EZREAL:增强多变能见度下的远距离目标零样本户外机器人导航
《EZREAL:动态能见度下远距离目标的零样本户外机器人导航增强》提出了一种创新系统,解决了户外导航中远距离微小目标识别和间歇性遮挡两大难题。该系统采用多尺度图像块金字塔技术增强目标感知,通过层级显著性融合放大微小目标信号;同时设计显著性驱动的航向记忆机制,在目标被遮挡时基于历史观测保持导航方向。实验表明,该系统能检测150米外的语义目标,在混合遮挡场景下恢复成功率达73.3%,显著优于现有方法。
1. 论文基本信息 (Bibliographic Information)
-
标题 (Title): EZREAL: Enhancing Zero-Shot Outdoor Robot Navigation toward Distant Targets under Varying Visibility
-
作者 (Authors): Tianle Zeng, Jianwei Peng, Hanjing Ye, Guangcheng Chen, Senzi Luo, Hong Zhang (IEEE Fellow)
-
机构 (Affiliation): 南方科技大学机器人与计算机视觉重点实验室 (Shenzhen Key Laboratory of Robotics and Computer Vision, SUSTech)
-
来源 (Source): arXiv:2509.13720v1 [cs.RO]
-
发表时间 (Year): 2025年9月
-
摘要速读 (Abstract Summary): 论文针对户外机器人导航中的“远距离微小目标”和“间歇性遮挡”两大难题,提出了一种名为 EZREAL 的系统。该系统利用多尺度图像块金字塔(Multi-scale image tile hierarchy)来增强对微小目标的感知,并利用显著性驱动的航向记忆(Saliency-driven heading maintenance)来应对目标忽隐忽现的情况。实验表明,该系统能检测到150米外的语义目标,并在遮挡下保持航向 。
2. 核心概念字典 (Concept Dictionary for Beginners)
这里先解释几个核心术语:
-
Zero-Shot Object Navigation (ZSON, 零样本目标导航):
-
通俗解释: 传统的机器人需要先看几千张“椅子”的照片才能认出椅子。ZSON 则是告诉机器人“去找一把椅子”,机器人依靠它对语言和图像的通用理解能力(通常借助大模型),就能在从未见过的环境中找到从未训练过的“椅子”。不需要针对特定物体进行重新训练 。
-
-
CLIP (Contrastive Language-Image Pre-training):
-
通俗解释: 一个超级“翻译官”模型,它能理解图片内容和文字描述之间的匹配程度。比如给它一张图和文字“无线电塔”,它会给出一个分数,分数越高表示图片里越可能有无线电塔。本文用它来给图像块打分 。
-
-
Saliency (显著性):
-
通俗解释: 图像中哪里最“显眼”、最符合我们寻找的目标。在本文中,显著性越高,意味着那个区域越像我们要找的目标。
-
-
Occlusion (遮挡):
-
通俗解释: 目标被树木、建筑物挡住了。户外导航中,目标一会儿看得到,一会儿看不到,这叫“动态能见度” (Dynamic Visibility) 。
-
-
Odometry (里程计):
-
通俗解释: 机器人通过计算轮子转了多少圈或者惯性传感器,来估算自己走了多远、转了多少度。
-
3. 整体概括 (Overview)
3.1 研究背景与动机 (Why?)
现有的 ZSON 方法在室内表现不错,但在户外大规模环境中经常“翻车”。主要有两个原因(文中称为“耦合挑战”):
-
目标太远太小: 户外目标可能在100米开外,普通深度相机(Depth Sensor)根本扫不到那么远,无法生成深度地图。在RGB图像上,这些目标往往只占极少的像素,特征非常模糊 。
-
能见度不稳定: 远处的物体很容易被路灯、树木遮挡。如果机器人只盯着眼前看,一旦目标被挡住,机器人就会迷失方向 。
3.2 核心贡献 (What?)
