机器人GPT时刻!英伟达WAM赋予全机器人零样本操作能力
这款拥有 14B 参数的世界动作模型,通过将视频生成与动作预测深度耦合,让机器人即便在从未见过的环境中,也能凭借对物理规律的理解完成从未训练过的复杂任务。英伟达刚刚发布的首个世界动作模型(World Action Model,WAM) DreamZero 让机器人拥有了通过视觉预测未来并指导动作的物理直觉。这款拥有 14B 参数的世界动作模型,通过将视频生成与动作预测深度耦合,让机器人即便在从未见
这款拥有 14B 参数的世界动作模型,通过将视频生成与动作预测深度耦合,让机器人即便在从未见过的环境中,也能凭借对物理规律的理解完成从未训练过的复杂任务。
英伟达刚刚发布的首个世界动作模型(World Action Model,WAM) DreamZero 让机器人拥有了通过视觉预测未来并指导动作的物理直觉。

这款拥有 14B 参数的世界动作模型,通过将视频生成与动作预测深度耦合,让机器人即便在从未见过的环境中,也能凭借对物理规律的理解完成从未训练过的复杂任务。
研究人员甚至称其为机器人 GPT 时刻:

视频预测编织出机器人的物理常识
目前的视觉语言动作模型 VLA 虽然在理解指令和识别物体上表现出色,却常常在真实的物理操作中栽跟头。
这些模型就像背熟了菜谱却从未进过厨房的学徒,它们知道要把可乐罐放到指定位置,却无法在复杂的现实环境中精准控制力道和轨迹。
这种缺陷源于它们缺乏对真实世界演化规律的深刻认知。
传统的训练方式依赖于海量重复的专家演示,这就好比让孩子通过死记硬背来学习走路,一旦路面稍有变化,他们就会无所适从。
DreamZero 改变了这种范式。它建立在 Wan2.1 这一强大的视频扩散模型基础之上。
当机器人接收到一条指令时,它的大脑会先生成一段关于未来世界如何演变的视频流。
这种视频预测是对物体几何形状、物理动力学以及运动控制的深度对齐。

这种机制让动作学习从枯燥的状态模仿变成了灵动的逆动力学过程。
机器人的每一个指令都与它预测到的视觉未来紧密挂钩。
如果预测的视频显示杯子被平稳抓起,模型就会反推出实现这一视觉目标所需的精确电机指令。
这种由内而外的物理直觉,让 DreamZero 在处理解鞋带、翻面汉堡或按电梯按钮等全新任务时,展现出了超过传统模型 2 倍以上的泛化能力。
异构数据打破重复劳动的魔咒
机器人学习领域长期认为通才政策必须建立在无数次重复的演示之上。
在这种逻辑下,为了教机器人抓取一个杯子,人类需要手动操作机器人成千上万次,甚至需要覆盖各种不同的光照和背景。
这种方法极其低效,也限制了机器人走出实验室的速度。
DreamZero 证明了通用政策可以从多样化且不重复的异构数据中高效汲取营养。
研究团队收集了约 500 小时的遥操作数据,这些数据并非在实验室的方寸之间反复磨炼,而是覆盖了家庭、餐厅、超市、咖啡厅和办公室等 22 个真实环境。
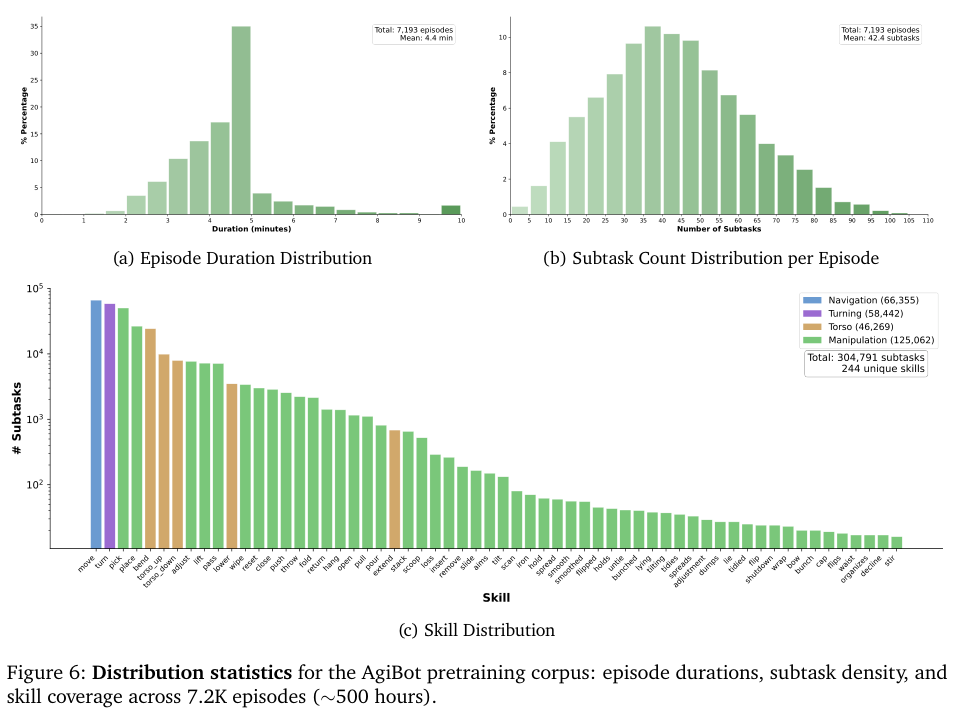
每个片段平均时长约 4.4 分钟,包含 42 个子任务,这种长序列、高密度的任务分布更接近人类的日常生活。
模型通过观察这些并不完美的真实执行过程,学会了物理世界中的通用运动原语。

