RISE——组合式世界模型驱动的RL框架:基于视频扩散模型预测的未来视觉状态,和VLA估计的进度价值评估,以先离线预热后在线改进
前言
世界模型一定是2026年的具身领域最热的研究方向之一,为何这么说呢
- 尽管模型容量和数据获取规模持续扩张,视觉–语言–动作(VLA)模型在接触丰富且高度动态的操作任务中仍然十分脆弱,在这些任务中,细微的执行偏差会累积并最终导致失败
- 另一方面,尽管强化学习(RL)为提升鲁棒性提供了一条有原则的途径,但在真实物理世界中,基于当前策略的强化学习受到安全风险、硬件成本以及环境重置等因素的限制
为弥合这一鸿沟,RISE应运而生,一个通过想象进行机器人强化学习的可扩展框架。其核心是一个组合式世界模型,该模型
- 通过可控的动力学模型预测多视角未来
- 使用进度价值模型评估想象出的结果,从而为策略改进产生信息量丰富的优势信号
第一部分 RISE: Self-Improving Robot Policy withCompositional World Model
1.1 引言与相关工作
1.1.1 引言
如原论文所说,在高层语义能力上,VLA 在复杂物理动力学条件下的稳健操作方面仍然有所欠缺,例如对运动物体的精确抓取或高效的双手协同操控 [65,37]
- 这一差距凸显了模仿学习(Imitation Learning, IL)的内在局限性——IL 是使 VLA 能够生成可执行动作的核心机制
具体而言,IL 天生受制于专家示范的质量和覆盖范围,同时还受到“暴露偏差”(exposure bias)问题的困扰:一旦机器人稍微偏离专家示范的流形,就缺乏将其轨迹纠正回来的恢复能力,从而导致误差不断累积 [73,45,37,15] - 通过自身成败(成功与失败)来提升智能体能力的强化学习则提供了一种潜在的补救途径
在诸如 LIBERO [60] 之类的虚拟模拟器中,智能体可以并行进行海量交互,其中状态与奖励的更新都是可控且可访问的。此类精心设计的模拟器所具备的这些特性,激发了将强化学习成功迁移到最新 VLAs 上的工作 [63,56,61]
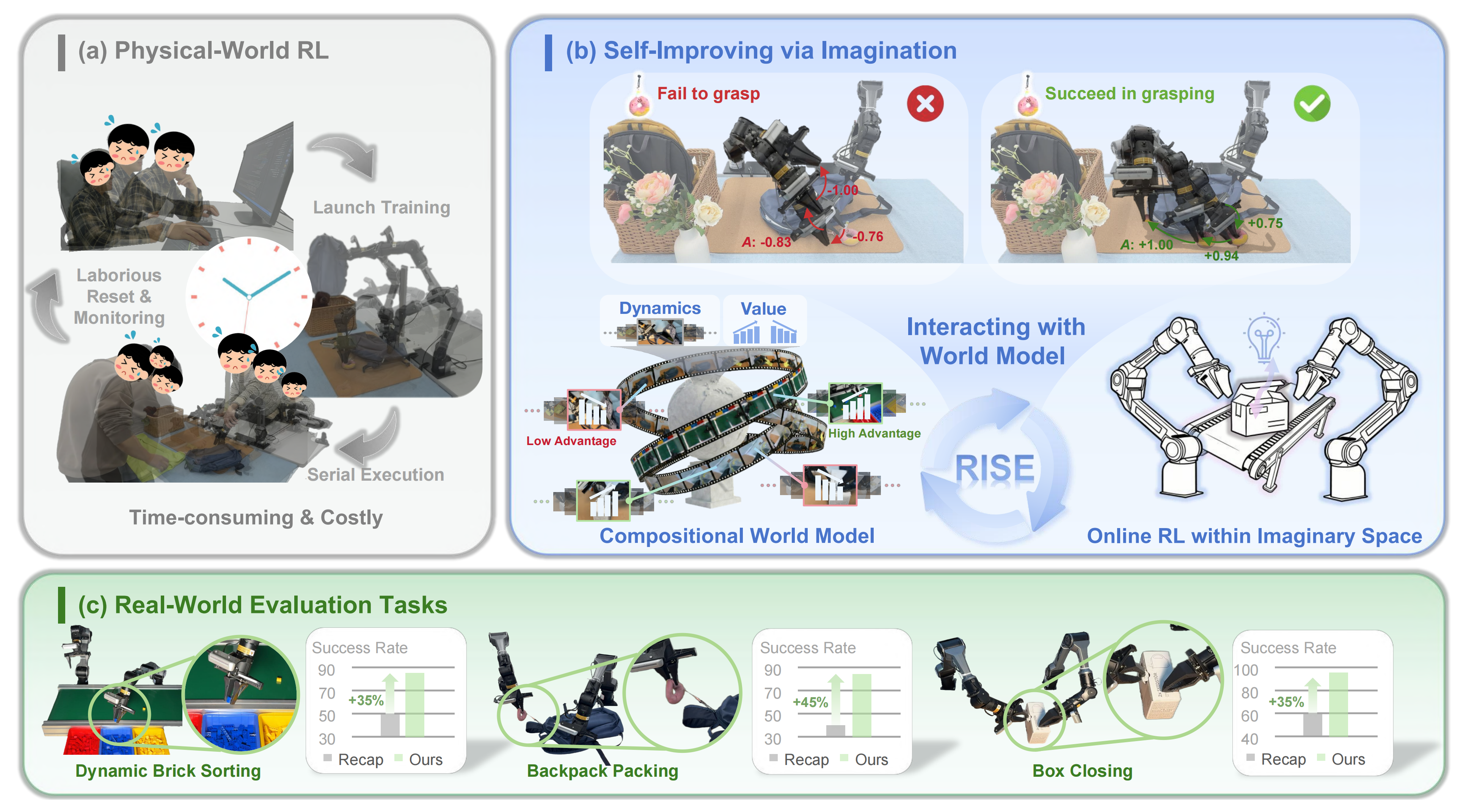
然而,这种可控性与并行性在真实世界环境中并不成立:如图 Fig.1(a) 所示,机器人的执行过程是串行的、耗时的,并且由于需要人工监控与复位而劳动密集。这些物理层面的挑战在很大程度上将以往真实世界强化学习方法限制在离线数据上,而这些数据与当前策略存在严重的分布偏移[85,64,65,80]
最终,如果缺乏足够的 on-policy 数据流,策略的改进可能会受到瓶颈限制 [52,90,72] - simulator与物理世界之间的差距推动了世界模型的发展
世界模型先从被动经验中学习,然后在给定不同动作的条件下模拟未来结果[78,27,29,30,31,50]然而,构建可用于真实世界机器人系统的世界模型面临根本性挑战。对于控制任务,世界模型必须对动作做出忠实响应,才能表达准确的后果。尽管通过集成高容量生成模型提升了视觉真实感 [87,26,99],但如何在各种动作上提高可控性仍然是一个开放问题 [55]
否则,判断最终是否成功就需要世界模型模拟整个任务执行过程,而这超出了大多数生成式世界模型的可靠预测范围 [55,57]
为了解决这些问题,来自1 The Chinese University of Hong Kong 2 Kinetix AI 3 The University of Hong Kong 4 Shanghai Innovation Institute 5 Horizon Robotics 6 Tsinghua University的研究者提出了 RISE,这是一个整体性的学习框架,如图 1(b) 所示
- 其paper地址为:RISE: Self-Improving Robot Policy with Compositional World Model
其作者包括
Jiazhi Yang1,2∗† Kunyang Lin2∗ Jinwei Li2,6∗ Wencong Zhang2∗ Tianwei Lin5 Longyan Wu4 Zhizhong Su5 Hao Zhao6 Ya-Qin Zhang6 Li Chen3 Ping Luo3 Xiangyu Yue1♮ Hongyang Li3♮ - 其项目地址为:opendrivelab.com/kai0-rl
至于代码宣称是26年3月份开放..
