概念解析:机器视觉如何赋予机器“三维双眼”——3D重建技术全景指南
在人工智能的浪潮中,如果说传统的2D图像识别是让机器“认出”物体,那么**3D重建(3D Reconstruction)**则是让机器真正“理解”物理世界。通过机器视觉实现3D重建,是赋予机器人、无人机和自动驾驶汽车空间感知能力的核心技术。
文章目录
前言
在人工智能的浪潮中,如果说传统的2D图像识别是让机器“认出”物体,那么**3D重建(3D Reconstruction)**则是让机器真正“理解”物理世界。通过机器视觉实现3D重建,是赋予机器人、无人机和自动驾驶汽车空间感知能力的核心技术。
1. 什么是通过机器视觉实现3D重建?
定义
通过机器视觉实现的3D重建,是指利用光学传感器(如相机)获取的2D图像序列,结合计算机视觉算法,恢复物体的三维几何形状、空间位置以及表面纹理的过程。
核心本质:从2D到3D的逆向投影
在物理世界中,3D物体通过相机的透镜成像在2D感光元件上,这是一个降维的过程(丢失了深度信息 Z Z Z)。3D重建的目标就是通过数学模型和算法,将这些丢失的深度信息找回来,把像素点还原到三维坐标系( X , Y , Z X, Y, Z X,Y,Z)中。
关键概念
- 点云(Point Cloud): 重建的第一步通常是生成大量带有空间坐标的采样点。
- 三角剖分(Triangulation): 利用几何关系确定点在空间中的位置。
- 深度图(Depth Map): 每个像素点代表距离相机距离的图像。
2. 效果演示:3D重建的过程
我们可以通过以下三个阶段来想象重建的视觉效果:
- 稀疏重建阶段(Sparse Reconstruction):
屏幕上出现零散的特征点,看起来像是一群发光的萤火虫构成了物体的轮廓。此时可以看清相机的运动轨迹。 - 稠密重建阶段(Dense Reconstruction):
点云变得极其密集,物体的形状已经清晰可辨,像是由无数细小的沙粒堆砌而成的雕塑。 - 表面网格化与纹理贴图(Meshing & Texturing):
