【论文阅读】Towards Learning a Generalist Model for Embodied Navigation
Towards Learning a Generalist Model for Embodied Navigation
-
摘要
-
研究痛点:
- 以前的具身导航模型都是“专才”,只能做特定任务。
- 模型缺乏泛化能力,遇到没见过的场景或任务就容易失败。
-
解决方案:
- 提出了 NaviLLM,这是该领域第一个通用模型。
- 核心技术:
- 用 LLM 作为主体架构
- 并提出了一种 Schema-based Instruction(基于图式的指令)。
- 原理: 这种技术将各种截然不同的导航和视觉任务,全部统一转化为语言模型的生成问题。这使得模型可以用统一的方式处理导航、问答、描述等多种任务。
-
训练优势:
- 由于任务格式统一,模型可以利用多种来源的数据集进行混合训练。
- 这让模型能够学习到更广泛的知识和能力。
-
实验成果:
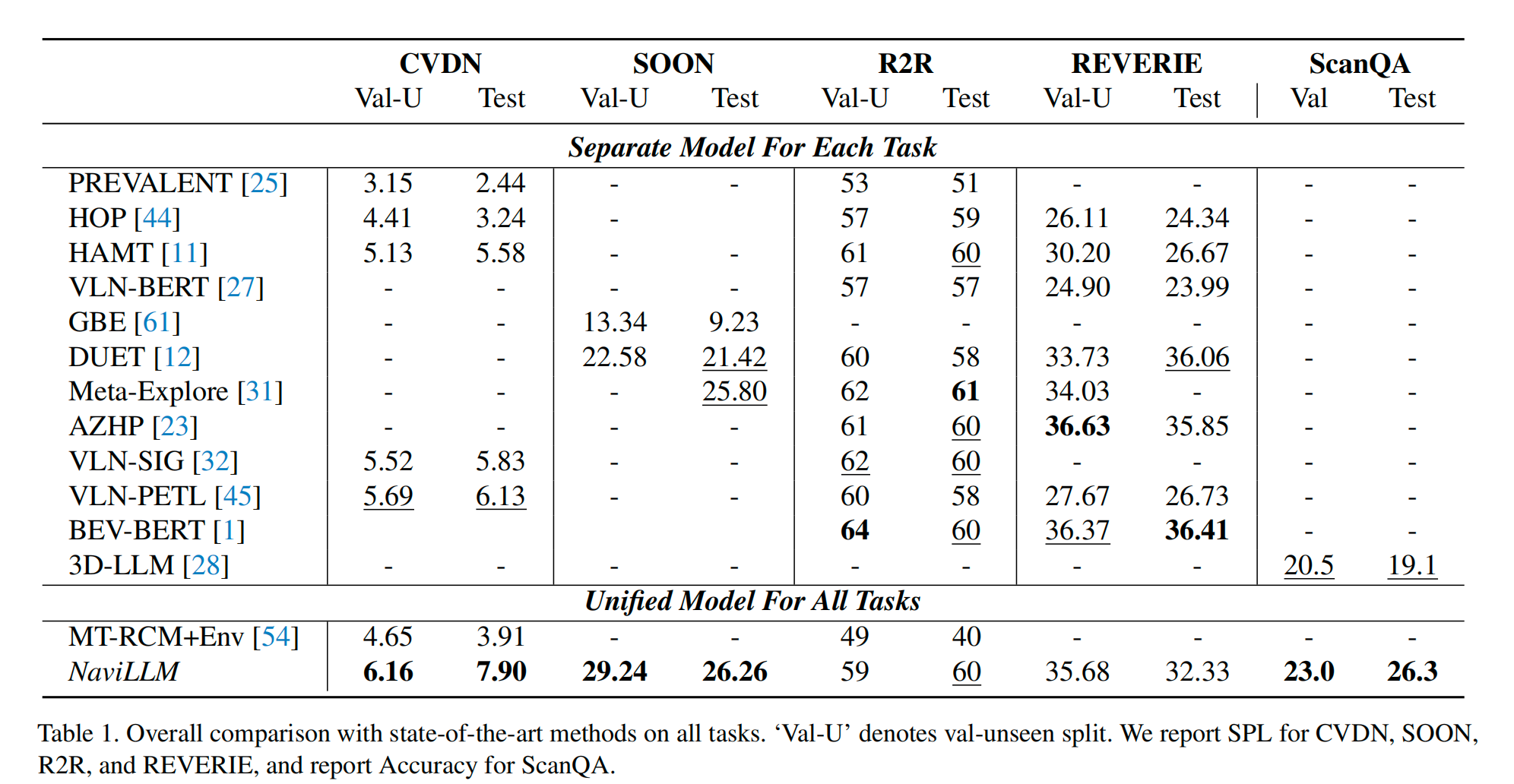
- 刷新纪录: 在 CVDN、SOON、ScanQA 三大主流榜单上均达到 SOTA 水平。
- 巨大提升: 在 CVDN 上比前人最好成绩高出 29%。
- 泛化强: 在未训练过的任务(如3D场景描述、具身问答)上也能表现出色
-
1. Introduction
-
核心问题与动机
-
AGI目标: 创造能像人一样在物理世界中互动和学习的智能体。
-
现状: 现有的具身导航模型大多是专才。它们针对特定任务(如按指令走、找物体、回答问题)训练,虽然在各自领域表现尚可,但无法泛化。
-
痛点: 缺乏一个能处理多种任务、适应未见场景的通才(Generalist)模型。
-
-
解决方案——NaviLLM
-
切入点: 利用 LLM 强大的文本理解和生成能力。
-
核心策略: 将所有不同的导航任务统一转化为 生成式建模 (Generative Modeling) 问题。
-
关键技术: Schema-based Instruction(基于图式的指令)。
- 设计了一套通用的模版,包含任务描述、视觉观察、导航历史等。
- 通过这个模版,将视觉和动作需求转化为文本生成问题
- 例如:把“导航”转化为“生成方向词”,把“定位”转化为“生成物体ID”。
-
-
方法优势
-
统一性: 一个模型就能干所有事。
-
数据利用: 可以把不同任务的数据集(CVDN, R2R, SOON等)混在一起训练,解决了单一任务数据不足的问题。
-
灵活性: 模型能理解不同格式、不同粗细粒度的指令。
-
-
实验成果
-
SOTA 表现: 在 CVDN、SOON、ScanQA 三大榜单上实现SOTA结果。
-
指标提升: 在 CVDN 任务上,性能比前人最好成绩提升了 29%。
-
强泛化性: 在 Unseen tasks 测试中:
- 在 SOON 数据集上做零样本测试,成功率比基线提升了 136%。
- 展示了原本没教过的能力,如 3D 场景描述。
-
-
主要贡献
-
