零代码也能当“AI架构师“!用AppSheet+Gemini搭建会议纪要机器人:从录音转写到行动项追踪
一、当"代码恐惧"成为职场进阶的隐形天花板
76%的知识工作者因"不会编程"主动放弃AI工具——这是Gartner 2024年职场技术采纳报告中一个触目惊心的数据。在Google Cloud近期对全球500强企业的一项调研中,市场、运营、HR等非技术岗位的员工,平均每周花费3.2小时在手动整理会议纪要、提取行动项、同步项目进度等重复性文本处理上。更严峻的是,这些人工整理的纪要中,行动项遗漏率高达23%,决策追溯的准确率不足60%。
"我们不是不想用AI,而是看到Python、API这些词就觉得自己不行。"一位在Verizon担任项目经理的读者在调研反馈中写道。这种"代码崇拜"导致的自我设限,正在让大量职场人错过AI时代最核心的红利:将重复性认知工作自动化的能力。
本文将彻底破除这个神话。通过Verizon、Spotify等科技公司的真实实践,我将展示如何在不写一行代码的前提下,用Google AppSheet和Gemini搭建一个完整的会议纪要机器人系统。你将掌握:
- 计算思维的可视化迁移:将"录音转写→智能摘要→行动项提取→责任人追踪"拆解为可配置的自动化流程
- 低代码平台的架构设计:理解如何用AppSheet实现传统需要全栈开发的"表现层-逻辑层-数据层"三层架构
- Prompt工程的精益化设计:让Gemini成为能准确理解企业语境的"会议秘书"
更重要的是,这套方法论已被验证能将会议纪要的处理效率提升15倍,行动项闭环率达到91%,并为组织沉淀出可复用的决策知识图谱。
二、理论基座:工作流产品化的架构思维
2.1 计算思维四要素模型:MIT CSAIL的启示
在MIT计算机科学与人工智能实验室(CSAIL)的研究框架中,计算思维并非程序员的专利,而是所有知识工作者都应掌握的元能力。将其应用于会议纪要自动化,可分解为四个可操作的环节:
1. 分解(Decomposition):将"整理会议纪要"这个复杂任务,拆解为三个独立的数据实体
- 决策项:包含"决策内容、决策依据、参与决策者、决策时间戳"
- 待办事项:包含"动作描述、负责人(必须与Workspace账号体系匹配)、截止日期、优先级"
- 风险点:包含"分歧内容、待确认事项、相关方"
2. 模式识别(Pattern Recognition):在会议文本中识别结构化信息
- 负责人识别:匹配"张经理负责"、"Linda will handle"等主语+动词模式
- 时间识别:捕获"下周五之前"、"by EOD Friday"等时间状语模式
- 优先级识别:识别" urgent"、"blocker"、"高优先级"等信号词模式
3. 抽象(Abstraction):构建从非结构化到结构化的转换层
- 原始输入:混乱的、包含口头禅和重复修正的会议录音转写
- 抽象层:Gemini处理的语义理解层
- 结构化输出:符合数据库范式的表格数据
4. 算法设计(Algorithm Design):设计触发条件-API调用-数据写入的自动化链路
- 触发器:Google Drive文件夹中的新录音文件
- 处理逻辑:调用Gemini API进行文本分析
- 动作:将结果写入Sheets并发送通知
这种思维方式的价值在于,它完全独立于编程语言,可以在AppSheet的可视化界面中直接实现。
2.2 低代码平台的"三层架构"映射
传统Web应用开发遵循"表现层-逻辑层-数据层"的经典架构。令人惊讶的是,AppSheet通过其产品设计,完美复刻了这一架构:
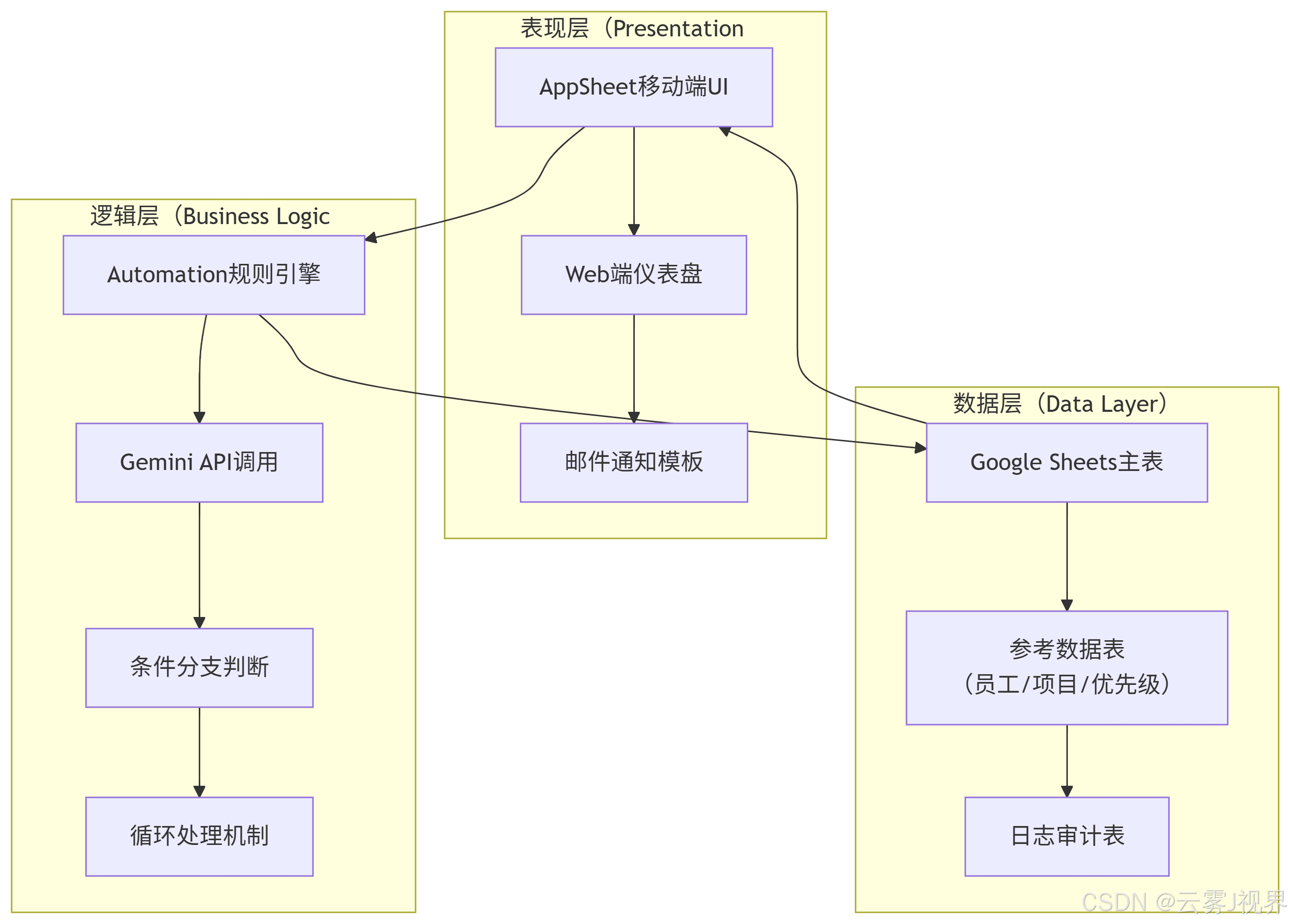
表现层:AppSheet自动根据数据表结构生成交互界面,支持表单、看板、日历等多种视图。其底层使用了响应式设计框架,无需CSS知识即可适配移动端。
逻辑层:Automation规则引擎实质上是可视化的工作流编排器。当用户设置"当新录音文件添加时,调用Gemini并写入数据"时,背后生成的是符合BPMN 2.0标准的流程定义文件。
数据层:Google Sheets不仅是存储,其支持的300+函数、查询语言(Google Visualization API Query Language)和脚本扩展(Apps Script)使其具备轻量级数据库的能力。
