RDT2——基于UMI数据实现零样本且跨本体的泛化:先训练VLM、后训练扩散动作专家、最后将扩散策略蒸馏为一步生成器(挑战叠衣服)
前言
前两天在朋友圈说道,希望今年上半年:通过100套umi数采工具,快速构建100万条真机数据,且想办法达到跨本体 跨任务 跨环境的能力
毕竟这是工业具身通用大脑必经之路,但只是第一阶段,离真正通用还远远不够
而本文要介绍的RDT2所关注的“跨本体、跨物体、跨场景”,也是我司所关注的:即于26年起,准备用十年时间,为所有机器人造通用大脑
- 跨本体(从机械臂到人形)
- 跨物体(开不同的柜门)
- 跨任务(从开门到拧螺丝)
- 跨场景(从工业场景到家庭场景)
- 跨环境(从白天到黑夜)
顺带感慨下
- 做科研的,或经常看论文的,都知道在一项技术极速发展的时候,极少有所谓的完全自研或完全独创
国/公司/人之间,互相启发,共同发展
————
比如
FiS-VLA code is built based on HybridVLA and Lift3D
HybridVLA code is built based on OpenVLA and CogACT(CogACT相当于把OpenVLA的离散化动作预测换成DiT)
openvla forked from TRI-ML/prismatic-vlms
而Prismatic VLM则组合的SigLIP、DinoV2、Llama 2 - 总之,一个人、一个公司的牛都是有限度的,但汇集广大开发者共同的努力与创造,则可以创造无限牛
respect 国内外一切有影响力的开源,包括本文要介绍的RDT2,我与其几个作者也互相认识
至于上一代RDT的解读,可见此文:《RDT——清华开源的双臂机器人“扩散动作大模型”(基于DiT改造而成):先预训练后微调,支持语言、图像、动作多种输入》
第一部分 RDT2: Exploring the Scaling Limit of UMI Data TowardsZero-Shot Cross-Embodiment Generalization
1.1 引言与相关工作
1.1.1 引言:RDT2的提出
如原论文所说,当前的 VLA 模型仍未能复现其他领域如NLP『Achiam et al., 2023-即Gpt-4; Touvronet al., 2023-即Llama; Bai et al., 2023-即Qwen technical report; Guo et al., 2025-即Deepseek-rl』中大规模模型所具有的广泛泛化能力
它们在面对新的场景、物体、指令或具身形态时往往难以稳定可靠地执行(Ma et al., 2024),从而阻碍了其在真实世界中的应用
为机器人开发具有良好泛化能力的 VLA 模型面临两个根本性挑战
- 其一是获取大规模且多样化的数据集
通过远程操作进行传统数据采集『Zhaoet al., 2023-即ALOHA ACT; Fu et al., 2024-即Mobile aloha』通常成本高得难以承受,并且由于机器人平台的物理约束和高昂费用而缺乏多样性
相比之下,Universal Manipulation Interface(UMI)提供了一种与具体具身形态无关的手持设备,使得在大量真实世界场景中能够高效且低成本地采集数据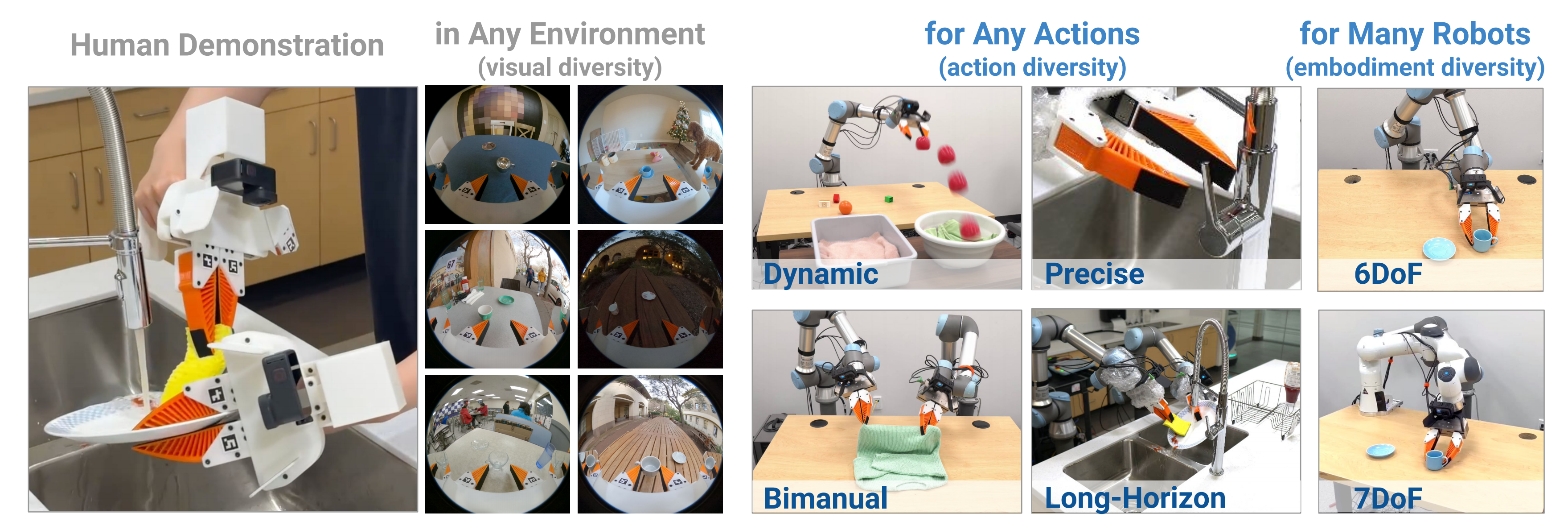
- 第二个挑战在于设计能够有效利用这些大规模机器人数据的网络架构
一个关键难点在于人工采集示范数据所固有的多峰性『Chen et al., 2022-Offline reinforcement learning via high-fidelity generative behavior modeling; Chi et al., 2023-即Diffusion policy』
先前通过离散化来建模动作概率的方法『Brohan et al.,2022-即Rt-1; Zitkovich et al., 2023-即Rt-2; Kim et al.,2024-即Openvla』,往往受到离散化误差以及自回归推理低效性的限制
使用扩散模型的替代方法
Chen etal., 2022-即Offline reinforcement learning via high-fidelity generative behavior modeling
Chi et al., 2025-即Diffusion policy
Liu et al., 2024
Black et al., 2024-即π0
则存在收敛缓慢(Pertsch et al.,2025-即FAST_π0),以及其连续概率分布与预训练视觉-语言模型(VLMs)中以离散形式表示的知识之间存在根本不匹配的问题
此外,这些模型规模不断增大,与机器人任务对实时性能的需求之间也存在显著矛盾
尽管已有部分工作探索了蒸馏技术
Chen et al., 2023,即Score regularized policy optimization through diffusion behavior
Wang et al., 2024b,即One-step diffusion policy: Fast visuomotor policies via diffusion distillation,通过扩散蒸馏实现的一步式快速生成视觉运动策略
Prasadet al., 2024,即Consistency policy,通过一致性蒸馏加速机器人策略的推理过程
但针对大规模 VLA 模型的实用方法的研发仍然是一个尚未解决的开放问题
此外,VLA 模型在跨形体部署方面面临一个重大限制。由于不同机器人平台在物理特性上的差异,在某一种形体上训练得到的模型当迁移到另一个时,在泛化能力上表现不佳
一些方法尝试将来自不同具身形式的数据统一到一个共同的嵌入空间中
- Team et al.,2024-即Octo
- Liu et al.,2024-即Rdt-1b
- Wang etal.,2024a-即Scaling proprioceptive-visual learning with heterogeneous pretrained transformers
探讨了利用异构预训练 Transformer 扩展视觉与本体感知学习 - Yang et al.,2024-即Pushing the limits of cross-embodiment learning for manipulation and navigation,研究了跨平台具身学习在操作与导航任务中的极限
但仍然难以实现在全新平台上的零样本部署
因此,将一个 VLA 模型适配到一台新机器人往往需要数百小时的数据采集和微调。这一巨大的成本不仅阻碍了 VLA 研究的可复现性和广泛适用性,也限制了整个领域的总体发展进程
- Khazatsky et al.,2024,即Droid: A large-scale in-the-wild robot manipulation dataset
- Atreyaet al.,2025,即Roboarena: Distributed real-world evaluation of generalist robot policies
