万字超详细LangChain4j文档详解
LangChain4j 是一个专为 Java 开发者设计的开源框架,旨在简化大语言模型(LLM)在Java应用中的集成。它的目标类似于Python生态中的LangChain,但针对Java生态进行了优化,提供统一的API抽象、上下文管理(Memory)、提示模板、文档检索(RAG)等功能核心定位:让Java开发者无需学习不同LLM提供商的专有API,快速构建智能应用(如聊天机器人、智能助手)。开发
LangChain4j文档详解
本篇笔记是对 LangChain4j 官方文档的自用详细解读
以下给出中文版的官方文档网站:https://docs.langchain4j.info/
一、介绍
LangChain4j 是一个专为 Java 开发者设计的开源框架,旨在简化大语言模型(LLM)在Java应用中的集成。它的目标类似于Python生态中的LangChain,但针对Java生态进行了优化,提供统一的API抽象、上下文管理(Memory)、提示模板、文档检索(RAG)等功能
-
核心定位:让Java开发者无需学习不同LLM提供商的专有API,快速构建智能应用(如聊天机器人、智能助手)。
LLM 提供商(如 OpenAI 或 Google Vertex AI)和嵌入(向量)存储(如 Pinecone 或 Milvus) 使用专有 API。LangChain4j 提供统一的 API,避免了学习和实现每个特定 API 的需求。
-
开发背景:因Python生态的LangChain占据主流,而Java生态缺乏类似工具,LangChain4j于2023年诞生以填补这一空白。
简单来说:LangChain4j 就是类似适配 Java 的 LangChain
二、快速上手
1、依赖区分
1.1、langchain4j-open-ai
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
<version>1.0.0-beta3</version>
</dependency>
- 提供的能力:
- OpenAI模型集成(如GPT-3.5/4)
- 聊天补全(Chat Completion)
- 嵌入生成(Embeddings)
- 函数调用(Function Calling)
- 不包含的功能:
- 本地向量存储(需额外添加
langchain4j或langchain4j-redis) - 文档加载/分割(需配合
langchain4j核心库依赖)
- 本地向量存储(需额外添加
1.2、langchain4j
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>1.0.0-beta3</version>
</dependency>
- 包含的功能:核心框架,包含:
- 基本抽象(ChatModel, EmbeddingModel, Tool等)
- 链式调用(Chain)
- 内存管理(Memory)
- 文档加载器、解析器、分割器
- 向量存储接口
- 不包含的功能:
-
- OpenAI模型(需配合
langchain4j-open-ai依赖) - 本地向量存储(需配合
langchain4j-qdrant/langchain4j-redis等其他嵌入模型依赖) - 本地模型运行(需配合
langchain4j-ollama/langchain4j-local-ai依赖) - 评估监控(需配合
langchain4j-evaluation依赖)
- OpenAI模型(需配合
1.3、langchain4j-spring-boot-starter
该依赖是Spring 通用集成
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-spring-boot-starter</artifactId>
<version>1.0.0-beta3</version>
</dependency>
- 包含的功能:为 Spring Boot 提供:
-
- 自动扫描和注册
AiService
- 自动扫描和注册
-
- 统一的配置属性前缀(
langchain4j.*)
- 统一的配置属性前缀(
-
- 与 Spring 依赖注入集成
1.4、langchain4j-{integration-name}-spring-boot-starter
要使用Spring Boot 的专用启动器之一,需导入该依赖
以下以 OpenAI 为例(该配置专用于OpenAI集成):
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai-spring-boot-starter</artifactId>
<version>1.0.0-beta3</version>
</dependency>
这是 组合依赖,内部已经包含了:
langchain4jlangchain4j-open-ailangchain4j-spring-boot-starter
并提供额外的:
OpenAiChatModel的自动配置langchain4j.open-ai.*配置属性
1.5、langchain4j-bom(物料清单)
该依赖主要是为了进行依赖管理配置,用于统一管理 LangChain4j 生态中各个模块的版本
①、BOM 的核心作用
- 版本统一:确保所有 LangChain4j 相关依赖(
langchain4j-core、langchain4j-open-ai等)自动继承1.0.0-beta3版本 - 避免冲突:解决多模块项目中可能出现的版本不一致问题
- 简化配置:子模块中无需重复指定版本号
②、举例
<!-- 父 POM 或主 POM 指定LangChain4j 生态中各个模块的版本,确保版本统一 -->
<dependencyManagement>
<dependencies>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-bom</artifactId>
<version>1.0.0-beta3</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<!-- 子模块中无需指定版本 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-qdrant</artifactId>
</dependency>
<!-- 若某个子模块中需特定版本 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-ollama</artifactId>
<version>0.25.0</version> <!-- 显式覆盖BOM版本即可 -->
</dependency>
</dependencies>
1.6、官方文档易误解之处
易被误解为:
langchain4j-open-ai 是比 langchain4j更基础的版本,langchain4j 是 langchain4j-open-ai的高级使用
正确理解为:
langchain4j-open-ai 内置 langchain4j-core核心库
需要使用高级功能的情况可能为:
- 手动管理依赖版本
- 使用核心库中的特殊API
- 混合多个LLM提供商时避免冲突
详细关系对比以及依赖的内置关系可见下方对比
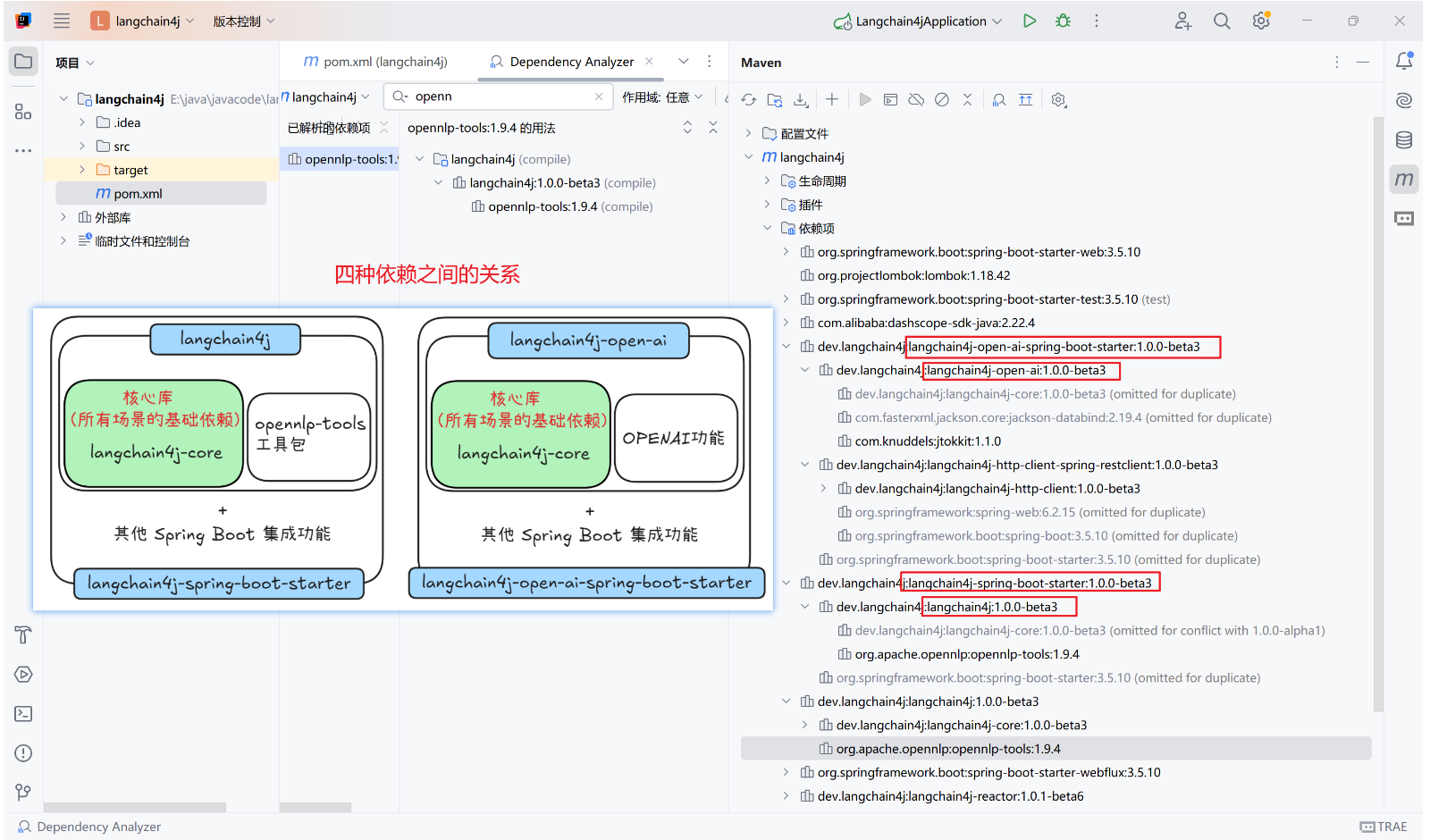
1.7、前四种依赖关系对比
| 依赖 | 类型 | 核心功能 | 典型使用场景 |
|---|---|---|---|
langchain4j |
核心库 | 框架基础 API、内存存储、工具调用等通用功能 | 所有场景的基础依赖 |
langchain4j-open-ai |
模型集成 | OpenAI API 的具体实现(ChatGPT、GPT-4、Embeddings 等) | 需要对接 OpenAI 服务 |
langchain4j-spring-boot-starter |
Spring Boot 集成 | 自动配置 LangChain4j 核心组件到 Spring 容器 | 使用 Spring Boot 框架时 |
langchain4j-open-ai-spring-boot-starter |
专用 Starter | 专门自动配置 OpenAI 相关的 Bean 和属性 | Spring Boot + OpenAI 的组合场景 |
下图包含依赖之间的内置关系:
以下是非 Spring Boot 项目(非 Spring 的传统 Java 应用(如桌面应用、命令行工具),即不使用 Spring Boot、Spring MVC 等 Spring 生态组件)和 Spring Boot 项目的区别:
| 特性 | langchain4j-open-ai (基础集成) |
langchain4j-open-ai-spring-boot-starter |
|---|---|---|
| 自动配置 | ❌ 手动配置所有参数 | ✅ 通过application.yml自动配置 |
| Bean管理 | ❌ 手动创建实例 | ✅ 自动创建Spring Bean |
| 属性绑定 | ❌ 硬编码或自定义读取 | ✅ 支持@ConfigurationProperties |
| 依赖注入 | ❌ 需要自己管理 | ✅ 自动注入 |
| 配置复杂度 | 高,需要编码配置 | 低,声明式配置 |
1.8、分场景使用
①、非Spring项目
- langchain4j
- langchain4j-open-ai
- 之后手动创建和配置组件
②、Spring Boot + OpenAI
- langchain4j-open-ai-spring-boot-starter
- 之后在配置文件中配置好apikey、模型名称等配置
③、Spring Boot + 多模型
-
langchain4j-spring-boot-starter
-
langchain4j-{integration-name}-spring-boot-starter(具体模型模块)
按需添加:
langchain4j-open-ai(OpenAI)langchain4j-ollama(本地 Ollama 模型)langchain4j-huggingface(HuggingFace 模型)- 其他厂商适配模块(如未来的
langchain4j-deepseek)
-
之后在配置文件中配置好apikey、模型名称等配置
2、入门案例
以下以阿里云百炼为例
2.1、创建API 密钥
配置进系统的环境变量,预防泄露,警惕明文显示
- 在Windows系统桌面中按
Win+Q键,在搜索框中搜索编辑系统环境变量,单击打开系统属性界面。- 在系统属性窗口,单击环境变量,然后在系统变量区域下单击新建,变量名填入
DASHSCOPE_API_KEY,变量值填入您的DashScope API Key。
如果没有自己的 OpenAI API 密钥,可以临时使用 LangChain4j 官方免费提供的 demo 密钥,用于演示目的。 注意,当使用 demo 密钥时,所有对 OpenAI API 的请求都需要通过我们的代理, 该代理会在转发请求到 OpenAI API 之前注入真实的密钥。 demo 密钥有配额限制,仅限于使用 gpt-4o-mini 模型,并且应该仅用于演示目的。
OpenAiChatModel model = OpenAiChatModel.builder()
.baseUrl("http://langchain4j.dev/demo/openai/v1")
.apiKey("demo")
.modelName("gpt-4o-mini")
.build();
2.2、引入依赖坐标
①、DashScope Java SDK 依赖
此处选择了阿里云百炼的 SDK 工具库,当然也可选择其他厂商,如: OpenAI 的 SDK
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>dashscope-sdk-java</artifactId>
<version>the-latest-version</version>
</dependency>
the-latest-version 替换为最新的合适版本号
②、LangChain4j 依赖
| 特性 | langchain4j-open-ai |
langchain4j-open-ai-spring-boot-starter |
langchain4j-spring-boot-starter |
|---|---|---|---|
| Spring Boot 支持 | ❌ 需手动配置 | ✅ 自动配置 | ✅ 自动配置(仅核心功能) |
| OpenAI 集成 | ✅ 核心 API 封装 | ✅ 封装 + 自动配置 | ❌ 需额外引入 langchain4j-open-ai |
| 配置方式 | 代码硬编码 | application.yml 或 Properties 文件 |
需手动添加模型提供商配置 |
| 依赖范围 | 单一 OpenAI 功能 | OpenAI + Spring Boot 自动化 | LangChain4j 核心 + Spring Boot 自动化 |
2.3、创建实例进行chat测试
①、非Spring Boot项目
以OpenAI 基础集成为例:
Ⅰ、自己手动创建一个 OpenAiChatModel 实例
OpenAiChatModel model = OpenAiChatModel.builder()
.apiKey(apiKey)
.modelName("gpt-4o-mini")
.build();
Ⅱ、测试聊天
String answer = model.chat("Say 'Hello World'");
System.out.println(answer); // Hello World
②、Spring Boot项目
Ⅰ、完善配置文件
可以在 application.properties 文件(也可改为 yaml 文件)中配置模型参数,如下所示:
langchain4j.open-ai.chat-model.api-key=${DASHSCOPE_API_KEY} # 从环境变量中获取 APIKEY
langchain4j.open-ai.chat-model.model-name=gpt-4o # 配置模型名称
langchain4j.open-ai.chat-model.log-requests=true # 开启请求日志
langchain4j.open-ai.chat-model.log-responses=true # 开启响应日志
...
