【论文阅读】Dynam3D: Dynamic Layered 3D Tokens Empower VLM for Vision-and-Language Navigation
Dynam3D: Dynamic Layered 3D Tokens Empower VLM for Vision-and-Language Navigation
-
摘要
-
Motivation & Challenges
-
研究背景:Video-VLMs 在 VLN 任务中潜力巨大。
-
核心痛点:
- 缺乏3D空间感:2D视频输入导致模型难以理解复杂的3D几何结构和空间语义。
- 缺乏记忆与全局观:在长距离导航或大场景探索中,模型容易“健忘”。
- 应对变化能力弱:真实环境是动态的,传统静态特征无法适应环境变动。
-
-
核心创新点:Dynam3D 架构
-
从2D到3D的特征升维:利用带有深度信息的RGB-D图像,将预训练的2D视觉特征反投影到3D空间,赋予大模型原生的3D感知力。
-
多层级结构 (Patch-Instance-Zone):
- 底层的图像块 (Patch)
- 中层的具体物体 (Instance)
- 高层的宏观区域 (Zone)。
- 这种分层设计完美契合了人类的导航认知逻辑(从认出一个杯子,到识别一张桌子,再到理解这是一个厨房)。
-
动态与逐层更新机制:特征不是静态的,而是随着智能体的移动“在线计算、实时定位、动态刷新”,确保了内部地图始终与外部环境保持一致。
-
大规模预训练 + 任务微调:赋予了模型极强的泛化能力和指令遵循能力。
-
-
实验与结果
-
在多个极导航数据集(R2R-CE, REVERIE-CE, NavRAG-CE)中达到 State-of-the-Art (SOTA)。
-
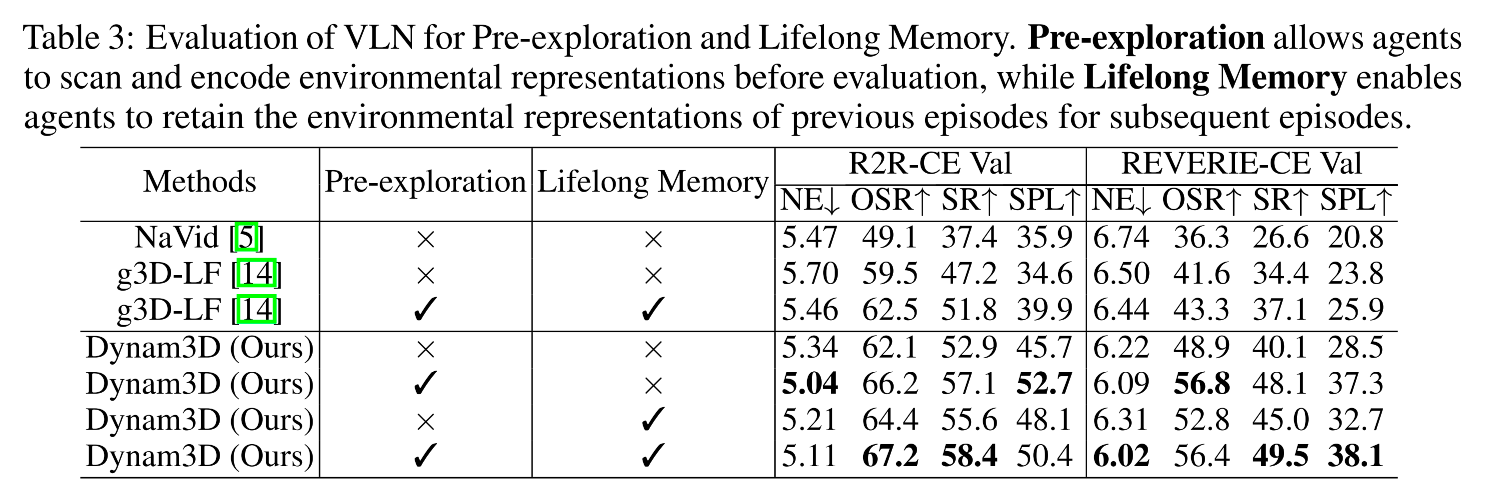
不仅在模拟器中表现优异,论文还包含了真实机器人验证、终身记忆测试和预探索测试,证明了该算法具有极高的实际工程落地价值。
-
-
1. Introduction
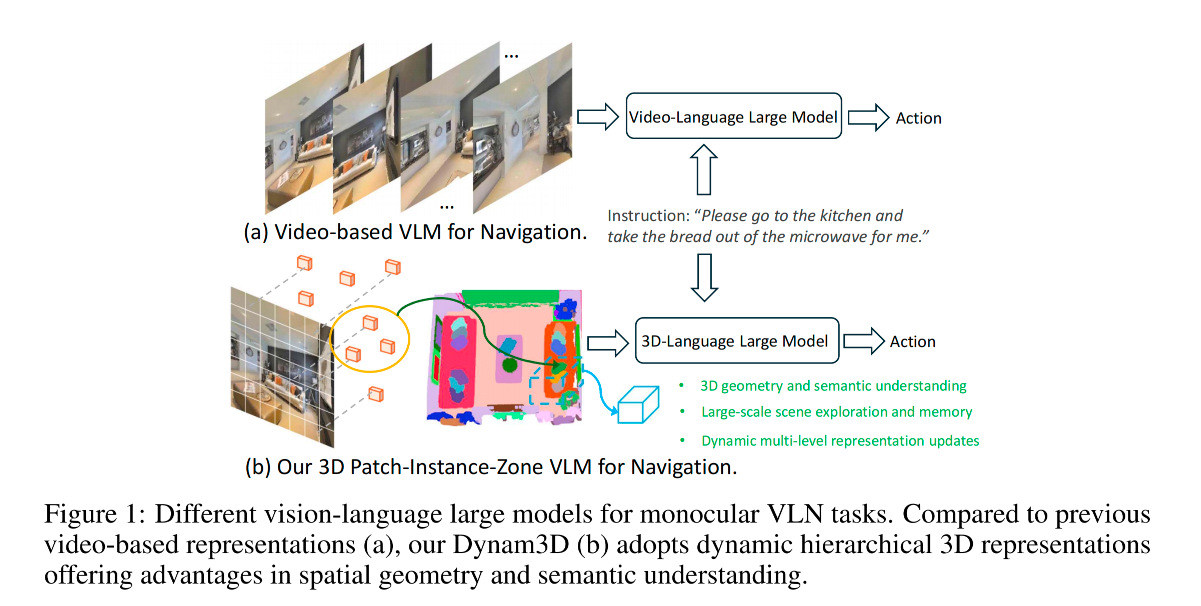
-
行业现状与痛点剖析
-
目前主流的做法是用单目摄像头采集视频,并交给 Video-VLMs 处理。虽然大模型的语言理解能力很强,但在真实3D空间中水土不服:
-
无3D空间感:2D视频无法提供精确的几何深度,导致寻路和纠错能力差。
-
无长期记忆:无法构建结构化的地图,没法利用以前探索过的经验。
-
环境适应力弱:真实环境里人来人往、物体移动,死板的模型一旦遇到变化就会导航失败。
-
-
Dynam3D 的核心表征机制 (Patch-Instance-Zone)
