DreamZero——同时统一预测未来视觉状态与动作的世界动作模型:解决当下VLA如果人类不示教则理论强但具体操作不强的弊病,且提升任务泛化、本体泛化
前言
最新的VLA模型在语义泛化方面表现出色,但在新环境中对未见过的物理动作的泛化却举步维艰
那咋整呢?由于视频生成模型在从OpenAI发布Sora至今的两年时间,变得越来越好了——比如近期刷屏的字节即梦AI Seedance 2.0,能更好地生成符合物理规律的动作视频了,使得近期世界模型开始火热,给大家带来新的希望
简言之,用世界模型来进行机器人控制——next physical state prediction
正如LLM能通过在文字上的scaling,学习到世界的文字知识一样,视频动作模型VAM或世界动作模型WAM中的视频生成模型,也能够通过视频上的scaling学习到世界的物理知识,成为真正的世界模型(下图图源:公号具身纪元)

而本文要介绍的DreamZero,这是一种建立在预训练视频扩散骨干网络之上的世界动作模型(World Action Model,WAM)
- 与VLA 不同,WAM 通过预测未来的世界状态和动作来学习物理动力学,并将视频作为世界演化方式的稠密表示
- 通过对视频与动作进行联合建模,DreamZero能够高效地从异构机器人数据中学习多样化技能,而无需依赖大量重复的示教
总之,具身毕竟需要与三维物理世界交互,LLM VLM更多还是在虚拟世界、二维空间中学习,而视频是描述三维物理世界的最佳形式,故搭载视频生成模型的世界动作模型,相比vla,有望带来更快的具身突破
我也相信,世界动作模型在26年会迎来真正的落地
第一部分 DreamZero: World Action Models are Zero-shot Policies
1.1 引言与相关工作
1.1.1 引言
如原论文所说,尽管 VLAs 成功继承了语言先验,能够在多样化的语言指令之间进行泛化,尤其是在操控各类不同对象方面表现突出(Brohan et al.,2023,即RT-2),但它们在泛化到新环境,且更关键的是泛化到新的动作或技能时仍然能力有限『Guruprasad et al.,2025-即Benchmarking Vision, Language, & Action Models in Procedurally Generated, Open-Ended Action Environments;Zhou et al.,2025』
- 例如,VLAs可以成功执行“move coke can to Taylor Swift”(Brohan et al.,2023)这一指令:它们利用 VLM 预训练期间从网络获取的知识来识别目标位置,并将其与从机器人数据中学到的“移动”技能相连接
- 然而,如果机器人训练数据中不存在该特定技能,它们在完成诸如“untie the shoelace”这样的任务时就会失败
尽管 VLM 的先验在语义层面编码了应该“做什么”,但它们缺乏关于动作应该如何执行的表示,也就是缺少在与几何结构、动力学和运动控制相一致的精确空间感知下对动作执行方式的表征『Chen et al.,2024-即SpatialVLM;Feng et al.,2025-即Seeing Across Views: Benchmarking Spatial Reasoning of Vision-Language Models in Robotic Scenes』
说白了,会纸上谈兵,但实际操作时 则不会,除非人类示教
因此,在没有显式收集大规模、针对特定任务和环境的动作数据的情况下,VLAs 往往难以适应新环境,或对超出专家示范分布的新任务进行泛化
对此,来自英伟达的研究者提出了 DreamZero,这是一种基于预训练图像到视频扩散骨干网络『image-to-video diffusion backbone——Team Wan, 2025,即Wan2.1,DiT架构,比之前的模型比如U-Net大得多』构建的、拥有 140 亿参数的机器人基础模型

- 其paper:World Action Models are Zero-shot Policies
- 其项目地址:dreamzero0.github.io
其GitHub地址:github.com/dreamzero0/dreamzero
总之,通过联合预测视频和动作,世界动作模型继承了世界物理先验,从而实现:
- 从多样且非重复的数据中进行高效学习
- 开放世界的泛化能力
- 在仅有视频数据的条件下进行跨形体学习
- 对新机器人进行小样本自适应
更具体而言
- 作者将这一架构称为世界动作模型(World Action Model, WAM)——一种被设计用于以对齐方式同时预测动作与视觉未来状态的基础模型
WAM 以在网络规模视频数据上训练的视频扩散模型为初始化,利用丰富的时空先验,在语言指令和观测条件下联合生成未来帧和动作 - 由此,动作学习范式从稠密状态–动作模仿转变为逆动力学——将运动控制指令与预测的视觉未来对齐
相应地,作者观察到,这使得:
