RoboMIND 2.0:用于通用具身智能的多模态、双手移动操作数据集(下)
25年12月来自北京人形机器人创新中心和北大的论文“RoboMIND 2.0: A Multimodal, Bimanual Mobile Manipulation Dataset for Generalizable Embodied Intelligence”。尽管数据驱动的模仿学习已经彻底改变了机器人操作,但当前的方法仍然受到大规模、多样化真实世界演示数据匮乏的限制。因此,现有模型在长时程双臂
25年12月来自北京人形机器人创新中心和北大的论文“RoboMIND 2.0: A Multimodal, Bimanual Mobile Manipulation Dataset for Generalizable Embodied Intelligence”。
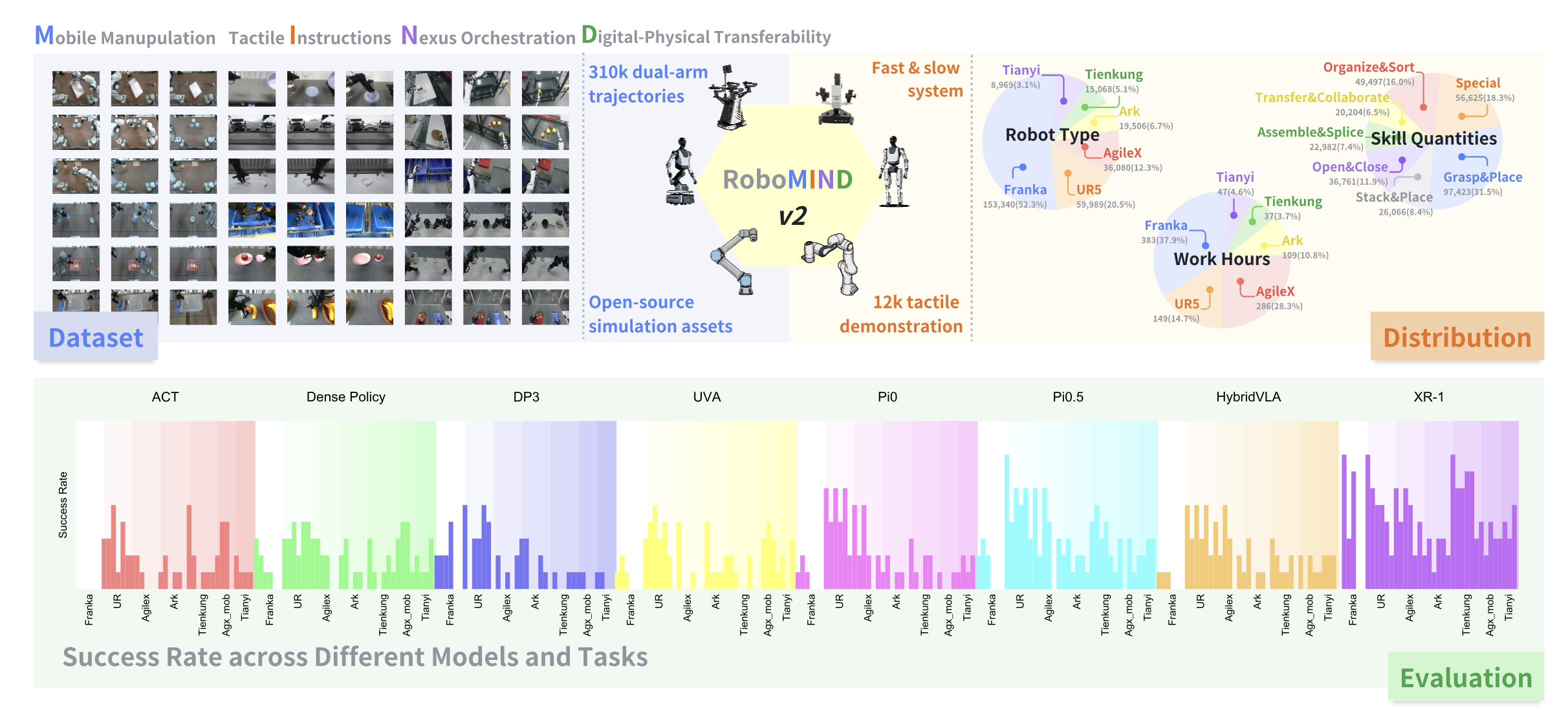
尽管数据驱动的模仿学习已经彻底改变了机器人操作,但当前的方法仍然受到大规模、多样化真实世界演示数据匮乏的限制。因此,现有模型在长时程双臂任务和非结构化环境下的移动操作方面的泛化能力仍然有限。为了弥补这一差距,RoboMIND 2.0是一个包含超过 31 万条双臂操作轨迹的综合真实世界数据集,这些轨迹采集自六种不同的机器人形态和 739 个复杂任务。至关重要的是,为了支持对接触丰富且空间扩展的任务的研究,该数据集包含了 1.2 万个触觉增强的实验片段和 2 万条移动操作轨迹。除了这些物理数据之外,还构建真实世界环境的高保真数字孪生模型,并发布一个包含 2 万条轨迹的模拟数据集,以促进稳健的仿真-到-真实迁移。为了充分发挥 RoboMIND 2.0 的潜力,提出 MIND-2 系统,这是一个通过离线强化学习优化的分层双-系统框架。MIND-2 集成了一个高级语义规划器 (MIND-2-VLM),用于将抽象的自然语言指令分解为具体的子目标;同时集成一个低级视觉-语言-动作执行器 (MIND-2-VLA),用于生成精确的、感知本体感觉的运动动作。对六种不同的机器人进行广泛的评估,验证数据集的有效性,并证明MIND-2系统显著优于四个单任务基线模型(涵盖二维图像和三维点云模态以及四种最先进的VLA模型)。此外,集成触觉模态能够显著提升精细操作任务的性能。最后,实验结果表明,在训练过程中混合真实数据和模拟数据能够持续提高物理执行性能,验证模拟基准的准确性以及合成数据增强的成本效益。
。。。。。。继续。。。。。。
本文提出一种机器人操作系统,它由基于视觉-语言模型(VLM)的“机器人大脑”慢-速系统(MIND-2-VLM)和基于视觉-语言-动作模型(VLA)的快-速机器人操作系统(MIND-2-VLA)组成。机器人大脑慢速系统MIND-2-VLM是一个视觉-语言模型,它为视觉-语言-动作模型MIND-2-VLA生成子任务指令。MIND-2-VLA负责根据当前任务状态和物理环境的动态变化来执行机器人操作。机器人快-速操作系统MIND-2-VLA是一个视觉-语言-动作(VLA)模型,它根据任务指令、机器人的当前状态和任务环境的视觉信息,为机器人的基座和双臂操作生成控制指令。
