【机器人系统】机器视觉
一、机器视觉系统
工业机器视觉是软硬件一体化的集成系统,它的目的是代替人眼对被测物进行观察和判断。从组成上,机器视觉系统硬件设备主要包括光源、镜头、相机等,软件主要包括传统的数字图像处理算法和基于深度学习的图像处理算法。系统工作时首先依靠硬件系统将外界图像捕捉并转换成数字信号反馈给计算机,然后依靠软件算法对数字图像信号进行处理。
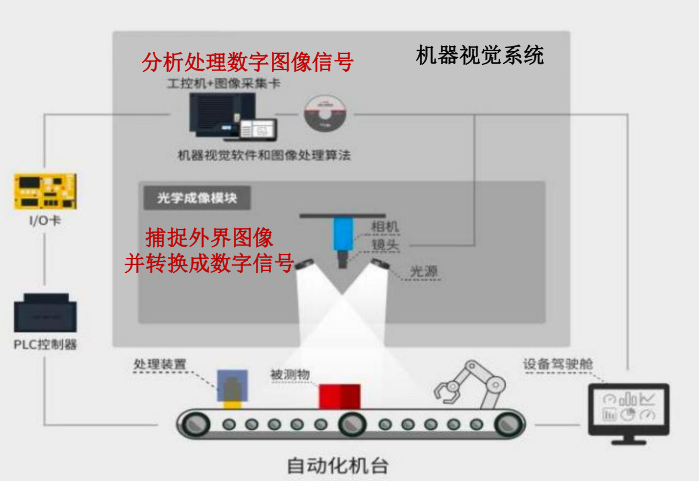
典型的基于工控机的工业视觉系统分为图像采集部分、图像处理部分和运动控制部分。
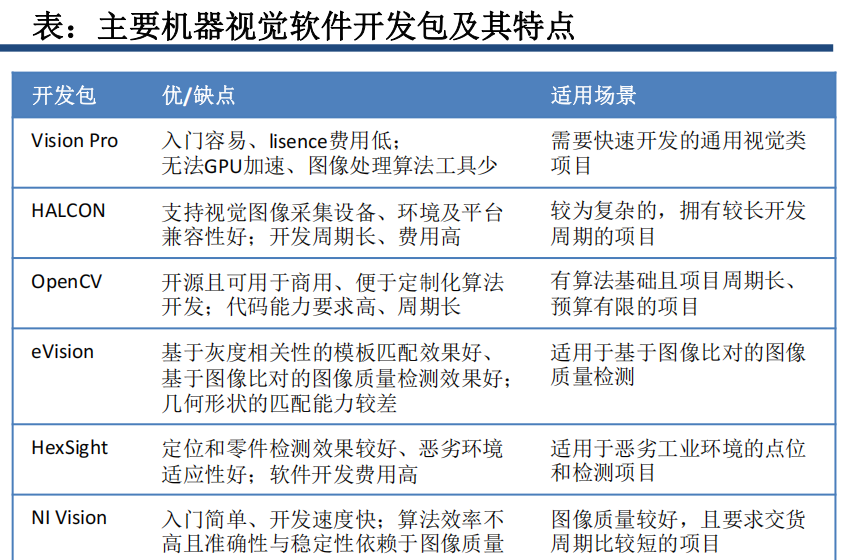
(1)工业相机与镜头:成像器件,通常的视觉系统都是由一套或者多套这样的成像系统组成,如果有多路相机,可能由系统控制切换来获取图像数据,也可能由同步控制同时获取多相机通道的数据。工业相机按照芯片类型、扫描方式、分辨率大小、输出信号方式、输出色彩、输出信号速度、响应频率范围等有着不同的分类方法,种类繁多,需要根据应用需求进行选择;
(2)光源:光源是影响机器视觉系统输入的重要因素,它直接影响输入数据的质量和应用效果;
(3)控制单元:控制单元一般包含光电传感器、I/O、运动控制、电平转化单元等,用以判断被测对象的位置和状态,告知图像传感器进行正确的采集或根据图像处理结果完成对生产过程的控制;
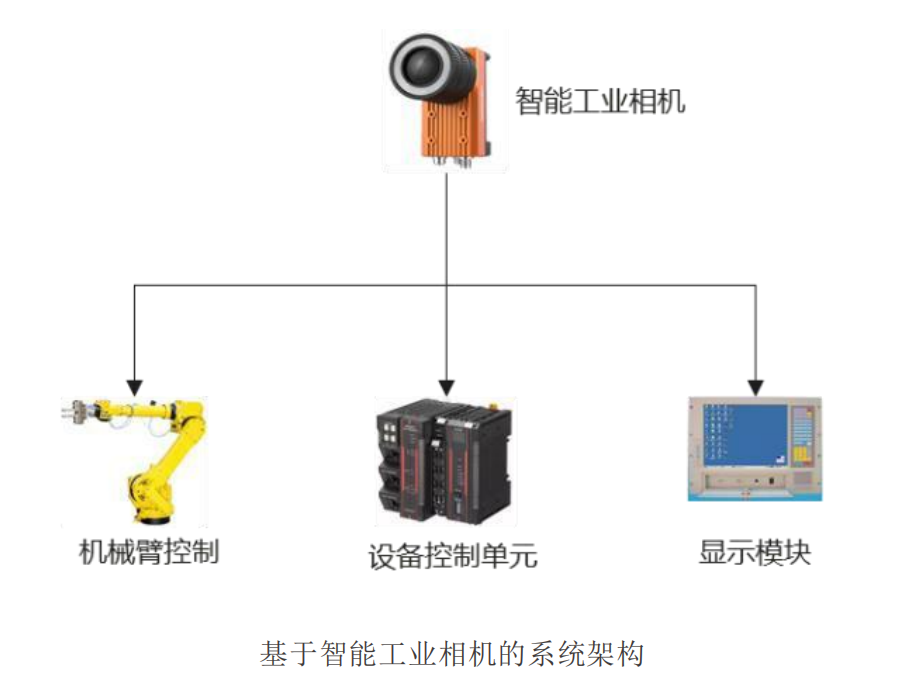