这种学习方式的妙处在于它对噪声的容忍度。
即使人类在遥操作时动作有些许迟疑或偏差,模型也能通过视频流理解意图。
它并不只是死板地记录动作序列,而是理解环境如何随动作而改变。
实验结果表明,在相同的训练时长下,使用多样化数据训练的模型在抓取等基础任务上的成功率达到 50%,而使用重复性数据训练的模型仅为 33%。
对于更复杂的未见任务,这种差距被进一步拉大。
跨越机体的视觉经验大迁移
DreamZero 最令人惊叹的特性之一是它对不同机体(Embodiment)的适应能力。
在传统的机器人训练中,如果你在 A 机器人上训练了一个抓取模型,由于臂长、电机扭矩和传感器位置的不同,这个模型几乎无法直接在 B 机器人上运行。
这种机体间的鸿沟一直是阻碍机器人技术规模化应用的巨大障碍。
由于 DreamZero 是以视频为核心的世界模型,它学习的是物理世界的通用动态,而不仅仅是特定的电机指令。
人类拍摄的视频或者其他机器人的操作视频,都可以成为它的教材。
研究人员通过收集 12 分钟的人类第一视角视频和 20 分钟的其他机器人操作视频,在没有任何动作标签的情况下,通过纯视频预测任务对模型进行微调。
结果显示,这种纯视觉经验的注入让模型在未见任务上的表现提升了 42% 以上。
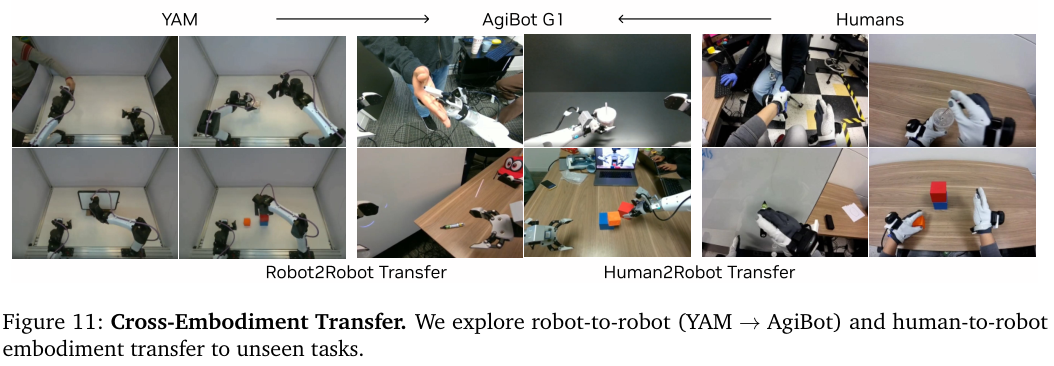
这种少样本适配能力在 YAM 机器人的实验中得到了进一步证实。
仅凭 30 分钟的随机玩耍数据,原本在 AgiBot G1 机器人上训练的模型就能迅速适应全新的 YAM 机体,并保持强大的语言理解和任务执行能力。
这种高效的适配过程表明,模型已经理解了如何将预测的视频画面映射到不同结构的机械臂动作上。
这就像一个精通驾驶的人,即使换了一辆从未见过的跑车,只需摸索几分钟就能自如掌控,因为他理解的是驾驶和物理本身。