- Mirchandani et al.,2025,即Robocrowd: Scaling robot data collection through crowdsourcing
为了解决上述挑战,来自清华大学的研究者提出了 RDT2

- 其paper地址为:RDT2: Exploring the Scaling Limit of UMI Data Towards Zero-Shot Cross-Embodiment Generalization
其作者包括
Songming Liu * 1 Bangguo Li * 1 Kai Ma * 1 Lingxuan Wu * 1 Hengkai Tan 1 Xiao Ouyang 1 Hang Su 1 Jun Zhu 1 - 其项目地址为:rdt-robotics.github.io/rdt2
其GitHub地址为:github.com/thu-ml/RDT2
具体而言,它是首批能够在新型实体形态上实现 zero-shot 部署的机器人基础模型之一,能够处理开放词表任务
- RDT2构建在一个 7B 规模的预训练 VLM Qwen2.5-VL之上,配备了专门的动作头,以及用于从大规模机器人数据中学习的三阶段训练策略
- 为了加速收敛
在阶段 1 中,作者使用 Residual Vector Quantization,即RVQ
VanDen Oord et al., 2017,即Neural discrete representation learning,提出了 VQ-VAE 模型,开创了通过向量量化学习离散潜变量表示的方法
Esser et al., 2021,即Taming transformers for high-resolution image synthesis,提出了 VQGAN,将卷积的归纳偏置与 Transformer 的表达能力结合,用于高质量图像合成
Lee etal., 2022,即Autoregressive image generation using residual quantization,提出了 RQ-VAE,引入残差向量量化(RVQ)来提高表示精度,是 RDT2 动作分词器的核心参考
将连续的机器人动作编码为离散token,然后通过最小化交叉熵损失来训练 VLM
这也避免了破坏在预训练阶段以离散概率形式存储的知识
1.1.2 相关工作
首先,对于机器人数据金字塔
用于机器人学习的数据版图可以被概念化为一个金字塔(Bjorck et al.,2025)
- 位于塔尖的是遥操作数据,这类数据通过 VR 等系统
Khazatsky et al.,2024,即Droid: A large-scale in-the-wild robot manipulation dataset
Cheng et al.,2024,即Open-television
Chen etal.,2025a,即Arcap: Collecting high-quality human demonstrations for robot learning with augmented reality feedback,利用增强现实AR反馈采集高质量机器人学习的人类演示数据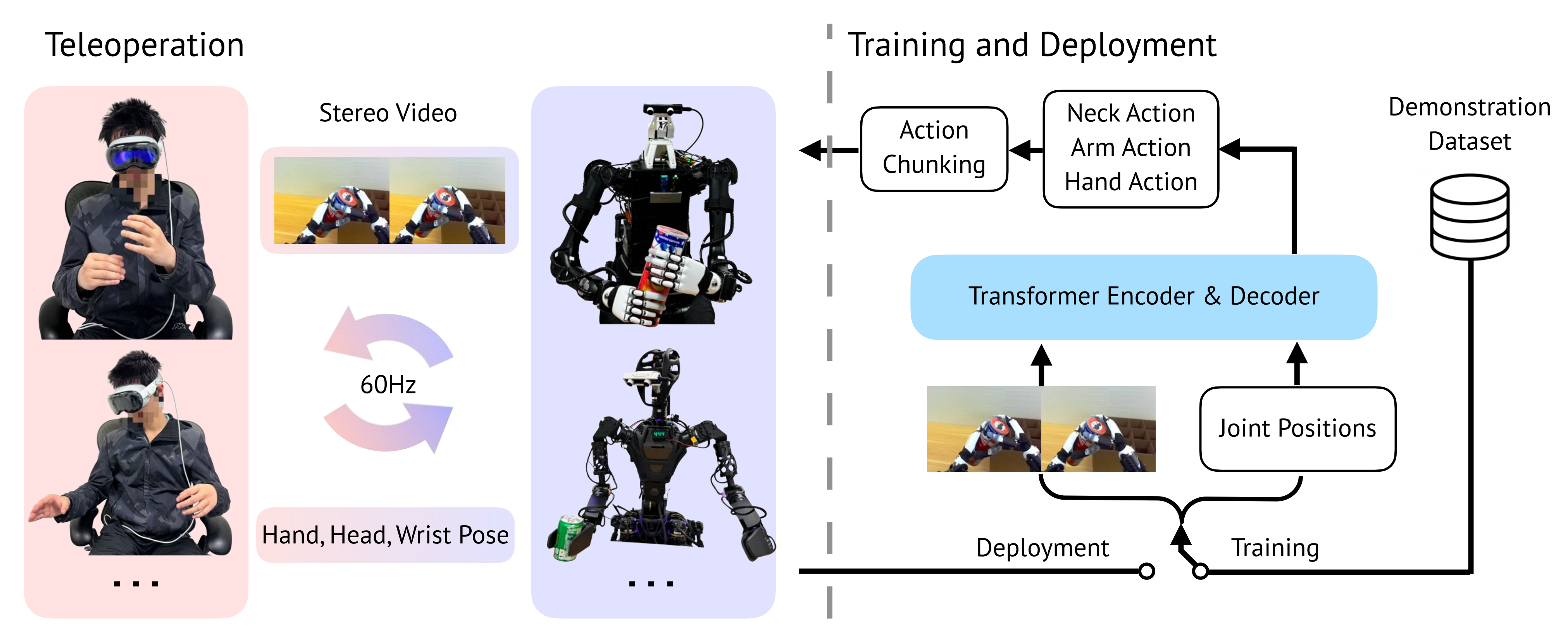
或主从机械臂
Zhao et al.,2023;即ALOHA ACT
Fu etal.,2024,即Mobile aloha
Aldaco et al.,2024,即Aloha 2
采集,具有最高的保真度,但获取成本也最高
其采集通常局限于结构化的实验室环境
Walke et al.,2023,即Bridgedata v2: A dataset for robot learning at scale
Fang etal.,2023,即Rh20t: A comprehensive robotic dataset for learning diverse skills in one-shot
Khazatsky et al.,2024,即Droid: A large-scale in-the-wild robot manipulation dataset
O’Neill et al.,2024,即Open x-embodiment
Wuet al.,2024,即Robomind: Benchmark on multi-embodiment intelligence normative data for robot manipulation
从而在训练数据与真实世界应用之间造成分布差距 - 位于中间层的是仿真数据
Wang etal.,2023,即Robogen: Towards unleashing infinite data for automated robot learning via generative simulation
Li et al.,2023,即Behavior-1k: A benchmark for embodied ai with 1,000 everyday activities and realistic simulation
Mu et al.,2024,即Robotwin: Dual-arm robot benchmark with generative digital twins (early version)
Chen etal.,2025b,即Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization
这种数据成本低且具有良好的可扩展性,但受到显著的“仿真到真实”(sim-to-real)鸿沟困扰
并且如何生成多样化、具备交互性且逼真的场景仍然是一个尚未解决的开放问题
Nasiriany etal.,2024,即Robocasa: Large-scale simulation of everyday tasks for generalist robots
Ren et al.,2024,即Infinite-world: A unified scalable simulation framework for general visual-language robot interaction
Zhang et al.,2025,即Agentworld: An interactive simulation platform for scene construction and mobile robotic manipulation - 位于底层的是海量的互联网视频资源
Ye etal.,2024,即Latent action pretraining from videos,从互联网视频中进行潜动作(Latent Action)预训练
Yang et al.,2025,即Egovla: Learning vision-language-action models from egocentric human videos,从第一人称视角(第一视角)视频中学习 VLA 模型
