收藏!小白也能学会:用LangGraph+FastAPI打造生产级AI大模型API服务
本文介绍了如何将LangGraph工作流封装在FastAPI中,创建一个生产就绪的AI服务。内容涵盖项目设置、构建工作流、错误处理与重试机制、输入验证、日志记录,以及使用FastAPI暴露为API。还介绍了测试方法、扩展策略(如异步执行、多进程工作、Docker化和认证)。这种架构可将任何LangGraph变成API,支持从聊天机器人到AI SaaS产品的各种应用。
文章介绍了如何将LangGraph工作流封装在FastAPI中创建生产就绪的AI服务。内容包括项目设置、构建工作流、添加错误处理与重试机制、输入验证和日志记录,以及使用FastAPI暴露为API。还介绍了测试方法、扩展策略如异步执行、多进程工作、Docker化和认证。这种架构可将任何LangGraph变成API,支持从聊天机器人到AI SaaS产品的各种应用。
Large Language Models (LLMs) 擅长推理,但现实世界的应用往往需要有状态、多步骤的工作流。这就是 LangGraph 的用武之地——它让你可以通过由 LLM 驱动的节点图来构建智能工作流。

但如果你想把这些工作流暴露为 APIs,让其他应用(或用户)可以调用呢?这时候 FastAPI 就派上用场了——一个轻量级、高性能的 Python Web 框架。
在这篇指南中,你将学习如何将 LangGraph 工作流封装在 FastAPI 中,变成一个生产就绪的 endpoint。
为什么选择 LangGraph + FastAPI?
- • LangGraph:创建多步骤、有状态的 LLM 工作流(例如,多智能体推理、数据处理)。
- • FastAPI:轻松将这些工作流暴露为 REST APIs,以便与 Web 应用、微服务或自动化流水线集成。
- • 结合两者:构建可从任何地方访问的可扩展 AI 智能体。
- 项目设置
创建一个新项目文件夹并安装依赖:
mkdir langgraph_fastapi_demo && cd langgraph_fastapi_demo
python -m venv .venv
source .venv/bin/activate # 在 Windows 上:.venv\Scripts\activate
pip install fastapi uvicorn langgraph langchain-openai python-dotenv
创建一个 .env 文件来存储你的 API 密钥:
OPENAI_API_KEY=你的_openai_密钥_在此
2. 构建一个简单的 LangGraph 工作流
让我们构建一个简单的 LangGraph,它接收用户的问题并返回 AI 生成的答案。
# workflow.py
from langgraph.graph import StateGraph, START, END
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
import os
from dotenv import load_dotenv
load_dotenv()
llm = ChatOpenAI(model="gpt-4o") # 可以切换到 gpt-4o-mini 以降低成本
# 定义状态
defanswer_question(state: dict) -> dict:
user_input = state["user_input"]
response = llm.invoke([HumanMessage(content=user_input)])
return {"answer": response.content}
# 构建图
workflow = StateGraph(dict)
workflow.add_node("answer", answer_question)
workflow.add_edge(START, "answer")
workflow.add_edge("answer", END)
graph = workflow.compile()
这个图:
- • 接收 user_input
- • 将其发送到 GPT-4o
- • 返回 AI 生成的响应
- 让它生产就绪
在向全世界开放之前,让我们为真实用例加固它。
错误处理与重试
LLM APIs 可能会失败或超时。用 try/except 包装调用:
from tenacity import retry, wait_exponential, stop_after_attempt
@retry(wait=wait_exponential(multiplier=1, min=2, max=10), stop=stop_after_attempt(3))
def safe_invoke_llm(message):
return llm.invoke([HumanMessage(content=message)])
def answer_question(state: dict) -> dict:
user_input = state["user_input"]
try:
response = safe_invoke_llm(user_input)
return {"answer": response.content}
except Exception as e:
return {"answer": f"错误:{str(e)}"}
输入验证
我们不想让别人发送巨大的数据负载。添加 Pydantic 约束:
from pydantic import BaseModel, constr
class RequestData(BaseModel):
user_input: constr(min_length=1, max_length=500) # 限制输入大小
日志记录
添加日志以提高可见性:
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def answer_question(state: dict) -> dict:
logger.info(f"收到输入:{state['user_input']}")
response = safe_invoke_llm(state['user_input'])
logger.info("已生成 LLM 响应")
return {"answer": response.content}
- 使用 FastAPI 暴露工作流
现在,让我们将这个工作流封装在 FastAPI 中。
# main.py
from fastapi import FastAPI
from workflow import graph, RequestData
app = FastAPI()
@app.post("/run")
async def run_workflow(data: RequestData):
result = graph.invoke({"user_input": data.user_input})
return {"result": result["answer"]}
运行服务器:
uvicorn main:app --reload
- 测试 API
你可以使用 curl 测试:
curl -X POST "http://127.0.0.1:8000/run" \
-H "Content-Type: application/json" \
-d '{"user_input":"什么是 LangGraph?"}'
或者在浏览器中打开 http://127.0.0.1:8000/docs —— FastAPI 会自动为你生成 Swagger UI!
