FastAPI部署LangGraph实战教程(非常详细),Chatbot搭建从入门到精通,收藏这一篇就够了!
在本教程中,我们将使用 FastAPI 和 LangGraph 构建一个简单的聊天机器人。并使用一个辅助函数来管理对话上下文,该函数会将消息裁剪到符合标记限制的范围内。最终页面会输出思考过程、消耗token及思考耗时

在本教程中,我们将使用 FastAPI 和 LangGraph 构建一个简单的聊天机器人。并使用一个辅助函数来管理对话上下文,该函数会将消息裁剪到符合标记限制的范围内。最终页面会输出思考过程、消耗token及思考耗时

概述
我们的项目由以下几个关键部分组成:

一. 环境搭建
创建一个新的项目目录,并添加一个requirements.txt文件,其中包含以下依赖项:
fastapi
uvicorn
langgraph
python-dotenv
tiktoken
langchain_core
langchain_openai
使用 pip 安装它们:
pip install -r requirements.txt
二. 管理对话语境
为了确保我们的语言模型在词元限制范围内接收到提示,我们在llm.py 文件中定义了辅助函数。该文件包含一个用于统计消息中词元数量的函数,以及另一个用于在保留最新上下文的同时修剪旧消息的函数。
def count_tokens(messages: list[BaseMessage]) -> int:
"""
按你的逻辑统计 Token 数:内容 Token + 每条消息 4 Token 开销
:param messages: BaseMessage 列表
:return: 总 Token 数
"""
if not messages:
return 0
# 使用 gpt-3.5-turbo 编码器近似 Llama 模型(你的原逻辑)
encoding = encoding_for_model("gpt-3.5-turbo")
num_tokens = 0
for message in messages:
# 统计消息内容 Token
if hasattr(message, "content") and message.content:
num_tokens += len(encoding.encode(message.content))
# 每条消息固定 4 Token 开销(你的原逻辑)
num_tokens += 4
return num_tokens
# ===================== 4. 你的消息裁剪逻辑(完整集成) =====================
def trim_messages(messages: list[BaseMessage], max_tokens: int = 4000) -> list[BaseMessage]:
"""
按你的逻辑裁剪消息:
1. 保留系统消息(如果存在)
2. 移除最旧的普通消息,直到 Token 数低于阈值
:param messages: BaseMessage 列表
:param max_tokens: 最大 Token 限制
:return: 裁剪后的消息列表
"""
if not messages:
return messages
# 分离系统消息和普通消息(你的原逻辑)
system_message = None
chat_messages = messages.copy()
if chat_messages and chat_messages[0].type == "system":
system_message = chat_messages.pop(0)
# 计算当前 Token 数并裁剪(你的原逻辑)
current_tokens = count_tokens(chat_messages)
trimmed_count = 0 # 记录裁剪的消息数
while current_tokens > max_tokens and len(chat_messages) > 1:
chat_messages.pop(0) # 移除最旧的普通消息
current_tokens = count_tokens(chat_messages)
trimmed_count += 1
# 合并系统消息 + 裁剪后的普通消息
if system_message:
final_messages = [system_message] + chat_messages
else:
final_messages = chat_messages
return final_messages, trimmed_count # 返回裁剪后消息 + 裁剪数量
三. 构建对话图谱
我们应用程序的核心在于llm.py 文件,其中我们使用 LangGraph 定义了一个状态图。该图包含一个chatbot处理对话状态的节点。它会对消息进行修剪(使用我们的上下文管理器),以确保不超过词元限制,然后用系统指令调用语言模型。
# ===================== 5. 改造裁剪节点(集成你的逻辑 + 时间/Token 统计) =====================
async def trim_node(state: AgentState) -> AgentState:
"""裁剪节点:使用你的 Token/裁剪逻辑 + 时间统计 + Token 可视化"""
# 1. 时间统计开始
trim_start_ts = time.time()
trim_start_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S.%f")[:-3]
state.timestamps["trim_start"] = trim_start_ts
# state.thought_logs.append(f"⏰ 裁剪节点开始时间:{trim_start_time}")
# 2. 裁剪前统计(使用你的 count_tokens 函数)
before_trim_count = len(state.messages)
before_trim_tokens = count_tokens(state.messages)
# 3. 执行裁剪(使用你的 trim_messages 函数)
trimmed_messages, trimmed_count = trim_messages(state.messages, max_tokens=4000)
state.messages = trimmed_messages