————
26年5.1日更新:github地址:github.com/OpenDriveLab/RISE
[2026/04/27] 🚀 RISE 被 RSS 2026 录取
[2026/04/22] 训练代码和预训练动力学模型已发布
具体而言,其核心思想是通过“想象”来强化机器人基础模型,从而实现自我提升。在该框架的核心,是由一个学习得到的世界模型所实现的在线学习环境
受先前工作启发,这些工作将世界建模分解为可处理的子问题,从而能够灵活利用异构的架构和先验知识 [5,20,97,86],作者构建了一个组合式世界模型(Compositional World Model),将仿真问题分解为两个目标:动力学预测和价值估计,使得每一部分都可以采用最适合其角色的网络架构和训练目标来实例化
- 基于高效的视频扩散模型 [59,28],作者在大规模机器人数据集上采用 Task-centric Batching 策略对动力学模型进行预训练,以提升动作控制能力,从而有助于在目标任务上的高效微调
- 价值模型从预训练的 VLA 骨干网络 [8] 初始化,并通过进度估计 [66, 92,25] 和时序差分(Temporal-Difference)学习 [77] 两种目标进行适配,从而对想象状态提供稠密且对失败敏感的评估
最终,作者将这些组件结合起来,为候选动作计算优势,使得通过优势条件化训练实现稳定的策略改进
由此,RISE 能在想象中高效地执行同策略强化学习。如图 Fig.2 所示,作者在一系列真实世界任务上对 RISE 进行了严格评估,这些任务对动态适应性和精确性提出了严苛要求

结果表明,RISE 以不小的幅度优于以往的 RL 方法,同时避免了代价高昂的真实世界试错过程
1.1.2 相关工作
第一,面向机器人学习的世界模型
世界模型被视为通过内部想象实现高效规划和学习的一条路径
- 50-A path towards autonomous machine intelligence
- 27-Recurrent World Models Facilitate Policy Evolution
- 29-Dream to Control: Learning Behaviors by Latent Imagination
- 78-Dyna, an integrated architecture for learning, planning, and reacting
- 机器人与控制领域的早期方法侧重于在潜在空间中进行抽象状态建模,并采用容量较小的动力学模型,这些方法在捕获真实世界操作所需的丰富视觉与接触动力学方面存在局限
30-Mastering Atari with Discrete World Models
31-Mastering Atari with Discrete World Models
34-Temporal difference learning for model predictive control
35-TD-MPC2: Scalable, robust world models for continuous control,为连续控制任务提出了一种可扩展且稳健的世界模型框架
33-MoDem: Accelerating visual model-based reinforcement learning with demonstrations,利用专家演示加速基于视觉的世界模型强化学习过程
49-MoDem-V2: Visuo-motor world models for real-world robot manipulation,将基于视觉的世界模型应用于真实的机器人操纵任务 - 大规模生成式建模的最新进展,使得在高保真观测空间中进行世界建模重新受到关注
10-Genie: Generative interactive environments,提出了一种能够通过视频学习并生成交互式虚拟环境的模型
1-World simulation with video foundation models for physical ai,介绍了 Cosmos 系统,一个用于物理人工智能模拟的大规模视频基础模型
32-Training agents inside of scalable world models
87-Learning interactive real-world simulators,提出了 UniSim 框架,用于从不同数据源学习通用的真实世界交互模拟器
88-Video as the new language for real-world decision making
99-IRASim: Learning interactive real-robot action simulators
然而,要将此类模型适配为强化学习的交互环境仍然具有挑战性。大多数方法更重视视觉逼真性而非动作可控性,从而带来了高得难以接受的推理成本,无法在强化学习循环中使用
————
说白了,不能只是单纯的预测未来视觉状态了事,还需要预测的靠谱 贴近真实的物理环境
顺带说下,对此,Chelsea组最新出了篇论文,也可以看下:VLAW: Iterative Co-Improvement of Vision-Language-Action Policy and World Model
除了动力学预测之外,奖励与价值塑形也在将这些模型用于策略改进时引入了额外的瓶颈。以往工作在很大程度上依赖稀疏的终止奖励或指向目标状态的启发式距离,这些信号对于长时程操控任务提供的指导不足,并且在存在长期预测误差时非常脆弱
96-DINO-WM: World models on pre-trained visual features enable zero-shot planning,利用预训练的视觉特征构建世界模型,实现无需额外训练的零样本规划
93-Reinforcing action policies by prophesying,提出通过预测未来状态作为辅助信号来增强动作策略的学习
100-WMPO: World model-based policy optimization for vision-language-action models,使用基于世界生成的合成数据来优化 VLA(视觉-语言-动作)模型
68-Structured world models from human videos