对于 MIND-2-VLM 模型,用 RoboMIND 2.0 移动机器人数据集中的分段子任务数据集对开源 VLM 模型 InternVL3-8B [139] 进行微调,使其能够根据机器人的当前状态确定应执行的子任务。在收集机器人数据集的过程中,生成大量的任务失败数据。然而,这些失败数据并非毫无意义;相反,它们提供宝贵的信息,可以帮助机器人模型避免此类错误行为。因此,采用离线强化学习方法,利用失败和成功轨迹来训练 MIND-2-VLA 模型,使其不仅能够从成功经验中学习最优动作,还能识别并避免失败案例中出现的次优或错误行为。
MIND-2-VLM:构建类脑视觉-语言模型
为了实现基于多模态观测的高级任务推理,对开源视觉-语言模型 InternVL3-8B [139] 进行微调,该模型基于 RoboMIND 2.0 机器人,能够将以机器人为中心的视觉和本体感觉输入映射到结构化的语义输出。
每个训练样本都构建为一个单轮指令跟随对话。输入提示(作为“人类”话语)整合三个关键组件:
多视角视觉上下文:三个 tokens,分别代表当前时间步同步的前视图、左手腕视图和右手腕视图。
任务上下文:该回合中所有子任务的枚举列表(例如,“1. 拿起红色积木”,“2. 将其放入垃圾桶”),这些子任务源自人工或自动时间分割标注。
执行上下文:当前机器人状态,包括7自由度机械臂关节位置和底盘扭转速度;先前推断的任务索引(或初始帧的“None”),从而实现基本的序列感知。
模型的输出——“辅助”响应——被监督为如下形式的确定性字符串:
Answer:
Task Index:xx
Process:xx
其中,真实任务索引通过在标注的任务片段中定位当前帧获得,进度值在片段的起始帧和结束帧之间进行线性插值,公式为:
progress = (t - t_start) / (t_end - t_start) ∈ [0,1]。
在微调过程中,InternVL3-8B 进行端到端训练,以最小化基于多模态输入的文本输出的交叉熵损失。严格的输出格式确保下游策略系统可以直接解析预测结果。该设计将原始机器人日志转换为可扩展的语言条件监督源,使慢速推理模块(MIND-2-VLM)能够在长期任务的背景下可靠地解释实时观察结果。
MIND-2-VLA:基于隐式Q学习的VLA离线训练
为了在无需在线交互的情况下,利用大规模真实机器人演示数据训练快速机器人执行策略MIND-2-VLA,采用隐式Q学习(IQL)[34]。IQL是一种离策略离线强化学习算法,非常适合包含成功和次优轨迹的异构数据集。IQL将值和Q函数学习与策略优化解耦,从而能够有效地从混合质量数据(例如RoboMindV2和Galaxea开放世界数据集)中学习。
首先使用时间折扣奖励信号标注所有轨迹(包括正向(成功)和负向(失败)轨迹),以提供密集监督。具体来说,对于成功的轨迹,终点步骤的奖励为 +1,其前 t 个步骤的奖励为 r_t = γT−t,其中 γ = 0.999,形成递减的正收益。对于失败的轨迹,终点步骤的奖励为 −1,其前 t 个步骤的奖励按 r_t = −γT−t 进行反向减损,确保导致失败的动作的收益越来越负。T 表示动作序列中的时间步数(或帧数),即轨迹的长度,或者给定回合中机器人连续动作和观测的总数。
