从感知到行动:空间人工智能智体和世界模型
26年2月来自AtlasPro AI的论文“From Perception to Action: Spatial AI Agents and World Models”。虽然大语言模型已成为智能推理和规划的主流方法,但它们在符号领域的成功并不容易转化为物理世界的成功。空间智能,即感知三维结构、推理物体关系以及在物理约束下行动的能力,是一种正交能力,对具身智体至关重要。现有综述要么孤立地探讨智体架构
26年2月来自AtlasPro AI的论文“From Perception to Action: Spatial AI Agents and World Models”。
虽然大语言模型已成为智能推理和规划的主流方法,但它们在符号领域的成功并不容易转化为物理世界的成功。空间智能,即感知三维结构、推理物体关系以及在物理约束下行动的能力,是一种正交能力,对具身智体至关重要。现有综述要么孤立地探讨智体架构,要么孤立地探讨空间领域,均未提供一个统一的框架来连接这些互补的能力。提出一个统一的三轴分类体系,将智体能力与跨尺度的空间任务联系起来。至关重要的是,将空间基础(对几何和物理的度量理解)与符号基础(将图像与文本联系起来)区分开来,并认为仅凭感知本身并不能赋予主体性。分析揭示与这些轴相对应的三个关键发现:(1)层级记忆系统(能力轴)对于长时程空间任务至关重要。 (2)GNN-LLM集成(任务轴)是结构化空间推理的一种很有前景的方法。(3)世界模型(尺度轴)对于从微观到宏观空间尺度的安全部署至关重要。最后,总结六大挑战,并概述了未来研究方向,其中包括需要建立统一的评估框架以规范跨领域评估。
如图所示,提出一种三轴分类法,将智体能力映射到不同空间尺度下的空间任务需求。该框架的理解方式如下:每种方法同时占据三个轴上的位置。任务轴描述系统执行的操作,能力轴描述系统的推理和行动方式,尺度轴描述空间粒度。这种结构能够对各种方法进行详细比较,并识别设计空间中尚未充分探索的区域。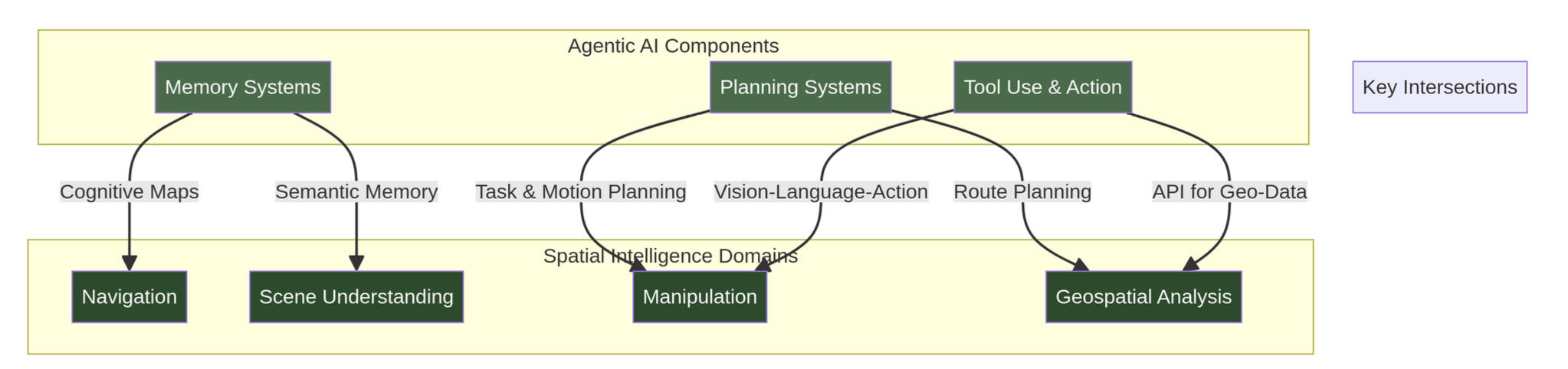
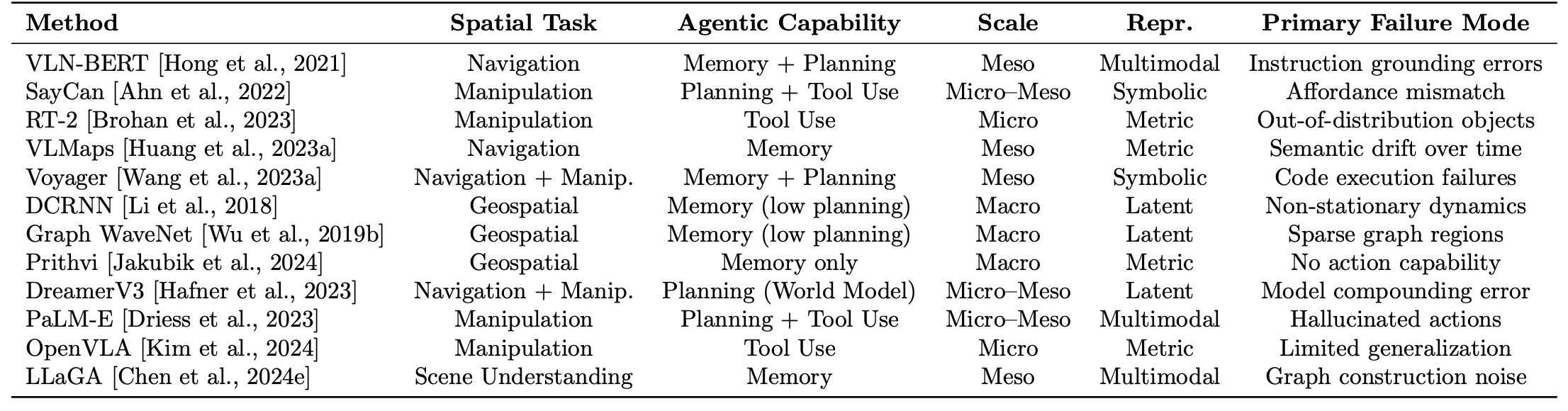
至关重要的是,强制执行结构规范:每种方法都明确映射到所有三个轴上(如表所示),从而确保特征描述的一致性,并实现方法间的直接比较。
记忆系统:智体如何记忆空间信息?
记忆使智体能够积累和检索经验知识。认知科学提供基础理论[Tulving, 1972, Baddeley, 2003],而重点在于使人工智能系统能够维持持久空间知识的计算实现。核心挑战是:智体如何才能在不同的时间跨度和尺度上维持持久的空间知识?