Luo et al.,2025,即Being-h0: vision-language-action pretraining from large-scale human videos,基于大规模人类视频进行的视觉-语言-动作预训练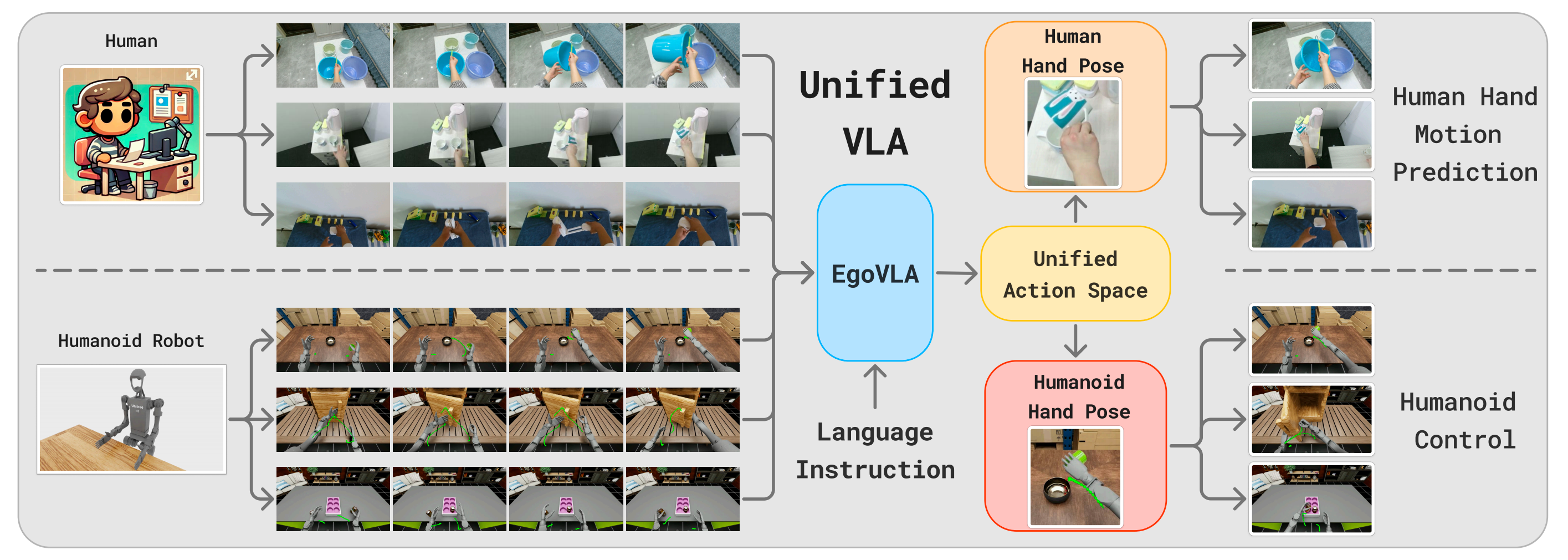
Feng etal.,2025,即Vidar: Embodied video diffusion model for generalist manipulation,用于通用具身操作的视频扩散模型
尽管数量丰富,这类数据是非结构化且噪声较大,更重要的是,缺乏监督策略训练所需的显式动作标签
McCarthy et al.,2025,即Towards generalist robot learning from internet video: A survey,关于如何从互联网视频学习通用机器人技能的综述
其次,对于模仿学习模型
先前的模型大致可以按照其泛化策略进行分类
- 大量研究工作聚焦于小规模模型
Pari etal., 2021,即The surprising effectiveness of representation learning for visual imitation
Florence et al., 2022,即Implicit behavioral cloning
Shafiullah et al., 2022,即Behavior transformers: Cloning k modes with one stone
Jang et al., 2022,即Bc-z: Zero-shot task generalization with robotic imitation learning
例如Diffusion Policy
Chen et al.,2022;,即Offline reinforcement learning via high-fidelity generative behavior modeling,通过高保真生成行为建模进行离线强化学习
Chi et al., 2023,即Diffusion policy
和
ACT,Zhao et al., 2023,即ALOHA ACT
它们通常是在每个任务的基础上进行训练。虽然在各自的特定领域内表现出色,这些模型在本质上缺乏跨多样任务或不同实体(embodiments)进行泛化的能力 - 为了解决跨实体的挑战
另一类研究利用UMI,包括dexumi,来收集与实体无关的数据
然而,这些数据集的规模有限,从而限制了所得模型在开放词汇任务上的表现
最近,该领域出现了诸如OpenVLA、RDT-1B、π0和π0.5等大型模型
然而,由于其数据集依赖于特定机器人,这些模型在不进行微调的情况下难以实现良好的实体可迁移性
1.1.3 问题表述与挑战
作者在针对 VLA 模型的语言条件模仿学习设定下研究双臂操作任务,而这一设定在机器人学习领域已经相当成熟
- 从形式上看,该任务被建模为一个序贯决策过程
令表示描述该任务的自由形式语言指令。在每个时间步
,智能体需要采取一个动作块
,该动作块从
中采样得到,
————
其中是在
维动-作,
是块大小(Zhao et al.,2023),并且
是智能体在t 时刻接收的RGB 观测
这里, 作者假设 - 为了获得一个可行的智能体, 作者训练一个VLA 模型, 从人类专家的演示数据集
中学习分布
其中是第
条轨迹的长度,
是轨迹的总数量
一个给定的操作任务由若干关键要素的组合所定义:被操作的物体、操作场景、来自用户的自然语言指令,以及机器人的具身形式
任何有限的训练数据集只能覆盖由这些要素张成的庞大组合空间中的一个稀疏子集
因此,一个实用的 VLA 模型在部署时必须能够推广到未见过的物体、场景、指令,甚至全新具身形式的组合上。实现这种组合泛化——这对真实世界应用至关重要——面临两个根本性挑战:
- 扩展机器人数据规模的挑战
在自然语言处理和计算机视觉领域,人们已经充分研究并证实:增加数据集的规模与多样性可以提升模型的泛化能力(Kaplan et al.,2020; Zhai et al., 2022)
————
然而,将这一原则通过远程操作(teleoperation)直接应用到机器人领域目前并不现实。机器人成本高昂,使得并行采集数据——也就是进行大规模数据收集——的费用高得难以承受
此外,这类系统缺乏可移植性,使得数据采集主要局限于实验室或工厂环境,从而严重限制了数据的多样性以及所收集数据的真实世界相关性
这种数据稀缺性还被硬件的异构性进一步加剧,因为在一个机器人平台上收集的数据往往无法与其他平台兼容,从而形成彼此隔离且不可互操作的数据集 - 网络架构的挑战
根据已有研究(Chen et al.,2022; Chi et al., 2023),人类数据呈现显著的多模态特征,这要求模型学习的是动作的分布,而不是确定性的映射。这就引出了在离散与连续动作表示之间的选择问题,而二者各自具有不同的权衡
————
离散方法在形式上与预训练 VLM 的概率输出天然契合,但会受到量化误差以及自回归采样低效性的影响
相反,连续方法(例如扩散模型)在采样效率上更具优势,但其训练收敛更慢(Pertsch et al., 2025),并且存在破坏 VLM中离散知识的风险(Deng et al., 2025)
因此,一个关键挑战在于综合这两种范式的优点
此外,机器人任务对实时性能的要求,使得高效部署大规模 VLA 成为一项极其艰巨的障碍
1.1.4 硬件
为了解决数据扩展挑战,作者采用 UMI(Chi et al.,2024),这是一种便携式框架,可用于支持可扩展的真实环境数据采集
关于UMI,详见此文《UMI——斯坦福刷盘机器人:通过手持夹爪革新数据收集方式,且使用视觉SLAM和Diffusion Policy预测动作》
- UMI 使用带有视觉模块和跟踪器的手持设备,记录 6 自由度末端执行器位姿以及夹爪张开宽度
- 当安装物理参数一致的夹爪时,由 UMI 数据学习得到的策略可以部署到多种不同的机械臂上,因为在不同具身形态之间的视觉差异和结构差异都被最小化
然而,原始的 UMI 硬件缺乏进行大规模真实环境采集所必需的可靠性。为了解决这一问题,作者对整个系统『图 1a,即图 1 展示了作者的 UMI 解决方案从设计到部署的全过程』进行了重新工程设计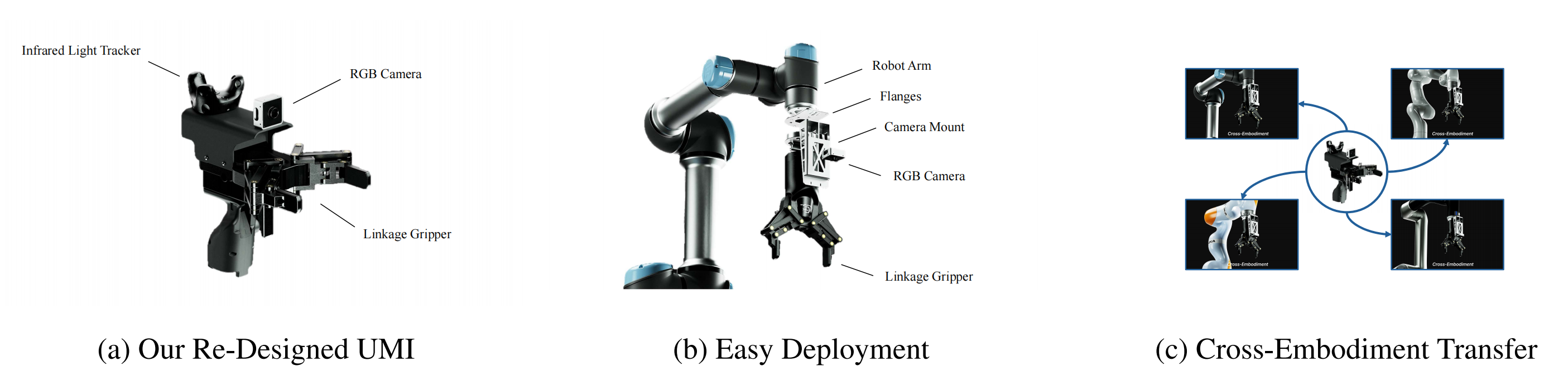
以最大化结构刚度,确保无漂移红外跟踪,并在杂乱环境中提升操作灵巧性
如表1所示,这些改动解决了关键的位姿不一致问题和可达性限制,从而显著提高了数据保真度;更详细的硬件规格见附录A
如论文附录A.1. 数据采集硬件(手持式 UMI)所说
手持式数据采集设备(图 9a)集成了计算单元、高帧率视觉系统、高精度红外跟踪以及自定义夹持器接口
- 计算单元
数据记录由一台搭载 Intel Core Ultra 7 155H 处理器、配备 32GB 内存和 2TB SSD 的工业控制单元完成- 视觉系统
