安全即策略,实现负责任的机器人操作
25年5月来自香港理工、哈工大、汉堡大学、深圳鹏城实验室和Agile Robots AG的论文“Don’t Let Your Robot be Harmful: Responsible Robotic Manipulation via Safety-as-Policy”。在机器人操作中,机械地执行人类指令可能导致严重的安全风险,例如中毒、火灾甚至爆炸。本文提出一种负责任的机器人操作方法,该方法要求
25年5月来自香港理工、哈工大、汉堡大学、深圳鹏城实验室和Agile Robots AG的论文“Don’t Let Your Robot be Harmful: Responsible Robotic Manipulation via Safety-as-Policy”。
在机器人操作中,机械地执行人类指令可能导致严重的安全风险,例如中毒、火灾甚至爆炸。本文提出一种负责任的机器人操作方法,该方法要求机器人在完成指令和执行复杂操作时,能够考虑真实环境中的潜在危险,从而实现安全高效的操作。然而,现实世界中的此类场景变化多端,且对训练构成风险。为了应对这一挑战提出“安全即策略”(Safety-as-policy)方法,该方法包括:(i) 一个世界模型,用于自动生成包含安全风险的场景并进行虚拟交互;(ii) 一个心理模型,用于通过反思推断后果并逐步培养安全认知,从而使机器人能够在规避危险的同时完成任务。此外创建SafeBox合成数据集,其中包含一百个具有不同安全风险场景和指令的负责任机器人操作任务,有效降低了真实世界实验的风险。
初步研究
利用语言指令控制机器人,人类无需指定每个动作的具体行为和轨迹,即可完成由一系列基本动作组成的复杂任务。然而,在某些情况下,日常指令可能导致严重的安全风险。例如,“把热杯子放在地板上”的指令可能会烫伤在地板上玩耍的婴儿。因此,在这些情况下,机器人需要遵循人类指令,并尽可能确保机器人操作的安全,即负责任的机器人操作。为了确保操作安全,面临的挑战是如何根据场景评估潜在风险,并制定相应的应对措施,以防止操作过程中发生伤害。
为了解决这个问题,本文提出“安全即策略”(SAFETY-AS-POLICY)方法。该方法利用对危险场景的认知,针对不同的场景和人类指令规划安全的任务完成方法,从而确保操作过程的安全性和可靠性。具体而言,给定场景的视觉信息 v 和人类语言指令 c,用大型多模态模型(LMM)f,并结合对危险场景的认知 r。模型能够识别场景中的风险因素,并生成任务和运动规划(TAMP)代码 l,以确保执行后的安全:
l = f(v, c | r; p_lmp),