# 以上是properties,以下是 yaml
langchain4j:
open-ai:
chat-model:
api-key: ${DASHSCOPE_API_KEY} # 从环境变量中获取 API 密钥
model-name: qwen-plus # 模型名称,即模型 Code
# 模型 API 基础 URL(从官方文档中获取)
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1
log-responses: true # 是否记录响应日志
log-requests: true # 是否记录请求日志
Ⅱ、测试聊天
在确保正确引入了 langchain4j-spring-boot-starter 依赖的情况下,将自动创建 OpenAiChatModel(ChatLanguageModel 的实现)的实例, 我们可以在需要的地方自动装配它
(即已经自动创建和管理 OpenAiChatModel 到 AOC 容器中了,不需要显式使用 @Autowired 来注入它):
@RestController
public class ChatController {
ChatLanguageModel chatLanguageModel;
public ChatController(ChatLanguageModel chatLanguageModel) {
this.chatLanguageModel = chatLanguageModel;
}
@GetMapping("/chat")
public String model(@RequestParam(value = "message", defaultValue = "Hello") String message) {
return chatLanguageModel.chat(message);
}
}
三、教程
0、补充:了解大模型
0.1、大模型部署
个人的大模型部署可主要分为:
- 本地部署(如:Ollama进行本地部署)
- 云服务器部署(借用类似阿里云百炼、硅基流动等云服务器厂商将大模型部署)
①、本地部署
以 Ollama(官网:https://ollama.com/) 为例:
-
选择 Windows/Mac/Linux 合适版本的 Ollama 进行下载
-
选择想要部署的大模型(该大模型又根据所需要资源对应不同的大小版本)
-
运行命令:ollama run < 要运行的版本>,如:ollama run qwen3-vl:2b
(如果未拉取过该大小版本的模型则进行首次拉取下载,若下载过则直接启动) -
进行对话**(以 curl 方式为例 )**
curl http://localhost:11434/api/chat -d '{ "model": "qwen3-vl:2b", "messages": [{ "role": "user", "content": "你是谁" }], "stream": false }'
具体可见官方文档:https://docs.ollama.com/
②、云服务器部署
以阿里云百炼为例:
-
开通阿里云百炼
-
获取 APIKEY(建议配置到环境变量中以防泄露)
-
选择大模型进行对话**(以 curl 方式为例 )**
不同地域的 Base URL 不通用(以下示例是北京地域 Base URL)
华北2(北京):
https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completionscurl -X POST https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions \ -H "Authorization: Bearer $DASHSCOPE_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "qwen-plus", "messages": [ { "role": "user", "content": "你是谁?" } ] }'
具体可见官方文档:https://bailian.console.aliyun.com/cn-beijing/?spm=5176.29597918.J_SEsSjsNv72yRuRFS2VknO.2.60e37b08A98n84&tab=doc#/doc
0.2、大模型调用
①、通用请求参数(Request Parameters)
Ⅰ、基础参数
| 参数名 | 类型 | 必填 | 说明 | 示例值 |
|---|---|---|---|---|
model |
string | ✅ | 指定调用的模型名称 | qwen-max (通义千问) |
messages |
array | ✅ | 对话历史(多轮对话上下文) | [{role: "user", content: "你好"}] |
temperature |
float | ❌ | 生成多样性(0-2,越高越随机) | 0.8 |
max_tokens |
integer | ❌ | 生成的最大token数 | 1024 |
stream |
boolean | ❌ | 是否启用流式响应 | true |
enable_search |
boolean | ❌ | 是否启用联网搜索或知识库检索功能 | true |
messages 中的 role:
| 角色 (role) | 适用平台 | 说明 | 典型使用场景 |
|---|---|---|---|
user |
OpenAI, 阿里云, 百度文心等 | 表示用户输入的问题或指令 | 用户提问:"明天北京天气怎么样?" |
assistant |
OpenAI, 阿里云, 百度文心等 | 表示AI助手的回复内容 | AI回答:"北京明天晴,25-32℃。" |
system |
OpenAI, Claude等 | 系统级指令,用于设定AI行为(通常只在对话开头出现一次) | 设定身份:"你是一个专业的医疗助手" |
function |
OpenAI (Function Calling) | 标识函数调用的请求或结果 | 工具调用:{"name": "get_weather"} |
tool |
OpenAI (Tool Calls) | 新版工具调用角色(替代部分function场景) |
工具响应:{"tool_call_id": "123"} |
Ⅱ、高级参数
| 参数名 | 类型 | 适用模型 | 说明 |
|---|---|---|---|
top_p |
float | 通用 | 核采样概率(0-1,与temperature二选一) |
stop |
array | 通用 | 停止词(遇到这些词停止生成) |
frequency_penalty |
float | OpenAI | 频率惩罚(-2.0~2.0,降低重复内容) |
presence_penalty |
float | OpenAI | 存在惩罚(-2.0~2.0,避免重复话题) |
seed |
integer | 部分模型 | 随机种子(用于结果复现) |
Ⅲ、示例
curl http://localhost:11434/api/chat -d '{
"model": "qwen3-vl:2b",
"messages": [{
"role": "user",
"content": "你是谁"
}],
"stream": true
}'
- 使用的模型:qwen3-vl:2b
- 用户(user)发送的内容为:你是谁
- 是否启用流式响应:是——> 即每生成一部分就直接响应回复,而不是等所有内容生产完一次性响应回复
基础大模型没有记忆性,即本次回复需携带上一次问答内容才可协调回复,如:第一次用户单独询问清华大学是211吗,第一次大模型回复是,第二次用户单独询问是985吗,由于未携带第一次的问答大模型第二次回复是提示给出更详细的大学信息
curl -X POST https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions \
-H "Authorization: Bearer $DASHSCOPE_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "qwen-plus",
"messages": [
{
"role": "user",
"content": "清华大学是211吗?"
},{
"role": "assistant",
"content": "是。。。。。"
},{
"role": "user",
"content": "是985吗?"
}
]
}'
②、通用响应参数(Response Parameters)
Ⅰ、关键参数
| 参数 | 说明 | 示例值 |
|---|---|---|
| id | 唯一请求标识符 | chatcmpl-xxx |
| object | 对象类型 | chat.completion / chat.completion.chunk |
| created | 创建时间戳(Unix时间) | 1718901234 |
| model | 使用的模型版本 | gpt-4o-2024-05-13 |
| choices | 生成结果数组(通常1个) | 包含消息内容的数组 |
| usage | Token使用量统计 | prompt/completion/total_tokens |
| system_fingerprint | 系统指纹(追踪模型配置) | fp_xxx |
Token 是大模型处理文本的最小单位
choices数组内部结构
| 参数 | 说明 |
|---|---|
| index | 选择项索引(0-based) |
| message/delta | 非流式用message,流式用delta |
| finish_reason | 停止原因:stop/length/content_filter/tool_calls |
| logprobs | 词元概率信息(可选) |
Ⅱ、示例
{
"id": "chatcmpl-9vTCSx3x8K4vR2nQpL5mZ7yA1B2C3D4E",
"object": "chat.completion",
"created": 1718901234,
"model": "gpt-4o-2024-05-13",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "这是一个典型的AI助手回复示例。我可以回答问题、撰写内容、分析数据、编写代码等。",
"refusal": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 15,
"completion_tokens": 32,
"total_tokens": 47
},
"system_fingerprint": "fp_abc123def456"
}
Ⅲ、参数配置
-
使用builder 构造器进行构造
OpenAiChatModel model = OpenAiChatModel.builder() .apiKey(System.getenv("OPENAI_API_KEY")) .modelName("gpt-4o-mini") .temperature(0.3) .timeout(ofSeconds(60)) .logRequests(true) .logResponses(true) .build(); -
在配置文件(properties/yaml)中进行配置
langchain4j.open-ai.chat-model.api-key=${DASHSCOPE_API_KEY} # 从环境变量中获取 APIKEY langchain4j.open-ai.chat-model.model-name=gpt-4o # 配置模型名称 langchain4j.open-ai.chat-model.log-requests=true # 开启请求日志 langchain4j.open-ai.chat-model.log-responses=true # 开启响应日志 ... # 以上是properties,以下是 yaml langchain4j: open-ai: chat-model: api-key: ${DASHSCOPE_API_KEY} # 从环境变量中获取 API 密钥 model-name: qwen-plus # 模型名称,即模型 Code base-url: https://dashscope.aliyuncs.com/compatible-mode/v1 # 模型 API 基础 URL log-responses: true # 是否记录响应日志 log-requests: true # 是否记录请求日志
1、低级 API
低级 API 需要我们**手动构建对话,**直接操作模型,完全可控,但代码冗长
// 1. 创建模型(以OpenAI为例) ChatModel model = OpenAiChatModel.builder() .apiKey("demo") .build(); // 2. 手动构建消息历史以实现多轮对话 List<ChatMessage> messages = new ArrayList<>(); messages.add(SystemMessage.from("你是一个友好的助手。")); messages.add(UserMessage.from("你好,我叫小明。")); messages.add(AiMessage.from("你好小明!有什么可以帮你的?")); messages.add(UserMessage.from("我刚才说我叫什么?")); // 3. 调用并获取响应 Response<AiMessage> response = model.generate(messages); System.out.println(response.content().text()); // 输出: 小明
以下是LangChain4j 支持的常见模型类型:
| API 类/接口 | 用途 |
|---|---|
LanguageModel |
最基本的文本生成接口(如 generate(String prompt))。 |
ChatLanguageModel |
支持对话式交互(如 generate(List<ChatMessage> messages))。 |
EmbeddingModel |
文本嵌入(生成向量表示,如 embed(String text))。 |
ModerationModel |
内容审核(如检查是否违规)。 |
ImageModel |
图像生成(如 DALL-E)。 |
ScoringModel |
对查询的多个文本片段进行评分(或排名)。 |
StreamingChatLanguageModel |
处理流式响应(逐块返回结果)。 |
1.1、LanguageModel
该 API 非常简单 - 接受 String 作为输入并返回 String 作为输出。
public interface LanguageModel {
Response<String> generate(String var1);
default Response<String> generate(Prompt prompt) {
return this.generate(prompt.text());
}
}
LangChain4j 不会再扩展对 LanguageModel 的支持,该 API 正在被 ChatLanguageModel 取代
1.2、ChatLanguageModel
①、String 作为请求
public interface ChatLanguageModel {
default String chat(String userMessage) {
ChatRequest chatRequest = ChatRequest.builder().messages(new ChatMessage[]{UserMessage.from(userMessage)}).build();
ChatResponse chatResponse = this.chat(chatRequest);
return chatResponse.aiMessage().text();
}
}
可见该简单的 chat 方法其实类似于 LanguageModel
该方法其本质其实还是 ChatMessage 作为请求,只不过是无需将 String 包装在 UserMessage 中,这是一个进行聊天实验的快捷方式。
②、ChatMessage 作为请求
Ⅰ、单个 ChatMessage
public interface ChatLanguageModel {
default ChatResponse chat(ChatMessage... messages) {
ChatRequest chatRequest = ChatRequest.builder().messages(messages).build();
return this.chat(chatRequest);
}
}
Ⅱ、多个 ChatMessage
public interface ChatLanguageModel {
default ChatResponse chat(List<ChatMessage> messages) {
ChatRequest chatRequest = ChatRequest.builder().messages(messages).build();
return this.chat(chatRequest);
}
}
为什么需要多个 ChatMessage:
LLM 本质上是无状态的,意味着它们不维护对话的状态(不具有记忆功能)。 因此,如果想支持多轮对话,我们应该负责管理对话的状态。即每次进行对话都要携带上一次的交互信息,LLM 才可以接着上次对话进行继续交互,而如何携带之前的交互信息,就是通过多个 ChatMessage 进行携带。
Ⅲ、ChatMessage 的类型
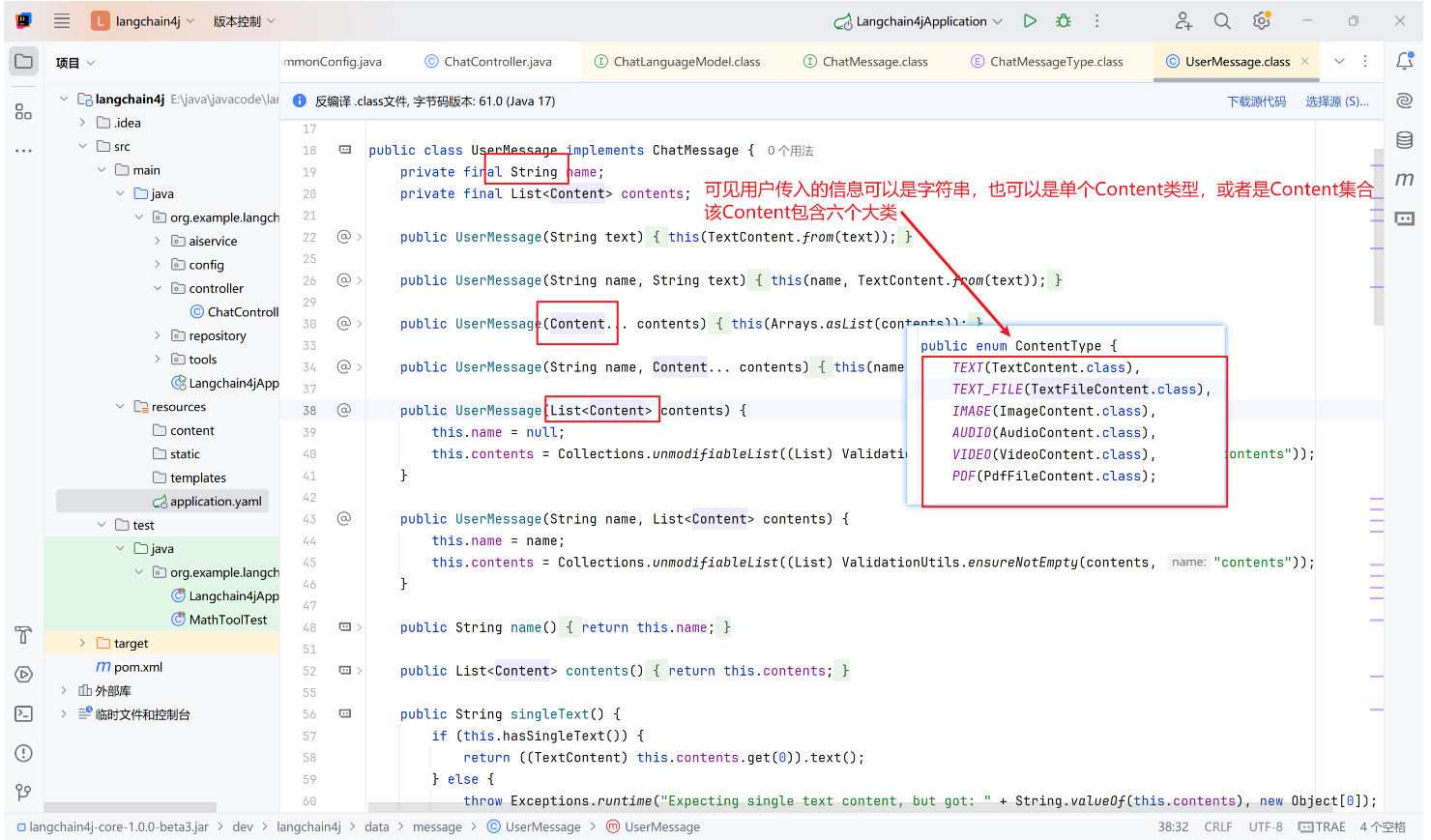
根据官方文档以及源码中枚举类 ChatMessageType 可知,目前有主流的四种类型聊天信息+Ollama的CustomMessage,每种对应消息的一个"来源":
-
UserMessage:来自用户的消息。 用户可以是应用程序的最终用户(人类)或应用程序本身。
其传入的参数类型: -
-
String 字符串类型
-
单个Content 类型
-
Content 集合(多模态内容)
每个Content 可以是: -
TextContentImageContentAudioContentVideoContentPdfFileContent
-
-
AiMessage:AI 生成的消息,通常是对
UserMessage的回应。 -
ToolExecutionResultMessage:工具调用的结果,
ToolExecutionRequest的结果 -
SystemMessage:来自系统的消息,作为开发人员应该定义此消息的内容。 通常,您会在这里写入关于 LLM 角色是什么、它应该如何行为、以什么风格回答等指令。LLM 被训练为比其他类型的消息更加关注
SystemMessage, 所以最好不要让最终用户自由定义或在SystemMessage中注入一些输入。 通常,它位于对话的开始。 -
CustomMessage:这是一个可以包含任意属性的自定义消息。这种消息类型只能由支持它的
ChatLanguageModel实现使用(目前只有 Ollama)。
| 类型 | 说明 | 使用场景 |
|---|---|---|
UserMessage |
用户消息 | 用户输入的问题、指令 |
AiMessage |
AI 回复消息 | 模型生成的回答 |
SystemMessage |
系统消息 | 设置 AI 角色、行为规则,训练LLM垂直领域的专业性 |
ToolExecutionResultMessage |
工具执行结果 | Tool 调用后的返回结果 |
CustomMessage |
可以包含任意属性的自定义消息 | 目前Ollama独有 |
③、ChatRequest 作为请求(自定义请求)
public interface ChatLanguageModel {
default ChatResponse chat(ChatRequest chatRequest) {
ChatRequest finalChatRequest = ChatRequest.builder().messages(chatRequest.messages()).parameters(this.defaultRequestParameters().overrideWith(chatRequest.parameters())).build();
List<ChatModelListener> listeners = this.listeners();
Map<Object, Object> attributes = new ConcurrentHashMap();
ListenersUtil.onRequest(finalChatRequest, this.provider(), attributes, listeners);
try {
ChatResponse chatResponse = this.doChat(finalChatRequest);
ListenersUtil.onResponse(chatResponse, finalChatRequest, this.provider(), attributes, listeners);
return chatResponse;
} catch (Exception var6) {
Exception error = var6;
ListenersUtil.onError(error, finalChatRequest, this.provider(), attributes, listeners);
throw error;
}
}
default ChatResponse doChat(ChatRequest chatRequest) {
throw new RuntimeException("Not implemented");
}
}
2、AI 服务
AI 服务其思想是将与 LLM 和其他组件交互的复杂性隐藏在简单的 API 后面。
以声明方式定义具有所需 API 的接口, 然后 LangChain4j 提供实现该接口的对象(代理)。 可以将 AI 服务视为应用程序服务层中的组件,它提供 AI 服务。(即带有 AI 服务的 Service 层)
2.1、最简单的 AI 服务
①、例子
首先,我们定义一个带有单个方法 chat 的接口,该方法接受 String 作为输入并返回 String。
interface Assistant {
String chat(String userMessage);
}
然后,我们创建低级组件。这些组件将在我们的 AI 服务底层使用。 在这种情况下,我们只需要 ChatLanguageModel:
ChatLanguageModel model = OpenAiChatModel.builder()
.apiKey(System.getenv("OPENAI_API_KEY"))
.modelName(GPT_4_O_MINI)
.build();
最后,我们可以使用 AiServices 类创建我们的 AI 服务实例:
Assistant assistant = AiServices.create(Assistant.class, model);
在 Quarkus 和 Spring Boot 应用程序中, 自动配置会处理创建 Assistant bean。 这意味着不需要调用 AiServices.create(...),只需在需要的地方注入/自动装配 Assistant 即可。
之后可以使用 Assistant进行对话测试:
String answer = assistant.chat("Hello");
System.out.println(answer); // Hello, how can I help you?
