LangChain4j简单入门
大模型可分为多种:文本处理大模型、音频处理大模型、图片处理大模型、向量处理大模型等等LangChain4j 是一个专为Java 开发者设计的开源框架,旨在简化大语言模型(LLM)在Java应用中的集成。它的目标类似于Python生态中的LangChain,但针对Java生态进行了优化,提供统一的API抽象、上下文管理(Memory)、提示模板、文档检索(RAG)等功能核心定位:让Java开发者无需
LangChain4j简单入门
本篇笔记是基于黑马老师的课程+LangChain4j官方文档进行简单学习的
【黑马程序员LangChain4j从入门到实战项目全套视频课程,涵盖LangChain4j+ollama+RAG,Java传统项目AI智能化升级】https://www.bilibili.com/video/BV1sDMqzpEQ3?p=13&vd_source=038c840243de6bb9f5de37ad9ebc0821
LangChain4j官方文档:https://docs.langchain4j.info/intro
一、大模型简介
大模型可分为多种:文本处理大模型、音频处理大模型、图片处理大模型、向量处理大模型等等
1、大模型部署
个人的大模型部署可主要分为:
- 本地部署(如:Ollama进行本地部署)
- 云服务器部署(借用类似阿里云百炼、硅基流动等云服务器厂商将大模型部署)
1.1、本地部署
以 Ollama(官网:https://ollama.com/) 为例:
-
选择 Windows/Mac/Linux 合适版本的 Ollama 进行下载
-
选择想要部署的大模型(该大模型又根据所需要资源对应不同的大小版本)
-
运行命令:ollama run < 要运行的版本>,如:ollama run qwen3-vl:2b
(如果未拉取过该大小版本的模型则进行首次拉取下载,若下载过则直接启动) -
进行对话**(以 curl 方式为例 )**
curl http://localhost:11434/api/chat -d '{ "model": "qwen3-vl:2b", "messages": [{ "role": "user", "content": "你是谁" }], "stream": false }'
具体可见官方文档:https://docs.ollama.com/
1.2、云服务器部署
以阿里云百炼为例:
-
开通阿里云百炼
-
获取 APIKEY(建议配置到环境变量中以防泄露)
-
选择大模型进行对话**(以 curl 方式为例 )**
不同地域的 Base URL 不通用(以下示例是北京地域 Base URL)
华北2(北京):
https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completionscurl -X POST https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions \ -H "Authorization: Bearer $DASHSCOPE_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "qwen-plus", "messages": [ { "role": "user", "content": "你是谁?" } ] }'
具体可见官方文档:https://bailian.console.aliyun.com/cn-beijing/?spm=5176.29597918.J_SEsSjsNv72yRuRFS2VknO.2.60e37b08A98n84&tab=doc#/doc
2、大模型调用
2.1、通用请求参数(Request Parameters)
①、基础参数
| 参数名 | 类型 | 必填 | 说明 | 示例值 |
|---|---|---|---|---|
model |
string | ✅ | 指定调用的模型名称 | qwen-max (通义千问) |
messages |
array | ✅ | 对话历史(多轮对话上下文) | [{role: "user", content: "你好"}] |
temperature |
float | ❌ | 生成多样性(0-2,越高越随机) | 0.8 |
max_tokens |
integer | ❌ | 生成的最大token数 | 1024 |
stream |
boolean | ❌ | 是否启用流式响应 | true |
enable_search |
boolean | ❌ | 是否启用联网搜索或知识库检索功能 | true |
messages 中的 role:
| 角色 (role) | 适用平台 | 说明 | 典型使用场景 |
|---|---|---|---|
user |
OpenAI, 阿里云, 百度文心等 | 表示用户输入的问题或指令 | 用户提问:"明天北京天气怎么样?" |
assistant |
OpenAI, 阿里云, 百度文心等 | 表示AI助手的回复内容 | AI回答:"北京明天晴,25-32℃。" |
system |
OpenAI, Claude等 | 系统级指令,用于设定AI行为(通常只在对话开头出现一次) | 设定身份:"你是一个专业的医疗助手" |
function |
OpenAI (Function Calling) | 标识函数调用的请求或结果 | 工具调用:{"name": "get_weather"} |
tool |
OpenAI (Tool Calls) | 新版工具调用角色(替代部分function场景) |
工具响应:{"tool_call_id": "123"} |
②、高级参数
| 参数名 | 类型 | 适用模型 | 说明 |
|---|---|---|---|
top_p |
float | 通用 | 核采样概率(0-1,与temperature二选一) |
stop |
array | 通用 | 停止词(遇到这些词停止生成) |
frequency_penalty |
float | OpenAI | 频率惩罚(-2.0~2.0,降低重复内容) |
presence_penalty |
float | OpenAI | 存在惩罚(-2.0~2.0,避免重复话题) |
seed |
integer | 部分模型 | 随机种子(用于结果复现) |
③、示例
curl http://localhost:11434/api/chat -d '{
"model": "qwen3-vl:2b",
"messages": [{
"role": "user",
"content": "你是谁"
}],
"stream": true
}'
- 使用的模型:qwen3-vl:2b
- 用户(user)发送的内容为:你是谁
- 是否启用流式响应:是——> 即每生成一部分就直接响应回复,而不是等所有内容生产完一次性响应回复
基础大模型没有记忆性,即本次回复需携带上一次问答内容才可协调回复,如:第一次用户单独询问清华大学是211吗,第一次大模型回复是,第二次用户单独询问是985吗,由于未携带第一次的问答大模型第二次回复是提示给出更详细的大学信息
curl -X POST https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions \
-H "Authorization: Bearer $DASHSCOPE_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "qwen-plus",
"messages": [
{
"role": "user",
"content": "清华大学是211吗?"
},{
"role": "assistant",
"content": "是。。。。。"
},{
"role": "user",
"content": "是985吗?"
}
]
}'
2.2、通用响应参数(Response Parameters)
①、关键参数
| 参数 | 说明 | 示例值 |
|---|---|---|
| id | 唯一请求标识符 | chatcmpl-xxx |
| object | 对象类型 | chat.completion / chat.completion.chunk |
| created | 创建时间戳(Unix时间) | 1718901234 |
| model | 使用的模型版本 | gpt-4o-2024-05-13 |
| choices | 生成结果数组(通常1个) | 包含消息内容的数组 |
| usage | Token使用量统计 | prompt/completion/total_tokens |
| system_fingerprint | 系统指纹(追踪模型配置) | fp_xxx |
Token 是大模型处理文本的最小单位
choices数组内部结构
| 参数 | 说明 |
|---|---|
| index | 选择项索引(0-based) |
| message/delta | 非流式用message,流式用delta |
| finish_reason | 停止原因:stop/length/content_filter/tool_calls |
| logprobs | 词元概率信息(可选) |
②、示例
{
"id": "chatcmpl-9vTCSx3x8K4vR2nQpL5mZ7yA1B2C3D4E",
"object": "chat.completion",
"created": 1718901234,
"model": "gpt-4o-2024-05-13",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "这是一个典型的AI助手回复示例。我可以回答问题、撰写内容、分析数据、编写代码等。",
"refusal": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 15,