短期记忆。上下文学习[Brown et al., 2020, Dong et al., 2022, Olsson et al., 2022, Akyurek et al., 2023, Dai et al., 2023a, Min et al., 2022, Xie et al., 2022, Wei et al., 2023, Chan et al., 2022]使模型能够通过提示中的示例来适应新任务。这种机制无需参数更新即可实现快速适应,利用注意机制对已提供的演示进行条件化。工作记忆机制[Graves et al., 2014, Weston et al., 2015, Sukhbaatar et al., 2015, Kumar et al., 2016, Santoro et al., 2016, Graves et al., 2016, Munkhdalai & Yu, 2017]支持推理过程中信息的临时存储,从而支持超越单次前向传递能力的多步骤计算。为了说明它与空间记忆的区别:短期记忆可能保留“去厨房找一个红杯子”的指令,而空间记忆则编码厨房本身的布局,包括门的位置和橱柜的位置。
长期记忆。检索增强生成(Lewis et al., 2020, Packer et al., 2023, Guu et al., 2020, Borgeaud et al., 2022, Asai et al., 2023, Trivedi et al., 2023, Izacard et al., 2023, Shi et al., 2023, Ram et al., 2023, Khandelwal et al., 2020)实现知识的持久化,突破了上下文的限制。MemGPT(Packer et al., 2023)引入用于扩展对话的分层记忆管理。AMEM(Xu et al., 2025)为LLM提供智体记忆。MemEvolve(Zhang et al., 2025a)实现了智体记忆的元进化。向量数据库[Johnson et al., 2019, Malkov & Yashunin, 2018, Douze et al., 2024, Wang et al., 2021, Pinecone, 2023, Jegou et al., 2011, Ge et al., 2014, Guo et al., 2020]为记忆检索提供了高效的相似性搜索,使智体能够访问相关的过往经验。
上下文记忆。上下文记忆存储特定的经验和事件(发生了什么),使智体能够从过去的交互中学习[Blundell et al., 2016, Pritzel et al., 2017, Banino et al., 2018, Ritter et al., 2018, Fortunato et al., 2019, Botvinick et al., 2019, Gershman and Daw, 2017]。这种记忆对于空间智体至关重要,因为它们必须记住访问过的位置、遇到的物体以及成功执行的动作序列[Savinov et al., 2018, Chaplot et al., 2020c, Fang et al., 2019, Ramakrishnan et al., 2022, Ye et al., 2021, Chen et al., 2022f]。与空间记忆的区别至关重要:上下文记忆记录的是“机器人下午3点撞到了椅子”,而空间记忆则编码的是持续存在的几何结构(椅子相对于桌子的位置),它独立于任何特定事件。
空间记忆。上下文记忆记录的是事件发生的地点,而空间记忆则编码的是地点本身的结构:独立于特定事件而持续存在的几何和拓扑关系。专门的实现方式包括认知地图[Tolman, 1948, O’Keefe & Nadel, 1978, Moser, 2008, Hafting, 2005]、拓扑表示[Kuipers, 2000, Choset & Nagatani, 2001, Thrun, 1998, Kuipers & Byun, 1991]和度量地图[Thrun, 2005, Durrant-Whyte & Bailey, 2006, Cadena, 2016, Mur-Artal, 2015, Mur-Artal & Tard ́os, 2017, Campos, 2021, Engel, 2017, 2014]。空间记忆的神经方法包括神经SLAM [Chaplot et al., 2020c,d,b, 2021]、语义地图 [Huang et al., 2023a, Henriques & Vedaldi, 2018, Shah et al., 2023b,a, Huang et al., 2023c, Chen et al., 2023a] 和场景图 [Armeni et al., 2019, Rosinol et al., 2020, Hughes et al., 2022, Gu et al., 2024, Wu et al., 2021, Wald et al., 2020, Kim et al., 2019]。
空间失效模式。仅具备语言能力的智体在空间任务中表现不佳,是因为它们缺乏基于语境的空间表征。这些失败可归纳为四类,每一类都可追溯到特定的表征缺陷:(1)空间幻觉,即智能体描述不可能的空间配置(GPT-4V 在 SpatialBench 测试中 40% 的空间关系问题上表现不佳 [Chen et al., 2024a])。(2)参考系混淆,即智体混淆以自我为中心的坐标系和以他人为中心的坐标系(VLN 智体由于参考系错位而出现 15-20% 的错误率 [Anderson et al., 2018c])。(3)尺度不敏感,即智体无法区分微观、中观和宏观尺度推理(当物体尺度与训练数据不同时,SayCan 的affordance模型会失效 [Ahn et al., 2022])。(4)时间漂移,即空间记忆在较长时间内退化(VLMaps 在 100 多个步骤后未更新地图时出现语义漂移 [Huang et al., 2023a])。
规划系统:智体如何进行空间范围规划?
规划将目标分解为可执行的动作序列,从而实现复杂任务的完成[Russell & Norvig, 2010; Ghallab et al., 2004; LaValle, 2006; Fikes & Nilsson, 1971; Sacerdoti, 1974; Nau et al., 2003; Bylander, 1994; Geffner & Bonet, 2013; Kautz & Selman, 1992; Helmert, 2006]。其核心挑战在于:智体如何在考虑几何约束的情况下,将空间目标分解为可行的动作序列?