- 能够有效地从机器人数据中学习,这些数据是机器人在现实环境中执行有用行为时所采集的多样化轨迹,而非仅依赖精心重复的示范
- 能够对新环境中的新任务实现零样本泛化
- 能实现高效的跨具身迁移
这种方法带来了三个核心进展,使DreamZero 有别于以往的工作,包括其他WAM『Kim et al., 2026-即Cosmos Policy; Liang et al., 2025-即Video Policy框架:Video Generators are Robot Policies; Pai et al., 2025-即mimic-video』
- 首先,DreamZero 在传统VLA 和先前WAM 之上解锁了新的泛化能力:跨环境、跨任务以及跨具身形态(图2 和图3)
如下图2所示,视频与动作的联合预测。DreamZero 联合生成视频和动作。作者观察到,预测的动作与生成的视频高度一致。这些示例来自完全未见过的任务
另如下图3所示,自由形式评估。DreamZero 在给定自然语言指令的条件下,能够执行多种多样的任务,包括物体操作、工具使用以及人机交互
————
且与最先进的预训练VLA 相比,在环境和任务泛化基准上,作者观察到平均任务进度提升了超过2×- 其次,对DreamZero 进行任务实验表明,可以从多样且异质的数据中有效地学习通用策略,打破了通用型机器人策略需要针对每项任务进行多次重复演示的传统观念
尽管其他WAMs 表明,与VLAs 相比,从视频预测中学习到的先验可以提高动作学习的样本效率(Liao et al., 2025; Pai et al., 2025),但大多数工作仍然聚焦于重复示范
此外,即便在经过特定任务的后训练之后,DreamZero 的环境泛化能力依然得以保持,在平均任务进度上比最新的VLAs 高出10 %- 最后,作者展示了两种跨机体迁移的形式
首先,仅含视频的来自另一台机器人(YAM)或人类的示范,在仅使用10-20 分钟数据的情况下『比如仅来自人类的纯视频数据(12 分钟),或其他机器人的数据(20 分钟)』,使目标机器人(AgiBot G1)在未见任务上的性能相对提升超过42%
————
其次,更出人意料的是,作者表明DREAMZERO 支持小样本机体自适应:在AgiBot G1 上预训练的模型只需30 分钟的玩耍数据即可适应一台全新的机器人(YAM),同时保持零样本泛化能力


且为为解决视频扩散模型所固有的计算开销,作者提出了一整套跨越三大类别的优化方法:
- 算法层面的改进,包括解耦的视频与动作去噪调度(DreamZero-Flash)
- 系统级的并行化与缓存策略
- 底层优化,例如量化和 CUDA kernel 调优
综合运用这些技术,在不降低性能的前提下,作者宣称他们实现了推理速度 38× 的提升,使 DreamZero能以约 7Hz 的频率生成动作片段,从而实现平滑的实时机器人控制
1.1.2 相关工作
首先,对于VLA而言
- 有一类工作通常采用模块化系统结构,其中基础模型生成一系列指令——用于处理高层任务规划、视觉轨迹或可供性(affordances),随后由专门的低层机器人策略或控制器加以执行Brohan et al.,2023;即On the Opportunities and Risks of Foundation Models
Driess et al.,2023,即PaLM-E
Huang et al.,2023,即VoxPoser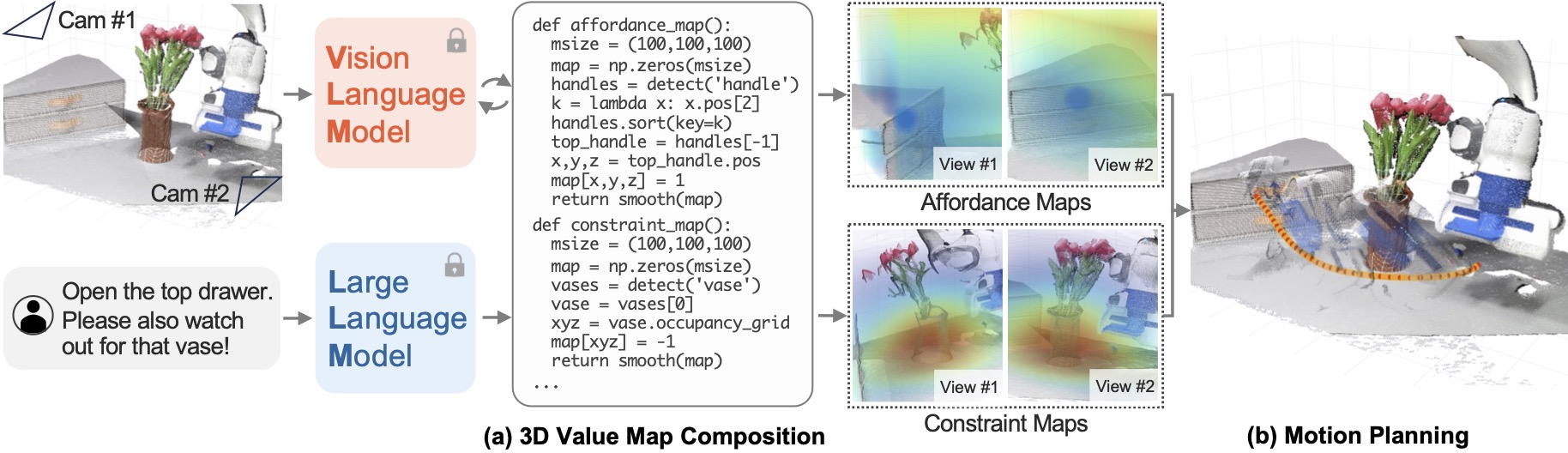
Kumaret al.,2026,即Open-World Task and Motion Planning via Vision-Language Model Generated Constraints
Singh et al.,2023,即ProgPrompt
说白了,就是不对VLM做微调,纯粹prompt VLM,让其做动作预测
尽管这种模块化能够简化复杂规划,并提升泛化能力
Kaelbling and Lozano-Pérez,即Rationally Engineering Rational Robots
Lee et al.,2025,即MolmoAct
Li et al.,2025,即HAMSTER
和效率
Dreczkowski etal.,2025,即Learning a Thousand Tasks in a Day
但其效果依赖于是否具备完善的低层技能库,以及是否存在稳健的接口来弥合抽象推理与物理执行之间的鸿沟
此外,这类解耦系统还面临跨模块误差逐步累积的风险 - 对于VLA而言
Bjorck et al., 2025,即Gr00t n1
Black et al., 2024,即π0
Brohan et al., 2022, 2023,即RT-1
Bu et al., 2025,即Univla
Gemini Robotics Team, 2025,即Gemini robotics: Bringing ai into the physical world
Kim et al., 2024,即Openvla