算法在点与点之间连线形成三角面片(Mesh),并把照片上的颜色“贴”上去。此时,物体在屏幕上看起来与真实照片无异,但你可以旋转、缩放它。
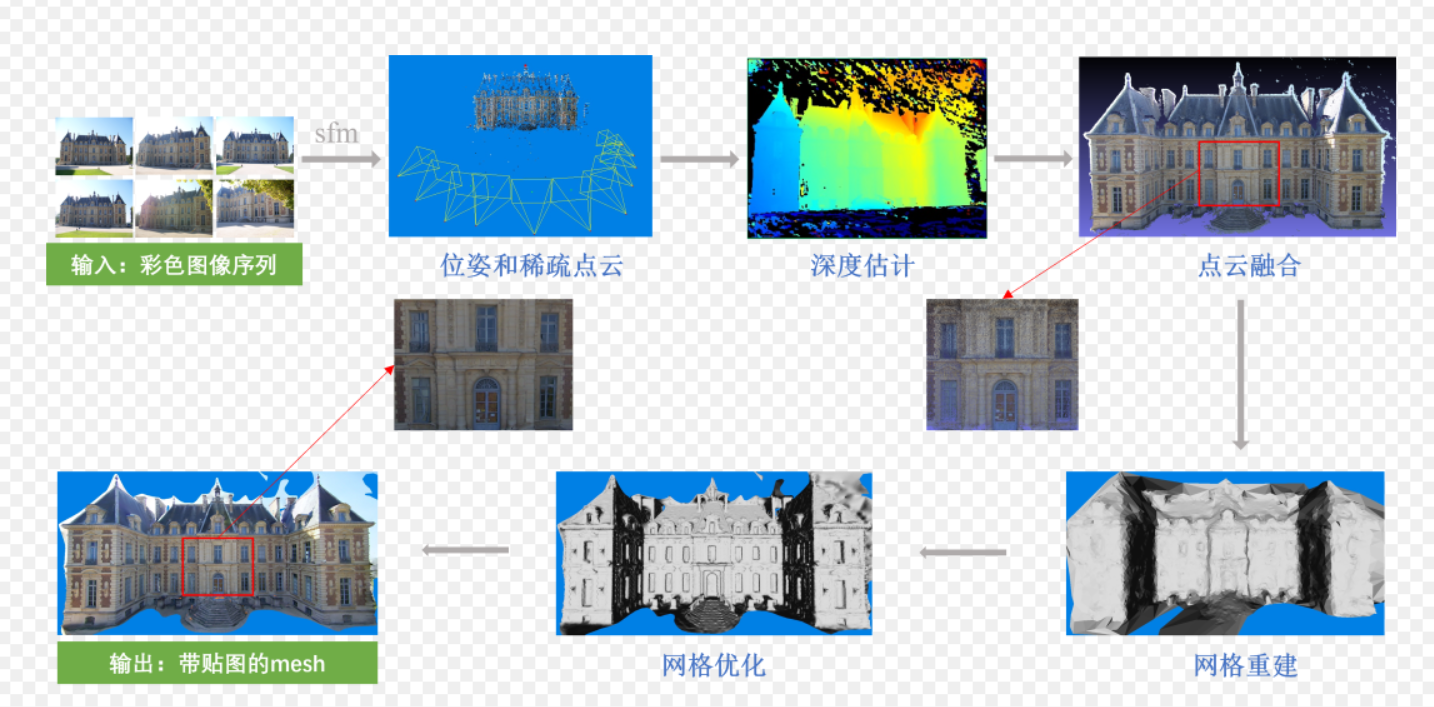
概念解读:
1. Mesh(网格 / 三角网格)
Mesh 是三维模型的 “几何骨架”,它由大量三角形(或多边形)面片拼接而成,只定义了物体的三维形状、轮廓和结构,就像建筑的钢筋框架,本身没有颜色和纹理。
2. 贴图(Texture Mapping)
贴图是一张包含颜色、纹理、细节信息的二维图像,比如墙面的砖石纹理、窗户的玻璃质感。它的作用是把这些表面细节 “贴” 到 Mesh 的几何框架上。
3. 目前的主流方法
3D重建的方法主要分为主动视觉和被动视觉两大类:
一、被动视觉(Passive Vision)—— 仅依赖环境光
这类方法不向物体发射能量,仅通过捕捉环境光成像。
A. 单目重建(Monocular Reconstruction):
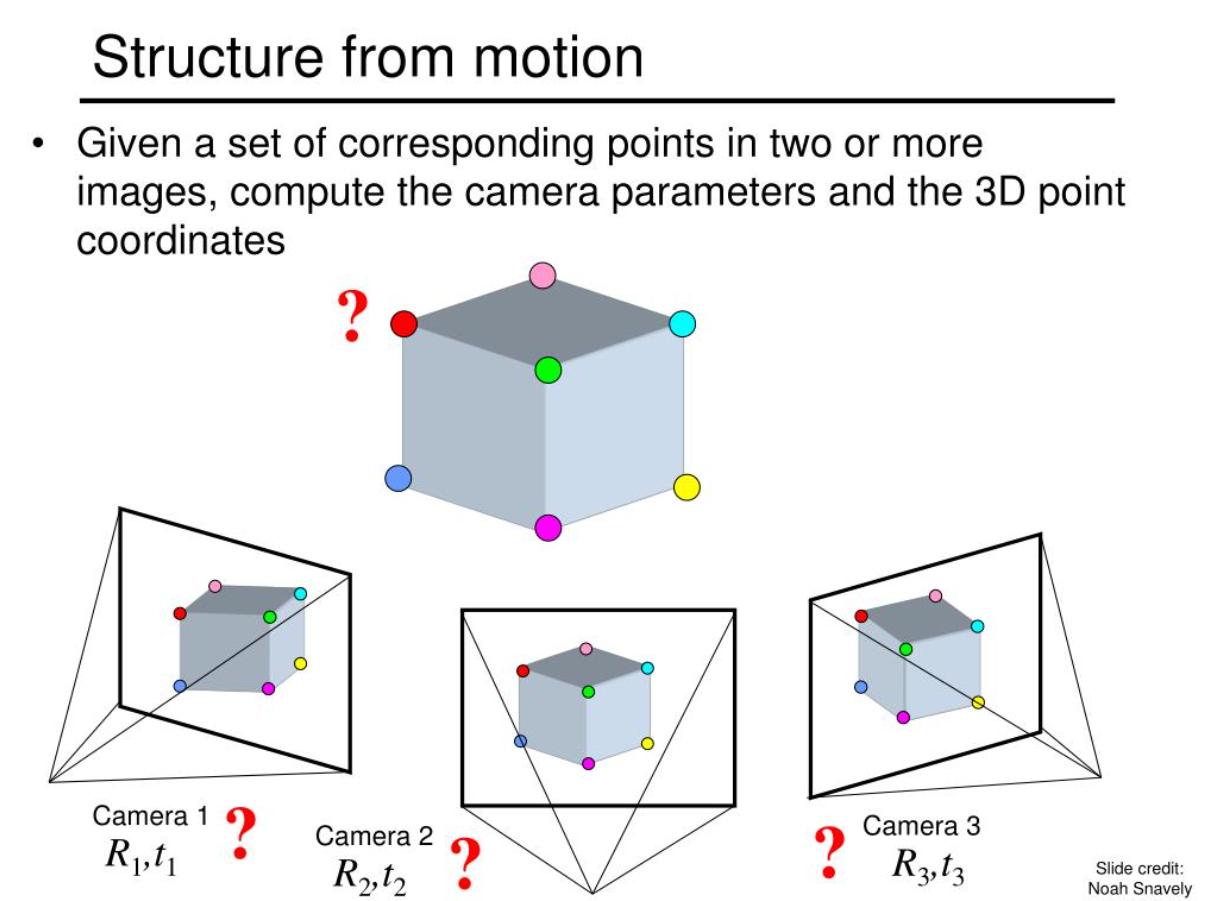
原理:利用运动恢复结构(SfM, Structure from Motion)。通过单台相机在不同位置拍摄的多张照片,计算相机位姿变化并重建场景。
难点: 存在尺度不确定性(不知道物体到底有多大)。
简单来说,SfM 就是通过移动的相机拍摄的一系列2D图像,来推算出物体的3D形状和相机的空间轨迹。
下面我将非常详细地为你拆解 SfM 的原理、步骤以及它背后的数学逻辑。
什么是 SfM(Structure from Motion)?
- Structure(结构): 指的是被拍摄物体的三维坐标(点云)。
- Motion(运动): 指的是相机在拍摄每一张照片时的位置(位姿,Pose)。
- From(通过…恢复): 强调了因果关系。
核心思想:
想象你围着一个雕像转圈拍照。虽然每张照片都是平面的(2D),但当你从左边移动到右边时,雕像上的特征点(比如鼻子尖)在照片里的位置会发生移动。SfM 算法就像你的大脑一样,通过分析这些点移动的幅度、方向和规律,反过来推算出:“哦,原来鼻子尖距离我这么远,而我刚才向右移动了 50 厘米。”
SfM 的全流程(极简步骤版)
一个标准的 SfM 系统通常包含以下五个核心步骤:
1. 特征提取与匹配 (Feature Extraction & Matching)
- 做什么: 算法会在每一张照片中寻找“地标”——那些无论光照怎么变、角度怎么变都能认出来的点(通常使用 SIFT 或 ORB 算法)。
- 目的: 确定第一张照片里的那个“点”和第二张照片里的哪个“点”是物理世界中的同一个位置。
- 结果: 得到一堆配对好的像素点坐标。
2. 计算几何关系 (Estimating Epipolar Geometry)
- 做什么: 利用对极几何(Epipolar Geometry)理论。通过匹配的点对,计算出两张照片之间的数学变换关系,即基础矩阵(Fundamental Matrix)或本质矩阵(Essential Matrix)。
- 原理: 即使不知道物体的形状,只要有足够的匹配点,我们就能算出相机从位置 A 到位置 B 到底旋转了多少度,平移了多少距离。
3. 三角测量 (Triangulation)
- 做什么: 有了相机的位姿,算法会从两个相机中心向同一个特征点发射两条射线。
- 原理: 这两条射线的交点,就是该特征点在三维空间中的真实坐标( X , Y , Z X, Y, Z X,Y,Z)。
- 结果: 生成了最初的稀疏点云。
4. 增量式重建 (Incremental Reconstruction)
- 做什么: 算法不会一次性处理几百张照片,而是先从两张开始,重建出一小部分,然后像拼图一样,不断加入第三张、第四张照片。
- 过程: 每加入一张新照片,就利用已有的 3D 点云来反推这张新照片的相机位置(这叫 PnP 算法),然后再把新看到的点加入点云。