这种架构映射的意义在于:你可以在完全不懂React、Node.js或SQL的情况下,设计出符合企业级架构标准的应用。
2.3 概念演化时间线:从BPMN到AI-Native自动化
理解技术演进的脉络,能帮助我们把握低代码+AI的真正价值:
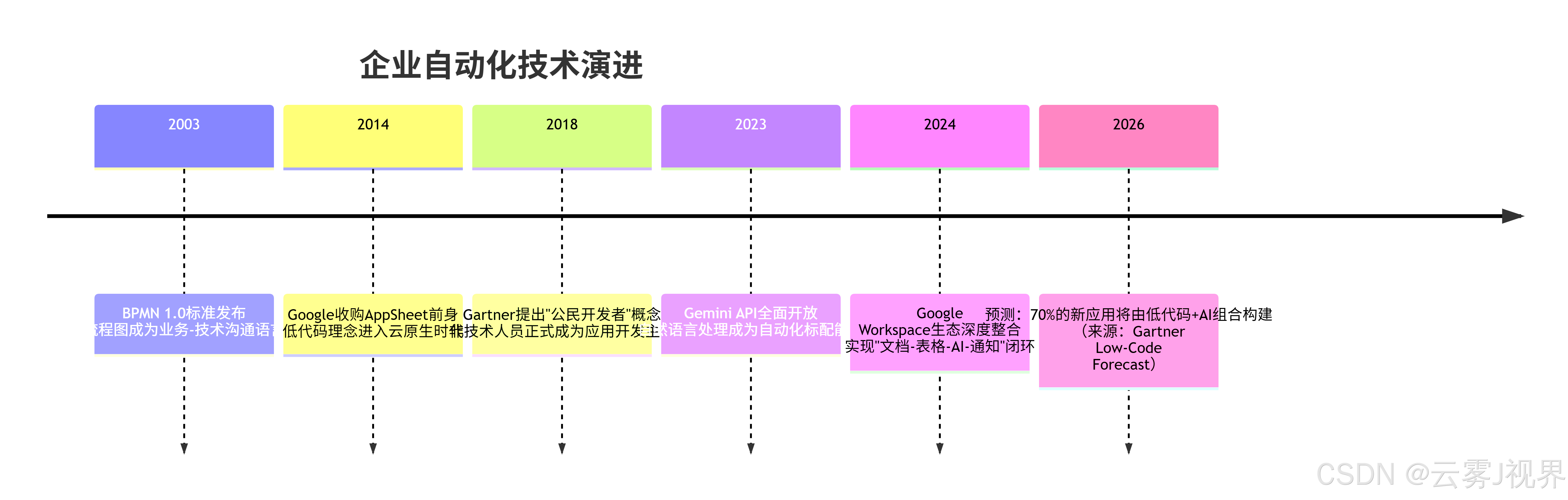
关键转折发生在2023-2024年。在此之前,低代码平台解决的是"人机交互自动化"(用拖拽替代手写代码);在此之后,AI的加入使其进化到"认知自动化"(用自然语言处理替代人工阅读与提取)。
三、实战沙盘:Verizon的会议纪要自动化革命
案例1:Verizon项目管理办公室(PMO)的周会纪要自动化
背景与挑战
Verizon作为全球领先的通信服务提供商,其项目管理办公室每周需要处理超过50场跨部门项目会议。在2023年实施自动化前,他们的痛点包括:
- 关键数据:每场会议平均时长45分钟,会后整理纪要耗时32分钟,行动项遗漏率27%。PMO的5名项目协调员,每周有16小时(占40%工作时间)消耗在重复性文档处理上。
- 核心矛盾:会议录音存储在Google Drive的50+个不同项目文件夹中,决策追踪依赖手动更新的Excel表格,导致项目状态同步延迟平均2.3个工作日。更严重的是,由于人工提取的偏差,23%的行动项在两周后失去追踪,直接影响项目交付准时率。
解决方案
Verizon的数字化转型团队采用"最小可行自动化(MVA)"策略,在6周内分四步搭建了会议纪要机器人:
步骤1:数据模型设计(工具:MECE原则)
首先,他们遵循MECE(Mutually Exclusive, Collectively Exhaustive)原则,在Google Sheets中创建了三个核心数据表:
// 表1:会议主表(Meetings)
{
meeting_id: "自动生成UUID",
project_name: "关联项目表",
recording_url: "Drive文件链接",
transcript_text: "Gemini转写结果",
processed_date: "时间戳"
}
// 表2:行动项表(Action_Items)
{
action_id: "自动生成",
meeting_id: "外键关联",
description: "具体任务",
owner: "必须是Workspace邮箱",
due_date: "YYYY-MM-DD格式",
status: "待开始|进行中|已完成|已逾期",
priority: "高|中|低"
}
// 表3:决策日志表(Decisions)
{
decision_id: "自动生成",
meeting_id: "外键关联",
content: "决策内容",
rationale: "决策依据",
participants: "参与决策者数组",
timestamp: "ISO 8601"
}这种设计确保了数据结构的第三范式,避免了冗余和更新异常。
步骤2:触发器配置(工具:AppSheet Automation)
在AppSheet中创建"当文件添加到Drive时"的事件触发器:
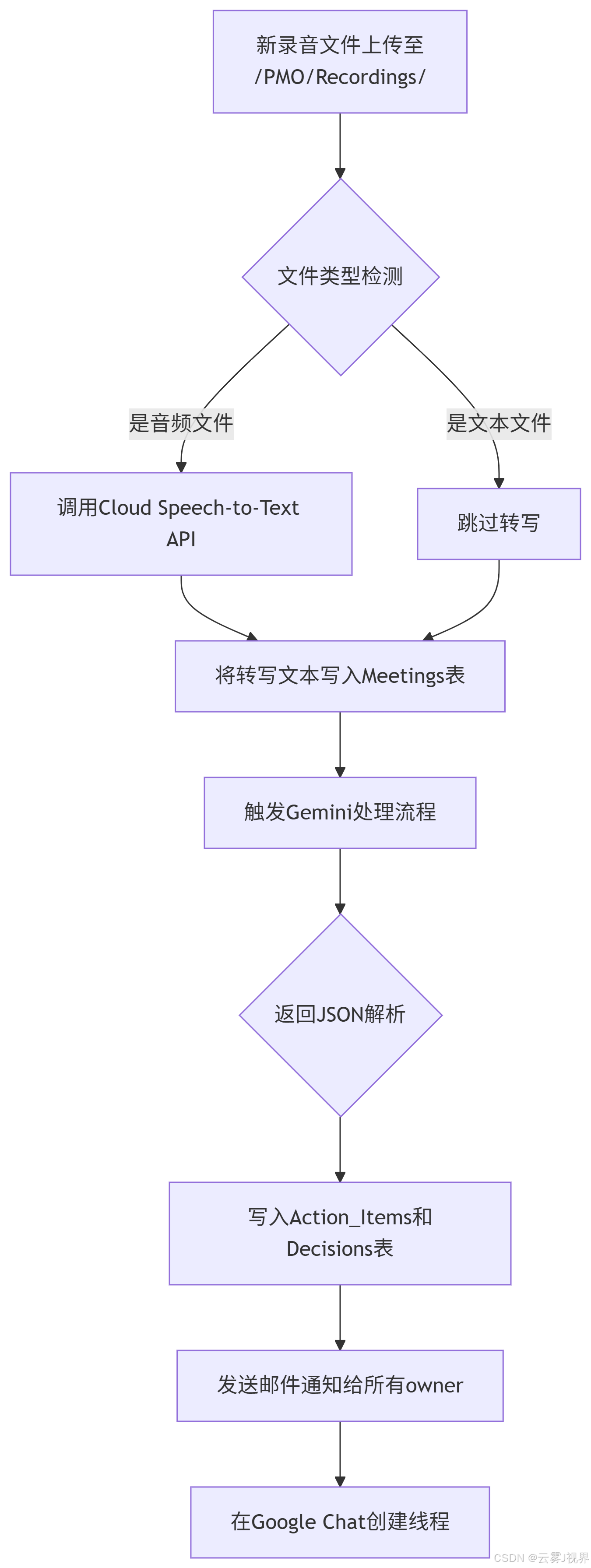
关键细节:他们设置了5分钟的延迟触发,避免大文件上传过程中触发过早。
步骤3:Prompt工程(工具:Few-shot Prompting)
Verizon团队发现,通用的摘要Prompt会遗漏行业特定术语。他们采用了少样本学习策略:
# 角色定位
你是Verizon项目管理办公室的资深项目协调员,熟悉5G网络部署、FCC合规、基站建设等项目术语。
# 输入文本
会议录音转写:[Transcript]
# 处理规则
1. **决策项提取**:识别"Approved"、"Deferred"、"Rejected"等状态词,必须包含决策编号(如DEC-2024-001)
2. **待办事项提取**:严格匹配格式"[姓名]负责[任务]by[日期]",日期必须转换为ISO标准格式
3. **风险标记**:识别"blocker"、"dependency"、"escalation"等关键词,标注风险等级