更重要的是,既有工作主要集中在模拟基准
34-Temporal difference learning for model predictive control,将时序差分学习与模型预测控制(MPC)相结合以提高控制效率
35-TD-MPC2: Scalable, robust world models for continuous control,为连续控制任务提出了一种可扩展且稳健的世界模型框架
33-MoDem: Accelerating visual model-based reinforcement learning with demonstrations,利用专家演示加速基于视觉的世界模型强化学习过程
低层控制问题
84-DayDreamer: World models for physical robot learning
36-Hierarchical world models as visual whole-body humanoid controllers,使用分层世界模型来控制复杂的人形机器人全身运动,其项目地址为:www.nicklashansen.com/rlpuppeteer
74-Learned perceptive forward dynamics model for safe and platform-aware robotic navigation,学习感知型前向动力学模型以实现安全的机器人导航,其GitHub为:github.com/leggedrobotics/fdm
或短时任务(例如抓取与放置),而在接触丰富且动力学复杂的真实世界任务上的验证仍然有限
13-DiWA: Diffusion policy adaptation with world models,利用世界模型对扩散策略(Diffusion Policy)进行环境适应性训练
44-World4RL: Diffusion world models for policy refinement with reinforcement learning,提出使用基于扩散的世界模型对操纵策略进行强化学习细化,其项目地址为:world4rl.github.io
39-NORA-1.5: A VLA model trained using world model-and action-based preference rewards,使用来自世界模型的偏好奖励来训练 VLA 控制模型,其项目地址为:declare-lab.github.io/nora-1.5
26-Ctrl-world: A controllable generative world model for robot manipulation,开发了一种具备高度动作可控性的生成式视频世界模型
41-DreamGen: Unlocking generalization in robot learning through video world models,通过视频世界模型生成的训练样本来释放机器人学习的泛化能力
3-V-JEPA 2: Self-supervised video models enable understanding, prediction and planning,提出了一种用于理解、预测和规划的自监督视频表示模型
98-Unified world models: Coupling video and action diffusion for pretraining,在大规模机器人数据集上通过耦合视频和动作扩散来预训练统一世界模型
受此前那些通过精心集成异构模块来应对具有挑战性的世界建模问题的工作启发
- 97-RoboDreamer: Learning compositional world models for robot imagination,通过组合式世界模型设计来提升机器人想象的质量
- 5-Dream to Manipulate: Compositional world models empowering robot imitation learning,利用组合式世界模型通过想象力来增强机器人的模仿学习
- 20-Video Language Planning,提出了将视频生成模型作为规划器来执行长时程机器人任务
作者将动力学模型与价值函数无缝组合,从而实现对各类动作的忠实模拟
第二,用于基础策略的强化学习
强化学习越来越多地被用于增强 VLA 基础政策在操作稳健性和精确性方面的表现,且大量工作在仿真环境中利用强化学习(RL)对 VLA 进行后训练
- 60-LIBERO: Benchmarking knowledge transfer for lifelong robot learning
- 69-RoboTwin: Dual-arm robot benchmark with generative digital twins
- 16-RoboTwin 2.0
- 67-CALVIN: A benchmark for language-conditioned policy learning
其中交互成本低、可重置且可并行
- 63-VLA-RL: Towards masterful and general robotic manipulation with scalable RL,探索了如何通过可扩展的强化学习来提升 VLA 模型的操纵能力
- 56-SimpleVLA-RL: Scaling VLA training via reinforcement learning,提出了一种简化框架,通过强化学习来规模化训练 VLA 模型
- 14-πRL: Online RL fine-tuning for flow-based VLA models,专门为基于流匹配(Flow-matching)的 VLA 模型设计的在线强化学习微调方法
- 61-What can RL bring to VLA generalization? An empirical study,通过实验研究了强化学习对 VLA 模型泛化性能的具体贡献
- 17-TGRPO: Fine-tuning VLA model via trajectory-wise group relative policy optimization,提出了一种基于轨迹级的群体相对策略优化方法来微调 VLA 模型