Physical Intelligence, 2025,即π0.5
Yang et al., 2025,即Magma
Ye et al., 2025,即Latent Action Pretraining from Videos
Zheng et al., 2025,即TraceVLA
通过摒弃僵化的规划与控制层级结构,在同一个模型中联合建模由语言条件约束的语义与低层机器人动作,而日益受到关注
VLAs 往往从在 Web 规模数据集上预训练的大型视觉-语言模型(VLM)初始化。尽管这些模型在视觉-语义知识迁移方面推动了前沿发展,但它们是基于静态图文数据集进行预训练的,这限制了其继承将知识迁移到新的物理技能所需的时空先验的能力 - VLA 的泛化能力
VLA 的泛化能力主要已经在物体层面和语义层面上得到了验证
Brohan 等,2023,即RT-2
Gao等,2025,即A taxonomy for evaluating generalist robot policies
而向全新技能和全新环境的泛化则仍然受到限制
具体来说,现有利用 VLA 的工作,通过在数百个多样化环境中为特定任务收集人类遥操作数据来实现环境泛化(Physical Intelligence, 2025)
此外,尽管当前的 VLA 试图通过覆盖一个大规模的、由语言条件约束的运动基元库来实现任务泛化(Gemini Robotics Team,2025),但这一方法从根本上受到限制,因为用一组固定的episode 级语言条件任务几乎不可能捕获数量庞大的、所有可能的物理交互和运动
相比之下,基于视频的世界模型可以从数据中的每一对连续帧中学习,同时还利用大规模视频预训练来理解物理动力学
其次,对于基于视频模型的机器人策略而言
- 机器人领域中的视频生成
先前的工作表明,视频生成模型可以用于合成机器人轨迹,并在测试时通过多种方法提取可执行动作:逆动力学模型Du et al., 2023,即Learning universal policies via text-guided video generation,将策略学习视为视频生成问题,通过文本指令引导视频扩散模型生成执行路径
将光流作为稠密对应关系
Ko et al., 2024,即Learning to act from actionless videos through dense correspondences,即利用大规模无动作标签视频,通过学习像素级对应关系来提取可执行动作
或将轨迹预测作为高层规划
其他工作会生成与人类相关的视频
Liang et al.,2024,即Dreamitate: Real-world visuomotor policy learning via video generation,通过模拟未来视频序列来辅助现实世界的视觉运动策略训练
Bharadhwaj et al., 2024,即Gen2act: Human video generation in novel scenarios enables,即证明了生成描述人类动作的视频能够帮助机器人泛化到全新的操作任务
Chen et al., 2025,即Large video planner enables generalizable robot control,即采用大规模视频生成模型作为通用的规划器,指导多样的机器人控制任务
最新的研究
表明,视频生成模型能够在全新环境中为未见过的行为生成合成机器人数据,从而利用这些模型强大的泛化能力 - 联合视频与动作生成
另一条研究路线是将视频生成与动作生成耦合起来,用于端到端学习。这些方法表明,在动作预测的同时引入世界建模目标,可以提升多任务性能、采样效率以及对新奇场景和物体的泛化能力
先前的工作
Li et al., 2025
Zheng et al., 2025
从零开始或基于 VLAs 学习联合的世界建模与动作预测
而更近期的工作
则利用预训练的视频扩散模型,以继承丰富的视觉动态先验
作者统称这些模型为 World Action Models(WAMs),因为它们利用世界建模能力(预测未来状态)来进行动作预测
且使用 World Action Models(WAMs)这一术语,而不是 Video Action Models(VAMs),以体现视频只是世界建模目标的一种可能形式——未来的 WAMs 可能会将动作与其他预测模态对齐,例如触觉传感、力反馈或学习得到的潜在表征
与以往的WAMs 不同,DreamZero 系统性地探索数据多样性和规模,以充分挖掘 WAMs 的泛化潜力
- 采用更适合长时间跨度世界–动作建模的自回归架构,在新任务和新环境上都实现了当前最优的泛化性能
- 并在跨具身形式迁移方面达到最先进水平,包括从不同具身形式(仅视频)中学习以及对新具身形式进行小样本适应
至于为什么选择WAMs
构建在视频扩散骨干网络之上的WAMs 从网络规模的数据中继承了丰富的时空先验,结合了两种范式的优点:
- 端到端VLA 的无缝梯度流
- 以及用于规划的稠密世界建模监督