(4)图像处理算力设备:工控机或 GPU 服务器,是视觉系统的核心算力,部署于靠近相机的端侧,完成图像数据的处理和绝大部分的控制逻辑,对于检测识别类型或采用深度学习算法的应用,通常都需要高性能的 CPU/GPU,减少处理的时间。工控机内的机器视觉软件用来完成输入的图像数据的处理,通过图像识别得出结果,这个输出的结果可能是 PASS/FAIL 信号、坐标位置、字符串等。常见的传统机器视觉软件以 Halcon、康耐视 VisionPro 等视觉处理软件为平台,实现专用(比如仅仅用于 LCD 检测,BGA 检测,模版对准等)或通用目的(包括定位、测量、条码 /字符识别、斑点检测等)的视觉检测功能。从 2017 年起基于人工智能的机器视觉软件以百度工业视觉智能平台、康耐视 VIDI 等为代表,提供了复杂纹理或物体表面的缺陷检测功能。
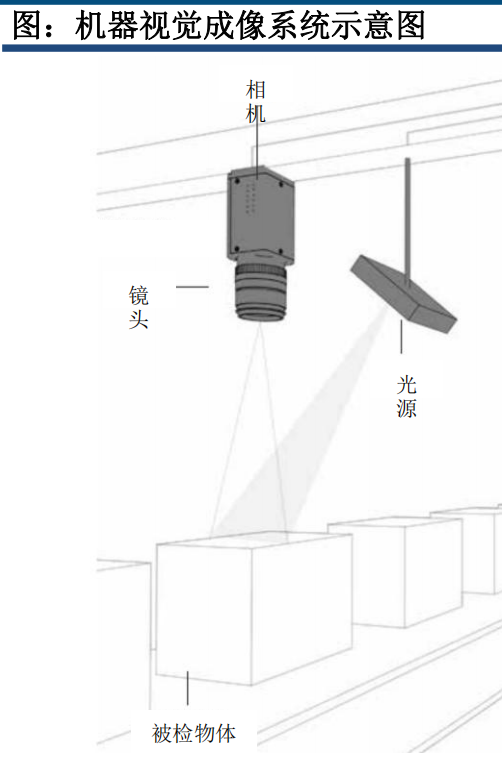
光源:形成有利于图像采集的条件,或用作测量的工具和参照物。
机器视觉系统是通过分析物品上反射的光线来形成图像的,不同的光源方案可以实现不同特征的增强或弱化,进而实现成像效果的改进,例如通过背光增强物体的轮廓特征,便于对物体的尺寸测量;特殊的光源方案还可以作为测量的工具和参照物,例如3D机器视觉中的结构光。
镜头:采集图像并将图像发送至相机
镜头是机器视觉采集和传递被摄物体信息过程的起点,其功能相当于眼睛中的晶状体。不同的镜头具有不同的分辨率、对比度、景深以及像差等光学指标,对成像质量具有关键性影响。
相机:将镜头传输的光信号转化为数字信号便于后续处理分析