"completion_tokens": 32,
"total_tokens": 47
},
"system_fingerprint": "fp_abc123def456"
}
二、 LangChain4j介绍
1、了解概述
LangChain4j 是一个专为 Java 开发者设计的开源框架,旨在简化大语言模型(LLM)在Java应用中的集成。它的目标类似于Python生态中的LangChain,但针对Java生态进行了优化,提供统一的API抽象、上下文管理(Memory)、提示模板、文档检索(RAG)等功能
- 核心定位:让Java开发者无需学习不同LLM提供商的专有API,快速构建智能应用(如聊天机器人、智能助手)。
- 开发背景:因Python生态的LangChain占据主流,而Java生态缺乏类似工具,LangChain4j于2023年诞生以填补这一空白。
| 框架 | 语言 | 官方生态 | 核心目标 |
|---|---|---|---|
| LangChain | Python | AI 原生生态(PyTorch/TensorFlow) | 为 Python 开发者提供灵活的 AI 链式编程工具 |
| LangChain4j | Java | Java 企业生态(Spring/Quarkus) | 让 Java 开发者也能使用 LangChain 的核心能力 |
简单来说就是适配 Java 版的 LangChain
2、对比传统项目
在 Spring Boot 项目中集成 LangChain4j 时,通常会将其功能嵌入到 Service 层,作为对传统数据库操作(Mapper/DAO)的增强,同时协调第三方 API(如 OpenAI)和向量数据库的操作。
- Controller 保持纯净,仅处理HTTP协议转换。
- Service 层 成为 “AI 调度中心”,协调传统数据库和 LangChain4j 功能。
- Mapper/DAO 仍负责结构化数据持久化,必要时与向量数据关联。
这种架构既保留了Spring Boot的分层优势,又无缝集成了AI能力。
| 层级 | 传统 Spring Boot 职责 | 集成 LangChain4j 后的变化 |
|---|---|---|
| Controller | 接收 HTTP 请求,返回响应 | 不变,仍处理 HTTP 交互 |
| Service | 业务逻辑,调用 Mapper 操作关系数据库 | 新增:调度 LangChain4j 的 LLM 和向量数据库操作(即在原有基础上增加 AI 功能) |
| Mapper/DAO | 操作 MySQL/PostgreSQL 等关系数据库 | 不变,但可能新增向量数据的关联查询 |
3、简单入门
在大模型部署中,两次示例都是通过curl 请求进行请求响应的,现在我们想要在 idea 中(第三方工具中)进行开发调用其大模型 API(以阿里云百炼的云服务器部署为例)
3.1、创建API 密钥
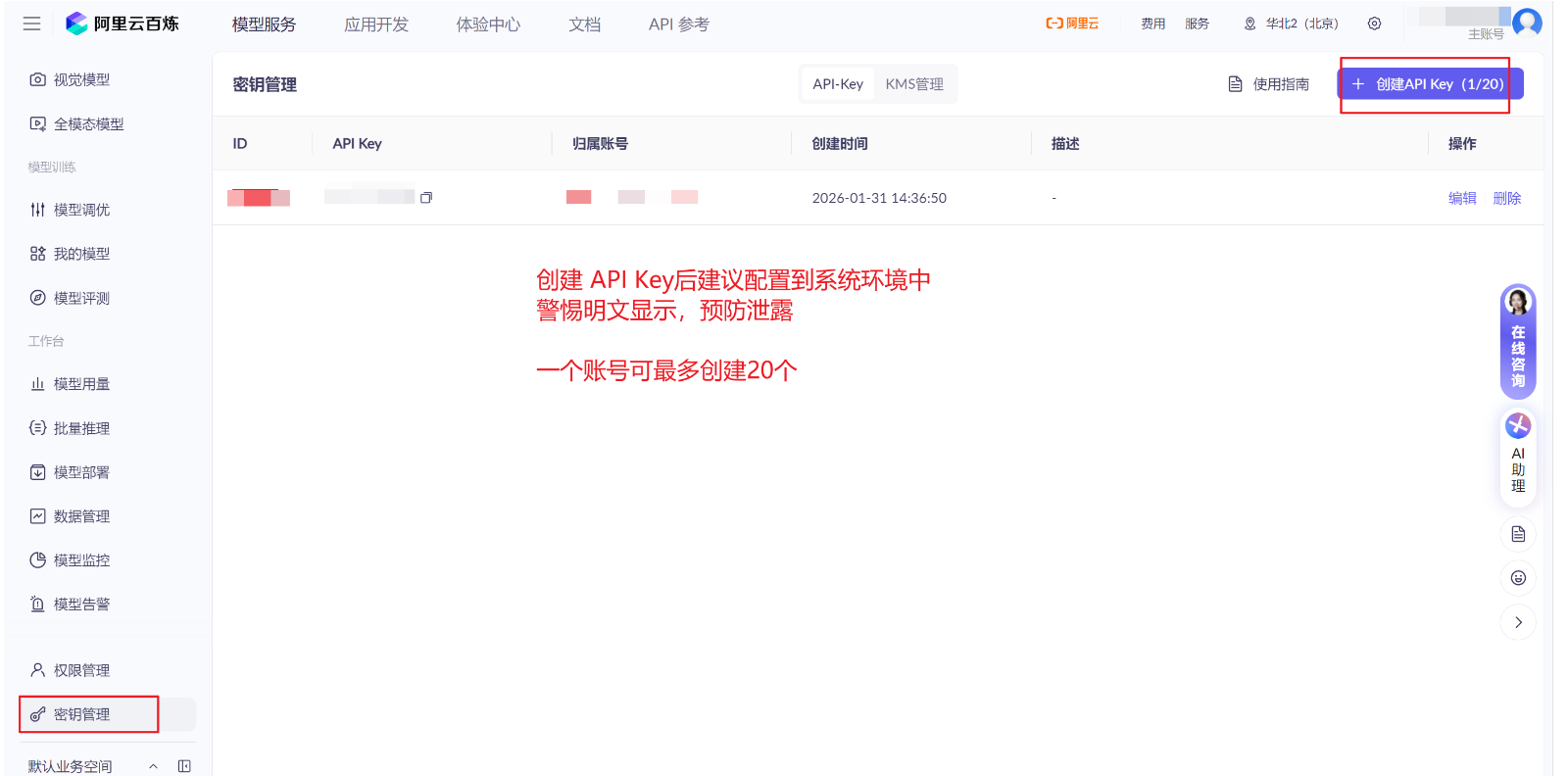
配置进系统的环境变量,预防泄露,警惕明文显示
- 在Windows系统桌面中按
Win+Q键,在搜索框中搜索编辑系统环境变量,单击打开系统属性界面。- 在系统属性窗口,单击环境变量,然后在系统变量区域下单击新建,变量名填入
DASHSCOPE_API_KEY,变量值填入您的DashScope API Key。
3.2、引入依赖坐标
①、DashScope Java SDK 依赖
此处选择了阿里云百炼的 SDK 工具库,当然也可选择 OpenAI 的 SDK
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>dashscope-sdk-java</artifactId>
<version>the-latest-version</version>
</dependency>
the-latest-version 替换为最新的合适版本号
②、LangChain4j 依赖
| 特性 | langchain4j-open-ai |
langchain4j-open-ai-spring-boot-starter |
langchain4j-spring-boot-starter |
|---|---|---|---|
| Spring Boot 支持 | ❌ 需手动配置 | ✅ 自动配置 | ✅ 自动配置(仅核心功能) |
| OpenAI 集成 | ✅ 核心 API 封装 | ✅ 封装 + 自动配置 | ❌ 需额外引入 langchain4j-open-ai |
| 配置方式 | 代码硬编码 | application.yml 或 Properties 文件 |
需手动添加模型提供商配置 |
| 依赖范围 | 单一 OpenAI 功能 | OpenAI + Spring Boot 自动化 | LangChain4j 核心 + Spring Boot 自动化 |
选择建议
- **纯 OpenAI 项目:**直接使用
langchain4j-open-ai-spring-boot-starter(最简洁)。- 定义:仅使用 OpenAI 提供的模型(如 GPT-4、GPT-3.5、DALL·E、Whisper 等)的项目。
- 技术栈
- 依赖:
langchain4j-open-ai-spring-boot-starter(或langchain4j-open-ai)。 - 配置:只需填写 OpenAI 的 API Key 和模型参数。
- 依赖:
- 多模型混合项目:组合
langchain4j-spring-boot-starter+langchain4j-open-ai(灵活)。- 定义:集成 多个厂商的大模型(如 OpenAI + DeepSeek + 本地模型),根据场景灵活调用不同模型。
- 技术栈
- 核心依赖:
langchain4j-spring-boot-starter(提供通用框架)。 - 按需添加:
langchain4j-open-ai(OpenAI)langchain4j-ollama(本地 Ollama 模型)langchain4j-huggingface(HuggingFace 模型)- 其他厂商适配模块(如未来的
langchain4j-deepseek)
- 核心依赖:
- 非 Spring Boot 项目:仅用
langchain4j-open-ai(轻量级)。
Ⅰ、OpenAI 基础集成
即非 Spring 的传统 Java 应用(如桌面应用、命令行工具),不使用 Spring Boot、Spring MVC 等 Spring 生态组件。
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
<version>1.0.0-beta3</version>
</dependency>
<!-- 如果您希望使用高级 AI 服务 API,还需要添加以下依赖项:-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>1.0.0-beta3</version>
</dependency>
Ⅱ、Spring Boot项目
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-spring-boot-starter</artifactId>
<version>1.0.0-beta3</version>
</dependency>
或者
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai-spring-boot-starter</artifactId>
<version>1.0.0-beta3</version>
</dependency>
详见LangChain4j 官方文档
3.3、创建实例进行chat测试
①、OpenAI 基础集成
需要自己手动创建一个 OpenAiChatModel 实例
OpenAiChatModel model = OpenAiChatModel.builder()
.apiKey(apiKey)
.modelName("gpt-4o-mini")
.build();
之后即可开始聊天:
String answer = model.chat("Say 'Hello World'");
System.out.println(answer); // Hello World
如果想看见大模型的日志:
Ⅰ、引入依赖
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.5.18</version>
</dependency>
Ⅱ、创建实例
OpenAiChatModel model = OpenAiChatModel.builder()
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
.apiKey(System.getenv("API-KEY"))
.modelName("qwen-plus")
.logRequests(true)
.logResponses(true)
.build();
- 通过
.logRequests(true)和.logResponses(true)开启请求和响应的日志记录(图中红框标注部分)
②、Spring Boot项目
可以在 application.properties 文件(也可改为 yaml 文件)中配置模型参数,如下所示:
langchain4j.open-ai.chat-model.api-key=${DASHSCOPE_API_KEY} # 从环境变量中获取 APIKEY
langchain4j.open-ai.chat-model.model-name=gpt-4o # 配置模型名称
langchain4j.open-ai.chat-model.log-requests=true # 开启请求日志
langchain4j.open-ai.chat-model.log-responses=true # 开启响应日志
...