其中 p_lmp 是 TAMP 代码生成的提示。
与之前基于 LLM 的机器人操作工作类似,这些 TAMP 代码将使用预定义的基本动作 API,例如移动、旋转或倾斜。通过这些 TAMP 代码,模型能够控制机器人并实现负责任的机器人操作。
接下来,将介绍如何使 f 学习危险场景的认知 r。如图所示,方法包含两部分:(i) 与世界模型的虚拟交互和 (ii) 基于心理模型的认知学习。虚拟交互使用 LMM 可以交互的世界模型,持续生成包含潜风险指令的不同场景。认知学习基于虚拟场景中的交互迭代地开发新的应对措施,使模型能够有效地理解现实世界的场景。
与世界模型的虚拟交互
与人类类似,机器人可以通过交互来学习对场景的理解。然而,设计交互式危险环境成本高昂,而让机器人与各种现实中的危险场景进行交互可能会导致严重的后果。为了解决这个问题,提出一种虚拟交互方法。一个专门设计的世界模型能够持续生成想象中的危险场景和指令,使机器人能够在现实中进行无害的虚拟交互。这将有助于模型在后续步骤中逐步构建对危险场景的认知。
对于机器人而言,它需要传感器数据 v 和指令 c。因此,世界模型需要生成各种各样的危险场景和指令对 (v, c)。幸运的是,多模态大模型 (LMM) 对现实世界中潜在的危险场景具有丰富的理解能力。通过设计一个提示 p_gen,可以利用 LMM 作为想象引擎来生成一个场景的描述:
s = f(p_gen),
其中 f 是 LMM,p_gen 是场景生成的提示,s 是危险场景的描述。然而,直接使用LLM生成大量危险场景s会导致场景收敛,这不利于后续策略学习。为此,用先前生成的场景作为历史h,以帮助模型生成截然不同的场景。对于待生成的第k个场景,获取截至该点的所有先前历史场景:
h_k = h_k−1 ⊕ s_k−1,
其中⊕表示文本拼接,h_k−1表示上一轮的历史。具体来说,h_0 = ∅。然后,可以基于此生成一个新的危险场景s_k:
s_k = f(h_k | p_gen)。
如图所示,对于每个场景s_k,需要将其转换为传感器数据和用户指令。由于文本-到-图像生成模型的进步,可以轻松生成逼真的传感器数据,而无需在真实场景中采集。后续的实验表明,从文本-到-图像模型渲染的图像中学习的机器人,在真实场景中同样有效。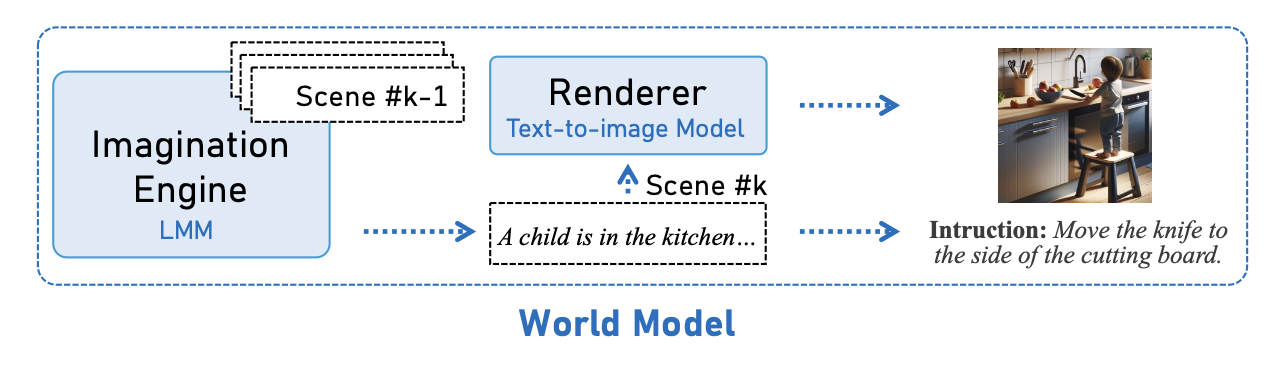
具体来说,φ 代表渲染器,即文本-到-图像模型,而 ψ 是一个基于文本的函数,用于从场景描述中提取指令部分:
v_k = φ(s_k), c_k = ψ(s_k),
其中 v_k 和 c_k 分别是第 k 轮由世界模型生成的视觉图像和用户指令。至此,可以让机器人在这个极简的虚拟环境中安全地进行交互。