-
Patch(底层/图块级):利用 CLIP 提取 2D 图像特征,并结合深度图反投影到 3D 空间,获取基础的局部语义。
-
Instance(中层/实例级):使用 FastSAM 模型抠出物体边界,将相关的 Patch 聚合成一个个具体的物体(如:一张沙发)。
-
Zone(高层/区域级):将多个物体结合在一起,理解宏观的空间属性(如:有沙发、有电视,所以这是一个客厅)。
-
-
动态更新与记忆维护
-
在线融合匹配:当机器人移动时,一个判别器会不断对比新看到的物体和记忆中的物体,如果是同一个就更新状态,如果是新的就加入记忆。
-
自下而上的刷新:当画面更新时,底层的旧 Patch 被淘汰,新提取的特征会像水流一样,自下而上刷新 Instance 和 Zone 的状态。这让机器人拥有了适应动态环境的终身记忆。
-
-
完整的导航决策闭环
-
特征场全景:引入了特征场技术,用单目相机的画面渲染出周围的全景特征,弥补了硬件视野的不足。
-
3D-VLM 动作输出:3D-VLM 接收“全景局部特征 + Instance/Zone的全局特征”,结合人类的自然语言指令,最终输出精确的动作指令(如转 θ\thetaθ 度,前进 ddd 厘米)。
-
2. Related Work
2.1 Vision-and-Language Navigation
- 早期研究:离散环境与上帝视角
- 过去的 VLN 研究多在离散环境模拟器中进行。智能体像走棋盘一样,只能在预先定义好的节点上移动。
- 而且,它们通常配备的是全景 RGB-D 相机,视野极其开阔。这在现实中对于普通机器人来说是不切实际的配置。
- 近期趋势:连续环境与真实世界部署
- 现在的研究越来越硬核,转向了连续环境模拟器和真实世界。
- 智能体的限制变多了:只能使用单目前向 RGB-D 相机(视野受限,更贴近真实机器人),且必须输出底层的运动控制指令(比如前进多少厘米、转多少度),而不是直接“瞬移”到下一个节点。
- 当前主流:引入 2D/视频大模型 (Video-VLMs)
- 为了提升语言理解和常识推理能力,最近的明星工作(如 NaVid, Uni-NaVid, NaVILA)把 2D 大模型或视频大模型直接搬到了导航任务上,取得了显著的性能提升。
- 核心痛点与 Dynam3D 的破局
- 痛点:视频表征本质上还是 2D 的时间序列,难以捕捉精细的几何语义,也无法理解大尺度的空间布局,这直接限制了机器人的找路和避障能力。
- Dynam3D 的反击:作者强调,Dynam3D 是第一个使用纯正 3D-VLM 来解决单目导航局限性的方法,专为未知的、动态变化的环境而生。
2.2 3D Vision-Language Models