作者采用 Hikrobot MV-CS016-10UC 工业相机(Hikrobot MV-CS016-10UC 产品页面)传感器:Sony IMX273 全局快门 CMOS(1/2.9")
• 分辨率:1440×1080(1.6 MP)
• 像素尺寸:3.45µm×3.45µm
• 帧率:最高 249 fps(采集时配置为 30 Hz)
• 接口:USB 3.0- Tracking System
采用了一种基于红外光的定位系统,使用 4 个 HTC VIVE Tracker 3.0(HTC VIVE Tracker 3.0 产品页面)来跟踪末端执行器的 6-DoF 位姿- 夹爪
为确保接触动力学的一致性,在实际方案中用于机器人执行时,作者采用 ZhiXingCTAG2F120 夹爪(ZhiXing 夹爪产品页面)————
对于手持式数据采集装置,作者开发了一款无致动的定制仿真夹爪,其配置与几何形状与原始 ZhiXing 夹爪完全一致
该仿真夹爪机体由玻璃纤维增强尼龙 66(PA66+GF)通过 CNC 加工制成,辅件则采用不锈钢和铜材料。这一装置配备带机械限位开关的滑轨机构,使操作员能够手动控制夹爪的张开宽度,并使其与机器人端对应夹爪的运动范围严格一致
如原论文附录A.2. 机器人部署设置所说



1.1.5 数据集:大规模 UMI 数据集
得益于上述硬件进步,作者整理了迄今为止最大规模的开源 UMI 数据集之一,包含超过 10,000 小时的操作数据,覆盖100 多个家庭
该数据集完全在真实环境中采集,囊括了大量无结构环境和复杂人类行为的分布,为通用策略学习提供了坚实基础;关于数据集的详细信息见附录 B
如原论文「B. UMI 数据集」所述
B.1. 数据集概述
- UMI 数据集包含大约 10,000 小时的交互数据,这些数据采集自 100 多个独特的家庭环境。虽然该数据集包含来自展示厅、样板公寓、洗手间和养老院等结构化场景的数据,但其中相当大一部分由通过付费众包在私人住宅中收集的数据构成
- 在住宅环境中进行数据采集,可以捕获长尾对象类别、多样的材质以及在受控实验室中难以复现的空间布局
这些特性提高了数据集的生态效度,并有助于学习能够在不同环境和部署场景中实现良好泛化的表示- 近期的大规模操作数据集同样将规模和多样性作为重点
与这些发现一致,UMI 数据集同样强调,规模、场景多样性和任务覆盖度是实现机器人操作中表征学习和泛化能力的关键要素
B.2. 家庭环境中的数据采集
- 在家庭环境中,作者定义了超过 50 项任务,用以覆盖各种日常操作类活动(图10)
例如抓取与放置、倒液体、擦拭、摇晃、搅拌以及整理归纳等
- 在每一次录制过程中,数据采集人员会被给予一条高层次指令(见表3)
并使用他们家中现有的物体来完成相应任务
- 数据采集协议在设计时就明确以多样性为目标
作者鼓励数据采集人员在物体、容器和操作策略的选择上进行变化。例如,在打包任务中,采集人员可以根据实际情况将物品放入背包、塑料袋或篮子中
这些在家庭环境中录制的数据涵盖了与超过 1,000 个不同物体的交互- 该数据集还包含接触丰富的交互,例如按压、插接和开关门,以及对可变形物体的操作,如叠衣服和清洁。我们还加入了长时程任务,例如整理杂乱的台面,这类任务需要多步规划和持续执行
B.3. 基于实验场所的核心操作技能数据采集
- 为补充家庭场景数据,作者在一个专门设计用于并行数据采集的实验场所中收集了操作数据
该场所有 50 个工位,因此多名数据采集人员可以在受控的布局和感知条件下同时进行录制。这样的设置确保了对核心操作技能的一致性覆盖- 作者使用了一个包含 3,000 多个物体的集合,这些物体在形状、尺寸、重量、材质以及日常类别(例如容器、工具、包装物和可变形物体)上各不相同
通过在不同工位间采样物体组合,在保持任务结构一致的同时,确保了抓取和接触交互的多样性- 在该环境中的指令主要集中于抓取、抬起、移动到目标区域等操作基础动作。这类在受控环境下采集的数据,通过在可复现的设置中强化低层次操作表征,从而对居家场景的数据集形成补充
B.4. 两阶段标注流程
作者采用一个由两个阶段组成的流水线,对 UMI 数据集进行了人工与机器结合的标注(见图11-标注示例)
- 首先,根据高层级任务指令对录音进行分段,以生成任务级片段;
- 其次,将这些片段进一步分解为细粒度的动作片段
标注内容以自然语言形式存储(例如:“用右手抓起红色杯子”),但遵循一个结构化的模式,用于明确指定所使用的手、所操作的物体以及动作原语
这种方式确保了感知、语言与运动行为之间的对齐与映射
B.5. 语言增强
为提升语言覆盖度,作者对细粒度标注进行了系统性的语言增强
- 对于每条指令,作者都会生成在语义上等价的改写句,以及省略特定手部或物体细节的简化变体
例如,指令“Put the black-handled rolling knifeon the near left side of the table using the left hand”
被改写为“Using your left hand, place the rolling knifewith the black handle onto the near left side of the table”
或被简化为“Place the knife on the left.”- 这一过程提高了系统对语言变化的鲁棒性,并有助于跨不同指令风格的泛化
机器标注是通过 Google Gemini2.5 Pro(Google Gemini 2.5 Pro Documents)生成的
在图 12 中展示了增强后的语言示例
B.6. 视觉–语言问答预训练数据集
- 作者的VLA 模型在一个由第一视角和与机器人相关的视觉问答(VQA)数据集组成的集合上进行预训练,该集合包含超过 1200 万个问答对
- 该语料库将互联网规模的视觉–语言数据与具身式 QA 数据集相结合,涵盖静态图像、第一视角视频和机器人操控场景
由此为语义落地、时序推理、空间理解以及语言–动作对齐提供了监督信号
- Ego4D + QaEgo4D
- HD-EPIC
HD-EPIC 数据集将第一人称视频理解扩展到具有高细节的厨房环境,并配备密集标注,其中包括多种类型的视觉问答问题,这些问题需要对细粒度动作识别、物体运动理解以及在长时间第一人称视频片段上的三维空间推理(Perrett et al., 2025)- RoboVQA
RoboVQA 是一个用于机器人在长时程视频数据上进行推理的大规模多模态问答基准。它包含数十万个来源于机器人和工具具身场景的问答对,适用于可供性推理和未来预测任务(Sermanet et al., 2023)- 其他数据集
其余数据源包括大规模互联网级视觉–语言集合,如 PixMo-Cap-QA 和 Cambrian-10M,这些数据集提供了广泛的视觉与语言覆盖,有助于在多模态预训练中增强整体语义对齐和指令理解能力(Deitke et al., 2024; Tonget al., 2024)
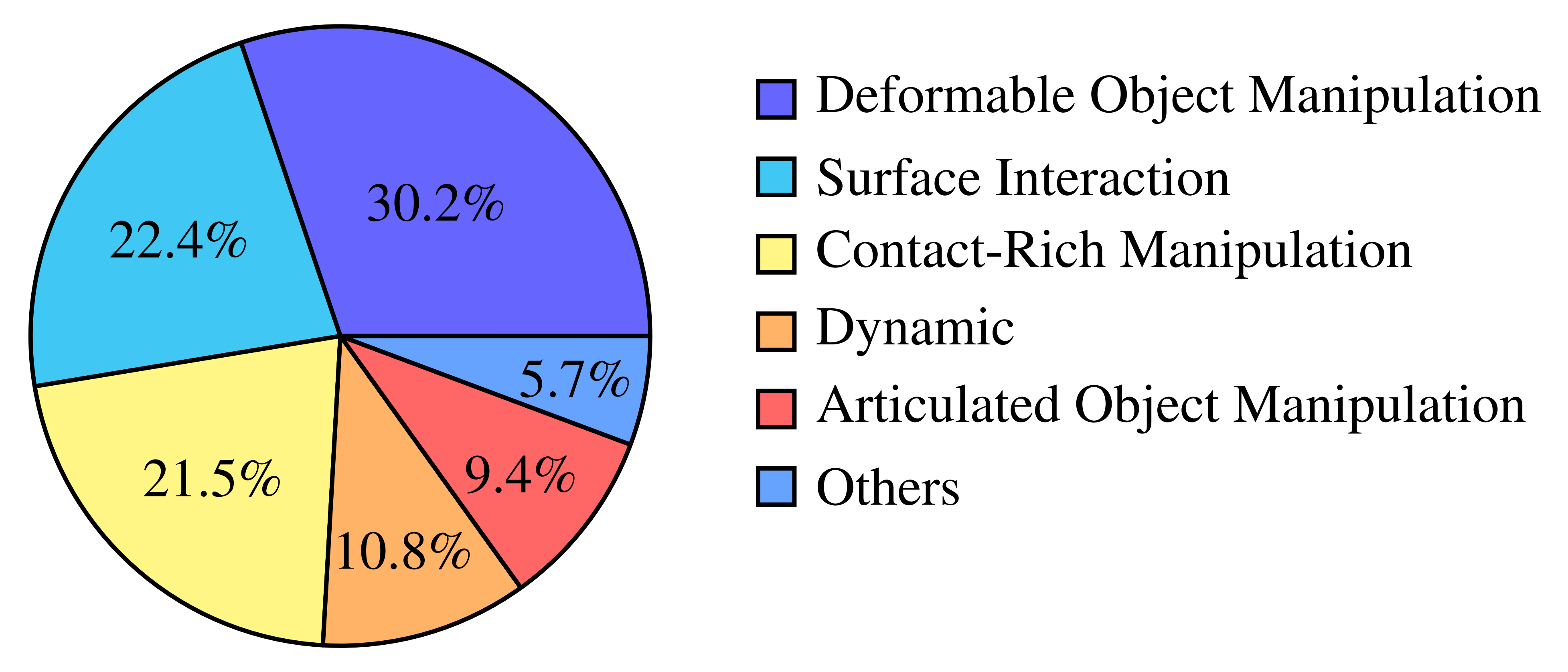
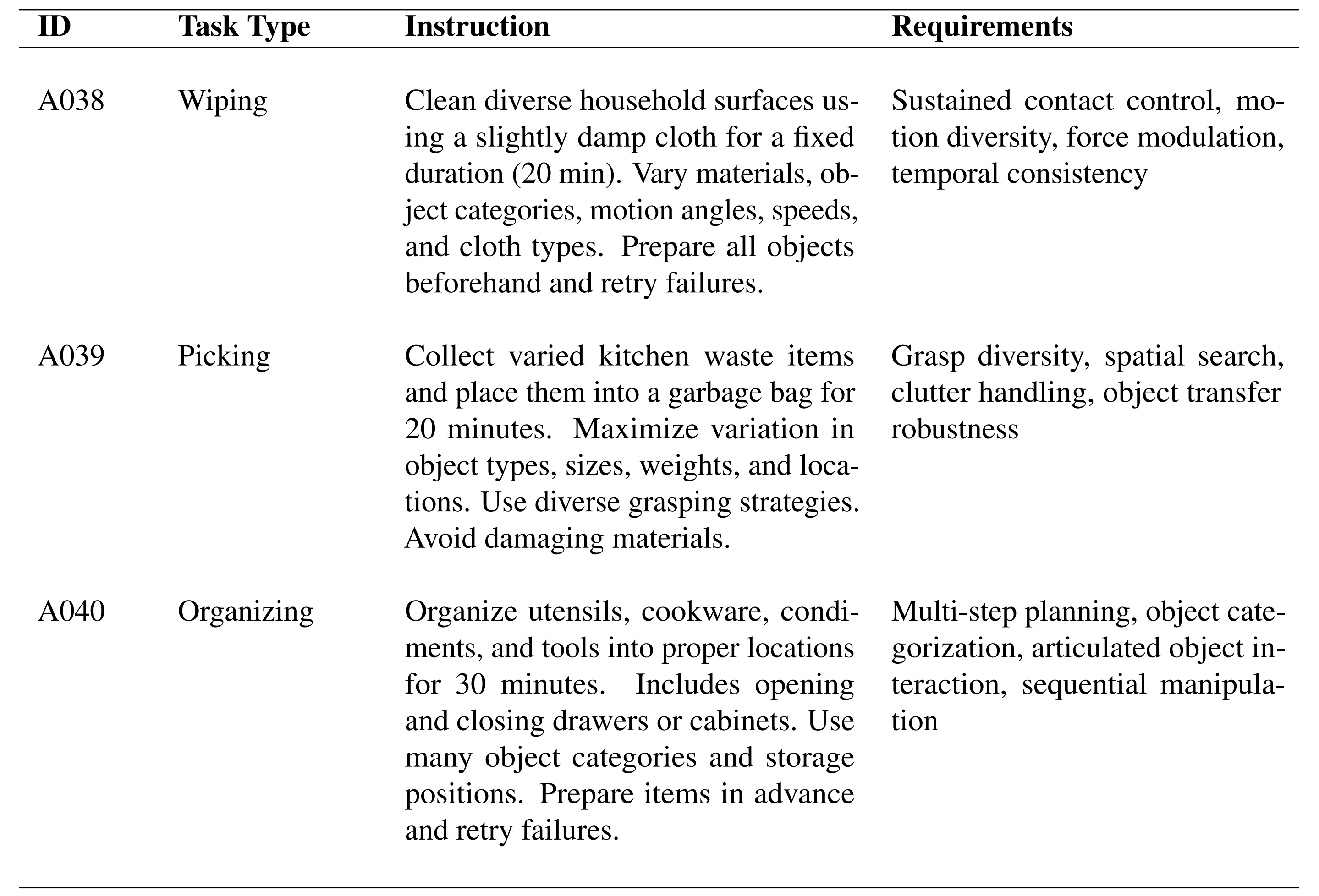
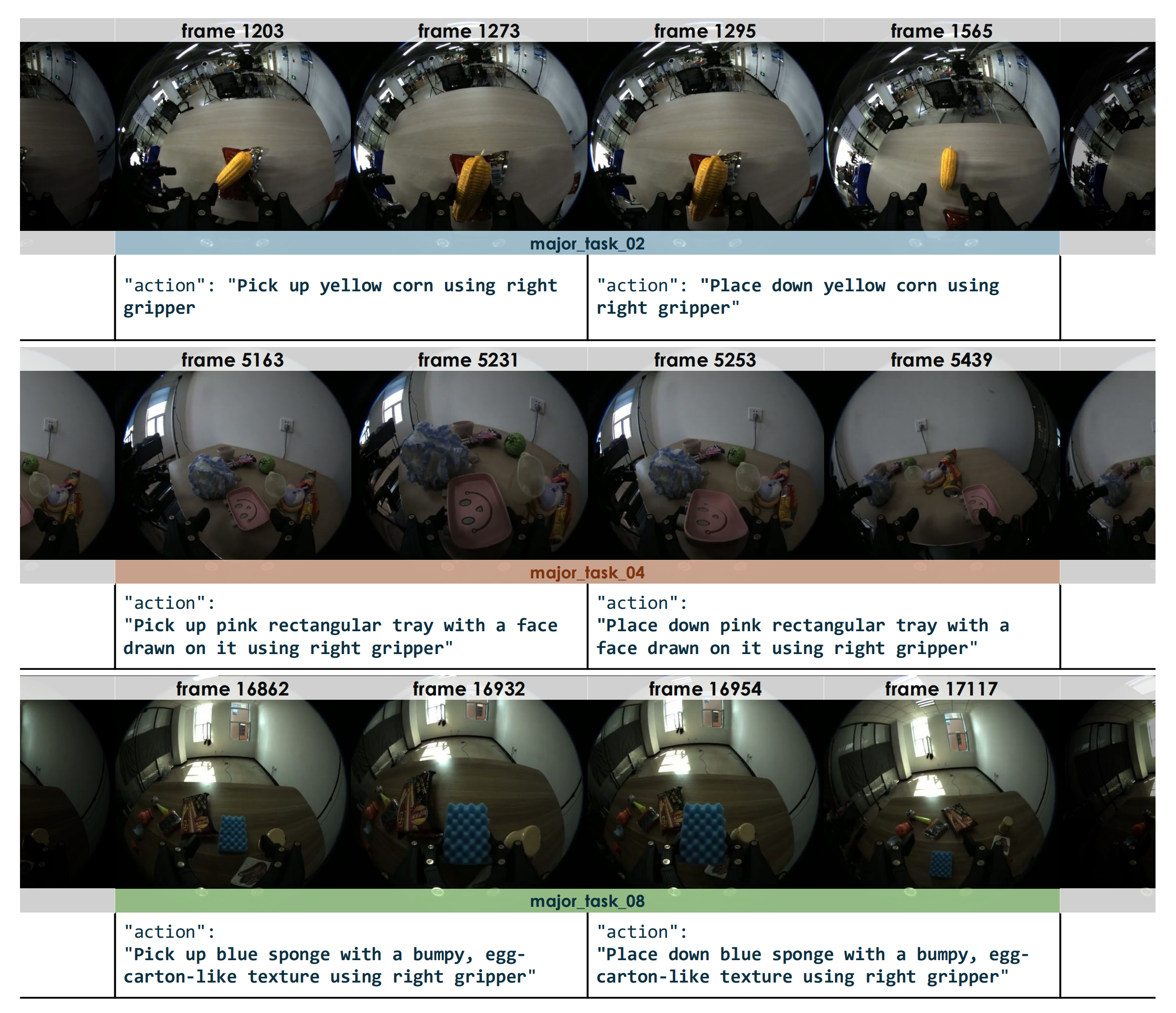