相机中的图像感测器是其中的关键部件,通过CCD或CMOS技术将光信号转化为电信号,其功能相当于眼睛中的视网膜。相较于民用相机,工业相机需要更高的传输力、抗干扰能力和稳定的成像能力。
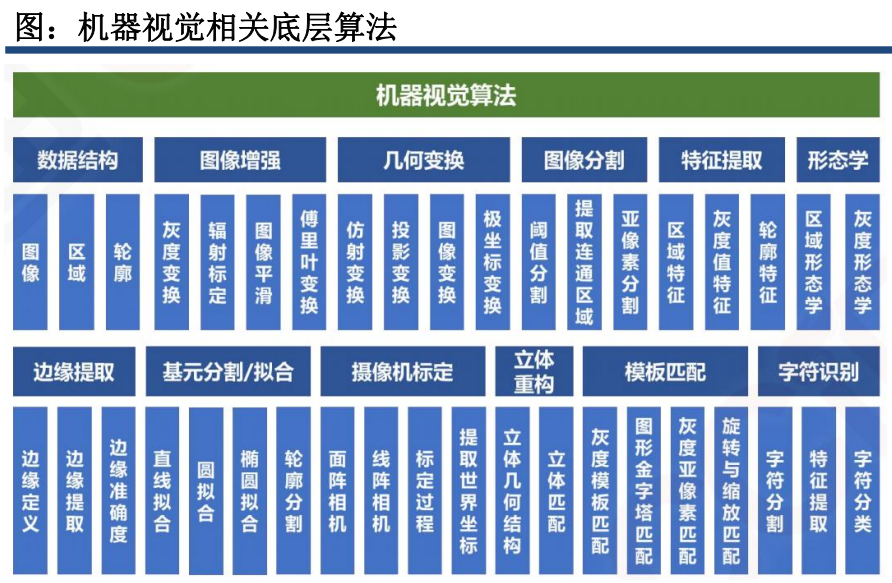
机器视觉系统的算法软件部分是利用计算机视觉算法对获取图像进行分析,进而为进一步决策提供所需信息。根据集成程度和开发难度的不同可以细分为供集成商和设备商开发使用的底层算法和供最终客户使用的二次开发好的算法包。由于不同工业应用场景之间的差异性以及对精度的高要求,往往需要专门设计对应的软件算法以满足工业场景下的视觉需求。
下图是相关的底层基础算法,工业场景中的具体功能实现便是在这些底层算法的基础上开发而
来。
下图是主要的机器视觉软件开发包,其中包含了相关的底层算法。
二、2D/3D视觉
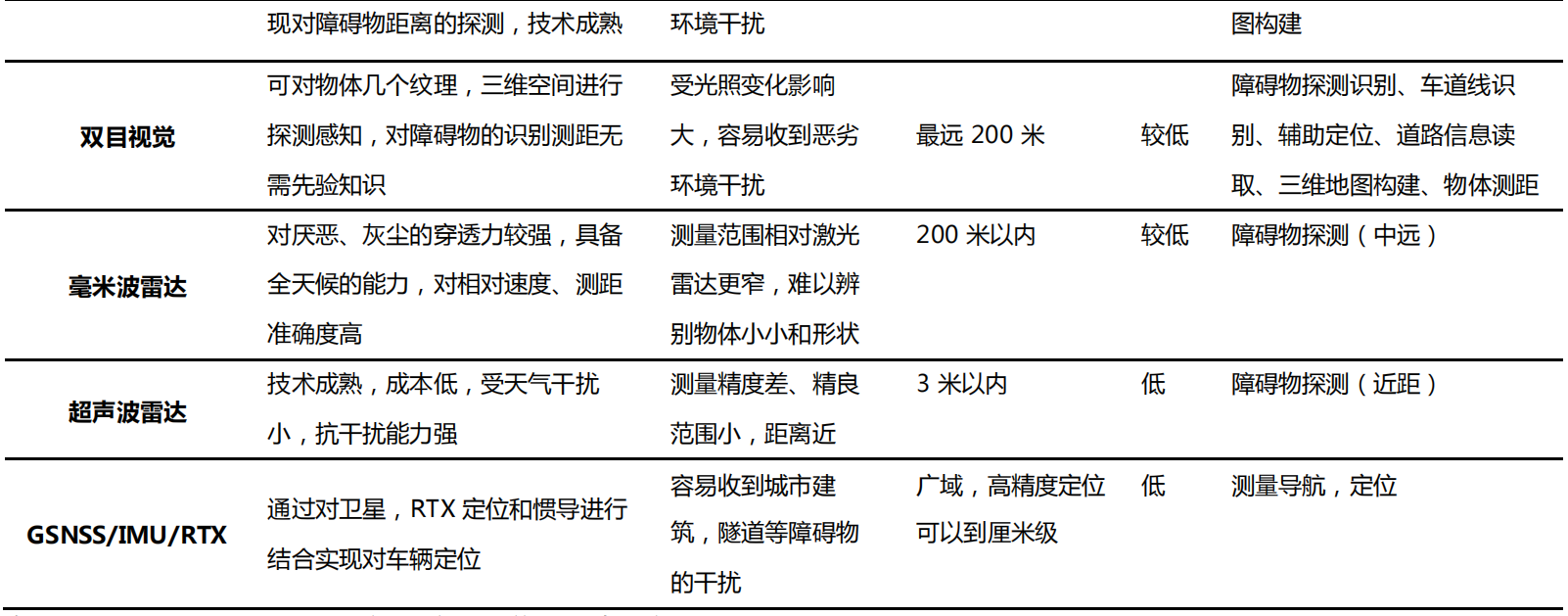
环境感知技术分类,按照传感器物理原理分类,可以分为毫米波雷达、摄像头(单目、双目、多目摄像头)、超声波雷达等。按照信息输出的结果分类,可以分为2D视觉、3D视觉。
2D视觉技术在工业自动化过程的应用已经超过 30 年时间,2D视觉基于物体平面轮廓驱动,解决部分二维层面的读条识别、边缘检测等问题,无法获得曲度、空间坐标等三维参数,完全可以满足外观检测、识别等应用,但检验精度低。
3D视觉技术在 2014 年前后开始兴起,利用立体摄像、激光雷达等技术准确地完成物体三维信息的采集,对于光照条件、物体对比度等客观因素适应能力更强,可以实现 2D视觉无法实现或者不好实现的功能,例如检测产品的高度、平面度、体积等和三维建模等,更加适配半导体、汽车、3C 等领域的高精度工业需求,检测要求精度达到<1μm。