思维链推理。逐步推理[Wei et al., 2022, Kojima et al., 2022, Wang et al., 2022, Zhou et al., 2023a, Fu et al., 2023, Chen et al., 2023c, Zhang et al., 2023, Khot et al., 2023, Diao et al., 2023]能够实现结构化的问题分解。自洽性[Wang et al., 2022]通过多条推理路径提高可靠性。零样本思维链[Kojima et al., 2022]无需论证即可进行推理。
基于树的搜索。思维树(Tree of Thoughts)[Yao et al., 2023a, Long, 2023, Xie et al., 2023, Hulbert et al., 2024]通过有意识的搜索探索多个解决方案分支。思维图(Graph of Thoughts)[Besta et al., 2023, Lei et al., 2023, Yao et al., 2024]支持具有任意连接的更复杂的推理结构。RAP[Hao et al., 2023, Shridhar et al., 2020b, Zhao et al., 2024, Liu et al., 2024d]将推理与行动结合在一个规划框架中。蒙特卡洛树搜索的各种变体[Silver et al., 2016, Schrittwieser et al., 2020, Browne et al., 2012, Anthony et al., 2017, Silver et al., 2017, 2018, Vinyals et al., 2019, Kocsis & Szepesvári, 2006]提供了具有理论保证的原则性探索。
分层规划。LLM-Planner[Song et al., 2023]支持具身智体的少样本基础规划。Inner Monologue[Huang et al., 2022a]通过内部对话提供反馈驱动的规划。HiPlan[Li et al., 2025b]引入基于LLM的分层规划。分层强化学习方法[Nachum et al., 2018, Vezhnevets et al., 2017, Bacon et al., 2017, Pertsch et al., 2021, Kulkarni et al., 2016, Gupta et al., 2019, Levy et al., 2019, Li et al., 2020, Zhang et al., 2021b, Sutton et al., 1999]将任务分解为具有时间抽象的子任务。
任务和运动规划。 TAMP [Garrett et al., 2021, Kaelbling & Lozano-Pérez, 2011, Toussaint, 2015, Dantam et al., 2016, Srivastava et al., 2014, Garrett et al., 2020, Driess et al., 2020] 将符号规划与连续运动规划相结合,应用于机器人领域。该方法融合了符号推理的表达能力和几何规划的精确性。
从符号规划到神经规划。上述方法依赖于显式的符号表示,这些表示提供了形式化的保证:规划可以根据前提条件进行验证,并且可以通过检查中间状态来诊断故障。最近的研究探索了大型神经模型是否能够涵盖这些能力,用学习的、泛化能力更强的表示来替代手工构建的结构,但代价是牺牲可解释性。这种转变引发关于规划可验证性和故障恢复的根本性问题,尤其是在安全关键型应用中,理解规划失败的原因与了解规划是否成功同样重要。
基于语言模型的规划。近期研究直接使用语言模型进行规划[Huang et al., 2022b, Valmeekam et al., 2023a, Song et al., 2023, Silver et al., 2024, Liu et al., 2023a, Kambhampati et al., 2024, Valmeekam et al., 2023b]。SayCan[Ahn et al., 2022]将语言模型与可供性联系起来。Code as Policies[Liang et al., 2023b]生成可执行的机器人代码。ProgPrompt[Singh et al., 2023]使用程序提示进行任务规划。一个关键的警告:LLM 生成的规划无法进行形式化验证,以确保其正确性和安全性。与保证前提条件满足的传统规划器不同,LLM 规划器可能会生成流畅但物理上不可能的动作序列。对于安全至关重要的应用(例如,手术机器人、自动驾驶车辆),这一局限性尤其令人担忧,因为规划失败会造成不可逆转的后果。
空间规划失败模式。基于 LLM 的规划器在以下情况下会失败:(1)违反几何约束:在 BEHAVIOR-1K 数据集 [Li et al., 2023a] 上,由于忽略碰撞的规划,LLM 规划器的成功率仅为 12%。(2)未满足动作前提条件:VirtualHome [Puig et al., 2018] 显示,35% 的 LLM 规划因违反前提条件而失败。 (3)长期信用分配失败:ALFRED [Shridhar,2020a] 的成功率随着任务范围从 5 步增加到 20 步而从 65% 下降到 18%。(4)缺乏动态重规划:RoboTHOR [Deitke,2020] 在出现意外障碍时表现出 40% 的失败率。
工具使用与操作:智体如何将语言与几何联系起来?
工具使用通过外部接口和物理操作扩展了智体的能力[Osiurak & Badets,2016;Vaesen,2012;Beck,2011;Shumaker,2011;Seed & Byrne,2010;Tomasello,1999]。核心挑战在于:如何将基于语言的推理转化为精确的几何操作?区分两个截然不同的类别:在数字空间中运行并具有确定性结果的符号工具(API、代码执行、数据库查询),以及在连续物理空间中运行并具有随机动力学和不可逆后果的物理操作(抓取、移动、操作)。这种区分至关重要,因为符号工具的错误可以被捕获并重试,而物理操作的错误可能会造成永久性损坏。
API 集成。 Toolformer [Schick et al., 2023, Parisi et al., 2022, Mialon et al., 2023, Nakano et al., 2021] 支持自监督工具学习。Gorilla [Patil et al., 2023, Li et al., 2023e, Tang et al., 2023] 专注于 API 调用和检索增强。ToolLLM [Qin et al., 2024a, Hao et al., 2024, Qin et al., 2024b, Xu et al., 2023d] 提供全面的工具使用基准测试。TaskMatrix [Liang et al., 2023c, Lu et al., 2023, Yang et al., 2023b] 将基础模型与数百万个 API 连接起来。 TALM [Parisi et al., 2022] 通过工具使用来增强语言模型。其他工具使用框架包括 HuggingGPT [Shen et al., 2023b]、ViperGPT [Surís et al., 2023]、Visual ChatGPT [Wu et al., 2023a] 和 MM-REACT [Yang et al., 2023b]。
代码生成。PAL [Gao et al., 2023, Wang et al., 2024a] 使用代码进行推理。Code as Policies [Liang et al., 2023b] 从语言生成可执行的机器人代码。 Codex [Chen et al., 2021a]、StarCoder [Li et al., 2023f]、CodeLlama [Roziere et al., 2023]、DeepSeek-Coder [Guo et al., 2024a] 和 WizardCoder [Luo et al., 2023] 提供代码生成功能。ProgPrompt [Singh et al., 2023] 使用程序提示进行机器人编程。自调试 [Chen et al., 2023f, Olausson et al., 2023] 通过迭代改进来提高代码质量。
ReAct 架构。ReAct [Yao et al., 2023b,c, Liu et al., 2023c] 将推理与动作执行交错进行,使智体能够在行动之前进行思考。反思(Reflexion)[Shinn et al., 2023b,a, Kim et al., 2023]通过语言强化来促进自我反思和改进。这些架构构成了许多空间智体的基础。
物理动作。对于具身智体而言,工具的使用扩展到物理操作[Zeng et al., 2021, Brohan et al., 2022, 2023, Shridhar et al., 2022, 2023]。动作基元(Action primities)[Dalal et al., 2021, Nasiriany et al., 2022, Mandlekar et al., 2021]提供了可重用的构建模块。技能库 [Wang et al., 2023a, Lynch et al., 2020, Pertsch et al., 2021, Singh et al., 2021, Xu et al., 2023a] 实现了组合式动作。
关键要点:智体组件
- 记忆系统必须具有明确的空间性:认知地图、语义地图和场景图在空间任务中优于通用检索方法。
- 具有几何基础的层级规划弥合了高级语言目标和低级运动指令之间的差距。
- 工具的使用通过代码生成、API 调用和学习到的动作基元连接了语言和动作。
- 主要失败模式源于缺乏空间基础:幻觉、参考系混淆和违反几何约束。
智体必须具备哪些空间能力才能在物理世界中运行?
