(2026|NVIDIA,DreamZero,泛化,IDM动作/自回归视频联合预测,解耦推理/动作执行,解耦视频/动作噪声调度,DiT,流匹配)世界动作模型是零样本策略
本文提出 DREAMZERO,一个建立在预训练视频扩散骨干上的世界动作模型。与 VLA 不同,它通过预测未来世界状态和动作来学习物理动态,使用视频作为世界如何演变的密集表征。通过联合建模视频和动作,它能够有效地从异构机器人数据中学习多样化技能,而不依赖重复演示
World Action Models are Zero-shot Policies

论文地址:https://arxiv.org/abs/2602.15922
项目页面:https://dreamzero0.github.io/
进 Q 学术交流群:922230617 或加 CV_EDPJ 进 W 交流群
目录
1. 引言
最先进的 视觉-语言-动作(Vision-Language-Action,VLA)模型擅长语义泛化,但难以泛化到新环境中未见过的物理运动。
本文提出 DREAMZERO,一个建立在 预训练图像到视频扩散(image-to-video diffusion)骨干 上的 14B 参数机器人基础模型。本文将这种架构称为世界动作模型(World Action Model,WAM)——一种旨在 以对齐方式同时预测动作和视觉未来状态的基础模型。

从在网络规模视频数据上训练的视频扩散模型初始化,WAM 利用丰富的时空先验,根据语言指令和观察,联合生成未来帧和动作。这将动作学习从密集的状态-动作模仿(state–action imitation)转变为逆动力学(inverse dynamics)——将电机指令与预测的视觉未来对齐。因此,观察到这使得能够:
- 从异构轨迹(在实际环境中执行有用行为时收集,而非仅依赖精心重复的演示)中有效学习;
- 零样本泛化到新环境中的新任务;
- 高效的跨具身迁移。
这种方法产生了三项核心进展,使 DREAMZERO 区别于先前的工作。
1)DREAMZERO 解锁了超越传统 VLA 和先前 WAM 的新泛化能力——跨环境、跨任务和跨具身(cross-embodiment)。与最先进的预训练 VLA 相比,本文在环境和任务泛化基准上的平均任务进度观察到了超过 2 倍的提升。
2)DREAMZERO 证明了 可以从多样、异构的数据中有效学习通用策略,打破了通用机器人策略需要每个任务多次重复演示的传统观念。尽管其他 WAM 表明,与 VLA 相比,从视频预测中学习的先验提高了动作学习的样本效率,但大多数工作仍然侧重于重复演示。此外,即使在特定任务的后训练之后,DREAMZERO 的环境泛化能力仍然保持,平均任务进度上比最先进的 VLA 高出10%。
3)本文展示了两种形式的 跨具身(cross-embodiment)迁移。
- 首先,来自另一个机器人(YAM)或人类的纯视频演示,仅用 10-20 分钟的数据,就能为目标机器人(AgiBot G1)的未见任务性能带来超过 42% 的相对提升。
- 其次,本文展示了 DREAMZERO 实现了少样本具身适应:在 AgiBot G1 上预训练的模型,仅用 30 分钟的自由玩耍数据就能适应一个全新的机器人(YAM),同时保留零样本泛化能力。据本文所知,这为数据高效的具身适应设立了新基准。
DREAMZERO 是一个 14B 参数的自回归扩散变换器(diffusion transformer,DiT),使用教师强制的逐块视频去噪目标进行训练。
