rpc_timeout=6000)
# 定义客户端和每个服务器之间的GPU设备映射
# 这是实现GPU到GPU直接数据传输的关键
for i, simulator_name in enumerate(simulator_lists):
client_gpu = int(device_list[rank])
server_gpu = int(device_list[i])
opts.set_device_map(simulator_name, {client_gpu: server_gpu})
logger.info(f"RPC device map: client:{client_gpu} -> server '{simulator_name}':{server_gpu}")
# 初始化当前客户端进程的RPC框架
logger.info("[Client] Initializing RPC...")
rpc.init_rpc(name="ppo_trainer", rank=rank, world_size=world_size, rpc_backend_options=opts)
logger.info("[Client] RPC initialized successfully.")
# 创建并返回EnvClient实例
logger.info(f"[Client] Creating EnvClient on device {device_list[rank]}...")
env_client = EnvClient(config, device=device_list[rank])
logger.info("[Client] EnvClient created successfully.")
return env_client
…详情请参照古月居

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 17
17 0
0- 0



 已为社区贡献69条内容
已为社区贡献69条内容

所有评论(0)