【第三十周】文献阅读
本周主要学习了两篇前沿论文,分别涉及增强现实技术在技能传授中的应用以及机器人零样本目标导航问题。第一篇论文介绍了InstruMentAR系统,它允许非专业用户通过穿戴式设备记录手指压力与手势,自动化生成数字仪器的AR操作教程,并能对新手用户提供实时的视觉-触觉反馈与错误纠正,从而大幅降低AR教程的制作门槛。
目录
摘要
本周主要学习了两篇前沿论文,分别涉及增强现实技术在技能传授中的应用以及机器人零样本目标导航问题。第一篇论文介绍了InstruMentAR系统,它允许非专业用户通过穿戴式设备记录手指压力与手势,自动化生成数字仪器的AR操作教程,并能对新手用户提供实时的视觉-触觉反馈与错误纠正,从而大幅降低AR教程的制作门槛。第二篇论文提出了OAM框架,通过引入类似人类短时记忆的时空缓冲模块,让智能体在未知环境中能够回顾历史观测,并结合视觉语言模型对目标进行语义匹配,从而更高效地选择探索方向,解决了传统方法依赖单帧观测的局限性。通过本周学习,我认识到无论是提升人类的学习效率还是赋予机器更强的环境理解能力,多模态感知与智能化反馈机制都扮演着至关重要的角色。
Abstract
This week’s study focused on two cutting-edge papers concerning Augmented Reality (AR) for skill transfer and zero-shot object navigation for robots. The first paper introduced the InstruMentAR system, which allows non-expert users to automatically generate step-by-step AR tutorials for digital instruments by recording their embodied demonstrations. Using wearable devices to capture finger pressure and gestures, the system creates intuitive virtual guides and provides real-time visual-haptic feedback to correct novice users’ mistakes, significantly lowering the barrier to creating AR tutorials. The second paper proposed the OAM framework, which enhances zero-shot object navigation by incorporating a spatio-temporal memory buffer. This mechanism enables an agent to recall past observations in unknown environments and use a Vision-Language Model to perform semantic matching on target patches, thereby making more informed decisions about which frontiers to explore, overcoming the limitations of single-frame observations. Through this week’s learning, I recognized that whether it is improving human learning efficiency or empowering machines with a deeper understanding of their environment, multi-modal perception and intelligent feedback mechanisms play a crucial role.
一、《InstruMentAR: Auto-Generation of Augmented Reality Tutorials for Operating Digital Instruments Through Recording Embodied Demonstration》
1、研究目的