- 架构分析揭示,更大规模的预训练视频扩散模型 能产生更高质量的视频预测,这直接转化为更优的下游动作执行——表明策略性能根本上与视频生成质量相关。
- 本文进一步发现,训练数据的多样化分布 对泛化至关重要,在相同小时数下,其性能优于多任务重复数据。
- 此外,本文观察到 自回归架构 能带来更平滑的机器人动作和预测视频与执行动作之间更高的模态对齐度。
为了解决视频扩散模型固有的计算开销,本文引入了一系列涵盖三个类别的优化:
- 算法改进,包括解耦视频和动作去噪调度(DREAMZERO-Flash);
- 系统级并行和缓存策略;
- 低级优化,如量化、CUDA 内核调优。
这些技术实现了 38 倍的推理加速,且性能无损,使 DREAMZERO 能够以约 7Hz 的频率生成动作块,实现平滑的实时机器人控制。
3. DreamZero
预训练的视频扩散模型提供了来自网络规模数据的丰富时空先验,使其成为机器人策略有吸引力的骨干。
然而,将这些模型转化为有效的世界动作模型(WAM)面临三个关键挑战:
- 视频-动作对齐:联合预测视频和动作需要视觉未来和电机指令之间的紧密耦合,然而简单地组合分离的视频和动作头可能导致不对齐;
- 架构设计:尚不清楚双向或自回归架构哪个更适合WAM,这对模态对齐、误差累积和推理效率有影响;
- 实时推理:视频扩散模型需要在高维潜空间上进行迭代去噪,使其对于闭环控制来说慢得难以承受。
DreamZero 通过三个设计选择来应对这些挑战。
- 首先,本文训练一个 单一的端到端模型,使用共享目标联合对视频和动作进行去噪,确保模态间的深度融合。
- 其次,本文采用 自回归架构 并利用闭环设置的优势:在每个动作块执行后,本文用 KV 缓存中的真实观测值替换预测帧,消除了复合误差,同时通过 KV 缓存实现高效推理,并通过保持原生帧率实现精确的模态对齐。
- 第三,本文引入了一套 系统、实现和模型级别的优化,实现了 38 倍的推理加速,使得以 7Hz 进行实时控制成为可能。
3.1. 模型架构
DreamZero 联合预测视频 o_{l:l+H} 和动作 a_{l:l+H},条件为语言指令 c、具身感受状态 q_l 以及包含当前和历史信息的视觉观测 o_{0:l},其中 H>0 是固定视界,l 是从轨迹中随机采样的索引。
注意,视频和动作的联合预测是 自回归视频预测 和 逆动力学模型(IDM)动作预测 的分解:
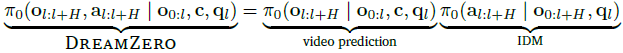
本文没有使用两个分离的模型(视频预测模型和逆动力学模型)来建模分解后的目标,而是训练单个端到端模型,使用联合预测目标。
由于预训练的视频模型已经在多样化的网络规模视频数据上针对视频预测目标进行了优化,DREAMZERO 只需额外学习预测机器人具身的视频,并从生成的视频中提取相应的动作。本文进一步假设,这比从 VLM 训练 VLA 的传统做法更能鼓励泛化,因为本文的方法明确地从用作条件输入和预测目标的视频帧中学习时间动态。
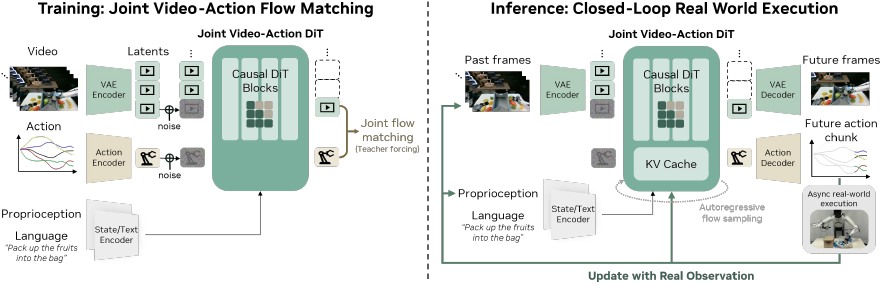
模型架构 如上图所示。
- 为了保留视频模型的泛化能力,本文引入了最少的额外参数:状态编码器、动作编码器和解码器。
- 对于包含多视角的机器人训练数据,本文将所有视角连接成单个帧,而不是对骨干模型进行架构更改。