提出了 NaviLLM,这是该领域第一个通用的具身导航模型。
-
设计了 Schema-based instruction,成功利用 LLM 统一了多种异构任务。
-
通过混合训练实现了 SOTA 性能,并证明了模型具有极强的泛化能力。
-
2. Related Work
2.1. Vision-Language Navigation
- 任务类型: 现有的研究涵盖了多种侧重点不同的具身能力任务:
- R2R (Room-to-Room): 要求智能体遵循细粒度的指令,一步步导航。
- CVDN (Cooperative Vision-and-Dialog Navigation): 要求智能体根据对话历史进行导航。
- SOON & REVERIE: 除了导航,还要求智能体定位指令中查询的具体物体。
- EQA (Embodied Question Answering): 要求通过主动探索环境来回答关于3D环境的问题。
- 现有方法的局限:
- Specialist Models: 以前的方法主要致力于为每一个单独的任务设计特定的模型。
- 缺乏泛化性: 这些模型往往难以迁移到其他任务上,泛化能力差。
- 方法对比:
- 对比 MT-RCM: MT-RCM 是一个为了减少过拟合设计的多任务模型。
- NaviLLM 与其区别在于利用了 LLM 来增强泛化性,且覆盖的任务范围更广。
- 对比 Pipeline 方法: 现有的一些工作利用现成的基础模型串联起来解决问题。
- NaviLLM 是一个统一的、端到端的具身模型,而不是多个独立模型的拼凑。
- 对比 MT-RCM: MT-RCM 是一个为了减少过拟合设计的多任务模型。
2.2. Multimodal Instruction Tuning
- 现有进展: LLM 在文本理解和生成上已革命性突破,且已扩展到处理 2D 图像(如 LLaVA)和视频。
- 本文的创新性:
- 多模态 LLM 主要关注图像或视频,而忽略了Embodied AI,特别是导航和 3D 理解。
- 对比 3D-LLM:
- 虽然 3D-LLM 将 LLM 适配到了 3D 数据上,但它没有解决连续决策的问题。
- 连续决策和静态任务的对比
- 连续决策:智能体不能只做一次决定,而是要在一系列的时间步中,根据每一步产生的变化,连续不断地做出新的决定。
- 静态任务:它是上帝视角或静态视角。它是一次性把场景看完了,做出一次决策或者回答。
2.3. Large Language Models as Embodied Agents
-
路线一:Frozen LLMs + 转换
- 将视觉信息翻译成文本,然后喂给参数冻结的 LLM,让其生成计划、路标或代码。
-
路线二:Fine-tuning
-
直接在包含动作序列的数据集上微调 LLM。
-
这条路线目前主要集中在 manipulation 上。
-
本文也采用微调的方法。
-
区别: 本文专注于解决具身导航中的各种任务,而不是机器人操作。
-
3. Method
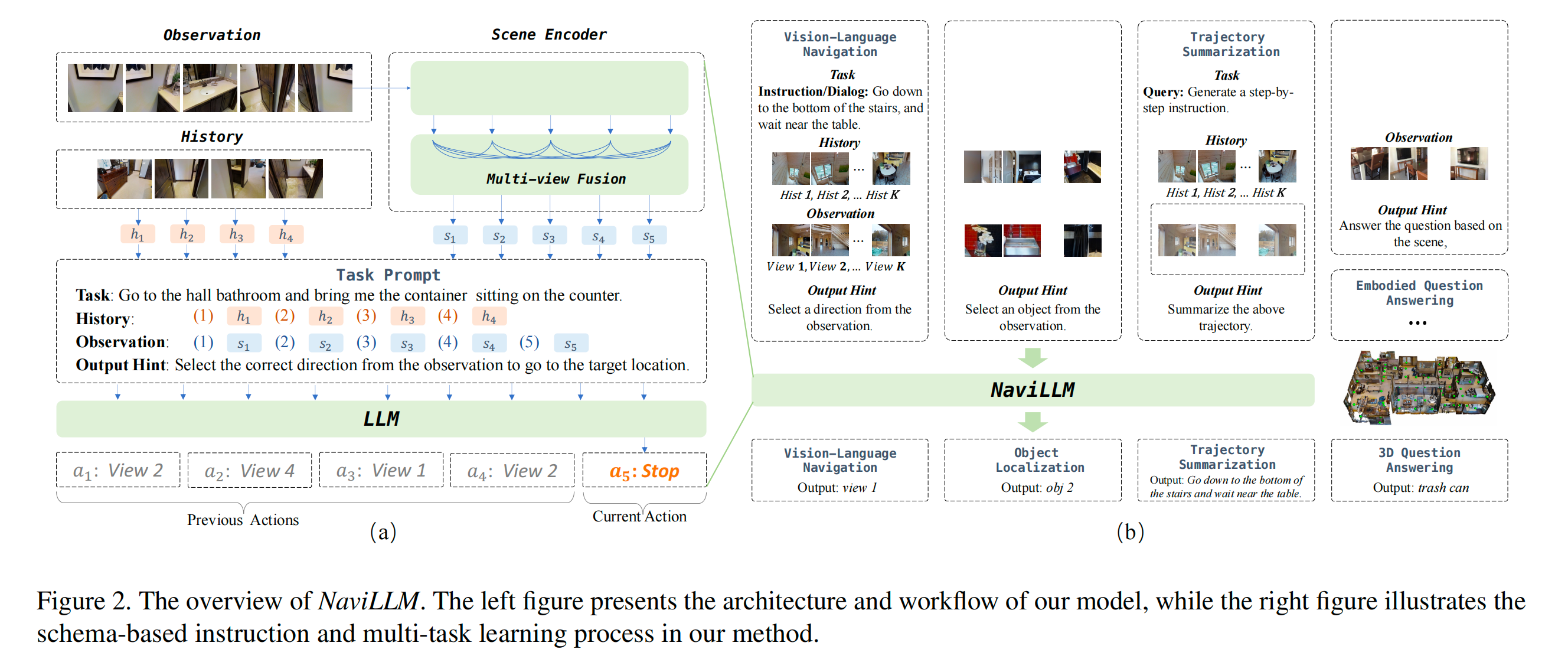
