具身智能:原理、算法与系统 第19章 技能学习与运动原语
扩散策略的优势包括:表达多模态分布(如绕过障碍物的左右两条路径),训练稳定性(去噪目标比直接回归更容易学习),以及动作序列的一致性(通过预测动作块而非单步动作)。选项框架(Options Framework)将技能形式化为时间扩展的动作,包含:启动集(技能适用的状态),内部策略(技能执行期间的控制),与终止条件(技能结束的判断)。技能序列学习识别技能间的依赖关系与合法转换。每个技能包含:动作原语(
目录
第19章 技能学习与运动原语
19.1 动态运动原语(DMP)
动态运动原语(Dynamic Movement Primitives, DMP)是一种用于表示和学习机器人运动的标准化框架,通过非线性动态系统编码目标导向的运动轨迹。DMP的核心优势在于其稳定性保证、对目标点和速度的适应性,以及便于从示范中学习。
19.1.1 DMP的数学形式
DMP由一组非线性微分方程定义,包含变换系统(transformation system)与正则系统(canonical system)两个耦合部分。变换系统描述系统的运动动力学,正则系统提供时间依赖的相位变量。
对于单自由度系统,变换系统表示为:
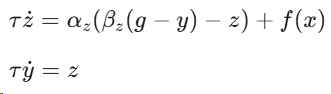

正则系统提供单调递减的相位变量 x :
其中 为衰减系数。相位变量 x 从1指数衰减至0,替代显式时间依赖,使系统对时间扰动具有鲁棒性。
非线性强迫项 f(x) 由基函数的线性组合构成:

19.1.2 形状吸引子与目标吸引子
DMP包含两个吸引子机制:形状吸引子(shape attractor)与目标吸引子(goal attractor)。目标吸引子由线性动态系统的收敛特性保证,确保系统最终到达目标位置 g 。形状吸引子通过非线性强迫项编码期望的轨迹形状。
目标吸引子的稳定性由特征方程分析:当 且
时,线性系统矩阵的特征值实部为负,保证渐近稳定性。即使存在外部扰动,系统仍能收敛至目标点。
形状吸引子通过基函数权重 wi 编码任意复杂的轨迹形状。权重学习通常采用局部加权回归(Locally Weighted Regression, LWR),最小化示范轨迹与DMP生成轨迹之间的误差:
每个基函数的权重独立学习,实现局部泛化:修改轨迹某段的形状不会影响其他段。
对于周期性运动(如行走、跑步),DMP扩展为节律形式,使用相位振荡器替代衰减正则系统:
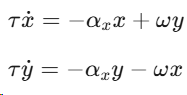
其中 ω 为振荡频率,(x,y) 在极限环上运动,产生周期性相位变量。
19.1.3 DMP的学习与调制
DMP的学习过程从示范轨迹中提取权重参数。给定示教轨迹 ,首先计算期望的强迫项:
然后通过线性回归求解权重 wi 。这种学习方法保证DMP能够精确复现示范轨迹。
DMP的调制能力体现在多个方面:目标点调制通过改变 g 实现,系统自动生成到达新目标的轨迹;速度调制通过调整 τ 实现,加速或减速运动而不改变形状;空间调制通过仿射变换(旋转、缩放)实现,适应不同的任务配置。
耦合项(Coupling Term)扩展DMP以响应外部信号。例如,在避障场景中,添加排斥势场耦合项:
其中为障碍物位置,η 与 γ 为增益参数。耦合项插入变换系统的速度方程,使轨迹实时偏离障碍物。
19.1.4 DMP的扩展与应用
DMP的扩展包括多自由度协调、时间耦合与层次化组合。多自由度DMP通过共享正则系统实现同步,所有自由度使用相同的相位变量 x ,确保各关节运动的时序协调。
时间耦合(Temporal Coupling)允许DMP根据外部事件调整执行速度。通过监测与目标的距离或感知信号,动态调整时间缩放因子 τ ,实现反应式运动调整。
层次化DMP组合多个原语形成复杂行为。高层DMP生成子目标序列,低层DMP执行具体运动。这种层次结构支持任务分解与复用,如行走DMP调用迈步DMP,迈步DMP调用关节轨迹DMP。
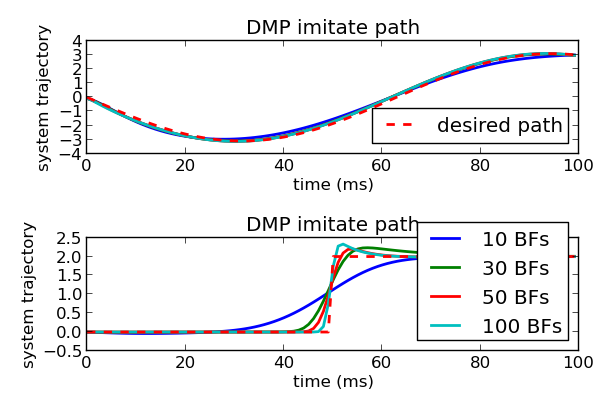
图19.1:DMP轨迹学习与基函数数量影响。上图显示DMP对期望路径的拟合能力,下图展示不同数量基函数(10-100个)对轨迹形状表达能力的影响。更多基函数支持更复杂的形状,但也增加计算负担与过拟合风险。
DMP在机器人操作、行走、抓取等任务中广泛应用。其优势在于数学形式简洁、稳定性保证明确、便于学习与调制。局限性包括难以处理硬约束(如关节限位)、对高维系统的扩展性有限,以及缺乏概率不确定性表示。
19.2 概率运动原语(ProMP)
概率运动原语(Probabilistic Movement Primitives, ProMP)是DMP的概率扩展,将确定性轨迹表示为概率分布,支持不确定性量化、风格变化与强化学习。
19.2.1 轨迹分布表示