EZREAL 系统提出了一个闭环解决方案:
-
感知层面: 不把图片整体缩放,而是切成不同大小的块(Tile),利用“层级显著性融合”技术,像放大镜一样把微弱的目标信号放大 。
-
导航层面: 既然目标容易消失,机器人就记住目标上次出现的方向和特征(关键帧),在看不见目标时依靠“记忆”和“推算”继续行走,或者主动四处张望寻找目标 。
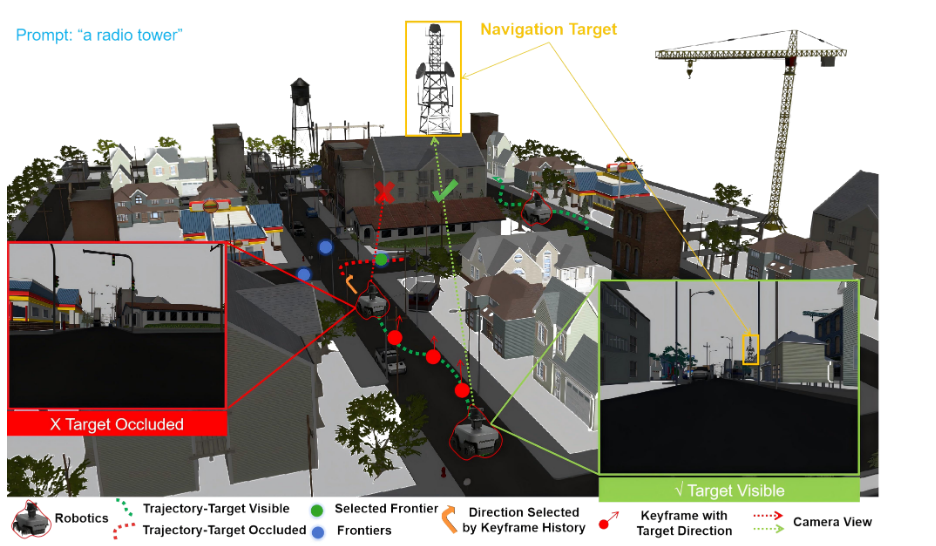
内容描述: 这张图展示了一个机器人在复杂街道寻找“无线电塔 (radio tower)”的场景。
左侧插图 (Target Occluded): 红色框显示机器人视角,目标被建筑物挡住,红点路径表示此时机器人依赖记忆导航。
右侧插图 (Target Visible): 绿色框显示目标可见,绿点路径表示机器人直接根据视觉导航。
核心含义: 图中的红色叉号和绿色对勾路径表明,EZREAL 能够在目标可见(绿色虚线)和被遮挡(红色虚线)的混合状态下,依然规划出正确的路径到达远处的黄色目标区域 。
4. 方法详解 (Methods)
EZREAL 系统像一个精密的闭环系统,分为“怎么看”(感知)和“怎么走”(导航)。
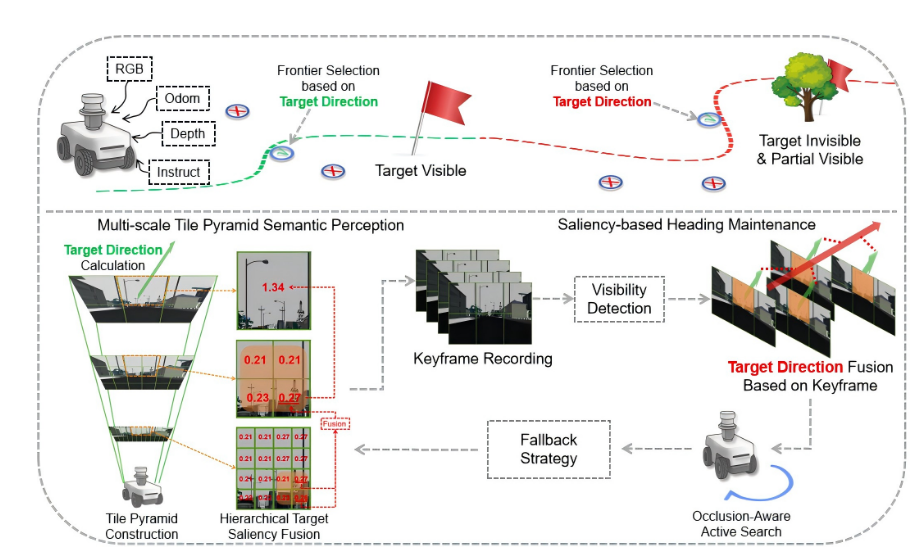
内容描述: 图片分为上下两部分。上半部分是机器人在环境中的运动逻辑(看到目标直走,看不到就找)。下半部分是技术细节:左下角是图像金字塔(把图片切碎),右侧是关键帧记录(像胶卷一样存下历史画面)。
核心含义: 展示了感知模块(左下)如何将处理后的方向信息传递给导航模块(右上),以及导航模块如何在丢失目标时利用关键帧(右中)进行回溯和主动搜索 。
4.1 多尺度瓦片金字塔感知 (Multi-scale Tile Pyramid Perception)
这是为了解决“看不清”的问题。
-
原理: 系统不直接缩放整张图片(那样会让小目标彻底消失),而是把原始分辨率的图片切成不同层级的“瓦片” (Tiles)。
-
$T_1$ (精细层): $8 \times 12$ 个小块。
-
$T_2$ (中等层): $4 \times 6$ 个中块。
-
$T_3$ (粗糙层): $2 \times 3$ 个大块 。
-
对齐: 这些块是严格对齐的,1个粗块对应4个中块,1个中块对应4个细块 。
-
-
计算过程 (Hierarchical Fusion):
-
打分: 用 CLIP 模型计算每个瓦片与文本(如“radio tower”)的相似度分数 $s$。
-
融合公式: 并不是简单的加和,而是利用方差 (Variance) 来放大信号。如果一组子瓦片里分数差异很大(说明有一个突出的目标),就给它加权。
从 $T_1$ 到 $T_2$ 的融合公式为:
$$s_{2}^{\prime}=s_{2}+\beta\cdot\sum_{Top-2}s_{1}$$
其中 $\beta = base^{\hat{\sigma}}$,$\hat{\sigma}$ 是子瓦片分数的标准差。这意味着:如果局部区域对比度强烈(很有可能是目标),信号就会被指数级放大;如果是平坦的背景,信号就被抑制 。
-
-
目标方向计算:
在最粗糙的一层找到分数最高的块,计算其中心像素 $p_{img}$,结合相机内参 $K$ 和外参 $T_{c \rightarrow w}$,算出目标在世界坐标系中的方向向量 $\hat{d}_{target}$:
$$\hat{d}_{target}=T_{c\rightarrow w}K^{-1}\tilde{p}_{img}$$
4.2 基于显著性的航向维护 (Saliency-based Heading Maintenance)
这是为了解决“看不见”的问题。
-
关键帧记录 (Keyframe Recording):
当目标清晰可见时,机器人会拍下一张“快照”(关键帧),记录下:
-
最显著区域的特征及分数。
-
当时的目标方向。
-
机器人当时的位置 。
-
-
可见性检测 (Visibility Detection):
机器人怎么知道自己“看没看见”?它计算分数的稀疏比 (Sparsity Ratio) $r_l$:
$$r_{l} = \frac{\max(s_l^{(i)})}{\sum s_l^{(i)} + \epsilon}$$
如果最高分非常突出($r_l$ 高)且分布稀疏($\sigma_l$ 高),系统就判定“目标可见”;否则判定为“被遮挡” 。
-
方向融合 (Direction Fusion): 当目标看不见时,机器人不会瞎猜,而是把历史关键帧里记录的方向拿出来,做一个加权平均(权重取决于当时看得清不清楚和时间远近),算出一个平滑的航向 $d_{target}$ 继续走 。
-
主动搜索 (Active Search): 如果一直盲走也不是办法。当长时间看不见时,机器人会走到推测的方向,然后原地转头(Look-around)扫描。它会将眼前看到的画面与记忆中的关键帧进行比对,只有特征和语义都匹配上了,才确认“我又找到它了” 。
5. 数据集与评测指标 (Datasets and Evaluation Metrics)
为了验证效果,作者使用了以下设置:
5.1 数据集
-
TartanAir (仿真数据集): 这是一个高保真的视觉SLAM数据集。作者选取了不同距离(10m, 25m, 50m, 100m, 150m)的场景,包含各种天气和光照条件 。
-
真实世界 (Real-world): 在深圳南方科技大学校园内进行测试,场地范围达 $350m \times 450m$,包含复杂的遮挡物 。
5.2 评测指标
为了公平评价,作者定义了专门的指标:
-
惩罚角度误差 (Penalized Angular Error, $e_{avg}$):
用来衡量“看”得准不准。
$$e_{avg} = \frac{1}{N} \sum_{i=1}^{N} \begin{cases} |\hat{\theta}_i - \theta_i|, & \text{if detected} \\ \pi, & \text{otherwise} \end{cases}$$
如果检测到了,算角度误差;如果没检测到(漏检),直接罚一个最大误差 $\pi$ (180度)。这个指标同时考察了准确率和召回率 。
-
导航指标:
-
RSR (Recovery Success Rate): 恢复成功率。目标消失后,机器人能重新找回目标的概率 。