导航:智体如何在空间中移动?
导航要求智体感知环境、规划路径并执行朝向目标的运动[Bonin-Font et al., 2008, DeSouza & Kak, 2002, Thrun, 2002, Siegwart et al., 2011, Choset et al., 2005, Cadena et al., 2016, Engel et al., 2017, Fuentes-Pacheco et al., 2015, Durrant-Whyte & Bailey, 2006, Konolige et al., 2008]。
视觉-语言导航。 VLN 任务要求智体在视觉环境中遵循自然语言指令 [Anderson,2018c,Qi,2020,Krantz ,2020,Fried,2018,Chen ,2022h,Shah ,2023b,Hong ,2020,Chen ,2021c,An ,2023,Wang ,2019b,Ma ,2019a,Tan ,2019,Zhu ,2020,Hong ,2021,Qiao ,2022,Chen ,2022g,Guhur ,2021]。 R2R [Anderson et al., 2018c] 引入了该范式。REVERIE [Qi et al., 2020] 增加了对象接地功能。VLN-CE [Krantz et al., 2020] 扩展到了连续环境。
对象-目标导航。对象导航需要导航到对象类别 [Batra et al., 2020, Chaplot et al., 2020a, Majumdar et al., 2022, Gadre et al., 2022, 2023, Dorbala et al., 2022, Ramakrishnan et al., 2022, Ye et al., 2021, Khandelwal et al., 2022, Yokoyama et al., 2024]。 ZSON [Majumdar ,2022] 支持零样本导航。CLIP-Nav [Dorbala ,2022] 使用视觉语言模型。CoW [Gadre ,2022] 使用基于 CLIP 的轮式系统进行语义导航。
视听导航。音频线索引导 SoundSpaces 中的导航 [Chen ,2020,2022d,Gan ,2020,Chen ,2021b,Majumdar ,2022,Chen ,2022c]。这种模式对于寻找发声目标至关重要。
具身问答。EQA需要导航来回答问题[Das et al., 2018b, Gordon et al., 2018, Wijmans et al., 2019, Yu et al., 2019, Das et al., 2018a, Gordon et al., 2019]。3D问答[Azuma et al., 2022, Ma et al., 2022a, Hong et al., 2023b, Chen et al., 2024f, Zhu et al., 2023, Huang et al., 2024b]则扩展到对3D场景的理解。
场景理解:智体如何感知3D结构?
场景表征决定了智体可以计划哪些行动:更丰富的表征能够使其对物体的功能和空间限制进行更复杂的推理。
场景理解包括感知三维几何形状[Hartley&Zisserman,2003;Szeliski,2022;Forsyth&Ponce,2011;Marr,1982;Prince,2012;Faugeras,1993]、识别物体[Krizhevsky,2012;He,2016;Simonyan&Zisserman,2015;Szegedy,2015;Huang,2017;Tan&Le,2019]以及推理空间关系[Johnson,2015;Krishna,2017;Lu,2016;Xu,2017;Zellers,2019]。
神经场景表征。 NeRF [Mildenhall ,2020,Barron ,2022,Mu ̈ller ,2022,Park ,2019,Mescheder ,2019,Barron ,2023,Martin-Brualla ,2021,Tancik ,2022,Chen , 2022a,Fridovich-Keil ,2022] 彻底改变了 3D 重建。 Mip-NeRF [Barron et al., 2022] 处理多尺度渲染。三维高斯溅射[Kerbl,2023;Luiten,2023;Fan,2024;Yu,2024;Huang,2024a]可实现实时渲染。与SLAM[Sucar,2021;Zhu,2022;Keetha,2024;Bird,2025;Teed&Deng,2021;Teed,2024;Mur-Artal&Tardós,2017;Campos,2021]的集成可实现在线重建。
点云处理。点云方法[Qi et al., 2017a,b, Wang et al., 2019c, Thomas et al., 2019, Zhao et al., 2021, Wu et al., 2019a, Liu et al., 2019, Ma et al., 2022b]处理原始3D数据。Point-BERT[Yu et al., 2022b]、Point-MAE[Pang et al., 2022]、PointGPT[Chen et al., 2024b]、Point-Bind[Guo et al., 2023]和Uni3D[Zhou et al., 2024]引入了自监督预训练。 3D 对象检测 [Shi et al., 2019, Qi et al., 2019, Shi et al., 2020, Chen et al., 2023g, Lang et al., 2019, Yin et al., 2021, Fan et al., 2022, Zhou & Tuzel, 2018] 支持场景解析。
深度估计。单目深度估计[Godard et al., 2019, Ranftl et al., 2021, 2020, Yang et al., 2024c, Fu et al., 2024b, Bhat et al., 2021, Li et al., 2022, Yuan et al., 2022, Eigen et al., 2014]能够从单幅图像中获取几何信息。Depth Anything[Yang et al., 2024c]实现了强大的零样本迁移。Metric3D[Yin et al., 2023]能够恢复度量深度。
语义分割。语义分割 [Long et al., 2015, Chen et al., 2017, Kirillov et al., 2023, Peng et al., 2023, Chen et al., 2023b, Xie et al., 2021, Cheng et al., 2022, Jain et al., 2023]可以实现场景解析。 SAM [Kirillov et al., 2023] 提供及时的分割。开放词汇方法 [Ghiasi et al., 2022, Liang et al., 2023a, Chen et al., 2023a, Ding et al., 2022, Xu et al., 2023b, Zhou et al., 2022] 可以实现零样本识别。
与智体规划的连接。这些表示本身并非目的,而是下游规划的输入。NeRF 为碰撞检测提供几何基础。语义地图告知规划器哪些区域可通行。场景图编码了任务分解所需的关联结构。表示的选择直接限制了智体可以生成和验证的规划方案。
操作:智体如何与物体交互?