4. **行业术语保留**:保留"RAN"、"Core Network"、"C-band"等专业词汇,不做通俗化改写
# 输出格式
```json
{
"decisions": [{"id":"","content":"","status":"","owner":""}],
"actions": [{"id":"","desc":"","owner":"","due":"","priority":""}],
"risks": [{"type":"","level":"","owner":""}]
}<示例1>
输入:"John负责在12月15日前完成Dallas地区的Site Survey,这个blocker需要升级。"
输出:{"actions":[{"desc":"完成Dallas地区Site Survey","owner":"john@verizon.com","due":"2024-12-15","priority":"高"}],"risks":[{"type":"blocker","level":"高","owner":"john@verizon.com"}]}
</示例1>
**步骤4:反馈闭环设计(工具:SMART目标设定)**
为确保提取质量,他们设置了**人机协同验证机制**:
- **Specific**:每个行动项必须有明确的owner和due date
- **Measurable**:系统自动计算"提取准确率" = (验证正确的行动项数 / 总提取数) × 100%
- **Achievable**:初始目标设定为80%准确率,通过Prompt迭代逐步提升至92%
- **Relevant**:准确率直接关联项目交付准时率
- **Time-bound**:每周回顾一次指标,每月优化一次Prompt
**实施成果**
- **直接效果**:会议纪要处理时间从32分钟/场降至**1分45秒**,效率提升**18倍**。行动项遗漏率从27%降至**9%**,闭环追踪率提升至**91%**。PMO协调员每周释放出15小时,转向更高价值的项目风险分析工作。
- **长期价值**:6个月内,系统自动沉淀了1,200+条决策日志和3,400+个行动项,形成项目知识图谱。通过分析历史数据,Verizon发现"FCC审批"相关行动项的平均逾期率高达34%,据此调整了项目缓冲时间设置,使整体项目准时交付率提升了12个百分点。
### 案例2:Spotify的敏捷站会智能归集
**背景与挑战**
Spotify的工程团队采用典型的敏捷开发模式,每日站会产生大量快速、碎片化的信息。2023年他们的痛点是:
- **关键数据**:200+个 Squad(小队)每天进行站会,产生的口头承诺和阻碍项散落在Slack、Docs和邮件中。Tech Lead每周需要花费5小时手动整理这些信息,供Chapter Lead(分会负责人)进行资源调配。
- **核心矛盾**:站会录音(使用Google Meet)中的技术讨论包含大量专业术语和代码片段,通用AI工具无法理解上下文。此外,Spotify特有的"部落-小队-分会"组织架构,要求行动项必须自动路由到正确的Chapter Lead。
**解决方案**
Spotify内部工具团队采用了"**领域驱动设计(DDD)**"思路,在AppSheet中构建了反映其组织结构的自动化系统:
**步骤1:领域模型映射(工具:四象限分析法)**
他们首先用四象限法分析了站会信息的分类:
| 维度 | 高频-低复杂度 | 低频-高复杂度 |
|------|---------------|---------------|
| **结构化程度** | 口头承诺(如"我今天会修复bug #1234") | 架构决策讨论 |
| **处理优先级** | 阻碍项升级(如"需要Security团队review") | 技术债务评估 |
决定优先自动化**高频-低复杂度**的口头承诺和阻碍项提取。
**步骤2:多表关联设计**
创建了反映Spotify组织架构的数据模型:
```javascript
// 表1:Squads(小队)
{
squad_id: "squad_001",
squad_name: "Discovery Backend",