②、底层实现
- 将接口的
Class与低级组件一起提供给AiServices, 然后AiServices创建一个实现该接口的代理对象。 - 这个代理对象处理所有输入和输出的转换(目前官方采用的是反射的方法)
AiService会自动将其转换为UserMessage并调用ChatLanguageModel(接受ChatMessage作为输入)- 由于
chat方法的输出类型是String,在ChatLanguageModel返回AiMessage后, 它将在从chat方法返回之前转换为String。
简单来说就是:
- 提供接口类和低级组件给
AiServiceAiService创建实现该接口的代理对象- 代理对象采用反射方法处理输入和输出的转换
2.2、Spring Boot 中的 AI 服务
| 特性 | Spring Boot | 非 Spring 环境 |
|---|---|---|
| @AiService 支持 | ✅ 自动代理生成 | ✅ 需手动调用 AiServices.create() |
| 依赖管理 | 自动注入 ChatModel、Tools 等 |
手动传递依赖实例 |
| 生态集成 | 无缝结合 Spring 的 DI、AOP 等 | 需自行管理组件生命周期 |
①、Spring Boot 启动器
Spring Boot 启动器通过属性配置帮助创建和配置 语言模型、 嵌入模型、 嵌入存储 和其他 LangChain4j 核心组件。
要使用 Spring Boot 启动器 之一, 请导入相应的依赖项。
即 langchain4j-{integration-name}-spring-boot-starter 依赖
导入完对应启动器的依赖后会自动创建ChatLanguageModel 的实现, 可以在需要的地方自动装配它(即该实现已经交由 Spring 管理)
之后可在配置文件中配置模型的参数:
- 配置普通模型就是chat-model
- 配置流式响应模型就是streaming-chat-model
- 配置嵌入模型就是embedding-model
- 等等
②、声明式 AI 服务
Ⅰ、依赖导入
确保依赖项中含 langchain4j-spring-boot-starter 依赖(不论是直接导入,还是其他依赖内置)
Ⅱ、注解使用
现在可以定义 AI 服务接口并使用 @AiService 注解它:
@AiService
interface Assistant {
@SystemMessage("You are a polite assistant")
String chat(String userMessage);
}
将其视为标准的 Spring Boot @Service,但具有 AI 功能
以下是 @AiService 可加的参数:
| 参数 | 类型 | 说明 | 默认值 |
|---|---|---|---|
wiringMode |
AiServiceWiringMode |
组件绑定模式:AUTOMATIC(自动查找)或 EXPLICIT(显式指定) |
AUTOMATIC |
chatModel |
String |
显式模式下指定 ChatLanguageModel Bean 的名称 |
"" |
streamingChatModel |
String |
显式模式下指定 StreamingChatLanguageModel Bean 的名称 |
"" |
chatMemory |
String |
显式模式下指定 ChatMemory Bean 的名称 |
"" |
chatMemoryProvider |
String |
显式模式下指定 ChatMemoryProvider Bean 的名称 |
"" |
contentRetriever |
String |
显式模式下指定 ContentRetriever Bean 的名称(用于 RAG) |
"" |
retrievalAugmentor |
String |
显式模式下指定 RetrievalAugmentor Bean 的名称 |
"" |
moderationModel |
String |
显式模式下指定 ModerationModel Bean 的名称(内容审核) |
"" |
tools |
String[] |
显式模式下指定包含 @Tool 注解方法的 Bean 名称数组 |
{} |
Ⅲ、@Autowired 装配
当应用程序启动时,LangChain4j 启动器将扫描类路径 并找到所有带有 @AiService 注解的接口。
对于找到的每个 AI 服务,它将使用应用程序上下文中可用的所有 LangChain4j 组件创建此接口的实现,并将其注册为 bean, 这样就可以在需要的地方自动装配它:
@RestController
class AssistantController {
@Autowired
Assistant assistant;
@GetMapping("/chat")
public String chat(String message) {
return assistant.chat(message);
}
}
③、自动组件装配
如果以下组件在应用程序上下文中可用,它们将自动装配到 AI 服务中:
ChatLanguageModelStreamingChatLanguageModelChatMemoryChatMemoryProviderContentRetrieverRetrievalAugmentor- 任何
@Component或@Service类中带有@Tool注解的所有方法
简单来说就是:确保依赖正确导入——>以上组件在应用程序上下文中可用,那么他们就会自动交给 Spring 管理,我们可以直接使用
如果应用程序上下文中存在多个相同类型的组件,应用程序将无法启动。 在这种情况下,使用显式装配模式
④、显式组件装配
如果应用程序上下文中存在多个相同类型的组件,应用程序将无法启动。 在这种情况下,使用显式装配模式
如果您有多个 AI 服务,并希望将不同的 LangChain4j 组件装配到每个服务中, 您可以使用显式装配模式(@AiService(wiringMode = EXPLICIT))指定要使用的组件。
假设我们配置了两个 ChatLanguageModel:
# OpenAI
langchain4j.open-ai.chat-model.api-key=${OPENAI_API_KEY}
langchain4j.open-ai.chat-model.model-name=gpt-4o-mini
# Ollama
langchain4j.ollama.chat-model.base-url=http://localhost:11434
langchain4j.ollama.chat-model.model-name=llama3.1
那么要想正确使用 ChatLanguageModel 需要我们在 @AiService 注解上显示标注要使用的模型名称
@AiService(wiringMode = EXPLICIT, chatModel = "openAiChatModel")
interface OpenAiAssistant {
@SystemMessage("You are a polite assistant")
String chat(String userMessage);
}
@AiService(wiringMode = EXPLICIT, chatModel = "ollamaChatModel")
interface OllamaAssistant {
@SystemMessage("You are a polite assistant")
String chat(String userMessage);
}
注意此处选的 chatModel 的名字与你引入的 Spring Boot 的启动器依赖有关
⑤、监听 AI 服务注册事件
在以声明方式完成 AI 服务的开发后,您可以通过实现 ApplicationListener<AiServiceRegisteredEvent> 接口来监听 AiServiceRegisteredEvent。 当 AI 服务在 Spring 上下文中注册时,会触发此事件, 使您能够在运行时获取有关所有已注册的 AI 服务及其工具的信息。 以下是一个示例:
@Component
class AiServiceRegisteredEventListener implements ApplicationListener<AiServiceRegisteredEvent> {
@Override
public void onApplicationEvent(AiServiceRegisteredEvent event) {
Class<?> aiServiceClass = event.aiServiceClass();
List<ToolSpecification> toolSpecifications = event.toolSpecifications();
for (int i = 0; i < toolSpecifications.size(); i++) {
System.out.printf("[%s]: [Tool-%s]: %s%n", aiServiceClass.getSimpleName(), i + 1, toolSpecifications.get(i));
}
}
}
简单来说就是:通过实现该类可监听 AI 服务的注册信息
⑥、流式响应
流式调用(Streaming) 允许逐步获取 AI 模型的生成结果(如逐字或逐句返回),而非等待完整响应。
简单来说就是从原来的等大模型全部生成完一次性输出——>生成一点输出一点
| 对比项 | 普通调用(同步) | 流式调用(异步流) |
|---|---|---|
| 响应方式 | 一次性返回完整结果 | 逐步返回部分结果(如 SSE/WebFlux) |
| 延迟感知 | 用户需等待全部生成完成 | 用户可即时看到部分结果 |
| 适用场景 | 短文本、简单问答 | 长文本生成、实时交互 |
| 资源占用 | 内存中保存完整响应 | 按需处理分块数据,内存更高效 |
Ⅰ、引入依赖
<!-- 流式调用依赖①【spring boot项目独有】 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
<!-- 流式调用依赖② 【流式处理所需】 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-reactor</artifactId>
<version>1.0.1-beta6</version>
</dependency>
除以上两个依赖,还有spring boot启动器的依赖,这里默认已填
Ⅱ、配置文件
langchain4j:
open-ai:
chat-model:
api-key: ${DASHSCOPE_API_KEY} # 从环境变量中获取 API 密钥
model-name: qwen-plus # 模型名称,即模型 Code
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1 # 模型 API 基础 URL
log-responses: true # 是否记录响应日志
log-requests: true # 是否记录请求日志
# 流式响应
streaming-chat-model:
api-key: ${DASHSCOPE_API_KEY} # 从环境变量中获取 API 密钥
model-name: qwen-plus # 模型名称,即模型 Code
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1 # 模型 API 基础 URL
log-responses: true # 是否记录响应日志
log-requests: true # 是否记录请求日志
Ⅲ、显式装配组件并创建接口
注意此处选的 chatModel 的名字与你引入的 Spring Boot 的启动器依赖有关,下面以 OpenAI 为例,当然也可使用其他模型(如 HuggingFace、LocalAI):
- Bean 名称遵循类似规则(首字母小写),例如
huggingFaceChatModel
@AiService(
wiringMode = AiServiceWiringMode.EXPLICIT, // 显式注入模型
chatModel = "openAiChatModel", // 绑定普通模型组件
streamingChatModel = "openAiStreamingChatModel" // 绑定流式模型组件
)
public interface StreamingChatService {
// ai 聊天(普通调用)
// public String chat(String question);
// ai 聊天(流式调用)
public Flux<String> chatStreaming(String question);
}
Ⅳ、controller层调用
@RestController
public class ChatController {
@Autowired
private StreamingChatService streamingChatService;
@RequestMapping(value = "/chatStreaming", produces = "text/html;charset=UTF-8")
public Flux<String> streamingChat(String userMessage) {
return streamingChatService.chatStreaming(userMessage);
}
}
若前端输出乱码,可指定 produces = “text/html;charset=UTF-8”,响应给前端的编码类型
⑦、可观察性
要为 ChatLanguageModel 或 StreamingChatLanguageModel bean 启用可观察性, 需要声明一个或多个 ChatModelListener bean:
@Configuration
class MyConfiguration {
@Bean
ChatModelListener chatModelListener() {
return new ChatModelListener() {
private static final Logger log = LoggerFactory.getLogger(ChatModelListener.class);
@Override
public void onRequest(ChatModelRequestContext requestContext) {
log.info("onRequest(): {}", requestContext.chatRequest());
}
@Override
public void onResponse(ChatModelResponseContext responseContext) {
log.info("onResponse(): {}", responseContext.chatResponse());
}
@Override
public void onError(ChatModelErrorContext errorContext) {
log.info("onError(): {}", errorContext.error().getMessage());
}
};
}
}
应用程序上下文中的每个 ChatModelListener bean 都将自动 注入到由我们的 Spring Boot 启动器之一创建的所有 ChatLanguageModel 和 StreamingChatLanguageModel bean 中。
⑧、@SystemMessage
Ⅰ、直接输入提示模板
interface Friend {
@SystemMessage("You are a good friend of mine. Answer using slang.")
String chat(String userMessage);
}
Friend friend = AiServices.create(Friend.class, model);
String answer = friend.chat("Hello"); // 可能回答:Hey! What's up?