对于智体而言,操作是规划与物理现实的交汇点:每个动作都会产生不可逆的后果,从而限制所有未来的可能性。
操作需要理解对象affordance [Gibson, 1979, Do et al., 2018, Nagarajan et al., 2019, Fang et al., 2018, Zhu et al., 2015, Myers et al., 2015],规划丰富的接触交互 [Chitnis et al., 2020, Kroemer et al., 2021],并执行精确的操作运动命令 [Argall et al., 2009, Billard et al., 2008, Ravichandar et al., 2020]。
视觉-语言-行动模型。 VLA模型[Brohan,2022,2023;Team,2024;Kim,2024;Black,2024;Driess,2023;Collaboration,2023;Zitkovich,2023;Padalkar,2023]直接将视觉观察和语言指令映射到动作。RT-1[Brohan,2022]引入大规模机器人学习。RT-2[Brohan,2023]展示了网络规模的预训练迁移。RT-X[Collaboration,2023]实现跨具身学习。Octo[Team,2024]提供了一种开放的通用策略。 OpenVLA [Kim et al., 2024] 提供开源的 VLA。π0 [Black et al., 2024] 引入了用于机器人学习的流匹配。RoboCat [Bousmalis et al., 2023] 展示了自我改进能力。
模仿学习。行为克隆 [Pomerleau, 1988, Chi et al., 2023, Zhao et al., 2023b, Chi et al., 2024, Florence et al., 2022, Mandlekar et al., 2021, 2022] 从示范中学习。扩散策略 [Chi et al., 2023] 将扩散模型应用于动作生成。ACT [Zhao et al., 2023b] 使用 Transformer 进行动作分块。从游戏中学习 [Lynch,2020] 可以实现非结构化学习。
强化学习。用于操作的强化学习 [Kalashnikov,2018;Levine,2018;Haarnoja,2018;Schulman,2017;Fujimoto,2018;Lillicrap,2016;Mnih,2015,2016] 可以实现从交互中学习。QT-Opt [Kalashnikov,2018] 可扩展到真实世界的抓取操作。SAC [Haarnoja,2018] 提供高效的样本学习。
仿真环境。仿真平台 [James et al., 2020、Yu et al., 2020、Makoviychuk et al., 2021、Savva et al., 2019、Kolve et al., 2017、Gu et al., 2023、Deitke et al., 2023、Xiang et al., 2020、Mu et al., 2021、Ehsani et al. al., 2021, Szot et al., 2021, Li et al., 2021, Shen et al., 2021] 提供训练环境。 RLBench [James et al., 2020] 提供多种操作任务。 Meta-World [Yu et al., 2020] 提供多任务基准测试。 Isaac Gym [Makoviychuk et al., 2021] 支持 GPU 加速仿真。
长时程任务组合。现实世界的操作很少是孤立的动作。制作三明治需要打开抽屉、取出面包、关上抽屉、打开冰箱等等,每个动作都会为后续步骤创造前提条件。这种顺序依赖结构将操作与导航区分开来:走错路可以纠正,但破了的鸡蛋却无法复原。目前的基准测试,例如 BEHAVIOR-1K [Li et al., 2023a] 和 ARNOLD [Gong et al., 2023],明确地测试了这种组合结构,结果表明,随着任务时程从 5 步增加到 20 步,成功率会急剧下降(通常下降 50% 或更多)。
地理空间分析:智体如何在行星尺度上进行推理?
对于在城市或行星尺度上运行的主体而言,这些方法能够帮助他们推断在数小时到数年内发生的现象,这需要与房间尺度任务截然不同的规划视野。
地理空间分析需要处理卫星影像[Zhu et al., 2017, Ma et al., 2019b, Yuan et al., 2020a, Zhang et al., 2016, Tuia et al., 2016, Camps-Valls et al., 2014]、构建城市动态模型[Bibri & Krogstie, 2017, Batty, 2013, Kitchin, 2014, Jiang et al., 2021]以及推断地理关系[Egenhofer & Franzosa, 1991, Cohn a&d Renz, 2008, Randell et al., 1992]。
遥感基础模型。Prithvi [Jakubik et al., 2024] 提供基于协调的Landsat Sentinel-2数据训练的地理空间基础模型。 SatMAE [Cong et al., 2022] 引入用于卫星图像的掩码自编码器。Satlas [Bastani et al., 2023] 实现大规模地理空间理解。GeoAI [Janowicz et al., 2020, Mai et al., 2023] 对该领域进行调研。CROMA [Fuller et al., 2024] 和微估计 [Chi et al., 2022] 推进遥感分析。
时空图神经网络 (STGNN) 通过图结构表示来模拟复杂的城市动态 [Jin et al., 2023, Atluri et al., 2018, Wang et al., 2020, Jiang & Luo, 2022, Balachandar et al., 2025]。其核心直觉是,空间位置(交叉路口、传感器、社区)构成一个图,其中边编码邻近性或连通性,每个节点的状态随时间演变。通用公式结合空间消息传递(信息如何在连通位置之间流动)和时间卷积(每个位置的状态如何随时间演变)。DCRNN [Li et al., 2018] 将交通建模为图上的扩散,捕捉拥堵在路网中扩散的直观过程,就像热量在材料中扩散一样。STGCN [Yu et al., 2018] 通过三明治结构结合图卷积和时间卷积。Graph WaveNet [Wu et al., 2019b] 解决一个关键限制:预定义的邻接矩阵(基于物理道路连接)可能会遗漏重要的依赖关系。即使没有直接的道路连接,两个相距遥远的地点也可能由于通勤模式的共享而具有很强的相关性。Graph WaveNet 从数据中学习图结构。AGCRN [Bai,2020;Song,2020] 通过自适应模块引入节点特定的模式。ASTGCN [Guo,2019,2021] 添加空间和时间注意机制。GMAN [Zheng,2020;Park ,2020] 使用图多重注意机制和变换注意机制来处理长程依赖关系。STGRAT [Choi,2022] 推动该领域的发展。
城市计算。城市计算[Zheng et al., 2014, Yuan et al., 2020b, Zheng, 2015]将人工智能应用于城市尺度的挑战。ST-LLM[Liu et al., 2024a]和UniST[Yuan et al., 2024]将语言模型与时空推理相结合。交通预测[Li et al., 2018, Yu et al., 2018, Wu et al., 2019b]和需求预测[Geng et al., 2019, Yao et al., 2018, Zhang et al., 2017]是其关键应用。
关键要点:空间领域
• 导航已从点目标范式发展到语言引导和零样本范式,这得益于视觉-语言融合
• 场景理解受益于神经隐式表征(NeRF、3DGS)与语义基础的结合
• 视觉-语言-动作(VLA)模型正在变革操控方式,将网络规模的知识迁移到机器人控制中
• 地理空间分析越来越多地使用基础模型和图神经网络(GNN)进行行星级推理
图神经网络:智体如何推理关系?