- 然而,这种可扩展性在物理世界中并不成立,在真实环境中交互是串行的、缓慢的,并且需要大量人力
因此,先前关于真实世界 RL 的工作往往受限于大量重复使用离策略数据,而在线交互只能在数量有限的机器人硬件上进行,这可能会成为策略改进的瓶颈,并且难以扩展
65-Precise and dexterous robotic manipulation via human-in-the-loop RL,即著名的HIL-SERL
85-Self-improving VLA models with data generation via residual RL,详见此文的解读《PLD——自我改进的VLA:先通过离策略RL学习一个轻量级的残差动作策略,然后让该残差策略收集专家数据,最后蒸馏到VLA中》
4-Efficient online reinforcement learning with offline data,探讨了如何在使用大量离线数据的同时进行高效的在线强化学习探索
64-SERL: A software suite for sample-efficient robotic reinforcement learning - 在学习稳定性方面,有研究提出在优化额外的残差策略 [85]或仅优化输入噪声分布 [80-DSRL,58-GR-RL] 的同时,冻结大规模预训练策略
由于大部分参数保持不变,这类方法牺牲了策略对目标任务的适应性
相比之下,RECAP [2-即π0.6] 通过一种优势条件化(advantage-conditioned)的形式化
23-Diffusion guidance is a controllable policy improvement operator
48-Robotic World Model: A neural network simulator for robust policy optimization,构建了一个神经网络模拟器,专门用于支持机器人策略的稳健优化
来微调预训练策略,从而免去了为扩散或流匹配策略 [51-RL-100: Performant robotic manipulation with real-world reinforcement learning] 调整去噪链的复杂性 - 为了得到可靠的优势用于策略优化,近期工作借助带有进度估计形式化的视觉-语言模型,该形式在数值上稳定且无需繁琐的人工标注
66-Vision language models are in-context value learners,发现视觉语言模型可以通过上下文学习来估计任务进度(即作为价值函数)
94-ReWiND: Language-guided rewards teach robot policies without new demonstrations,利用语言模型生成的指导性奖励来训练机器人,无需额外的人类演示
2-即π0.6
92-A vision-language-action-critic model for robotic real-world RL,提出了一种包含评论家(Critic)模型的 VLA 架构,以支持真实的强化学习任务,其GitHub地址为:github.com/InternRobotics/VLAC
25-Self-improving embodied foundation models,探讨了具身智能基础模型如何通过自我实践不断提升能力的路径
然而,这样的目标容易出现过拟合问题,并且对细微的失败不够敏感 [2,58]
有别于先前方法,作者通过一个学习得到的世界模型,将学习环境从物理世界转移到想象空间,从而实现基于策略的强化学习
此外,作者的价值模型在稳定性和对失败的敏感性方面,同时受益于进度估计和时序差分(Temporal-Difference)学习 [77-Learning to predict by the methods of temporal differences,首次正式提出了时序差分(TD)学习算法]
1.1.3 预备知识
首先,对于世界模型的形式化表述
如原论文所述,作者旨在构建一个世界模型,它由
- 一个用于预测未来状态的动力学模型
- 一个用于预测不同行动方案下回报的价值模型组成。关键在于,这些预测的回报被转换为优势,以指导RL 训练
形式上,令为时刻
的多视角观测,其中包含
个摄像机视角
- 作者采用长度为N 的历史窗口
来捕获时间依赖性 - 条件动作
从当前运行的策略π 中采样:即
其中的动作序列(即动作块)来应用,而
是描述任务的语言指令
动力学模型 在给定历史上下文和所提出的动作序列的条件下,预测未来观测
为了评估想象轨迹的效用,作者进一步引入一个价值模型,其根据观测和任务指令,通过
为“成功完成”分配一个进度信号,总之,作者将优势定义为整个片段上的平均累积改进
具体来说,作者将每个预测的未来观测值与初始观测值
之间的差值作为动作
的奖励,然后在该动作片段的时间范围上取期望,作为优势——视为公式2:
其中 A 与策略 π 提出的动作块相关联,从而构成用于策略优化的学习信号。D 与 V 之间的交互发生在想象空间中,且这两个模块都兼容多视图图像
其次,对于强化学习
作者将该问题表述为一个标准的RL 设定,其决策过程是由元组表征的马尔可夫决策过程MDP
- 在每个时间步
,给定观测
和任务指令
生成一个时域为
,在每一步获得奖励
- 策略与环境之间的交互诱导出轨迹分布
,其中
目标是最大化期望回报
为了度量特定动作序列相对于平均策略表现的优劣,作者使用优势函数,通过式(2) 进行估计
为了确保相对于参考策略 的稳定提升,作者采用来自π∗0.6 [2] 的概率推断框架。且不是直接最大化正则化目标,而是通过用改进概率
对
加权来构造目标分布
——即公式3:
由于改进完全由优势值决定,故有。应用贝叶斯法则使得能够将改进的似然表示为一个密度比——定义为公式4:
将式(4) 代入目标分布并令β = 1,即可抵消无条件先验 ,从而得到简化的目标
在实践中,作者通过将策略条件化在离散化的优势上来实现这一点,从而引导生成朝向高回报轨迹
为了方便大家更好的理解,我还是给大家step by step的解释一下:公式4以及最后简化的目标,即其到底是如何一步一步推导出来的
- 第一步,首先明确公式4的目的/含义(明白了公式4,最后的简化目标便可迎刃而解)
公式 (4) 的目的是将改进似然度表达为一个密度比Density Ratio