# 4. 裁剪后统计
after_trim_count = len(state.messages)
after_trim_tokens = count_tokens(state.messages)
token_reduction = before_trim_tokens - after_trim_tokens
# 5. 时间统计结束
trim_end_ts = time.time()
trim_end_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S.%f")[:-3]
trim_duration = round(trim_end_ts - trim_start_ts, 3)
state.timestamps["trim_end"] = trim_end_ts
# state.thought_logs.extend([
# f"\n⏰ 裁剪节点结束时间:{trim_end_time}",
# f"⏱️ 裁剪节点总耗时:{trim_duration} 秒"
# ])
return state
# ===================== 6. 思考节点(补充 Token 统计) =====================
async def thought_node(state: AgentState) -> AgentState:
"""思考节点:时间统计 + Token 上下文"""
# 1. 时间统计开始
thought_start_ts = time.time()
thought_start_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S.%f")[:-3]
state.timestamps["thought_start"] = thought_start_ts
# state.thought_logs.append(f"\n⏰ 思考节点开始时间:{thought_start_time}")
# 2. 当前上下文 Token 统计(使用你的 count_tokens 函数)
current_tokens = count_tokens(state.messages)
user_question = state.messages[-1].content if (state.messages and state.messages[-1].type == "human") else ""
token_usage_rate = round(current_tokens / 4000 * 100, 2) # 基于 4000 Token 阈值计算使用率
# 3. 思考步骤(补充 Token 信息)
thought_steps = [
("📌 分析用户问题", f"用户问题:{user_question}"),
("🔍 判断工具调用", "当前问题无需调用工具,可直接回答"),
# ("📋 确定回答框架", "核心优势 → 分点说明 → 总结"),
("📊 上下文 Token 状态", f"总 Token:{current_tokens}(使用率:{token_usage_rate}%,阈值:4000 Token)")
]
# 4. 单步耗时统计
for step_title, step_content in thought_steps:
step_start_ts = time.time()
step_start_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S.%f")[:-3]
await asyncio.sleep(0.1) # 模拟思考耗时
step_end_ts = time.time()
step_duration = round(step_end_ts - step_start_ts, 3)
state.thought_logs.extend([
f"\n{step_title}:{step_content}",
# f" ├─ 开始时间:{step_start_time}",
f" └─ 耗时:{step_duration} 秒"
])
# 5. 时间统计结束
thought_end_ts = time.time()
thought_end_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S.%f")[:-3]
thought_total_duration = round(thought_end_ts - thought_start_ts, 3)
state.timestamps["thought_end"] = thought_end_ts
return state
# ===================== 7. 回复节点 + 工作流 + 流式函数(不变,适配新逻辑) =====================
async def reply_node(state: AgentState) -> AgentState:
"""回复节点:记录耗时 + 生成回复"""
reply_start_ts = time.time()
reply_start_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S.%f")[:-3]
# state.thought_logs.append(f"\n⏰ 回复节点开始时间:{reply_start_time}")
# 生成回复
prompt = ChatPromptTemplate.from_messages([
("system", "根据以下思考过程回答用户问题,要求简洁明了,分点说明:\n{thought_logs}"),
("human", "{question}")
])
user_question = state.messages[-1].content if (state.messages and state.messages[-1].type == "human") else ""
thought_logs = "\n".join(state.thought_logs)
response = await prompt.ainvoke({"thought_logs": thought_logs, "question": user_question})
ai_response = await llm.ainvoke(response)
state.messages.append(AIMessage(content=ai_response.content))