# 以上是properties,以下是 yaml
langchain4j:
open-ai:
chat-model:
api-key: ${DASHSCOPE_API_KEY} # 从环境变量中获取 API 密钥
model-name: qwen-plus # 模型名称,即模型 Code
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1 # 模型 API 基础 URL
log-responses: true # 是否记录响应日志
log-requests: true # 是否记录请求日志
在这种情况下,将自动创建 OpenAiChatModel(ChatLanguageModel 的实现)的实例, 您可以在需要的地方自动装配它
(即已经自动创建和管理 OpenAiChatModel 到 AOC 容器中了,不需要显式使用 @Autowired 来注入它)::
@RestController
public class ChatController {
ChatLanguageModel chatLanguageModel;
public ChatController(ChatLanguageModel chatLanguageModel) {
this.chatLanguageModel = chatLanguageModel;
}
@GetMapping("/chat")
public String model(@RequestParam(value = "message", defaultValue = "Hello") String message) {
return chatLanguageModel.chat(message);
}
}
三、简单会话功能
1、AI Service
根据官方文档可见:其思想是将与 LLM 和其他组件交互的复杂性隐藏在简单的 API 后面。
用户以声明方式定义具有所需 API 的接口, 然后 LangChain4j 提供实现该接口的对象(代理)
| 维度 | 直接调用 ChatModel |
声明式 AI 服务 |
|---|---|---|
| 耦合性 | 高(直接依赖模型 API) | 低(通过接口抽象) |
| 功能扩展 | 需手动实现 | 内置记忆、工具调用、动态提示词等 |
| 代码复用 | 重复代码多 | 通过 AOP 统一增强 |
| 维护成本 | 高(改模型需修改业务代码) | 低(配置驱动) |
| 适用场景 | 简单测试、临时脚本 | 生产级应用、复杂交互场景 |
1.1、手动创建
①、确保正确引入依赖
<!-- 引入阿里云百炼的 Java SDK -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>dashscope-sdk-java</artifactId>
<version>2.22.4</version>
</dependency>
<!-- 引入 langchain4j-open-ai-spring-boot-starter 依赖 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai-spring-boot-starter</artifactId>
<version>1.0.0-beta3</version>
</dependency>
<!-- 引入 langchain4j-spring-boot-starter 依赖 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-spring-boot-starter</artifactId>
<version>1.0.0-beta3</version>
</dependency>
②、创建接口
public interface ConsultantService {
// ai 聊天
String chat(String question);
}
③、创建代理
package org.example.langchain4j.config;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.model.openai.OpenAiChatModel;
import dev.langchain4j.service.AiServices;
import org.example.langchain4j.aiservice.ConsultantService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class CommonConfig {
// 注入 OpenAiChatModel (ChatLanguageModel 的实现) 实例
// 只有引入 langchain4j-open-ai-spring-boot-starter 依赖才会自动配置 OpenAiChatModel 实例
// langchain4j-spring-boot-starter 依赖不会自动配置 OpenAiChatModel 实例
@Autowired
private OpenAiChatModel chatModel;
@Bean
public ConsultantService getConsultantService() {
// 使用 AiServices 抽象类创建 ConsultantService 的代理对象并注入到容器中
return AiServices.builder(ConsultantService.class)
.chatLanguageModel(chatModel)
.build();
}
}
④、调用测试
package org.example.langchain4j.controller;
import org.example.langchain4j.aiservice.ConsultantService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class ChatController {
@Autowired
private ConsultantService consultantService;
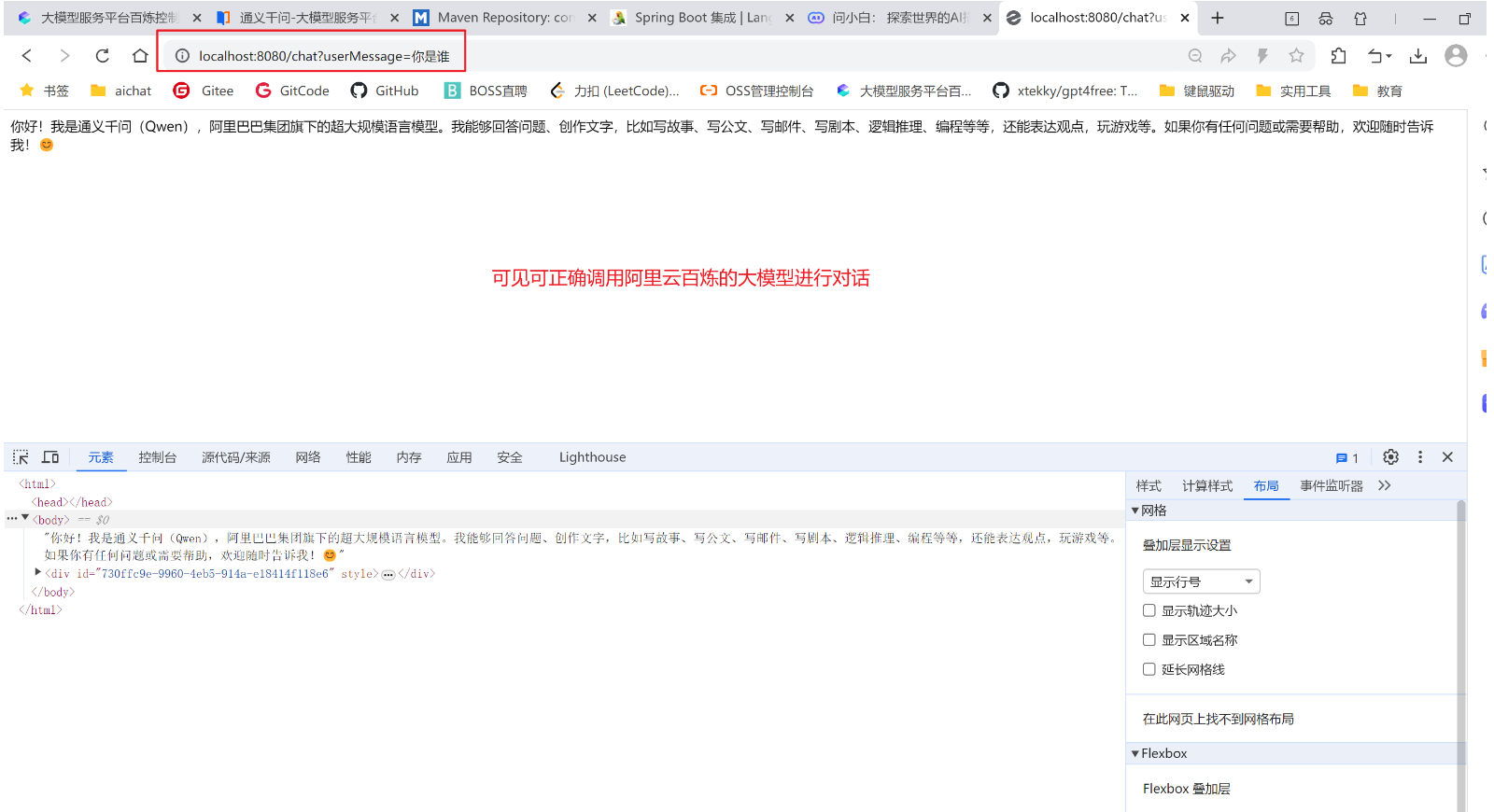
@RequestMapping("/chat")
public String consultant(String userMessage) {
return consultantService.chat(userMessage);
}
}
1.2、基于 @AiService 注解自动创建
@AiService 是 LangChain4j 框架中用于快速定义和绑定 AI 服务的核心注解,其参数主要用于控制模型绑定、装配模式及服务行为。
①、补充:注解常见参数
Ⅰ、wiringMode
- 作用:指定 AI 服务与
ChatModel的装配方式。 - 可选值
- AUTOMATIC(默认):自动从 Spring 容器中查找匹配的ChatModel或StreamingChatModel的Bean。若容器中仅有一个模型 Bean,无需额外配置
- EXPLICIT:手动指定模型名称(通过chatModel或streamingChatModel参数),适用于多模型混合项目
- 示例:
@AiService(wiringMode = AiServiceWiringMode.EXPLICIT, chatModel = "openAiChatModel")
public interface ConsultantService {
String chat(String message);
}
Ⅱ、chatModel / streamingChatModel
- 作用:显式绑定具体的模型 Bean 名称(需与
wiringMode = EXPLICIT配合使用)。 - 区别:
chatModel:绑定普通聊天模型(如OpenAiChatModel),用于同步调用。streamingChatModel:绑定流式模型(如OpenAiStreamingChatModel),支持逐字输出
- 示例:
@AiService(streamingChatModel = "openAiStreamingModel")
public interface StreamingService {
Flux<String> chatStream(String message);
}
Ⅲ、tools
- 作用:声明可被 AI 调用的外部工具类(需配合
@Tool注解使用),扩展模型能力(如计算、数据查询等) - 示例:
@AiService(tools = {MathTool.class, SearchTool.class})
public interface ToolService {
String solveProblem(String input);
}
Ⅳ、memoryId
- 作用:绑定对话记忆(
ChatMemory)的唯一标识,支持多轮会话上下文管理。可通过动态参数或固定值指定 - 示例:
@AiService(memoryId = "user_123") // 固定记忆 ID
public interface ChatWithMemory {
String chat(String input);
}
// 或动态指定
@AiService
public interface DynamicMemoryChat {
String chat(@MemoryId String userId, String input);
}
Ⅴ、modelName
- 作用:直接指定模型名称(如
gpt-4、qwen-plus),覆盖配置文件中定义的默认模型 - 示例:
@AiService(modelName = "qwen-max")
public interface CustomModelService {
String generate(String prompt);
}
| 参数 | 类型 | 说明 | 默认值 |
|---|---|---|---|
wiringMode |
AiServiceWiringMode |
组件绑定模式:AUTOMATIC(自动查找)或 EXPLICIT(显式指定) |
AUTOMATIC |
chatModel |
String |
显式模式下指定 ChatLanguageModel Bean 的名称 |
"" |
streamingChatModel |
String |
显式模式下指定 StreamingChatLanguageModel Bean 的名称 |
"" |
chatMemory |
String |
显式模式下指定 ChatMemory Bean 的名称 |
"" |
chatMemoryProvider |
String |
显式模式下指定 ChatMemoryProvider Bean 的名称 |
"" |
contentRetriever |
String |
显式模式下指定 ContentRetriever Bean 的名称(用于 RAG) |
"" |
retrievalAugmentor |
String |
显式模式下指定 RetrievalAugmentor Bean 的名称 |
"" |
moderationModel |
String |