其中:代表改进(Improvement)这一随机事件
:在状态
和指令
- 第二步,设定基本假设:改进由优势函数决定
论文指出,由于改进事件决定,因此存在等价关系 :
- 第三步,应用贝叶斯定理
根据贝叶斯定理的基本形式,可将
,将动作
(在给定
- 第四步,映射到策略符号
为了使公式与强化学习框架一致,论文将概率分布映射到具体的策略表示上 :
即对于上面第三步最后那个等式右边的项,从下至上、从左至右
:这是在给定状态下选择动作
:这是在已知会发生“改进”的条件下选择动作
:这是在当前状态下发生改进的先验概率
————
将上述符号代入,并由于该项主要作为目标分布的加权因子,因此使用比例符号
(正比于)来表示这个密度比
把上面第4步最后得到的公式4,代入到此公式3
中,可得
由于该式子的右侧中,分子分母皆存在一个
故两者相除便可直接抵消,从而使得剩下的项为
由于是“给定状态下发生改进的先验概率”,它与具体的动作
————
因此,可以直接得到简化的目标分布上面一系列推导的意义在于
- 原本需要根据“优势函数”去加权旧策略-公式3
这在计算上可能很复杂
通过上述推导,目标分布变成了“在改进发生的条件下采取动作的概率”- 从而使得在实际训练中,这意味着只需要让模型学习那些被打上“高优势(High Advantage)”标签的动作即可
简单来说,抵消先验
1.2 RISE的完整方法论
如原论文所述,本节会有三个部分的内容
- 作者提出了一种组合式世界模型,将动力学预测与价值估计相结合,从而提供一个具有信息量丰富学习信号的交互式环境
值得注意的是,对于世界模型的训练
首先,动力学模型的训练分为两个阶段
- 首先,在 Galaxea [43] 和 Agibot World [11] 上进行预训练,该阶段使用 16 张 NVIDIA H100 GPU,整体(global)batch size 为 512,耗时约七天
- 随后,在任务相关的数据上进行微调,使用 8 张 NVIDIA H100 GPU,整体batch size 为 64,训练大约三天即可完成
其次,价值模型以预训练的 VLA [8] 作为参数化起点,直接在任务相关数据上进行微调,这得益于其从策略骨干网络继承而来的以机器人为中心的知识
- 在前 10k 个训练步中只使用进度估计损失(progress estimate loss),在随后的 40k个训练步中额外加入 TD 学习损失(TD learningloss)
- 在 8 张 GPU 上总 batch size 为 64 的设置下,模型大约在一天的训练后即可收敛
需要强调的是,世界模型的这两个模块仅在策略学习阶段被使用,因此在现实世界的策略执行过程中不会带来任何推理开销
- 在真实环境经验上建立一个策略预热阶段,使策略锚定于实际行为分布,并赋予其基于优势量条件的能力
- 提出一个自改进循环,在世界模型内迭代生成想象轨迹并优化策略
至于算力分配在内的实现细节在最后给出
策略预热阶段在很大程度上沿用了 RECAP [2]在离线收集数据集上的训练流程
- 其中策略以学习得到的价值模型标注的优势(advantage)作为条件
- 随后进行的自我改进阶段大约运行 1 万步
在这两个阶段中,全局 batch size 为 64,使用 8 张 GPU 进行训练
1.2.1 组合式世界模型:先实现可控动力学模型、后实现进度值模型
可扩展的强化学习(RL)需要精确的环境建模,以将当前状态和策略动作映射到未来的动态和回报
- 为此,作者提出一种组合式世界模型,将动力学预测与价值估计解耦,从而使得可以对每个组件的架构进行独立优化
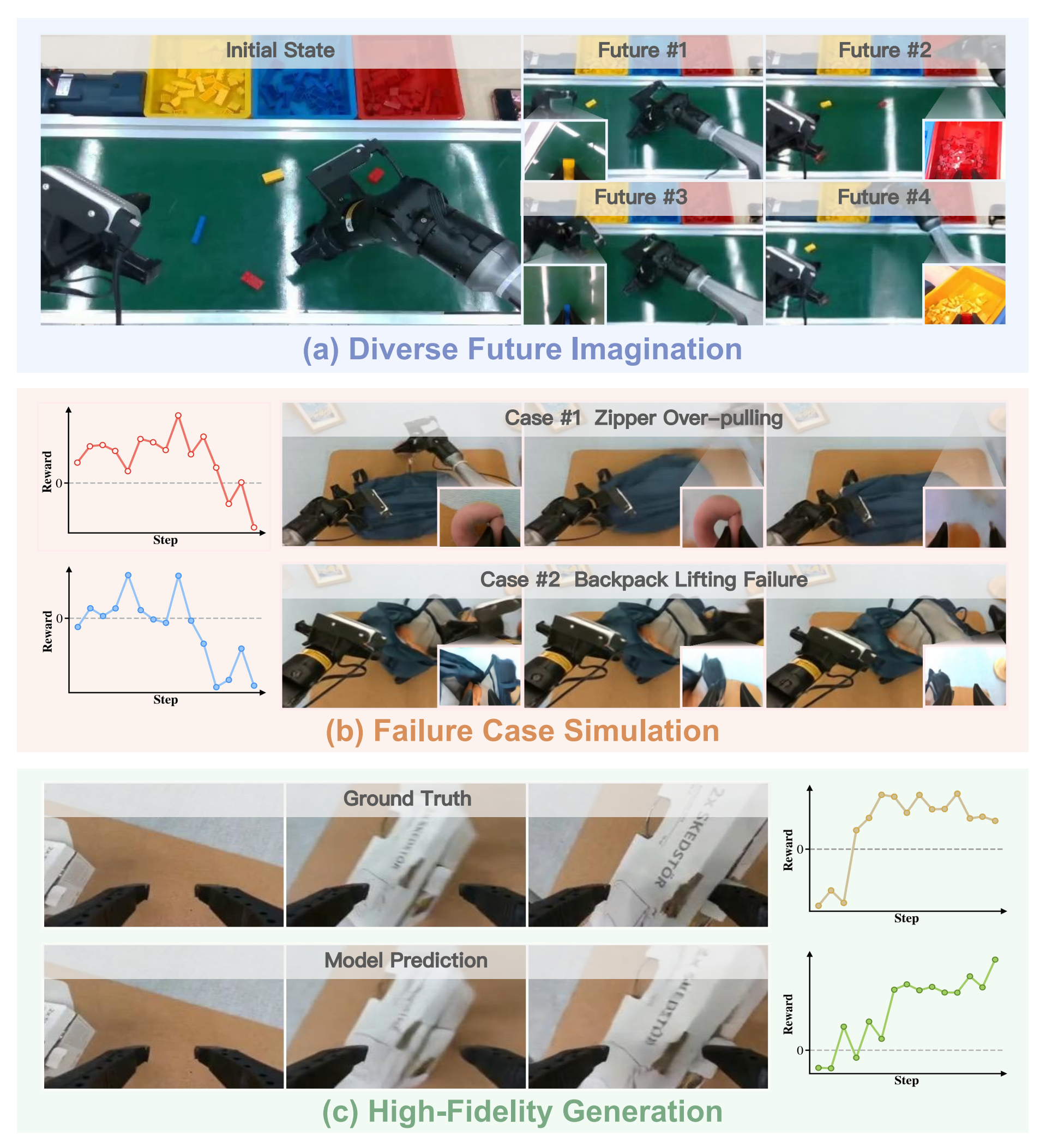
即从一个上下文观测开始,在候选动作片段条件下,动力学模型会模拟出可信的未来轨迹,这些轨迹会由价值模型进行评估,以便为策略改进推导出优势 - 作者在图3中给出了想象结果的若干定性样本
关键的是,该模型仅在训练阶段使用,在推理阶段不会带来任何计算开销
至于世界模型的训练配方和推理流程如图4所示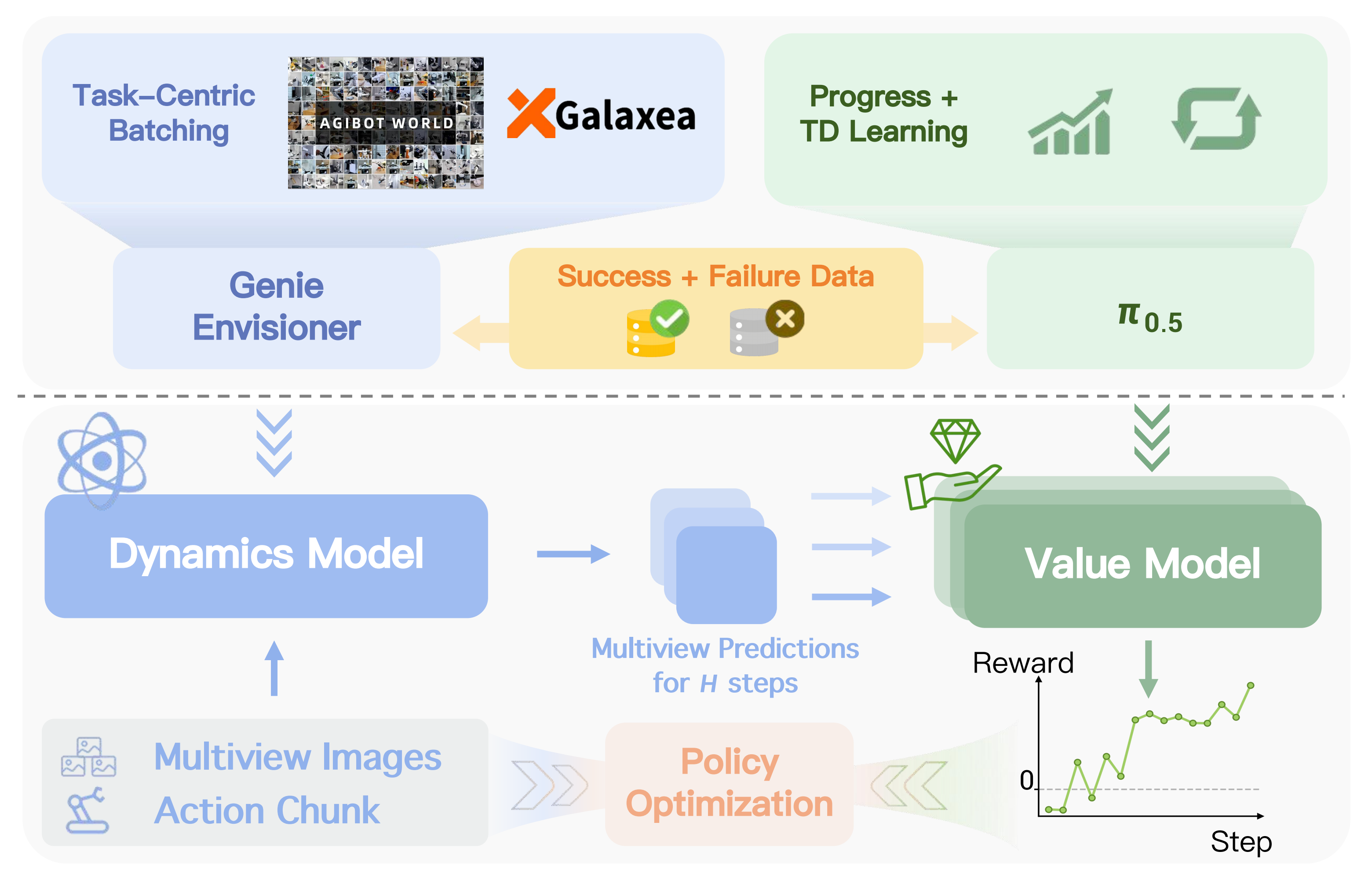
首先,如果想实现可控动力学模型,即要在强化学习中可靠地模拟未来状态,需要满足两个基本要求:
- 生成延迟不能高得难以接受,否则会成为强化学习系统吞吐量的瓶颈
- 生成的状态不仅在视觉上要合理可信,还必须与条件动作保持一致
因此,作者将动力学模型初始化为预训练的 Genie Envisioner [59](即 GE-base 变体),该模型继承了 LTX-Video [28] 的架构优势,并在生成质量与推理速度之间实现了良好的折中
相比之下,诸如Cosmos [1] 等先进世界模型在合成 25 帧多视角观测时需要超过 10 分钟,而 GE 只需不到 2 秒即可达到同样的预测时域,带来约 300 倍的加速。这样的生成效率是支撑实用强化学习训练的关键支柱
不过
- 尽管具有较高的效率,GE-Base 最初是以文本为条件进行建模,而不是以细粒度的机器人动作为条件。为了赋予该模型精确的动作可控性,使其能够进一步应用于特定任务场景,作者还在大规模动作标注数据集『包括 AgibotWorld [11] 和 Galaxea [43]』上对模型进行了进一步优化——通过加入一个额外的轻量级动作编码器来实现
此外,与原始 GE-base训练相比,作者在上下文帧上施加更强的噪声,以提升在遇到运动模糊和视觉伪影(这些现象可能同时出现在真实录制和合成数据中)时的生成鲁棒性 - 然而,当在每次优化迭代中将多种任务和视觉域混合在同一 batch 中时,在异构动作数据上微调可控世界模型容易出现不稳定和收敛缓慢的问题
作者又通过一种任务中心的批处理策略(Task-Centric Batching)来缓解这一问题,其中,每个 batch 只从少量任务中采样,但在同一任务下覆盖更多与不同动作相关的样本
直观来看,该批处理策略在 batch 优化中更侧重同一场景下的动作多样性,而不是场景多样性,从而有助于提升动作可控性
在实验上,采用该策略既提高了特定任务微调的效率(见表 V),也带来了更显著的策略提升(见表 IV)
在上述设计的加持下,作者的动力学模型能够提供快速且忠实的多视角状态预测,从而支撑自我改进闭环
总之,动力学模型在来自俯视和双侧手腕相机的多视角RGB 观测(192 × 256) 上运行,并以未来动作为条件