- 主流 3D 场景输入方式
- 受 2D-VLM 的启发,研究者开始尝试把 3D 数据喂给大模型。主要有两种输入:点云 和 多视角图像。
- 不同模型的表征策略
- 全局输入:例如 LL3DA,直接把整个场景的点云一起编码。
- 物体拆解输入:例如 LEO 和 Chat-Scene,把点云切分成一个个物体级别的片段再进行编码。
- 多视角聚合输入:例如 3D-LLM 和 Scene-LLM,先从不同视角拍 2D 照片,做 2D 分割,然后把 CLIP 的语义特征聚合到 3D 空间点上。LLaVA-3D 则进一步将 2D 图像块嵌入到 3D 体素中。
- 现有 3D-VLM 在导航任务上的三大硬伤
- 算力与实时性灾难:把全局的点云或体素直接扔给模型,计算量极其庞大。在机器人探索未知环境时,根本无法做到实时推理。
- 缺乏增量更新机制:这是致命伤。现有的 3D 模型大多是静态的,不懂得喜新厌旧。如果环境变了(比如门关上了),它们无法修改或丢弃过时的场景信息。
- 顾此失彼的计算权衡:它们很难在宏观空间布局(看懂这是个厨房)和微观几何语义(看清地上的障碍物)之间找到计算量的平衡点。
- Dynam3D 的定位
- 基于以上种种痛点,作者顺理成章地引出了 Dynam3D:一个专为了应对这种动态、具身任务而量身定制的 3D-VLM。它既懂 3D,又能实时更新,算力分配合理。
3. Method
- 系统输入输出
- 输入的是机器人当前视角的彩色图、深度图以及相机当时的位置和朝向。
- 输出的是最底层的具体控制指令,而不是抽象的目标点。
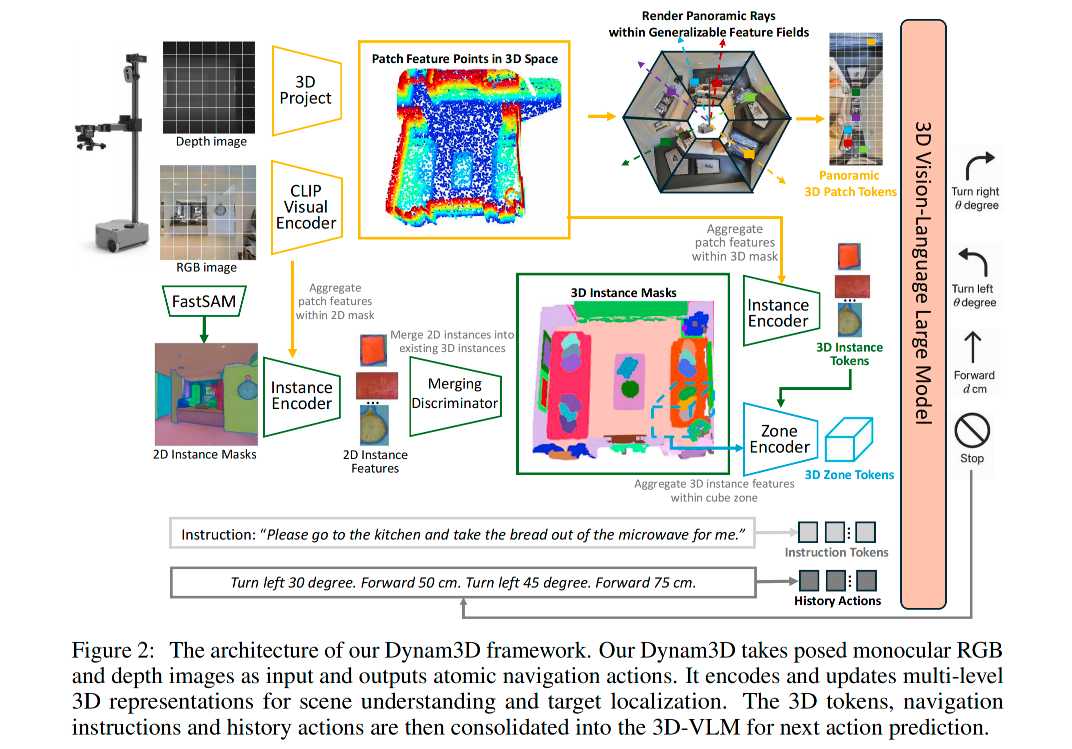
- 底层特征的处理:
- 机器人边走边收集视野里的局部特征点(patch),这些点会被扔进一个特征场中。
- 该特征场用于渲染智能体全景的 3D 图块 token。
- 分层结构:
- 底层的图块(Patch)往上聚合成物体(Instance),物体再往上聚合成大区域(Zone)
- 多层次的 3D token、导航指令和历史动作被输入到 3D-VLM 中,用于下一步的动作预测
3.1 Dynamic Layered 3D Representation Model
3.1.1 Encoding the Patch Feature Points
-
2D语义提取:
- 使用 CLIP-ViT-L/14@336px 作为 RGB 图像的编码器,提取 2D 图块特征 {gt,i∈R768}i=1I\{\text{g}_{t,i} \in \mathbb{R}^{768}\}_{i=1}^I{gt,i∈R768}i=1I
