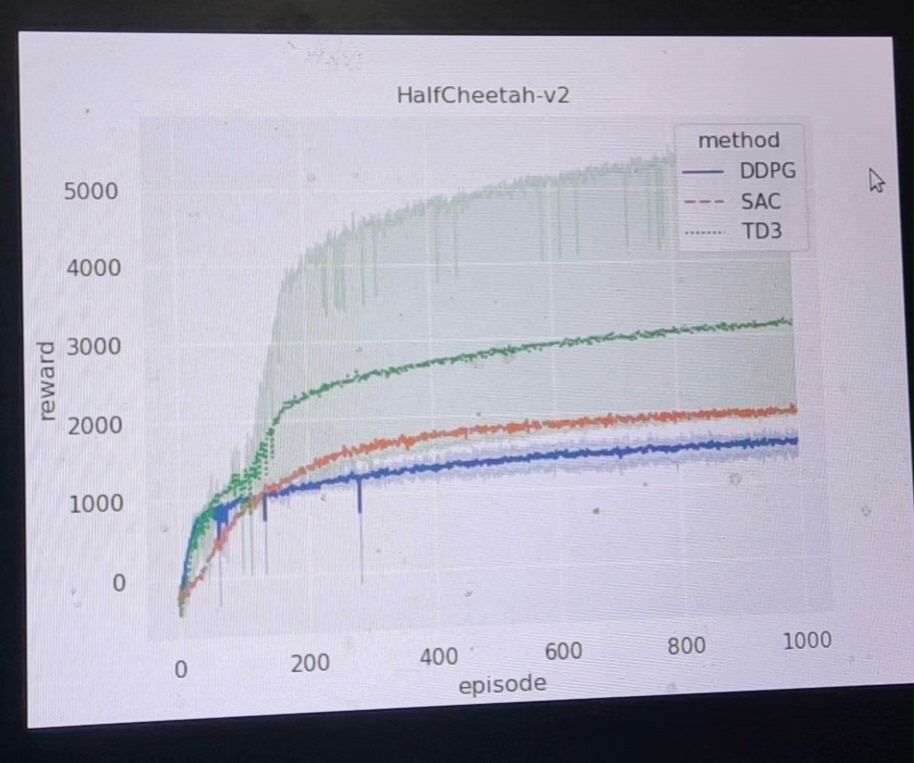
HalfCheetah-v2环境下深度强化学习算法代码功能说明
本项目围绕机器人MuJoCo仿真环境中的HalfCheetah-v2任务,实现了A3C(Asynchronous Advantage Actor-Critic)、DDPG(Deep Deterministic Policy Gradient)、SAC(Soft Actor-Critic)和TD3(Twin Delayed DDPG)四种主流深度强化学习算法,旨在通过多算法对比实验,验证不同算法在连
深度强化学习算法:DDPG TD3 SAC 实验环境:机器人MuJoCo
一、项目概述
本项目围绕机器人MuJoCo仿真环境中的HalfCheetah-v2任务,实现了A3C(Asynchronous Advantage Actor-Critic)、DDPG(Deep Deterministic Policy Gradient)、SAC(Soft Actor-Critic)和TD3(Twin Delayed DDPG)四种主流深度强化学习算法,旨在通过多算法对比实验,验证不同算法在连续动作空间机器人控制任务中的性能表现。项目代码结构清晰,每个算法均包含训练、测试及结果可视化模块,支持批量实验与数据统计分析,为强化学习算法在机器人控制领域的应用提供了完整的技术方案。
二、环境与依赖
(一)核心环境
- 仿真环境:HalfCheetah-v2(来自OpenAI Gym与MuJoCo,用于模拟猎豹机器人的连续动作控制任务,观测空间包含机器人关节角度、速度等状态信息,动作空间为6维连续控制信号)
- 计算框架:PyTorch(用于构建神经网络模型与自动微分计算)
- 并行计算:Python多进程(
torch.multiprocessing,仅A3C算法使用,实现异步训练加速)
(二)关键依赖库
| 库名称 | 核心用途 |
|---|---|
gym |
加载HalfCheetah-v2仿真环境,提供环境交互接口 |
numpy |
数据格式转换与数值计算(如状态/动作数组处理) |
pandas |
实验数据存储(如训练奖励记录保存为Excel文件) |
matplotlib |
结果可视化(绘制训练奖励曲线与测试分数分布) |
torch.nn |
构建算法所需的神经网络(Actor、Critic等模块) |
三、算法模块功能说明
(一)A3C算法模块(a3c1/a3c2/a3c3目录)
A3C算法通过异步多进程训练实现策略更新,每个进程独立与环境交互采集数据,并行更新全局网络参数,适用于高样本效率的连续控制任务。三个子目录仅训练参数(最大episode数)存在差异,核心逻辑一致。
1. 核心组件
- SharedAdam优化器:支持多进程共享的Adam优化器,确保各进程更新全局网络时参数状态同步,避免梯度冲突。
- ACNet网络:整合Actor(策略网络)与Critic(价值网络)的端到端模型:
- Actor:输出动作的高斯分布参数(均值
mu与标准差sigma),通过采样生成连续动作; - Critic:评估当前状态的价值,计算优势函数用于Actor策略更新。
- Worker进程:每个进程对应一个独立的环境交互实例,负责:
- 采集状态、动作、奖励数据;