3.1 Problem Fromulation
- 在具身导航中,位于3D环境中的具身智能体需要完成用自然语言描述的任务。
- 输入: Past Trajectories + 现在看到的画面(Current Observations)。
- 输出: 下一步动作(Action)。
- 动作包括导航移动、物体的边界框和文本响应。
3.2 NaviLLM
- NaviLLM 包含两个模块:场景编码器(Scene Encoder)和 LLM。
- 场景编码器以当前的视觉观察为输入,并将其转化为一系列场景表示。
- 利用这些场景表示,我们为不同的任务构建各种图式(Schemas),这些图式作为 LLM 的输入,以产生下一个动作。
- 核心流程:图片 -> 向量 -> 模版(Schema) -> LLM -> 动作。
3.2.1 Scene Encoding
- 场景编码器从由一组图像 {Ii}i=1n\{I_i\}_{i=1}^n{Ii}i=1n 组成的观察中提取场景表示,每个图像代表一种viewpoint。
- 机器人通常看一圈(全景图切分成几个方向),这里 nnn 就是方向的数量。
- 第一步:单张图片处理。用 ViT 把每张图变成特征向量
- 第二步:不同视角的这些特征进行多视角融合(Multi-view Fusion),产生场景表示 {si}i=1n\{s_i\}_{i=1}^n{si}i=1n
3.2.1.1 Visual Feature Extraction
-
ViT 的处理过程:Patching -> 加 [CLS] token -> Transformer -> 取 [CLS] 输出。
fi=ViT(Ii) f_i = \text{ViT}(I_i) fi=ViT(Ii) -
这里选用的是 [CLS] token 作为一个Image的特征表示
3.2.1.2 Multi-view Fusion
-
目的:模型需要理解不同图片的联系(比如“图片A”是“图片B”的左边)。
- 这一步就是为了捕捉不同视角之间复杂的相互依赖关系。
-
核心机制:Transformer Encoder
-
输入: 之前通过 ViT 提取出的所有单张图像特征 {fi}i=1n\{f_i\}_{i=1}^n{fi}i=1n。
-
处理: 将这些特征作为一个序列喂给一个 Transformer Encoder。
-
作用: 利用Self-Attention,学习到它们之间的空间关系。
-
-
数学表达
{si}i=1n=Transformer-Encoder({fi}i=1n) \{s_i\}_{i=1}^n = \text{Transformer-Encoder}(\{f_i\}_{i=1}^n) {si}i=1n=Transformer-Encoder({fi}i=1n)-
fif_ifi:只是第 iii 张图原本的视觉特征(孤立的)。
-
sis_isi:是融合了周围环境上下文后的第 iii 个视角的场景表示(全局的)。
-
-
Geometric Information
-
角度信息: 知道每张图是朝哪个方向拍的。
-