# 耗时统计
reply_end_ts = time.time()
reply_end_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S.%f")[:-3]
reply_duration = round(reply_end_ts - reply_start_ts, 3)
state.timestamps["reply_end"] = reply_end_ts
state.thought_logs.extend([
# f"⏰ 回复节点结束时间:{reply_end_time}",
f"⏱️ 回复节点总耗时:{reply_duration} 秒"
])
return state
def build_agent_graph():
"""构建工作流"""
graph = StateGraph(AgentState)
graph.add_node("trim", trim_node)
graph.add_node("thought", thought_node)
graph.add_node("reply", reply_node)
graph.add_edge(START, "trim")
graph.add_edge("trim", "thought")
graph.add_edge("thought", "reply")
graph.add_edge("reply", END)
return graph.compile()
四. 创建 FastAPI 应用程序
我们首先在main.py 文件中定义 FastAPI 应用。该文件设置了一个/stream-chat端点,用于接收包含聊天消息的 POST 请求。然后,该端点将消息传递给我们的 LangGraph 图进行处理。
# 请求体模型(不变)
class StreamRequest(BaseModel):
system_message: str = "你是一个友好的助手,回答简洁明了。"
messages: list
# 改造流式接口:调用带思考的函数
@app.post("/stream-chat")
async def stream_chat(request: StreamRequest):
try:
if not request.messages:
raise HTTPException(status_code=400, detail="消息列表不能为空")
return StreamingResponse(
stream_llm_with_real_thought(request.system_message, request.messages),
media_type="text/plain; charset=utf-8"
)
except Exception as e:
raise HTTPException(status_code=500, detail=f"流式响应失败:{str(e)}")
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)
五.流式输出
我们将利用 LangGraph 的功能和 FastAPI 的 支持,添加一个简单的基于 HTML 的聊天界面,使其支持实时流式传输。这样,用户就可以实时看到聊天机器人的回复,从而获得更具互动性的体验。
# 带思考过程展示的前端页面
@app.get("/", response_class=HTMLResponse)
async def index():
return """
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>LLM 流式对话(带思考过程),token计算</title>
<style>
body {
max-width: 1000px;
margin: 20px auto;
padding: 0 20px;
font-family: Arial, sans-serif;
}
.container {
display: flex;
gap: 20px;
margin-top: 20px;
}
.thought-panel {
width: 40%;
border: 1px solid #ffc107;
border-radius: 8px;
padding: 15px;
height: 400px;
overflow-y: auto;
background-color: #fff8e1;
}
.chat-panel {
width: 60%;
border: 1px solid #eee;
border-radius: 8px;
padding: 15px;
height: 400px;
overflow-y: auto;
background-color: #f9f9f9;
}
.input-area {
margin-top: 20px;
display: flex;
gap: 10px;
}
#question-input {
flex: 1;
padding: 10px;
border: 1px solid #ddd;
border-radius: 4px;
font-size: 16px;
}
#send-btn {
padding: 10px 20px;
background-color: #007bff;
color: white;
border: none;
border-radius: 4px;
cursor: pointer;
font-size: 16px;
}
#send-btn:disabled {
background-color: #6c757d;
cursor: not-allowed;
}
.user-message {
text-align: right;
margin: 10px 0;
color: #007bff;
}
.ai-message {
text-align: left;
margin: 10px 0;
color: #28a745;
}
.thought-title {
color: #ff8c00;
font-weight: bold;
margin-bottom: 10px;
}
</style>
</head>
<body>
<h1>LLM 流式对话(带思考过程)</h1>
<div class="container">
<!-- 思考过程面板 -->
<div class="thought-panel">