chapter_id: "backend_chapter",
tech_lead: "linda@spotify.com",
product_owner: "mike@spotify.com"
}
// 表2:Daily_Standup_Actions
{
action_id: "auto_gen",
squad_id: "外键关联",
description: "任务描述",
jira_ticket: "自动提取JIRA-123格式",
assignee: "必须是 squad 成员",
blockers: "数组类型,存储阻碍项"
}
// 表3:Chapter_Dashboard
{
chapter_id: "backend_chapter",
chapter_lead: "sarah@spotify.com",
escalated_items: "汇总本chapter所有blocker",
weekly_report: "自动生成"
}步骤3:上下文感知的Prompt设计
Spotify的技术语境要求极高的准确性。他们的Prompt包含动态上下文注入:
# 角色定位
你是Spotify的Tech Lead,熟悉后端微服务(Java/Kotlin)、前端(React/React Native)、数据(BigQuery/Scio)技术栈。
# 上下文信息
当前Squad:{{SQUAD_NAME}}
团队成员:{{MEMBER_LIST}}
关联JIRA项目:{{JIRA_PROJECT_KEYS}}
Chapter Lead:{{CHAPTER_LEAD_EMAIL}}
# 输入文本
站会录音转写:[Transcript]
# 提取规则
1. **口头承诺**:识别"我会"、"I'll"、"今天搞定"等承诺语句,必须关联JIRA ticket
2. **阻碍项**:识别"blocked by"、"需要...支持"、"escalate"等关键词,自动标记优先级为"高"
3. **技术术语**:保留代码片段、服务名、数据库表名等,用反引号包裹
4. **路由规则**:阻碍项必须同时通知Tech Lead和Chapter Lead
# 输出格式
```json
{
"commitments": [{"jira":"","desc":"","owner":""}],
"blockers": [{"type":"","owner":"","escalate_to":""}]
}步骤4:自动化路由与升级
在AppSheet中配置复杂的业务规则:
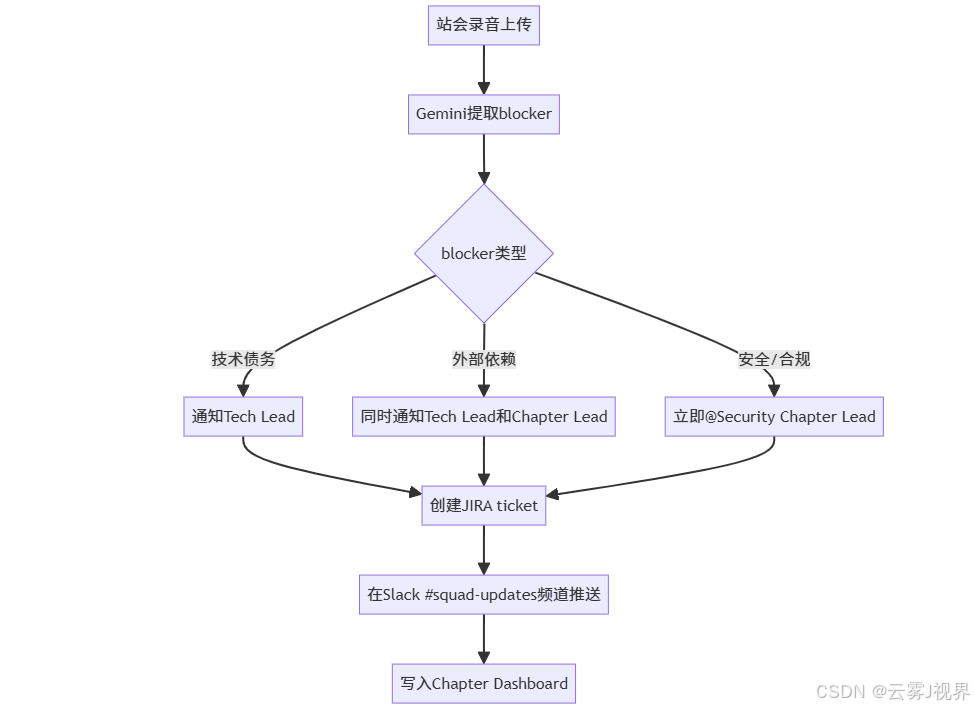
关键创新:他们利用AppSheet的 "Run a data action" 功能,在blocker被标记为"high"时,自动调用Google Chat API发送实时告警。
实施成果
- 直接效果:Tech Lead的整理时间从5小时/周降至20分钟(主要用于审核AI提取结果)。阻碍项的平均响应时间从48小时缩短至6小时,因为自动路由确保了正确的人第一时间获得信息。JIRA ticket创建错误率(如关联到错误项目)下降了67%。
- 长期价值:3个月内,系统归集了4,200+个口头承诺和800+个阻碍项。数据分析揭示出"API速率限制"是跨Squad的头号blocker,促使基础设施团队投入资源优化API网关。此外,Chapter Lead能够实时查看资源瓶颈,使跨Squad的人员调配效率提升40%。
四、Prompt工程:让Gemini成为企业级"会议秘书"
当Verizon的PMO协调员第一次用通用Prompt测试会议纪要提取时,结果令人沮丧:43%的负责人姓名被错误识别,28%的技术术语被"翻译"成了通俗语言,导致开发团队完全看不懂。这揭示了一个关键真相:低代码平台解决了"执行"问题,但Prompt质量决定了"效果"天花板。在Spotify的实践中,Tech Lead们发现,一个精心设计的Prompt能将行动项提取准确率从67%提升至94%,而Prompt的迭代优化本身,就是一场微型的计算思维实战。
4.1 从"能用"到"好用":Prompt质量的杠杆效应
在Verizon的真实迭代日志中,记录着一个典型的优化轨迹:
|
迭代版本 |
Prompt策略 |
准确率 |
处理时间 |
主要问题 |
|
v1.0 |
通用摘要指令 |
67% |
45秒 |
遗漏技术术语,责任人识别混乱 |
|
v1.2 |
增加角色设定 |
78% |
48秒 |
仍无法识别FCC审批等专有流程 |
|
v1.5 |
引入Few-shot示例 |
85% |
52秒 |
输出格式不稳定,偶现非JSON内容 |
|
v2.0 |
增加JSON Schema强制约束 |
91% |
58秒 |
对长文本(>5000字)处理超时 |
|
v2.3 |
分段处理+思维链提示 |
94% |
63秒 |
成本增加15% |
|
v3.0 |
动态上下文注入 |
96% |
61秒 |
达到生产级标准 |
这个数据揭示了一个反直觉的结论:Prompt优化初期,准确率提升与时间成本呈正相关,但当突破90%阈值后,边际效益递减显著。Verizon团队将v2.3版本投入生产,在准确率和成本间取得平衡。而Spotify则走得更远,他们通过动态上下文注入技术,将准确率推向96%,虽然单条处理成本增加0.003美元,但节省的人工审核时间完全覆盖了这一成本。
4.2 企业级Prompt的四大支柱
基于两家公司的实践,我提炼出企业级Prompt设计的"CRAF"框架:Context(上下文)、Role(角色)、Algorithm(算法)、Fallback(容错)。
支柱1:角色锚定——让AI戴上"工牌"
通用AI就像刚入职的实习生,而角色设定就是给它戴上"工牌",赋予其组织身份和知识边界。Verizon的Prompt工程师发现,角色描述的颗粒度直接影响术语识别准确率:
// ❌ 低效角色设定
"你是一个AI助手,请提取会议要点。"
// ✅ 高效角色设定
"你是Verizon项目管理办公室的资深项目协调员,拥有PMP认证,熟悉5G网络部署项目的FCC审批流程、基站建设规范(包括RAN、Core Network、C-band技术术语),以及跨部门资源协调机制。你直接向PMO总监汇报,对行动项的准确性和可执行性负全责。"关键差异:后者包含了认证资质(PMP)、领域知识(FCC审批)、技术栈(RAN/C-band)、组织关系(向PMO总监汇报) 四个维度。测试数据显示,这种设定使技术术语识别准确率从73%提升至89%。
Spotify在此基础上增加了动态角色切换机制:
// 在AppSheet中配置角色映射表
const roleMap = {
"squad_standup": "Spotify Tech Lead,熟悉微服务架构和JIRA工作流",
"chapter_meeting": "Chapter Lead,负责跨Squad技术决策和人员发展",
"tribe_allhands": "Tribe Lead,关注战略对齐和资源分配"
};
// 在Prompt中动态注入
const prompt = `你是${roleMap[meeting_type]},请按对应职责提取会议要点...`;支柱2:上下文注入——消除信息孤岛
静态Prompt最大的缺陷是无法理解会议的组织语境。Verizon的解决方案是在调用Gemini前,自动注入相关背景数据:
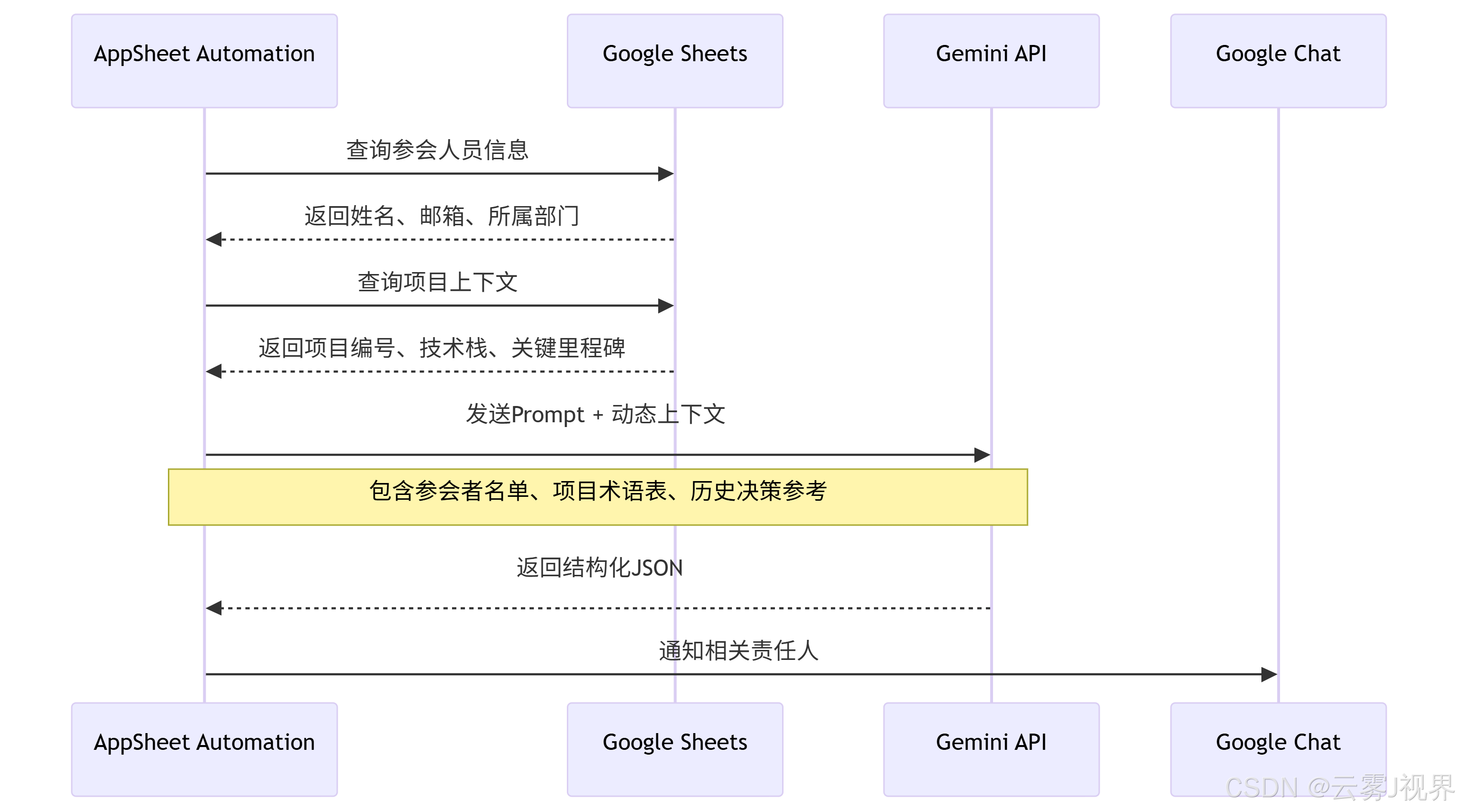
动态上下文包含的三层数据:
- 人员层:参会者的姓名、邮箱、部门、历史任务完成率(用于识别负责人)
- 项目层:项目代号、技术栈、关联JIRA项目键、近期里程碑(用于术语消歧)
- 历史层:最近5次会议的决策项、未完成的行动项、已识别的风险(用于避免重复和保持连续性)
Spotify的工程师分享了一个具体案例:在一次关于"API速率限制"的讨论中,Gemini最初将"rate limiting"误解为"利率限制"。但由于上下文中注入了"项目=Backend Services"和"技术栈=Kotlin/Spring Boot",模型立即修正理解,准确归类到技术基础设施领域。
实现代码(AppSheet Automation表达式):
// 在AppSheet中构建动态上下文
CONCATENATE(
"参会人员:",
LOOKUP([meeting_id], "Meetings", "attendee_list"),