特别地,DREAMZERO 被训练来自回归地预测视频帧和相应的动作。自回归生成具有以下优势:
- 通过利用 KV 缓存实现更快的推理速度;
- 策略模型可以利用视觉观察历史作为下一轮生成的指导;
- 避免了双向模型固有的模态对齐挑战(视频、动作和语言对齐)。具体来说,双向扩散通常需要处理固定长度的序列,这往往需要对视频进行子采样,从而扭曲原生 FPS,可能损害视频-动作对齐。另一方面,自回归生成利用 KV 缓存来支持单次前向传递中的任意长上下文。这保留了原生帧率,确保视频帧与机器人动作之间的精确对齐。
本文仅对视频模态引入自回归建模,以避免来自闭环动作预测的误差传播。
- DREAMZERO 被训练以逐块方式预测视频帧;每个块有固定数量的潜帧(latent frames) K 以匹配动作视界。
- 逐块生成使得能够对可变长度的视频进行训练,类似于 LLM 在可变长度的语言 token 上进行训练的方式。
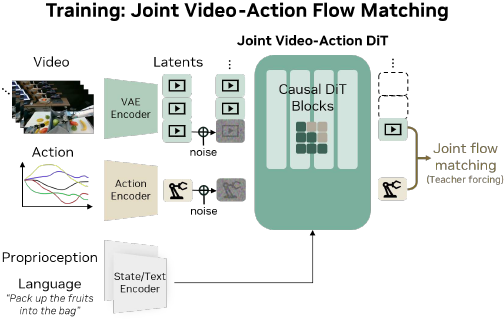
训练目标。
- 类似于最近的视频扩散模型和 VLA,本文采用 流匹配 作为训练目标。
- 与最近的 WAM不同,DREAMZERO 在视频和动作模态之间 共享去噪时间步,以便在训练初期更快收敛。
- 此外,本文应用 教师强制(teacher forcing)作为训练目标;模型被训练以干净的前一块为条件,对带噪声的当前块进行去噪。
形式上,给定块索引 k > 0 和去噪时间步 t_k ∈ [0,1],本文将原始视频 o^k 对应的带噪声视频潜变量表示为 z^k_{t_k},将归一化动作表示为 a^k_{t_k}。同一块内的所有帧共享相同的时间步 t_k,而不同的块被分配独立的时间步。
本文的模型对 z^k_{t_k} 和 a^k_{t_k} 进行去噪,它们被定义为干净向量与随机高斯噪声之间的线性插值:
![]()
其中 z^k_0 ∼ N(0,I),a^k_0 ∼ N(0,I),而 z^k_1 和 a^k_1 分别是干净视频潜向量和归一化动作。因此,来自前一块的干净上下文可以表示为
![]()
本文训练模型 u_θ 使用以下流匹配目标来预测两个模态的联合速度:
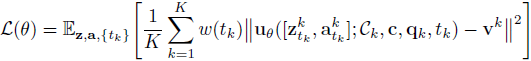
![]()
其中 w(t_k) > 0 是 t_k 的预定义权重函数,c 是文本条件,q_k 是第 k 块的具身感受状态, v^k 表示速度。
为了实现高效训练,本文执行轨迹级别的更新,并应用注意力掩码,使得当前带噪声块可以关注之前块的干净上下文。本文在算法1中提供伪代码。
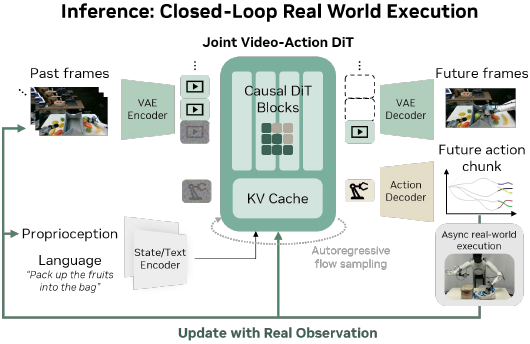
模型推理。 如上图所示,
- 在推理过程中,DREAMZERO 联合对视频和动作块进行去噪,利用 KV 缓存提高效率。
- 与纯视频生成不同,本文的闭环设置允许在每个动作执行后,用真实观测值替换 KV 缓存中生成的帧。这消除了自回归视频生成固有的复合误差问题——这是 WAM 独有的关键优势。
- 此外,作为一个有状态的策略,DREAMZERO 可以利用视觉历史来执行需要记忆的任务。
3.2. DREAMZERO 的实时执行
基于扩散的 WAM 继承了视频基础模型强大的泛化能力,但其 迭代去噪过程 与 反应式机器人控制 产生了根本性的矛盾。
本文解决两个问题:
- 是什么阻碍了 WAM 成为反应式策略?
- 如何解决这个问题以实现实时控制?