GPS 信息: 知道当前所处的绝对或相对坐标。
-
这些信息被编码后加入到场景编码中,帮助模型建立更精确的三维空间感。
-
3.2.2 Schema-Based Instruction
-
核心理念:设计一种统一的输入格式。不同任务都会被转化成同一种结构喂给 LLM。
-
目的: 这种灵活性使得模型可以输入各种不同来源的数据,实现通用性。
作者将输入信息拆解为以下四个部分:
-
Task
-
定义: 用自然语言描述智能体需要执行的命令。
-
形式: 一段文本序列。
-
-
Observation
-
这是智能体现在看到的东西。
-
难点: LLM 只能读文本,读不懂图片特征向量。
-
解决方案: 加 ID。
- 作者把当前视角的图像特征 {si}\{s_i\}{si} 序列化。
- 关键操作: 在每一个图像特征前面,加一个对应的 ID Embedding(ID嵌入向量)。
-
格式:
[Emb(1),s1,Emb(2),s2,...,Emb(n),sn] [\text{Emb}(1), s_1, \text{Emb}(2), s_2, ..., \text{Emb}(n), s_n] [Emb(1),s1,Emb(2),s2,...,Emb(n),sn]- 这里 Emb(1)\text{Emb}(1)Emb(1) 代表数字“1”的向量,s1s_1s1 代表方向1的图像特征。
-
作用: 这样 LLM 就能通过输出数字 ID,来代表它选择了“方向1”的画面,从而实现了“视觉选择”。
-
-
History
-
这是智能体过去看到的东西。
-
定义: 记录截止到当前第 ttt 步的所有过去视觉观察序列。
-
作用:
- 提供时间上下文。
- 帮助智能体知道自己走过了哪些地方,避免Looping。
- 让智能体通过对比历史和现在,获得行为的反馈。
-
格式: 同样采用加 ID 的方式,但这里的 ID 代表时间步。
[Emb(1),h1,...,Emb(t),ht] [\text{Emb}(1), h_1, ..., \text{Emb}(t), h_t] [Emb(1),h1,...,Emb(t),ht]- 表示:第1步看到了 h1h_1h1,…,第 ttt 步看到了 hth_tht。
-
-
Output Hint
-
定义: 提示模型预期的输出格式。
-
作用: 将生成问题约束在特定范围内,对齐任务需求。
-
例子:
- 导航时提示:“Select a viewpoint ID.”(请选一个视角ID)
- 问答时提示:“Answer the question.”(请回答问题)
- 总结时提示:“Summarize the trajectory.”(请总结路径)
-
整个过程可视作给LLM写一个非常详细的prompt,如:
[Task]: “请找到厨房里的微波炉。”
[History]: “你第1步看到了走廊(图像特征A),第2步看到了客厅(图像特征B)…”
[Observation]: “现在你面前有:<1>号方向是墙(图像特征C),<2>号方向是门(图像特征D)…”