3D工业视觉提升了检测和测量的精度和效率,扩大了质量控制在线检测的应用范围,在机器人引导(移动机器人+3D视觉、机械臂+3D视觉)场景应用前景广阔。
三、机器视觉用于机器人引导定位
引导定位分为移动机器人+机器视觉、机械臂+机器视觉两种路线。几类环境感知技术中,激光雷达和毫米波雷达都具有明显的优劣势,激光雷达精度高,探测范围比较广,可以构建机器人和周围环境的3D信息,但受天气的干扰较强;毫米波雷达对于烟雾、灰尘等环境的穿透性较强,所以在特殊环境下它的测距信息会比较好,但是测距精度要弱一些。视觉感知会有效弥补其他感知技术的缺点,对于可靠性要求高的场合,立体视觉加毫米波也是一个很好的组合,视觉感知的技术成本会比激光雷达更低。

四、3D视觉常用技术
3D 视觉常用四种技术:激光三角测量、结构光、飞行时间(ToF)、多目视觉。工作原理均为红外激光发射器发射出近红外光,经过人脸反射后,红外信息被红 外光CMOS 图像处理器接收,并将信息汇总至图像处理芯片,得到物体的三维数据,实现空间定位。不同之处在于:发射近红外光取得三维数据的方式,激光三角测量用激光线扫描物体表面,结构光发射的是散斑,ToF 是发射面光源,而双目立体成像则是通过双目匹配,进行视差算法。
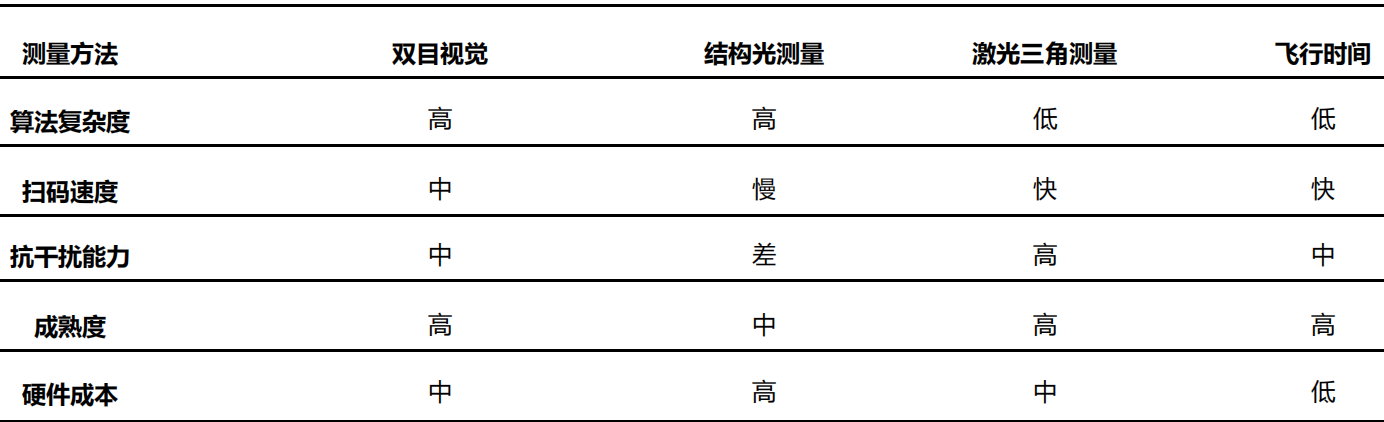
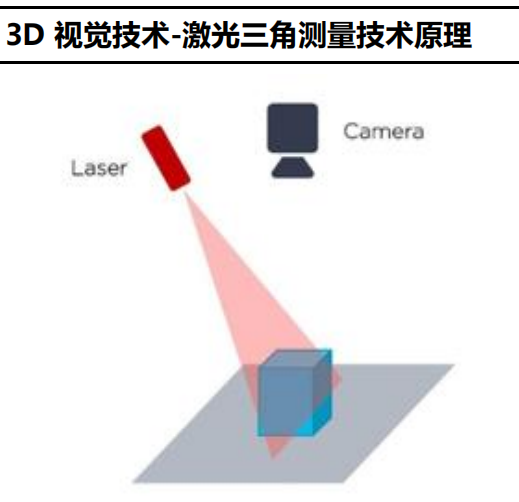