3.2.1. 反应性差距
反应式策略必须在几十毫秒内对环境变化做出响应。在单个 GPU 上,DREAMZERO 的朴素实现每个动作块需要大约 5.7 秒,这是由于三个瓶颈:
- 为了平滑动作需要进行 16 步迭代去噪;
- 14B 参数 DiT 骨干的计算成本;
- 推理期间阻塞机器人运动的串行执行。
这种延迟使得闭环控制变得不可行。
3.2.2. 异步闭环执行
本文解决此问题的第一步是 通过异步执行,将推理与动作执行解耦。
- 运动控制器持续执行最新的动作块,而推理则与最新观测值同时运行。
- 这种结构将延迟约束从 "推理必须在机器人移动前完成" 转变为 "推理必须在当前动作块到期前完成"。
在本文的实验中,以 30Hz 的控制频率部署策略,动作视界为 48 步(每个块 1.6 秒),用于双臂操作机器人。因此,目标是将推理延迟降低到大约 200ms 以下,以确保有足够的重叠来实现平滑、反应式的控制。
3.2.3. 系统级优化
在异步执行结构下,通过并行和缓存优化推理吞吐量。
CFG 并行。 无分类器指导(Classifier-free guidance,CFG)需要两次前向传递(条件和无条件)。本文将这两次传递分布到两个GPU上,使每步延迟降低了 47%。
DiT 缓存。 利用流匹配过程中速度预测的方向一致性。当连续速度之间的余弦相似度超过阈值时,重用(reuse)缓存的速度,将有效 DiT 步骤从 16 步减少到 4 步,而对动作预测的质量影响极小。
3.2.4. 实现级优化
本文通过编译器和内核增强进一步降低延迟。
Torch Compile 和 CUDA Graphs。 本文应用 torch.compile 与 CUDA Graphs 以消除 CPU 开销并融合算子。静态形状仅在第一个轨迹期间引起重新编译。
训练后量化。 在 Blackwell 架构上,本文将权重和激活量化为 NVFP4,同时将敏感操作(QKV, Softmax)保持在 FP8,非线性操作保持在 FP16。
内核和调度器增强。 本文使用 cuDNN 后端进行注意力计算,并将调度器操作迁移到 GPU 以消除 CPU-GPU 同步延迟。
3.2.5. 模型级优化:DREAMZERO-Flash
即使有系统优化,扩散步骤的数量仍然是主要的延迟瓶颈。然而,简单地减少步骤会降低动作质量,因为残留的视觉噪声会传播到动作预测中。
DREAMZERO-Flash 通过 在训练期间解耦视频和动作噪声调度 来解决这个问题。
- 关键的洞见是,在推理时,动作应该去噪到其最终值,同时以当前块内仍然带噪声的视频表示为条件,因为如果去噪步骤非常少(例如少于 4 步),生成的视频 token 可能仍然不准确,从而提供带噪声的条件信号。
- 标准的 DREAMZERO 为两种模态采样一个共享的时间步 t_k ∼ U(0,1)。这造成了训练-测试的不匹配:训练时,模型学习在视频和动作处于相同噪声水平时预测动作,但少步或单步推理需要预测干净动作,而视频仍然部分带噪。
【注:下面所说的时间步偏置,简单来说就是
- 视频处于高噪声时间步时,动作处于低噪声时间步
- 视频处于低噪声时间步时,动作处于无噪声时间步
】
DREAMZERO-Flash 通过将视频时间步偏置到高噪声状态来弥合这一差距,即
![]()
![]()

实践中,使用 Beta(7,1) 作为示例配置,得到 E[t^video_k] = 0.125(主要是带噪声的),而动作时间步保持均匀分布(如上图所示)。在训练期间,这使模型暴露于必须从带噪声的视觉上下文中预测干净动作的配置,直接匹配了少步或单步推理场景。结果,将扩散步骤从四步减少到一步,将推理时间从约 350ms 减少到约 150ms,而性能损失极小。
此外,Flash 公式允许灵活的训练配置——例如改变视频和动作的噪声采样比率——以更好地将训练与不同的少步或单步推理场景对齐。在实践中,本文主要在主要的 DREAMZERO 模型训练之后,将 Flash 训练作为最后阶段应用。
动作块平滑。 为了抑制生成动作中的高频噪声,本文将块上采样到 2 倍分辨率,应用 Savitzky-Golay 滤波器,然后下采样回原始分辨率。
3.2.6. 总结
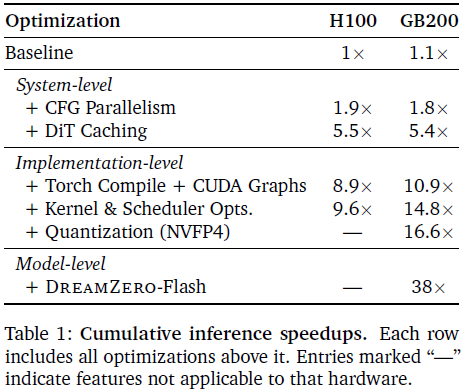
上表总结了累积加速(Cumulative inference speedups)。系统和实现优化在 H100 上产生约 9 倍加速,在 GB200 上产生约 16 倍加速;加入 DREAMZERO-Flash 后,在 GB200 上达到 38 倍加速,将延迟从 5.7 秒降至 150 毫秒。
除了 DiT 缓存和量化外,所有系统和实现级优化在数学上与基线等效,且未观察到可衡量的性能下降。
4. 实验设置
本文在两个机器人具身上验证关于从多样数据中学习的主要假设:AgiBot G1 移动双臂操作器和 Franka 单臂机器人。本文为每个具身分别进行预训练,将多具身训练留待未来工作。对于跨具身实验,本文同时使用 YAM 机器人和人类以自我为中心的数据。
本文与两个最先进的视觉-语言-动作模型(VLA)进行比较:GROOT N1.6 和 π_{0.5}。对于每个基线,本文评估两种初始化策略:
- 从零开始(scratch),使用预训练的 VLM 权重,但未经过先前的机器人数据训练,以便与 DREAMZERO 进行公平的比较;
- 从预训练开始,使用在数千小时跨具身机器人数据上预训练的官方检查点。
两种变体然后在与 DREAMZERO 相同的数据上进行训练:为 AgiBot G1 收集的约 500 小时遥操作数据,以及为 Franka 收集的 DROID 数据集。
本文通过匹配总的批次大小和梯度步数,在所有方法之间保持计算预算相当。
5. 实验结果
5.1. 主要结果
本文评估了 DREAMZERO 相比基线模型的零样本泛化性能,并探究了以下研究问题:
Q1. WAM 能从多样、非重复的数据中学习得更好吗?