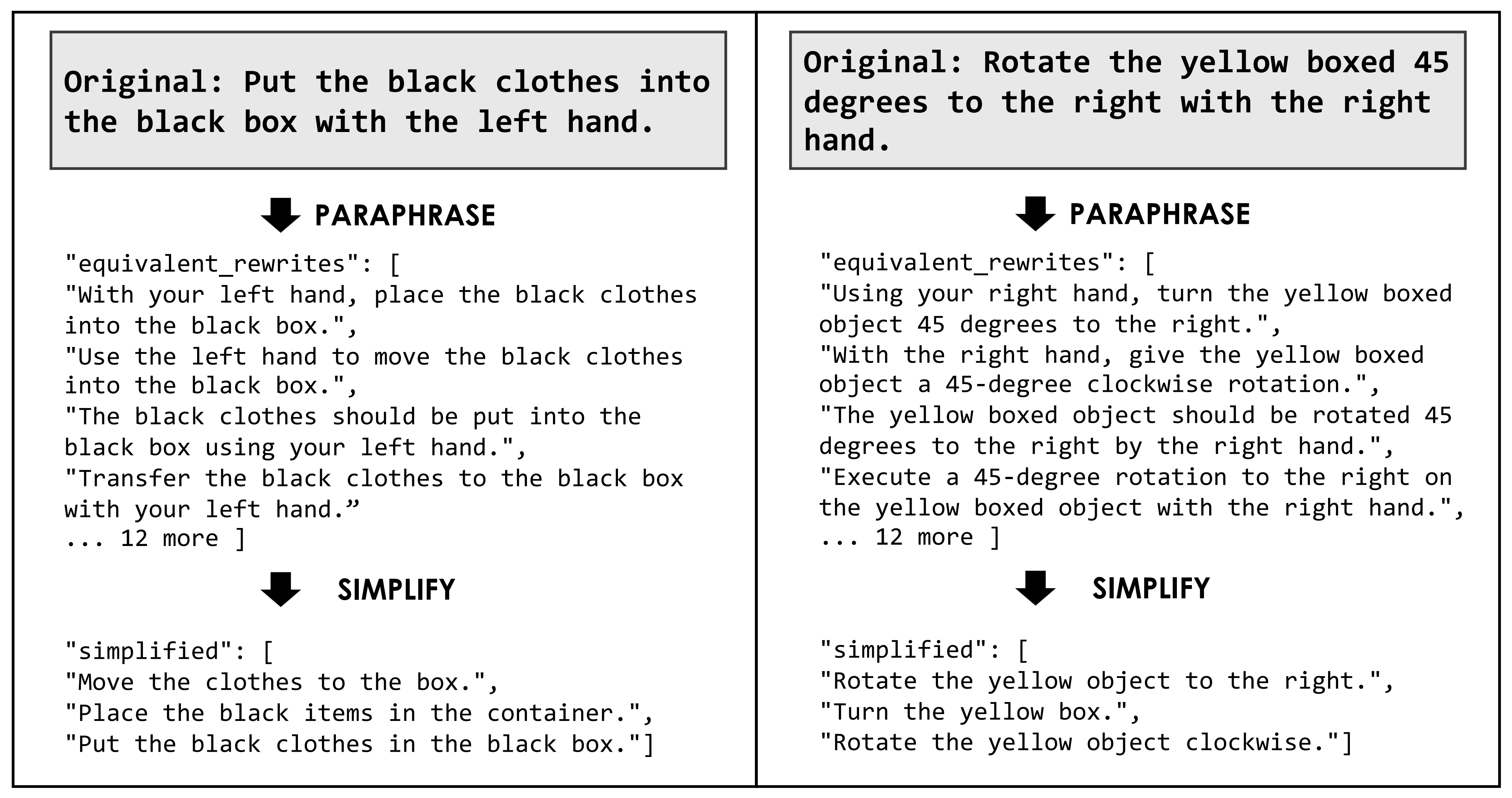
1.2 三阶段训练流程:离散化预训练(学认知)、连续流匹配(学动作)、扩散蒸馏(提速度)
RDT2,这是一种按照图 2 所示三阶段流程训练的 VLA 模型

- 在第一阶段,作者使用 RVQ 将连续动作空间离散化为 token,并通过标准交叉熵损失训练 VLM 主干网络
即使用离散化的动作数据预训练一个 70 亿参数的 VLM主干模型,以获得视觉-语言推理能力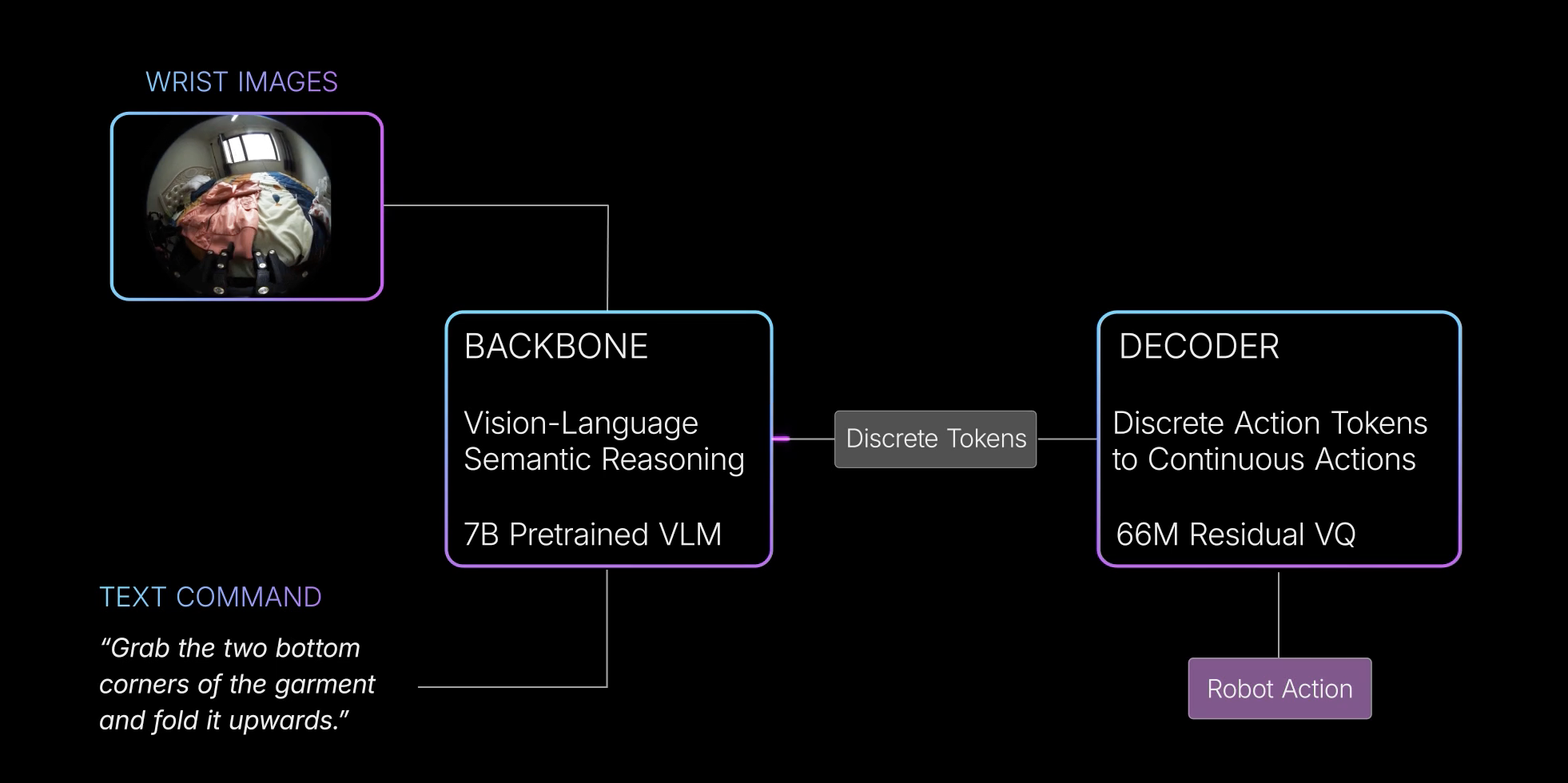
- 随后,在第二阶段,作者冻结 VLM 主干网络,并训练一个基于扩散的动作专家,利用flow-matching 损失来生成连续动作
————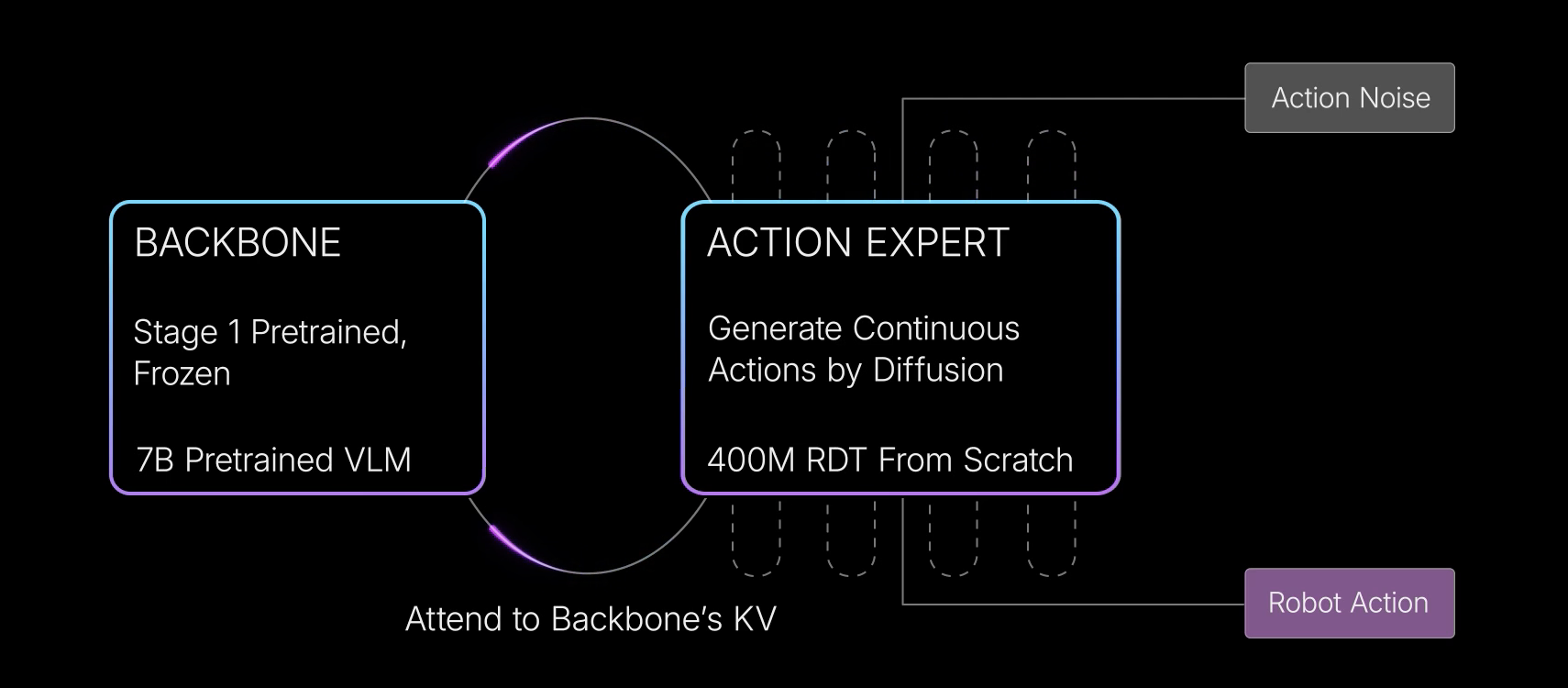
即训练一个小型扩散式动作专家模型,以高效生成连续动作
这种混合方法兼具离散化和扩散两种范式的优点,有效应对了对多峰动作分布建模的挑战 - 最后,为了解决机器人任务中的实时性难题,第三阶段将多步动作专家蒸馏为高效的单步生成器,从而使该大规模 VLA 模型能够进行快速推理
即对于高度动态的任务,作者进一步引入第三阶段,将扩散策略蒸馏为一步生成器,从而实现极快的推理速度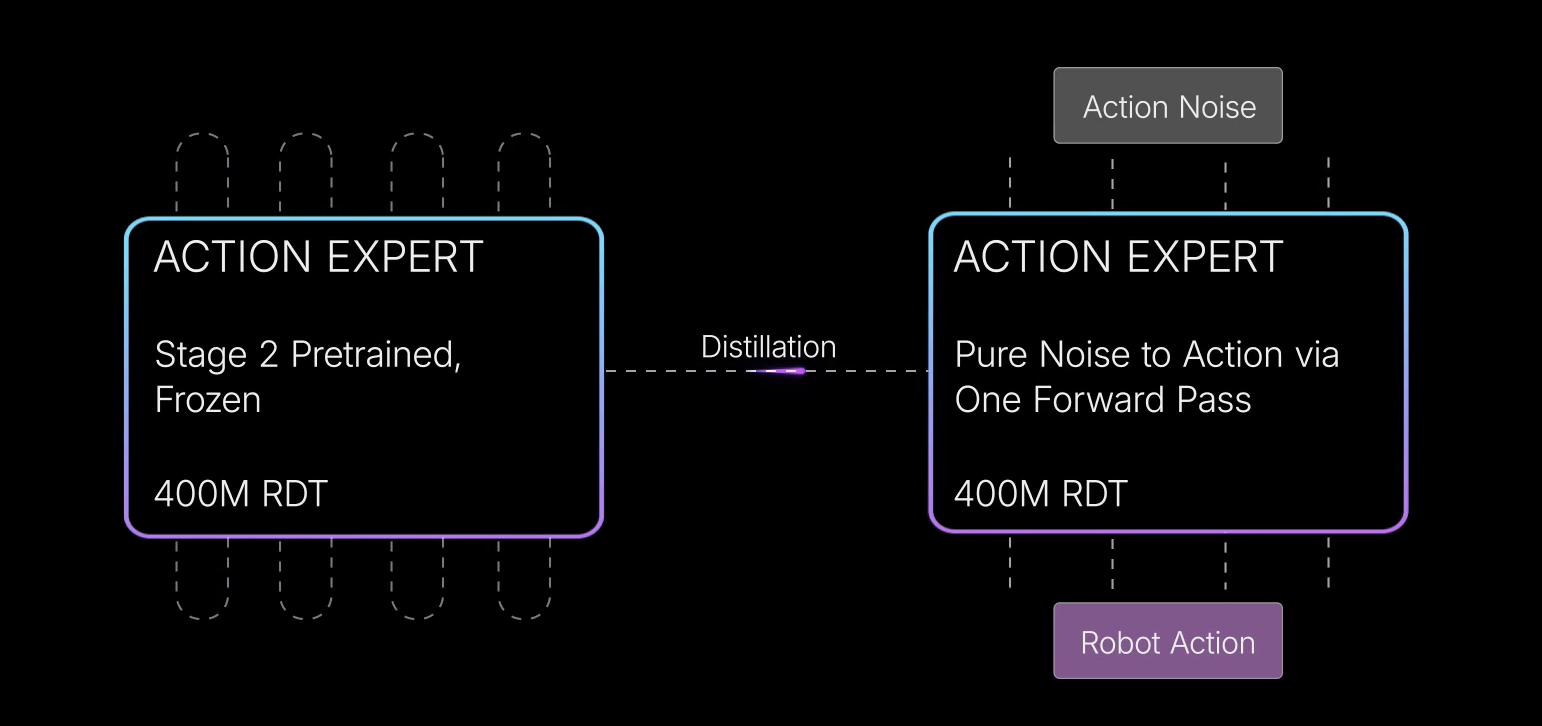
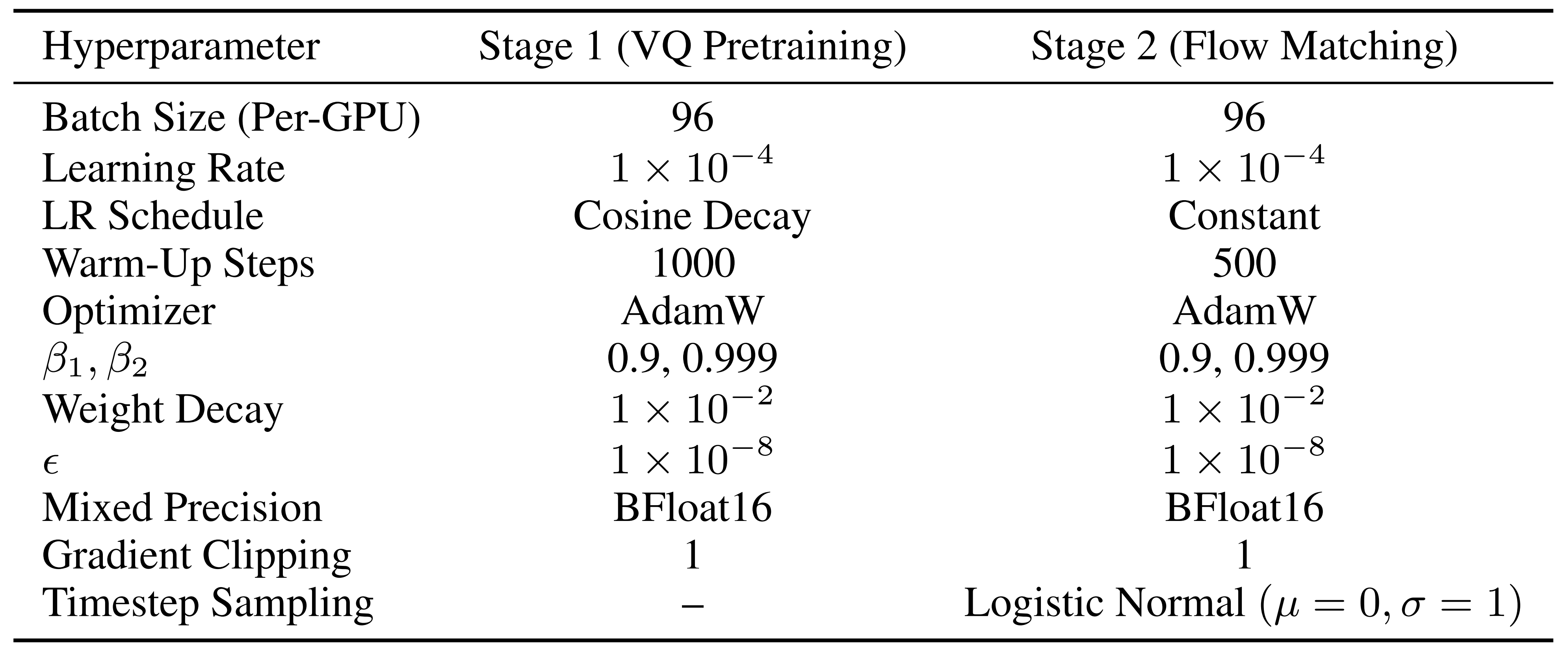
关于超参数和训练细节,请参见附录 C
对于平台和数据流水线,作者使用 PyTorch(链接到 PyTorch 代码库)和 DeepSpeed(链接到 DeepSpeed 代码库)实现他们的训练框架,以支持高效的分布式训练
- 他们的基础设施核心组件之一是高吞吐量的WebDataset(链接到 WebDataset 代码库)流式处理。且将所有数据集转换为 POSIXtarshards,并使用 Resamplemode,从而实现无 epoch 边界的无限数据流
- 来自异构源的数据在训练过程中通过 wds.RandomMix 动态混合,使得能够在训练过程中按需调整不同数据集的采样权重
1.2.1 阶段一 基于残差矢量量化RVQ的VLM离散化预训练
如前所述,扩散模型在 VLA 训练中主要存在两个问题:收敛速度慢,以及预训练 VLM 中离散概率知识的退化
为缓解这些问题,作者首先选择使用交叉熵损失对 VLM 主干网络进行预训练,然后再进行扩散训练,这与其原始训练目标保持一致。这样有助于有效保留模型中宝贵的预训练知识,并且还可以在训练过程中受益于额外加入的视觉-语言数据
如图6所示
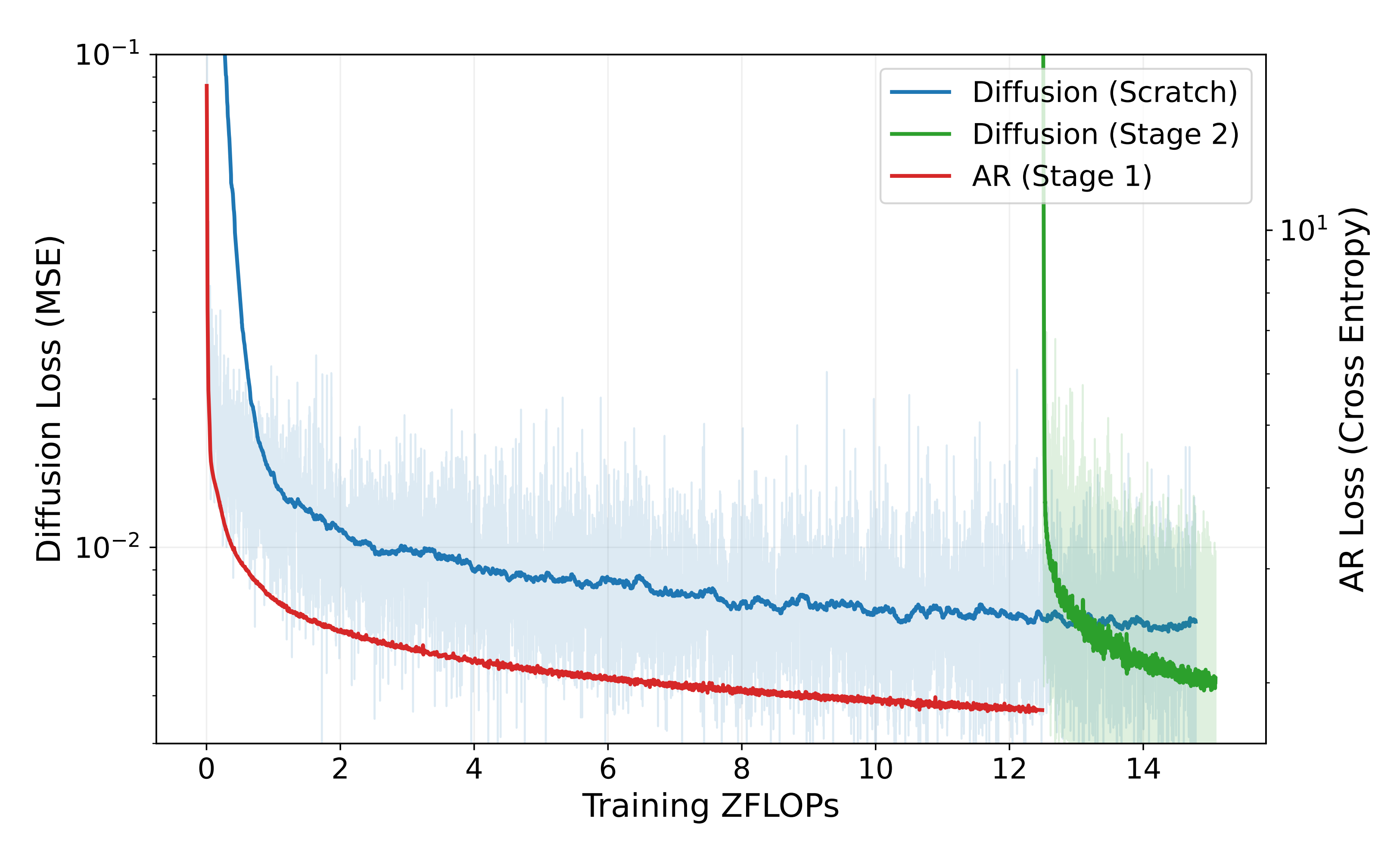
作者宣称,他们的实验表明,与从一开始就直接使用扩散损失进行训练相比,这一离散化预训练阶段显著加速了VLA模型的收敛(说白了,自回归训练快 推理慢,扩散策略 训练慢 推理快)
首先,对于RVQ 分词器
为了便于交叉熵训练,作者采用RVQ
- Van Den Oord et al., 2017
- Esser et al., 2021
- Lee etal., 2022
进行离散化,因为其具有很高的压缩效率
- 具体而言,首先使用一维时间卷积神经网络(CNNs)
将连续动作片段
编码为个
维的潜变量,记作
- 对于每个
,从
开始,作者通过深度为
的迭代过程对其进行量化——记为公式1:
- 对于
,其中
是深度为
、大小为
的可学习codebook
由此
将作为的token 索引
而
将是量化结果,其中是反向1D CNN 解码器
- 作者通过最小化以下损失来训练tokenizer——定义为公式2
上面这段 可能不太好理解,为了方便大家更好的理解,我再详细解释下
首先,上面这段介绍的是残差矢量量化(Residual Vector Quantization, RVQ)分词器的工作原理
- 在机器人领域,动作(比如机械臂移动的速度、角度)通常是连续的数值,而大语言模型(VLM)更擅长处理离散的“词元”(Token)
- RVQ 的目的就是把连续的机器人动作,高效地压缩并翻译成离散的“动作词典”里的索引(Token),让语言模型能看懂并预测
具体怎么操作呢
- 特征编码
机器人的一段连续动作序列被称为(包含
————
系统首先用一个一维卷积神经网络(CNN,记作)
把这个长长的动作序列“浓缩”成
大白话:把你做的一整套复杂动作,提取成几个关键的“特征点”- 残差量化 (核心循环,对应公式 1)
对于每个提取出的特征向量,设定初始残差
,然后进行深度为
码本(Codebook,记作),它就像一本字典,里面预先存了
):拿原始特征
去第一本字典里找,找到最像它的那个标准向量,记下这个向量在字典里的编号
此时,真实特征和标准向量之间肯定有误差,这个误差就是残差(用真实值减去标准值)
):拿着第一步剩下的残差
。然后计算新的残差
循环往复:一直做
结果:原本一个复杂的连续向量,这就变成了离散的 Token
————
大白话比喻:假设你要付 186 块钱(真实特征)。第一本字典只有一百元的钞票,你选了 1 张(记录:1张百元),还差 86 块(残差);第二本字典只有十元钞票,你选了 8 张(记录:8张十元),还差 6 块(新的残差);第三本字典是一元硬币,你选了 6 个。最终,186 这个数字被量化成了序列[1, 8, 6]- 第三步:重构解码 (Decoding)
既然变成了字典编号,怎么还原回动作呢?
就是把刚才每一层字典里选中的那个标准向量加起来:
然后通过一个解码器(反向 CNN,)把特征还原成连续的动作序列
- 第四步:损失函数 (对应公式 2)
为了让这个模型既能精准量化,又能让字典(码本)学到有用的东西,需要用公式 (2) 进行训练:
这三项分别代表::量化还原后的动作
必须尽可能和真实动作
:
意思是 stop-gradient(停止梯度更新)。这一项固定住编码器提取的特征
去主动靠近真实特征
:反过来,固定住字典向量,强迫编码器提取出的特征
是一个权重系数
总之,以上定义了一个能把连续动作数据像切香肠一样,一层层剥离误差,最终变成离散整数词元 (Token) 的压缩系统
这样大语言模型就能像“读句子”一样“读懂并生成”机器人动作了
为缓解众所周知的码本坍塌问题,作者在 RVQ 训练过程中采取了多项措施,包括:
- 降低码本维度(Yu et al., 2021)
- 在式 (1) 中用余弦相似度替换欧氏距离(Yu et al., 2021)
- 通过指数移动平均(EMA)(Razavi et al., 2019)平滑码本更新
- 以及每隔固定周期重启不活跃的码本条目(Zeghidouret al., 2021)
如图 8 所示
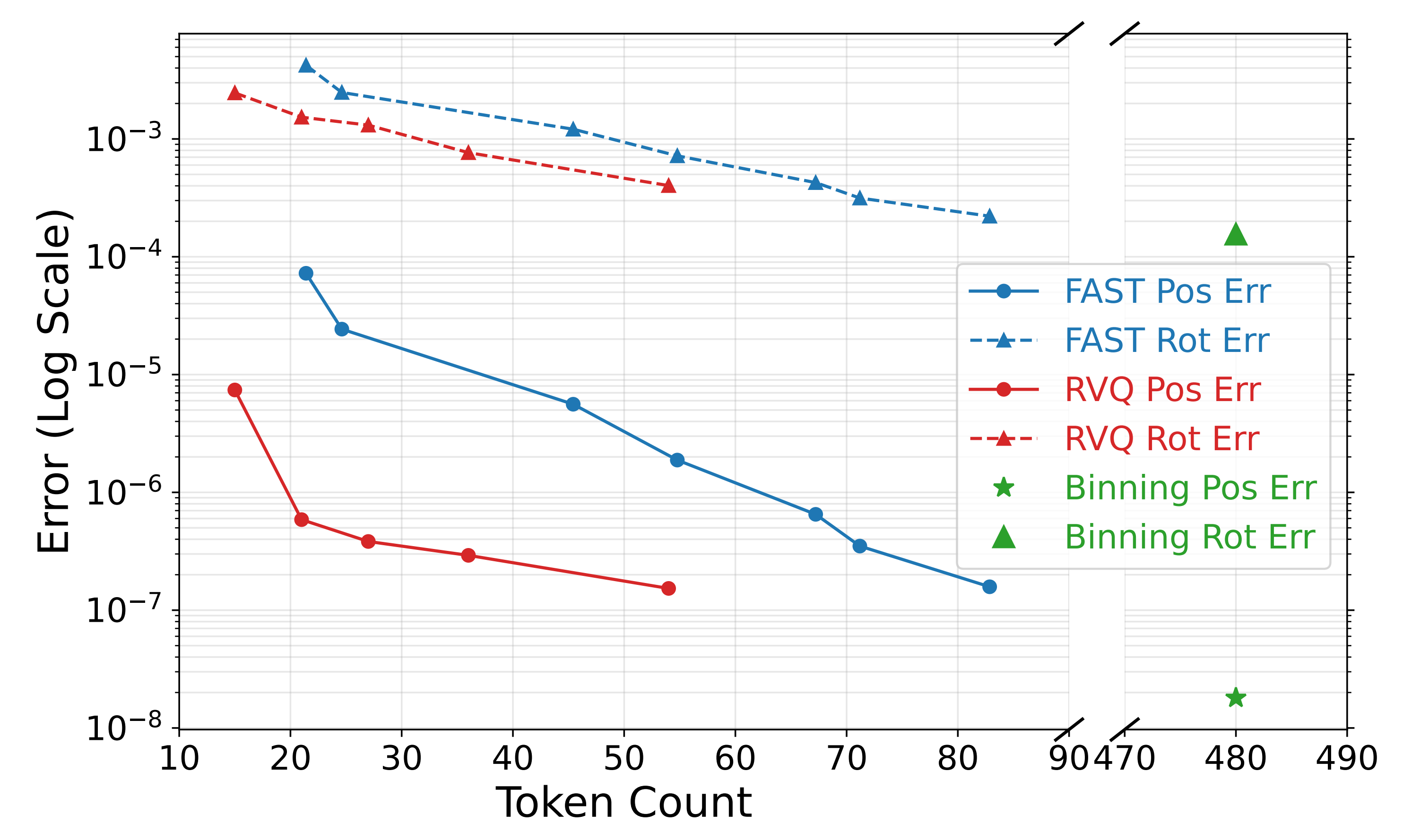
在量化误差相同的前提下,RVQ 能将动作片段压缩为更少的token,从而显著加速大型 VLA 的收敛
其次,对于模型细节
作者选择了 7B Qwen2.5-VL(Bai et al., 2025)作为VLA 主干模型——其在大规模视觉-语言语料库上进行预训练