显式模式下指定 ModerationModel Bean 的名称(内容审核) |
"" |
tools |
String[] |
显式模式下指定包含 @Tool 注解方法的 Bean 名称数组 |
{} |
②、创建接口并添加注解
@AiService // 此处是自动查找,也可开启手动指定
public interface ConsultantService {
// ai 聊天
String chat(String question);
}
可将其视为标准的 Spring Boot @Service,但具有 AI 功能。
③、调用测试
package org.example.langchain4j.controller;
import org.example.langchain4j.aiservice.ConsultantService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class ChatController {
@Autowired
private ConsultantService consultantService;
@RequestMapping("/chat")
public String consultant(String userMessage) {
return consultantService.chat(userMessage);
}
}
可见:通过 @AiService 注解实现声明式 AI 服务较简单,其省略了中间我们自己手动创建代理的过程,转而使用注解的形式简化调用
2、流式调用
流式调用(Streaming) 允许逐步获取 AI 模型的生成结果(如逐字或逐句返回),而非等待完整响应。
简单来说就是从原来的等大模型全部生成完一次性输出——>生成一点输出一点
| 对比项 | 普通调用(同步) | 流式调用(异步流) |
|---|---|---|
| 响应方式 | 一次性返回完整结果 | 逐步返回部分结果(如 SSE/WebFlux) |
| 延迟感知 | 用户需等待全部生成完成 | 用户可即时看到部分结果 |
| 适用场景 | 短文本、简单问答 | 长文本生成、实时交互 |
| 资源占用 | 内存中保存完整响应 | 按需处理分块数据,内存更高效 |
简单实现
①、引入依赖
<!-- 流式调用依赖①【spring boot项目独有】 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
<!-- 流式调用依赖② 【流式处理所需】 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-reactor</artifactId>
<version>1.0.1-beta6</version>
</dependency>
除以上两个依赖,还有spring boot启动器的依赖,这里默认已填
②、配置文件
langchain4j:
open-ai:
chat-model:
api-key: ${DASHSCOPE_API_KEY} # 从环境变量中获取 API 密钥
model-name: qwen-plus # 模型名称,即模型 Code
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1 # 模型 API 基础 URL
log-responses: true # 是否记录响应日志
log-requests: true # 是否记录请求日志
# 流式响应
streaming-chat-model:
api-key: ${DASHSCOPE_API_KEY} # 从环境变量中获取 API 密钥
model-name: qwen-plus # 模型名称,即模型 Code
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1 # 模型 API 基础 URL
log-responses: true # 是否记录响应日志
log-requests: true # 是否记录请求日志
③、显式装配组件并创建接口
注意此处选的 chatModel 的名字与你引入的 Spring Boot 的启动器依赖有关,下面以 OpenAI 为例,当然也可使用其他模型(如 HuggingFace、LocalAI):
- Bean 名称遵循类似规则(首字母小写),例如
huggingFaceChatModel
@AiService(
wiringMode = AiServiceWiringMode.EXPLICIT, // 显式注入模型
chatModel = "openAiChatModel", // 绑定普通模型组件
streamingChatModel = "openAiStreamingChatModel" // 绑定流式模型组件
)
public interface ConsultantService {
// ai 聊天(普通调用)
public String chat(String question);
// ai 聊天(流式调用)
public Flux<String> chatStreaming(String question);
}
④、controller层调用
package org.example.langchain4j.controller;
import org.example.langchain4j.aiservice.ConsultantService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
@RestController
public class ChatController {
@Autowired
private ConsultantService consultantService;
@RequestMapping("/chat")
public String consultant(String userMessage) {
return consultantService.chat(userMessage);
}
@RequestMapping(value = "/chatStreaming", produces = "text/html;charset=UTF-8")
public Flux<String> consultantStreaming(String userMessage) {
return consultantService.chatStreaming(userMessage);
}
}
若前端输出乱码,可指定 produces = “text/html;charset=UTF-8”,响应给前端的编码类型
3、信息注解
3.1、@SystemMessage
interface Friend {
@SystemMessage("You are a good friend of mine. Answer using slang.")
String chat(String userMessage);
}
Friend friend = AiServices.create(Friend.class, model);
String answer = friend.chat("Hello"); // 可能回答:Hey! What's up?
interface Doctor {
// 在资源路径(resources)下的 my-prompt-template.txt文件加载提示模板
@SystemMessage(fromResource = "my-prompt-template.txt")
String chat(String userMessage);
}
Doctor doctor = AiServices.create(Doctor.class, model);
String answer1 = doctor.chat("我感冒怎么办"); // 可能回答:可以喝99感冒灵。。。
String answer2 = doctor.chat("股票分析"); // 可能回答:抱歉我只回答医疗相关的问题。。。
可理解为:该注解可为 LLM 提供系统信息,包含但不限于为其设定身份/指定回答范围等等
3.2、@UserMessage
interface Friend {
// 指定了一个包含变量 it 的提示模板,该变量指的是唯一的方法参数(必须是 {{it}})
@UserMessage("You are a good friend of mine. Answer using slang. {{it}}")
String chat(String userMessage);
}
Friend friend = AiServices.create(Friend.class, model);
String answer = friend.chat("Hello"); // Hey! What's shakin'?
interface Friend {
// 也可以用 @V 注解 String userMessage, 并为提示模板变量分配自定义名称
@UserMessage("You are a good friend of mine. Answer using slang. {{message}}")
String chat(@V("message") String userMessage);
}
interface Friend {
// 也可指定资源路径(resources)下的 my-prompt-template.txt文件加载提示模板
@SystemMessage(fromResource = "my-prompt-template.txt")
String chat(String userMessage);
}
注意:在较新版本中的 LangChain4j中的 Spring Boot 项目可不使用 {{it}}指定唯一参数
以下是合法的使用方法
String chat(String userMessage);
String chat(@UserMessage String userMessage);
String chat(@UserMessage String userMessage, @V("country") String country); // userMessage 包含 "{{country}}" 模板变量
@UserMessage("What is the capital of Germany?")
String chat();
@UserMessage("What is the capital of {{it}}?")
String chat(String country);
@UserMessage("What is the capital of {{country}}?")
String chat(@V("country") String country);
@UserMessage("What is the {{something}} of {{country}}?")
String chat(@V("something") String something, @V("country") String country);
@UserMessage("What is the capital of {{country}}?")