GNN 如何对空间关系进行建模,以及消息传递机制及其在微观和宏观尺度空间推理中的应用。
为什么要在空间智体综述中纳入 GNN?答案在于它们的归纳偏置。Transformer 将输入视为无序集合(或具有学习位置编码的序列),因此它们无法感知空间数据中固有的关系结构。相比之下,GNN 将关系显式编码为边,从而为空间约束提供了一种自然的表示:场景中的物体、道路网络中的交叉路口或机器人手臂中的关节。这种关系偏好使得图神经网络(GNN)在连接结构与节点内容同等重要的任务中尤为有效[Kipf and Welling, 2017, Veliˇckovi ́c et al., 2018, Xu et al., 2019, Hamilton et al., 2017, Wu et al., 2020b,a, Zhou et al., 2020, Zhang et al., 2020, Li et al., 2016, Defferrard et al., 2016, Bruna et al., 2014]。
消息传递框架。通用的图神经网络(GNN)公式遵循消息传递范式[Gilmer et al., 2017, Scarselli et al., 2009, Battaglia et al., 2018, Xu et al., 2018, Morris et al., 2019]。从几何角度来看,这可以理解为每个节点“聆听”其邻居节点,收集它们的信息,然后根据所听到的信息更新自身的表示,这很像机器人关节通过感知相邻关节的位置来更新其对机械臂构型的理解。
GNN-LLM集成。一个关键的概念性见解:图可以作为基于LLM智体的外部空间记忆。虽然LLM在语义推理方面表现出色,但它们缺乏持久的、结构化的空间关系表示。通过将场景图、道路网络或物体配置编码为图,并通过GNN进行处理,智体可以保持跨推理步骤的持久空间状态,并克服上下文窗口的限制。新兴研究将图神经网络(GNN)与大语言模型(LLM)相结合,用于结构化空间推理[Chen et al., 2024e, Tang et al., 2024, Fatemi et al., 2023, 2024, Gowda et al., 2025, Ye et al., 2024, Zhao et al., 2023a, Huang et al., 2024c]。图指令调优[Zhang et al., 2024b]进一步增强了这种能力。LLaGA[Chen et al., 2024e]提供了语言-图对齐。GraphGPT[Tang et al., 2024]通过语言模型实现图推理。
几何深度学习。几何深度学习[Bronstein et al., 2021]为非欧几里得域上的空间推理提供了理论基础。等变网络 [Cohen & Welling,2016,Fuchs ,2020,Satorras ,2021,Weiler & Cesa,2019,Thomas ,2018,Kondor ,2018] 通过以下方式尊重空间对称性:图转换器 [Ying ,2021,Dwivedi ,2023,Ramp ́aˇsek ,2022,Kreuzer ,2021,Chen ,2022e] 将注意与图结构结合起来。 E3NN [Batzner et al., 2022]、几何消息传递 [Brandstetter et al., 2022] 和 SchNet [Schu ̈tt et al., 2017] 推进等变架构。
世界模型:智体如何预测未来?
世界模型,它使智体能够模拟其行为的未来结果。
为了使智体能够在物理世界中安全有效地行动,它必须能够预测其行为的后果。世界模型提供了这种预测能力,通过学习世界运行的模型来实现规划和预见[LeCun, 2022, Schmidhuber, 2015, Matsuo et al., 2022, LeCun, 2024b,a, Moerland et al., 2023, Sutton, 1991, Deisenroth and Rasmussen, 2011]。这对于空间安全至关重要,因为它使智体能够避免物理上危险或不可逆的状态。
潜在动力学模型。核心思想很简单:世界模型并非直接预测未来图像(计算成本高且容易出现累积误差),而是将观测数据压缩到一个紧凑的潜空间中,并在该空间中预测动态变化。编码器将高维观测数据(例如图像)压缩到一个紧凑的潜状态。然后,动态模型根据当前状态和动作预测下一个潜状态,从而有效地在压缩空间中模拟未来。解码器可以在需要时重构观测数据。
基于模型的强化学习。Dreamer [Hafner,2020,2019b] 引入了潜在想象,通过循环状态空间模型实现样本高效的学习。 DreamerV2 [Hafner et al., 2021] 利用离散潜状态实现与人类Atari游戏机相当的性能。DreamerV3 [Hafner et al., 2023] 通过符号对数预测,展示单一算法在跨领域的应用能力。从Dreamer到DreamerV3的演进展现了一条关键的研究轨迹:从连续潜状态到离散表示以提高精度,最终发展到无需修改即可掌握多个领域的单一、高度泛化的模型。至关重要的是,DayDreamer [Wu et al., 2023b] 展示该方法在机器人领域的巨大潜力,成功地将仿真中学习的世界模型迁移到物理机器人上,并且只需在真实世界数据上进行少量微调。这为弥合仿真与现实之间的差距提供一条充满希望的途径。PlaNet [Hafner et al., 2019a,b] 开创了潜在动力学学习的先河。 MuZero [Schrittwieser,2020] 将学习模型与蒙特卡洛树搜索 (MCTS) 相结合,用于游戏。其他方法包括 MBPO [Janner,2019;Chua,2018]、世界模型 [Ha & Schmidhuber,2018]、TD-MPC [Hansen,2022,2024] 和 IRIS [Micheli,2023]。
视频世界模型。最近的发展是从视频中学习的世界模型,这些模型分为两大类,对空间智体的影响也各不相同:可控世界模型从未标记的网络视频中学习交互式环境,从而实现基于动作的预测。Genie [Bruce,2024b] 允许用户控制生成世界中的角色,而 Genie 2 [Bruce,2024a] 则将其扩展到 3D 环境。这些模型可直接用于智体规划,因为它们能够模拟行为的后果。
生成式世界模型侧重于高保真视觉模拟,而无需显式的行为条件化。GAIA-1 [Hu et al., 2023a] 和 WorldDreamer [Yang et al., 2024d] 可生成逼真的驾驶视频,而 Sora [OpenAI, 2024] 则展示大规模视频生成。尽管这些模型在视觉上令人印象深刻,但由于缺乏决策所需的行为条件化结构,它们在智体规划中的应用相对有限 [Yang et al., 2024a, Baker et al., 2022, Wu et al., 2024, Yan et al., 2021, Wu et al., 2022]。
基于 LLM 的世界模型。 LLM可以作为规划的世界模型[Hao et al., 2023, Huang et al., 2022b],无需显式环境模型即可预测状态转换。这种方法利用LLM中编码的大量知识来模拟世界动态。然而,必须指出的是,尽管LLM可以对抽象的状态转换进行建模,但它们目前缺乏专用世界模型所具备的精细物理保真度,这对于需要精确几何和物理推理的任务而言是一个关键的局限性。RAP[Hao et al., 2023]通过世界模型的展开将推理与行动相结合。TransDreamer[Chen et al., 2022b]、UniSim[Yang et al., 2023a]和Genie 2[Bruce et al., 2024a]推进了世界建模的发展。这些模型对于分类体系中中观和宏观尺度的规划能力尤为有效,因为在这些尺度上,抽象的、高层次的预测通常就足够了。
多模态基础模型:智体如何将语言与感知联系起来?