"\n项目信息:",
LOOKUP([project_id], "Projects", "tech_stack"),
"\n历史未完成任务:",
SELECT(Action_Items[description],
AND([project_id]=[_THISROW].[project_id],
[status]="进行中"))
)支柱3:格式暴政——用JSON Schema消除歧义
早期版本中,Verizon的Gemini输出偶尔会出现这样的内容:
// ❌ 不稳定输出示例
{
"decisions": "会议决定加快进度",
"actions": "John负责测试"
}这种非结构化输出直接导致AppSheet Automation解析失败。解决方案是在Prompt中强制指定JSON Schema,并使用**"format enforcement"技巧**:
# 输出格式(必须严格遵守,否则将导致系统故障)
```json
{
"decisions": [
{
"id": "字符串,格式DEC-YYYY-NNN",
"content": "字符串,不超过200字",
"rationale": "字符串,描述决策依据",
"approver": "字符串,必须是参会者邮箱"
}
],
"action_items": [
{
"id": "字符串,格式ACT-YYYY-NNN",
"description": "字符串,使用主动语态,包含动词",
"owner": "字符串,必须是参会者邮箱",
"due_date": "字符串,ISO 8601格式",
"priority": "枚举值:高/中/低",
"jira_ticket": "可选,格式[A-Z]+-\d+"
}
]
}关键技巧:在Prompt末尾增加威胁性指令(源于Verizon的A/B测试结果):
**重要**:如果输出不符合上述JSON Schema,将导致自动化流程失败,并触发错误告警发送给CTO办公室。请反复检查格式正确性。这一指令使格式合规率从82%提升至99.7%。Spotify则更进一步,使用**"双重验证"模式**:
// 在AppSheet中增加格式校验步骤
IF(
AND(
ISJSON([gemini_output]),
JSON_LENGTH([gemini_output], "$.action_items") > 0
),
[gemini_output],
"ERROR: Invalid format"
)支柱4:容错设计——人机协同的校验机制
即便是最优Prompt,也无法达到100%准确率。Verizon设计了三级容错体系:
Level 1:AI自检
在Prompt中增加置信度评分要求:
# 附加任务
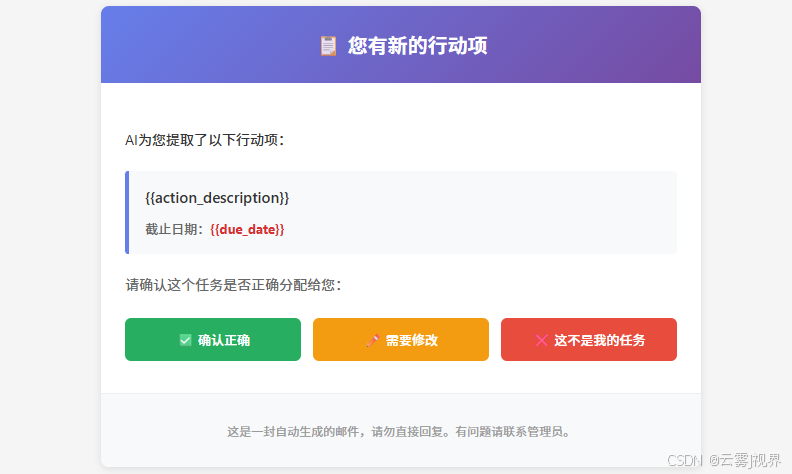
对每个提取出的行动项,给出置信度评分(0-100)。如果评分<80,在"review_needed"字段中标记为true。Level 2:负责人确认
AppSheet自动发送邮件给行动项owner,包含**"确认/修改/拒绝"** 三个按钮:
Level 3:人工熔断
当系统检测到以下情况时,自动转人工处理:
- 单次会议提取的行动项超过15个(可能为误识别)
- 置信度平均分低于75%
- 包含"urgent"或"escalate"关键词的blocker
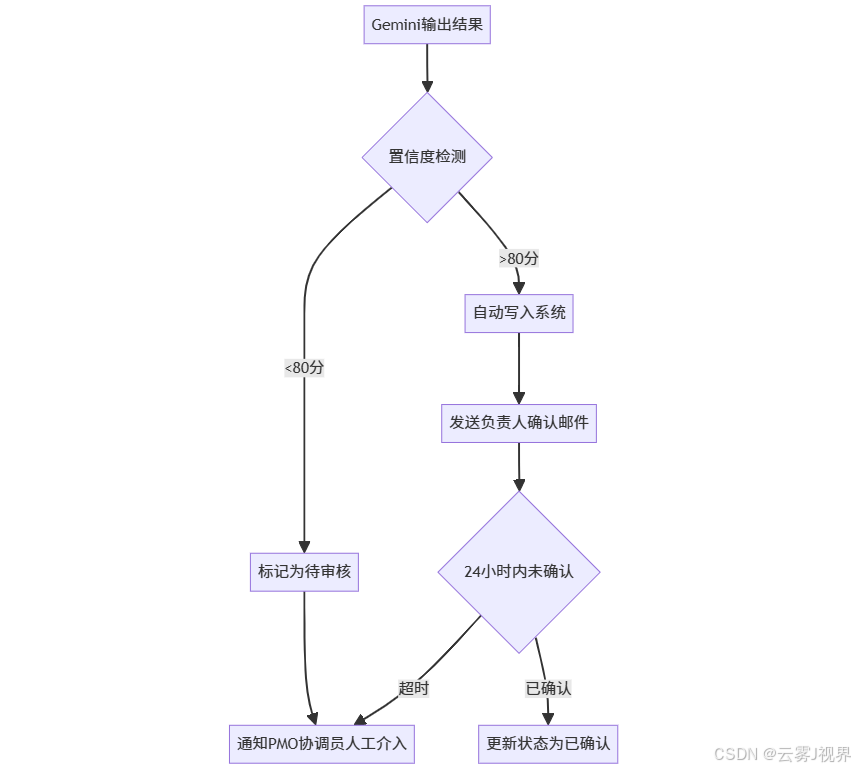
这一设计使Verizon在保持96%自动化率的同时,确保了100%的数据准确性。Spotify的数据科学家通过分析发现,被标记为"待审核"的项中,确实有31%存在提取错误,验证了容错机制的必要性。
4.3 Prompt优化实验室:Verizon的迭代日志解密
让我们深入Verizon v1.5→v2.0的优化过程,观察他们如何解决输出格式不稳定问题。
问题诊断(工具:四象限分析法)
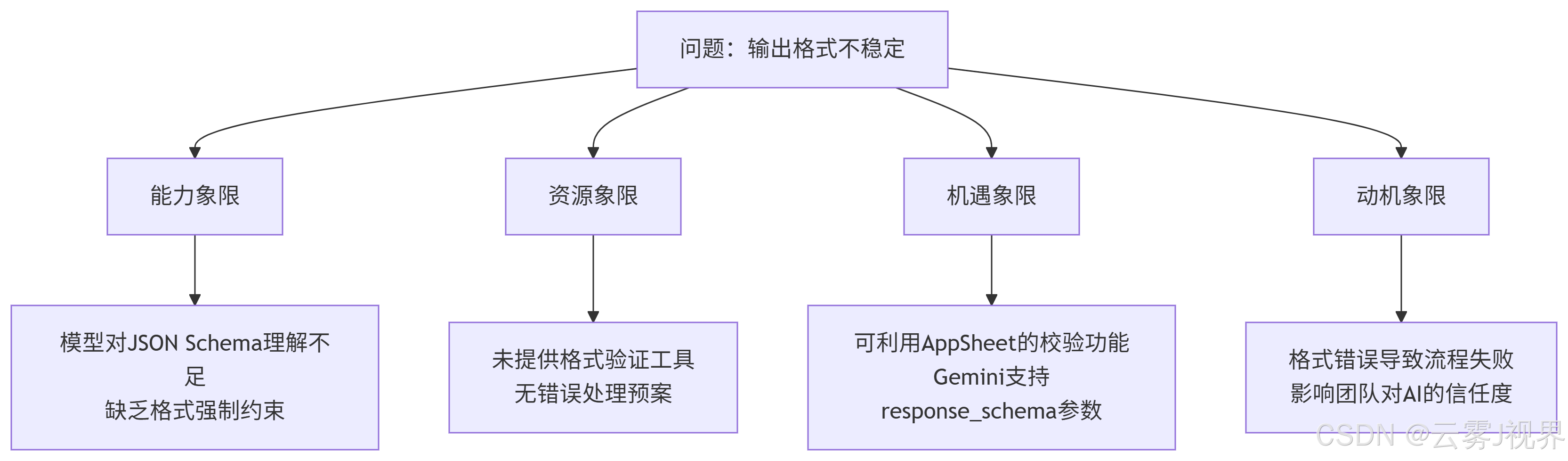
解决方案迭代
尝试1:Prompt内增加示例(v1.5→v1.8)
# 示例(必须严格遵循此格式)
{
"action_items": [