- 基于时序差分(TD)计算目标价值
R; - 反向传播损失(含策略损失、价值损失与熵正则项),更新全局网络。
2. 核心流程
- 初始化:创建全局ACNet、SharedAdam优化器,以及多进程共享的episode计数、总奖励等状态变量;
- 异步训练:启动与CPU核心数一致的Worker进程,每个进程独立完成“环境交互-数据采集-梯度计算-全局更新”循环;
- 动态参数调整:根据当前episode的步数动态调整更新步长(
UPDATE_STRIDE),平衡训练稳定性与效率; - 结果保存:训练过程中自动保存奖励曲线(
res.png)、模型参数(net.pkl)与Excel格式的奖励数据。
3. 测试模块(test.py)
加载训练好的ACNet模型,在HalfCheetah-v2环境中运行100个测试episode,记录每个episode的奖励与步数,计算平均奖励并绘制测试分数分布曲线,验证算法的泛化性能。
(二)DDPG算法模块(ddpg1/ddpg2/ddpg3目录)
DDPG是针对连续动作空间的确定性策略梯度算法,通过“目标网络软更新”与“经验回放”解决训练不稳定性问题,三个子目录代码完全一致,支持批量重复实验以验证结果可靠性。
1. 核心组件
- Ornstein-Uhlenbeck噪声:为确定性动作添加时序相关噪声,平衡探索与利用,噪声强度随训练进程自适应衰减;
- ReplayBuffer(经验回放池):存储历史交互数据(状态、动作、奖励、下一状态、结束标志),训练时随机采样批量数据,打破样本相关性;
- Actor-Critic双网络结构:
- Actor:输入状态,输出确定性连续动作,通过目标网络平滑策略更新;
- Critic:输入“状态+动作”,评估动作价值,为Actor提供梯度更新方向;
- 目标网络软更新:通过
tau参数(0.001)缓慢更新目标网络参数,避免目标价值波动过大。
2. 核心流程
- 经验池初始化:训练前预填充1000条随机动作采集的数据,避免初始训练数据稀疏;
- 动作生成:Actor输出基础动作,叠加OU噪声后输入环境,确保充分探索;
- 数据存储:每次环境交互后,将数据存入经验回放池;
- 网络更新:当经验池数据量满足批量大小(64)时,交替更新Critic(最小化TD误差)与Actor(最大化Critic评估的动作价值);
- 结果保存:训练结束后保存Actor/Critic模型参数(
netDDPGA.pkl/netDDPGC.pkl)、奖励曲线与Excel数据。
3. 测试模块(test.py)
加载训练好的Actor模型,无噪声生成确定性动作,在环境中运行100个测试episode,统计平均奖励与步数,验证算法的控制精度。
(三)SAC算法模块(sac1/sac2/sac3目录)
SAC(Soft Actor-Critic)是基于最大熵强化学习的算法,通过引入熵正则项鼓励策略探索,同时使用双Q网络缓解过估计问题,三个子目录仅训练episode数存在差异,核心逻辑一致。
1. 核心组件
- 双Q网络(QNetwork):两个结构相同的Q网络,评估“状态+动作”的价值,取最小值作为目标价值,避免单Q网络的价值过估计;
- GaussianPolicy(高斯策略网络):输出动作的高斯分布,通过重参数化技巧实现梯度可导,支持策略熵的计算;