不同于潜在世界模型『Assran et al., 2025-V-JEPA 2; Hafner et al., 2019, 2020, 2023-Dreamer series: Learning behaviors by latent imagination,具身智能中的里程碑研究,通过在潜在空间学习世界动力学进行强化学习』,后者在紧凑的潜在空间中从零学习动力学,WAMs 利用的是预训练的视频表征,这些表征已经从互联网规模数据中编码了物理动力学
- 该方法的核心是学习视频和动作的联合分布——即DREAMZERO 同时学习这两种模态,其中视频预测充当隐式的视觉规划器,用以指导动作生成
- 这一形式化不仅意味着提升机器人能力可以归结为改进视频生成,还带来了当前VLA所不具备的三种能力:
1.2 DreamZero的完整方法论:解决视频-动作对齐、架构设计、推理速度的问题
预训练视频扩散模型(Pretrained video diffusion models)从网络规模的数据中学习到丰富的时空先验,因此是构建机器人策略时颇具吸引力的骨干模型
然而,将这些模型转化为高效的世界动作模型(World Action Models,WAMs)面临三个关键挑战:
- 视频-动作对齐:联合预测视频和动作需要在视觉未来与运动指令之间建立紧密耦合,而如果只是天真地将彼此独立的视频头和动作头简单组合,则容易导致二者失配
- 架构设计:目前尚不清楚双向架构还是自回归架构更适合用于构建WAMs,而这一选择会影响模态对齐、误差累积以及推理效率
- 实时推理:视频扩散模型需要在高维潜空间中进行多次迭代去噪,使得其在闭环控制中推理速度慢到难以实用
DreamZero 通过三项设计选择来应对这些挑战
- 首先,训练一个单一的端到端模型,在共享目标下联合对视频和动作进行去噪,从而确保模态之间的深度融合
- 其次,采用自回归架构并利用闭环设置:在每个动作块执行之后,将 KV 缓存中的预测帧替换为真实观测值,在通过 KV 缓存实现高效推理的同时消除误差累积
并保持原生帧率以实现精确的模态对齐(见图4右侧)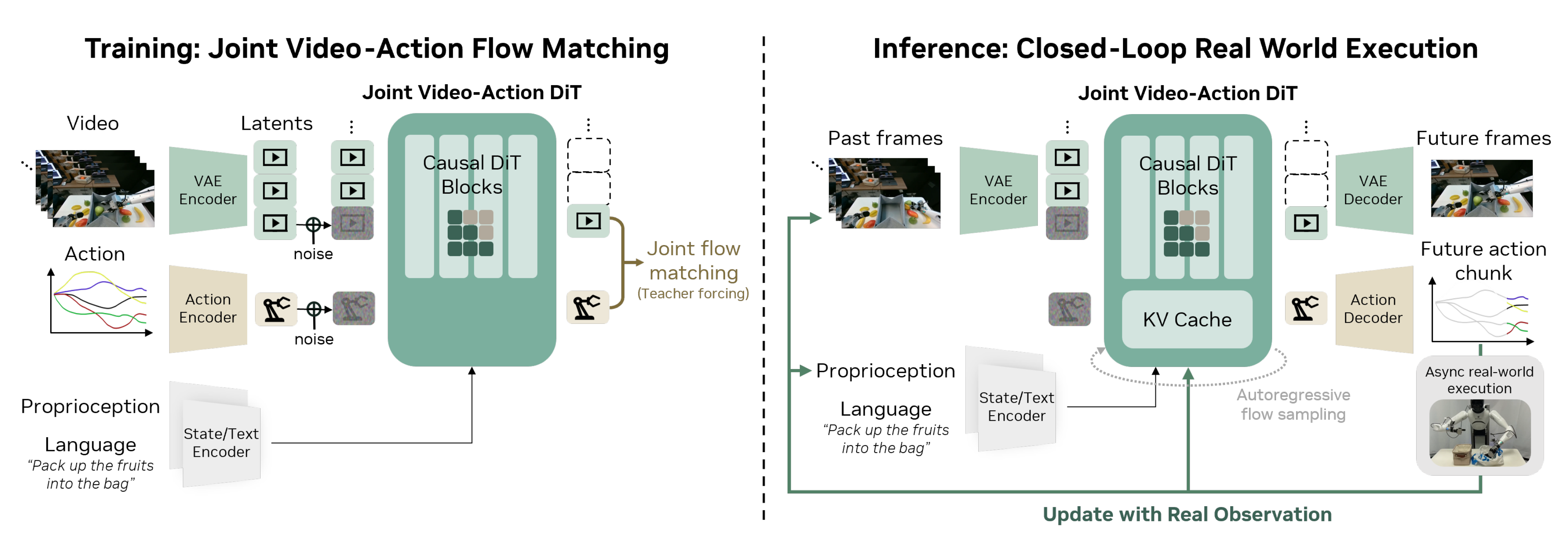
说白了,在推理时,它虽然预言了未来画面,但如果机器人动了之后发现实际画面和预言不一样,它会用真实的观测画面替换掉脑子里的预言画面(更新 KV Cache),从而防止越想越偏(Hallucination accumulation) - 第三,在系统层面、实现层面和模型层面引入了一系列优化,实现了 38× 的推理加速,从而在 7 Hz 下实现实时控制
1.2.1 模型架构(训练目标:视觉预测与动作预测均用的扩散去噪模式)
首先,对于问题表述
DreamZero 在给定语言指令、本体感觉状态
,以及包含当前和过去历史
的视觉观测的条件下,联合预测视频
和动作
,其中H > 0 是一个固定的预测视界,l 是从轨迹中采样的一个随机索引
为了方便大家更好的理解,我补充一下
- 你可以把它想象成,模型在接收到:过去-当前的画面、和人类语言指令后,它的大脑里在同步发生两件事:
一边构思“未来世界画面会怎么演变”——这是视频生成模型的发挥逻辑
另一边同步输出“为了达到这个画面,我的手(关节)应该怎么动”——这是逆动力学模型(IDM)发挥的逻辑
——————
对于这个同时生成,可能有同学有疑问:“既然视频和动作联合各自生成,那还有世界动作模型的优势么
因为世界动作模型先生成的视频,不就是为了给后预测生成的动作,提供视觉监督指导么”
对此,可以想象有两个学生(视频和动作)坐在同一张桌子上考试(同一个网络,同一次前向传播计算)
由于“注意力掩码”的设定,考官允许“动作同学”在写自己卷子的时候,随时随地偷瞄“视频同学”正在写的解题步骤
但最终,考场里的时间是同步流逝的,他们俩是同时停笔、同时交卷的『网络在一个步骤内同时输出两者的去噪速度和
』
- 而视频的 Ground Truth就是机器人在真实执行任务时,摄像头拍下来的、接下来真实发生的视频片段
至于动作的Ground Truth,则是人类的示教
——
相当于在人类摇操机器人(采数据)的过程中,系统是双管齐下在做记录的:
总之,这就好比驾校教练教你开车,他不仅让你看前方的路况(Video),同时他还把手放在方向盘上带着你转(Action),你感受到他转动的真实幅度和力度,那就是动作的 Ground Truth
注意,视频和动作的联合预测可以分解为:1) 自回归视频预测,以及2)来自逆动力学模型(IDM)的动作预测:
不同于使用两个独立模型(视频预测模型和逆动力学模型)来建模分解后的目标(Li etal., 2026; Pai et al., 2025),作者采用联合预测目标,以端到端的方式训练一个单一模型
作者认为,这种端到端设计通过对这两种模态的深度融合,实现了更好的视频-动作对齐
- 由于预训练视频模型已经在多样化的网络级规模视频数据上针对视频预测目标进行了优化,DreamZero 只需要在此基础上额外学习:为机器人具身视频进行视频预测,并从生成的视频中提取相应的动作
- 作者进一步假设,相比于从 VLM 训练 VLA 的传统做法,这种方法更有利于获得更好的泛化能力,因为作者的方法显式地从既作为条件输入又作为预测目标的视频帧中学习时间动态