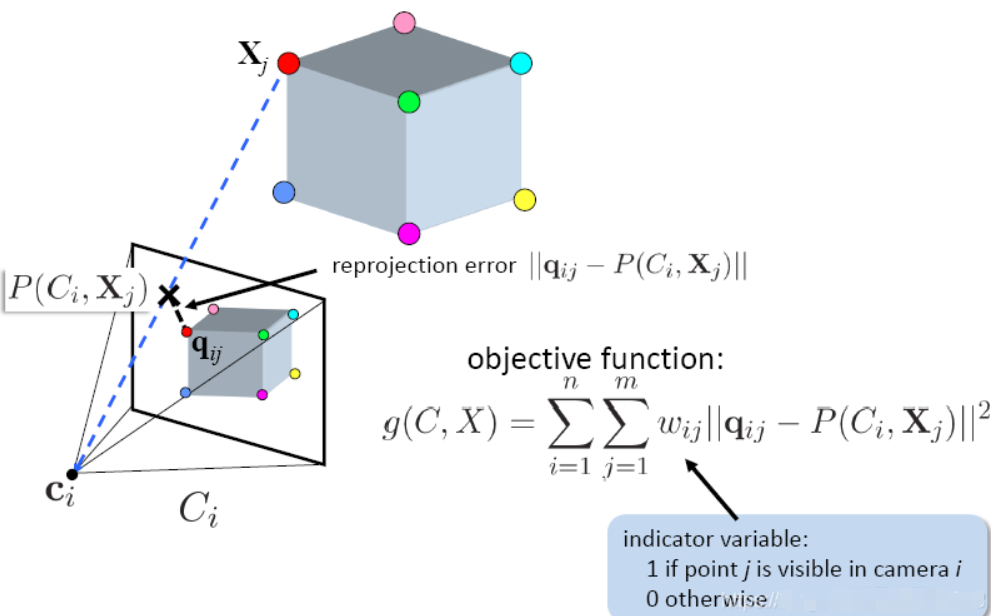
5. 全局优化:光束法平差 (Bundle Adjustment, BA)
- 这是 SfM 的灵魂: 随着照片越来越多,误差会累积,点云会“飘”掉或变形。
- 做什么: BA 是一项大型优化工程。它会同时调整所有相机的位姿和所有 3D 点的坐标,使得每一个 3D 点投影回照片上时,与照片里原始像素点的距离(重投影误差)最小。
为什么单目 SfM 无法感知“绝对尺度”?
这是单目重建最致命的弱点,也是面试或学术讨论中必问的问题。
原理:
在数学上,SfM 恢复出的空间结构具有尺度等比性。
- 如果你拍摄一张桌子上的水杯,重建出来的模型可能看起来很完美。
- 但是,算法无法分辨这是一个真实的高 10 厘米的水杯,还是一个高 10 米的巨型水杯模型。
原因:
在单目相机看来,一个很小的物体离相机很近,和一个巨大的物体离相机很远,在照片上的像素表现是一模一样的。除非你额外告诉算法一个参考值(比如:照片里那个硬币直径是 25mm,或者两个相机其实距离 10cm),否则它只能告诉你:“A 点到 B 点的距离是 C 点到 D 点距离的 2 倍”,而不能告诉你到底是多少米。
SfM 的两种主流流派
-
增量式 SfM (Incremental SfM):
- 代表作:COLMAP(目前学术界和工业界最常用的开源工具)。
- 优点:非常鲁棒,精度高。
- 缺点:慢,照片多了之后优化非常耗时。
-
全局式 SfM (Global SfM):
- 代表作:TheiaSfM。
- 优点:速度极快,适合大规模场景。
- 缺点:对异常匹配点非常敏感,容易崩溃。
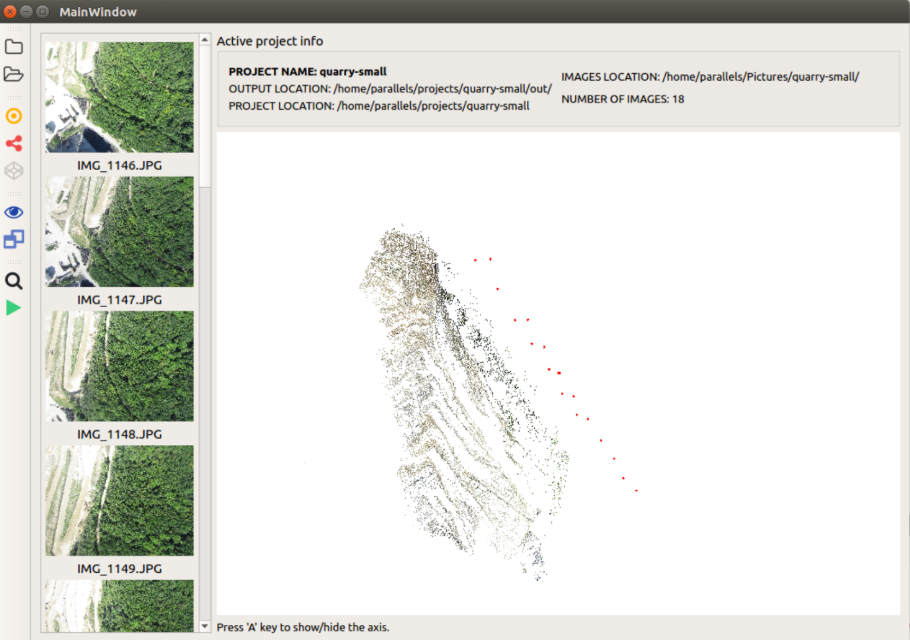
参考文件
若要深入研究 SfM 的底层数学,以下文献是必读的:
- Agarwal, S., et al. (2011). Building Rome in a Day. Communications of the ACM.