ProMP将轨迹建模为时间相关的随机过程,通过权重空间的概率分布诱导轨迹分布。假设权重 w 服从高斯分布:

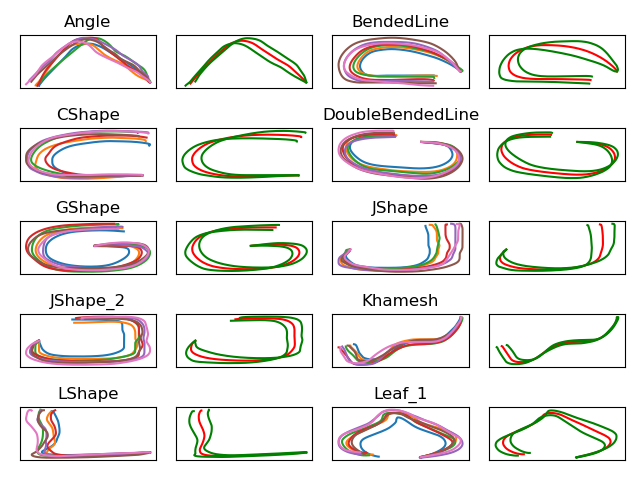
图19.2:ProMP在LASA数据集上的轨迹分布。每种形状显示多条示范轨迹(灰色)与学习的概率分布(绿色为均值,红色为方差)。ProMP捕捉轨迹的变异性,支持在约束下的概率推理。
ProMP的学习通过最大似然估计或贝叶斯推断实现。给定示范轨迹集 ,权重后验为:
高斯先验与共轭似然导致高斯后验,解析更新均值与协方差。
19.2.2 条件概率与风格变化
ProMP的条件概率分布支持在部分观测或约束下的轨迹推理。给定经由点(via-point)约束
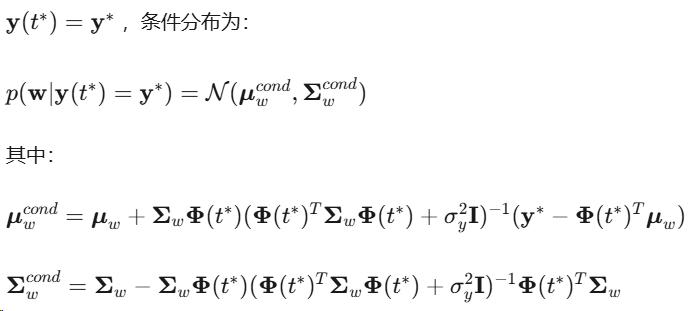
条件分布调整均值以通过约束点,同时减小方差反映增加的确定性。
风格变化(Style Variation)通过隐变量模型实现。假设存在风格参数 s (如运动幅度、速度),影响权重分布:
通过从示范中分离风格与内容,ProMP能够生成风格一致的新轨迹。风格参数可通过最大似然或变分推断学习。
19.2.3 ProMP的强化学习

19.2.4 与其他原语的比较
ProMP与DMP的主要区别在于概率表示。DMP提供确定性轨迹,稳定性由动态系统保证;ProMP提供轨迹分布,支持不确定性推理与约束满足。DMP的非线性强迫项能够表达复杂形状,但学习需要回归;ProMP的线性权重模型简化学习,但形状表达能力受限于基函数选择。
与隐马尔可夫模型(HMM)相比,ProMP专注于连续轨迹生成,而HMM擅长离散状态转换。ProMP与HMM的结合(如HSMM)同时捕捉时间结构与状态转换,适用于分段运动学习。
PRIMP(Probabilistically-Informed Motion Primitives)扩展ProMP到工作空间(而非关节空间),支持机器人无关的技能表示与迁移。通过学习末端执行器轨迹的6D位姿分布(位置+方向),PRIMP能够在不同机器人之间传递技能,通过工作空间密度适应目标机器人的运动学特性。
19.3 隐式策略表示
隐式策略表示通过能量函数或评分函数定义策略,而非显式的条件分布。这种表示支持多模态动作分布、组合泛化与高维动作空间的学习。
19.3.1 神经网络策略

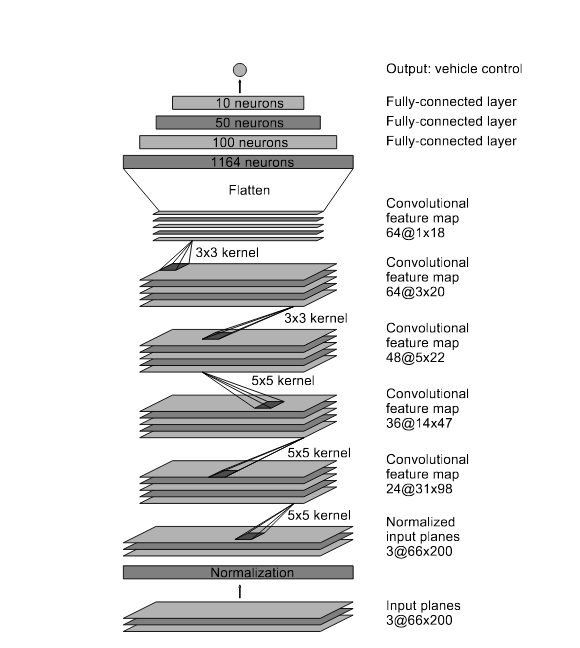