在定义了动作序列的奖励之后,接下来利用隐式Q学习(IQL)对视觉-语言-动作(VLA)模型进行离线强化学习(RL)微调。IQL框架由三个组件构成:状态值函数𝑉(𝑠)、Q函数𝑄(𝑠,𝑎)和策略𝜋_𝜓(𝑎|𝑠)。所有组件均在静态数据集D = {(𝑠, 𝑎, 𝑟, 𝑠′)}上进行训练,该数据集由某种未知的行为策略收集。
首先通过将状态值函数𝑉(𝑠)回归到数据集D中行为策略下的预期收益来学习它。这可以通过最小化损失函数L_V(𝜙)来实现,其中𝜌_𝜏(𝑢)是非对称分位数损失。接下来,用标准时间差分 (TD) 学习更新 Q 函数 𝑄(𝑠, 𝑎),目标值L_Q(𝜃) 由 𝑉(𝑠′) 计算得出,其中 𝑄_𝜃(𝑠,𝑎) 由 𝜃 参数化,𝑟(𝑠,𝑎) 是奖励信号,𝛾𝑟𝑙 ∈ [0,1) 是折扣因子。最后,通过优势加权回归更新策略 𝜋_𝜓(𝑎|𝑠),重点关注在每个状态下表现优于平均值的动作。
纳入失败轨迹至关重要:通过对比高回报和低回报序列,IQL 能够区分看似合理但最终导致失败的行为(例如,抓握不稳或错位)和那些能够可靠成功的行为。这使得 MIND-2-VLA 不仅能够模仿成功的行为,还能主动避免已知的失败模式——从而能够从真实世界的开放数据中学习到稳健、通用且安全的策略。
单任务模仿学习的训练与评估设置。对于单任务模仿学习,采用四种成熟的基线方法:ACT [35]、Dense Policy [8]、DP3 [9] 和 UVA [36]。遵循其原始文献中指定的默认模型配置。使用这些方法,在各自的数据集上从头开始训练每个单任务模型。训练完成后,将模型直接部署到真实环境中进行评估。模型性能基于任务成功率进行评估。每个模型测试十次,测试人员记录每次试验的成功或失败情况,以及失败的原因。这种系统性的评估方法为未来的改进提供宝贵的见解。
VLA大模型的训练与评估设置。评估四个模型(HybridVLA [12]、𝜋0 [2]、𝜋0.5 [3] 和 XR-1 [13])的性能,这些模型均基于 RoboMIND 2.0 的演示数据进行微调,以完成各种真实世界的任务。在 VLA 模型的训练过程中,用与公开代码中相同的预训练配置和超参,对每个任务上公开可用的预训练 VLA 模型进行微调。
关于真实机器人设置,如图所示机器人实战环境设置。对于 Franka 和 UR5e 机器人,用位于顶部、左侧和右侧视角的摄像头记录任务轨迹的视觉信息。对于人形机器人(Tien-Kung和Tian-Yi),用其内置的 RGB-D 摄像头进行视觉观测。对于 AgileX 和 ARX 机器人,用双腕摄像头(每只手臂一个)以及一个头戴式摄像头来采集视觉信息。
如图所示多种机器人平台执行多样化的双手操作任务。包括 Franka、UR5e、AgileX、ARX LIFT 和 Tien Kung 在内的不同机器人平台执行多种双手操作任务,并在不同的基准测试中进行测试。
实验任务而言,如图所示Tian-Yi和 AgileX 机器人平台在各种真实环境中执行移动操作任务的示例:


DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 16
16 0
0- 0



 已为社区贡献211条内容
已为社区贡献211条内容

所有评论(0)