<div class="thought-title">🤔 AI 思考过程</div>
<div id="thought-container"></div>
</div>
<!-- 聊天面板 -->
<div class="chat-panel" id="chat-container"></div>
</div>
<div class="input-area">
<input type="text" id="question-input" placeholder="请输入你的问题,按回车或点击发送..." autocomplete="off">
<button id="send-btn" onclick="sendMessage()">发送</button>
</div>
<script>
let isGenerating = false;
async function sendMessage() {
const inputEl = document.getElementById('question-input');
const sendBtn = document.getElementById('send-btn');
const chatContainer = document.getElementById('chat-container');
const thoughtContainer = document.getElementById('thought-container');
const question = inputEl.value.trim();
if (!question || isGenerating) return;
// 重置状态
isGenerating = true;
sendBtn.disabled = true;
inputEl.value = '';
thoughtContainer.textContent = ''; // 清空思考面板
chatContainer.innerHTML = ''; // 清空聊天面板
// 添加用户消息
const userMsgEl = document.createElement('div');
userMsgEl.className = 'user-message';
userMsgEl.textContent = `问题:${question}`;
chatContainer.appendChild(userMsgEl);
chatContainer.scrollTop = chatContainer.scrollHeight;
// 添加AI回复占位符
const aiMsgEl = document.createElement('div');
aiMsgEl.className = 'ai-message';
aiMsgEl.textContent = 'AI:';
chatContainer.appendChild(aiMsgEl);
chatContainer.scrollTop = chatContainer.scrollHeight;
try {
const res = await fetch('/stream-chat', {
method: 'POST',
headers: {'Content-Type': 'application/json'},
body: JSON.stringify({
messages: [{"role": "human", "content": question}]
})
});
const reader = res.body.getReader();
const decoder = new TextDecoder('utf-8');
// 解析流式数据(区分思考和回复)
while (true) {
const { done, value } = await reader.read();
if (done) break;
const chunk = decoder.decode(value);
// 按行分割(处理多字符chunk)
const lines = chunk.split(/(THOUGHT:|RESPONSE:)/);
for (let i = 1; i < lines.length; i += 2) {
const type = lines[i];
const content = lines[i+1] || '';
if (type === 'THOUGHT:') {
// 追加到思考面板
thoughtContainer.textContent += content;
thoughtContainer.scrollTop = thoughtContainer.scrollHeight;
} else if (type === 'RESPONSE:') {
// 追加到回复面板
aiMsgEl.textContent += content;
chatContainer.scrollTop = chatContainer.scrollHeight;
}
}
}
} catch (e) {
aiMsgEl.textContent += `【出错了:${e.message}】`;
} finally {
isGenerating = false;
sendBtn.disabled = false;
}
}
// 回车触发发送
document.getElementById('question-input').addEventListener('keydown', (e) => {
if (e.key === 'Enter') sendMessage();
});
// 页面加载聚焦输入框
window.onload = () => {
document.getElementById('question-input').focus();
};
</script>
</body>
</html>
"""
六. 在本地运行应用程序
python main.py
七. 测试
- 打开浏览器并导航至
http://localhost:8000/. - 在输入框中输入消息如“介绍你自己”,然后按“发送”。
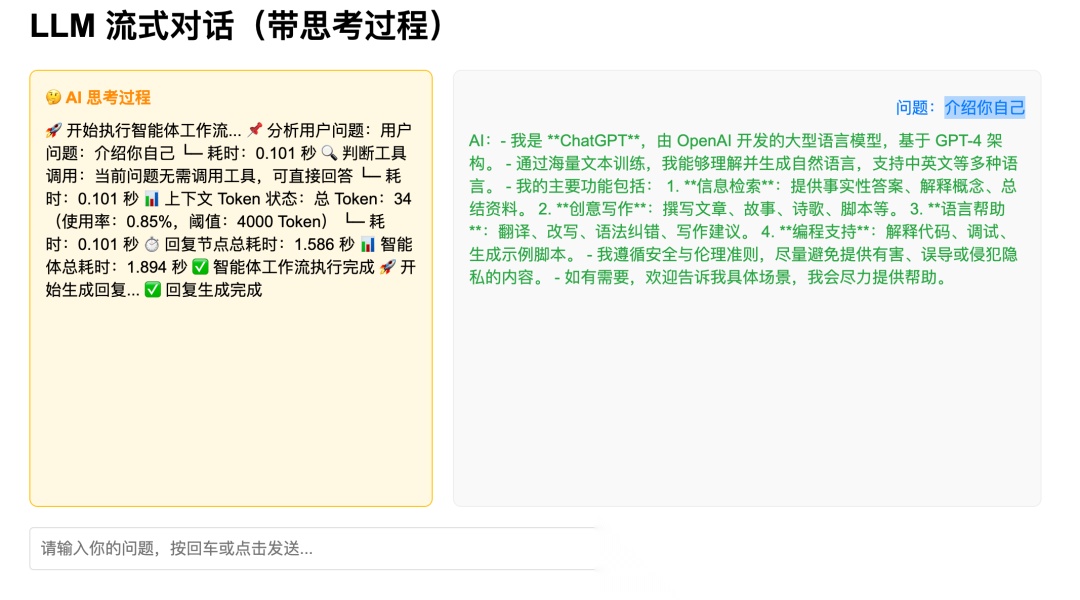
3.在输入框左上方实时查看思考响应流,右上方看到回答响应流。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 18
18 0
0- 0



 已为社区贡献63条内容
已为社区贡献63条内容

所有评论(0)