(这是 SfM 历史上的里程碑,证明了利用互联网上的成千上万张照片重建一座城市是可能的)。 - Schönberger, J. L., & Frahm, J. M. (2016). Structure-from-Motion Revisited. CVPR.
(这是 COLMAP 的核心论文,目前被公认为增量式 SfM 的最优实践)。 - Triggs, B., et al. (1999). Bundle Adjustment – A Modern Synthesis. Vision Algorithms: Theory and Practice.
(深入讲解了 SfM 中最关键的优化算法 BA)。 - Snavely, N., Seitz, S. M., & Szeliski, R. (2006). Photo Tourism: Exploring image collections in 3D. SIGGRAPH.
(首次向大众展示了如何通过非结构化照片集进行 3D 导航)。 - Longuet-Higgins, H. C. (1981). A computer algorithm for reconstructing a scene from two projections. Nature.
(提出了著名的八点算法,是 SfM 几何计算的基石)。
B. 双目/多目立体视觉(Stereo Vision):
原理: 模拟人类双眼。通过计算左右两个相机拍摄图像的视差(Disparity),利用三角测量原理计算深度。
如果说 SfM(运动恢复结构)是模仿人类“边走边看”来认知空间,那么双目立体视觉(Stereo Vision)则是直接模仿人类的双眼结构。
它是机器视觉中最经典、应用最广泛的深度感知技术之一。下面我们深度拆解双目立体视觉的原理、数学逻辑以及实现过程。
1. 核心定义
双目立体视觉是指使用两台成像特性相同(焦距、像素尺寸等一致)的相机,安装在同一平面上,保持一定的水平距离(基线,Baseline),通过计算左右图像中同一物体像素点的相对位姿差异,来获取物体三维信息的方法。
直观理解:
伸出你的一根手指放在眼前,先闭上左眼看,再闭上右眼看。你会发现手指相对于背景的位置发生了“跳动”。
- 手指离眼睛越近,跳动幅度(位姿差异)越大。
- 手指离眼睛越远,跳动幅度越小。
- 这种跳动的位移量,在计算机视觉中被称为视差(Disparity)。
2. 核心数学原理:三角测量(Triangulation)
双目视觉的精髓可以用一个极其简单的几何公式来概括。
假设两台相机完全平行,焦距为 f f f,两相机中心距离(基线)为 B B B。空间中一点 P P P 在左相机成像面上的横坐标是 x L x_L xL,在右相机成像面上的横坐标是 x R x_R xR。
- 视差(Disparity)定义: d = x L − x R d = x_L - x_R d=xL−xR
- 深度(Depth)计算公式:
Z = f ⋅ B d Z = \frac{f \cdot B}{d} Z=df⋅B
这个公式告诉我们两个关键信息:
- 反比关系: 深度 Z Z Z 与视差 d d d 成反比。视差越大,物体越近。
- 尺度确定性: 与单目 SfM 不同,由于基线 B B B 是提前测量好的物理常数(比如两相机间距 6 厘米),所以双目视觉可以直接计算出物体的真实物理距离(米或毫米),不存在尺度不确定性。
3. 标准算法流程(Stereo Pipeline)
实现高质量的双目重建通常需要经过以下四个严谨的步骤:
第一步:相机标定(Camera Calibration)
- 目的: 确定相机的内参(焦距、中心点)和外参(两相机之间的精确旋转和平移关系)。
- 意义: 如果相机镜头有畸变(比如鱼眼效果),或者两个相机没装正,后续计算全是错的。
第二步:立体校正(Stereo Rectification)—— 极关键
- 做什么: 通过数学变换,把拍摄时的两张照片对齐,使得左右图像的极线(Epipolar Line)处于同一水平线上。
- 意义: 校正后,左图中的一个点,在右图中一定能在同一行找到。这把一个 2D 的搜索问题降维成了 1D 搜索,极大地提高了运算速度。
第三步:立体匹配(Stereo Matching)—— 最核心、最难