其次,对于模型架构
DreamZero 的模型架构如下图4所示,该模型接收三类输入:视觉上下文(通过 VAE 编码)、语言指令(通过文本编码器),以及本体感受状态(通过状态编码器)
这些输入由使用 flow matching的自回归 DiT 主干网络进行处理,并通过不同的解码器联合预测未来的视频帧和动作
- 在训练阶段(左),对于每个分块,模型在干净的视频上下文条件下,对带噪的视频和动作潜变量进行去噪
- 在推理阶段(右),预测结果在真实世界中以异步方式执行,同时将真实观测反馈回KV 缓存,以防止误差累积
为了保持视频模型的泛化能力,作者仅引入了极少量的额外参数:状态编码器、动作编码器和解码器
对于包含多视角的机器人训练数据,作者将所有视角拼接成单帧输入,而不是对主干模型进行结构上的修改
特别地,DreamZero 通过自回归方式同时预测视频帧和相应动作
自回归生成具有以下优势:
- 可以利用 KV 缓存实现更快的推理速度
- 策略模型能够将历史视觉观测作为下一步生成的指导
- 避免了双向模型中固有的模态对齐难题(视频、动作与语言的对齐)
具体而言,双向扩散模型通常需要处理固定长度的序列,这往往需要对视频进行子采样,从而破坏原生 FPS,可能损害视频与动作的对齐
————
相对地,自回归生成利用 KV 缓存,在一次前向传播中即可支持任意长度的上下文,从而保留原始帧率,并确保视频帧与机器人动作之间的精确对齐
关于这种差异的更详细说明见附录 B
作者仅对视频模态引入自回归建模,以避免由闭环动作预测带来的误差传播。DreamZero 以分块的方式训练来预测视频帧;每个块包含固定数量的潜在帧K,以匹配动作时域。按块生成使得可以在可变长度的视频上进行训练,这类似于LLM 在可变长度的语言tokens 上的训练方式
且作者在附录C 中提供了关于针对不同模态的QKV 注意力掩码策略的更多细节
再其次,对于训练目标
与近期的视频扩散模型和 VLAs 类似,作者采用流匹配flow-matching「Albergo etal.,2023;Lipman et al.,2022;Liu et al.,2022」作为训练目标(Ali et al.,2025;Team Wan,2025;Teng et al.,2025)
- 不同于最近的 WAMs(Kim et al.,2026;Li et al.,2025;Liao et al.,2025;Zhu etal.,2025),DreamZero 在视频模态和动作模态之间共享去噪时间步,从而在训练初期实现更快的收敛
- 此外,作者采用教师强制(teacher forcing)(Gao et al.,2024;Jin et al.,2024)作为训练目标;在以前面干净的片段为条件的情况下,训练模型对当前含噪的片段进行去噪
说白了,即模型预测:未来视觉状态和动作,均用的扩散去噪模式
形式上,给定一个块索引 和去噪时间步长
,作者将原始视频
对应的
- 含噪视频潜在向量表示为
- 含噪归一化动作表示为
进一步
- 同一块内的所有帧共享相同的时间步长
,而不同的块则被分配独立的时间步长
作者的模型对和
进行去噪——就像把一副已经被完全马赛克的图片 从左至右 逐步的把上面的马赛克 一点一点去掉 最终漏出清晰的图片
而被带部分噪声的
其中,
,是出发的起始点
并且和
分别是干净的视频潜在向量和归一化动作,是模型需要逼近的真实目标——相当于ground truth
- 因此,来自先前块的干净上下文可表示为
- 作者训练模型
,使其在两种模态下都能预测关节速度,并采用以下 flow-matching 目标函数:
其中是一个预定义的权重函数,作用于
是文本条件
是第
个片段的本体感受状态
并且速度『ground truth,该真实的速度向量 等于终点向量(干净视频或动作) - 起点向量(噪声)』
如果你对上面这段中最初的含噪公式、以及最后的速度公式
都不太理解咋来的,啥意思,则可以参见下此文《π0——用于通用机器人控制的VLA模型:一套框架控制7种机械臂(基于PaliGemma和流匹配的3B模型)》的此节《1.2.1 整体理解:PaliGemma + 动作专家 + 流匹配(含对速度向量公式的解释)》

且为了实现高效训练,作者进行轨迹级更新并应用注意力掩码(例如, 有关细节见图14),以便当前带噪声的片段能够关注前面片段的干净上下文
且,作者在算法1 中给出了伪代码『我相信,下图中的大部分伪代码 都可以通过上文内容理解,至于第11-13行所代表的DreamZero-Flash,下一节很快会介绍』

为了方便大家更好的理解,我还是不厌其烦的给大家逐行解读下 上面的27行伪代码
🚗 一、准备阶段 (Setup)
Algorithm 1 DreamZero Training (Flow Matching) 1: Input: Dataset D, Text condition c 2: Hyperparams: Number of chunks M 3: Model: u_θ (Joint Video-Action DiT)