- 且作者将多种模态投射到统一的潜在空间中进行学习:视觉和语言由Qwen 编码器处理,动作由他们的 RVQ 模型处理
且在词表中预留了出现频率最低的 1024 个条目,用于表示这些动作 token - VLA 模型在一个由作者的 UMI数据集,与一小部分视觉-语言数据构成的混合数据集上训练了 128K 次迭代,采用下一 token 预测作为目标
总之,在第一阶段中,作者将 Qwen2.5-VL 主干网络与机器人领域对齐。模型通过标准的交叉熵目标被训练来预测离散化的动作token
- 为了确保鲁棒的视觉表征,作者采用一整套图像增强操作
且使用标准的颜色抖动(亮度、对比度、饱和度、色相),并辅以随机组合的图像损坏序列,包括注入高斯/拉普拉斯噪声、运动模糊以及 JPEG 压缩伪影- 且在训练过程中采用了余弦学习率调度器,并在最后 8K 次迭代中额外通过指数衰减对其进行退火
1.2.2 阶段二 基于流匹配的连续动作专家网络训练
为了在推理效率上超越自回归模型,作者引入第二阶段训练:冻结 VQA 主干网络,并使用 Conditional Flow Matching(CFM)来优化 RDT 动作专家
在训练配置上
- 作者使用Logistic Normal 分布(µ = 0, σ = 1) 在训练过程中对时间步t 进行采样,而不是使用均匀分布。这样在经验上可以将训练预算集中到流轨迹中最复杂的区域(t ≈0.5)
- 为了监控收敛情况,每2,500 步在留出的验证集上使用完整的多步积分来评估模型
且报告Action MSE、末端执行器Position MSE、RotationGeodesic Error 和Gripper Width MSE,并基于聚合的验证误差选择检查点
具体而言,在该阶段,作者冻结第 1 阶段预训练得到的 VLA 主干网络,并单独训练一个动作专家模型
- 该专家模型是 RDT-1B的一个 4 亿参数变体
通过将多头注意力
替换为
分组查询注意力
以优化速度 - 它通过扩散过程生成连续动作,该过程以“被冻结的 VLA 主干网络编码得到的自然语言和图像表征 ”为条件
具体而言,动作专家利用交叉注意力,将来自 VLA 主干网络各层的潜在特征融入其中
即动作专家由一个 Flow-Matching 损失进行监督(Lipman 等,2022)——定义为公式3:
其中
是flow-matching 时间步
是具有可训练参数
的去噪网络
以及是冻结的VLA主干网络
在这里,作者将含噪动作片段记为,其中
是随机高斯噪声
- 真实速度(ground-truth velocity)给定为
在推理过程中,作者首先采样一个高斯噪声向量:,然后对其进行去噪以得到一个干净的动作片段——定义为公式4
其从 到
在实践中,作者将步长设置为 , 对应于5 个积分步
此外, 由于在积分过程中保持不变,只计算一次,在作者的实验中,他们随机初始化了动作专家, 并在他们的UMI 数据集上训练了66 K 次迭代, 同时冻结VLA 骨干网络(在阶段1 中训练得到)
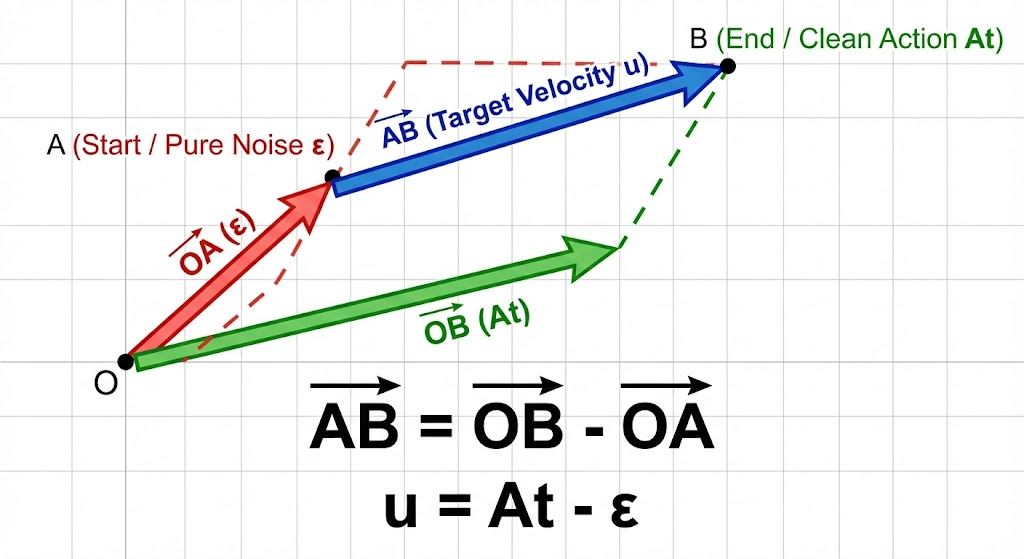
这里面 依然有一个可能一些朋友困惑的问题,即对于
- 你可能会误以为:
是所添加的实际噪声,
是纯噪声,那按道理 不应该是:
么
相当于纯噪声 减 不带噪声的干净动作,等于所添加的实际噪声- 实则不是,具体详见此文《π0——用于通用机器人控制的VLA模型:一套框架控制7种机械臂(基于PaliGemma和流匹配的3B模型)》的1.2.1节
当然,为了方便大家更好的理解,我也还是不厌其烦的给大家再解释说明下
- 这里的问题在于把
理解成了“所添加的实际噪声”
但在流匹配的数学语境下,的物理意义是“速度向量”(Velocity),它指明了状态演变的方向
具体而言,在时间
注意这里的时间
当时(起点):
,这代表推理(生成)的最开始,状态是纯噪声
当(终点):
。这代表推理的结束,状态变成了干净的动作数据
- 为什么是
?
在推理(生成)阶段,模型要做的事情是:从纯噪声
那么,你应该往哪个方向开?在向量数学中,从点(起点
(终点
目标速度向量
总之
- 在公式 (3) 中
神经网络训练的根本目的,就是去拟合/预测这个固定的“速度方向”
- 预测准了之后,在公式 (4) 的推理阶段
模型就能顺着这个方向,一步步()把纯噪声推演成清晰的机器人动作
————
当前位置 = 也就是:上一个位置 + 速度时间
:你现在所处的带噪状态(位置)
:你往前走的一小段“时间步长”(比如每次走 0.1 或 0.2)
:你走完这一步后,到达的下一个更清晰的状态(新位置)
1.2.3 基于扩散蒸馏的单步动作生成器构建
- 首先,如式 (4)
所述的动作生成过程,对于每个动作片段需要在去噪网络中顺序执行五次前向传播,这带来了相当可观的推理开销
这种延迟在诸如打乒乓球等对动态性能要求很高的任务中构成了实际瓶颈 - 为克服这一限制,作者采用扩散蒸馏diffusion distillation(Salimans & Ho,2022; Chen et al., 2023),将第二阶段训练得到的专家策略转换为单步生成器
如图 7 所示
该技术大幅降低了模型时延,使规模 VLA能够实现远快于体量小得多的模型的推理速度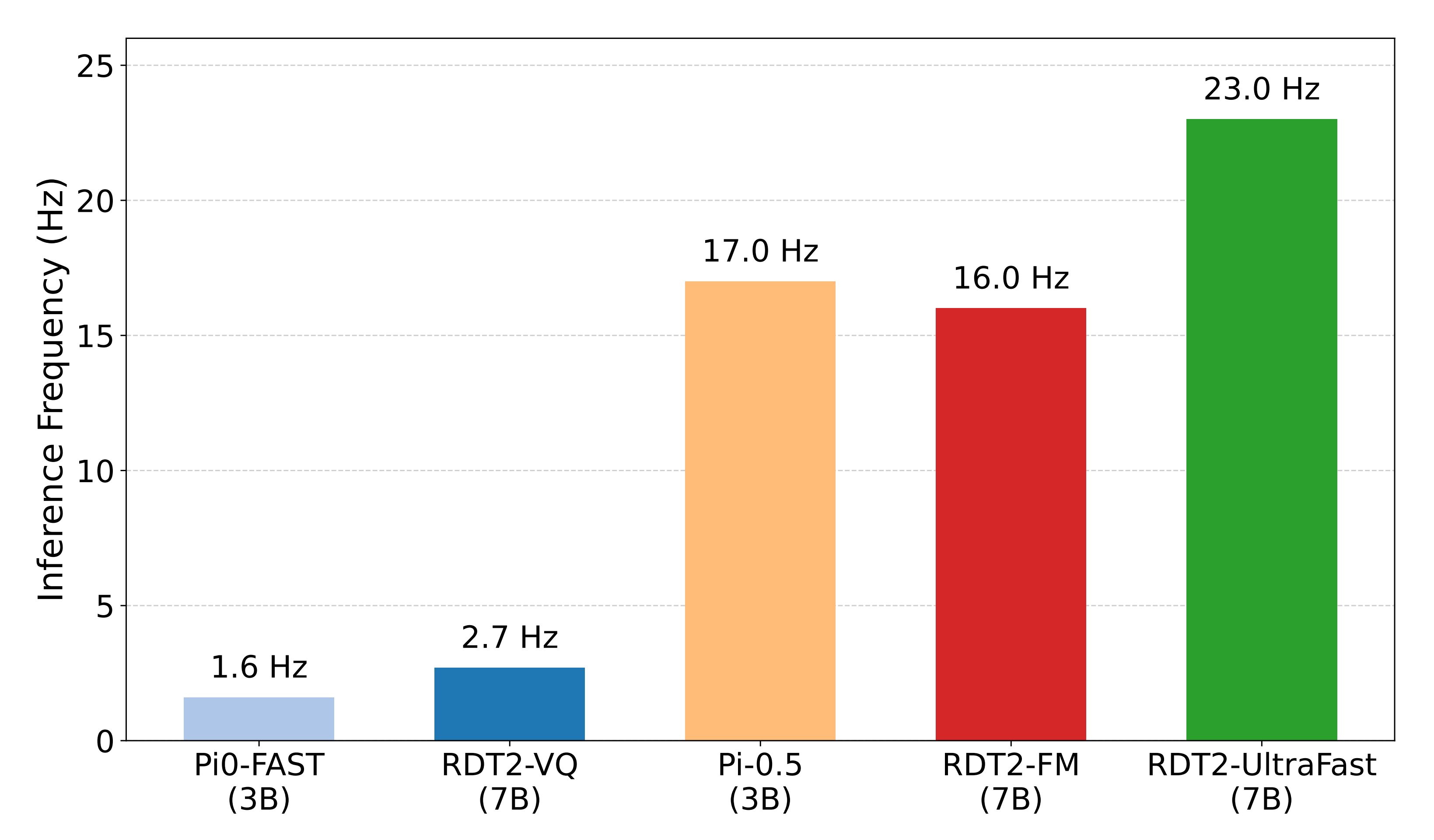
具体而言,是扩散蒸馏
对于高度动态的任务,作者使用以下回归目标函数,将动作专家模型蒸馏为一个参数为 的单步生成器:
其中
表示式(4)中的生成过程
- 而
是目标单步生成器
需要注意的是
而是可训练的,由
与以往的蒸馏实践不同,- 同时,它通过显著降低蒸馏得到的策略对预生成数据过拟合的风险而带来显著收益,而对预生成数据的过拟合正是基于回归的蒸馏方法中的常见陷阱
为了实现高频率推理,作者将阶段3 策略蒸馏为单步生成器
- 且将阶段2 模型冻结作为教师模型,并训练其学生副本在一次前向传播中回归教师的多步输出
- 学生模型在条件t = 0 下进行,并最小化其预测速度与教师有效轨迹之间的均方误差(MSE)
1.3 实验:泛化性、缩放定律、复杂任务、各部分对性能提升的贡献度
如原论文所述,作者旨在通过增加数据的数量和多样性来获得具有更强泛化能力的机器人模型,并将在本节中对这一点进行严格验证
尽管在评估前对 VLA 进行微调是常见做法,作者希望在“4U”设定下对RDT2 进行零样本测试——即未见过的机体(Unseen embodiment)、未见过的场景(Unseen scene)、未见过的物体(Unseen object)以及未见过的指令(Unseen instruction)
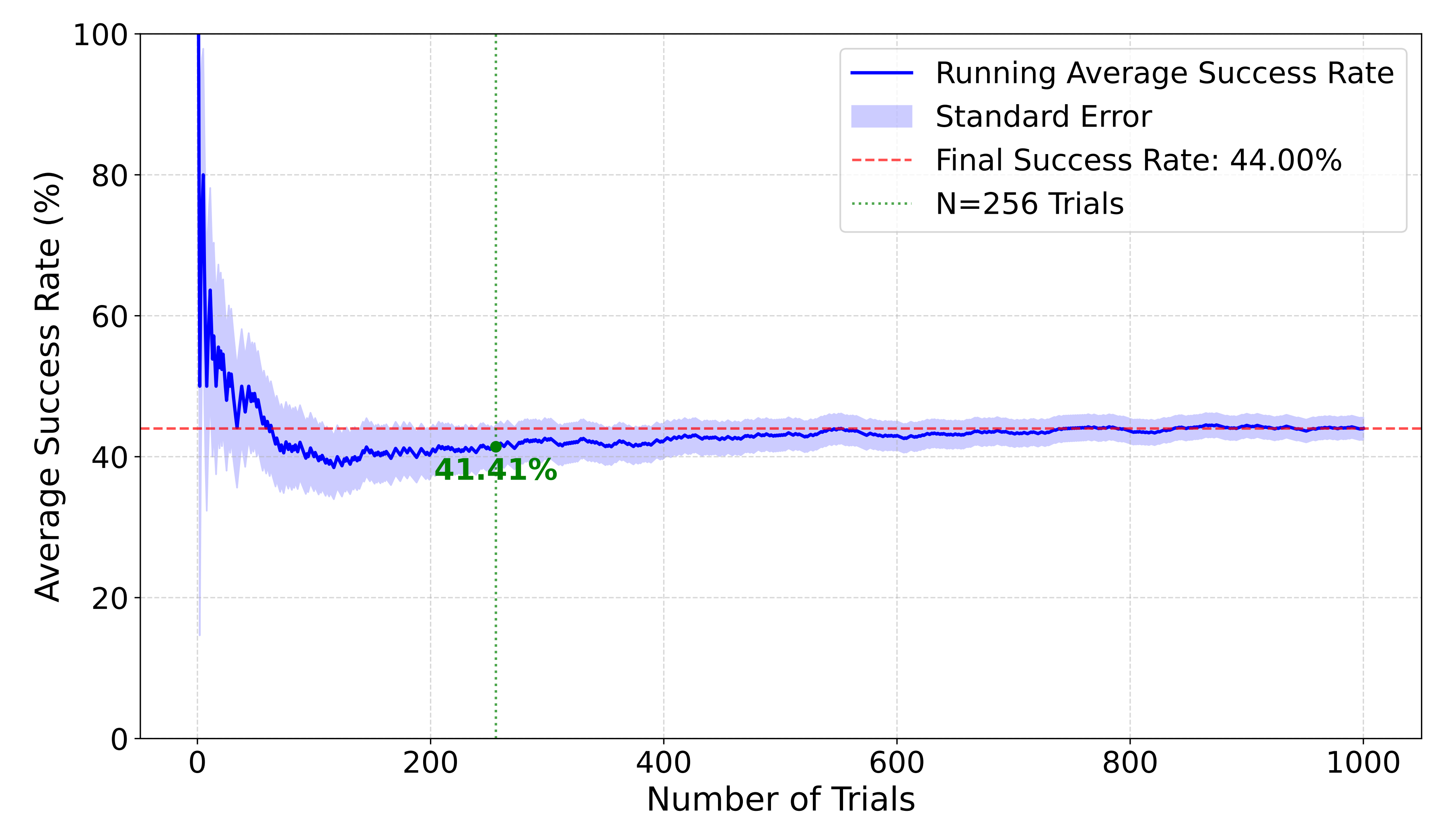
在定量评估方面,作者将最多进行 1000 次重复实验,以确保方差足够小,详见图4——在重复试验中的统计成功率收敛曲线(Pick任务,RDT2-FM)
这一点在许多以往研究中是缺失的,却对结果的可靠性至关重要
具体而言,作者的一系列实验将回答以下问题(实验细节见附录 D):
- Q1:RDT2 是否能够有效泛化到此前未见过的具身形式、物体、场景和指令上,而这对以往的 VLA 来说是难以实现的?