String chat(String country); // 这仅在 Quarkus 和 Spring Boot 应用程序中有效
4、会话记忆
4.1、简单体验
①、创建会话记忆对象
目前,LangChain4j提供了2种开箱即用的实现:
- 较简单的一种,
MessageWindowChatMemory,作为滑动窗口运行, 保留最近的N条消息,并淘汰不再适合的旧消息。 然而,由于每条消息可能包含不同数量的令牌,MessageWindowChatMemory主要用于快速原型设计。 - 更复杂的选项是
TokenWindowChatMemory, 它也作为滑动窗口运行,但专注于保留最近的N个令牌, 根据需要淘汰旧消息。 消息是不可分割的。如果一条消息不适合,它会被完全淘汰。TokenWindowChatMemory需要一个Tokenizer来计算每个ChatMessage中的令牌数。
以下以 MessageWindowChatMemory 的实例对象为例:
@Configuration
public class CommonConfig {
// 注入 OpenAiChatModel (ChatLanguageModel 的实现) 实例
// 只有引入 langchain4j-open-ai-spring-boot-starter 依赖才会自动配置 OpenAiChatModel 实例
// langchain4j-spring-boot-starter 依赖不会自动配置 OpenAiChatModel 实例
@Autowired
private OpenAiChatModel chatModel;
@Bean
public ConsultantService getConsultantService() {
// 使用 AiServices 抽象类创建 ConsultantService 的代理对象并注入到容器中
return AiServices.builder(ConsultantService.class)
.chatLanguageModel(chatModel)
.build();
}
@Bean
// ChatMemory 类中含 id、add、messages、clear 方法
// id 方法是为了在多线程环境下,每个线程都有自己的 ChatMemory 实例,即记忆存储对象的唯一标识
// add 方法是为了将 ChatMessage 实例添加到记忆存储对象中
// messages 方法是为了获取记忆存储对象中的所有 ChatMessage 实例
// clear 方法是为了清空记忆存储对象中的所有 ChatMessage 实例
// 这里使用 MessageWindowChatMemory 实现类,最多存储 10 条消息
public ChatMemory getChatMemory() {
return MessageWindowChatMemory.builder()
.maxMessages(10)
.build();
}
}
②、配置会话记忆对象
@AiService(
wiringMode = AiServiceWiringMode.EXPLICIT, // 显式注入模型
chatModel = "openAiChatModel", // 绑定普通模型
streamingChatModel = "openAiStreamingChatModel", // 绑定流式模型
chatMemory = "getChatMemory" // 绑定内存
)
public interface ConsultantService {
// 。。。。。
}
4.2、会话记忆隔离
如果像简单体验中一样配置完了会话记忆对象,即使换个线程去再次进行访问会话,仍然会延续上一个线程的内容,即用户1进行完了对话,此时用户2开启新的会话,该会话仍然会基于用户1的会话内容进行延续,这显然是不合理的,没有做到会话记忆的隔离性(原先是共用一个会话记忆对象,现在为每个不同用户提供不同的对象)
为了解决这个问题,我们可以通过为会话记忆对象设置唯一 id,同时配置会话记忆对象的提供者
| 场景 | 是否自动隔离 | 原因 |
|---|---|---|
| 手动管理多个 ChatMemory 实例 | ✅ 是 | 每个实例独立存储消息。 |
| 未配置 ChatMemoryProvider 且单例注入 | ❌ 否 | 所有请求共享同一内存。 |
| 配置 ChatMemoryProvider | ✅ 是 | 根据 memoryId 动态隔离。 |
①、创建会话记忆提供者
@Configuration
public class CommonConfig {
// 注入 OpenAiChatModel (ChatLanguageModel 的实现) 实例
// 只有引入 langchain4j-open-ai-spring-boot-starter 依赖才会自动配置 OpenAiChatModel 实例
// langchain4j-spring-boot-starter 依赖不会自动配置 OpenAiChatModel 实例
@Autowired
private OpenAiChatModel chatModel;
@Bean
public ConsultantService getConsultantService() {
// 使用 AiServices 抽象类创建 ConsultantService 的代理对象并注入到容器中
return AiServices.builder(ConsultantService.class)
.chatLanguageModel(chatModel)
.build();
}
@Bean
// ChatMemory 类中含 id、add、messages、clear 方法
// id 方法是为了在多线程环境下,每个线程都有自己的 ChatMemory 实例,即记忆存储对象的唯一标识
// add 方法是为了将 ChatMessage 实例添加到记忆存储对象中
// messages 方法是为了获取记忆存储对象中的所有 ChatMessage 实例
// clear 方法是为了清空记忆存储对象中的所有 ChatMessage 实例
// 这里使用 MessageWindowChatMemory 实现类,最多存储 10 条消息
public ChatMemory getChatMemory() {
return MessageWindowChatMemory.builder()
.maxMessages(10)
.build();
}
@Bean
// 创建会话记忆提供者
public ChatMemoryProvider getChatMemoryProvider() {
return new ChatMemoryProvider() {
// 重写 ChatMemoryProvider 中的 get 方法
@Override
public ChatMemory get(Object memoryId) {
return MessageWindowChatMemory.builder()
.id(memoryId)
.maxMessages(10)
.build();
}
};
}
}
②、配置会话记忆提供者
@AiService(
wiringMode = AiServiceWiringMode.EXPLICIT, // 显式注入模型
chatModel = "openAiChatModel", // 绑定普通模型
streamingChatModel = "openAiStreamingChatModel", // 绑定流式模型
// chatMemory = "getChatMemory" // 配置会话记忆公共对象
chatMemoryProvider = "getChatMemoryProvider" // 配置带有唯一 id 的会话记忆对象
)
public interface ConsultantService {
// 带唯一 id 的聊天
@SystemMessage("你是一个医疗助手")
public Flux<String> chatStreamingWithId(
@MemoryId String memoryId, // 需要使用 @MemoryId 标注唯一id
@UserMessage String question // 多个参数需要使用 @UserMessage 标注用户信息
);
}
③、controller层调用
@RestController
public class ChatController {
@Autowired
private ConsultantService consultantService;
@RequestMapping(value = "/chatStreamingWithId", produces = "text/html;charset=UTF-8")
public Flux<String> consultantStreamingWithId(String memoryId,String userMessage) {
return consultantService.chatStreamingWithId(memoryId,userMessage);
}
}
4.3、会话记忆持久化
当后端维护人员重启后端,用户原有的会话丢失,这是由于默认情况下,ChatMemory(底部两个实现:MessageWindowChatMemory、TokenWindowChatMemory)实现在服务器内存中存储ChatMessage,这就导致每次服务器的重启,其内存信息会丢失,进而导致用户会话记忆丢失。
如果需要持久化,可以实现自定义的ChatMemoryStore, 将ChatMessage存储在您选择的任何持久化存储中
class PersistentChatMemoryStore implements ChatMemoryStore {
@Override
public List<ChatMessage> getMessages(Object memoryId) {
// TODO: 实现通过内存ID从持久化存储中获取所有消息。
// 可以使用ChatMessageDeserializer.messageFromJson(String)和
// ChatMessageDeserializer.messagesFromJson(String)辅助方法
// 轻松地从JSON反序列化聊天消息。
}
@Override
public void updateMessages(Object memoryId, List<ChatMessage> messages) {
// TODO: 实现通过内存ID更新持久化存储中的所有消息。
// 可以使用ChatMessageSerializer.messageToJson(ChatMessage)和
// ChatMessageSerializer.messagesToJson(List<ChatMessage>)辅助方法
// 轻松地将聊天消息序列化为JSON。
}
@Override
public void deleteMessages(Object memoryId) {
// TODO: 实现通过内存ID删除持久化存储中的所有消息。
}
}
public ChatMemory getMyChatMemory() {
return MessageWindowChatMemory.builder()