- 且采用Flow Matching 目标进行训练。对于时间步调度,作者遵循SD3 [21] 采用Logit-Normal 分布,定义为
,其中m = 0.2 和s = 1.0
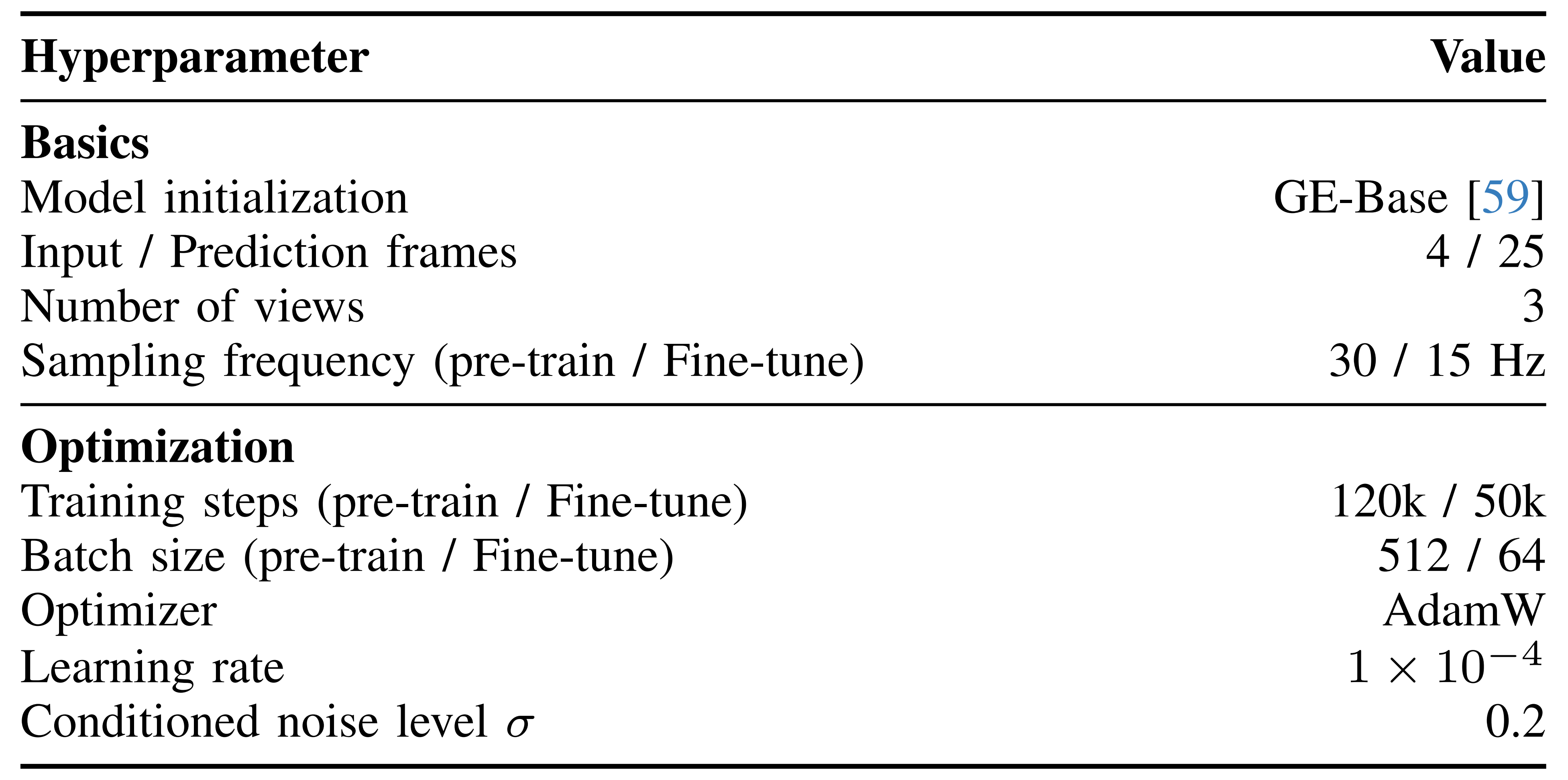
优化采用AdamW,在经过2k 步线性预热后使用恒定学习率1 × 10−4- 在推理过程中,作者使用欧拉离散形式求解流动常微分方程(flow ODE),并采用50 个去噪步骤。更多配置见表VIII
其次,实现进度值模型
基于想象的策略改进在关键上依赖于一种与奖励相关的信号,该信号在(i) 长时间范围内是稠密的,并且(ii) 对接触密集操控中的细微失败敏感
因此,作者学习一个价值估计器V,它将感知到的观测映射为一个用于对想象轨迹进行评分的标量值。V 是从一个预训练的VLA 策略π0.5 [8] 参数化得到的,这带来了两个优势
- 首先,π0.5 已在广泛的机器人数据集上进行过训练,因此具备可自然迁移到价值估计上的机器人中心理解
- 其次,该策略的骨干网络兼容多视角输入,而通用的VLM 多数是在单视角图像上开发的,并未进行此类适配
在训练方面
- 作者使用一个简单的时间进度估计作为目标,来对V 进行 warm-start,这使得作者的价值模型具备对单调时间结构的粗略理解
其中的一个回合中的当前时间步。尽管进度回归提供了稠密的信号,但它往往过于平滑,并且对失败不敏感,尤其是在接触丰富的设置中,此时执行错误在视觉上可能非常细微
- 为了解决这一问题,作者将进度损失与时间差分(Temporal-Difference, TD)学习[77] 结合起来,后者同时利用成功示范和失败轨迹来建立一个能够区分成功与错误的价值函数
其中是时间折扣因子,并且
在中间步骤中被设为0,而在成功和失败的序列末尾分别被设为
作者的最终价值学习目标简单地将两个项结合起来,以分别利用这两项所提供的学习稳定性和误差敏感性
价值模型的训练配置如表 IX 所示
- 对于每个任务,总训练大约需要 50k 个步骤。在前 10k 个步骤中,作者只施加进度估计损失;
而在剩余步骤中,作者同时施加进度估计损失和时间差分学习(Temporal Difference learning)损失- 值得注意的是,在用于策略优化的自改进循环过程中,动力学模型和价值模型都保持冻结

1.2.2 基于真实世界经验的策略预热
在进行 on-policy 改进之前,作者首先利用离线收集的数据对学习过程进行热启动,这会将策略锚定在目标任务上物理上合理的行为分布上,从而避免在后续阶段出现不加选择的探索
- 数据构成和训练目标主要遵循 RECAP [2]
对于每个任务,作者在离线收集的数据上对预训练策略(即 π0.5[8])进行微调,这些数据由专家示范、包含成功与失败的策略 rollout,以及有人为干预的纠正组成 - 在训练过程中,策略以优势信号为条件,该优势信号由我们学习得到的价值模型 V——见下述式 (2)进行标注
其中将视作离线录制视频中的后续帧
不同于RECAP 中同时为离线数据和策略 rollout 标注优势,作者宣称,在他们的早期实验中作者发现,同时为这两种数据源分配优势的效果反而比仅对 rollout 数据标注优势更差
因此,在作者的实验中,只对 rollout 数据分配学习得到的优势,而专家数据和人工纠正数据则直接与最优优势(记为 )配对
)配对
由此,该预热阶段使策略能够吸收不同质量的动作数据,这对于随后基于在线试错进行学习的自我改进阶段至关重要
策略首先主要按照离线RL 方法[2] 进行预热,但有两个不同之处
- RECAP 将带标签的优势离散为二元分箱,而作者发现将优势以均匀间隔离散为10 个分箱能取得更高的效果
- 此外,直接将人类示范分配到最高分箱,同时仅对策略回滚数据进行标注,可以稳定学到的行为
这两点差异可能源于这样一个事实:作者的模型初始化π0.5 并未在优势条件化的设定下进行预训练,这与RECAP 实例化时的离线RL 预训练π∗0.6 不同
随后,作者按照表X 中列出的配置启动自我改进循环

1.2.3 利用世界模型进行自我改进:迭代地执行 rollout 阶段和训练阶段
在经过离线数据预热阶段获得优势条件化能力之后,作者将组合式世界模型作为一个交互式模拟器来改进策略
该自我改进循环如图 5 所示,迭代地执行 rollout 阶段和训练阶段『RISE 的自我改进循环。学习流程包含两个阶段。上:Rollout 阶段。在给定最优优势作为提示的情况下,rollout 策略与世界模型交互以生成 rollout 数据。下:训练阶段。随后在优势条件化方案下训练行为策略,以生成合适的动作』
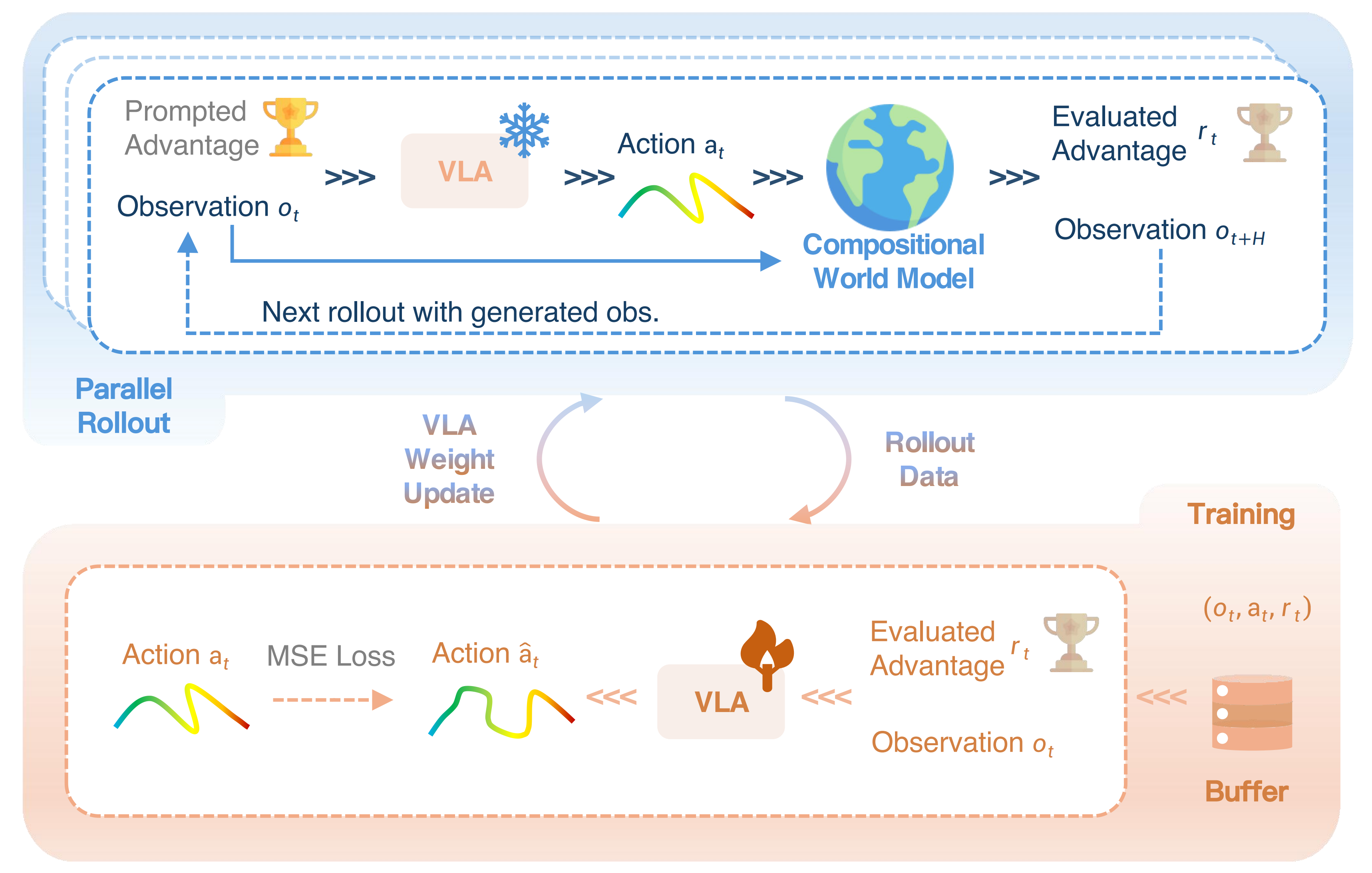
- Rollout 阶段
首先,作者从预热离线数据集中采样一个初始状态,除了进行观察外,作者还通过最优优势值来提示策略 ,以推断出具有积极意图的动作
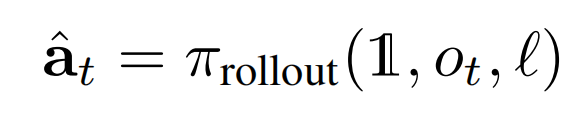
将视觉历史和动作提案输入到动力学模型中,以合成接下来的H 个视觉状态
然后,由价值模型对这些想象状态进行评估,计算所提动作的实际优势,记为
作者将定义为用于推断最优动作的提示优势,而表示评估得到的优势,反映了生成动作的真实效用。该优势被离散化为N 个均匀的区间,用于表示当前状态下该动作的实际优势
——————
为了在在线训练过程中拓宽状态覆盖范围,想象状态也会作为后续rollout 的输入。从每个离线状态出发,这种连续交互最多进行两次,以考虑生成式视频模型的误差累积问题[38]
rollout 策略参数通过指数滑动平均(Exponential Moving Average, EMA)[40]进行更新,由行为策略权重混合得到
RISE 与先前同样将世界模型作为学习环境的研究[44, 93, 13] 的一个主要区别在于,RISE 避免了为获取奖励而显式模拟终止状态,而是直接为所提动作产生以片段为单位的优势 - 训练阶段
策略内 rollout 数据组成批量样本用于优化策略
给定评估得到的优势之间的距离
这样一来,策略即可同时从想象中发现的高优势成功案例和低优势失败案例中学习
且为防止在探索过程中出现灾难性遗忘,作者还将离线标注数据混入批量数据中
无论是线下还是线上的experiences都在统一的学习目标下得到充分利用
其在通用 flow-matching 准则 [7,8] 下进行优化