仅使用 10 到 20 分钟的纯视频演示数据,人机迁移、机器间迁移两种迁移设置均显著提升了基准性能。
实时控制与闪电般的推理速度
视频扩散模型高昂的计算开销一直是实时控制的死穴。
一个拥有 14B 参数的模型如果每秒只能输出一帧,那它在动态环境中的反应速度甚至不如树懒。
为了解决这个反应间隙(Reactivity Gap),研究团队引入了一系列系统级和模型级的深度优化,统称为 DreamZero-Flash 。
首先是异步闭环执行机制。
机器人不再傻傻地等待推理完成才动,而是让推理模块和运动控制模块同步并行。
当机器人执行当前的动作块时,推理模块已经在利用最新的视觉观测准备下一阶段的动作。
通过 GPU 上的并行计算和 DiT 缓存技术,研究人员成功将每次推理所需的扩散步骤从 16 步压缩到了 4 步,同时保持了极高的预测质量。
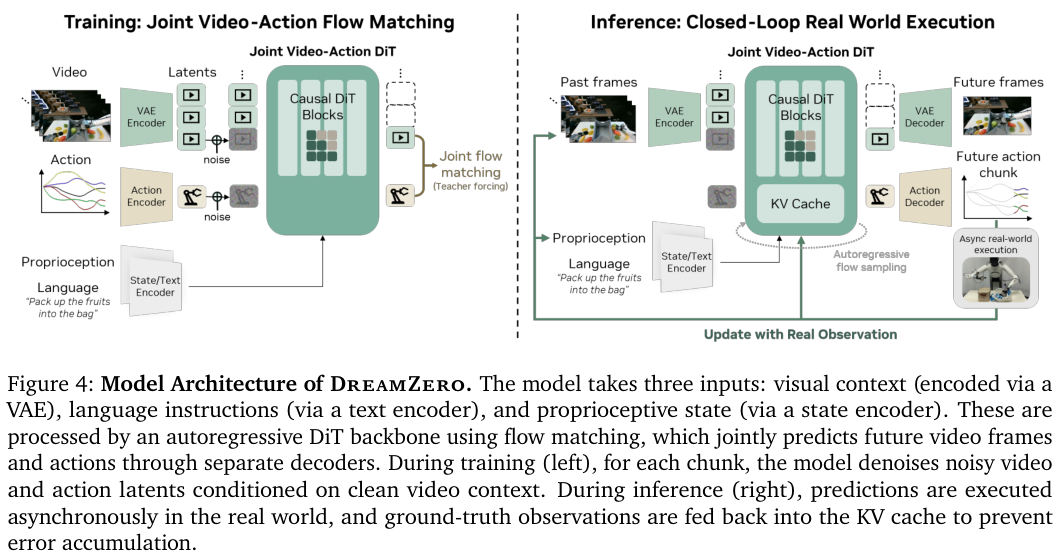
最精妙的优化在于解耦噪声时间表。
在 DreamZero-Flash 中,视频和动作的降噪过程不再共用同一个节奏。
模型在训练时就被特意引导,使其学会在视频画面依然存在部分噪声(即视觉预测尚未完全清晰)的情况下,就能准确推断出清晰的动作。
通过一系列深度优化,模型在英伟达 Blackwell 架构上实现了 38 倍的推理提速。
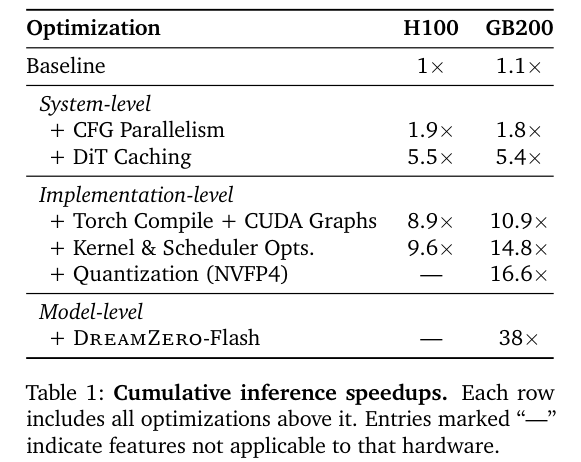
这种降噪策略的错位,让模型在推理速度提升了 38 倍的情况下,依然能够维持流畅的闭环控制,刷新频率达到了 7Hz。
DreamZero 不仅能够思考,更具备了快速反应的能力。
在面对不断变化的环境时,它能够根据实时的视觉反馈动态调整轨迹,从而避免了传统预测模型中常见的误差累积问题。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 11
11 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)