Ⅱ、从资源路径加载提示模板
interface Doctor {
// 在资源路径(resources)下的 my-prompt-template.txt文件加载提示模板
@SystemMessage(fromResource = "my-prompt-template.txt")
String chat(String userMessage);
}
Doctor doctor = AiServices.create(Doctor.class, model);
String answer1 = doctor.chat("我感冒怎么办"); // 可能回答:可以喝99感冒灵。。。
String answer2 = doctor.chat("股票分析"); // 可能回答:抱歉我只回答医疗相关的问题。。。
可理解为:该注解可为 LLM 提供系统信息,包含但不限于为其设定身份/指定回答范围等等
⑨、@UserMessage
Ⅰ、直接输入提示模板
interface Friend {
// 指定了一个包含变量 it 的提示模板,该变量指的是唯一的方法参数(必须是 {{it}})
@UserMessage("You are a good friend of mine. Answer using slang. {{it}}")
String chat(String userMessage);
}
Friend friend = AiServices.create(Friend.class, model);
String answer = friend.chat("Hello"); // Hey! What's shakin'?
interface Friend {
// 也可以用 @V 注解 String userMessage, 并为提示模板变量分配自定义名称
@UserMessage("You are a good friend of mine. Answer using slang. {{message}}")
String chat(@V("message") String userMessage);
}
Ⅱ、从资源路径加载提示模板
interface Friend {
// 也可指定资源路径(resources)下的 my-prompt-template.txt文件加载提示模板
@SystemMessage(fromResource = "my-prompt-template.txt")
String chat(String userMessage);
}
注意:在较新版本中的 LangChain4j中的 Spring Boot 项目可不使用 {{it}}指定唯一参数
以下是合法的使用方法
String chat(String userMessage);
String chat(@UserMessage String userMessage);
String chat(@UserMessage String userMessage, @V("country") String country); // userMessage 包含 "{{country}}" 模板变量
@UserMessage("What is the capital of Germany?")
String chat();
@UserMessage("What is the capital of {{it}}?")
String chat(String country);
@UserMessage("What is the capital of {{country}}?")
String chat(@V("country") String country);
@UserMessage("What is the {{something}} of {{country}}?")
String chat(@V("something") String something, @V("country") String country);
@UserMessage("What is the capital of {{country}}?")
String chat(String country); // 这仅在 Quarkus 和 Spring Boot 应用程序中有效
2.3、返回类型
AI 服务方法可以返回以下类型之一:
String- 在这种情况下,LLM 生成的输出将不经任何处理/解析直接返回- 结构化输出支持的任何类型 - 在这种情况下, AI 服务将在返回之前将 LLM 生成的输出解析为所需类型
任何类型都可以额外包装在 Result<T> 中,以获取有关 AI 服务调用的额外元数据:
TokenUsage- AI 服务调用期间使用的令牌总数。如果 AI 服务对 LLM 进行了多次调用 (例如,因为执行了工具),它将汇总所有调用的令牌使用情况。- Sources - 在 RAG 检索期间检索到的
Content - 已执行的工具
FinishReason
简单来说就是:AI 服务的返回类型可以是结构化输出支持的任意类型,其返回类型取决于最终 LLM 的输出被解析成什么类型
而同时我们可以获取到返回结果中有关 AI 服务调用的元数据:token使用情况、RAG 检索到的内容、使用的tool等等
2.4、流式处理
①、使用 TokenStream
interface Assistant {
TokenStream chat(String message);
}
// 创建流式聊天模型
StreamingChatLanguageModel model = OpenAiStreamingChatModel.builder()
.apiKey(System.getenv("OPENAI_API_KEY"))
.modelName(GPT_4_O_MINI)
.build();
// 假设不是 Spring Boot 项目,我们需要自己手动调用 AiServices.create 进行代理
Assistant assistant = AiServices.create(Assistant.class, model);
// 使用 TokenStream 进行手动的配置流式处理
TokenStream tokenStream = assistant.chat("Tell me a joke");
tokenStream.onPartialResponse((String partialResponse) -> System.out.println(partialResponse))
.onRetrieved((List<Content> contents) -> System.out.println(contents))
.onToolExecuted((ToolExecution toolExecution) -> System.out.println(toolExecution))
.onCompleteResponse((ChatResponse response) -> System.out.println(response))
.onError((Throwable error) -> error.printStackTrace())
.start();
②、使用Flux< String >
Ⅰ、导入依赖
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-reactor</artifactId>
<version>1.0.0-beta3</version>
</dependency>
Ⅱ、使用
interface Assistant {
Flux<String> chat(String message);
}
2.5、链接多个 AI 服务
该部分核心目的就是:使用性能次的大模型进行简单任务,性能好的进行复杂任务
对大模型进行集成测试并分别评估,为每个子任务找到最优参数,或者从长远来看,甚至可以为每个特定子任务微调一个小型专用模型。
个人认为类似微服务的感觉,为每个模块分配不同资源去处理不同难度的任务,做到使用效率最高、垂直专业性能最好
其余部分在下面分开来细说:如会话记忆、工具调用、RAG、结构化输出等
3、会话记忆
3.1、ChatMemory 介绍
①、ChatMemory 由来及功能
在我们介绍低级 API 时提到其中的 ChatLanguageModel 组件的请求参数可以是多个 ChatMessage 类型,低级 API 的组件需要我们自己手动配置和管理,这是很麻烦的。 因此,LangChain4j提供了ChatMemory抽象以及多种开箱即用的实现。
ChatMemory可以作为独立的低级组件使用, 或者作为高级组件(如AI服务)的一部分。
ChatMemory作为ChatMessage的容器(由List支持),具有以下额外功能:
- 淘汰策略
- 持久化
- 对
SystemMessage的特殊处理 - 对工具消息的特殊处理
简单来说,ChatMemory 是用来简化手动维护和管理
ChatMessage的
②、区别记忆与历史
- 历史保持用户和AI之间的所有消息完整无缺。历史是用户在UI中看到的内容。它代表实际对话内容。
- 记忆保存一些信息,这些信息呈现给LLM,使其表现得好像"记住"了对话。根据使用的记忆算法,记忆算法可以以各种方式修改历史: 淘汰一些消息,总结多条消息,总结单独的消息,从消息中删除不重要的细节, 向消息中注入额外信息(例如,用于RAG)或指令(例如,用于结构化输出)等等。
LangChain4j目前只提供"记忆",而不是"历史"。如果您需要保存完整的历史记录,请手动进行。
③、简单创建实例
@Bean
// ChatMemory 类中含 id、add、messages、clear 方法
// id 方法是为了在多线程环境下,每个线程都有自己的 ChatMemory 实例,即记忆存储对象的唯一标识
// add 方法是为了将 ChatMessage 实例添加到记忆存储对象中
// messages 方法是为了获取记忆存储对象中的所有 ChatMessage 实例
// clear 方法是为了清空记忆存储对象中的所有 ChatMessage 实例
// 这里使用 MessageWindowChatMemory 实现类,最多存储 10 条消息
public ChatMemory getChatMemory() {
return MessageWindowChatMemory.builder()
.maxMessages(10)
.build();
}
3.2、淘汰策略
在 LangChain4j 中,ChatMemory 的 淘汰策略(Eviction Policy) 用于控制对话历史消息的保留和移除机制,确保上下文长度不超过模型限制(如 OpenAI 的 Token 上限)或避免内存溢出。
①、需要的原因
- 控制数量。为了适应LLM的上下文窗口。LLM一次可以处理的令牌数量是有上限的。 在某些时候,对话可能会超过这个限制。在这种情况下,应该淘汰一些消息。
通常,最旧的消息会被淘汰,但如果需要,可以实现更复杂的算法。 - 控制成本。每个令牌都有成本,使每次调用LLM的费用逐渐增加。 淘汰不必要的消息可以降低成本。
- 控制延迟。发送给LLM的令牌越多,处理它们所需的时间就越长。
简单来说就是:为了控制发送给LLM的令牌数量、控制调用 LLM 的成本、控制处理令牌的时间
②、实现
目前,LangChain4j提供了2种开箱即用的实现:
- 较简单的一种,
MessageWindowChatMemory,作为滑动窗口运行, 保留最近的N条消息,并淘汰不再适合的旧消息。 然而,由于每条消息可能包含不同数量的令牌,MessageWindowChatMemory主要用于快速原型设计。 - 更复杂的选项是
TokenWindowChatMemory, 它也作为滑动窗口运行,但专注于保留最近的N个令牌, 根据需要淘汰旧消息。 消息是不可分割的。如果一条消息不适合,它会被完全淘汰。TokenWindowChatMemory需要一个Tokenizer来计算每个ChatMessage中的令牌数。
简单来说就是:MessageWindowChatMemory 保留最近 N 条信息,TokenWindowChatMemory 保留最近 N 条令牌。二者都是作为滑动窗口运行,二者源码均内置了 builder构造器,可通过其完成创建
当然也可自定义 ChatMemory 的实现
| 策略类型 | 实现类 | 说明 |
|---|---|---|
| 按消息数量截断 | MessageWindowChatMemory |
保留最近的 N 条消息,超出时移除最旧的消息。 |
| 按 Token 数量截断 | TokenWindowChatMemory |
累计消息的 Token 数超过阈值时,按顺序移除最旧的消息,直到满足限制。 |
| 混合策略 | 自定义组合 | 例如:先按 Token 截断,若仍超限则再按消息数截断。 |
| 持久化存储淘汰 | PersistentChatMemory |
结合数据库/Redis 的 TTL(生存时间)自动清理过期会话。 |
③、简单使用
Ⅰ、MessageWindowChatMemory(按消息数)
ChatMemory memory = MessageWindowChatMemory.builder()
.maxMessages(10) // 最多保留10条最新消息
.build();
- 触发条件:历史消息数量 >
maxMessages。 - 淘汰行为:移除最旧的消息(FIFO)。
Ⅱ、TokenWindowChatMemory(按 Token 数)
ChatMemory memory = TokenWindowChatMemory.builder()
.maxTokens(2000) // 最大Token数限制
.tokenizer(new OpenAiTokenizer("gpt-4")) // 指定Token计算方式(如GPT-4)
.build();
- 触发条件:累计 Token 数 >
maxTokens。 - 淘汰行为:从最旧的消息开始逐条移除,直到总 Token 数 ≤ 阈值。
3.3、会话记忆隔离
如果只是配置简单的会话记忆对象(公用会话记忆对象),那么即使换个线程去再次进行访问会话,仍然会延续上一个线程的内容,即用户1进行完了对话,此时用户2开启新的会话,该会话仍然会基于用户1的会话内容进行延续,这显然是不合理的,没有做到会话记忆的隔离性(原先是共用一个会话记忆对象,现在为每个不同用户提供不同的对象)。
在这种情况下,所有 AI 服务调用都将使用相同的 ChatMemory 实例。 然而,如果您有多个用户,这种方法将不起作用, 因为每个用户都需要自己的 ChatMemory 实例来维护各自的对话。
为了解决这个问题,我们可以通过为会话记忆对象设置唯一 id,同时配置会话记忆对象的提供者
| 场景 | 是否自动隔离 | 原因 |
|---|---|---|
| 手动管理多个 ChatMemory 实例 | ✅ 是 | 每个实例独立存储消息。 |
| 未配置 ChatMemoryProvider 且单例注入 | ❌ 否 | 所有请求共享同一内存。 |
| 配置 ChatMemoryProvider | ✅ 是 | 根据 memoryId 动态隔离。 |
①、创建会话记忆提供者
核心是重写 ChatMemoryProvider 中的 get 方法
@Configuration
public class CommonConfig {
// 注入 OpenAiChatModel (ChatLanguageModel 的实现) 实例
// 只有引入 langchain4j-open-ai-spring-boot-starter 依赖才会自动配置 OpenAiChatModel 实例
// langchain4j-spring-boot-starter 依赖不会自动配置 OpenAiChatModel 实例
@Autowired
private OpenAiChatModel chatModel;
@Bean
// ChatMemory 类中含 id、add、messages、clear 方法
// id 方法是为了在多线程环境下,每个线程都有自己的 ChatMemory 实例,即记忆存储对象的唯一标识
// add 方法是为了将 ChatMessage 实例添加到记忆存储对象中
// messages 方法是为了获取记忆存储对象中的所有 ChatMessage 实例
// clear 方法是为了清空记忆存储对象中的所有 ChatMessage 实例
// 这里使用 MessageWindowChatMemory 实现类,最多存储 10 条消息
public ChatMemory getChatMemory() {
return MessageWindowChatMemory.builder()
.maxMessages(10)
.build();
}
@Bean
// 创建会话记忆提供者
public ChatMemoryProvider getChatMemoryProvider() {
return new ChatMemoryProvider() {
// 重写 ChatMemoryProvider 中的 get 方法
@Override
public ChatMemory get(Object memoryId) {
return MessageWindowChatMemory.builder()
.id(memoryId)
.maxMessages(10)
.build();
}
};
}
}
②、配置会话记忆提供者
@AiService(
wiringMode = AiServiceWiringMode.EXPLICIT, // 显式注入模型
chatModel = "openAiChatModel", // 绑定普通模型
streamingChatModel = "openAiStreamingChatModel", // 绑定流式模型
// chatMemory = "getChatMemory" // 配置会话记忆公共对象
chatMemoryProvider = "getChatMemoryProvider" // 配置带有唯一 id 的会话记忆对象
)
public interface ConsultantService {
// 带唯一 id 的聊天
@SystemMessage("你是一个医疗助手")
public Flux<String> chatStreamingWithId(
@MemoryId String memoryId, // 需要使用 @MemoryId 标注唯一id
@UserMessage String question // 多个参数需要使用 @UserMessage 标注用户信息
);
}
在这种情况下,
ChatMemoryProvider将提供多个不同的ChatMemory实例,每个记忆 ID 一个。以这种方式使用
ChatMemory时,重要的是要清除不再需要的对话记忆,以避免内存泄漏。要使 AI 服务内部使用的聊天记忆可访问,只需让定义它的接口扩展ChatMemoryAccess接口即可。
**注意:**如果 AI 服务方法没有用 @MemoryId 注解的参数, ChatMemoryProvider 中 memoryId 的值将默认为字符串 "default"。
**注意:**不应对同一个 @MemoryId 并发调用 AI 服务, 因为这可能导致 ChatMemory 损坏。 目前,AI 服务没有实现任何机制来防止对同一 @MemoryId 的并发调用。
③、controller层调用
@RestController
public class ChatController {
@Autowired