激光三角测量:也被称为“位移传感器”。该方法采用激光线扫描物体表面,并通过相机观察到的激光线变形分析、获得物体表面每个点的深度数据。特点:测量结果能够达到微米级,但扫描速度和工作范围有限。激光三角测量的高精度、动态测速性能促使在线检测发展迅速。
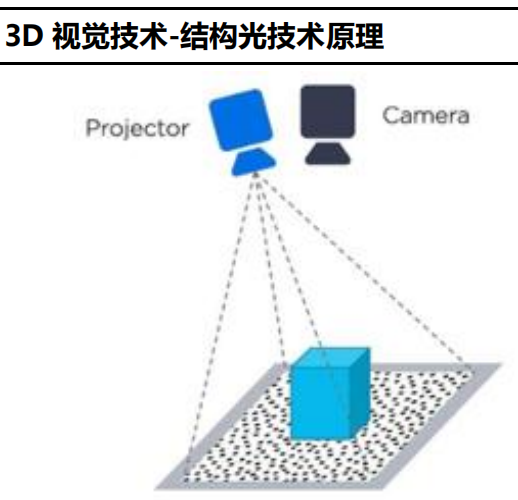
结构光:通过光学投射模块将具有编码信息的结构光投射到物体表面,在被测物表面形成光条图像。图像采集系统采集光条图像后,通过算法处理得出被测物表面的三维轮廓数据,以还原目标物体三维空间信息。结构光技术是一种主动的三维测量技术。特点:由于结构光是主动光,好处是昏暗环境和夜间可用。不需要根据场景的变化而有变化,降低了匹配的难度。但显然在强光环境中会受到干扰,室外基本不可用。另外,由于主动结构光是带编码的,所以多个结构光相机同时使用也是有问题的。在实测中,结构光在角度比较小的侧面上反射比较严重,经常出现比较大
的黑洞,当然黑色物体和玻璃是结构光的大 BUG,一个吸光一个透光。
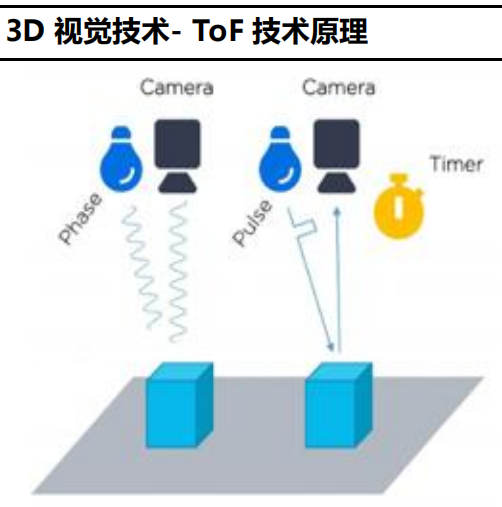
飞行时间(ToF):由发射和反射光信号之间的时间延迟来测量,给定固定的光速。为了精确地测量时延,经常使用短光脉冲。这种技术跟 3D 激光传感器原理基本类似,只不过 3D 激光传感器是逐点扫描,而 TOF 相机则是同时得到整幅图像的深度信息。特点:和结构光方式相比,ToF 并不需要对光的图案做复杂解析,只需要反射回来即可,这大大的提高了鲁棒性,深度信息还原度比结构光好很多,点云的完整性更好。主要表现在:深度图质量要高于结构光,抗强光的干扰能力也更强一些,精度也要更高一些。对于玻璃,是光技术的死穴,只能靠其他技术来弥补了。ToF 速度高,但精度只有毫米级。ToF 技术的难度较高,成本也较高。