- 输入:一堆人类遥操作的数据集
,以及对应的文本指令
(比如“擦桌子”)。
- 超参数:把一整段长视频切分成
个小块(Chunks)
- 模型:
,也就是那个大脑(联合视频-动作的 DiT 模型)
🎬 二、抽题与数据预处理
4: while not converged do 5: Sample trajectory τ ~ D只要模型还没练到满级,就不断从题库(数据集)里随机抽一段完整的操作录像(轨迹
)出来做练习
6: Encode video to clean latents z_1^{1:M}, normalize actions a_1^{1:M} 7: Split τ into M chunks
- 划重点:把Ground Truth 提取出来
把真实视频画面压缩成干净的潜变量
把真实的关节动作指令做归一化变成
————
类比- 然后把这段长任务切成
🧠 三、核心:按块学习与“教师强制” (Teacher Forcing)
8: for k = 1,...,M do ▷ Chunk-wise Training即开始逐块(Chunk)做题
9: Define clean context C_k ← {(z_1^j, a_1^j)}_{j=1}^{k-1} ▷ TF History
- 大白话:教师强制(Teacher Forcing)机制
当模型在做第到
块的标准答案(干净的视频和动作)直接摊在桌上给它看作为历史参考
,即
- 这就像是驾校教练手把手教你开车,这时说:“前面三步我完美示范过了,现在你看好当前的状态,告诉我第 4 步会发生什么画面?手该怎么动?”
🎲 四、制造考题:加噪 (Adding Noise)
10: Sample timestep t_k ~ U(0,1) 11: // Optional: DreamZero-Flash Decoupling 12: if Flash Mode then 13: t_vid ~ Beta(7,1), t_act ~ U(0,1) 14: else 15: t_vid ← t_k, t_act ← t_k 16: end if
- 模型做题的本质是“去噪”。这里要随机决定当前这道题的“模糊程度”(时间步
- 注:这里还提到了 Flash Mode
普通模式下,视频和动作的模糊程度是一样的;
Flash 模式下,视频故意搞得更模糊一点,这是为了让模型学会在视觉看不清的情况下依然能输出清晰的动作(为了以后的推理提速)17: Sample noise z_0^k, a_0^k ~ N(0, I) 18: Interpolate (Eq. 2): 19: z_t^k ← t_vid*z_1^k + (1-t_vid)*z_0^k 20: a_t^k ← t_act*a_1^k + (1-t_act)*a_0^k
- 教练拿纯净的 Ground Truth 答案(
,
),混入随机的瞎蒙的白噪声(
,
)
也类似于- 混合比例就是刚才决定的
,
)
✍️ 五、模型作答与教练打分 (Flow Matching & Update)
21: Predict velocity: 22: v_pred ← u_θ([z_t^k, a_t^k]; C_k, c, q_k, t_k)
- 模型看着带噪音的当前画面、看着刚才教练给的完美历史(
)
- 然后在脑子里憋出一个预测值:速度(Velocity,
)
这个“速度”指的是从噪音状态指向干净状态的去噪方向23: Target vel. v^k := [z_1^k, a_1^k] - [z_0^k, a_0^k]教练手里的标准答案(Target Velocity,
),也就是纯净 Ground Truth 和纯噪声之间的真实差值:
24: Loss L ← ||v_pred - v^k||^2 ▷ Eq. 3 25: Update θ ← θ - η∇L
- 对比模型预测的去噪方向和真实的去噪方向,计算两者的误差(Loss
)
- 教练给出一巴掌(或者一颗糖),通过反向传播(Backpropagation,
)更新模型大脑里的神经元权重
最后,对于模型推理
如图4所示
在推理阶段,DreamZero 联合对视频块和动作块进行去噪,并利用 KV 缓存提高效率(Huang et al., 2025; Teng et al., 2025; Yin et al., 2025)
- 与纯视频生成不同,作者的闭环设置允许在每次执行动作后,将真实观测替换 KV 缓存中的生成帧(见图14)
这消除了自回归视频生成中固有的误差累积问题——这是 WAMs 独有的关键优势 - 此外,作为一种有状态策略,DreamZero 可以利用视觉历史来完成需要记忆的任务。且,作者在算法2中给出了推理的伪代码
1.2.2 DreamZero 的实时执行
基于扩散的 WAMs 从视频基础模型中继承了强大的泛化能力,但其迭代去噪过程与反应式机器人控制之间存在根本性的矛盾
对此,作者讨论两个问题:
- 是什么阻止了 WAMs 成为反应式策略?
- 如何为实时控制解决这一问题?