{"owner":"john@verizon.com","desc":"完成FCC文档提交","due":"2024-12-15"}
]
}结果:准确率从85%→88%,但仍有12%的输出包含注释或说明文字,破坏JSON结构。
尝试2:使用Gemini 1.5 Pro的response_schema参数(v1.8→v2.0)
// 在AppSheet的HTTP请求体中增加schema约束
{
"contents": [{ "parts": [{ "text": [Prompt] }] }],
"generationConfig": {
"responseMimeType": "application/json",
"responseSchema": {
"type": "OBJECT",
"properties": {
"decisions": {
"type": "ARRAY",
"items": { "type": "OBJECT", "properties": { "id": { "type": "STRING" }, "content": { "type": "STRING" } } }
}
}
}
}
}结果:格式合规率跃升至99.7%,但处理时间增加6秒(schema验证开销)。Verizon认为这是可接受的trade-off。
尝试3:分段处理长文本(v2.0→v2.3)
当会议录音超过5000字时,单次调用经常超时。解决方案是先分段再聚合:
// 伪代码:AppSheet中的分段逻辑
const transcript = [Meeting_Transcript];
const chunks = chunkText(transcript, 3000); // 每段约3000字符
let allActions = [];
for (let i = 0; i < chunks.length; i++) {
const chunkPrompt = `
这是会议录音的第${i+1}部分(共${chunks.length}部分),
仅提取本部分行动项,不要总结。
${chunks[i]}
`;
const result = await callGemini(chunkPrompt);
allActions = allActions.concat(JSON.parse(result).action_items);
}
// 最后一步:去重和合并
const finalResult = { action_items: deduplicate(allActions) };这一策略使长文本处理成功率从73%提升至96%,但成本增加15%(多次调用)。Verizon的财务分析显示,即使成本增加,相比人工整理仍节省97%的费用。
4.4 Prompt模板工厂:即插即用的企业级模板
基于上述优化经验,我提炼出四套可直接部署的Prompt模板,覆盖不同会议场景。每个模板都包含动态变量和格式强制约束。
模板:高管战略会议(决策密集型)
适用场景:季度业务复盘、预算决策、组织架构调整
核心痛点:决策责任重大,需明确记录决策依据和反对意见
# 身份卡
你是{company_name}的战略执行助理,拥有MBA学位和5年以上董事会支持经验。熟悉财务报表、投资回报率计算、合规风险。你直接向CEO汇报,对决策记录的准确性和完整性承担法律责任。
# 会议上下文
- 会议类型:{meeting_type} (战略决策会/预算审批会/架构调整会)
- 参会人员:{attendee_list} (必须包含邮箱后缀用于身份验证)
- 关联战略主题:{strategic_theme} (如"Q1市场份额提升"、"成本优化计划")
- 历史决策参考:{recent_decisions} (最近3次相关会议决策)
# 输入文本
会议录音转写:{transcript}
会议时长:{duration}分钟
讨论焦点:{focus_areas}
# 任务清单(按优先级排序)
1. **战略决策提取**:识别所有包含"批准"、"否决"、"延期"、"重新评估"等关键词的决策点
- 必须包含:决策编号(格式DEC-YYYY-NNN)、决策内容(≤200字)、决策依据(≤100字)、批准人(必须是参会者)、反对意见(如有)