private ConsultantService consultantService;
@RequestMapping(value = "/chatStreamingWithId", produces = "text/html;charset=UTF-8")
public Flux<String> consultantStreamingWithId(String memoryId,String userMessage) {
return consultantService.chatStreamingWithId(memoryId,userMessage);
}
}
3.4、会话记忆持久化
当后端维护人员重启后端,用户原有的会话丢失,这是由于默认情况下,ChatMemory(底部两个实现:MessageWindowChatMemory、TokenWindowChatMemory)是在服务器内存中存储ChatMessage,这就导致每次服务器的重启,其内存信息会丢失,进而导致用户会话记忆丢失。
如果需要持久化,可以实现自定义的ChatMemoryStore, 将ChatMessage存储在您选择的任何持久化存储中
核心是实现ChatMemoryStore接口,重写其中的getMessages、updateMessages、deleteMessages三个方法
class PersistentChatMemoryStore implements ChatMemoryStore {
@Override
public List<ChatMessage> getMessages(Object memoryId) {
// TODO: 实现通过内存ID从持久化存储中获取所有消息。
// 可以使用ChatMessageDeserializer.messageFromJson(String)和
// ChatMessageDeserializer.messagesFromJson(String)辅助方法
// 轻松地从JSON反序列化聊天消息。
}
@Override
public void updateMessages(Object memoryId, List<ChatMessage> messages) {
// TODO: 实现通过内存ID更新持久化存储中的所有消息。
// 可以使用ChatMessageSerializer.messageToJson(ChatMessage)和
// ChatMessageSerializer.messagesToJson(List<ChatMessage>)辅助方法
// 轻松地将聊天消息序列化为JSON。
}
@Override
public void deleteMessages(Object memoryId) {
// TODO: 实现通过内存ID删除持久化存储中的所有消息。
}
}
public ChatMemory getMyChatMemory() {
return MessageWindowChatMemory.builder()
.id("12345")
.maxMessages(10)
.chatMemoryStore(new PersistentChatMemoryStore())
.build();
}
以下以 redis 为例(docker等配置redis自行了解,这里不多赘述):
①、配置并连接好redis
<!-- 引入 redis 依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
spring:
application:
name: langchain4j
data:
redis:
host: localhost
port: 6379
database: 3
②、创建自定义ChatMemoryStore
该自定义类要实现ChatMemoryStore接口,重写其中的getMessages、updateMessages、deleteMessages三个方法
@Repository
public class RedisChatMemoryStore implements ChatMemoryStore {
@Autowired
private StringRedisTemplate redisTemplate;
@Override
public List<ChatMessage> getMessages(Object memoryId) {
// 从 redis 中获取会话信息
String json = (String) redisTemplate.opsForValue().get(memoryId);
// 把 json 转为 List<ChatMessage>
List<ChatMessage> list = ChatMessageDeserializer.messagesFromJson(json);
return list;
}
@Override
public void updateMessages(Object memoryId, List<ChatMessage> list) {
// 将 list 转换为 json 格式
String json = ChatMessageSerializer.messagesToJson(list);
// 把 json 存到 redis 中(最好设置 TTL,避免会话内容永久存在)
redisTemplate.opsForValue().set(memoryId.toString(),json, Duration.ofDays(1));
}
@Override
public void deleteMessages(Object memoryId) {
// 删除内容
redisTemplate.delete(memoryId.toString());
}
}
③、使用自定义ChatMemoryStore
@Configuration
public class CommonConfig {
// 注入 OpenAiChatModel (ChatLanguageModel 的实现) 实例
// 只有引入 langchain4j-open-ai-spring-boot-starter 依赖才会自动配置 OpenAiChatModel 实例
// langchain4j-spring-boot-starter 依赖不会自动配置 OpenAiChatModel 实例
@Autowired
private OpenAiChatModel chatModel;
// 注入自定义的 ChatMemoryStore
@Autowired
private RedisChatMemoryStore redisChatMemoryStore;
@Bean
// 创建会话记忆提供者
public ChatMemoryProvider getMyChatMemoryProvider() {
return new ChatMemoryProvider() {
// 重写 ChatMemoryProvider 中的 get 方法
@Override
public ChatMemory get(Object memoryId) {
return MessageWindowChatMemory.builder()
.id(memoryId)
.maxMessages(10)
.chatMemoryStore(redisChatMemoryStore) // 使用自定义的 RedisChatMemoryStore
.build();
}
};
}
}
④、配置自定义ChatMemoryStore
@AiService(
wiringMode = AiServiceWiringMode.EXPLICIT, // 显式注入模型
chatModel = "openAiChatModel", // 绑定普通模型
streamingChatModel = "openAiStreamingChatModel", // 绑定流式模型
// chatMemory = "getChatMemory" // 配置会话记忆公共对象
// chatMemoryProvider = "getChatMemoryProvider" // 配置带有唯一 id 的会话记忆对象
chatMemoryProvider = "getMyChatMemoryProvider" // 配置带有自定义的 ChatMemoryStore类的会话记忆提供者
)
public interface ConsultantService {
// 带自定义的 ChatMemoryStore类和唯一 id 的聊天
@SystemMessage("你是一个医疗助手")
public Flux<String> chatStreamingWithIdAndR(
@MemoryId String memoryId, // 需要使用 @MemoryId 标注唯一id
@UserMessage String question // 多个参数需要使用 @UserMessage 标注用户信息
);
}
⑤、controller层调用
@RestController
public class ChatController {
@Autowired
private ConsultantService consultantService;
@RequestMapping(value = "/chatStreamingWithIdAndR", produces = "text/html;charset=UTF-8")
public Flux<String> consultantStreamingWithIdAndR(String memoryId,String userMessage) {
return consultantService.chatStreamingWithIdAndR(memoryId,userMessage);
}
}
⑥、调用详情
Ⅰ、updateMessages()方法
- 每当向
ChatMemory添加新的ChatMessage时,都会调用updateMessages()方法。 这通常在与LLM的每次交互中发生两次: 一次是添加新的UserMessage时,另一次是添加新的AiMessage时。 - 从
ChatMemory中淘汰的消息也将从ChatMemoryStore中淘汰。 当消息被淘汰时,会调用updateMessages()方法, 传入不包含被淘汰消息的消息列表。
Ⅱ、getMessages()方法
- 当
ChatMemory的用户请求所有消息时,会调用getMessages()方法。 这通常在与LLM的每次交互中发生一次。
Ⅲ、deleteMessages()方法
- 当调用
ChatMemory.clear()时,会调用deleteMessages()方法。 如果不使用此功能,可以将此方法留空。
3.5、对SystemMessage的特殊处理
- 一旦添加,
SystemMessage总是被保留。 - 一次只能保存一条
SystemMessage。 - 如果添加了具有相同内容的新
SystemMessage,它会被忽略。 - 如果添加了具有不同内容的新
SystemMessage,它会替换之前的消息。
3.6、对工具消息的特殊处理
如果包含ToolExecutionRequest的AiMessage被淘汰, 随后的孤立ToolExecutionResultMessage也会自动被淘汰, 以避免与某些LLM提供商(如OpenAI)出现问题, 这些提供商禁止在请求中发送孤立的ToolExecutionResultMessage。
简单来说就是没有了工具的调用,其结果也会被淘汰
4、工具(函数调用)
该概念允许 LLM 在必要时调用一个或多个可用的工具,通常由开发者定义。 工具可以是任何东西:网络搜索、调用外部 API 或执行特定代码片段等。 LLM 实际上不能自己调用工具;相反,它们在响应中表达调用特定工具的意图(而不是以纯文本形式响应)。 作为开发者,我们应该使用提供的参数执行这个工具,并将工具执行的结果反馈回来。
简单来说就是我们提供工具,工具允许 AI 模型(如 OpenAI GPT)动态调用外部方法或 API 以获取额外信息或执行操作(如计算、搜索、数据库查询等)。
为了增加 LLM 调用正确工具并使用正确参数的可能性, 我们应该提供清晰明确的:
- 工具名称
- 工具功能描述以及何时应该使用它
- 每个工具参数的描述
LangChain4j 提供了两个抽象级别来使用工具:
- 低级别,使用
ChatLanguageModel和ToolSpecificationAPI - 高级别,使用 AI 服务和带有
@Tool注解的 Java 方法
4.1、快速了解工具方法
①、工具方法限制
带有 @Tool 注解的方法:
- 可以是静态或非静态的
- 可以有任何可见性(public、private 等)。
②、工具方法参数
带有 @Tool 注解的方法可以接受的参数:
- 没有参数
- 任意数量基本类型:
int、double等 - 任意数量对象类型:
String、Integer、Double等 - 任意数量自定义 POJO(可以包含嵌套 POJO)
- 任意数量
enum(枚举) - 任意数量
List<T>/Set<T>,其中T是上述类型之一 - 任意数量
Map<K,V>(您需要在参数描述中使用@P手动指定K和V的类型)
默认情况下,所有工具方法参数都被视为必需的。 这意味着 LLM 必须为这样的参数生成一个值。 可以通过使用 @P(required = false) 注解使参数成为可选的:
@Tool
// unit 该参数可不填值
void getTemperature(String location, @P(required = false) Unit unit) {
...
}
复杂参数的字段和子字段默认也被视为必需的。 可以通过使用 @JsonProperty(required = false) 注解使字段成为可选的:
// user 该参数其中的 email 字段可不填
record User(String name, @JsonProperty(required = false) String email) {}
@Tool
void add(User user) {
...
}
③、工具方法返回类型
可以返回包括 void的任何类型
- 返回类型是
void,则在方法成功返回时会向 LLM 发送"Success"字符串。 - 返回类型是
String,则返回值会原样发送给 LLM,不进行任何转换。 - 其他返回类型,返回值会在发送给 LLM 之前转换为 JSON 字符串。
④、工具方法异常处理
如果带有 @Tool 注解的方法抛出 Exception, 异常的消息(e.getMessage())将作为工具执行的结果发送给 LLM。 这允许 LLM 纠正其错误并在认为必要时重试。
⑤、工具方法常用注释
Ⅰ、@Tool
任何带有 @Tool 注解的 Java 方法, 并且在构建 AI 服务时明确指定,都可以由 LLM 执行
@Tool 注解有 2 个可选字段:
name:工具名称。如果未提供,方法名将作为工具名称。value:工具描述。
根据工具的不同,LLM 可能即使没有任何描述也能很好地理解它 (例如,add(a, b) 是显而易见的), 但通常最好提供清晰有意义的名称和描述。 这样,LLM 有更多信息来决定是否调用给定的工具,以及如何调用。
即工具方法最好见名知意
Ⅱ、@P
方法参数可以选择使用 @P 注解。
@P 注解有 2 个字段
value:参数描述。必填字段。required:参数是否必需,默认为true。可选字段
即可通过该注解为工具的参数进行描述,方便 LLM 理解,之后才可调用
Ⅲ、@Description
类和字段的描述可以使用 @Description 注解指定:
@Description("要执行的查询")
class Query {
@Description("要选择的字段")
private List<String> select;
@Description("过滤条件")
private List<Condition> where;
}
@Tool
Result executeQuery(Query query) {
...
}
注意,放在 enum 值上的 @Description 没有效果,并且不会包含在生成的 JSON schema 中
Ⅳ、@ToolMemoryId
如果您的 AI 服务方法有一个带有 @MemoryId 注解的参数, 您也可以使用 @ToolMemoryId 注解 @Tool 方法的参数。 提供给 AI 服务方法的值将自动传递给 @Tool 方法。 如果您有多个用户和/或每个用户有多个聊天/记忆, 并希望在 @Tool 方法内区分它们,这个功能很有用。
简单来说该注解是 @Tool+@MemoryId 的结合
4.2、低级工具 API
简单来说就是手动创建 ToolSpecification 来进行工具的调用
在创建 ChatRequest 时指定一个或多个 ToolSpecification。
ToolSpecification 是一个包含工具所有信息的对象:
- 工具的
name(String类型:名称) - 工具的
description(String类型:描述) - 工具的
parameters(JsonObjectSchema类型:参数)及其描述 -
- JsonObjectSchema 是结构化输出的表示具有嵌套属性的对象(可见下方6、结构化输出的描述)
建议提供尽可能多的工具信息: 清晰的名称、全面的描述以及每个参数的描述等。
①、创建 ToolSpecification
Ⅰ、builder手动创建
ToolSpecification toolSpecification = ToolSpecification.builder()
.name("getWeather") // 自定义该工具对象名
.description("返回给定城市的天气预报") // 自定义该工具对象描述
.parameters(JsonObjectSchema.builder()
.addStringProperty("city", "应返回天气预报的城市")
.addEnumProperty("temperatureUnit", List.of("CELSIUS", "FAHRENHEIT"))
.required("city") // 必须明确指定必需的属性
.build())
.build();
Ⅱ、辅助方法手动创建
ToolSpecifications.toolSpecificationsFrom(Class)ToolSpecifications.toolSpecificationsFrom(Object)ToolSpecifications.toolSpecificationFrom(Method)
class WeatherTools {
@Tool("返回给定城市的天气预报")
String getWeather(
@P("应返回天气预报的城市") String city,
TemperatureUnit temperatureUnit
) {
...
}
}
List<ToolSpecification> toolSpecifications = ToolSpecifications.toolSpecificationsFrom(WeatherTools.class);
②、调用模型返回结果
一旦有了 ToolSpecification/List<ToolSpecification>,就可以调用模型进行对话:
ChatRequest request = ChatRequest.builder()
.messages(UserMessage.from("明天伦敦的天气会怎样?"))