第一,对于响应性缺口
反应式策略必须在几十毫秒内对环境变化作出响应。在单个 GPU 上对 DreamZero 进行朴素实现时,每个动作块大约需要 5.7 秒,原因在于三个瓶颈:
- 为获得平滑动作而进行的 16 步扩散迭代去噪
- 拥有 140 亿参数的 DiT 主干网络所带来的计算开销
- 顺序执行在推理期间会阻塞机器人运动
这种延迟使得闭环控制在实践中不可行
第二,对于异步闭环执行
作者解决这一问题的第一步,是通过一种将推理与动作执行解耦的异步执行机制。与其在每次推理完成前阻塞等待,不如让运动控制器在推理并行地基于最新观测运行时,持续执行“最新的动作块”
这种结构将延迟约束从“推理必须在机器人开始移动前完成”转变为“推理必须在当前动作块执行完之前完成”
在作者的实验中,对于双臂操作机器人,作者以 30Hz 的控制频率,在动作视野(action horizon)为 48 步的设置下部署策略(每个动作块对应 1.6 秒)
因此,作者将推理延迟目标控制在约 200ms 以下,以确保有足够的重叠时间,实现平滑且具有反应性的控制
第三,对于系统级优化
鉴于异步执行结构,作者通过并行化和缓存来优化推理吞吐量
- CFG 并行
Classifier-free guidance(Ho 和 Salimans, 2022)需要两次前向传播(条件和无条件)
作者将这两次前向传播分布到两块 GPU 上,将每步延迟降低了 47% - DiT 缓存
作者利用在 flow matching 过程中速度预测方向的一致性。当相邻速度之间的余弦相似度超过某个阈值时,复用缓存的速度,将有效的 DiT 步数从 16 减少到 4,同时对动作预测质量几乎没有损失
第四,对于实现层面的优化
作者通过对编译器和内核的改进进一步降低延迟
- Torch Compile 和 CUDA 图
作者应用 torch.compile 结合 CUDA Graphs,以消除 CPU 开销并融合算子。静态形状仅会在第一条轨迹期间触发重新编译 - 训练后量化
在 Blackwell 架构上,作者将权重和激活量化为 NVFP4,同时将敏感算子(QKV、Softmax)保持为 FP8,将非线性算子保持为 FP16 - 内核和调度器增强
作者在注意力机制中使用 cuDNN 后端,并将调度器相关操作迁移到 GPU,以消除CPU-GPU 同步停顿
第五,模型级优化:DreamZero-Flash
即使经过系统级优化,扩散步数仍然是延迟的主要瓶颈,然而,直接粗暴地减少步数会降低动作质量,因为残余的视觉噪声会传播到动作预测中