由题目我们就可以看出来该文献的研究对象,是一个名为InstruMentAR的系统,该系统致力于让非专业用户能够轻松创建和获取高质量的AR操作教程并且使用它
2、相关工作
1、提供了一种自动化制作流程,让终端用户能够通过直观的具身演示为数字仪器创建顺序化AR教程
2、提供一种多模态方法,结合手指压力和手势追踪,将制作者的操作转换为AR视觉元素
3、研发出一种自动反馈机制,能够根据新手用户的实时操作,判断系统应该进入下一步还是发出视觉-触觉警告
4、还做了几轮用户研究,通过与非自动化沉浸式制作系统对比,评估InstruMentAR的效率和可用性
3、方法
首先,我们需要对AR教程有一定的了解,所谓AR教程,就是将教程视频投影到AR设备上去,通过虚拟教程和现实场景的融合,引导用户能够更方便的学习和操作相应器械。AR教程分为同步和异步教程,同步教程中,指导者必须在场,实时为新手用户创建和提供教程,新;本文重点关注异步教程,这类教程由指导者预先录制,新手用户可以根据自己的需求随时学习。
1、AR视频的制作
文章给出了AR视频的制作与使用的一些方法,一是如何制作AR教程;二是如何追踪用户与物理对象的交互;此外在交互过程中,还有AR教程的即时反馈
1.1、硬件设计
InstruMentAR配备了定制设计的可穿戴设备,用于检测操作何时发生,并为错误操作提供触觉反馈,并且研究规定,所有的操作都由食指和拇指或者两者组合完成,因此可穿戴设备设计简单,仅包含三个组件——一个腕带和两个指套,指套安装在用户的食指和拇指的指尖,并且采用薄膜压力传感器手机手指施加的压力强度。腕带内置微处理器、线性驱动触觉模块和电池。为优化手部追踪,这些组件在用户佩戴时均隐藏在手腕下方。微处理器具备 Wi-Fi 功能,可实现可穿戴设备与AR头戴设备的通信。
1.1.1、操作阈值
一些按钮、旋钮需要达到一定压力后才会按下或转动,这个临界压力点的检测就非常关键,但受按钮材质、用户用力的差异、指套的佩戴差异,会导致这个临界压力点不确定,所以研究人员收集了8组数据进行数据拟合,推导如下方程:
其中B为初始模拟读数,T为施加最小力时的模拟读数(阈值)。现在可以根据基线值B的不同(基线值在用户的手每次进入仪器附近的交互区域时更新)。当压力传感器的读数超过操作阈值时,系统判定操作开始;反之,当读数低于操作阈值时,系统判定操作结束
1.2、支持的UI操作
InstruMentAR指出五种类型的UI元素:触摸屏、开关、按钮、旋钮和滑块,这些元素足以覆盖大多数仪器操作
1.3、AR教程的制作
传统的AR制作工具一般都将编程环境与操作环境分离。开发者在编程过程中往往难以准确映射每次操作后仪器的状态。近年来,研究人员常常将沉浸式编程用于制作过程以融入物理交互空间,用户通过直接操作虚拟内容来创建虚拟引导然后在用于现实操作,但这样开发者必须在操作仪器和虚拟内容之间来回切换,费时费力
为了解决这个问题,该文献的研究人员记录了用户操作的每个步骤,省去手动生成虚拟引导的过程并且记录操作对UI元素产生的效果,以便系统能够自动生成与这些操作匹配的明确符号化视觉引导
1.3.1、设置流程
初始设置阶段,用户需要绘制一个边界框来指定交互区域,有2个用途,首先,系统仅在手部位于交互区域时才会接收压力信号,确保仅记录与仪器相关的操作。此外,用户必须指定自动图像捕捉区域,这样AR眼镜才能确认是否通过操作以达到正确的仪器显示
1.3.2、操作检测
如前所示,可穿戴设备能帮助系统确定仪器何时被操作,接下来系统需要确定仪器是如何被操作的,操作完成后,系统记录与该操作相关的手势信息和压力传感器。研究人员开发了一种基于决策树的算法,用来对UI操作进行分类。决策树的第一层分析一个或两个压力读数是否超过操作阈值;第二层的手势姿态过滤器通过分析手部关节数据,判断用户执行的是触碰还是捏合手势;同时,第二层和第三层的手势变换过滤器判断用户的手是移动了一段距离还是原地旋转。系统通过判断操作是否落在用户定义的屏幕边界内,确定该操作是否在触摸屏上进行。
1.3.3、箭头的生成
检测到操作后,系统会在相关UI元素具有不同尺寸和方向生成虚拟箭头,对于离散操作,系统获取操作发生的位置以及操作时的手部姿态,并基于这些信息生成虚拟箭头以指导后续用户该向什么方向用力;对于连续操作,系统在操作开始和结束的时候钧获取拇指与食指之间的向量,生成相应的箭头,通过向量减法,系统计算出旋钮的旋转角度,同时食指与拇指之间的距离决定箭头的长度
此外,由于精度问题,有时箭头的精度还是有些问题,所以系统也支持用户调整箭头的位置
2、AR视频的操作指导
2.1、预防性反馈