.toolSpecifications(toolSpecifications)
.build();
ChatResponse response = model.chat(request);
AiMessage aiMessage = response.aiMessage();
返回的对话结果将在 toolExecutionRequests 字段中包含数据。
每个 ToolExecutionRequest 应包含:
- 工具调用的
id(某些 LLM 不提供) - 要调用的工具的
name,例如:getWeather arguments(参数),例如:{ "city": "London", "temperatureUnit": "CELSIUS" }
如果想将工具执行的结果发送回 LLM, 您需要创建一个 ToolExecutionResultMessage【ChatMessage 的其中之一类型】(每个 ToolExecutionRequest 对应一个) 并将其与所有先前的消息一起发送:
String result = "预计明天伦敦会下雨。";
ToolExecutionResultMessage toolExecutionResultMessage = ToolExecutionResultMessage.from(toolExecutionRequest, result);
ChatRequest request2 = ChatRequest.builder()
.messages(List.of(userMessage, aiMessage, toolExecutionResultMessage))
.toolSpecifications(toolSpecifications)
.build();
ChatResponse response2 = model.chat(request2);
4.3、高级工具 API
简单来说就是使用
@Tool注解任何 Java 方法, 并在创建 AI 服务时指定它们。这会自动创建ToolSpecification 来进行工具的调用
4.4、基础使用
①、定义工具类
@Component // 确保被 Spring 管理
public class CalculatorTools {
@Tool("计算两个数的加法")
public double add(double a, double b) {
return a + b;
}
@Tool("计算数字的平方根")
public double sqrt(double x) {
return Math.sqrt(x);
}
@Tool("获取当前天气")
public String getWeather(String city) {
// 模拟调用天气 API
return String.format("%s的天气是晴天,25°C", city);
}
}
②、配置 AiService 启用工具
@AiService(
chatModel = "openAiChatModel", // 指定模型 Bean
tools = {CalculatorTools.class} // 注册工具类
)
public interface Assistant {
@SystemMessage("你是一个数学和天气助手,可以使用工具解决问题。")
String chat(String userMessage); // 普通聊天方法
// 专用工具调用方法(可选)
@SystemMessage("回答时优先使用工具计算。")
String calculate(String question);
}
③、调用工具方法
Ⅰ、自动触发
当用户的提问涉及工具能力时,AI 会自动选择并调用合适的工具
@Autowired
private Assistant assistant;
// 触发加法工具
String answer = assistant.chat("123加456等于多少?");
System.out.println(answer); // "123 + 456 = 579"
// 触发天气工具
String weather = assistant.chat("北京天气怎么样?");
System.out.println(weather); // "北京的天气是晴天,25°C"
Ⅱ、手动触发
通过 ToolExecutionRequest 和 ToolExecutor 精细控制:
import dev.langchain4j.agent.tool.ToolExecutionRequest;
import dev.langchain4j.agent.tool.ToolExecutor;
// 手动构造工具请求
ToolExecutionRequest request = ToolExecutionRequest.builder()
.name("sqrt") // 工具方法名
.arguments("{\"x\": 16}") // JSON 格式参数
.build();
// 执行工具
ToolExecutor executor = ... // 从 AiService 获取
String result = executor.execute(request);
System.out.println(result); // "4.0"
4.5、调用流程
- 模型决策:AI 根据用户输入判断是否需要调用工具。
- 生成请求:模型返回
ToolExecutionRequest(包含工具名和参数 JSON)。 - 执行工具:LangChain4j 自动调用对应的
@Tool方法(我们自己实现)。 - 返回结果:工具结果被注入后续对话上下文,模型生成最终回复。
4.6、高级配置
①、强制使用工具
通过 @SystemMessage 提示模型优先使用工具:
@SystemMessage("""
你必须使用工具完成以下任务:
1. 数学计算调用计算器工具。
2. 查询天气使用天气工具。
""")
String enforceToolUsage(String question);
②、多工具冲突处理
若多个工具匹配,可通过 @Tool 的 name 属性显式指定:
@Tool(name = "weather_api", value = "获取城市天气")
public String fetchWeather(String city) { ... }
③、流式工具调用
结合 @Streaming 实现流式响应:
@Streaming
void streamingChat(String message, StreamingResponseHandler handler);
5、RAG (检索增强生成)
5.1、介绍RAG
①、什么是 RAG
简单来说,RAG 是一种在发送给 LLM 之前,从你的数据中找到并注入相关信息片段到提示中的方法。 这样 LLM 将获得(希望是)相关信息,并能够使用这些信息回复, 这应该会降低产生幻觉的概率。
相关信息片段可以使用各种信息检索方法找到。 最流行的方法有:
- 全文(关键词)搜索。这种方法使用 TF-IDF 和 BM25 等技术, 通过匹配查询(例如,用户提问的内容)中的关键词与文档数据库进行搜索。 它根据每个文档中这些关键词的频率和相关性对结果进行排名。
- 向量搜索,也称为"语义搜索"。 文本文档使用嵌入模型转换为数字向量。 然后根据查询向量和文档向量之间的余弦相似度 或其他相似度/距离度量找到并排序文档, 从而捕捉更深层次的语义含义。
- 混合搜索。结合多种搜索方法(例如,全文 + 向量)通常可以提高搜索的有效性。
目前,本页主要关注向量搜索。 全文和混合搜索目前仅由 Azure AI Search 集成支持, 详情请参阅 AzureAiSearchContentRetriever。 我们计划在不久的将来扩展 RAG 工具箱,包括全文和混合搜索。
②、为什么需要 RAG
让大语言模型(LLM)掌握特定领域的知识或专有数据,主要有以下三种方法,每种方法各有优缺点,适合不同场景:
Ⅰ、大模型微调(Fine-tuning)
- 原理:在领域数据上继续训练预训练好的大模型,调整其参数以适应特定任务或领域。
- 优点:
- 模型能深度内化领域知识,生成更符合领域风格的文本。
- 推理时无需额外检索步骤,响应速度快。
- 缺点:
- 需要大量高质量领域数据,训练成本高(算力、时间)。
- 知识更新需重新微调,灵活性差。
- 可能遗忘原有通用能力(灾难性遗忘)。
- 适用场景:领域知识稳定、数据充足且需高频使用的场景(如医疗诊断、法律文书生成)。
Ⅱ、检索增强生成(RAG, Retrieval-Augmented Generation)
- 原理:将外部知识库(如数据库、文档)与LLM结合,实时检索相关片段作为生成依据。
- 优点:
- 无需训练模型,成本低,部署灵活。
- 知识可动态更新(只需修改检索库)。
- 生成结果可溯源,适合需要引用的场景。
- 缺点:
- 依赖检索质量,若检索结果不相关,生成内容可能偏离需求。
- 推理速度受检索步骤影响。
- 适用场景:知识频繁更新或需结合实时数据的场景(如客服问答、新闻摘要)。
Ⅲ、微调 + RAG 结合
- 原理:先微调模型适应领域风格,再通过RAG补充实时或细节知识。
- 优点:
- 兼顾内化知识(微调)与外部扩展(RAG),效果更全面。
- 微调可优化模型对检索结果的理解和利用能力。
- 缺点:
- 实现复杂,需协调两种技术的交互。
- 成本高于单独使用RAG。
- 适用场景:对领域知识和实时性要求均高的复杂任务(如金融分析、科研辅助)。
5.2、RAG 的两个阶段
①、补充:向量余弦相似度
即两个向量夹角的余弦值,余弦值(cos)越大,两个向量越接近,相似度越高,对应的数据相似度也越高
我们可以利用这一特性进行数据的搜索筛选,比如我们的向量数据库中有:“我爱学习”、“我今天吃饭了”、“我爱打篮球“、”我爱学习英文”,我们现在要搜索的是【目标数据】:“我爱学习中文”,则每个向量数据和【目标数据】之间都会存在向量夹角,该夹角的余弦越大,数据越接近。
“我爱学习”【0.6】、“我今天吃饭了”【0.3】、“我爱打篮球“【0.2】、”我爱学习英文”【0.8】,这时候规定搜索的数据其向量余弦相似度要> 0.5,于是可筛选出“我爱学习”、”我爱学习英文”两个数据
简单来说就是相关性
②、索引
索引阶段可简单认为是对文档的预处理,以方便后续检索
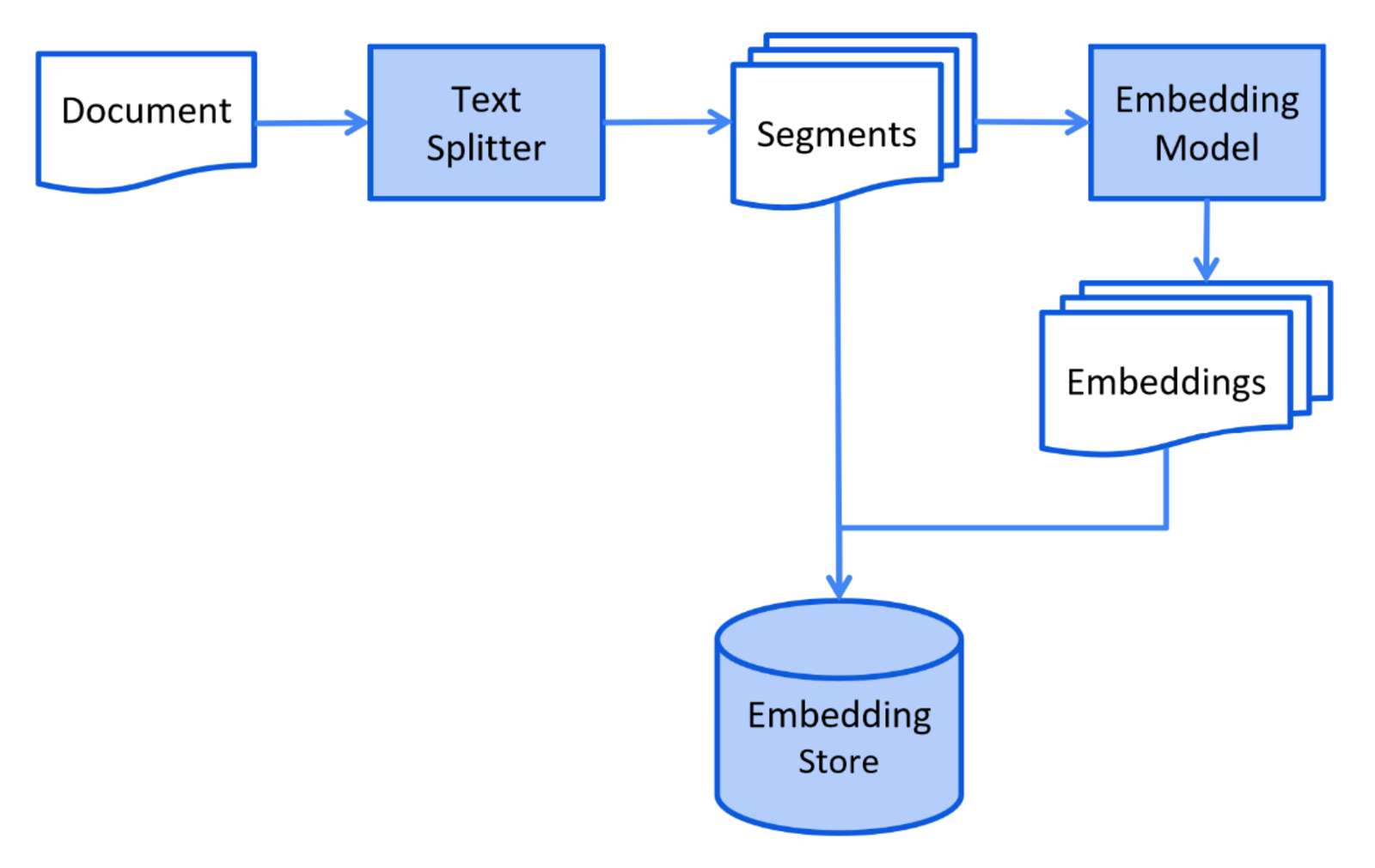
根据以上LangChain4j官方提供的索引阶段的简化图表可知:
- 一个文档先被分块——> 生成多个片段
- 片段交由向量大模型处理——> 生成对应的向量
- 将片段和对应的向量一起存储在向量数据库中
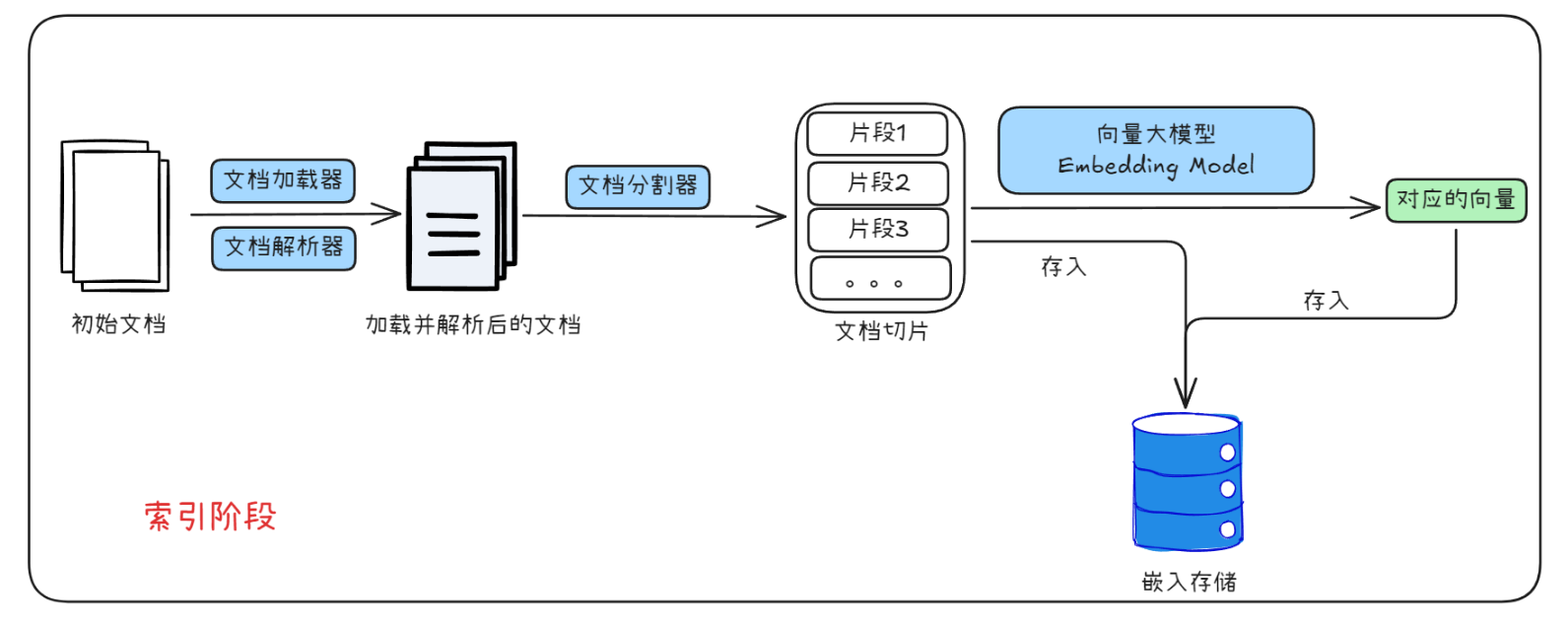
索引阶段通常是离线进行的,这意味着最终用户不需要等待其完成。 例如,可以通过定时任务在周末每周重新索引一次公司内部文档来实现。 负责索引的代码也可以是一个单独的应用程序,只处理索引任务。
然而,在某些情况下,最终用户可能希望上传自己的自定义文档,使 LLM 能够访问这些文档。 在这种情况下,索引应该在线进行,并成为主应用程序的一部分。
③、检索
检索阶段可认为是当用户提交一个应该使用索引文档回答的问题时进行
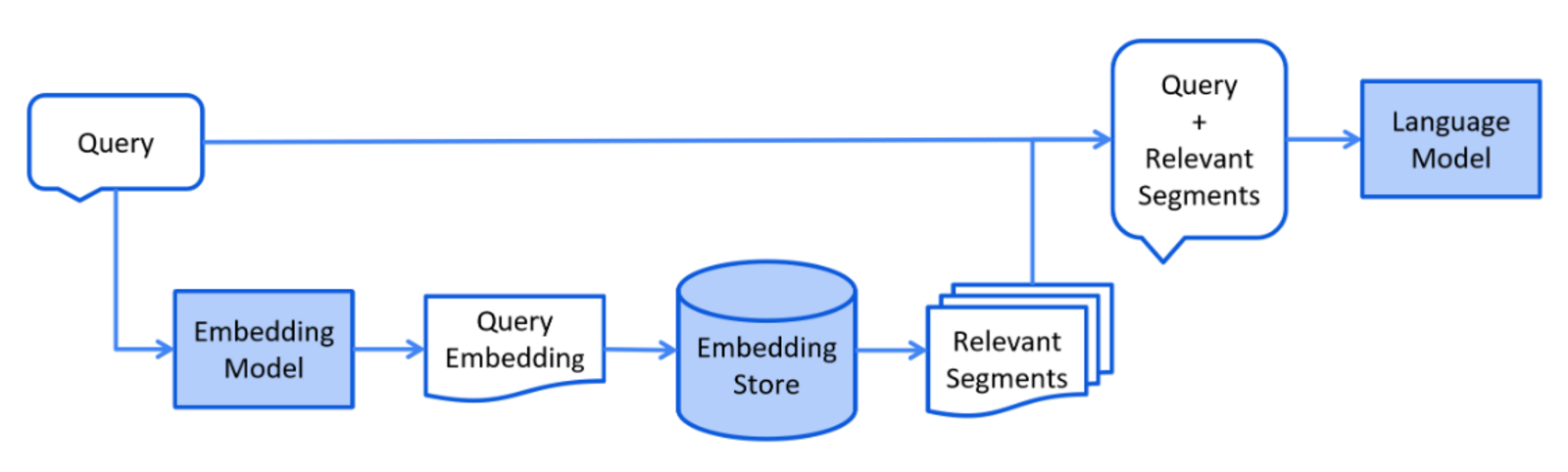
根据以上LangChain4j官方提供的检索阶段的简化图表可知:
-
一个问题请求交由向量大模型处理——> 生成多个问题片段
-
多个问题片段去向量数据库中检索——> 找到符合的答案片段
该步骤中的信息检索,不一定必须使用向量数据库,也可以是关系型数据库(如MySQL)或全文搜索引擎(如Elasticsearch, ES)等等只不过在RAG的应用场景中,主要是要比对向量余弦的相似度的某几个文档,而不是精确的查找某一条(MySQL、ES擅长),所以大多是去查询向量数据库
-
将问题片段和符合的答案片段一起交由语言大模型组织回应
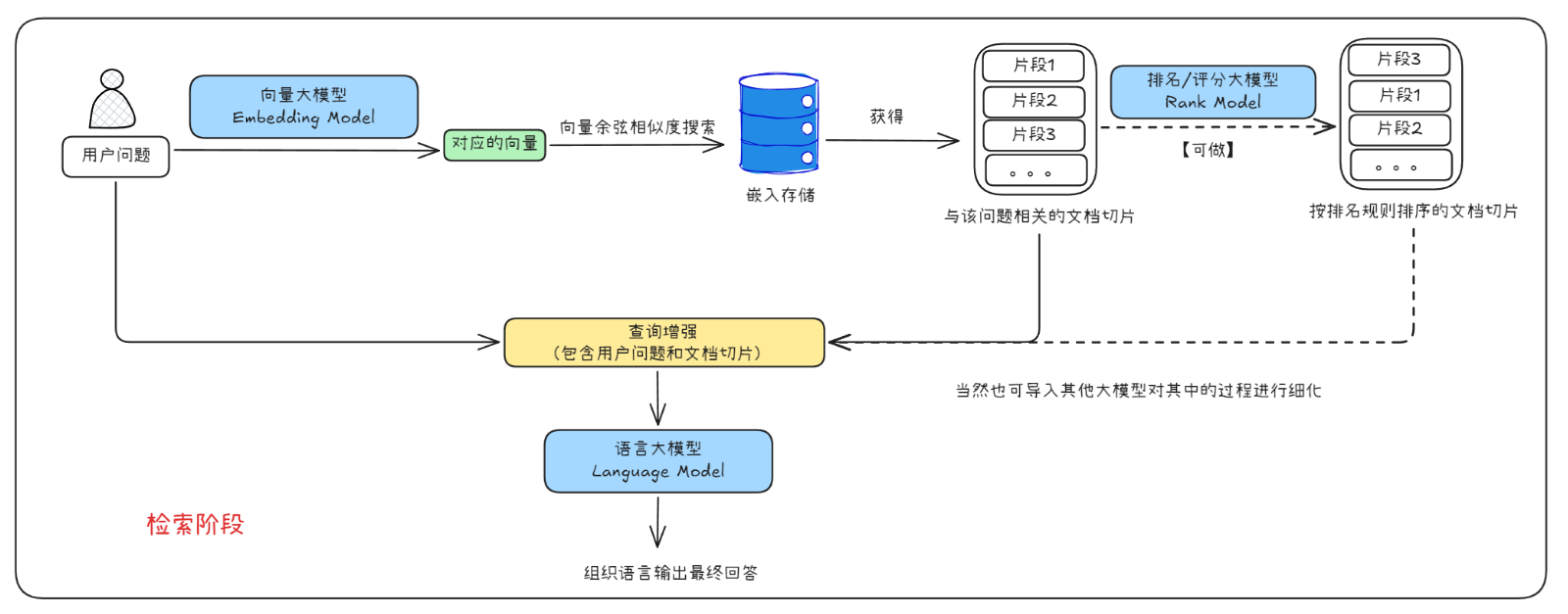
以上两个核心阶段主要涉及的组件有:
文档处理
- Document Loader:从 PDF、网页、数据库等加载原始数据(支持多种格式)
- Document Splitter:将大文档拆分为小片段(如按段落或句子),便于后续向量化
- Embedding Model:将文本转换为向量(如 OpenAI、Ollama、HuggingFace 等模型)
- Embedding Store:存储向量和文本片段,支持 Chroma、Pinecone、Milvus 等向量数据库
检索与生成
检索器(Retriever):根据用户查询从向量库中匹配相似文本片段
提示模板(Prompt Template):将检索结果与用户问题结合,生成 LLM 的输入提示
LLM 生成:调用大模型(如 GPT-4、Ollama)生成最终回答
5.3、RAG 的三个风格
LangChain4j 提供了三种 RAG 风格:
- Easy RAG:开始使用 RAG 的最简单方式
- Naive RAG:使用向量搜索的基本 RAG 实现
- Advanced RAG:一个模块化的 RAG 框架,允许额外的步骤,如 查询转换、从多个来源检索和重新排序
其中"Easy RAG"功能,使开始使用 RAG 变得尽可能简单,当然,这种"Easy RAG"的质量会低于定制的 RAG 设置。 然而,这是开始学习 RAG 和/或制作概念验证的最简单方法。 之后,你将能够平稳地从 Easy RAG 过渡到更高级的 RAG, 调整和定制更多方面。
以下以 Easy RAG 为例作为简单入门体验:
①、使用内存中的嵌入存储
重启后会出现会话记忆丢失
Ⅰ、引入依赖并准备文档
<!-- 导入 langchain4j-easy-rag 依赖 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-easy-rag</artifactId>
<version>1.0.0-beta3</version>
</dependency>
同时在资源路径(resources)下引入要处理的文档
Ⅱ、索引过程
将文档转换为向量表示并存储在内存中,为后续的语义搜索或问答系统做准备
@Configuration
public class CommonConfig {
// 注入 OpenAiChatModel (ChatLanguageModel 的实现) 实例
// 只有引入 langchain4j-open-ai-spring-boot-starter 依赖才会自动配置 OpenAiChatModel 实例
// langchain4j-spring-boot-starter 依赖不会自动配置 OpenAiChatModel 实例
@Autowired
private OpenAiChatModel chatModel;