图19.3:行为克隆的神经网络架构。输入图像经过卷积层提取特征,与状态信息拼接后通过全连接层输出动作。这种端到端学习直接从感知映射到控制,但面临分布偏移与复合误差问题。
神经网络策略的局限性包括:难以表达多模态分布(混合高斯假设模态数固定),对分布外状态泛化能力差,以及缺乏对动作约束的显式处理。
19.3.2 扩散策略(Diffusion Policy)
扩散策略(Diffusion Policy, DP)将策略表示为去噪扩散概率模型(DDPM),通过迭代去噪从随机噪声生成动作。这种表示能够表达任意复杂的、多模态的动作分布。
前向扩散过程逐步添加高斯噪声:

扩散策略的优势包括:表达多模态分布(如绕过障碍物的左右两条路径),训练稳定性(去噪目标比直接回归更容易学习),以及动作序列的一致性(通过预测动作块而非单步动作)。DP3(3D Diffusion Policy)将点云表示与扩散策略结合,在3D操作任务中实现 state-of-the-art 性能。
19.3.3 流匹配与生成模型
流匹配(Flow Matching, FM)是替代扩散模型的生成方法,直接学习概率路径的向量场,实现更高效的采样。与扩散的随机微分方程(SDE)不同,流匹配使用常微分方程(ODE):

流匹配的优势在于:确定性采样(ODE积分无需随机性),更快的推理(更少的函数评估),以及更好的数值稳定性。MP1(MeanFlow Policy)将流匹配应用于机器人策略学习,实现单步推理,显著加速动作生成。
19.3.4 隐式行为克隆

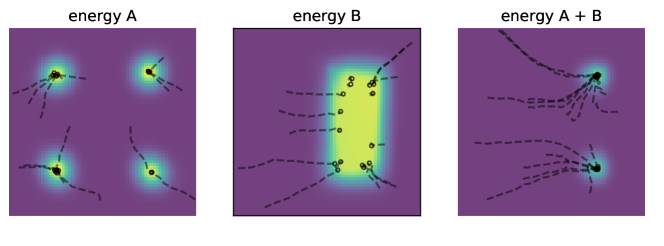
图19.4:隐式策略的能量函数表示。能量A与能量B定义不同的动作偏好,能量A+B通过乘积组合(对应能量相加)实现策略的组合。这种组合性支持零样本的任务组合与泛化。
推理时通过Langevin动力学或梯度下降采样动作:
隐式策略的优势包括:组合性(能量相加对应分布乘积),对多模态分布的自然表达,以及通过能量景观的形状编码约束。局限性在于推理需要迭代优化,计算成本高于显式前向传播。
19.4 技能组合与重用
技能组合与重用是实现机器人终身学习的关键,使智能体能够积累技能库、组合现有技能解决新任务,并在相似任务间迁移知识。
19.4.1 技能库构建
技能库(Skill Library)是机器人可复用行为的结构化集合。每个技能包含:动作原语(如DMP、ProMP或神经网络策略),前置条件(技能适用的状态),后置条件(执行后的状态变化),以及成功概率。