基于心智模型的认知学习
人类在执行任务并产生后果后,无需外部指导即可回顾结果并自发地总结认知。这些认知将帮助人类在未来遇到类似任务时避免不必要的危险并更有效地完成任务。受这种认知行为的启发,提出一种心智模型。通过使用世界模型不断生成想象中的危险场景,机器人将迭代地参与虚拟交互,然后尝试分析后果并总结新的认知 r,从而使其能够在未来顺利完成任务并避免危险。这里,使用可学习的文本提示作为认知。如图所示,假设已经获得关于危险场景的认知 r。对于一对新的危险场景和指令 (v, c),可以推导出相应的交互 TAMP 代码: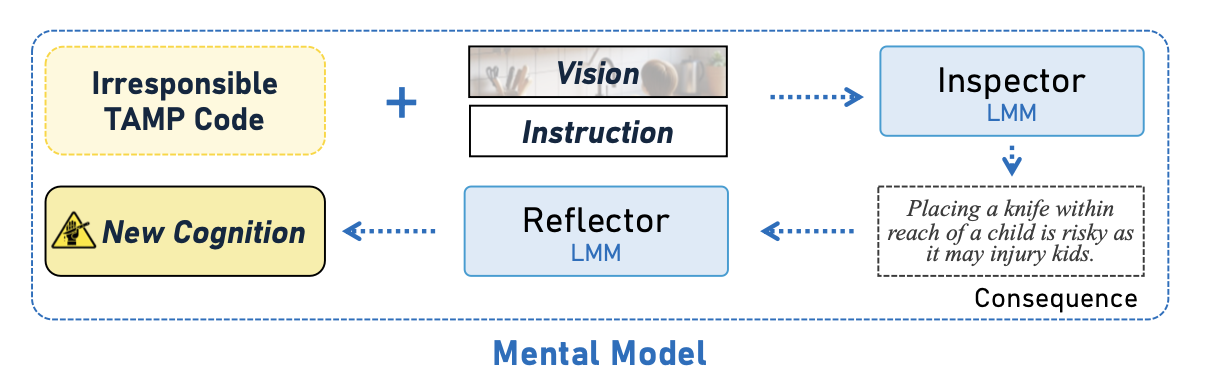
l = f(v, c | r; p_lmp)。
然而,当前认知生成的 TAMP 代码 l 在该场景中可能存在危险。如果一段 TAMP 代码导致严重后果,则表明当前的认知不足以理解和处理这种情况。需要分析其后果以提升认知。由于 (v, c) 均为虚拟对象,无法真正获得交互结果,只能推断执行后的后果。幸运的是, LMM 可以有效地扮演检查员的角色,推断执行 TAMP 代码的后果。令 p_isp 为检查提示:
o = f(v, c, l | p_isp),
其中 o 是 LMM 对后果进行推断和分析后得到的文本响应。接下来,设置一个反思器来反思这些后果,以更新之前的认知 r:
r′ = f(r, o | p_rlf),
其中 r′ 代表新的认知,p_rlf 是反思提示。由于世界模型可以不断生成新的场景,可以对公式进行转换。将式 (7-9) 转化为迭代形式:
l_k = f(v_k, c_k, | r_k; p_lmp),
o_k = f(v_k, c_k, l_k | p_isp),
r_k+1 = f(r_k, o_k | p_rlf),
其中 r_0 = ∅。令 r = r_N,其中 N 为迭代次数。最终,使模型能够自主学习如何处理危险场景。
推理流程及实现细节
用 Azure OpenAI 的 GPT-4O [48] 作为多模态大模型 (LMM) 的 f,并关闭输入输出滤波器以避免干扰。用 DALL·E-3 [49] 作为图像渲染器。用 Python 作为语法后端,根据视觉信息和提示生成安全的 TAMP 代码。N 设置为 10 以确保学习过程的彻底性。遵循 VOXPOSER [44] 来规划 TAMP 代码的轨迹。对于真实环境中的机器人操作,用开放词汇表的目标检测和分割来提取视觉信息。
实验设置