总之,对于任务特定数据,世界模型和策略在每个任务中共享同一套离线数据,其中包括专家示范以及包含成功和失败的策略 rollout(执行轨迹)
唯一的区别在于,策略学习还会额外使用一部分 DAgger 数据来丰富恢复模式,这与RECAP [2] 的做法类似
1.3 实验评估
作者进行了全面的实验评估,以研究 RISE 的能力
具体而言,作者关注以下问题:
- 对比分析:RISE 是否优于现有主流的 RL 和 IL 方法,尤其是在真实世界的灵巧操作和长时序任务中
- 设计选择:如何将世界模型有效地集成到 RL 闭环中,以及每个模块的设计是否都是必不可少的?
1.3.1 真实环境实验设置
作者的真实环境实验采用一台双臂 7 自由度(7-DoF)的 AgileX 机器人,并具有关节绝对控制能力『每个机械臂具有 6 个自由度(DoF)以及一个1 自由度的夹爪,并在腕部安装了摄像头。为提供全局视角,在两臂中间上方约 0.75 m 处居中放置了一台顶视摄像头。控制频率设置为 30 Hz。左上:在积木分类与背包装填任务中使用 Gripper A,而在需要更高精度的关盒任务中使用 Gripper B』
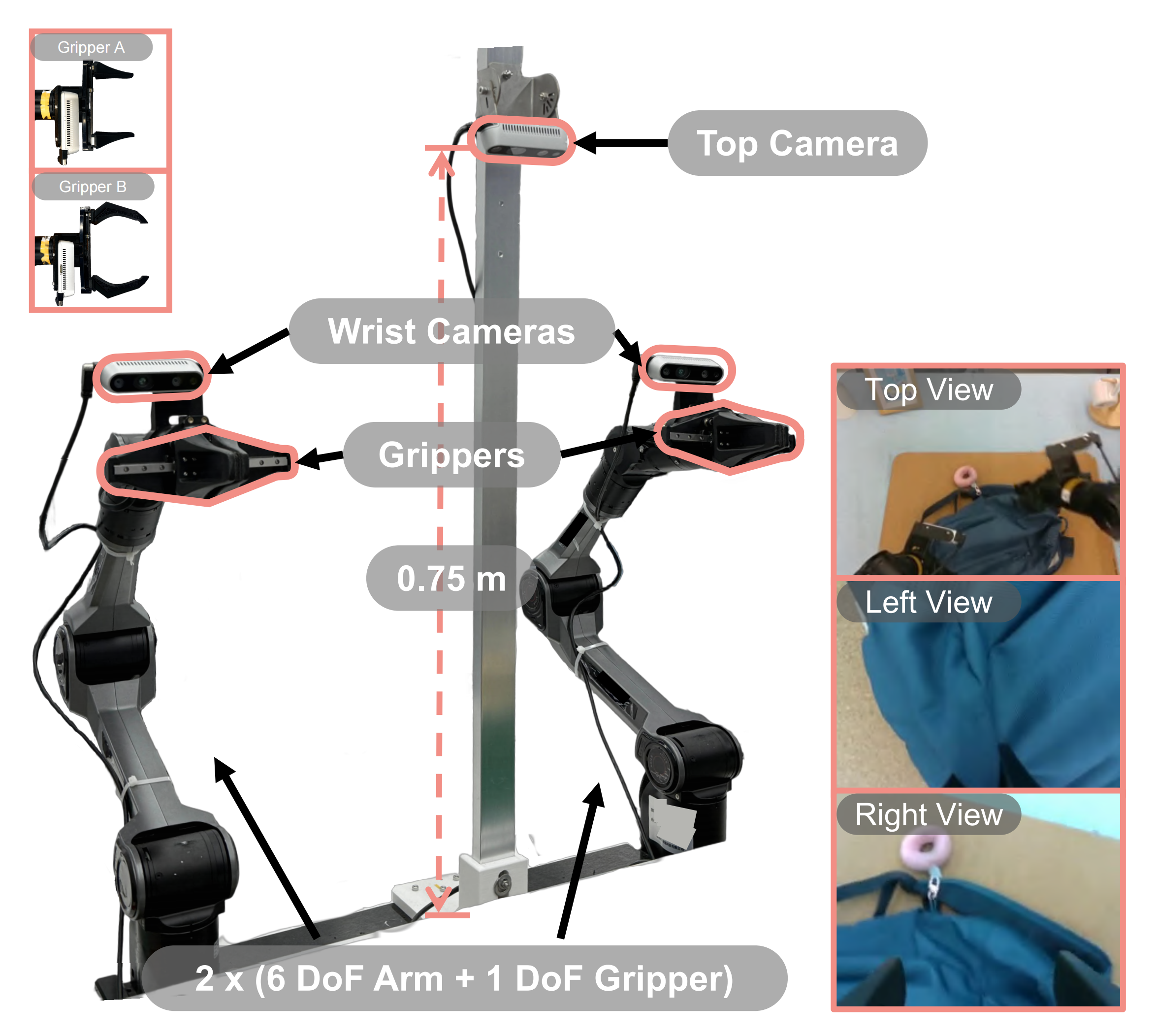
基准测试了三个高灵巧、长时序任务,包括:
- 动态砖块分拣:要求机器人在运行中的传送带上对多种类型的砖块进行动态分拣,如图2(a)所示
- 背包装填:该任务在顺应性和可变形物体操作方面具有挑战性,如图2(b)所示
- 纸箱封装:该任务要求双臂精确协调以完成对一个杯子的打包,如图2(c)所示
- Dynamic Brick Sorting 包含 3063 条人类示范数据和 610条策略 rollout 数据
- Backpack Packing 包含 2478 条人类示范数据和 507 条策略 rollout 数据
- Box Closing 包含2286 条人类示范数据、524 条策略 rollout 数据以及 540条人类纠正(DAgger)数据
作者指出,他们在实践中最具挑战性的任务(即动态砖块分拣)上进行了消融实验。在所有变体中,超参数保持不变。机器人的详细设置和评估指标见附录
1.3.2 主要结果
首先,对于基线
作者将 RISE 与最先进的模仿学习和强化学习基线方法进行对比评测。每一种对比方法的开发都使用了相近的计算预算。各个变体的实现细节和数据构成在附录中有详细说明
- π0.5 [8]: 一种在网络规模多机器人数据上预训练并在任务示范上微调的最新VLA 模型
- π0.5+ DAgger [73,45]: 一种交互式基线,利用同策略的人类纠正来减轻暴露偏差
- π0.5+ PPO [75]: 一种通过PPO 微调VLA 权重的标准在线强化学习基线
- π0.5+ DSRL [80]: 一种通过强化学习优化扩散潜在噪声来操控冻结VLA、具有高样本效率的方法
- RECAP [2]: 一种基于优势条件的离线RL方法[23, 48],最初建立在一个专有的预训练策略之上,即π0.6 [2]——详见此文《π∗0.6——通过RL框架RECAP微调流式VLA π0.6:先基于演示数据做离线RL预训练,再在线RL后训练(与环境自主交互,从经验数据中学习,且必要时人工干预)》
不过,由于无法获得π0.6,作者在与本方法相同的参数调节和离线数据语料上,将该方法应用于π0.5
整篇论文中,包括基线和作者策略在内的所有策略变体都基于预训练的π0.5 进行实例化,以公平评估各种后训练策略的有效性
- π0.5 : 该变体仅在作者的人类示范语料库上通过模仿学习进行微调,而不使用策略展开或人类纠正数据
- DSRL:整体训练配置遵循 DSRL [80] 的官方实现。作者使用 π0.5 模型 [8] 作为基础策略
为使策略适应,作者初始化重放缓冲区包含从基础策略中采集的10 条轨迹,该基础策略是使用标准高斯噪声w ∼N (0, I) 进行采样得到的,随后通过70 个在线控制回合来微调该行为- PPO:作者通过一个预训练的 π0.5 模型来初始化 PPO 策略。在 rollout 阶段,作者采样真实世界轨迹,并保留按照 RLinf [91] 计算得到的推理噪声和对数概率
在训练过程中,作者利用这些存储的推理噪声来生成带梯度的 on-policy 动作
随后,将这些动作与新旧对数概率及优势值结合起来,计算 PPO 损失。PPO 策略根据该 PPO 损失进行更新- DAgger:由于硬件限制无法进行高频率模式切换,作者采用单次干预协议:当即将发生失败时,由人工监督者接管并完成该回合
这一变体通过模仿学习,在专家示范数据和额外的人类纠正数据上进行训练- RECAP:该变体遵循策略预热阶段的步骤,详见第 XI-D 节
其次,对于结果
作者在表I 中给出了定量结果,报告了成功率和分阶段得分,评估标准在附录中提供
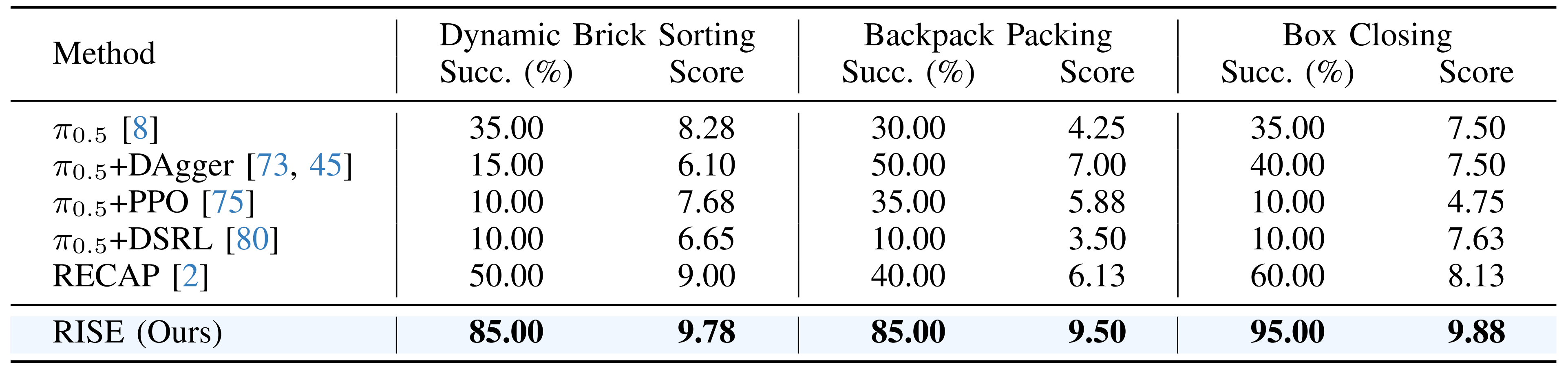
- 尽管π0.5 展现了初步能力,但作者观察到在线自适应(PPO,DSRL)带来了严重的不稳定性。这导致了性能退化,例如在动态砖块排序任务中性能出现明显下降(35 % →10 % )
- 至于RECAP 验证了优势条件化的收益,但仍不及RISE。值得注意的是,作者宣称,他们的方法在背包打包任务中取得了40 % 的优势,同时将砖块和盒子任务的成功率分别提高到85 % 和95 %
总体而言,作者宣称,RISE 在所有任务上显著优于所有 RL 和 IL 基线,并在成功率方面始终保持较高水平
1.3.3 消融研究
第一,在强化学习训练过程中,应当分配多少比例的离线数据?
- 仅依赖在线经验往往会因为离线示范与在线rollout 之间的分布偏移而导致性能崩溃
为了解决这一问题,作者研究了在训练中混合使用离线数据的最优比例,以保持性能
如 Table II 所示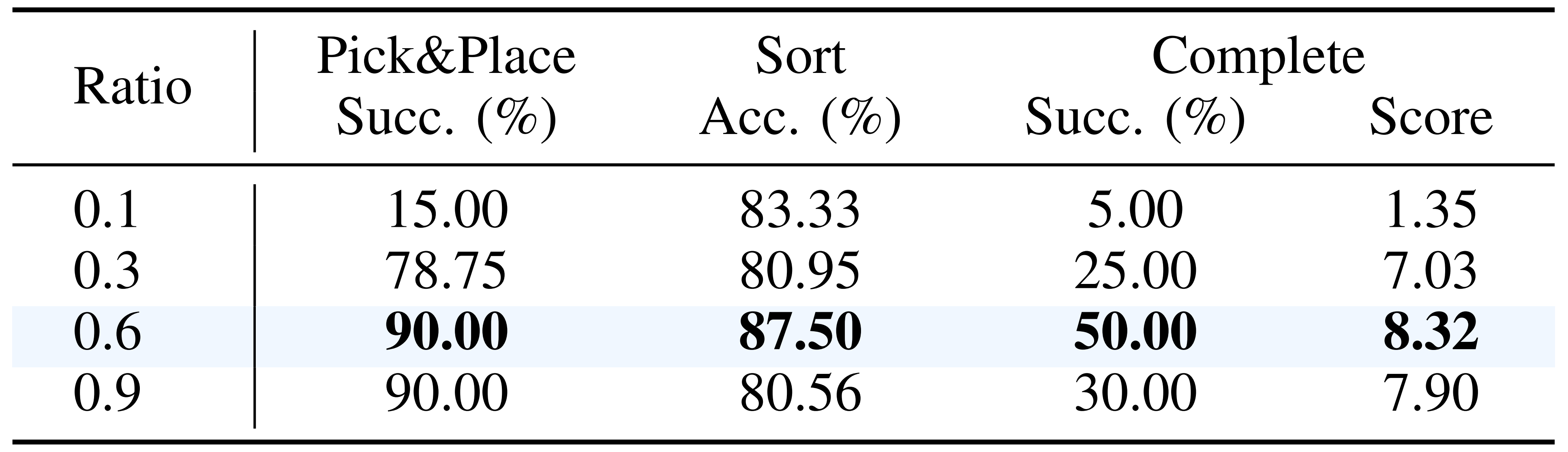
- 作者观察到一个明显的权衡。当离线数据比例过低(例如0.1)时,成功率骤降至 5%
作者认为,这验证了他们的假设:在大量在线数据的冲击下,如果离线数据保留不足,会导致灾难性遗忘
相反,当离线数据比例过高(例如 0.9)时,性能同样会下降
作者将其归因于过度正则化:此时策略被过度限制在离线数据分布附近,从而削弱了其探索和发现更优策略的能力
第二,VLA 模型能否从世界模型生成的在线动作或状态中获益?