研究人员设计了一个反馈机制,使得系统能在错误发生前发出警告,反馈包括触觉模块的振动和AR中显示的警告标志,错误分为两个类别:一是定位错误的UI元素、二是操作方式的错误,基于错误类型,反馈分为3个阶段:首先,当系统接收到表示手指正在触碰 UI 元素的半按压信号时,获取手指位置;如果该位置与预先制作的操作位置不一致(第一类错误),立即发出警告;其次,通过分别对比食指指尖和拇指指尖的压力信号,预测手指的预期运动方向(这仅适用于滑块操作);对于旋钮和滑动操作,一旦用户开始向错误方向旋转 / 滑动,系统立即发出警告。只有当用户将手指从控制面板移开或纠正操作(如立即反向旋转旋钮)时,警告反馈才会消失。
2.2、错误处理和自动回放
如果检测到错误,AR教程会暂停,用户若认为该错误无负面影响,可手动恢复;若认为有影响,则可选择重新开始;如果未检测到错误,系统会自动进入下一步
4、实验
实验主要进行了3轮用户评估,每轮评估都采用李克特量表评分,李克特量表是一种广泛应用于社会科学、心理学、市场调研和问卷调查中的心理测量工具,用于测量受访者对某一陈述的态度、看法或感受
1、第一轮:模型检测评估
本轮研究主要旨在评估操作检测模型的性能,研究人员招募了10名志愿者,每名志愿者需要执行每个UI元素支持的所有操作,对一些错误操作进行了分类,还发现了大多数操故障是由于手部追踪故障导致的,且连续操作更容易出现手部丢失的情况
2、第二轮:制作AR教程
本轮研究主要收集的是用户对于InstruMentAR系统下制作AR教程的评价,此外,研究人员还设计了一个基准方法,以与InstruMentAR进行对比,他们依旧招募了10名志愿者,结果显示,在InstruMentAR系统下的AR制作耗时更短、用户体验更好,但是,为了防止丢失手部的追踪,研究人员只能限制志愿者的手部移动速度,这也是一个限制制作时间的因素。
3、第三轮:使用AR教程
招募了10名志愿者,让他们在统一制作的AR教程中,学习如何操作规定仪器,一半先使用传统AR教程,一半先使用InstruMentAR,记录完成时间、错误次数、用户反馈。根据用户反馈,实时反馈让用户更加确信自己完成了每个步骤,因此无需频繁参考教程,大多数用户对预防错误这个功能表示了赞赏
二、《OAM:Object-Aware Memory and Vision-Language Models for Zero-Shot Object Navigation》
1、研究目的
该论文主要的是OAM,OAM是一款零样本目标导航框架,让智能体在完全未知的环境下,仅通过自然语言指令,自主导航并精确定位目标物体,其核心应用场景包括灾害救援,家庭服务等,无需针对具体环境或目标进行专门训练,具备极强的泛化能力
2、相关工作
1、提出OAM框架,通过短时间记忆回顾性检索历史观测,并利用视觉语言模型进行语义匹配,突破单帧观测的局限
2、引入目标级语义聚焦机制,实现边界点与目标语义的高效匹配,提升复杂环境下的决策质量
3、无需任务特定训练,利用预训练模型的常识知识,适配从未见过的环境和目标物体,提升原本零样本的泛化能力
3、研究方法
OAM由三个主要模块组成,分别为感知模块、探索模块、导航模块,三个模块的工作流程为:首先,感知模块以 RGB 图像、深度图和位姿信息为输入,构建占据栅格地图、提取边界点并生成边界地图,同时将智能体的观测序列存储为历史记忆。探索模块基于视野覆盖范围和空间距离过滤每个边界点的历史观测,然后利用目标检测器从图像中提取目标斑块,将其输入视觉语言模型计算相似度分数,该分数反映每个边界的语义相关性。最后选择最具价值的边界点,导航模块规划路径并执行导航,更新观测输入。
1、感知模块
1.1、边界地图构建
每个时间步,智能体接收RGB图像、深度图和当前位姿,通过将深度数据投影到全局坐标系,得到环境的局部3D结构,然后将信息整合到全局2D占栅格地图Mocc,地图内会将元素分为障碍物、自由单元、未知单元。为构建地图,首先识别Mocc中所有自由单元,并将至少一个未知邻居的单元标记为边界候选点。为了减少冗余,采用空间聚类将相邻边界分组,从中提取代表性点形成离散边界集
1.2、时空记忆
类比人类的习惯,面对潜在目标位置时,人类通常会回忆该区域之前见过的物品——这种能力类似于短时间记忆。受此认知机制启发,研究人员设计时空记忆缓冲模块,缓存智能体近期访问位置的视觉和几何信息,实现边界点的语义感知。该模块维护一个长度为 M 的先进先出(FIFO)观测队列: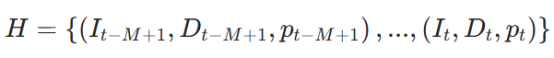
I为RGB图像、D为深度图像,p为位姿。该观测历史具有时间连续性和空间锚定性,形成轻量级短时感知记忆,作为后续 PathMatcher 语义评分模块的输入