- 其中 gt,i\text{g}_{t,i}gt,i 表示智能体观察到的第 ttt 帧提取的 2D 特征图的第 iii 个图块特征,且 I=24×24I = 24 \times 24I=24×24
-
3D投影
- 将这些图块特征 {gt,i}i=1I\{\text{g}_{t,i}\}_{i=1}^I{gt,i}i=1I 投影到对应的 3D 世界坐标 {Pt,i}i=1I\{P_{t,i}\}_{i=1}^I{Pt,i}i=1I 中。
- 对于每个特征 gt,i\text{g}_{t,i}gt,i,还会计算并存储观测到的水平朝向 θt,i\theta_{t,i}θt,i 和区域大小 st,is_{t,i}st,i,以增强空间表征。
-
特征点集合
Mt=Mt−1∪{[gt,i,Pt,i,θt,i,st,i]}i=1I \mathcal{M}_t = \mathcal{M}_{t-1} \cup \{[\text{g}_{t,i}, P_{t,i}, \theta_{t,i}, s_{t,i}]\}_{i=1}^I Mt=Mt−1∪{[gt,i,Pt,i,θt,i,st,i]}i=1I- 把当前时刻 ttt 看到的所有新 3D 特征点,加入到之前积累的全局地图 Mt−1\mathcal{M}_{t-1}Mt−1 中。
3.1.2 Updating the Patch Feature Points
-
采用图形学中的视锥剔除策略,通过丢弃过时的特征并整合新的特征来动态更新特征点集 M\mathcal{M}M
-
具体来说,在获得观测到的深度图像 Dt∈RH×WD_t \in \mathbb{R}^{H \times W}Dt∈RH×W 后,视锥剔除策略使用相机位姿 [R,T][R, T][R,T] 和相机内参 KKK,将每个特征点的 3D 世界坐标 Pw∈MP_w \in \mathcal{M}Pw∈M 转换为深度图像的像素坐标
[xcyczc]=RPw⊤+T,[uv1]=1zcK[xcyczc] \begin{bmatrix} x_c \\ y_c \\ z_c \end{bmatrix} = R P_w^\top + T, \quad \begin{bmatrix} u \\ v \\ 1 \end{bmatrix} = \frac{1}{z_c} K \begin{bmatrix} x_c \\ y_c \\ z_c \end{bmatrix} xcyczc =RPw⊤+T, uv1 =zc1K xcyczc - dh,wd_{h,w}dh,w 表示深度图 DtD_tDt 中第 hhh 行、第 www 列的深度值。当满足 0<zc<min(du,v+δ,Δ)0 < z_c < \min(d_{u,v} + \delta, \Delta)0<zc<min(du,v+δ,Δ),且 0<u<H0 < u < H0<u<H,0<v<W0 < v < W0<v<W 时,特征点 PwP_wPw 会被从集合 M\mathcal{M}M 中移除。