本文在预训练数据中存在的任务上评估预训练模型,但处于零样本环境并使用未见物体。结果显示在下图中。
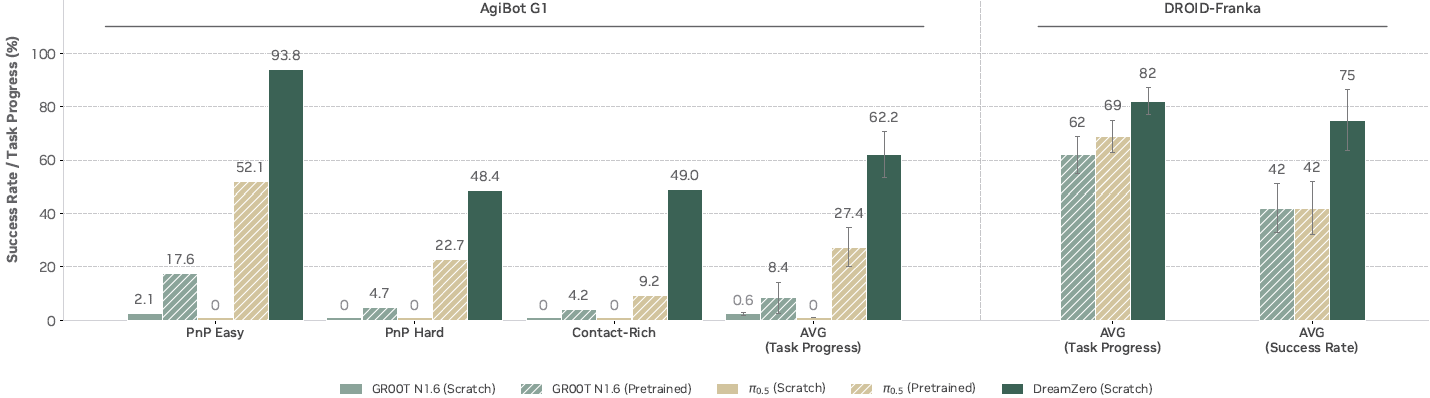
在 AgiBot G1 上,
- 从零开始的 VLA(GROOT N1.6 和 π_{0.5})在所有类别上几乎都取得了接近零的任务进度分数。即使在简单的拾取放置任务(PnP Easy)上,VLA有时也能朝向正确的物体,但在新颖环境中与未见物体的交互却失败了。
- 相比之下,DREAMZERO 成功地从异构数据中学习,取得了 62.2% 的平均任务进度——超过最佳预训练VLA基线(27.4%)的 2 倍,尽管那些基线在继续在本文数据混合集上训练之前,已经在数千小时的跨具身机器人数据上进行了预训练。
在 DROID-Franka 上,也展示了类似的结果;仅在 DROID 数据集上训练的 DREAMZERO,其性能超过了在多个机器人具身数据上预训练的基线模型。
本文将这一差距归因于联合视频-动作的公式:虽然 VLA 需要海量机器人数据来学习直接的观察到动作的映射,但 WAM 利用视频生成作为动作预测的强大先验,从而能够有效学习多样数据并泛化到未见环境。值得注意的是,本文观察到生成的视频与现实世界执行之间存在紧密对齐,即使是对于次优行为也是如此。大多数 DREAMZERO 的失败源于视频生成错误,而非动作预测——策略忠实地执行视频预测的任何轨迹。这表明改进视频骨干将直接转化为更好的 WAM 性能。
Q2. WAM 能泛化到未见任务吗?