好在DREAMZERO-Flash 通过在训练过程中将视频和动作的噪声调度解耦来解决这一问题
啥意思呢
- 在推理阶段,动作应当在当前片段中仍然以带噪视频表征为条件进行去噪直至其最终取值,因为在非常少的去噪步数下(例如少于4 步),生成的视频token 可能仍然不准确,从而只提供带噪的条件信号
- 但标准的DREAMZERO 为两种模态采样一个共享的时间步
便会造成训练与测试的不匹配:在训练时,模型学习在视频和动作处于相同噪声水平时预测动作,但在少步或单步推理时,则需要在视频仍然部分带噪的情况下预测干净的动作
————
说白了,视频和动作可能处于各自去噪路径的不同位置(比如视频已经去噪到一半,动作才刚开始)
故最好是允许视频和动作使用不同的时间步()
- DREAMZERO-Flash 通过将视频时间步偏向高噪声状态来弥合这一差距,其方式为
,其中
且
在实践中,作者采用Beta (7, 1) 作为示例配置
————
如上面算法1中所述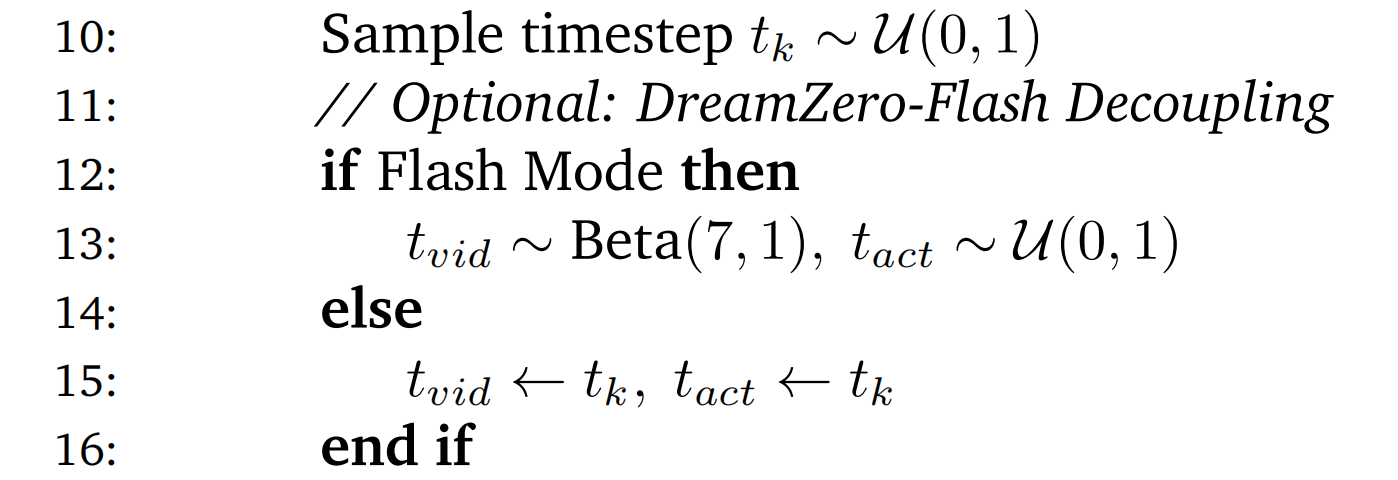
从而得到
————(以高噪声为主),而动作时间步保持均匀分布(图5)
在训练过程中,这使模型暴露于一种配置:它必须在噪声较大的视觉上下文中预测干净的动作,从而直接匹配少步或单步推理范式
由此,作者将扩散步数从4 步减至1 步,把推理时间从∼350 ms 降低到∼150 ms ,且性能损失极小(表3)
此外,Flash 表述还支持灵活的训练配置,例如调整视频与动作的噪声采样比例,以更好地使训练与不同的少步或单步推理范式对齐
在实践中,作者主要将Flash 训练作为主DREAMZERO 模型训练之后的最后阶段
动作块平滑。为抑制生成动作中的高频噪声,作者将这些块上采样到 2× 分辨率,应用 Savitzky-Golay 滤波器,然后再下采样回原始分辨率
最后小结一下
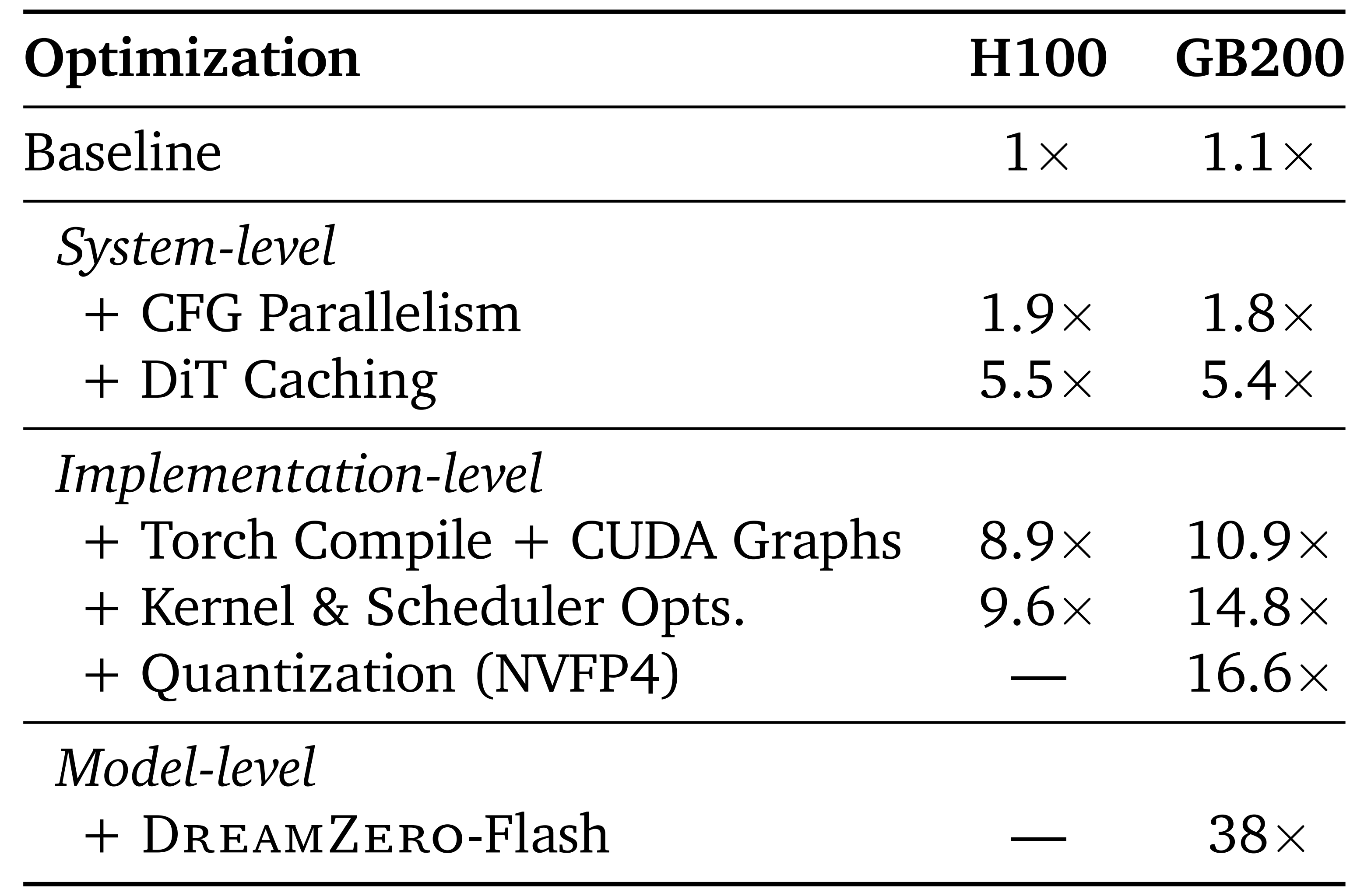
表1 总结了累积加速比
- 系统和实现优化在H100 上带来∼9× 的加速,在GB200 上带来∼16× 的加速;
而加入DREAMZERO-Flash 在GB200 上实现了38 × 的加速,将时延从5.7s 降低到150ms- 除 DiT 缓存和量化以外,所有系统级和实现级优化在数学上都与基线等价,且未显示出可测量的性能下降
1.3 实验设置
// 待更

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 18
18 0
0- 0



 已为社区贡献76条内容
已为社区贡献76条内容

所有评论(0)