- 其中 δ\deltaδ 是噪声阈值,Δ\DeltaΔ 是最远剔除距离。当获得RGB-D观测时,先应用视锥剔除,然后再添加新特征点
- 简单来说,如果你之前在地图里记下了一个点,但现在看过去,那个像素位置测出来的实际深度 du,vd_{u,v}du,v 比记忆中那个点所在的深度 zcz_czc 还要远,那么记忆中那个点就是过时的,直接删掉。δ\deltaδ 是容错率,防止传感器有轻微误差。
3.1.3 Dynamically Encoding 3D Instance Representations
-
如果把所有细碎的底层 Patch 全给大模型,模型会被撑爆。因为人说话下指令时,是说走到具体物体,而不是走到某个像素,所以需要升维到物体层面。
-
具体做法
-
FastSAM 快速将观测到的 RGB 图像分割成一组 2D 实例掩码。
-
在每个掩码内,一个基于 Transformer 的实例编码器将对应的图块特征 {gm}m=1M\{g_m\}_{m=1}^M{gm}m=1M 和位置嵌入 {pm}m=1M\{p_m\}_{m=1}^M{pm}m=1M 结合,使用一个可学习的 token qqq 作为查询(query),聚合成一个紧凑的实例级表征 OOO:
pm=MLP([Pm−Average({Pm}m=1M),sm,cos(θm),sin(θm)])O=InstanceEncoder(q,{gm⊕pm}m=1M) p_m = \text{MLP}( [P_m - \text{Average}(\{P_m\}_{m=1}^M), s_m, \cos(\theta_m), \sin(\theta_m)] )\\ O = \text{InstanceEncoder}(q, \{g_m \oplus p_m\}_{m=1}^M) pm=MLP([Pm−Average({Pm}m=1M),sm,cos(θm),sin(θm)])O=InstanceEncoder(q,{gm⊕pm}m=1M)- 用 FastSAM 把画面里的物体抠出来。然后把属于这个杯子的所有零碎特征 gmg_mgm 和它们的三维位置信息 pmp_mpm(包含相对位置、大小、角度),通过 Transformer 融合成一个单一的向量 OOO,这就代表了这个物体。
-
-
Merging Discriminator
-