2、探索模块
2.1、斑块匹配器
斑块是计算机视觉与图像处理中的一个关键概念,即为两幅图像中相似的小区域
获得候选边界集后,斑块匹配器为每个边界点分配与任务相关的语义价值。通过将当前导航目标与从历史观测中提取的语义斑块进行比较,该模块估算每个边界导向目标物体的可能性
2.1.1、边界 - 历史关联
系统维护过往观测历史,对于每个边界点,首先应用几何先验过滤最有可能包含相关信息的历史帧子集H,该过滤过程基于两个关键几何约束:
1)可见性约束:主要考虑的是某个历史观测的相机是否覆盖当前边界点,看的是定义边界与智能体的相对角度
若该角度落在水平视野 α 范围内,则认为边界点具有潜在可见性: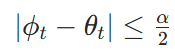
2)距离约束:边界点与历史观测位置的距离必须低于阈值dth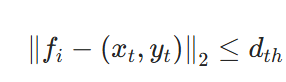
2.2.2、目标斑块提取
从选定的历史观测中识别语义相关的目标区域,该模块提取相应的图像区域作为斑块,然后将其存放在一个斑块集里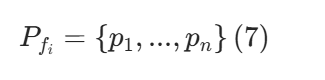
其中每个pj是与fi空间相关且具有潜在语义意义的图像区域,用于后续匹配和推理
2.2.3、语义边界
研究者采用视觉语言模型BLIP-2估算每个边界点与自然语言描述的目标物体之间的相似度分数,本文在此基础上,避免对整幅图像进行冗余处理
对于每个斑块,利用自然语言构建为文本提示描述导航目标,将斑块和文本输入 BLIP-2 计算余弦相似度分数: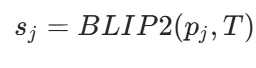
为获得每个边界点fi的整体语义分数,对其所有关联斑块的相似度分数取平均值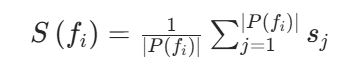
最后,选择语义分数最高的边界点作为下一个探索目标: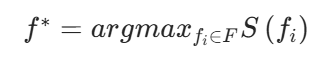
其中 F 是当前检测到的所有边界点的集合
该方法就是利用视觉语言模型进行记忆的匹配,通过自然语言的输入,探索目标物体,并且能够从历史观测数据中识别目标语义的物品,显著提升了模型的逻辑推理能力
3、探索模块
系统在占据栅格的地图上采用快速行进法(FMM)规划从智能体位置到边界点的无碰撞路径,并指导导航,若找到目标,则任务成功并中止,若没有找到,则系统重新评估分数,选择新目标,并重复该过程。
4、实验
1、在Hanbitat平台上,接入数据集Gibson、HM3D,测评OAM模块的性能,评估指标为成功率SR、路径长度加权成功比(SPL),然后对比了一些基线方法,研究人员采取了两类基线方法:有监督方法(SemExp、FSE、PONI)和零样本方法(ESC、L3MVN-Z、VLFM),结果表明,OAM在两大数据集钧优于所有基线方法,在Gibson数据集中,SR=84.5%、SPL=53.3%,较有监督方法最高提升 10.9%(SR)和 12.2%(SPL),较零样本方法 VLFM 提升 0.5%(SR)和 1.1%(SPL)。在HM3D数据集中,SR=54.3%、SPL=32.0%,较零样本方法 ESC 提升 15.1%(SR)和 9.7%(SPL),较 VLFM 提升 1.8%(SR)和 1.6%(SPL)
2、进行了消融实验,分别移除记忆缓冲和移除目标斑块,在移除记忆缓冲后,SR 降至 51.2%、SPL 降至 31.3%,证明历史观测能提升语义理解的一致性。在移除目标斑块后,SR 降至 52.3%、SPL 降至 30.9%,证明斑块级匹配能提升导航效率。
总结
本周的学习让我对AR辅助系统和智能导航技术有了更深的理解。从InstruMentAR项目中,我看到了AR技术如何从预设的静态指引向动态、自生成的交互式体验转变,特别是其通过触觉反馈预防错误的设计,让我意识到人机交互中实时感知与响应的重要性。而从OAM框架中,我学习到如何通过模拟人类的短时记忆机制,将历史观测数据与强大的视觉语言模型相结合,来解决机器人在未知环境中的泛化难题。这两个研究都强调了多模态信息融合的价值,无论是融合手势与压力,还是融合视觉图像与自然语言,都为提升系统的智能性与实用性提供了新思路,也启发我在未来的研究中更多地关注感知与反馈的闭环设计。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 8
8 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)