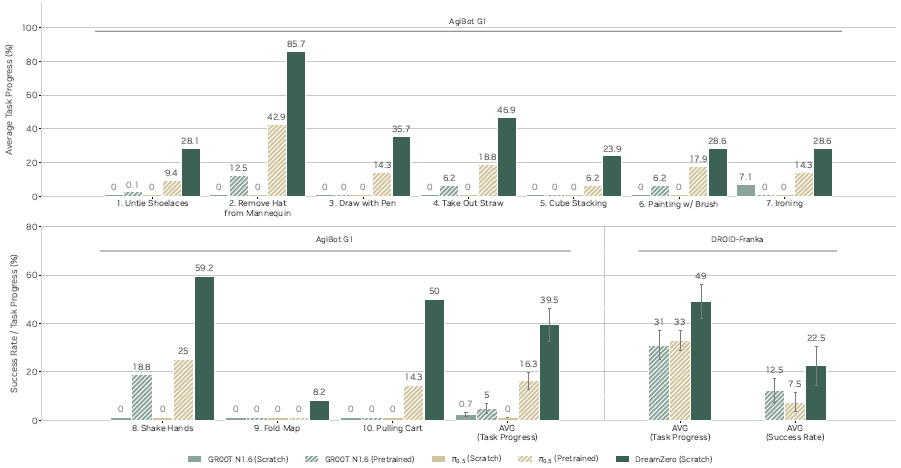
上图评估了对 10 个完全不在预训练分布内的任务的泛化能力,包括解开鞋带、熨烫、用刷子绘画和握手。
在 AgiBot G1 上,从零开始的 VLA 取得了接近零的任务进度(<1%),而 DREAMZERO 平均达到 39.5%——在 "从人体模型上取下帽子"(85.7%)和 "握手"(59.2%)等任务上表现强劲。DREAMZERO 也显著优于预训练的 VLA 基线(39.5%对16.3%),尽管那些基线可能在跨具身预训练中遇到过其中一些任务。
同样在 DROID-Franka 设置中,DREAMZERO(49%任务进度,22.5%成功率)显著优于其他预训练基线(GR00T N1.6 为 31% 任务进度,12.5% 成功率;π_{0.5} 为 33% 任务进度,7.5% 成功率)。
定性地说,本文观察到预训练的 VLA 常常不论指令如何,都倾向于朝向物体并尝试抓取,表明它们过拟合了主导的训练行为(例如拾取放置),而不是理解新任务的语义,这解释了尽管未能完成预期任务,它们却取得部分任务进度的原因。相比之下,DREAMZERO 为未见任务执行视觉规划并成功执行,生成的视频与现实世界动作之间具有强对齐性。
除了结构化评估,本文还通过对超过 100+ 个额外任务进行自由形式提示(包括口头指令)来进行自由形式测试。
Q3. WAM 能提高后训练性能吗?
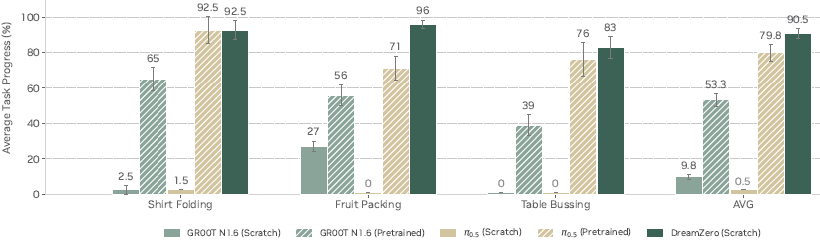
本文研究 WAM 即使在针对特定任务数据进行微调后,是否能保持其泛化能力。上图展示了在三个具有不同分布多样性的任务上的结果。
DREAMZero 在所有任务上匹配或优于 VLA 基线:在折叠衬衫和清理餐桌任务上性能相当,在水果打包任务上显著优于。与上文的发现类似,从零开始的基线未能学习准确的抓取目标物体的动作;这意味着从零开始的 VLA 倾向于过拟合训练数据,并且在场景中表格高度、表格距离、物体和物体放置变化时泛化失败,这主要是由于评估地点位于不同的地理位置。
尽管在具有重复数据的多机器人具身上的预训练大大提高了预训练基线的后训练泛化性能,但 DreamZero 在没有跨具身预训练的情况下仍然匹配或超过了预训练的 VLA 基线。由于本文在后训练中仍然评估未见环境,这意味着 DreamZero 的环境泛化能力在后训练后得以保留。
Q4. WAM 能实现对未见任务的强跨具身迁移吗?