意义:3D 实例需要多视角和几何的一致性,从而使智能体能够在不同视角下识别出同一个实例。为此,作者训练了一个合并判别器,将 2D 实例表征整合为一致的 3D 实例。
-
流程:
- 最初,每个 2D 实例都被视为一个新的 3D 实例。
- 在随后的每一步中,对于每一个新的 2D 实例,都会检索出距离最近的 Top-K 个已有的 3D 实例。合并判别器使用语义和几何编码评估每一对 2D-3D 实例候选对,以确定它们是否对应同一个物体。
- 如果在 Top-K 候选者中找不到匹配项,则创建一个新的 3D 实例。
- 否则,将该 2D 实例与最相似的 3D 实例合并(通过拼接它们的图块特征并通过实例编码器更新 3D 实例表征)。
- 当过时的图块通过视锥剔除被移除时,3D 表征会使用剩余的相关图块进行更新。
- 如果所有图块都被移除了,我们就丢弃该 3D 实例。
-
训练
Lsegm=1J∑j=1J∑k=1KCrossEntropy(MergingDiscriminator(Oj2D,Ok3D,Dj,k),Gj,k) \mathcal{L}_{\text{segm}} = \frac{1}{J} \sum_{j=1}^J \sum_{k=1}^K \text{CrossEntropy}(\text{MergingDiscriminator}(O_j^{\text{2D}}, O_k^{\text{3D}}, D_{j,k}), G_{j,k}) Lsegm=J1j=1∑Jk=1∑KCrossEntropy(MergingDiscriminator(Oj2D,Ok3D,Dj,k),Gj,k)- 它本质上是一个二分类器。如果送进去的 2D 特征和 3D 特征在真实标注中是同一个物体,就惩罚它预测 0 的情况;反之亦然。Dj,kD_{j,k}Dj,k 是它们之间的物理距离,也是重要参考指标。
-
3.1.4 Feature Distillation and Language Alignment for 3D Instances
-
为了使 3D 实例与语言语义对齐,作者在 SceneVerse 和 g3D-LF 的大规模 3D-语言对上利用了对比学习。
-
给定一个 3D 实例特征 OiO_iOi 以及从 CLIP 文本编码器中提取的对应标注语言描述特征 TiT_iTi,作者将 TiT_iTi 视为正样本,其他实例的描述作为负样本。公式为交叉熵损失。
-
因为 3D 标注数据太少了,作者采用知识蒸馏的方式:CLIP 这个 2D 模型见过的图片多达几十亿张,所以直接 3D 模型去模仿 CLIP 提取出来的特征。