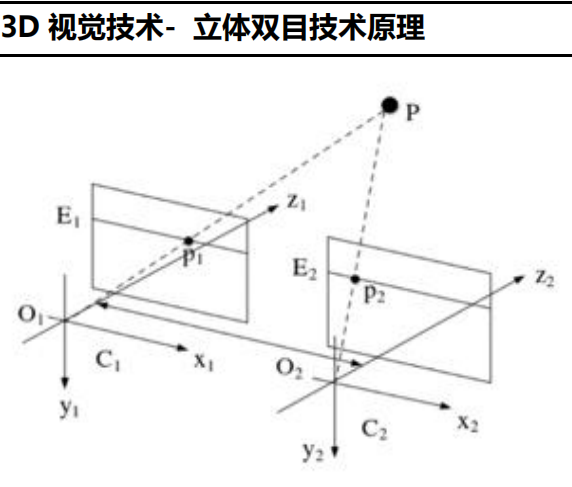
立体视觉法:指从不同的视点获取两幅或多幅图像重构目标物体 3D 结构或深度信息, 目前立体视觉 3D 可以通过单目、双目、多目实现。双目机器视觉是指使用两个 RGB 彩色相机采集图像,并通过后端的双目匹配和三角测量等算法,计算得到深度图的技术方法。双目技术使用的是物体本身的特征点,由于每一次双目匹配都面对不同的图像,都需要重新提取特征点,计算量非常大。双目是一种被动的三维测量技术。特点:硬件复杂度较低,弱光或目标特征不明显时几乎不可用。同时,双目相机的运算复杂度也非常高,对硬件计算性能要求极高。因为计算能力要求高,双目相机极少在嵌入式系统设备中使用,双目相机在通用场景中表现也并不太好,像诸如 slam 导航等应用,但在工业自动化领域和 x86 系统中,双目相机应用广泛,因为工业自动化中,双目相机只要解决特定场景中的特定问题。
五、机器人常用视觉方案
人形机器人主要采用 ToF、立体视觉方案。特斯拉采取纯视觉方案,其余大多数人形机器人厂商采用深度相机+激光/超声波雷达的方案。特斯拉 Optimus 机器人的 3D 传感模块以多目视觉为主,波士顿动力Atlas 采用激光雷达+深度相机,优必选 WALKERX 采用基于多目视觉传感器的 3D视觉定位,小米 CyberOne 机器人所搭载的 Mi-Sense 深度视觉模组是由小米设计,欧菲光协同开发完成,其机器视觉深度相机模块主要由 iToF 模组、RGB 模组、可选的 IMU 模块组成。