- Q2:在训练数据规模和模型规模方面,RDT2 的可泛化性遵循怎样的缩放定律?
- Q3:在针对具有挑战性的灵巧操作、动态或长时间跨度任务的微调实验中,RDT2 与其他 VLA 相比表现如何?
- Q4:训练策略中的各个组成部分分别是如何提升RDT2 的性能的?
1.3.1 零样本实验
为回答 Q1,在没有进行任何微调的情况下,作者将RDT2 部署到从未见过的物理形态上,并在包含未见过物体、场景和指令的任务上对其进行了评估
- 该模型仅在 UMI 人类数据和视觉-语言对上进行预训练,没有使用任何机器人数据
- 且考虑的是简单的开放词汇任务:拾取由自由形式语言指定的物体、拾取特定物体并将其放置到指定位置、用任意抹布擦拭桌子、按下任意按钮等并摇动任意物体。具体的任务设置如图15所示
为了保证实验的严谨性
- 首先,作者选择了三个在训练集中从未出现过的场景用于测试。这些场景是可控的,并且位于光照恒定的实验室中,从而确保结果的低方差和可复现性
- 其次,另外购买了一批新的物体用于测试,确保这些物体在训练集中是未出现过的
- 第三,为了验证指令同样是未见过的,依据训练集对测试指令进行了去重
图 3 的结果表明——RDT2 的零样本实验结果。误差条表示标准误差
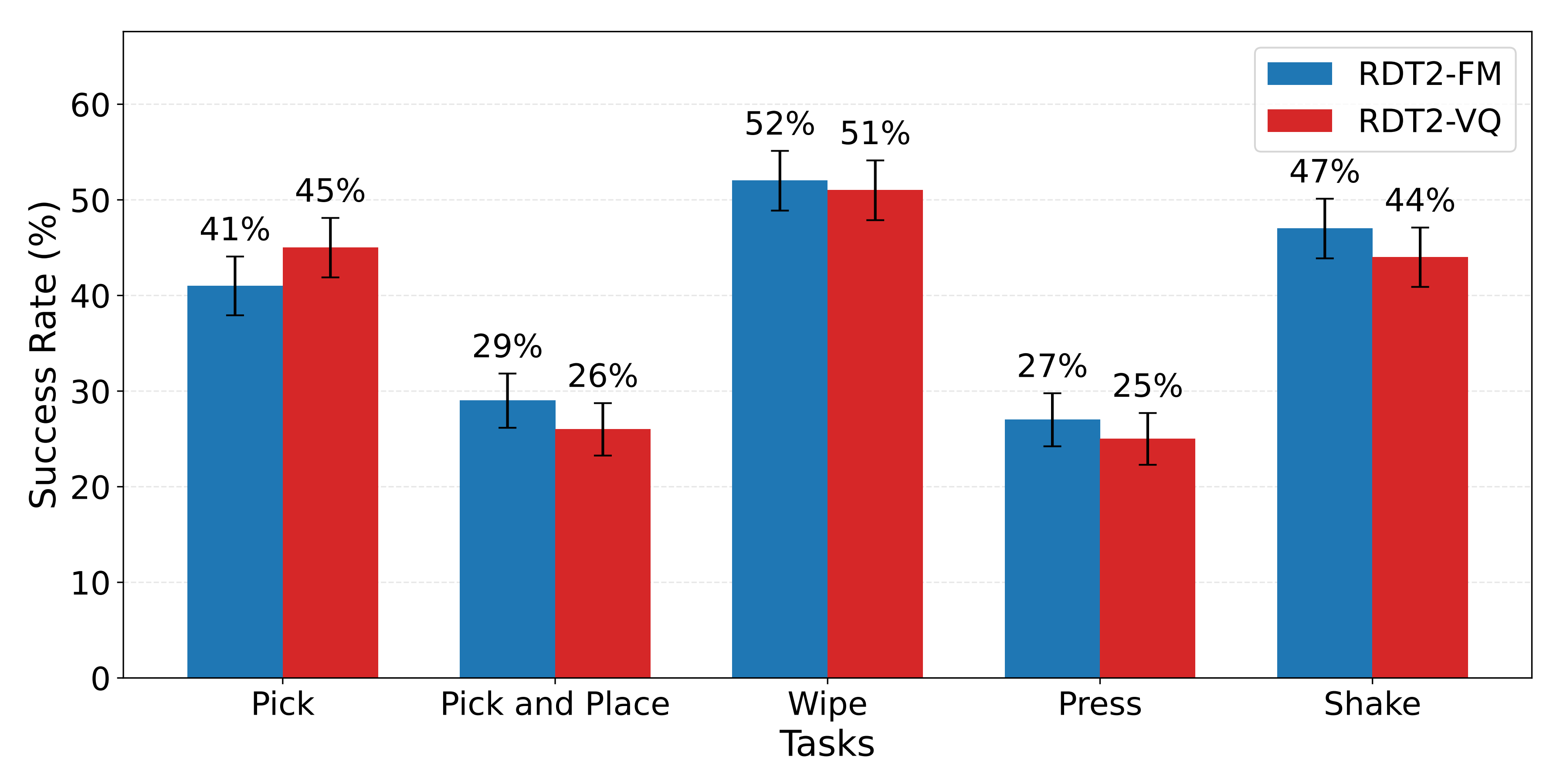
- 两种 RDT2 变体都能够在未见过的物体、场景、指令和具身形式的各种组合上完成基本的开放词汇任务
尽管成功率并不高,但这一结果具有深远意义:仅基于人类数据训练的大模型就能够在包括具身形式在内的多个因素上实现组合式泛化 - 此外,作者观察到,在标准误差方面,RDT2-VQ 与 RDT2-FM 之间没有显著差异
结合图7,这表明作者的第二阶段训练能够在不降低性能的前提下提升模型的推理效率
且为验证经验成功率的可靠性,作者在 Pick任务上使用 RDT2-FM 模型进行了 1,000 次实验
- 如图 4 所示
随着实验次数的增加,成功率逐渐收敛,而由标准误差形成的区域始终包含最终值(红色虚线)。这证明了实验结果的可靠性
- 然而,只有在实验次数足够多的情况下,标准误差才能降低到可接受的水平。为在可靠性与人工成本之间取得平衡,作者在后续所有实验中均选择进行 256 次试验
1.3.2 数据与模型规模的缩放定律
为回答问题 2 并精确测量缩放行为,作者采用了以下实验方案:不同规模的 RDT2-VQ 模型均在完整数据集上使用均匀采样训练一个epoch
- 在这一单个epoch 过程中,在多个中间检查点评估训练损失。由于每个数据token 只被使用一次,训练损失可以指示模型在未见样本上的泛化能力
- 这一设计使得能够将每个检查点与一个精确数量的有效算力『
相关联,其中N 是模型大小,而D 是截至该时间点已处理的数据样本(即,tokens消耗) 数量』
因此,可以将训练损失绘制为模型大小(), 从而分离它们对性能的影响
图5展示了 RDT2 的缩放定律曲线『RDT2 的缩放律。左:在不同模型参数规模下,训练损失随已消耗(不重复)token 数量的变化关系。“Total”参数包含视觉编码器。右:在不同训练数据量(以 token 数衡量)下,训练损失随模型总参数量的变化关系』
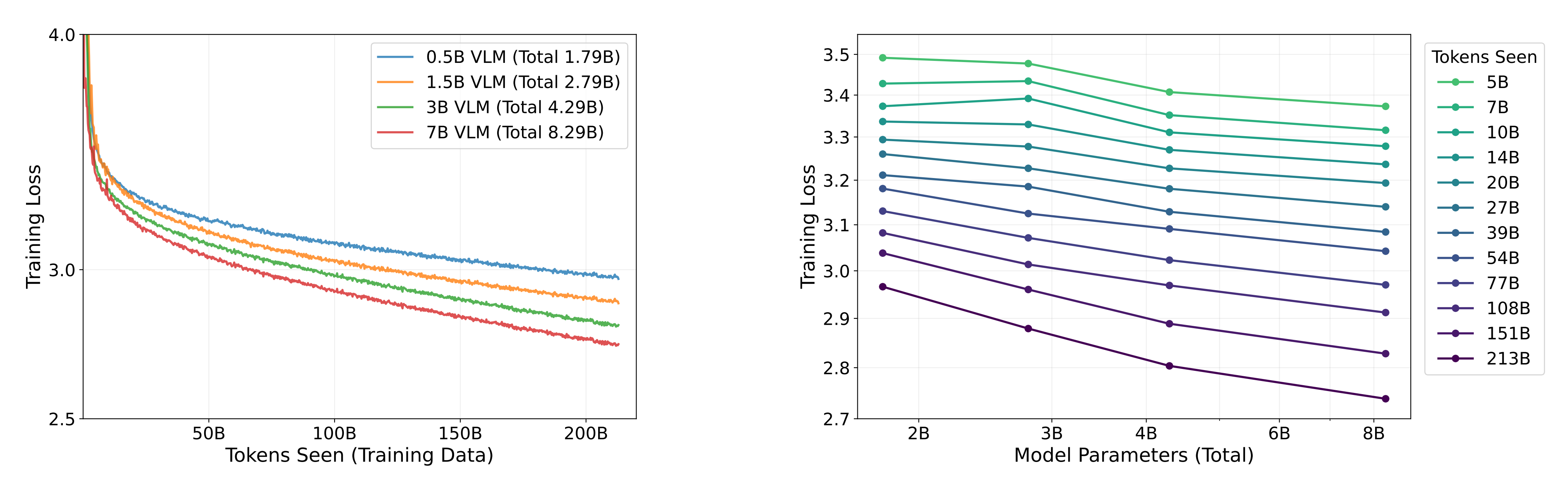
其结果与(Hoffmann etal., 2022; Kaplan et al., 2020)中的结果相吻合:
其中拟合结果表明E ∼2.1108, A ∼4.3754× 103, α ∼0.4402, B ∼1.7906 × 102, β ∼0.2251
这个缩放定律公式表明,同时增加模型参数数量和数据规模,会带来模型性能显著且持续的提升。这意味着,识别出高度可扩展的数据收集方式——例如来自可穿戴设备的数据采集——并对这类数据源进行规模化扩展,对提升模型智能至关重要
1.3.3 微调实验
为回答 Q3,作者将 RDT2 与当前最先进的基线进行比较:π0-FAST(Pertsch 等,2025)和π0.5(Intelligence 等,2025)
作者将RDT2 与两个基线模型进行比较:π0.5 和π0-FAST(Black et al.,2024; Pertsch et al.,2025; Intelligence etal., 2025)
且使用官方的OpenPI 代码库实现了这两个基线模型(指向OpenPI 代码库的链接)。没有修改架构,只修改了配置文件和检查点路径,以确保公平比较
- 对于π0.5,使用了标准的基于流的公式
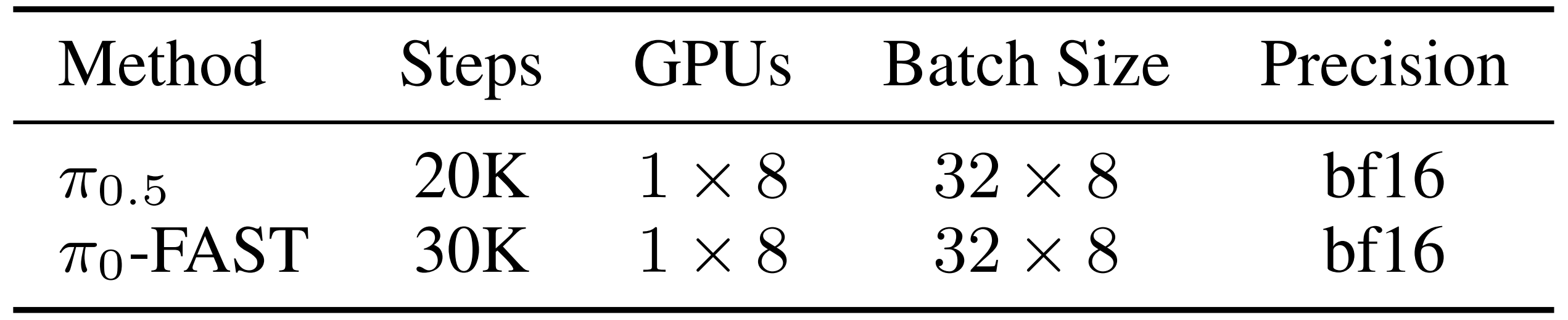
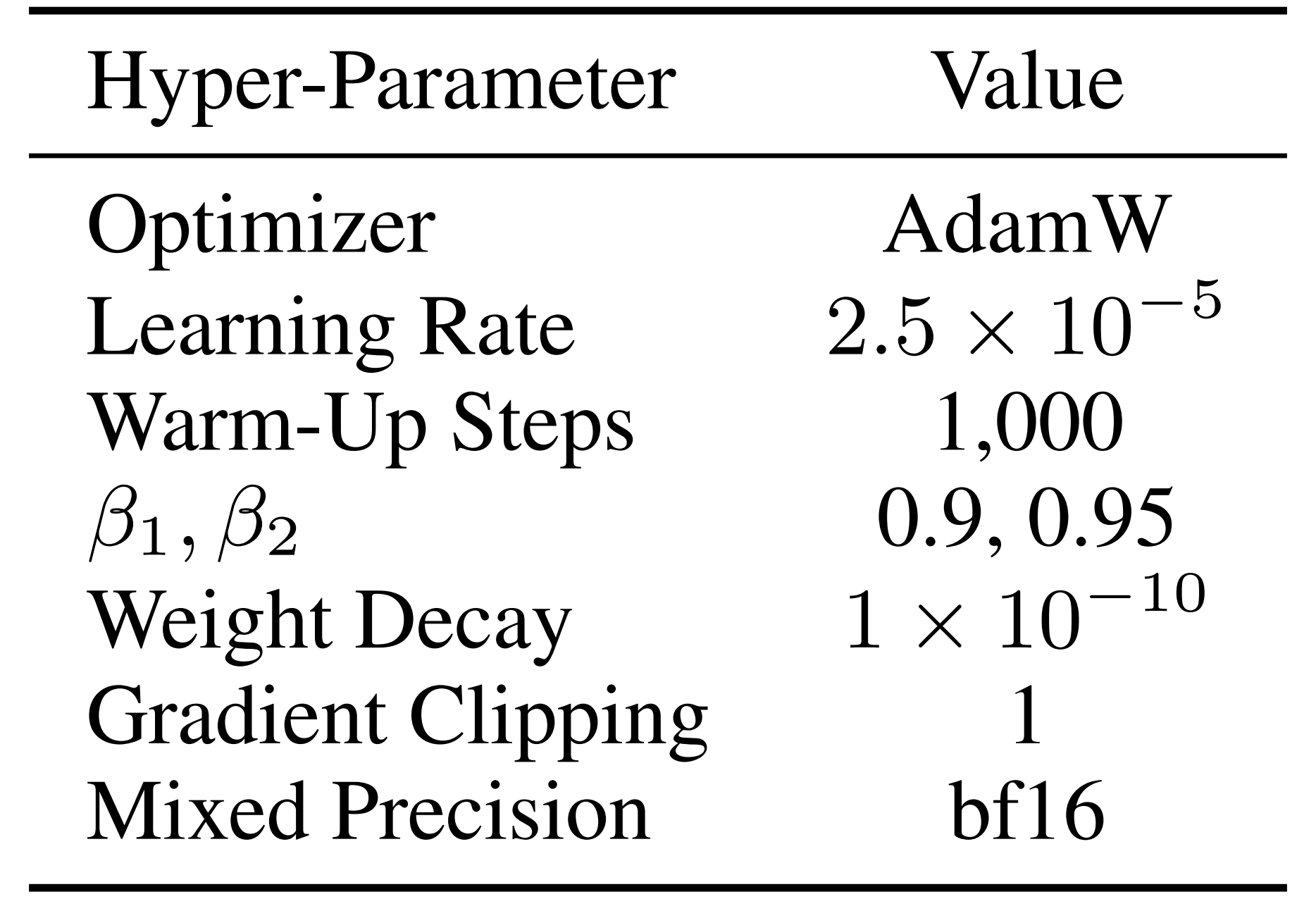
在一个具有8 个GPU 的节点上训练模型20,000 步,每个GPU 的批大小为32