多模态基础模型将语言与视觉和其他感官数据连接起来。
多模态模型整合了视觉、语言和动作理解,为智体系统提供了感知基础[Baltruˇsaitis et al., 2019, Xu et al., 2023c, Liang et al., 2024, Ngiam et al., 2011, Srivastava & Salakhutdinov, 2012, Ramachandram & Taylor, 2017]。必须做出一个关键区分:多模态对于空间智体来说是必要的,但并非充分条件。一个能够描述场景(“桌子上有一个红杯子”)的模型并不意味着它就具备了抓取该杯子的能力。感知提供了“是什么”和“在哪里”的信息。自主性需要额外的能力,例如规划(决定做什么)、记忆(跟踪状态随时间的变化)和行动(执行运动指令)。如果没有这些机制,多模态模型就只能是被动的观察者,而不是世界的积极参与者。
视觉语言模型。基础视觉语言模型大致可以分为两类。对比模型,例如 CLIP [Radford et al., 2021] 和 BLIP-2 [Li et al., 2023d],学习图像和文本之间共享的嵌入空间,从而实现强大的零样本分类。指令调整模型,如 LLaVA [Liu ,2023b,2024b]、InstructBLIP [Dai ,2023b] 和 Ferret [You ,2023,Zhang ,2024a],通过对话数据进行微调,以遵循用户指令,从而在视觉问答和对话中取得优异的性能。诸如 GPT-4V [OpenAI, 2023, Zheng et al., 2024, Yan et al., 2023]、Gemini [Team & Google, 2023]、Flamingo [Alayrac et al., 2022] 和 PaLI [Chen et al., 2023d,e] 等大规模模型进一步拓展多模态推理的边界,而 Qwen-VL [Bai et al., 2023]、CogVLM [Wang et al., 2023b] 和 InternVL [Chen et al., 2024h] 等开源替代方案则促进了更广泛的应用。
空间视觉语言模型。SpatialVLM [Chen et al., 2024a, Yang et al., 2024b] 专注于具有细粒度理解的空间推理。 SpatialRGPT [Cheng et al., 2024] 提供区域空间推理。VoxPoser [Huang et al., 2023b] 将视觉语言模型 (VLM) 中的affordance提取到三维表示中。这区分了以地图为中心的定位方式和以affordance为中心的定位方式。在以地图为中心的定位方式中,像 VLMaps [Huang et al., 2023a] 这样的模型构建用于导航的环境显式语义地图;而在以affordance为中心的定位方式中,像 VoxPoser [Huang et al., 2023b] 这样的模型无需完整地图即可直接推断场景的三维表示中的可操作affordance。这些模型代表了被动感知和主动规划之间的关键桥梁,将高级指令与具体的空间表示联系起来。
三维视觉语言模型。 3D-LLM [Hong et al., 2023b, Chen et al., 2024f, Zhu et al., 2023] 能够理解三维场景中的语言。Open3D-VQA [Zhang et al., 2025b] 提供开放词汇的三维视觉问答功能。LLM-Grounder [Yang et al., 2024b] 将语言置于三维环境中。向三维表示的转变从根本上增加了推理的复杂性,因为智体现在必须处理诸如遮挡、视角变化和体积属性等概念,而这些概念在基于二维图像的推理中并不存在。
关键要点:赋能技术
• GNN-LLM 集成代表着范式转变,它将关系推理与语义理解相结合。
• 世界模型能够通过想象实现高效的样本学习和安全规划。
• 空间视觉语言模型(SpatialVLM、VLMaps、VoxPoser)弥合了视觉语言理解和空间动作之间的鸿沟。
• 等变架构为几何推理提供了原则性的方法。
注意:这些模型的性能高度依赖于大规模、高质量的数据,并且在面对分布外场景时可能较为脆弱。
从基础技术出发,转向研究如何将它们集成到大规模部署的系统中。通过设计模式的视角分析现实世界的行业应用,为科学探究提供了一种强有力的方法。它能够超越定制化的系统描述,转而识别空间人工智能中常见问题的可重复、可推广的解决方案。这种方法将理论分类体系与实践相结合,不仅揭示了使用了哪些功能,还揭示了在商业可行性、安全性和规模的约束下,如何构建这些功能。
将行业部署抽象为可重用的空间人工智能系统设计模式。这些模式在现实世界的约束下,具体体现三轴分类法中的特定区域:每种模式代表了智体能力(记忆、规划、工具使用)、空间任务领域(导航、操作、地理空间推理)和操作尺度(微观、中观、宏观)的特定组合,揭示理论框架如何转化为已部署的系统。
遵循软件架构中已建立的形式化方法 [Gamma et al., 1994],以下每种模式都具体说明了问题、驱动力和解决方案。
设计模式 1:人机协同空间推理
问题:高风险的空间决策需要超越当前人工智能能力的精确度。制约因素:问责要求、责任风险、领域专家稀缺。解决方案:三步人机协同流程,其中:(1) 人工智能智体提出空间分析;(2) 人类专家验证或修正输出;(3) 利用反馈更新系统内存或策略,实现持续改进。
这种模式将人工智能空间分析与人类专家验证相结合[Amershi et al., 2019, Shneiderman, 2022, Wang et al., 2019a, Green & Chen, 2019, Fails & Olsen Jr, 2003, Stumpf et al., 2009, Holzinger, 2016, Dudley & Kristensson, 2018, Zanzotto, 2019],例如:
地理空间情报。地理空间情报融合平台将多源空间数据(卫星图像、信号情报、地形模型)与人类分析师的工作流程相结合[Palantir, 2023, Palantir Technologies, 2024]。这些系统能够在进行空间推理情报分析的同时,保持对关键决策的人工监督,这是国防领域问责制和法律约束所驱动的要求。
GIS工作流程。用于城市规划和环境监测的地理信息系统 (GIS) 集成了人工智能 (AI) 功能,以辅助规划人员 [ESRI, 2023, 2024b,a]。此工作流程直接实现了模式中定义的三步流程图。
设计模式 2:弱监督星-级学习
问题:宏观尺度的空间推理必须处理海量的未标记数据集以及由不同地理环境、传感器类型和大气条件造成的极端分布变化。
制约因素:在星级尺度上进行密集标注在经济和后勤方面都不可行。