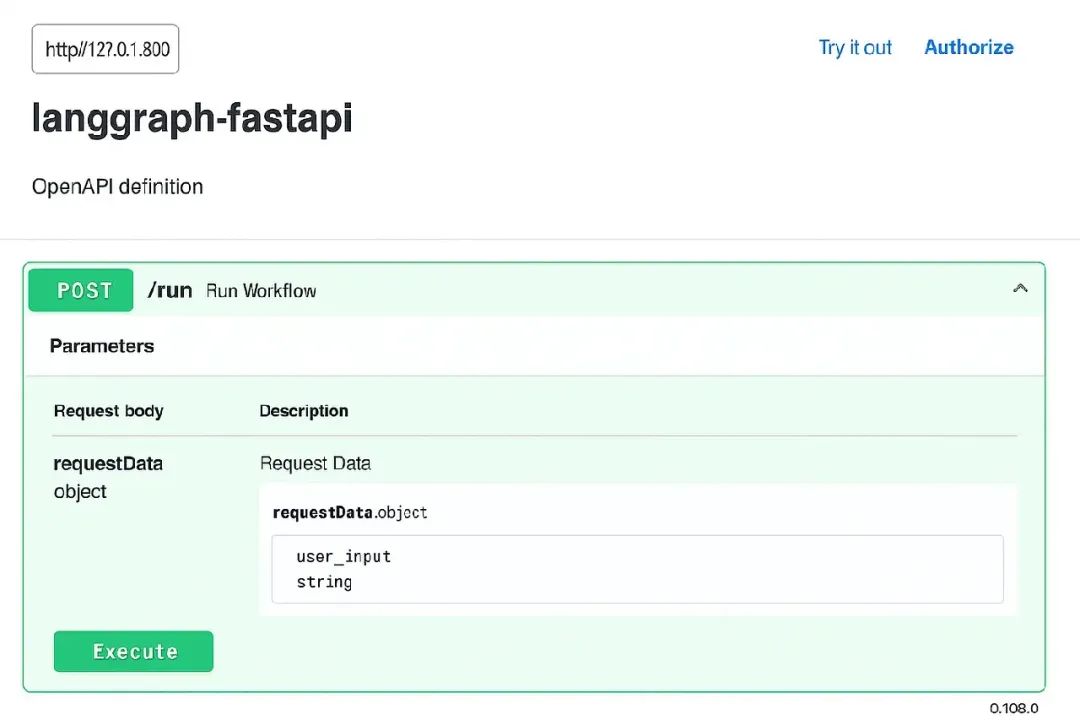
这个交互式 UI 让你直接在浏览器中测试你的 endpoint。
- 扩展与部署
为生产环境做准备的几个步骤:
- • 异步执行:FastAPI 是异步原生的。对于多个 LLM 调用,让函数变成异步的。
- • 工作进程:使用多进程运行以实现并发:
uvicorn main:app --workers 4 - • Docker 化:
FROM python:3.11-slim
WORKDIR /app
COPY ..
RUN pip install -r requirements.txt
CMD ["uvicorn","main:app","--host","0.0.0.0","--port","8000"]
- • 认证:使用 API 密钥或 JWT tokens 来保护 endpoints(第二部分即将推出)。
7. 架构概览
以下是整体连接方式:
POST /run
Client
FastAPI
LangGraph
OpenAI_API
Response
这个简单的架构让你可以将任何 LangGraph 变成一个 API。
- 结论
通过几个简单的步骤,我们:
- • 构建了一个 LangGraph 工作流
- • 使用 FastAPI 将其暴露为 REST API
- • 添加了生产就绪的功能(验证、重试、日志)
- • 为可扩展的 AI 微服务奠定了基础
这个设置可以支持从聊天机器人到文档处理器再到 AI SaaS 产品的各种应用。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 29
29 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)