- ReplayMemory:与DDPG的经验回放池功能一致,但支持固定随机种子确保实验可复现;
- 熵温度参数
alpha:平衡奖励与熵的权重,固定为0.2(非自动调整模式),控制策略的探索强度。
2. 核心流程
- 初始化:创建Q网络、目标Q网络、高斯策略网络,使用硬更新(
hard_update)初始化目标网络参数; - 探索阶段:前1000步采用随机动作采集数据,之后切换为策略网络生成动作(叠加高斯噪声);
- 网络更新:
- Q网络更新:最小化当前Q值与目标Q值(含熵项)的MSE损失;
- 策略网络更新:最大化“Q值-熵项”的期望,确保策略既优又具有探索性;
- 目标网络软更新:每步更新后,以tau=0.005缓慢同步目标网络与当前网络参数; - 结果保存:模型参数保存至
models目录,训练奖励曲线与Excel数据保存至根目录。
3. 测试模块(test.py)
加载训练好的策略网络,关闭探索噪声(evaluate=True),生成确定性动作,运行100个测试episode,统计平均奖励并绘制分数分布,验证算法的稳定控制能力。
(四)TD3算法模块(td31/td32/td33目录)
TD3(Twin Delayed DDPG)是DDPG的改进算法,通过双Q网络与延迟策略更新解决DDPG的过估计与训练震荡问题,三个子目录代码完全一致,支持批量实验。
1. 核心组件
- 双Critic网络:与SAC类似,通过两个Critic网络取最小值计算目标价值,缓解价值过估计;
- 延迟策略更新:每更新2次Critic网络,才更新1次Actor网络,避免策略更新过于频繁导致的训练不稳定;
- 目标动作噪声:为目标Actor输出的动作添加 clipped 高斯噪声,进一步降低价值估计偏差;
- ReplayBuffer:与DDPG功能一致,支持批量采样与数据存储。
2. 核心流程
- 初始化:创建Actor/Critic网络及对应的目标网络,目标网络参数通过硬更新初始化;
- 数据采集:前1500步随机探索,之后基于Actor输出动作叠加探索噪声(
expl_noise=0.1); - 网络更新:
- Critic更新:最小化双Critic网络与目标Q值的MSE损失;
- Actor更新:每2次Critic更新后,最大化Critic对Actor动作的评估值,更新策略;
- 目标网络软更新:以tau=0.005同步目标网络与当前网络参数; - 结果保存:训练奖励数据保存为Excel文件,支持后续对比分析。
3. 测试模块(td32/test.py)
注:仅td32目录包含测试代码,功能与其他算法一致:加载Actor模型,无噪声生成动作,运行100个测试episode,统计平均奖励并可视化结果。
四、结果分析模块(plot.py与plot-without-a3c.py)
该模块用于多算法性能对比,读取各算法的训练奖励数据(Excel文件),通过seaborn绘制统一的奖励曲线,支持两种对比模式:
| 脚本名称 | 对比算法 | 核心功能 |
|---|---|---|
plot.py |
A3C、DDPG、SAC、TD3 | 绘制四种算法的训练奖励曲线,对比整体性能 |
plot-without-a3c.py |
DDPG、SAC、TD3 | 排除A3C后的三种算法对比,聚焦确定性策略算法 |
核心流程
- 数据加载:读取各算法子目录下的Excel文件,提取训练过程中的奖励序列;