-
RPL (Recovery Path Length): 恢复路径长度。找回目标走了多远,越短越好 。
-
SR (Success Rate): 最终到达目标的成功率 。
-
6. 实验结果 (Results)
6.1 远距离感知能力
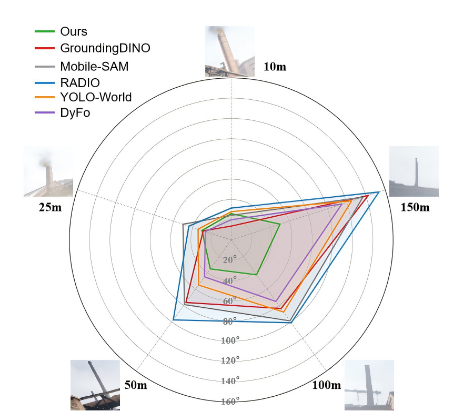
内容描述: 一个雷达图,不同方向代表不同距离(10m到150m),轴向数值代表误差(越靠近中心越好)。
分析: 在近距离(10m-25m),大家表现都差不多。但到了 50m 以外,其他方法(如 GroundingDINO, YOLO-World)的线条迅速向外扩散(误差变大),因为它们无法识别变成了几个像素的小点。而 EZREAL (绿色线) 始终保持在中心附近,说明它在150m的超远距离依然精准 。
6.2 动态能见度下的导航
在表格 II 中,作者对比了机器人应对“短时遮挡”、“长时遮挡”和“混合遮挡”的能力。
-
关键数据: 在混合遮挡场景下,EZREAL 的 RSR (找回率) 达到了 73.3%,而对比方法 RayFront 只有 41.7%。这证明了“航向记忆”和“主动搜索”策略极其有效 。
6.3 真实世界测试
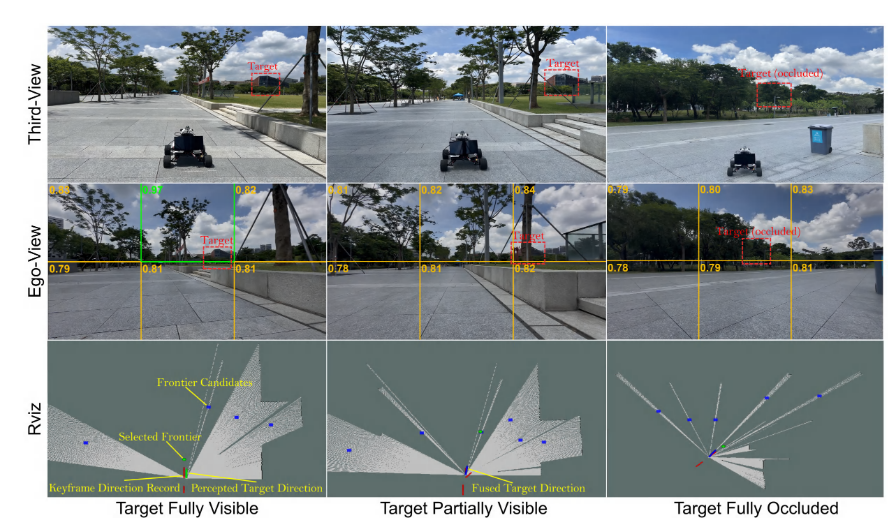
内容描述: 展示了三个阶段。
左列(可见):RViz视图中绿色箭头指向目标,机器人确信方向。
中列(部分可见):目标只露出一角,机器人利用红色箭头(记忆方向)辅助。 * 右列(全遮挡):目标完全被树挡住,RViz中显示机器人正在基于蓝色点(融合后的推测方向)继续探索 。
结论: 证明系统在现实中能像人类一样,即使暂时看不到目标,也能凭印象大概知道在哪。
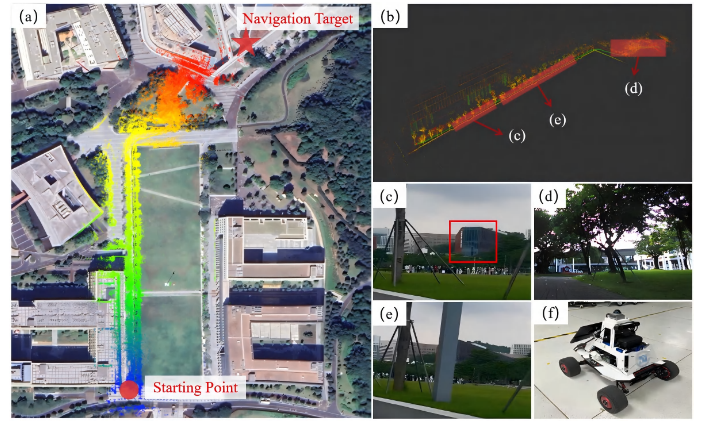
内容描述: 卫星地图上的彩色轨迹。
分析: 机器人从起点(红点)出发,穿越了长长的草坪和道路,最终到达远处的图书馆(红星)。轨迹颜色的变化(热力图)对应了构建的地图高度,证明机器人在长距离下依然能保持稳定的航向 。
7. 结论与局限性 (Conclusion & Critique)
7.1 总结
EZREAL 成功解决了一个痛点:户外机器人既要看得远(超分辨率感知),又要记得住(抗遮挡导航)。 它不需要深度地图,仅靠 RGB 图像就能在几百米的尺度上通过文字指令导航,且计算量小,适合移动机器人部署 。
7.2 局限性与思考
尽管表现出色,论文也坦诚了不足之处 :
-
依赖初始观测: 导航开始时必须先看一眼目标。如果一开始就看不见,机器人就不知道往哪走。
-
长时遮挡: 如果遮挡时间过长(比如超过10秒),累积误差会让搜索范围变得太大,导致效率降低。
-
路径规划简单: 目前只是基于方向的探索(Frontier Exploration),还没有结合复杂的环境语义(比如“顺着路走”这种高级推理)。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 12
12 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)