技能发现(Skill Discovery)从未标注的交互数据中识别可复用的行为模式。无监督方法基于状态空间的分割(如聚类、图分割)或变化点检测识别技能边界。LOTUS(Learning from Observations via Unsupervised Skill Discovery)通过变分推断学习离散技能表示,同时优化技能分解与策略学习。
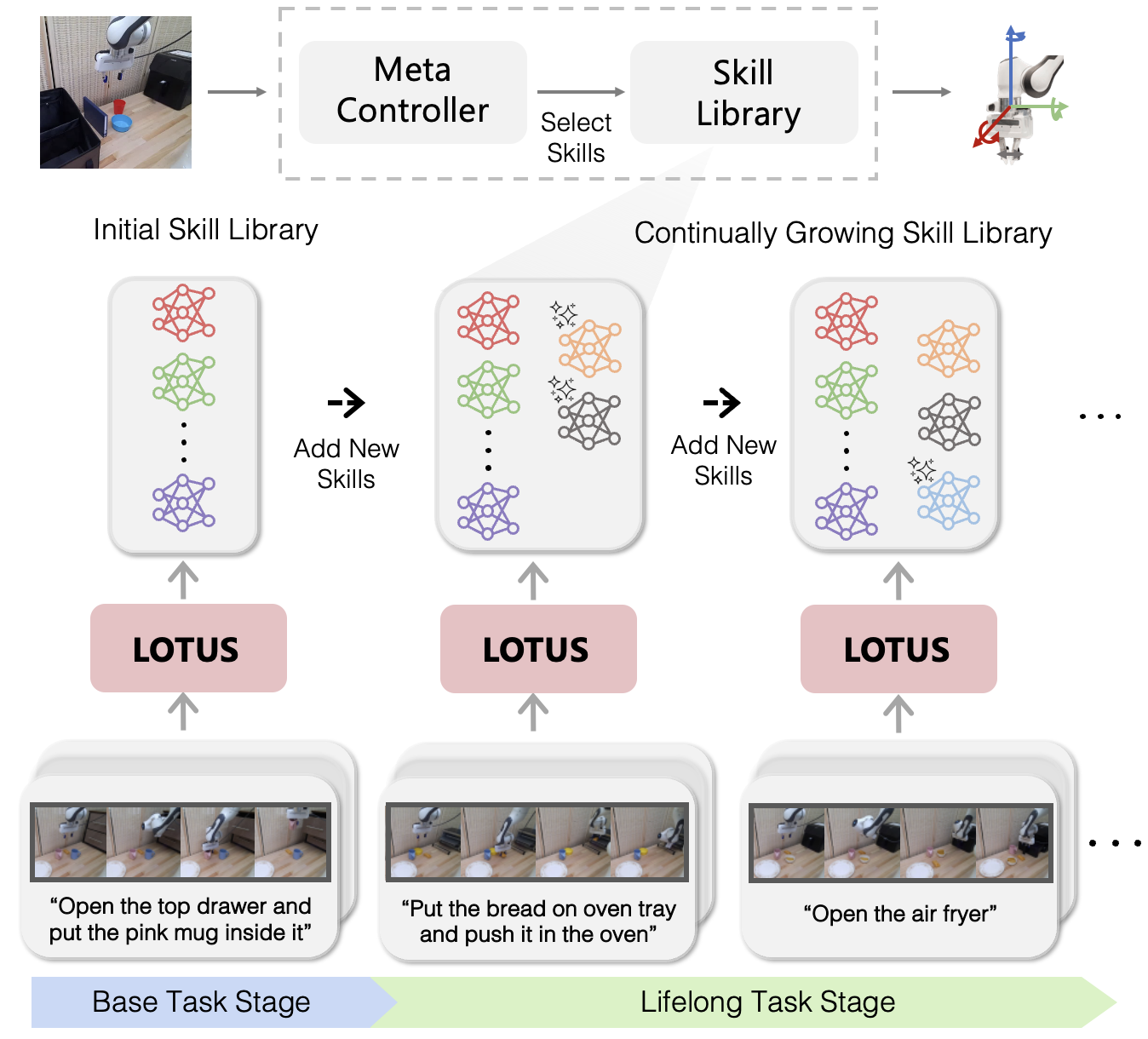
图19.5:LOTUS终身技能学习框架。初始技能库通过无监督发现从示教数据中提取。面对新任务时,元控制器选择相关技能组合,必要时添加新技能。技能库持续增长,支持不断扩展的任务范围。
技能库的组织影响检索效率。基于语义的索引(如自然语言描述、视觉特征)支持根据任务描述检索相关技能。层次化组织(从原子技能到复合技能)支持不同抽象层次的规划。
19.4.2 技能序列学习与自动机
复杂任务需要按特定顺序执行多个技能。技能序列学习识别技能间的依赖关系与合法转换。有限状态自动机(Finite State Machine, FSM)显式编码技能转换规则,每个状态对应一个技能,转换条件基于状态观测。
隐马尔可夫模型(HMM)与半马尔可夫模型(HSMM) probabilistically 建模技能序列,从示范中学习转换概率与持续时间。HSMM显式建模技能持续时间,适用于非均匀时间尺度的技能。
选项框架(Options Framework)将技能形式化为时间扩展的动作,包含:启动集(技能适用的状态),内部策略(技能执行期间的控制),与终止条件(技能结束的判断)。选项框架与标准RL框架兼容,支持在技能空间而非原始动作空间进行规划。
19.4.3 技能转移与适应
技能转移(Skill Transfer)将在源任务或源机器人学到的技能应用于目标任务或目标机器人。基于原语的转移利用DMP/ProMP的调制能力:改变目标点、速度或形状以适应新情境。基于模型的转移学习源任务与目标任务间的映射(如状态空间对齐、动作空间重定向)。
领域随机化(Domain Randomization)在训练时随机化模拟参数(摩擦、质量、几何),学习对参数变化鲁棒的技能,实现从模拟到真实的零样本转移。元学习(Meta-Learning)学习"如何快速学习新技能",在遇到新任务时通过少量适应步骤调整策略。