本文已经证明 WAM 能泛化到未见任务,现在本文研究 是否可以利用来自不同具身执行相同任务的视频数据来进一步提高这种泛化能力。关键的是,对于跨具身数据,本文仅使用视频预测目标(无动作),同时对 AgiBot 预训练数据保持联合视频-动作目标;因此,跨具身数据充当了额外的视觉体验,以加强世界模型对任务动态和预期行为的理解。
(1) 使用双臂YAM机器人的 机器人到机器人迁移,以及 (2) 使用以自我为中心的人类演示的 人类到机器人迁移。对于每种设置,本文收集了 9 个未见任务的 72 个多视角轨迹(每个任务 8 个演示,YAM 20分钟,人类 12 分钟)。然后,从 DREAMZERO-AgiBot 检查点开始,以 1:1 的比例与预训练数据混合,进行 10K 步的协同训练。
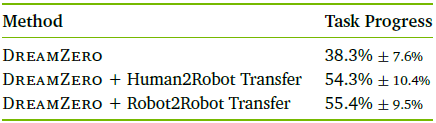
在 9 个未见任务上的结果如上表所示,两种迁移设置都提高了相对于基线 DREAMZERO 的性能。机器人到机器人迁移带来了最大的增益(38.3% → 55.4%),这可能是因为具身差距较小;YAM和 AgiBot 都是双臂平行夹爪。人类到机器人迁移也提高了性能(38.3% → 54.3%),尽管形态差距更大且视角是动态的以自我为中心。
这些结果指出了 WAM 的一个有前景的特性:与最近的 VLA 方法不同,本文的方法仅依赖视觉信息,无需动作标签。虽然目前的成功率仍然中等,但仅凭 10-20 分钟的纯视频数据就能带来持续改进,这提供了一个早期信号,表明跨具身的视觉经验可以有意义地迁移。这开辟了一条潜在的扩展路径:丰富的人类视频数据——数量级上大于机器人数据集——可能使 WAM 能够在不需动作标注的情况下获得多样化技能,但这有待进一步研究以加强迁移机制。
Q5. WAM 能实现少样本的新具身适应吗?
本文对 DREAMZERO-AgiBot 检查点在一个新的双臂操作器(YAM 机器人)上进行后训练,仅使用了 55 个跨 11 个独特任务的轨迹(约 30 分钟数据)。

如上图所示,尽管数据和多样性有限,后训练的策略仍保留了强大的语言跟随能力,甚至能泛化到训练期间未见的新物体,包括南瓜、泰迪熊、笔、杯面和纸袋。即使在数据极少的情况下,本文也观察到紧密的视频-动作对齐,展示了非常高效的跨具身迁移。
本文假设有两个因素促成了这种效率:
- AgiBot G1 和 YAM 具身在视觉上相似(均配备双臂平行夹爪);
- 更根本的是,从预测的视频中学习隐式 IDM 可能天生就比直接策略学习更具样本效率——模型只需要学习从视觉未来到动作的映射,同时利用预训练视频模型对物理动态的已有理解。
与本文AgiBot的发现一致,失败主要源于视频预测错误而非动作提取,这表明在后训练期间增加任务多样性可以进一步提高性能。
Q6. DREAMZERO-Flash 在使用更少去噪步骤时能保持性能吗?
本文评估 DREAMZERO-Flash 在激进的单步去噪下是否能保持任务性能。

如上表所示,将 DREAMZERO 从 4 步去噪减少到 1 步,在清理餐桌任务上任务进度大幅下降(83% → 52%)。相比之下,DREAMZERO-Flash 在单步推理时实现了更高的平均成功率(74%),仅比 4 步基线低 9%,同时速度快约 2 倍。这表明解耦噪声调度为实时部署提供了更有效的速度-准确性权衡。
5.2. 模型与数据消融
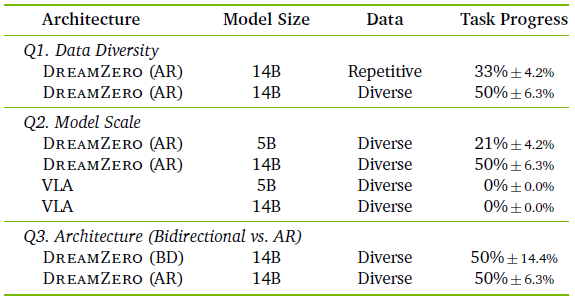
Q1. 数据多样性能否提高泛化能力?
本文将 DREAMZERO 在 500 小时多样数据上训练与在 500 小时重复数据上训练进行比较,后者包含 70 个任务,每个任务有大量使用相似物体位置和配置的重复演示。
如上表所示,即使在简单的拾取放置任务上,多样数据也显著提高了泛化能力(33% → 50%)。
文假设这反映了 WAM 的学习动态:由于视频预测大部分是从预训练中继承的,关键挑战在于学习逆动力学。一个鲁棒的 IDM 需要跨不同上下文的多样状态-动作对应关系,而这正是重复数据所缺乏的。
Q2. WAM 的性能会随着模型规模的扩大而提升吗?