- 数据格式化:将多算法的奖励数据整理为统一的DataFrame格式,添加算法标签;
- 可视化:绘制折线图(x轴为episode数,y轴为奖励值),通过不同颜色/线型区分算法,直观展示算法的收敛速度与最终性能。
五、批量实验与可复现性设计
(一)批量实验支持
- 多算法并行:各算法模块独立目录,可同时启动多个训练进程(如A3C与SAC并行训练);
- 重复实验:同一算法的三个子目录(如a3c1/a3c2/a3c3)仅训练参数差异,支持多次重复实验取平均,降低随机误差影响。
(二)可复现性保障
- 随机种子固定:所有算法均设置固定随机种子(如SAC的
seed=123456),确保每次训练的初始状态一致; - 数据存储完整:训练奖励、测试分数均以Excel/npy格式保存,支持后续重新绘制曲线或统计分析;
- 模型参数保存:各算法训练结束后自动保存网络参数,可直接加载进行测试或继续训练。
六、使用说明
(一)训练流程
- 安装依赖:通过
pip install gym numpy pandas matplotlib torch安装所需库; - 启动训练:进入目标算法目录(如
a3c1),运行python runmain.py,自动加载HalfCheetah-v2环境并启动训练; - 查看结果:训练结束后,目录下生成:
-res.png:训练奖励曲线;
-a3c.xlsx(或对应算法名称):完整奖励记录;
-net.pkl(或类似名称):训练好的模型参数。
(二)测试流程
- 准备模型:确保训练已生成模型参数文件(如A3C的
net.pkl); - 启动测试:运行算法目录下的
test.py,自动加载模型并在环境中运行测试; - 查看测试结果:生成
TestA3CHC.png(或对应算法名称),展示100次测试的分数分布与平均分数。
(三)多算法对比
- 准备数据:确保所有待对比算法均已完成训练,生成Excel格式的奖励数据;
- 运行对比脚本:执行
python plot.py,在当前目录生成HalfCheetah-v2.png,展示四种算法的奖励曲线对比。
七、算法性能特点总结
| 算法 | 核心优势 | 适用场景 | 训练效率 |
|---|---|---|---|
| A3C | 异步多进程训练,样本效率高 | 算力充足、需快速收敛的场景 | 快(多进程并行) |
| DDPG | 确定性策略,动作输出稳定 | 对动作平滑性要求高的控制任务 | 中(单进程) |
| SAC | 最大熵策略,探索能力强,泛化性好 | 复杂环境、需鲁棒控制的场景 | 中(单进程) |
| TD3 | 解决DDPG过估计问题,训练更稳定 | 对稳定性要求高的连续控制任务 | 中(单进程) |
通过本项目的代码实现,可快速验证四种主流强化学习算法在HalfCheetah-v2机器人控制任务中的性能差异,为实际机器人控制场景的算法选型提供参考。
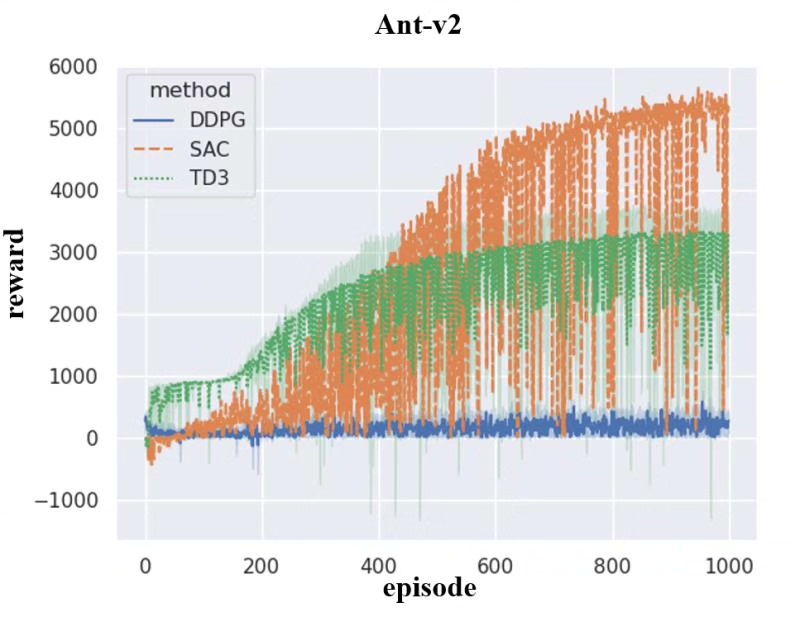
深度强化学习算法:DDPG TD3 SAC 实验环境:机器人MuJoCo

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 14
14 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)