配置遵循官方的π0.5 设置,采用离散状态输入、24 的动作视野以及32 维的动作空间。且将动作专家初始化自Gemma-300M 权重,将语言骨干网络初始化自Gemma-2B
训练使用bfloat16 精度、AdamW 优化器,以及1.0 的梯度裁剪- 对于 π0-FAST,作者在与策略相同的 RVQ 动作数据上训练 FAST tokenizer,遵循标准的 FAST 训练流程
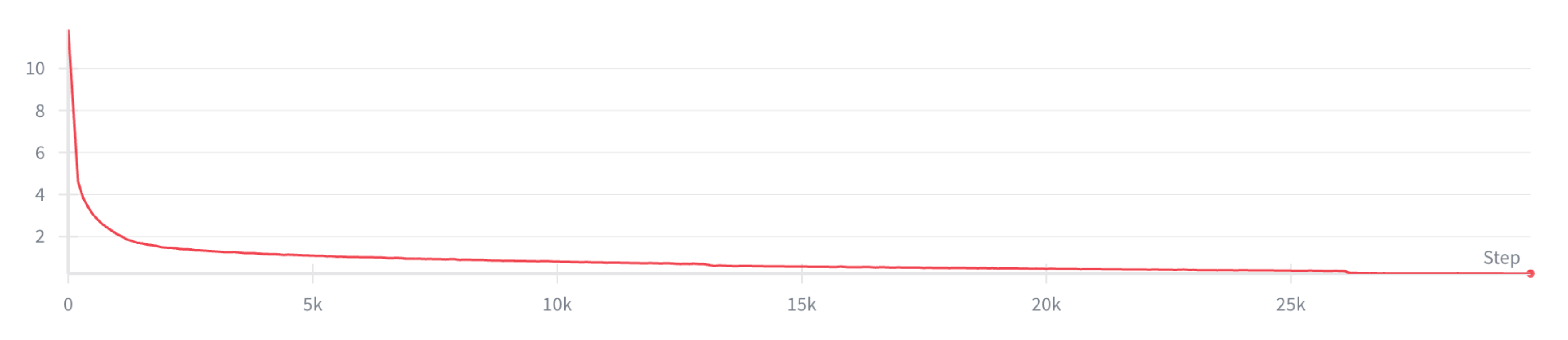
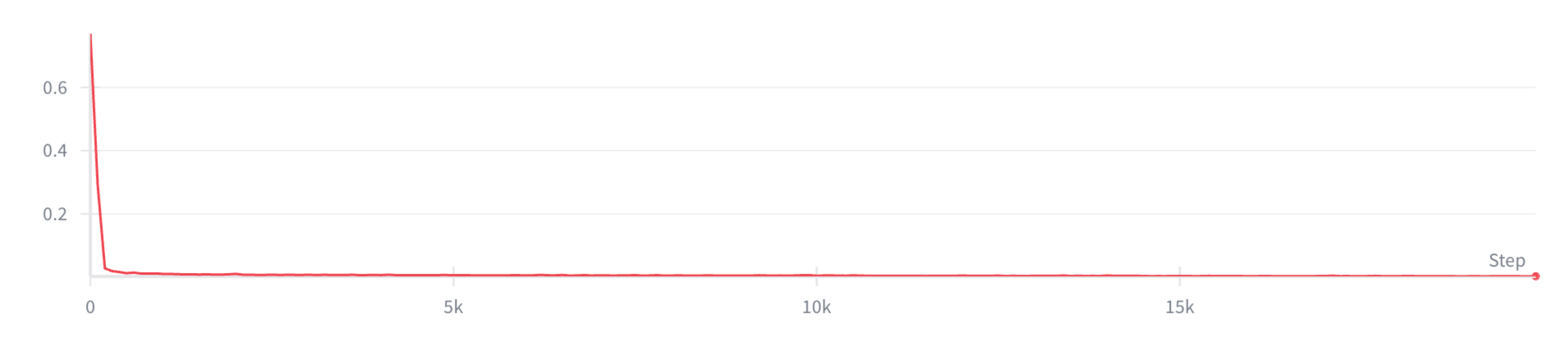
训练完成后,作者固定该 tokenizer,并将其用于策略训练,且在一个配备 8 块 GPU 的节点上对策略进行了 30,000 步的训练,每块 GPU 的批处理大小为 32
其他优化器和调度器的设置与 π0.5 的设置相同最终,作者针对每个任务对每个基线模型进行训练,直至稳定收敛
见图 13
和
图 14
至于
表 11 详细列出了训练资源
表 12 列出了超参数
作者对每个模型在具有挑战性的真实世界任务上进行微调,其中包括长时程任务(例如清理餐桌)、可变形物体操作(例如叠衣服、拉开拉链),以及动态任务(例如打乒乓球、快速按按钮)
有关任务描述请参见图16

本实验中作者使用 RDT2-UltraFast 变体
如表 2 所总结,RDT2 在所有任务类别上都展现出更优的性能『RDT2 与基线模型在具有挑战性的真实世界任务上的微调性能。进度得分为已完成子任务所占的平均百分比。对于按按钮任务,我们报告策略与人类专家远程操作员之间的反应时间差值(人类专家平均反应时间为 2661 ms)。需要指出的是,π0-FAST 模型未能生成足够快速、可用于打乒乓球的策略』
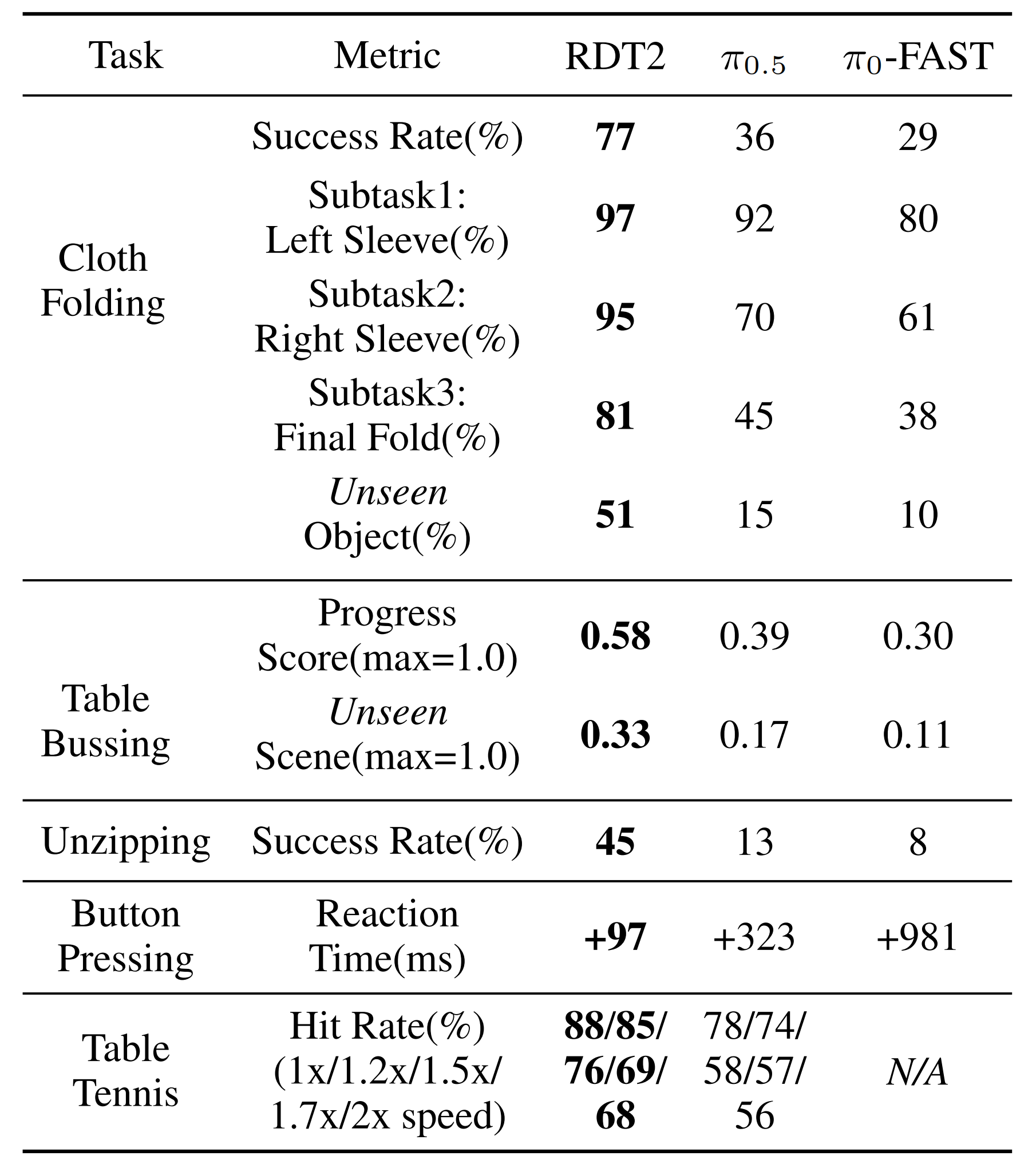
- 具体来说,在可变形物体操作任务中,RDT2 的成功率高于所有基线方法,尤其是在复杂的、多步骤的折布任务上表现突出
值得注意的是,在未见过的物体上,其表现比基线高出 4 倍,体现出很强的泛化能力 - 对于长时程的桌面清理(tablebussing)任务,RDT2 不仅将完整任务的成功率提升了一倍,还取得了显著更高的平均进度得分,表明其在长时程设置下具有更好的鲁棒性
- 在动态任务中,得益于第二阶段的蒸馏,RDT2 展现出更好的时间响应性(更快的按键反应时间)以及在乒乓球任务中更高的击球成功率
总之,作者宣称,他们的微调实验证实,RDT2 能够将其预训练知识有效迁移到多种具有挑战性的下游应用中,并达到当前最先进水平的性能
1.3.4 消融实验
为回答 Q4,作者对 RDT2 的关键组件进行了消融实验,包括自回归(AR)与扩散(第 1、2 阶段)的混合训练、用于动作离散化的 RVQ,以及第 3 阶段的蒸馏过程
- 图 6 对仅使用扩散训练(同时训练骨干网络和动作专家)与所提出的两阶段自回归(AR)+ 扩散框架进行了比较
AR 预训练避免了对离散VLM(视觉-语言模型)知识的破坏,并提供了良好的初始化,从而实现了更快的收敛。此外,作者发现 AR 预训练对于获得更低的最终损失也至关重要 - 图7展示了不同基线方法的推理速度
在自回归设置下,由于使用 RVQ tokenizer 后动作 token 数量更少,RDT2-VQ 表现出最高的推理频率
在扩散模型设置下,得益于第 3 阶段的一步扩散蒸馏,RDT2-UltraFast 成为速度最快的方法 - 图 8 在不同的表示 token 预算下评估了离散化误差
由于 RVQ 提供了更紧凑的潜在空间用于信息压缩,因此 RVQ 的误差始终低于 FAST tokenizer,并且最多可节省约三分之二的token
均匀分箱方法(Brohan et al., 2022;Zitkovich et al., 2023)虽然取得了最低的误差,但需要远多得多的 token,从而导致其效率很低
总之,RDT2作为一种机器人基础模型,旨在突破数据稀缺、推理时延以及跨形体泛化等方面的瓶颈
- 通过将超过 10,000 小时的大规模、与形体无关的数据集与一种新颖的三阶段训练策略相结合,作者宣称,他们成功弥合了大型VLM 的离散语义推理与运动控制所需的连续高精度之间的鸿沟
- 且通过高效的蒸馏机制保证了实时性能,并在新物体、新场景、新指令乃至全新机器人平台上展现出前所未有的零样本迁移能力
此外,在微调基准测试中,RDT2同样在灵巧操控、长时间跨度以及动态任务(如乒乓球)上达到了当前最先进的性能
// 待更

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 14
14 0
0- 0



 已为社区贡献77条内容
已为社区贡献77条内容

所有评论(0)