对于 VLA,扩大模型规模可以提高语义推理能力,但不一定能提高动作预测能力。本文发现 WAM 展现出更清晰的规模效应:14B 模型显著优于 5B 模型(50% 对 21%),较小的模型容易产生视觉幻觉,进而传播到错误的动作中。
为了确保公平比较,本文也扩大了 VLA 基线以匹配 DREAMZERO 的规模,从预训练的 8B 和 32B VLM初始化,截取 transformer 块的前半部分,并附加基于 DiT 的动作模块。
如上表所示,更大的 VLA 仍然无法从多样数据中学习(0% 任务进度),常常在物体附近徘徊而不接触。这表明仅增加模型容量并不能解决 VLA 在多样数据分布上的困难。
Q3. 自回归架构是否优于双向架构?
本文比较了 DREAMZERO 的自回归(AR)架构与双向(BD)变体。虽然任务进度相似(表4),但 AR 模型产生了明显更平滑的动作——通过整个动作序列的反向传播实现了更好的时间一致性。此外,由于 KV 缓存,AR 推理速度提高了 3-4 倍。
6. 讨论与未来工作
WAM 的规模定律。
- 本文发现,利用更大的视频骨干模型和在多样数据上训练可以提升下游性能。
- 然而,本文仍然缺乏机器人基础模型,特别是 WAM 规模定律的证据。
- 类似于语言模型的规模定律,需要探索 WAM 的规模定律(取决于模型大小、数据集大小和训练计算量),以确定提取 WAM 最大能力的最佳配置。
- 本文预计 WAM 的规模趋势将与 VLA 不同,显示出对动作更直接的规模定律。
- 本文将对 WAM 规模定律的深入研究留待未来工作。
从真实世界的人类数据中学习。
- 尽管本文研究了利用以自我为中心的人类数据来提高未见任务的性能,但本文的实验仍局限于小规模的实验室数据(仅 12 分钟)。
- 最近,大量比机器人数据分布更多样的人类视频数据已经发布。
- 由于 WAM 是在多样化的互联网视频数据上预训练的,本文假设,利用与机器人操作任务相关的大规模以自我为中心的人类视频数据,将比当前的 VLA 带来更强的下游机器人任务迁移能力。
- 本文将这一方向留待未来工作。
更快的推理。
- 通过模型和系统优化,本文使 DREAMZERO 能够使用 2 个 GB200以 7Hz 运行。
- 然而,与当前在消费级 GPU 上运行速度可达 20Hz 以上的 VLA 相比,由于大参数量和视频模型迭代去噪的特性,DREAMZERO 的计算成本仍然很高。
- 未来,如果较小的视频骨干模型也具有强大的泛化能力,WAM 有可能被用作轻量级边缘设备上的实时 System 1 模型。
长程推理。
- 当前的 DREAMZERO 架构主要作为 System 1 模型运行。
- 尽管 DREAMZERO 具有视觉记忆的概念,但当前是短程的(6 秒)。
- 鲁棒的长程执行将需要 System 2 规划器或具有显著扩展上下文窗口的 WAM。对于前者,模块化双系统架构和统一方法都提供了有希望的方向。对于后者,可以在扩展 WAM 上下文长度方面进行调整。
高精度任务。
- 虽然 DREAMZERO 广泛泛化于任务和环境,但它继承了行为克隆在需要亚厘米级精度任务(如钥匙插入或精细装配)上的局限性。
- 本文多样化的预训练策略优先考虑广度,这可能无法充分代表这些高精度操作所需的密集演示。
- 尽管如此,最近的研究显示了有希望的结果,即WAM在高精度操作任务上可能实际上具有优势,这是一个令人鼓舞的信号,表明广泛泛化与精细灵巧性之间的权衡可能通过进一步研究得到调和。
为 WAM 设计具身。 本文假设两个关键因素将塑造未来 WAM 开发的最佳机器人具身:
- 自由度:更高自由度的机器人将需要更多的自由玩耍数据来学习准确的隐式 IDM,因为从视觉未来到电机指令的映射随运动学复杂性呈组合增长。量化隐式 IDM 的准确性仍然是一个挑战。
- 与人类的相似性:更接近人类的实体,特别是具有灵巧操作能力的人形机器人,尽管自由度更高,但可能实现更高效的迁移,因为它们可以同时利用视频预训练中的运动先验和大量人类以自我为中心的视频数据。
- 这些因素相互制约——然而,类人实体可能通过以机械简单性换取获取网络规模人类数据(下一代机器人基础模型的燃料)而胜出。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 19
19 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)