- 做什么: 算法要在右图的同一行像素里,找到那个和左图点“长得最像”的点。
- 主流算法:
- BM (Block Matching): 快,但精度低,边缘粗糙。
- SGM (Semi-Global Matching): 工业界的主流,在速度和精度间取得了极佳平衡。
- 深度学习方法: 如 PSMNet,利用神经网络直接输出视差图,在处理无纹理区域表现更好。
第四步:视差转深度(Disparity to Depth)
- 做什么: 利用前面提到的公式 Z = ( f ⋅ B ) / d Z = (f \cdot B) / d Z=(f⋅B)/d,将像素级的视差图转化为物理世界的深度图。
4. 双目视觉 vs. 单目 SfM 的区别
| 特性 | 双目立体视觉 (Stereo) | 单目 SfM |
|---|---|---|
| 相机数量 | 2台或多台 | 1台 |
| 拍摄状态 | 可以静态拍摄(瞬间成像) | 必须移动相机(动态拍摄) |
| 尺度感知 | 自动获得真实物理尺度 | 无法获得真实尺度(仅有比例) |
| 实时性 | 高(适合避障、机器人) | 低(计算量大,需运动序列) |
| 适用范围 | 适合近距离、高精度感知 | 适合大场景、远距离建模 |
5. 适用场景与局限性
适用场景:
- 车载辅助驾驶(ADAS): 识别前方障碍物距离。
- 工业抓取: 机械臂识别零件的 3D 位置。
- 无人机避障: 实时感知周围墙体距离。
局限性:
- 环境纹理依赖: 如果墙面是纯白色的,算法无法在右图中找到匹配的点(因为看起来都一样),会导致深度丢失。
- 基线限制: 测量距离受限于基线 B B B。如果要测 100 米外的物体,基线必须足够宽,否则视差 d d d 太小,会导致误差剧增。
- 遮挡问题: 左眼看得到的地方,右眼可能被挡住了(暗影区),导致无法计算。
6. 参考资料与经典文献
- Scharstein, D., & Szeliski, R. (2002). A taxonomy and evaluation of dense two-frame stereo correspondence algorithms. International Journal of Computer Vision.
(立体匹配领域的基石论文,定义了评估标准)。 - Hirschmuller, H. (2005). Accurate and efficient stereo processing by semi-global matching and mutual information. CVPR.
(提出了著名的 SGM 算法,至今仍是该领域的工业标准)。 - Marr, D., & Poggio, T. (1979). A computational theory of human stereo vision. Proceedings of the Royal Society of London.
(从生物学和计算视觉角度解释了人类双眼如何感知深度)。 - Konolige, K. (1998). Small Vision Systems: Hardware and Implementation. International Symposium on Robotics Research.
(讲解了实时双目视觉系统的早期硬件实现)。 - Zhang, Z. (2000). A flexible new technique for camera calibration. IEEE Transactions on Pattern Analysis and Machine Intelligence.
(著名的“张氏标定法”,双目相机标定的必备基础)。
C. 神经辐射场(NeRF, Neural Radiance Fields)
* **前沿:** 2020年后的爆发性技术。利用深度学习将场景表示为一个连续的体积场,通过体渲染技术生成极其逼真的3D视图。
如果说 SfM 是在做“几何题”,双目视觉是在做“物理题”,那么 NeRF(Neural Radiance Fields,神经辐射场) 就是在用“人工智能算法”进行一次革命性的艺术创作。
NeRF 是 2020 年计算机视觉领域最具颠覆性的技术之一。它彻底改变了我们存储和表现 3D 世界的方式。
1. 什么是 NeRF?