[Output Hint]: “请输出你下一步想去的方向编号 (ID)。”
3.3 Multi-task Learning
-
核心思想:万物皆生成。所有任务都被转化为根据提示生成文本(或ID)的问题,并使用统一的交叉熵损失函数进行优化。
-
Vision-Language Navigation
-
输入 Schema:
- Task: 导航指令
- Observation: 当前位置所有可到达视角的场景表示(带ID)。
- Output Hint: 提示词,如“从观察中选择一个方向”。
-
输出机制: LLM 预测一个 数字 ID。这个 ID 对应某个可视方向,代表智能体决定往那里走。
-
-
Object Localization
-
这个任务通常发生在导航到达目的地之后,要求智能体指出具体物体在哪里。
-
输入 Schema:
- History: 之前的导航路径。
- Task: 定位指令。
- Observation: 变为当前视野内所有可见物体的表示(不再是方向)。
- 注:物体特征通过预训练 ViT 提取并映射到词向量维度。
- Output Hint: 提示词,如“从观察中选择一个物体”。
-
输出机制: LLM 生成被选中的 物体 ID。
-
-
Trajectory Summarization
-
这是导航的逆向任务。给定一段走过的路,让 AI 生成指挥这段路的指令。
-
输入 Schema:
- History & Observation: 同 VLN(提供路径信息)。
- Task: 描述总结的风格(如“细粒度”或“粗粒度”)。
- Output Hint: 提示词,如“总结上述路径”。
-
输出机制: LLM 生成 自然语言文本(即一段导航指令)。
-
-
3D Question Answering
-
这是一个静态任务,不需要移动,只要求根据当前场景回答问题。
-
输入 Schema:
- History: 不需要。
- Task: 关于室内场景的一个问题。
- Observation: 不同视角的场景表示(全景图)。
- Output Hint: 提示词,如“根据场景回答问题”。
-
输出机制: LLM 生成 自然语言文本答案。
-
-
Embodied Question Answering
-
定义: 智能体需要先走到问题所指的地方,然后再回答问题。
-
两阶段策略 (Two Stages):
- 导航阶段: 使用 VLN Schema,让模型生成 ID 进行移动,直到到达目标。
- 问答阶段: 到达后,切换到 3D-QA Schema,让模型观察环境并生成文本答案。
-
4. Experiment
4.1 Experiment Setup
4.1.1 Implementation Details
- 模型架构
- LLM 底座: 基于 Vicuna-7B-v0
- 视觉部分:
- 场景编码器中的 ViT 使用 EVA-CLIP-02-Large,且在训练过程中保持冻结。
- 物体特征提取使用 ViT-B16。
- 多视角融合模块使用一个 2 层的 Transformer Encoder (Hidden size 1024)。