.id("12345")
.maxMessages(10)
.chatMemoryStore(new PersistentChatMemoryStore())
.build();
}
以下以 redis 为例(docker等配置redis自行了解,这里不多赘述):
①、配置并连接好redis
<!-- 引入 redis 依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
spring:
application:
name: langchain4j
data:
redis:
host: localhost
port: 6379
database: 3
②、创建自定义ChatMemoryStore
该自定义类要实现ChatMemoryStore接口
@Repository
public class RedisChatMemoryStore implements ChatMemoryStore {
@Autowired
private StringRedisTemplate redisTemplate;
@Override
public List<ChatMessage> getMessages(Object memoryId) {
// 从 redis 中获取会话信息
String json = (String) redisTemplate.opsForValue().get(memoryId);
// 把 json 转为 List<ChatMessage>
List<ChatMessage> list = ChatMessageDeserializer.messagesFromJson(json);
return list;
}
@Override
public void updateMessages(Object memoryId, List<ChatMessage> list) {
// 将 list 转换为 json 格式
String json = ChatMessageSerializer.messagesToJson(list);
// 把 json 存到 redis 中(最好设置 TTL,避免会话内容永久存在)
redisTemplate.opsForValue().set(memoryId.toString(),json, Duration.ofDays(1));
}
@Override
public void deleteMessages(Object memoryId) {
// 删除内容
redisTemplate.delete(memoryId.toString());
}
}
③、使用自定义ChatMemoryStore
@Configuration
public class CommonConfig {
// 注入 OpenAiChatModel (ChatLanguageModel 的实现) 实例
// 只有引入 langchain4j-open-ai-spring-boot-starter 依赖才会自动配置 OpenAiChatModel 实例
// langchain4j-spring-boot-starter 依赖不会自动配置 OpenAiChatModel 实例
@Autowired
private OpenAiChatModel chatModel;
// 注入自定义的 ChatMemoryStore
@Autowired
private RedisChatMemoryStore redisChatMemoryStore;
@Bean
// 创建会话记忆提供者
public ChatMemoryProvider getMyChatMemoryProvider() {
return new ChatMemoryProvider() {
// 重写 ChatMemoryProvider 中的 get 方法
@Override
public ChatMemory get(Object memoryId) {
return MessageWindowChatMemory.builder()
.id(memoryId)
.maxMessages(10)
.chatMemoryStore(redisChatMemoryStore) // 配置自定义的 ChatMemoryStore
.build();
}
};
}
}
④、配置自定义ChatMemoryStore
@AiService(
wiringMode = AiServiceWiringMode.EXPLICIT, // 显式注入模型
chatModel = "openAiChatModel", // 绑定普通模型
streamingChatModel = "openAiStreamingChatModel", // 绑定流式模型
// chatMemory = "getChatMemory" // 配置会话记忆公共对象
// chatMemoryProvider = "getChatMemoryProvider" // 配置带有唯一 id 的会话记忆对象
chatMemoryProvider = "getMyChatMemoryProvider" // 配置带有自定义的 ChatMemoryStore类的会话记忆提供者
)
public interface ConsultantService {
// 带自定义的 ChatMemoryStore类和唯一 id 的聊天
@SystemMessage("你是一个医疗助手")
public Flux<String> chatStreamingWithIdAndR(
@MemoryId String memoryId, // 需要使用 @MemoryId 标注唯一id
@UserMessage String question // 多个参数需要使用 @UserMessage 标注用户信息
);
}
⑤、controller层调用
@RestController
public class ChatController {
@Autowired
private ConsultantService consultantService;
@RequestMapping(value = "/chatStreamingWithIdAndR", produces = "text/html;charset=UTF-8")
public Flux<String> consultantStreamingWithIdAndR(String memoryId,String userMessage) {
return consultantService.chatStreamingWithIdAndR(memoryId,userMessage);
}
}
四、简单了解RAG 知识库
LLM 的知识仅限于它已经训练过的数据,即在不联网搜索的情况下,LLM 的认知停留在最后一次训练时,其所含知识只有训练过的数据。 如果你想让 LLM 了解特定领域的知识或专有数据,你可以:
- 使用 RAG
- 用你的数据微调 LLM
- 结合 RAG 和微调
1、什么是 RAG
简单来说,RAG 是一种在发送给 LLM 之前,从你的数据中找到并注入相关信息片段到提示中的方法。 这样 LLM 将获得(希望是)相关信息,并能够使用这些信息回复, 这应该会降低产生幻觉的概率。
相关信息片段可以使用各种信息检索方法找到。 最流行的方法有:
- 全文(关键词)搜索。这种方法使用 TF-IDF 和 BM25 等技术, 通过匹配查询(例如,用户提问的内容)中的关键词与文档数据库进行搜索。 它根据每个文档中这些关键词的频率和相关性对结果进行排名。
- 向量搜索,也称为"语义搜索"。 文本文档使用嵌入模型转换为数字向量。 然后根据查询向量和文档向量之间的余弦相似度 或其他相似度/距离度量找到并排序文档, 从而捕捉更深层次的语义含义。
- 混合搜索。结合多种搜索方法(例如,全文 + 向量)通常可以提高搜索的有效性。
目前,本页主要关注向量搜索。 全文和混合搜索目前仅由 Azure AI Search 集成支持, 详情请参阅 AzureAiSearchContentRetriever。 我们计划在不久的将来扩展 RAG 工具箱,包括全文和混合搜索。
2、RAG 阶段
2.1、补充:向量余弦相似度
即两个向量夹角的余弦值,余弦值(cos)越大,两个向量越接近,相似度越高,对应的数据相似度也越高
我们可以利用这一特性进行数据的搜索筛选,比如我们的向量数据库中有:“我爱学习”、“我今天吃饭了”、“我爱打篮球“、”我爱学习英文”,我们现在要搜索的是【目标数据】:“我爱学习中文”,则每个向量数据和【目标数据】之间都会存在向量夹角,该夹角的余弦越大,数据越接近。
“我爱学习”【0.6】、“我今天吃饭了”【0.3】、“我爱打篮球“【0.2】、”我爱学习英文”【0.8】,这时候规定搜索的数据其向量余弦相似度要> 0.5,于是可筛选出“我爱学习”、”我爱学习英文”两个数据
简单来说就是相关性
2.2、索引
索引阶段可简单认为是对文档的预处理,以方便后续检索
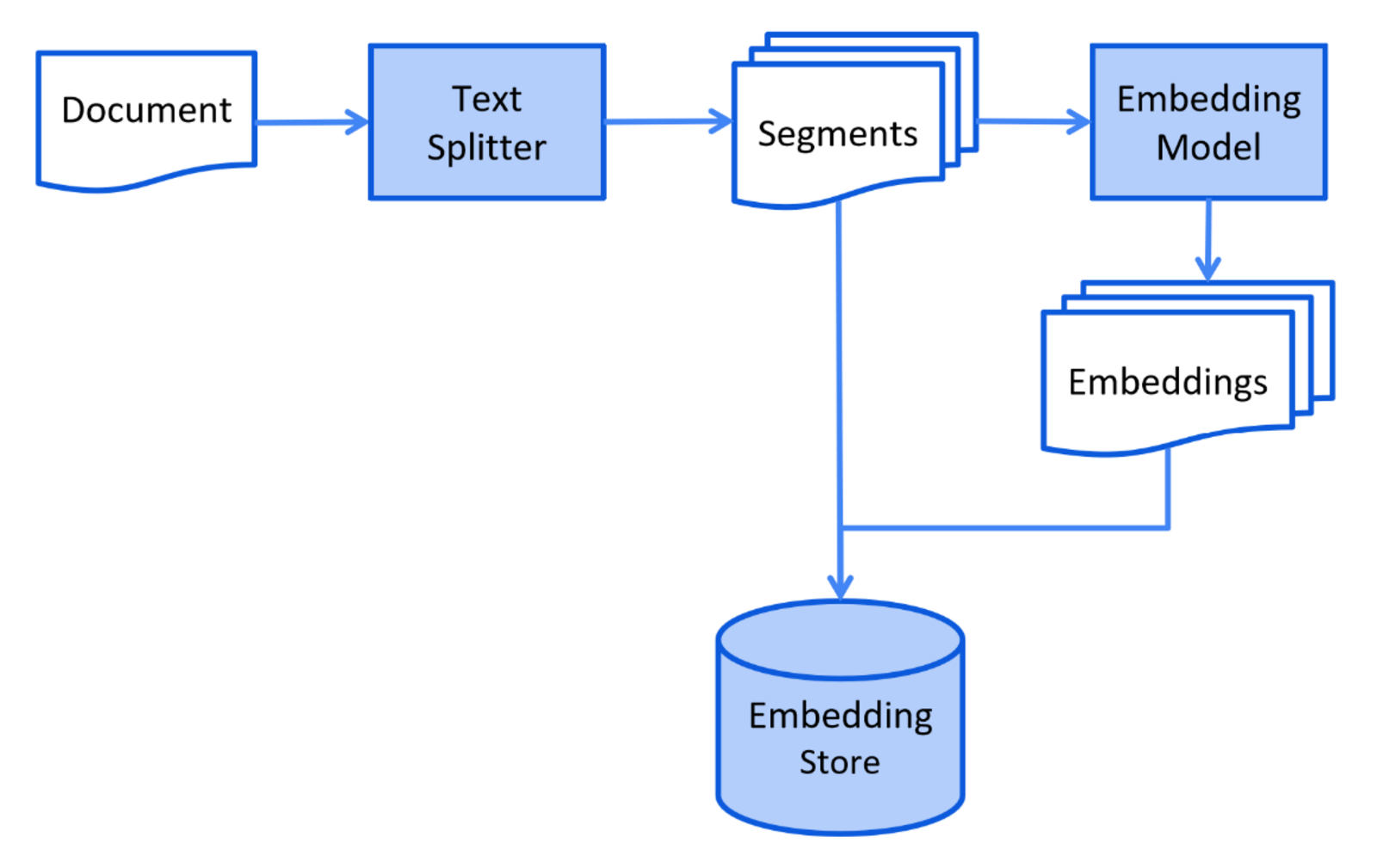
根据以上LangChain4j官方提供的索引阶段的简化图表可知:
- 一个文档先被分块——> 生成多个片段
- 片段交由向量大模型处理——> 生成对应的向量
- 将片段和对应的向量一起存储在向量数据库中
索引阶段通常是离线进行的,这意味着最终用户不需要等待其完成。 例如,可以通过定时任务在周末每周重新索引一次公司内部文档来实现。 负责索引的代码也可以是一个单独的应用程序,只处理索引任务。
然而,在某些情况下,最终用户可能希望上传自己的自定义文档,使 LLM 能够访问这些文档。 在这种情况下,索引应该在线进行,并成为主应用程序的一部分。
2.3、检索
检索阶段可认为是当用户提交一个应该使用索引文档回答的问题时进行
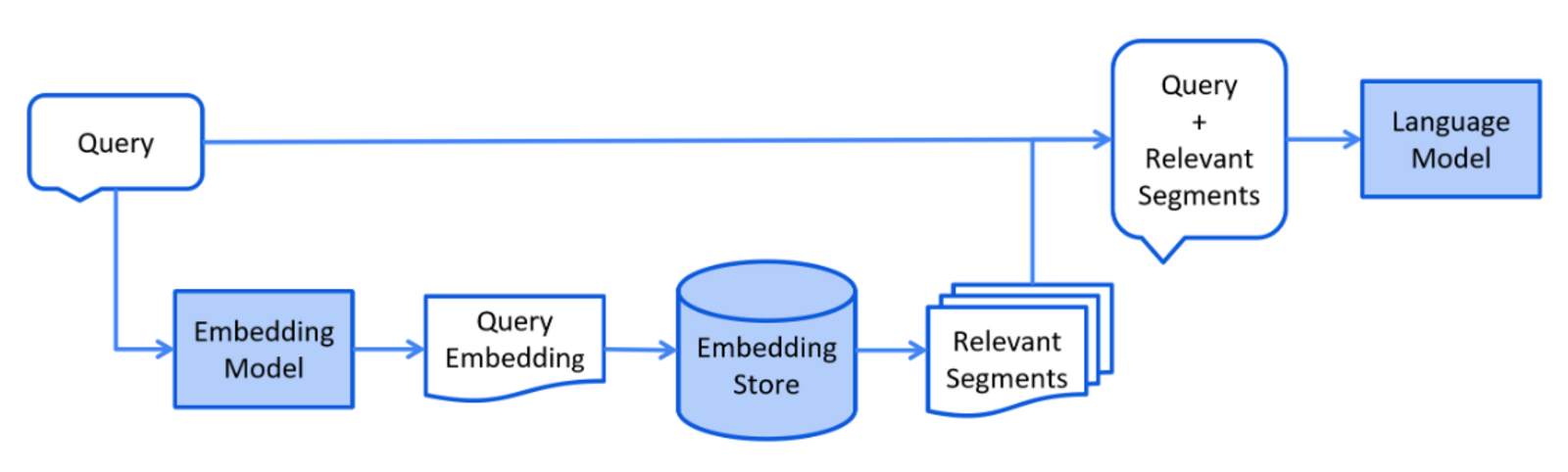
根据以上LangChain4j官方提供的检索阶段的简化图表可知:
- 一个问题请求交由向量大模型处理——> 生成多个问题片段
- 多个问题片段去向量数据库中检索——> 找到符合的答案片段
- 将问题片段和符合的答案片段一起交由语言大模型组织回应
3、简单入门
LangChain4j 提供了三种 RAG 风格:
- Easy RAG:开始使用 RAG 的最简单方式
- Naive RAG:使用向量搜索的基本 RAG 实现
- Advanced RAG:一个模块化的 RAG 框架,允许额外的步骤,如 查询转换、从多个来源检索和重新排序
其中"Easy RAG"功能,使开始使用 RAG 变得尽可能简单,当然,这种"Easy RAG"的质量会低于定制的 RAG 设置。 然而,这是开始学习 RAG 和/或制作概念验证的最简单方法。 之后,你将能够平稳地从 Easy RAG 过渡到更高级的 RAG, 调整和定制更多方面。
以下以 Easy RAG 为例作为简单入门体验:
3.1、使用内存中的嵌入存储
重启后会出现会话记忆丢失
①、引入依赖并准备文档
<!-- 导入 langchain4j-easy-rag 依赖 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-easy-rag</artifactId>
<version>1.0.0-beta3</version>
</dependency>
同时在资源路径(resources)下引入要处理的文档
②、索引过程