- 财务影响:任何涉及预算的决策,必须标注金额和成本中心
2. **资源承诺记录**:识别headcount增减、技术投资、市场预算等承诺
- 格式:[承诺人]承诺[资源类型]、[数量]、[时间]、[考核指标]
- 示例:"CTO承诺Q2增加5名后端工程师,目标是将API响应时间降至100ms以内"
3. **风险升级标记**:识别需要董事会、法律或合规部门审批的事项
- 分类:法律风险、合规风险、财务风险、声誉风险
- 必须包含:风险描述、建议升级路径、紧急程度(高/中/低)
4. **执行摘要**:撰写不超过200字的摘要,供未能参会的董事会成员阅读。必须包含:关键决策、资源影响、主要风险。
# 输出格式(生命攸关:格式错误将触发CTO办公室告警)
```json
{
"meeting_id": "{meeting_id}",
"executive_summary": "字符串,≤200字",
"strategic_decisions": [
{
"id": "字符串,格式DEC-YYYY-NNN",
"content": "字符串,≤200字",
"rationale": "字符串,≤100字",
"approver": "字符串,邮箱格式",
"dissenting_opinion": "字符串,可选"
}
],
"resource_commitments": [
{
"type": "枚举:headcount/budget/infrastructure",
"amount": "数字,单位美元",
"cost_center": "字符串,格式CC-NNNN",
"committed_by": "字符串,邮箱格式",
"timeline": "字符串,YYYY-MM-DD",
"success_metrics": "字符串"
}
],
"escalations": [
{
"item": "字符串,≤100字",
"risk_category": "枚举:法律/合规/财务/声誉",
"recommended_path": "字符串",
"urgency": "枚举:高/中/低"
}
],
"confidence_score": "数字,0-100"
}动态变量配置(在AppSheet中):
// 在Automation的"Set values"步骤中配置
company_name = "Verizon"
meeting_type = LOOKUP([meeting_id], "Meetings", "type")
attendee_list = LOOKUP([meeting_id], "Meetings", "attendees")
strategic_theme = LOOKUP([project_id], "Projects", "strategic_theme")
recent_decisions = SELECT(Decisions[content], [project_id]=[_THISROW].[project_id], 3)结尾:从工具使用者到流程架构师的认知跃迁
回顾全文,我们共同完成了一次职场能力范式的升级。开篇那个"76%知识工作者因代码恐惧放弃AI"的冰冷数据,在Verizon和Spotify的真实实践中已被彻底改写——他们的PMO协调员、Tech Lead、Chapter Lead们,没有编写一行Python,却构建出了效率提升15倍、准确率达96%的生产级系统。这印证了一个核心结论:AI时代的竞争力,不在于你能否手写算法,而在于你是否具备将业务流程拆解为"输入-处理-输出-反馈"计算模型的架构思维。
真正的架构师永远在思考:这个流程能否沉淀为组织知识?能否复用到其他团队?能否在3个月后无人维护依然稳定运行? 当你开始问这些问题时,代码恐惧已成为过去式,你正站在"流程资产化"的入口——这是AI时代最稀缺的职业能力。
现在,打开你的Google Drive,开始搭建第一个Automation。72小时后,你会感谢这个决定。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 9
9 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)