// 注入自定义的 ChatMemoryStore
@Autowired
private RedisChatMemoryStore redisChatMemoryStore;
// 注入向量模型(需在配置文件中先配置好)
@Autowired
private EmbeddingModel embeddingModel;
// 引入 langchain4j-easy-rag 依赖会自动向容器中注入 EmbeddingStore 实例(名称为 embeddingStore)
// 以下是自定义内存嵌入存储的 EmbeddingStore 实例
@Bean
// 索引过程
// 将文档转换为向量表示并存储在内存中,为后续的语义搜索或问答系统做准备
// InMemoryEmbeddingStore<TextSegment> 是 EmbeddingStore 的实现类
public EmbeddingStore getEmbeddingStore() {
// 加载指定目录中的所有文件,每个 Document 代表一个加载的文件
List<Document> documents = FileSystemDocumentLoader.loadDocuments("/home/langchain4j/documentation");
// 创建两个内存中的嵌入存储实例(就是创建两个轻量级的向量数据库)
// InMemoryEmbeddingStore 是将文档向量(嵌入)存储在内存中的实现
// TextSegment 表示文档的分块/片段
InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
InMemoryEmbeddingStore<TextSegment> embeddingStore2 = new InMemoryEmbeddingStore<>();
// 配置嵌入模型,将文档转换为嵌入向量并存储到内存中的嵌入存储中
// 方法一:使用默认配置处理文档(直接将文档摄入到 embeddingStore 嵌入存储中)
EmbeddingStoreIngestor.ingest(documents, embeddingStore);
// 方法二:使用构建器模式创建自定义的 EmbeddingStoreIngestor
// 将文档转换为嵌入向量并存储到 embeddingStore2 嵌入存储中
EmbeddingStoreIngestor ingestor2 = EmbeddingStoreIngestor.builder()
.embeddingModel(embeddingModel) // 配置向量大模型
.embeddingStore(embeddingStore2)
.build();
ingestor2.ingest(documents);
return embeddingStore;
}
}
Ⅲ、检索过程
@Configuration
public class CommonConfig {
// 注入 OpenAiChatModel (ChatLanguageModel 的实现) 实例
// 只有引入 langchain4j-open-ai-spring-boot-starter 依赖才会自动配置 OpenAiChatModel 实例
// langchain4j-spring-boot-starter 依赖不会自动配置 OpenAiChatModel 实例
@Autowired
private OpenAiChatModel chatModel;
// 注入自定义的 ChatMemoryStore
@Autowired
private RedisChatMemoryStore redisChatMemoryStore;
// 自定义 ContentRetriever 实例
@Bean
// 检索过程
// 根据用户输入的查询文本,从内存中的嵌入存储中检索最相关的文档片段
public ContentRetriever getContentRetriever(EmbeddingStore embeddingStore) {
return EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore) // 配置嵌入存储,用于检索文档向量
.minScore(0.5) // 最小相似度阈值
.maxResults(5) // 最大返回结果数
.build();
}
}
②、使用其他嵌入存储
可以使用 LangChain4j 支持的 15+ 嵌入存储中的任何一个,下面以 redis 为例
Ⅰ、引入依赖并准备文档
<!-- 导入 langchain4j-easy-rag 依赖 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-easy-rag</artifactId>
<version>1.0.0-beta3</version>
</dependency>
<!-- redis 内部分量存储依赖 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-redis</artifactId>
<version>1.0.0-alpha1</version>
<scope>compile</scope>
</dependency>
同时在资源路径(resources)下引入要处理的文档
Ⅱ、索引过程
@Configuration
public class CommonConfig {
// 注入 OpenAiChatModel (ChatLanguageModel 的实现) 实例
// 只有引入 langchain4j-open-ai-spring-boot-starter 依赖才会自动配置 OpenAiChatModel 实例
// langchain4j-spring-boot-starter 依赖不会自动配置 OpenAiChatModel 实例
@Autowired
private OpenAiChatModel chatModel;
// 注入自定义的 ChatMemoryStore
@Autowired
private RedisChatMemoryStore redisChatMemoryStore;
// 注入向量模型(需在配置文件中先配置好)
@Autowired
private EmbeddingModel embeddingModel;
@Bean
// 自定义 Redis 嵌入存储实例
public EmbeddingStore<TextSegment> getRedisEmbeddingStore() {
// 加载指定目录中的所有文件,每个 Document 代表一个加载的文件
List<Document> documents = FileSystemDocumentLoader.loadDocuments("/home/langchain4j/documentation");
// 创建 Redis 嵌入存储
RedisEmbeddingStore redisEmbeddingStore = RedisEmbeddingStore.builder()
.host("redis-host") // 必填
.port(6379) // 必填
.indexName("my_index") // 必填
.dimension(1536) // 必填
.user("admin") // 可选
.password("password") // 可选
.prefix("prod:") // 可选
.metadataKeys(List.of("category")) // 可选
.build();
// 配置并执行文档摄入
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.embeddingModel(embeddingModel) // 配置向量大模型
.embeddingStore(redisEmbeddingStore)
.build();
ingestor.ingest(documents);
return redisEmbeddingStore;
}
}
| 参数名 | 类型 | 必填 | 说明 |
|---|---|---|---|
host |
String | 是 | Redis 服务器地址(如 "localhost" 或 "192.168.1.100") |
port |
Integer | 是 | Redis 服务端口(默认 6379) |
user |
String | 否 | Redis 用户名(Redis 6.0+ 的 ACL 功能需要) |
password |
String | 否 | Redis 认证密码 |
indexName |
String | 是 | 向量索引名称(用于区分不同业务场景的索引) |
prefix |
String | 否 | Redis key 的前缀(默认空,建议用于多租户隔离) |
dimension |
Integer | 是 | 向量维度(必须与嵌入模型输出维度一致,如 OpenAI text-embedding-3-small 是 1536) |
metadataKeys |
Collection | 否 | 需要存储的元数据字段名集合(用于过滤检索) |
5.4、总结rag的使用
①、配置依赖
<!-- 导入 langchain4j-easy-rag 依赖 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-easy-rag</artifactId>
<version>1.0.0-beta3</version>
</dependency>
<!-- 其他嵌入存储对应的依赖 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-其他嵌入存储 </artifactId>
<version>对应版本</version>
</dependency>
②、知识采集后进行加载和解析
一般是从互联网上或者是自己公司内部提供资料进行知识的采集,获取到的各种文本文件,大部分都是放在resources目录下,方便后续对文件的加载和解析——使用文档加载器和文档解析器
Ⅰ、文档加载器
// ①、使用文件系统加载器——FileSystemDocumentLoader
// 加载单个目录所有文件(自动识别格式)
List<Document> docs = FileSystemDocumentLoader.loadDocuments(
Paths.get("/data/docs"),
new TextDocumentParser() // 指定文本解析器
);
// 加载单个文件
Document pdfDoc = FileSystemDocumentLoader.loadDocument(
Paths.get("/data/report.pdf"),
new ApachePdfDocumentParser() // 指定使用 PDF解析器(需额外引入依赖)
);
// 加载绝对路径文件
Document pdfDoc = FileSystemDocumentLoader.loadDocument(
"E:\\java\\project\\data"
);
// ②、使用远程加载器——UrlDocumentLoader
// 从URL加载HTML
Document webDoc = UrlDocumentLoader.load(
"https://example.com",
new JsoupHtmlParser() // 指定使用 HTML解析器
);
// ③、使用数据库加载器——JdbcDocumentLoader等其他数据库加载器
// 从JDBC加载
JdbcDocumentLoader jdbcLoader = new JdbcDocumentLoader(
dataSource,
"SELECT title, content FROM articles",
row -> Document.from(row.getString("content"))
);
List<Document> dbDocs = jdbcLoader.load();
// ④、使用类路径加载器——ClassPathDocumentLoader
// 加载单个目录所有文件(自动识别格式)
List<Document> docs = ClassPathDocumentLoader.loadDocuments(
"content/data/docs"
);
Ⅱ、文档解析器
| 文件类型 | 解析器类 | 依赖 |
|---|---|---|
| TXT/CSV | TextDocumentParser |
内置 |
ApachePdfDocumentParser |
org.apache.pdfbox:pdfbox |
|
| Word | ApachePoiDocParser |
org.apache.poi:poi |
| HTML | JsoupHtmlParser |
org.jsoup:jsoup |
| Markdown | CommonMarkParser |
org.commonmark:commonmark |
③、文档分隔
对上一步采集到并加载解析后的知识文本进行分隔——使用文档分割器
由于与LLM交互的时候输入的文本对应的token长度是有限制的,输入过长的内容(如将所有相关的知识都作为输入),LLM会无响应或直接该报错,我们需要将知识文档进行拆分,存储到向量库
每次调用LLM时,先找出与提出的问题关联度最高的文档片段,作为参考的上下文输入给LLM。
④、创建嵌入存储实例
可自定义
⑤、文本向量化并存储到嵌入存储中
通过向量模型对文档进行处理(向量化),并将处理后的文档存入嵌入存储实例中
方法一:使用默认配置处理文档(直接将文档摄入到 embeddingStore 嵌入存储中)
方法二:使用构建器模式创建自定义的 EmbeddingStoreIngestor
⑥、索引
根据用户输入的查询文本,从内存中的嵌入存储中检索最相关的文档片段
- 可指定要使用的嵌入存储
- 可指定最大返回结果数
- 可指定最小相似度阈值
6、结构化输出
结构化输出(Structured Output) 可以让大语言模型(LLM)返回格式化的数据(如 JSON、Java 对象等),而非纯文本
如:假设我们有一个 Person 类:
record Person(String name, int age, double height, boolean married) {
}
我们的目标是从像这样的非结构化文本中提取 Person 对象:
John is 42 years old and lives an independent life.