将文档转换为向量表示并存储在内存中,为后续的语义搜索或问答系统做准备
@Configuration
public class CommonConfig {
// 注入 OpenAiChatModel (ChatLanguageModel 的实现) 实例
// 只有引入 langchain4j-open-ai-spring-boot-starter 依赖才会自动配置 OpenAiChatModel 实例
// langchain4j-spring-boot-starter 依赖不会自动配置 OpenAiChatModel 实例
@Autowired
private OpenAiChatModel chatModel;
// 注入自定义的 ChatMemoryStore
@Autowired
private RedisChatMemoryStore redisChatMemoryStore;
// 注入向量模型(需在配置文件中先配置好)
@Autowired
private EmbeddingModel embeddingModel;
// 引入 langchain4j-easy-rag 依赖会自动向容器中注入 EmbeddingStore 实例(名称为 embeddingStore)
// 以下是自定义内存嵌入存储的 EmbeddingStore 实例
@Bean
// 索引过程
// 将文档转换为向量表示并存储在内存中,为后续的语义搜索或问答系统做准备
// InMemoryEmbeddingStore<TextSegment> 是 EmbeddingStore 的实现类
public EmbeddingStore getEmbeddingStore() {
// 加载指定目录中的所有文件,每个 Document 代表一个加载的文件
List<Document> documents = FileSystemDocumentLoader.loadDocuments("/home/langchain4j/documentation");
// 创建两个内存中的嵌入存储实例(就是创建两个轻量级的向量数据库)
// InMemoryEmbeddingStore 是将文档向量(嵌入)存储在内存中的实现
// TextSegment 表示文档的分块/片段
InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
InMemoryEmbeddingStore<TextSegment> embeddingStore2 = new InMemoryEmbeddingStore<>();
// 配置嵌入模型,将文档转换为嵌入向量并存储到内存中的嵌入存储中
// 方法一:使用默认配置处理文档(直接将文档摄入到 embeddingStore 嵌入存储中)
EmbeddingStoreIngestor.ingest(documents, embeddingStore);
// 方法二:使用构建器模式创建自定义的 EmbeddingStoreIngestor
// 将文档转换为嵌入向量并存储到 embeddingStore2 嵌入存储中
EmbeddingStoreIngestor ingestor2 = EmbeddingStoreIngestor.builder()
.embeddingModel(embeddingModel) // 配置向量大模型
.embeddingStore(embeddingStore2)
.build();
ingestor2.ingest(documents);
return embeddingStore;
}
}
③、检索过程
@Configuration
public class CommonConfig {
// 注入 OpenAiChatModel (ChatLanguageModel 的实现) 实例
// 只有引入 langchain4j-open-ai-spring-boot-starter 依赖才会自动配置 OpenAiChatModel 实例
// langchain4j-spring-boot-starter 依赖不会自动配置 OpenAiChatModel 实例
@Autowired
private OpenAiChatModel chatModel;
// 注入自定义的 ChatMemoryStore
@Autowired
private RedisChatMemoryStore redisChatMemoryStore;
// 自定义 ContentRetriever 实例
@Bean
// 检索过程
// 根据用户输入的查询文本,从内存中的嵌入存储中检索最相关的文档片段
public ContentRetriever getContentRetriever(EmbeddingStore embeddingStore) {
return EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore) // 配置嵌入存储,用于检索文档向量
.minScore(0.5) // 最小相似度阈值
.maxResults(5) // 最大返回结果数
.build();
}
}
3.2、使用其他嵌入存储
可以使用 LangChain4j 支持的 15+ 嵌入存储中的任何一个,下面以 redis 为例
①、引入依赖并准备文档
<!-- 导入 langchain4j-easy-rag 依赖 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-easy-rag</artifactId>
<version>1.0.0-beta3</version>
</dependency>
<!-- redis 内部分量存储依赖 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-redis</artifactId>
<version>1.0.0-alpha1</version>
<scope>compile</scope>
</dependency>
同时在资源路径(resources)下引入要处理的文档
②、索引过程
@Configuration
public class CommonConfig {
// 注入 OpenAiChatModel (ChatLanguageModel 的实现) 实例
// 只有引入 langchain4j-open-ai-spring-boot-starter 依赖才会自动配置 OpenAiChatModel 实例
// langchain4j-spring-boot-starter 依赖不会自动配置 OpenAiChatModel 实例
@Autowired
private OpenAiChatModel chatModel;
// 注入自定义的 ChatMemoryStore
@Autowired
private RedisChatMemoryStore redisChatMemoryStore;
// 注入向量模型(需在配置文件中先配置好)
@Autowired
private EmbeddingModel embeddingModel;
@Bean
// 自定义 Redis 嵌入存储实例
public EmbeddingStore<TextSegment> getRedisEmbeddingStore() {
// 加载指定目录中的所有文件,每个 Document 代表一个加载的文件
List<Document> documents = FileSystemDocumentLoader.loadDocuments("/home/langchain4j/documentation");
// 创建 Redis 嵌入存储
RedisEmbeddingStore redisEmbeddingStore = RedisEmbeddingStore.builder()
.host("redis-host") // 必填
.port(6379) // 必填
.indexName("my_index") // 必填
.dimension(1536) // 必填
.user("admin") // 可选
.password("password") // 可选
.prefix("prod:") // 可选
.metadataKeys(List.of("category")) // 可选
.build();
// 配置并执行文档摄入
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.embeddingModel(embeddingModel) // 配置向量大模型
.embeddingStore(redisEmbeddingStore)
.build();
ingestor.ingest(documents);
return redisEmbeddingStore;
}
}
| 参数名 | 类型 | 必填 | 说明 |
|---|---|---|---|
host |
String | 是 | Redis 服务器地址(如 "localhost" 或 "192.168.1.100") |
port |
Integer | 是 | Redis 服务端口(默认 6379) |
user |
String | 否 | Redis 用户名(Redis 6.0+ 的 ACL 功能需要) |
password |
String | 否 | Redis 认证密码 |
indexName |
String | 是 | 向量索引名称(用于区分不同业务场景的索引) |
prefix |
String | 否 | Redis key 的前缀(默认空,建议用于多租户隔离) |
dimension |
Integer | 是 | 向量维度(必须与嵌入模型输出维度一致,如 OpenAI text-embedding-3-small 是 1536) |
metadataKeys |
Collection | 否 | 需要存储的元数据字段名集合(用于过滤检索) |
4、部分核心API
4.1、文档加载器
①、文件系统加载器(最常用)
// 加载单个目录所有文件(自动识别格式)
List<Document> docs = FileSystemDocumentLoader.loadDocuments(
Paths.get("/data/docs"),
new TextDocumentParser() // 指定文本解析器
);
// 加载单个文件
Document pdfDoc = FileSystemDocumentLoader.loadDocument(
Paths.get("/data/report.pdf"),
new ApachePdfDocumentParser() // 指定使用 PDF解析器(需额外引入依赖)
);
// 加载绝对路径文件
Document pdfDoc = FileSystemDocumentLoader.loadDocument(
"E:\\java\\project\\data"
);
②、远程加载器
// 从URL加载HTML
Document webDoc = UrlDocumentLoader.load(
"https://example.com",
new JsoupHtmlParser() // 指定使用 HTML解析器
);
③、数据库加载器
// 从JDBC加载
JdbcDocumentLoader jdbcLoader = new JdbcDocumentLoader(