解决方案:一个两阶段流程,包括 (1) 在 PB 级未标记卫星图像上进行自监督预训练,以学习强大的通用表示,然后 (2) 使用少量标记数据进行快速的、特定任务的微调。
这种模式利用海量未标记数据,以最少的监督构建全球尺度模型[Ratner et al., 2017, Zhang & Yang, 2022, Zhou, 2018, Chapelle et al., 2009, Zhu, 2005, Oliver et al., 2018, Lee, 2013, Tarvainen & Valpola, 2017]:
卫星基础模型。这种模式遵循清晰的抽象概念:海量数据(来自Landsat、Sentinel、Planet和Maxar等供应商的PB级多光谱图像)使得通过自监督技术(例如掩码自编码)学习强大的表示成为可能,然后可以针对各种下游任务(例如土地覆盖分类、变化检测或作物产量预测)进行微调。 NASA-IBM Prithvi [Jakubik et al., 2024] 以协调的 Landsat Sentinel-2 数据为例,展示了这一流程。Planet Labs [Planet Labs PBC, 2023, 2024] 和 Maxar 提供数据基础设施,支持每日全球监测。
大规模地图绘制。大型地图平台通过基于云的地理空间数据服务部署人工智能,进行全球尺度的分析 [Google, 2023, 2024b,a]。学习循环清晰明了:用户与地图的交互(例如,更正商家位置、报告道路封闭)提供持续的弱监督信号流。这些信号被聚合并用于自动更新底层地理空间模型,从而在全球范围内提高地图的精度和时效性。
设计模式 3:智体辅助的空间工作流程
问题:空间分析任务对于人类专家而言既重复又耗时。
驱动因素:需要可扩展性、希望保留人类自主性、任务复杂度可变。
解决方案:人工智能智体作为主要分析者。人类提供高级指导并处理异常情况。
与 HITL 的对比:此模式与 HITL(模式 1)截然不同:
此模式部署人工智能代理来增强人类的空间推理能力 [Shneiderman, 2020, Horvitz, 1999, Amershi et al., 2014, Abdul et al., 2018, Gillies et al., 2016, Yang et al., 2020]:
自主 GIS。自主 GIS [Li et al., 2025a] 和 GeoGPT [Bai et al., 2024] 将代理能力与地理空间分析相结合。该模式涉及基于 LLM 的代理,这些代理可以查询空间数据库、生成地图并回答地理问题。差距:当前能力边界由智能体解决自然语言空间歧义(例如,“市中心附近”)以及在融合不同地理空间数据库时处理模式异构性的能力来界定。
位置智能。Foursquare [Foursquare, 2023, 2024] 和 Carto [CARTO, 2023, 2024] 提供基于位置的、由人工智能驱动的分析服务。Wherobots [Wherobots, 2023, 2024] 提供云原生空间分析。其模式是:基于人工智能的查询和分析的空间数据基础设施。当前局限性:集成异构空间数据库时存在模式不匹配,以及自然语言查询中存在空间歧义(例如,“靠近市中心”在不同城市有不同的解释)。
设计模式 4:大规模具身人工智能
安全作为首要设计约束。与之前错误可恢复的模式(例如,可以纠正错误的地图标注)不同,具身人工智能运行的领域中,故障可能导致人身伤害、财产损失或生命损失。这从根本上改变了设计空间:安全不再是可添加的功能,而是影响所有架构决策的首要约束。
问题:在安全至关重要的物理系统中部署空间人工智能,因为故障会造成不可接受的损失。
挑战因素:严格的监管框架(例如,美国国家公路交通安全管理局 (NHTSA)、欧盟人工智能法案)、责任问题、验证长尾安全场景性能的挑战以及赢得公众信任的必要性。
解决方案:一种安全至上的方法,结合大规模仿真进行初始策略学习、在人工监督下进行保守的实际部署,以及在严格的安全和验证约束下从车队数据中持续学习。
这种模式将学习的空间策略部署到物理系统中[Kober et al., 2013, Levine et al., 2016, Ibarz et al., 2021, Kalashnikov et al., 2021, Julian et al., 2020, Akkaya et al., 2019, Levine et al., 2018, Tobin et al., 2017]:
自动驾驶汽车。自动驾驶汽车行业展现了两种截然不同的感知理念。以激光雷达为中心的方案(例如 Waymo、Cruise)将激光雷达点云与摄像头图像融合,实现冗余的高精度深度估计,以更高的传感器成本为代价,优先考虑最大安全裕度 [Waymo, 2023, 2024, ?]。相比之下,纯视觉方案(例如 Tesla)依赖于一系列摄像头和强大的学习型深度估计算法,旨在降低硬件成本并实现更可扩展的解决方案,但对感知模型的可靠性提出了极高的要求 [Tesla, 2023, 2024]。然而,这两种范式都遵循着大规模仿真、谨慎的实际部署以及从车队数据中持续学习的总体模式,所有这些都必须在交通安全法规的严格约束下进行。
机器人学习平台。Open X-Embodiment [Collaboration, 2023] 提供来自 Google DeepMind 和合作机构的大规模机器人数据。 Bridge Data [Walke et al., 2023, 2024] 实现了跨域迁移。其模式为:多样化的数据收集、基础模型训练、迁移到特定实例。
对研究人员的启示:行业模式
• 将问题抽象为模式:行业解决方案通常旨在解决反复出现的科学难题。将这些难题抽象为设计模式可以为学术界提供可推广的见解。
• 数据是护城河,监督是瓶颈:获取行星级专有数据是行业的关键优势,但无法对其进行标注却造成了监督瓶颈。这凸显了自监督学习和弱监督学习研究的巨大机遇。
• 人机交互是一个连续谱:人为监督的程度并非非此即彼,而是一个从完全人为控制到完全智体自主的连续谱上的设计选择。对自适应自主性和动态人机协作的研究至关重要。
• 安全不容谈判:对于任何旨在实际应用的研究而言,安全性、验证性和法规遵从性不是事后考虑的,而是必须从一开始就解决的核心研究问题。
评估框架和基准分析
略
重大挑战与未来方向
- 统一的空间表征
- 落地的长范围规划
- 不确定下的安全部署
- sim-2-real迁移
- 规模化的多智体协调
- 高效的边缘部署
限制
略

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 42
42 0
0- 0



 已为社区贡献211条内容
已为社区贡献211条内容

所有评论(0)