为验证这一点,作者评估了三种变体:
- 一种是不含在线信号的基线模型
- 一种包含在线仅包含动作的版本
- 以及同时包含二者的完整RISE
作者宣称,他们的结果证实了在线信号的必要性
正如表III 所示,引入在线动作将成功率从35 % 提升到40 %
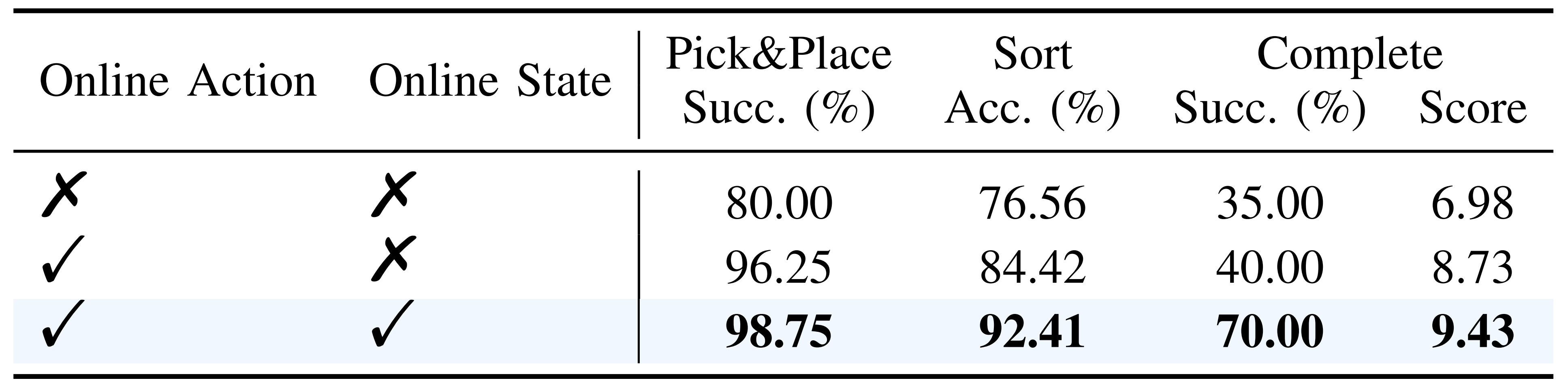
- 我们将这一改进归因于扩展的动作空间探索;不同于离线数据中通常呈现的静态行为模式,在线rollouts 允许VLA 区分高优势动作和次优失败行为
- 关键的是,引入在线状态进一步将成功率提升至70 % 。这表明,动态生成的在线状态提供了更丰富、几乎无界的训练分布,从而克服了固定离线数据集的局限性
第三,各模块对RISE 的影响有多大?
表IV 中的定量结果突出了每个组件的关键性
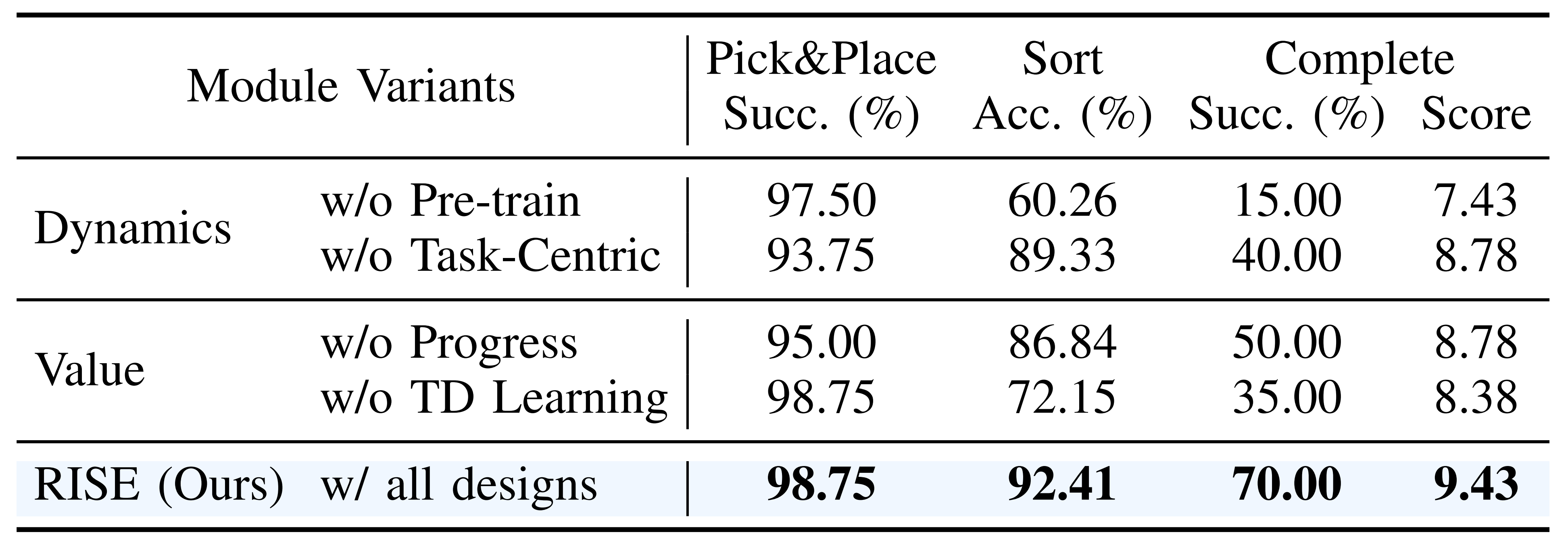
- 在动力学模型中,移除视觉预训练会使排序准确率降低32.15 %,并使完成降至15%,这凸显了视觉先验的必要性
缺乏以任务为中心的设计会使完成率降低30%,从而印证了过滤干扰因素的有效性 - 对于价值模型,移除进度回归会使成功率下降20%,这确认了稠密信号的重要性
此外,省略TD学习会导致表现下降35%,表明其在稳健估计中发挥着关键作用
第四,动力学模型有多可靠?
作者将 RISE 与 Cosmos [1] 和Genie Envisioner (GE) [59] 进行比较,以考察其可靠性
作者使用 PSNR、SSIM [82]、LPIPS [95] 和 FVD[79] 来评估生成质量,并采用光流端点误差(EPE)[93] 来衡量动作可控性
- 从定量结果来看,表 V 在相同实验设置下凸显了 RISE 相对于所有基线方法的优越性
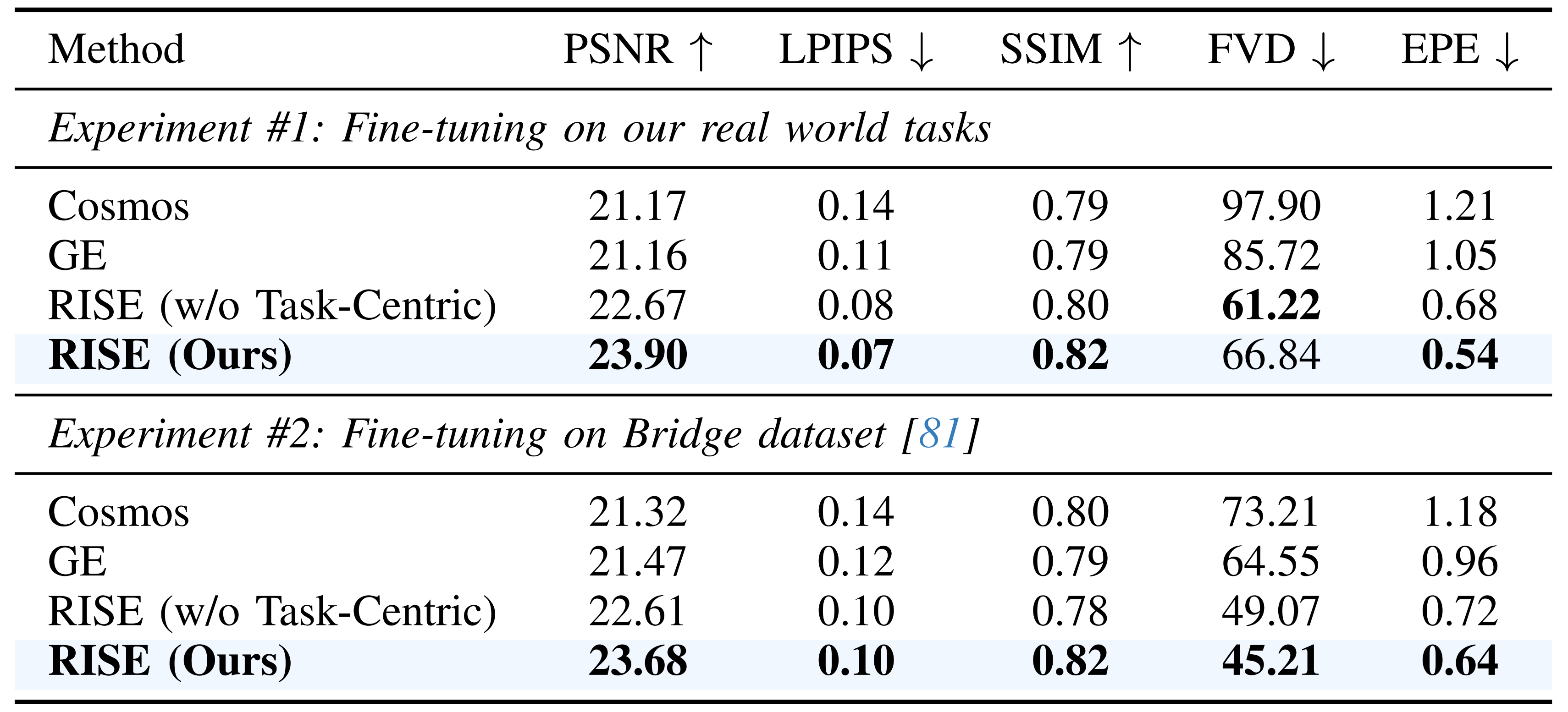
值得注意的是,EPE 的显著降低验证了作者的任务中心预训练策略,说明在训练中优先关注动作条件下的动力学,相比仅进行标准像素级重建,更能有效提升模型的运动感知能力 - 从定性结果来看(图6)

基线方法普遍存在模糊和运动学不一致等问题,而 RISE 则能够以较高保真度生成物理上合理的动力学过程。更多对比结果见附录
// 待更

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 28
28 0
0- 0



 已为社区贡献77条内容
已为社区贡献77条内容

所有评论(0)