dataSource,
"SELECT title, content FROM articles",
row -> Document.from(row.getString("content"))
);
List<Document> dbDocs = jdbcLoader.load();
④、类路径加载器
// 加载单个目录所有文件(自动识别格式)
List<Document> docs = ClassPathDocumentLoader.loadDocuments(
"content/data/docs"
);
除以上外还有其他
4.2、文档解析器
| 文件类型 | 解析器类 | 依赖 |
|---|---|---|
| TXT/CSV | TextDocumentParser |
内置 |
ApachePdfDocumentParser |
org.apache.pdfbox:pdfbox |
|
| Word | ApachePoiDocParser |
org.apache.poi:poi |
| HTML | JsoupHtmlParser |
org.jsoup:jsoup |
| Markdown | CommonMarkParser |
org.commonmark:commonmark |
4.3、文档分割器
①、按段落分割(语义保持)
DocumentByParagraphSplitter splitter = new DocumentByParagraphSplitter(
500, // 最大字符数
50 // 重叠字符数(避免上下文断裂)
);
List<TextSegment> segments = splitter.split(document);
- 特点:保留自然段落边界,适合技术文档/文章
- 参数调优:重叠字符数建议设为最大长度的10%-20%
②、按句子分割(精细粒度)
DocumentBySentenceSplitter splitter = new DocumentBySentenceSplitter(
300, // 最大字符数
30, // 重叠字符数
new OpenNlpSentenceDetector() // 句子检测算法
);
- 依赖:需添加
org.apache.opennlp:opennlp-tools - 适用场景:法律条款、合同等需要精确边界的内容
③、递归字符分割(通用型)
RecursiveTextSplitter splitter = new RecursiveTextSplitter(
1000, // 块大小
200, // 重叠大小
List.of("\n\n", "\n") // 优先按这些分隔符拆分
);
- 优势:自动尝试多级分隔符直到满足大小要求
④、标记(Token)感知分割(LLM优化)
TokenCountSplitter splitter = new TokenCountSplitter(
embeddingModel, // 需要注入EmbeddingModel
512, // 最大token数(如GPT-4的上下文窗口)
50 // 重叠token数
);
- 精确性:按LLM的实际token计数分割,避免截断单词
4.4、向量模型(嵌入模型)
在 LangChain4j 中,向量模型(Embedding Model) 是将文本转换为数值向量(嵌入)的核心组件,其质量直接决定检索效果。
在配置文件中配置好即可注入使用,如 RAG 简单入门中的索引过程(内存中和其他嵌入存储中均已注入)
langchain4j:
open-ai:
chat-model:
api-key: ${DASHSCOPE_API_KEY} # 从环境变量中获取 API 密钥
model-name: qwen-plus # 模型名称,即模型 Code
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1 # 模型 API 基础 URL
log-responses: true # 是否记录响应日志
log-requests: true # 是否记录请求日志
# 流式响应
streaming-chat-model:
api-key: ${DASHSCOPE_API_KEY} # 从环境变量中获取 API 密钥
model-name: qwen-plus # 模型名称,即模型 Code
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1 # 模型 API 基础 URL
log-responses: true # 是否记录响应日志
log-requests: true # 是否记录请求日志
# 向量模型(嵌入模型)
embedding-model:
api-key: ${DASHSCOPE_API_KEY} # 从环境变量中获取 API 密钥
model-name: text-embedding-v3 # 模型名称,即模型 Code
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1 # 模型 API 基础 URL
log-responses: true # 是否记录响应日志
log-requests: true # 是否记录请求日志
具体使用可配合对应云服务器厂商的官方 api 文档进行参考
4.5、向量数据库(嵌入存储)
RAG 简单入门中原默认是使用内存中的嵌入存储,该方法在重启后会出现数据丢失,无法持久化,故建议使用 LangChain4j 支持的 15+ 嵌入存储中的任何一个,如RAG 简单入门中有使用自定义的 redis 的向量数据库
需注意在进行了第一次的向量化数据存储后,其已经存储到了我们的向量数据库中,我们就可以注释掉 @Bean,以防止每次项目启动都重新加载文档执行索引过程
五、工具(函数调用)
该概念允许 LLM 在必要时调用一个或多个可用的工具,通常由开发者定义。 工具可以是任何东西:网络搜索、调用外部 API 或执行特定代码片段等。 LLM 实际上不能自己调用工具;相反,它们在响应中表达调用特定工具的意图(而不是以纯文本形式响应)。 作为开发者,我们应该使用提供的参数执行这个工具,并将工具执行的结果反馈回来。
简单来说就是我们提供工具,工具允许 AI 模型(如 OpenAI GPT)动态调用外部方法或 API 以获取额外信息或执行操作(如计算、搜索、数据库查询等)。
为了增加 LLM 调用正确工具并使用正确参数的可能性, 我们应该提供清晰明确的:
- 工具名称
- 工具功能描述以及何时应该使用它
- 每个工具参数的描述
以下给出两个简单的例子:
1、求数字算数平方根
1.1、准备工具方法
@Component
public class MathTools {
@Tool("求一个数的算数平方根") // 使用 @Tool 注解表示这是一个工具方法
public double sqrt(@P("待运算的数") double number) { // 使用 @P 注解描述清楚工具参数
return Math.sqrt(number);
}
}
1.2、配置工具方法
@AiService(
wiringMode = AiServiceWiringMode.EXPLICIT, // 显式注入模型
chatModel = "openAiChatModel", // 绑定普通模型
streamingChatModel = "openAiStreamingChatModel", // 绑定流式模型
// chatMemory = "getChatMemory" // 配置会话记忆公共对象
// chatMemoryProvider = "getChatMemoryProvider" // 配置带有唯一 id 的会话记忆对象
chatMemoryProvider = "getMyChatMemoryProvider", // 配置带有自定义的 ChatMemoryStore类的会话记忆提供者
tools = "mathTools" // 配置工具类
)
2、预约服务
先按照正常的 JavaWeb 流程完成service、mapper等层的设计,之后准备工具方法并配置即可
假设要预约的 User 实体类有name、age、gender、phone、address,那么我们可以为其设计好对应的 User 表,并且在 service和mapper 层完成插入的操作,之后完成对应的工具方法及配置即可
public interface UserService{
void insert (User user);
}
@Service
public class UserServiceImpl implements UserSerivce(){
@Autowired
private UserMapper userMapper;
public void insert (User user){
userMapper.insert(user);
}
}
@Mapper
public interface UserMapper{
@Insert("insert into user (name, age, gender, phone, address)
values (#{name}, #{age}, #{gender}, #{phone}, #{address})")
void insert (User user);
}
@Component
public class MyTools {
@Autowired
private UserService userService
@Tool("为一个用户进行预约操作") // 使用 @Tool 注解表示这是一个工具方法
public void addUser( // 使用 @P 注解描述清楚工具参数
@P("用户姓名") String name,
@P("用户年龄") String age,
@P("用户性别") String gender,
@P("用户手机号") String phone,
@P("用户姓住址") String address
) {
User user = new User(name,age,gender,phone,address)
userService.insert(user);
}
}
@AiService(
wiringMode = AiServiceWiringMode.EXPLICIT, // 显式注入模型
chatModel = "openAiChatModel", // 绑定普通模型
streamingChatModel = "openAiStreamingChatModel", // 绑定流式模型
// chatMemory = "getChatMemory" // 配置会话记忆公共对象
// chatMemoryProvider = "getChatMemoryProvider" // 配置带有唯一 id 的会话记忆对象
chatMemoryProvider = "getMyChatMemoryProvider", // 配置带有自定义的 ChatMemoryStore类的会话记忆提供者
// tools = "mathTools" // 配置工具类
tools = "myTools" // 配置工具类
)
本篇只是快速入门,详细请看后面的LangChain4j文档详解学习笔记

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)