定义:
NeRF 是一种利用深度神经网络(通常是多层感知机 MLP)来隐式地表示 3D 场景的技术。它不存储点云,也不存储三角面片,而是将整个 3D 场景编码进一个神经网络的权重里。
核心直觉:
想象空间中充满了“带颜色的烟雾”。在每一个坐标点上,烟雾都有特定的颜色和浓度。NeRF 的目标是训练一个 AI 助手,当你问它:“在坐标 ( x , y , z ) (x, y, z) (x,y,z) 这个点,从 ( θ , ϕ ) (\theta, \phi) (θ,ϕ) 这个角度看过去是什么颜色?”它能立刻计算出结果。
2. NeRF 的核心原理:5D 函数
NeRF 将场景表示为一个连续的 5D 函数:
- 输入 (5个参数): 空间位置 ( x , y , z ) (x, y, z) (x,y,z) + 观察视角 ( θ , ϕ ) (\theta, \phi) (θ,ϕ)。
- 输出 (4个参数): 该点的颜色 R G B RGB RGB + 该点的体积密度 σ \sigma σ(即光线通过这里的阻力,代表物体是否存在)。
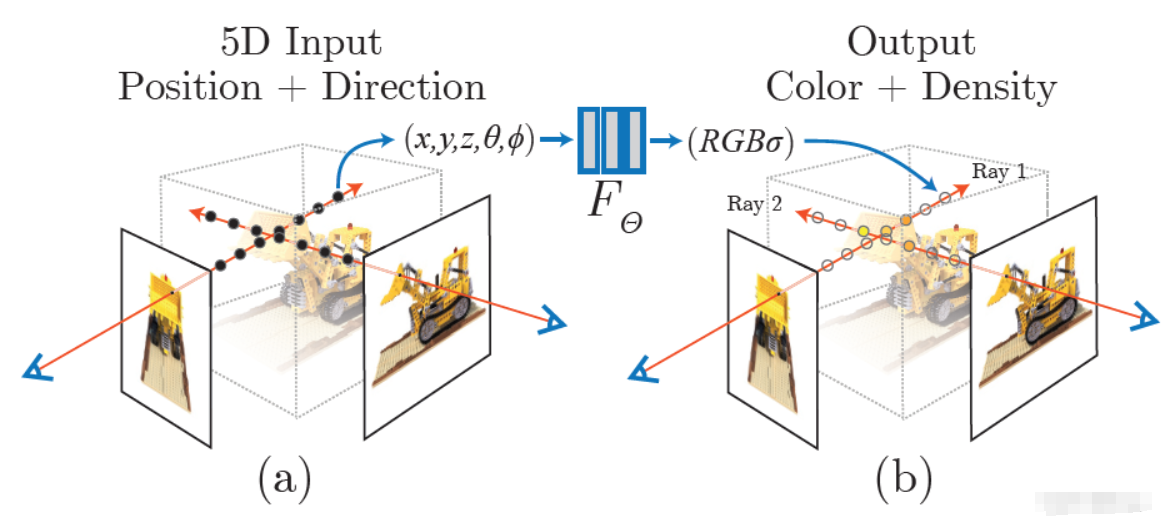
- 隐式表示(Implicit Representation):
传统的 3D 模型像“乐高积木”(体素)或“折纸”(网格)。NeRF 像“一段代码”,你给它坐标,它吐出颜色。这使得它能表现极其精细的细节,而不需要海量的存储空间。 - 位置编码(Positional Encoding):
这是 NeRF 能火的关键。神经网络天生倾向于学习“平滑”的东西,容易把图像变模糊。NeRF 通过把坐标转换成高频正弦/余弦波,强制网络记住细节(如物体的边缘、细小的纹理)。 - 可微体渲染(Differentiable Volume Rendering):
这是 NeRF 的“渲染引擎”。它沿着相机射出的一条光线进行采样,把路径上所有点的颜色和密度加权累加,最终得到一个像素的颜色。因为整个过程是数学可导的,所以可以通过对比生成的图像和真实照片的差异,利用反向传播来训练网络。
3. NeRF 的工作流程
- 准备数据: 拍摄几十张到上百张物体的照片,并利用 SfM (如 COLMAP) 算出每张照片拍摄时的精确相机位置。
- 光线投射: 对于图像上的每个像素,从相机中心射出一条穿过该像素的光线。
- 采样与查询: 在这条光线上采样成百上千个点,把这些点的坐标丢进神经网络里。
- 合成颜色: 神经网络输出这些点的颜色和密度,通过体渲染公式把它们“捏合”成一个像素颜色。
- 优化权重: 比较 AI 生成的像素和照片里的真实像素。如果不一样,就调整神经网络的参数。重复成千上万次,直到网络能完美预测出任何角度的画面。
4. 为什么 NeRF 效果这么震撼?
- 照片级的真实感: 它能完美处理光泽表面(如金属的反光)、透明物体(如玻璃杯)以及极其复杂的几何结构(如头发、树叶),这些都是传统点云或 Mesh 的噩梦。
- 无限的分辨率: 因为是连续函数,理论上你可以无限放大场景。
- 视角插值: 你只拍了 20 张照片,但 NeRF 可以生成相机从未经过的位置的平滑视频,效果就像在好莱坞电影里穿梭一样。
5. 局限性与目前的瓶颈
尽管效果惊艳,但原生 NeRF 存在以下问题:
- 训练极慢: 2020 年刚出来时,训练一个场景需要几小时甚至几天。
- 渲染(推理)极慢: 生成一张图需要几秒钟,无法做到实时互动。
- 场景是死板的: 原生 NeRF 只能重建静态场景,如果画面里有东西在动,或者光线变了,模型就会崩溃。
- 需要相机位姿: 它极其依赖 SfM 提供的精确坐标,如果照片位姿算错了,NeRF 出来的结果会是一团浆糊。
6. 进化之路(NeRF 的子孙们)
为了解决上述问题,诞生了一系列变体:
- Instant-NGP (NVIDIA): 将训练时间从小时级缩短到了秒级。
- Mip-NeRF: 解决了物体在远近切换时的锯齿问题。
- D-NeRF / NSVF: 尝试处理会动的物体(动态场景)。
- 3D Gaussian Splatting (2023): 虽然不完全是 NeRF,但它吸取了 NeRF 的思想,实现了真正实时的高质量渲染,是目前最火的替代方案。
7. 参考文献
- Mildenhall, B., Srinivasan, P. P., Tancik, M., Barron, J. T., Ramamoorthi, R., & Ng, R. (2020). NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis.