He stands 1.75 meters tall and carries himself with confidence.
Currently unmarried, he enjoys the freedom to focus on his personal goals and interests.
目前,根据 LLM 和 LLM 提供商的不同,有三种方式可以实现这一目标 (从最可靠到最不可靠):
- JSON Schema
- 提示prompt + JSON 模式
- 提示prompt (默认使用)
6.1、JSON Schema 方式
核心思想:通过 JSON Schema 定义输出结构,让 LLM 严格按照 Schema 生成 JSON 数据。适用场景:需要严格约束输出格式(如 API 接口返回)。
①、步骤
- 定义 JSON Schema。
- 在 Prompt 中嵌入 Schema 描述。
- 解析 LLM 返回的 JSON。
②、代码示例
import dev.langchain4j.model.openai.OpenAiChatModel;
import com.fasterxml.jackson.databind.ObjectMapper;
public class JsonSchemaExample {
public static void main(String[] args) throws Exception {
OpenAiChatModel model = OpenAiChatModel.withApiKey("your-api-key");
// 1. 定义 JSON Schema
String schema = """
{
"type": "object",
"properties": {
"name": {"type": "string", "description": "书名"},
"author": {"type": "string", "description": "作者"},
"year": {"type": "integer", "description": "出版年份"}
},
"required": ["name", "author"]
}
""";
// 2. 构造 Prompt(明确要求返回 JSON)
String prompt = """
请生成一本科技类书籍的信息,严格遵循以下 JSON Schema 格式:
%s
用户请求:推荐一本关于人工智能的书籍。
""".formatted(schema);
// 3. 调用模型并解析 JSON
String jsonOutput = model.generate(prompt);
ObjectMapper mapper = new ObjectMapper();
Book book = mapper.readValue(jsonOutput, Book.class);
System.out.println(book);
}
// 定义 Java 类
record Book(String name, String author, Integer year) {}
}
③、输出示例
{
"name": "人工智能:现代方法",
"author": "Stuart Russell",
"year": 2020
}
6.2、Prompt + JSON 模式
核心思想:在 Prompt 中直接描述 JSON 结构,但不使用严格的 Schema,依赖 LLM 理解并生成 JSON。适用场景:需要灵活输出,但希望保持结构化。
①、代码示例
import dev.langchain4j.model.openai.OpenAiChatModel;
public class PromptWithJsonExample {
public static void main(String[] args) {
OpenAiChatModel model = OpenAiChatModel.withApiKey("your-api-key");
// 1. 在 Prompt 中明确要求 JSON 格式
String prompt = """
请返回以下信息的 JSON 格式数据:
- 书名(name)
- 作者(author)
- 出版年份(year)
用户请求:推荐一本关于量子计算的书籍。
""";
// 2. 调用模型并获取 JSON 输出
String jsonOutput = model.generate(prompt);
System.out.println(jsonOutput);
}
}
②、输出示例
{
"name": "量子计算与量子信息",
"author": "Michael Nielsen",
"year": 2010
}
6.3、纯 Prompt 默认方式
核心思想:仅通过自然语言描述需求,让 LLM 自由返回文本,再手动提取结构化数据。适用场景:对输出格式无严格要求,或需要 LLM 自由发挥。
①、代码示例
import dev.langchain4j.model.openai.OpenAiChatModel;
import java.util.regex.*;
public class DefaultPromptExample {
public static void main(String[] args) {
OpenAiChatModel model = OpenAiChatModel.withApiKey("your-api-key");
// 1. 使用自然语言 Prompt
String prompt = "推荐一本关于区块链的书籍,包含书名、作者和出版年份。";
// 2. 获取模型响应(非严格 JSON)
String response = model.generate(prompt);
System.out.println(response);
// 3. 手动提取数据(如正则匹配)
Pattern pattern = Pattern.compile("书名:《(.+?)》,作者:(.+?),出版年份:(\\d{4})");
Matcher matcher = pattern.matcher(response);
if (matcher.find()) {
String name = matcher.group(1);
String author = matcher.group(2);
int year = Integer.parseInt(matcher.group(3));
System.out.printf("解析结果:%s, %s, %d\n", name, author, year);
}
}
}
②、输出示例
推荐书籍:《区块链革命》,作者:Don Tapscott,出版年份:2016。
解析结果:区块链革命, Don Tapscott, 2016
6.4、方法对比
| 方法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| JSON Schema | 严格约束格式,易于解析 | 需预定义 Schema,灵活性低 | API 接口、数据管道 |
| Prompt + JSON | 灵活且结构化 | 依赖 LLM 理解 JSON 格式 | 需要半结构化输出的场景 |
| 纯 Prompt | 完全自由,LLM 发挥空间大 | 需手动解析,易出错 | 自然语言交互,非严格结构化 |
6.5、最佳实践建议
- 优先使用 JSON Schema:
- 当需要与下游系统(如数据库、API)交互时,用 Schema 确保数据一致性。
- 混合使用 Prompt + JSON:
- 在需要灵活性的场景下,通过 Prompt 引导 LLM 生成 JSON。
- 仅当必要时用纯 Prompt:
- 如果输出无需进一步处理,或允许自由文本响应(如聊天机器人)。
7、分类
分类对于将文本分类到预定义标签中至关重要,例如情感分析、意图检测和实体识别。
以下以情感分析分类为例:
情感分类系统将输入文本分类为以下情感类别之一:
- POSITIVE(积极)
- NEUTRAL(中性)
- NEGATIVE(消极)
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.model.openai.OpenAiChatModel;
import dev.langchain4j.service.AiServices;
import dev.langchain4j.service.UserMessage;
public class SentimentClassification {
// 使用 OpenAI 初始化聊天模型(利用自己的 apikey 初始化模型)
static ChatLanguageModel chatLanguageModel = OpenAiChatModel.withApiKey("YOUR_OPENAI_API_KEY");
// 定义情感枚举(积极、中性、消极)
enum Sentiment {
POSITIVE, NEUTRAL, NEGATIVE
}
// 定义 AI 驱动的情感分析器接口
interface SentimentAnalyzer {
@UserMessage("Analyze sentiment of {{it}}")
Sentiment analyzeSentimentOf(String text);
@UserMessage("Does {{it}} have a positive sentiment?")
boolean isPositive(String text);
}
public static void main(String[] args) {
// 创建 AI 驱动的情感分析器实例
SentimentAnalyzer sentimentAnalyzer = AiServices.create(SentimentAnalyzer.class, chatLanguageModel);
// 情感分析示例
Sentiment sentiment = sentimentAnalyzer.analyzeSentimentOf("I love this product!");
System.out.println(sentiment); // 预期输出: POSITIVE
boolean positive = sentimentAnalyzer.isPositive("This is a terrible experience.");
System.out.println(positive); // 预期输出: false
}
}
8、日志及可观测性
8.1、日志记录
①、纯java
可以通过在创建模型实例时设置 .logRequests(true) 和 .logResponses(true) 来启用对 LLM 的每个请求和响应的日志记录:
OpenAiChatModel.builder()
...
.logRequests(true)
.logResponses(true)
.build();
确保你的依赖中有一个 SLF4J 日志后端,例如 Logback:
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.5.8</version>
</dependency>
②、Spring Boot项目
直接在配置文件(properties/yaml均可)中设置即可
...
langchain4j.open-ai.chat-model.log-requests = true
langchain4j.open-ai.chat-model.log-responses = true
logging.level.dev.langchain4j = DEBUG
8.2、可观测性
①、ChatModelListener
用途:监听与大语言模型(LLM)交互过程中的事件,例如请求发送前、响应返回后、错误发生时的回调。适用于需要监控或干预模型交互流程的场景。
Ⅰ、核心事件方法:
onRequest():模型调用前触发,可修改请求参数。onResponse():成功获取模型响应后触发。onError():模型调用失败时触发。
Ⅱ、代码示例:
ChatModelListener listener = new ChatModelListener() {
@Override
public void onRequest(ChatModelRequest request) {
System.out.println("发送请求: " + request.messages());
}
@Override
public void onResponse(ChatModelResponse response) {
System.out.println("收到响应: " + response.content());
}
@Override
public void onError(Throwable error) {
System.err.println("调用失败: " + error.getMessage());
}
};
// 注册监听器到 ChatModel
ChatModel model = OpenAiChatModel.builder()
.apiKey("your-key")
.listener(listener) // 添加监听器
.build();
Ⅲ、典型使用场景:
- 日志记录(请求/响应日志)。
- 敏感信息过滤(在发送前修改请求内容)。
- 性能监控(统计请求耗时)。
②、ApplicationListener
用途:监听 Spring 应用的生命周期事件(如应用启动、关闭),属于 Spring Framework 的核心功能,与 LangChain4j 无直接关联,但常用于管理 AI 组件的初始化或清理。
Ⅰ、核心事件:
onApplicationEvent(ContextRefreshedEvent):应用上下文初始化完成时触发。onApplicationEvent(ContextClosedEvent):应用关闭时触发。
Ⅱ、代码示例:
import org.springframework.context.ApplicationListener;
import org.springframework.context.event.ContextRefreshedEvent;
@Component
public class MyAppListener implements ApplicationListener<ContextRefreshedEvent> {
@Override
public void onApplicationEvent(ContextRefreshedEvent event) {
// 应用启动后初始化向量数据库
VectorStoreInitializer.init();
System.out.println("应用已启动,RAG 组件加载完成!");
}
}
Ⅲ、典型使用场景:
- 初始化资源(如加载向量数据库、预缓存模型)。
- 优雅关闭(释放模型资源、保存临时数据)。
③、区别
| 特性 | ChatModelListener |
ApplicationListener |
|---|---|---|
| 所属框架 | LangChain4j 或 AI 模型 SDK | Spring Framework |
| 监听目标 | 模型交互流程(请求/响应) | 应用生命周期(启动/关闭) |
| 使用场景 | 日志、监控、请求干预 | 资源初始化、清理 |
| 注册方式 | 通过模型构建器(如 .listener()) |
Spring 组件注解(如 @Component) |
ApplicationListener 是体现 Spring Boot 应用程序中的可观测性
ChatModelListener 是体现更普遍的集成了 LangChain4j 或 AI 模型 SDK的应用程序中的可观测性
9、模型上下文协议 (MCP)
MCP(Model Context Protocol) 是由 Anthropic 提出并得到众多AI应用和模型提供商支持的开放协议。它的核心目标是标准化大型语言模型(LLM)与外部工具、数据源和服务之间的交互方式。
9.1、MCP 介绍
①、什么是 MCP
一个 MCP 服务(Server) 就是一个遵循 MCP 协议的程序,它负责:
- 封装能力:将特定的功能(如读取文件、查询数据库、调用 API)包装起来。
- 暴露接口:通过标准化的方式向 LLM 客户端(Client)描述自己有哪些能力(称为 Resources 和 Tools)。
- 处理请求:接收来自 LLM 客户端的请求,执行相应的操作,并返回结构化的结果。
②、为什么需要 MCP
在没有 MCP 之前,让 LLM 使用外部工具面临巨大挑战:
- 碎片化:每个模型、每个应用(如 LangChain, LlamaIndex)都有自己定义工具的方式,无法通用。
- 开发复杂:开发者需要为不同的模型和框架重复编写适配代码。
- 体验割裂:用户在不同的 AI 应用中无法使用自己统一的一套工具。
MCP 通过制定一个开放协议,完美解决了这些问题:
- 一次编写,到处使用:你编写一个 MCP 服务,可以在任何支持 MCP 的客户端(如 Claude Code, Cursor, Windy)中使用。
- 生态繁荣:开发者可以专注于编写好用的工具,而不必担心兼容性问题。
- 用户自主:用户可以自行寻找或开发 MCP 服务来扩展 AI 助手的能力,打造个人工作流。
③、MCP 核心概念
- Server(服务):提供工具和资源的后台程序。例如,一个
GitHub Server可以提供search_issues,create_pr等工具。 - Client(客户端):LLM 应用本身(如 Claude Code, Cursor)。它负责发现、调用 MCP 服务并管理会话。
- Tools(工具):可执行的操作。客户端可以调用工具,服务端执行并返回结果。例如:
search_web,execute_sql。 - Resources(资源):可读取的数据源。它们提供静态或动态的内容供 LLM 读取。例如:
file:///path/to/file.txt,https://api.example.com/feed。
9.2、使用
①、选择实现方式
MCP 支持两种通信方式:
- SSE (Server-Sent Events):基于 HTTP,服务作为一个 Web 服务器运行。更适合远程调用。
- STDIO (Standard Input/Output):基于标准输入输出,服务作为一个本地命令行程序运行。
②、创建 MCP 工具提供者
可去 MCP 服务市场查找
Ⅰ、创建MCP 传输实例
Ⅱ、创建MCP 客户端
Ⅲ、创建MCP 工具提供者
以上总体下来再注入到 spring 容器中即可
使用他人的服务可能需要去创建 apikey(按量收费),可能还需要使用到 apikey,这里就不进行演示了
@Configuration
public class McpConfig {
@Bean
public McpToolProvider mcpToolProvider() {
// 创建 MCP 传输实例
// STDIO 方式
McpTransport transport = new StdioMcpTransport.Builder()
.command(List.of("/usr/bin/npm", "exec", "@modelcontextprotocol/server-everything@0.6.2")) // 实际命令可见 MCP 市场
.logEvents(true) // 如果你想在日志中查看流量
.build();
// HTTP 方式
McpTransport transport = new HttpMcpTransport.Builder()
.sseUrl("http://localhost:3001/sse") // 实际命令可见 MCP 市场
.logRequests(true) // 如果你想在日志中查看流量
.logResponses(true)
.build();
// 创建 MCP 客户端
McpClient mcpClient = new DefaultMcpClient.Builder()
.transport(transport)
.build();
// 创建 MCP 工具提供者
ToolProvider toolProvider = McpToolProvider.builder()
.mcpClients(List.of(mcpClient))
.build();
return toolProvider;
}
}
③、应用
将工具提供者绑定到 AI 服务,只需使用 AI 服务构建器的 toolProvider 方法:
Bot bot = AiServices.builder(Bot.class)
.chatLanguageModel(model)
.toolProvider(toolProvider)
.build();

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 33
33 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)