- 训练策略:
- 采用 两阶段训练:
- 预训练: 10,000 步,使用 Teacher-forcing。
- 多任务微调: 5,000 步,交替使用 Teacher-forcing 和 Student-forcing。
- 硬件与时间: 8 张 Nvidia A100 GPU,训练约 80 小时。
- 推理策略:
- SOON 和 REVERIE 任务:使用采样策略 (Temperature 0.01) 以鼓励探索。
- 其他任务:使用贪婪策略 (Greedy strategy)。
- 采用 两阶段训练:
- 训练数据构建:
- 数据来源: 混合了 CVDN, SOON, R2R, REVERIE, ScanQA 以及 LLaVA-23k 等多个数据集。
- 任务转换技巧:
- 路径总结: 将 VLN 的“指令-路径”对翻转,变成“路径-指令”对进行训练。
- 3D-QA: 除了 ScanQA,还利用 R2R 的细粒度注释构建了额外的问答对。
- 留出集 (Held-out): 特意不使用 EQA 数据集进行训练,专门用来测试模型的“零样本”泛化能力。
4.1.2 Setup for VLN
- 数据集: 选取了四个具有代表性的数据集,分别对应不同的挑战:
- CVDN: 基于多轮对话历史进行导航。
- SOON: 根据详尽的语义描述寻找物体。
- R2R: 遵循一步步的细粒度指令进行导航。
- REVERIE: 根据简短的高层指令寻找远处物体。
- 评估指标:
- SR (Success Rate): 成功率。
- SPL (Success Rate Weighted by Path Length): 路径加权成功率(主要指标,用于 R2R, SOON, REVERIE)。
- GP (Goal Progress): 目标进程(向目标靠近了多少米,主要用于 CVDN)。
- OSR: Oracle 成功率。
- TL: 轨迹长度。
- Baselines: 与各数据集上最新的 SOTA 方法进行对比(排除那些使用了预探索或额外环境增强的方法)。
4.1.3 Setup for 3D-QA
- 数据集: 使用 ScanQA 数据集。
- 评估指标: 标准的自然语言处理指标,包括 EM, METEOR, ROUGE-L, CIDER, BLEU-4。
- 基线方法: 对比 VoteNet+MCAN, ScanRefer+MCAN 以及当前的 SOTA 模型 3D-LLM。
4.1.4 Setup for EQA
- 测试性质: 零样本推理。因为模型在训练时没见过这个任务的数据。
- 数据集: MP3D-EQA。作者手动过滤了其中终点不准确的无效数据。
- 评估指标:
- 导航阶段:SR, SPL。
- 问答阶段:ACC (Accuracy) 准确率。
- 基线方法: 对比全监督的 VQA 模型和零样本的 DUET 模型。
4.2 Experiment Results

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)