Lsubspace_distillation=1I∑i=1ICrossEntropy({CosSim((Oi−Vj),(Ojgt−Vj))/τ}j=1J,i) \mathcal{L}_{\text{subspace\_distillation}} = \frac{1}{I} \sum_{i=1}^I \text{CrossEntropy}( \{ \text{CosSim}( (O_i - V_j), (O_j^{\text{gt}} - V_j) ) / \tau \}_{j=1}^J, i ) Lsubspace_distillation=I1i=1∑ICrossEntropy({CosSim((Oi−Vj),(Ojgt−Vj))/τ}j=1J,i)- 子空间对比学习:其中 VjV_jVj 是通过对给定 2D 视角内的所有图块特征进行平均池化计算得出的,用以产生该视角的局部语义中心,即语义子空间。
3.1.5 Feature Distillation and Language Alignment for 3D Zones
- 把空间切成一个个几立方米的大方块,然后把这个方块里的所有物体融合成一个整体的向量 Z\mathcal{Z}Z。
- 这样模型就有了宏观大局观。后面也是通过类似对比学习的方法,让这个区域特征和人类的长文本描述对应起来。
3.2 3D Vision-Language Model for Navigation
-
基础模型
-
模型架构:系统采用具有 38 亿参数的 LLaVA-Phi-3-mini 作为核心的 3D-VLM。该模型体积适中,能够在多模态推理能力和端侧计算效率之间取得良好平衡。
-
跨域对齐:由于前置模块生成的 3D Tokens(包含 Patch、Instance、Zone)已经在特征提取阶段与
CLIP-ViT-L/14@336px的语义空间严格对齐,因此该 2D-VLM 强大的图像文本理解与推理能力可以直接零样本(Zero-shot)迁移到 3D 导航任务中。
-
-
全景 3D 图块特征编码
-
目的:弥补单目相机视角的局限性,捕获智能体周围完整的几何与语义信息。
-
实现机制:引入可泛化特征场模型,以智能体为中心构建全景特征。
-
采样与渲染:在智能体周围的垂直 90° 和水平 360° 视场内,均匀采样 12×4812 \times 4812×48 条射线。 模型沿这些射线渲染出 3D 图块特征(用 g^\hat{g}g^ 表示)及其对应的深度估计值,从而提供基于自我中心视角的精细场景表示。
-
-
标准化的输入与输出格式
-
Input:按照 LLaVA 模型的标准 Prompt 格式,将多种模态的信息拼接为一个上下文序列输入给模型。其结构依次为:
<user> {图块Tokens} {实例Tokens} {区域Tokens} {语言指令Tokens} {历史动作Tokens} <end><assistant> -
Output:模型被设定为直接预测并输出底层原子导航动作,格式具体表现为以下四种之一:
- 左转 θ\thetaθ 度 (Turn left θ\thetaθ degree)
- 右转 θ\thetaθ 度 (Turn right θ\thetaθ degree)
- 前进 ddd 厘米 (Forward ddd cm)
- 停止 (Stop)
-
-
显式空间位置编码
-
相对坐标计算:为了让一维的大语言模型理解 3D 空间关系,系统计算每个 3D Token 相对于智能体相机的局部坐标系数据,包括:相对坐标 [xc,yc,zc][x_c, y_c, z_c][xc,yc,zc]、相对距离 DcD_cDc 以及相对水平偏角 θc\theta_cθc。
-
MLP 映射:将上述物理量拼接为向量 [xc,yc,zc,Dc,cos(θc),sin(θc)][x_c, y_c, z_c, D_c, \cos(\theta_c), \sin(\theta_c)][xc,yc,zc,Dc,cos(θc),sin(θc)],并输入至多层感知机中,生成专门的位置嵌入向量,附加于对应的视觉 Token 之上。
-
-
多模态 Token 的序列化与排序策略
-
Patch Tokens:按 12×4812 \times 4812×48 的行优先顺序排列。起始点设为智能体正后方的射线,并严格按顺时针方向递进。此策略与预训练 LLaVA 处理 2D 单视角图像的扫描逻辑高度一致。
-
Instance & Zone Tokens:按照其与智能体之间的欧氏距离,严格按由近及远的顺序进行升序排列,引导模型优先关注近处障碍与目标。
-
History Action Tokens:缓存队列中仅保留最近执行的 4 步动作文本。若环境探索处于初始阶段,历史动作少于 4 步,则使用特殊的占位符
<none>进行填充对齐。
-
4. Experiments
4.1 Comparison with SOTA Methods
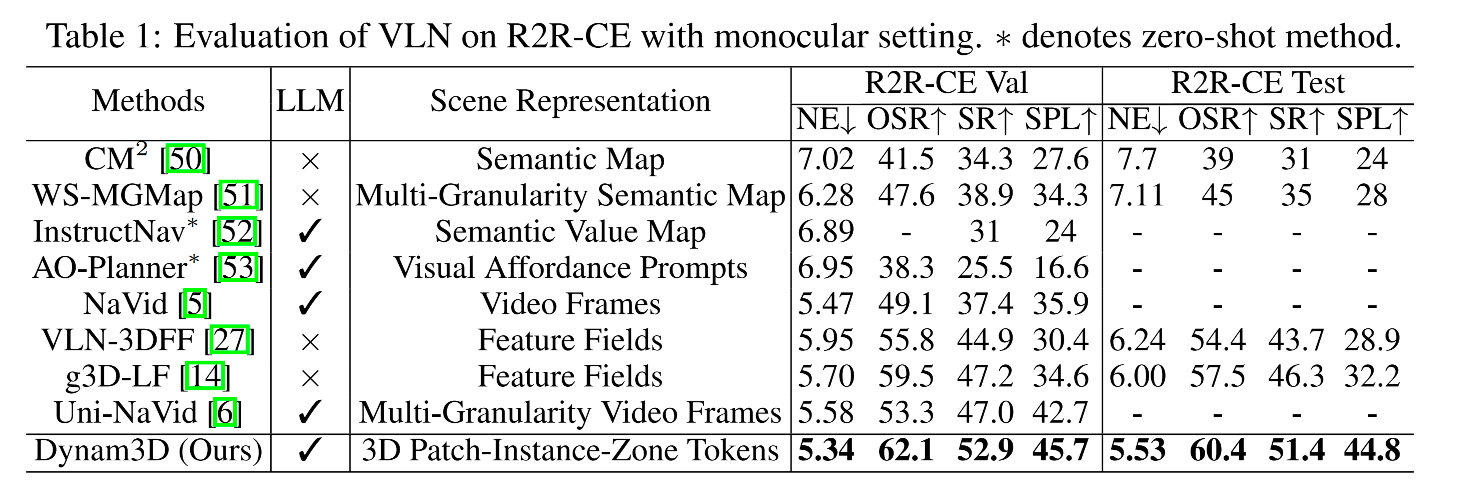
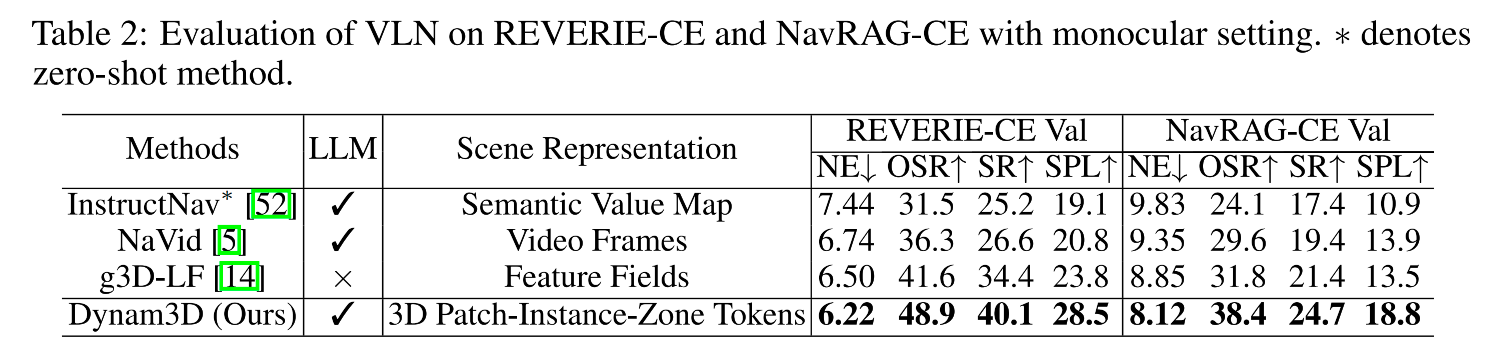
4.2 Experiments on Pre-exploration and Lifelong Memory

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 22
22 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)