技能适应(Skill Adaptation)在线调整技能参数以应对环境变化。贝叶斯适应更新技能后验分布,强化学习调整技能策略,阻抗控制调整交互刚度。适应的速度与范围取决于技能表示的选择:显式参数(如DMP权重)易于快速调整,隐式表示(如神经网络)需要更多数据但支持更大变化。
19.4.4 终身技能积累
终身学习(Lifelong Learning)要求机器人在不断学习新技能的同时保持旧技能,避免灾难性遗忘(Catastrophic Forgetting)。弹性权重巩固(Elastic Weight Consolidation, EWC)识别对旧任务重要的网络参数,在学习新任务时施加惩罚保护这些参数。
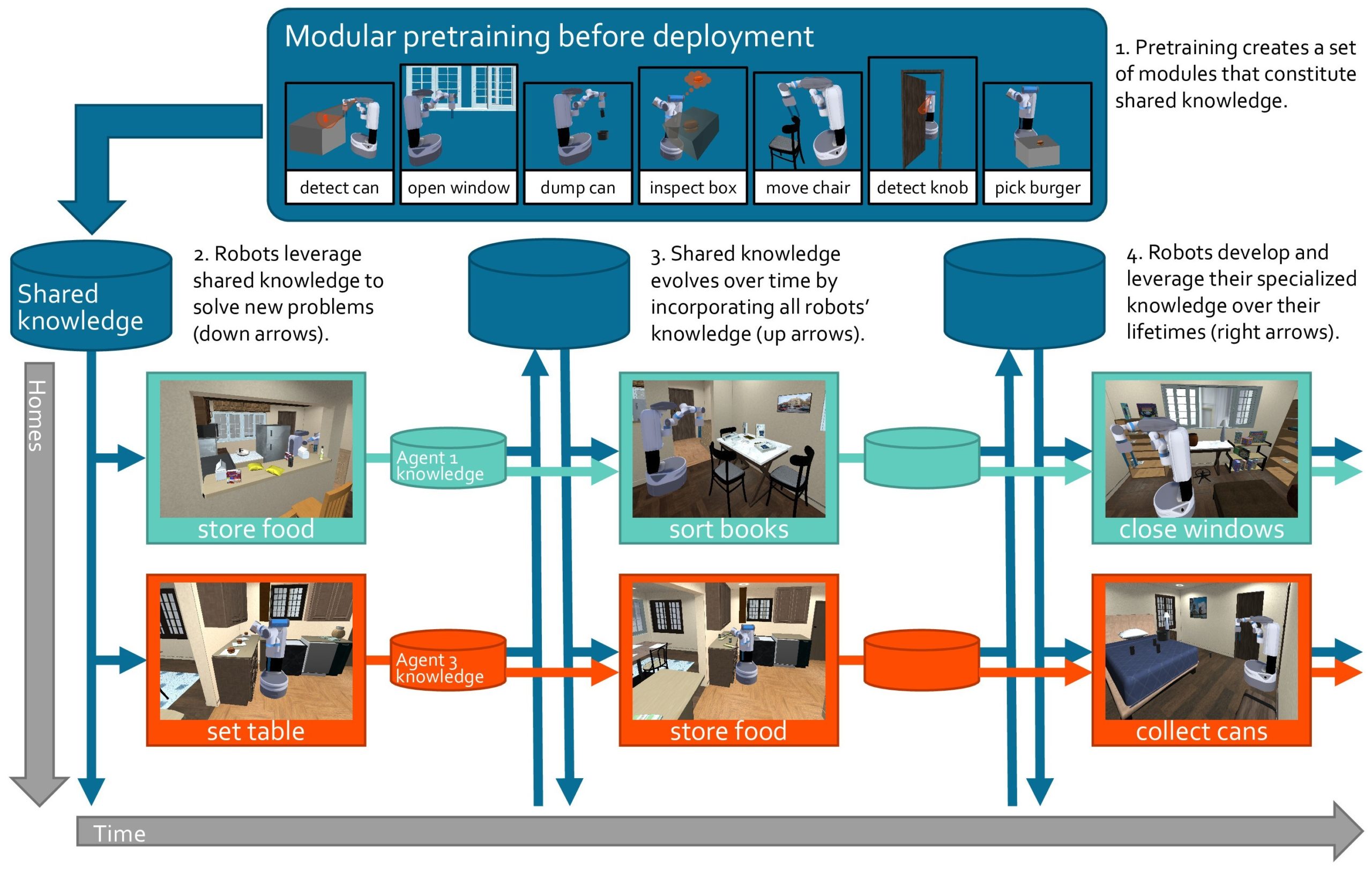
图19.6:模块化终身学习架构。技能库以模块化形式存储,新技能通过元学习快速添加。技能选择基于任务相似性,执行时组合相关技能。模块化设计隔离技能间的干扰,支持持续积累而不遗忘。
模块化架构将技能存储为独立模块(如专家混合Mixture of Experts),新技能添加新专家而非修改共享参数。稀疏激活确保只有相关专家参与推理,减少计算成本与技能间干扰。稀疏扩散策略(Sparse Diffusion Policy, SDP)采用MoE架构,在保持性能的同时实现高效的多任务与持续学习。
技能积累还涉及技能间的知识迁移与组合。组合性(Compositionality)允许从有限原子技能生成无限复合技能。层次化技能学习发现技能间的抽象关系,支持跨领域迁移。元认知(Metacognition)使机器人能够评估自身技能库的覆盖范围,识别知识缺口并主动寻求相关学习经验。
本章小结
技能学习与运动原语为具身智能系统提供了从示范中学习、表示与复用行为的能力。动态运动原语通过非线性动态系统编码稳定的目标导向运动;概率运动原语引入不确定性表示,支持约束推理与强化学习;隐式策略表示通过扩散模型与能量函数表达复杂的多模态分布;技能组合与重用实现了终身学习与持续适应。这些技术的融合正推动机器人从单一任务执行者向通用智能体演进,能够在开放环境中不断积累知识、适应变化并解决新颖挑战。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 15
15 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)