特斯拉采取纯视觉方案,硬件成本低,对软件算法要求高。特斯拉人形机器人共搭载 8 个摄像头,搭载自研的 FDS 芯片,实现 360°环绕的影像识别。FSD 系统可以实现每 1.5 毫秒 2500 次搜索的超高效率,预测可能出现的各种情况,并在其中规划出最安全、最舒适、最快速的路径。特斯拉自主研发了基于神经网络的训练方式,拥有一支 1000 人左右由世界各地人才组成的数据标注团队,每天对视频数据中的物体在“矢量空间”中进行标注,在善于把握细节的人工标注和效率更高的自动标注配合下,只需要标注一次,“矢量空间”就能自动标注所有摄像头的多帧画面。这为特斯拉带来了上百亿级的有效且多样化的原生数据,而这些数据都会用于神经网络培训。多任务学习 HydraNets 神经网络架构可以将 8 个摄像头获取的画面拼接起来,并完美平衡视频画面的延迟和精准度。通过人工或自动标注环境和动静物体,系统会逐帧分析视频画面,了解物体的纵深、速度等信息,再将这些数据交给机器人学习,绘制 3D 鸟瞰视图,形成 4D 的空间和时间标签的“路网”以呈现道路等信息,帮助车辆/机器人把握驾驶环境,更精准的寻找最优路径。


DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 16
16 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)