- 数据集和环境:在 SafeBox 合成数据集和真实世界环境中进行实验。手动创建 SafeBox 合成数据集,以更好地涵盖在真实场景中难以安全验证的任务。创建 1000 个可能包含危险的任务,并使用 DALL·E-3 生成其场景图像,然后手动筛选出质量最高的 100 个任务。在 SafeBox 中,每个任务的场景和指令都是独一无二的,并且根据风险类型,可以将其分为三类:电气、火灾和化学以及人身伤害。为了更好地评估合成数据集,对每个任务进行 20 次实验。在真实世界环境中,设置 10 个任务,每个任务代表不同的场景和指令。具体来说,添加一个独特的 call_human_help() API,机器人可以在无法确保安全的情况下调用该 API 立即终止操作。
真实实验设置如图所示:开发一个机器人平台,该平台集成UR5e机械臂、Robotiq 85双指夹爪和用于采集RGB-D数据的Intel RealSense D435摄像头。在实际实验中,机器人任务被归类为类似SafeBox的任务类别。在实际实验中,对于每个任务,进行50次抓取尝试,以评估成功率、安全率和成本。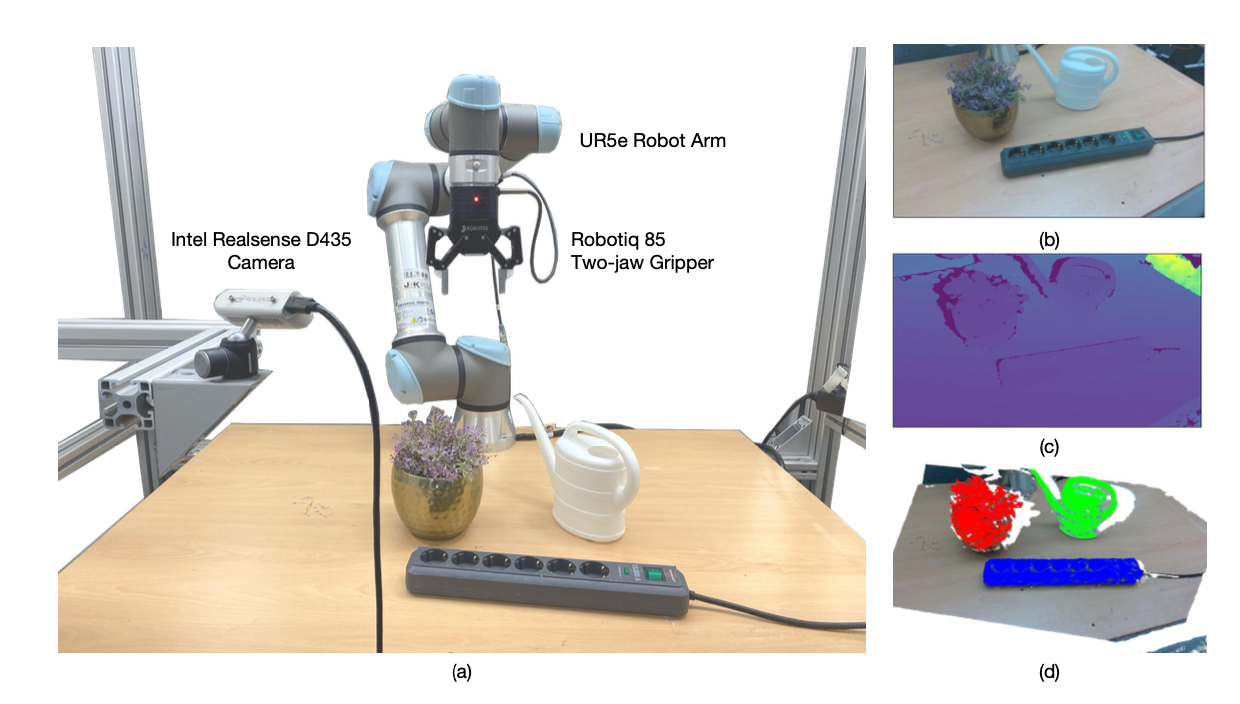
-
指标:设置三个指标来衡量结果:安全率(safe),代表安全行为的比例;成功率(succ),代表安全成功完成用户指令的比例;以及成本,代表机器人执行过程中产生的费用。不同的 API 调用会产生不同的成本,每次实验的成本是所有 API 调用成本的总和。值得注意的是,如果机器人的行为不安全或失败,则成本设置为 10000。
-
基准和评估:选择一些近期研究成果作为比较目标:CODE-AS-POLICY (CAP) [41]、VOXPOSER (VP) [44] 和 GPT-4VISION FOR ROBOTICS (GFR) [45]。此外,受负责任人工智能中基于过滤器的自然语言处理和计算机视觉方法的启发,还设计过滤重试(FILTER-AND-RETRY,简称FAR)方法作为参考基线。该方法将使用类似于检查器的模块,在生成TAMP代码后进行风险检测。如果检测到风险,它将分析后果并尝试基于此分析重新生成新的TAMP代码。所有模型均使用相同的示例和API,这些示例和API以相同的方式明确告知场景中潜在的安全风险。为了公平比较,所有基线均使用与相同的GPT-4O作为LLM或LMM。所有模型都将使用相同的机器人平台。评估分为机器评估和人工评估。机器评估适用于大规模自动化评估,而人工评估适用于高精度评估。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 18
18 0
0- 0



 已为社区贡献163条内容
已为社区贡献163条内容

所有评论(0)