ECCV. (NeRF 的开山之作)。 - Müller, T., Evans, A., Schied, C., & Keller, A. (2022). Instant Neural Graphics Primitives with a Multiresolution Hash Encoding. ACM Transactions on Graphics.
(NVIDIA 提出的 Instant-NGP,让 NeRF 走向实用化)。 - Barron, J. T., et al. (2021). Mip-NeRF: A Multiscale Representation for Anti-Aliasing Neural Radiance Fields. ICCV.
(解决了抗锯齿和多尺度问题)。 - Tancik, M., et al. (2022). Block-NeRF: Scalable Large Scene Neural View Synthesis. CVPR.
(证明了 NeRF 可以用来重建整个城市街道)。 - Martin-Brualla, R., et al. (2021). NeRF in the Wild: Neural Radiance Fields for Unconstrained Photo Collections. CVPR.
(解决了利用互联网乱七八糟的照片进行重建的问题)。
D. 3D Gaussian Splatting (3DGS):
最新: 2023年出现的技术,通过大量3D高斯椭球体拟合场景,实现了比NeRF更快的渲染速度和极高的重建质量。
如果说 NeRF 是 3D 重建领域的“数字幻觉”,那么 3D Gaussian Splatting (3DGS) 就是在 2023 年横空出世的“数字画笔”。
3DGS 的出现直接解决了 NeRF 渲染慢、训练久的核心痛点,将 3D 重建推向了实时、高画质、可交互的新纪元。
1. 什么是 3D Gaussian Splatting (3DGS)?
定义:
3DGS 是一种基于显式辐射场(Explicit Radiance Field)的场景表示技术。它不使用神经网络来“猜”颜色,而是直接在空间中抛洒数百万个带有颜色、形状和透明度的3D 高斯椭球体(Gaussian Kernels),通过这些椭球体的叠加来拼凑出整个世界。
形象比喻:
- NeRF 像是一个记忆力超强的画师:你问他画里某个坐标是什么颜色,他想一下告诉你。
- 3DGS 像是一个贴纸大师:他直接在透明的空间里贴了数百万张半透明的彩色贴纸(椭球体),你从任何角度看过去,这些贴纸叠加在一起就是一张完美的照片。
2. 核心原理:3D 高斯椭球体的“基因”
每一个 3D 高斯椭球体都包含了一组极其精简的数学参数(基因):
- 中心位置 (Position, X , Y , Z X, Y, Z X,Y,Z): 椭球体在哪。
- 协方差矩阵 (Covariance, Σ \Sigma Σ): 决定椭球体的形状和方向。为了方便计算,它被分解为:
- 缩放 (Scaling): 它是长的、圆的还是扁的。
- 旋转 (Rotation): 它是横着的还是斜着的。
- 不透明度 (Opacity, α \alpha α): 这个椭球体有多透明。
- 球谐函数颜色 (Spherical Harmonics, SH): 这是一种特殊的颜色表示法。它不只是一个单一颜色,而是记录了从不同方向看这个点时颜色的变化(比如金属的高光)。
3. 工作流程:从点云到精美建模
第一步:初始化 (Initialization)
3DGS 通常以 SfM (如 COLMAP) 产生的稀疏点云作为起点。每个点被初始化为一个小的 3D 高斯球。
第二步:可微投影与渲染 (Splatting & Rasterization)
这是 3DGS 速度极快的秘诀。
- 算法将 3D 的椭球体平扁化(投影)到 2D 屏幕上,变成一个个 2D 椭圆。
- 采用基于分块(Tile-based)的快速光栅化渲染器。它将屏幕分成许多小格子(Tiles),只渲染对这个格子有贡献的椭球体。这与现代显卡(GPU)的处理逻辑完全匹配。
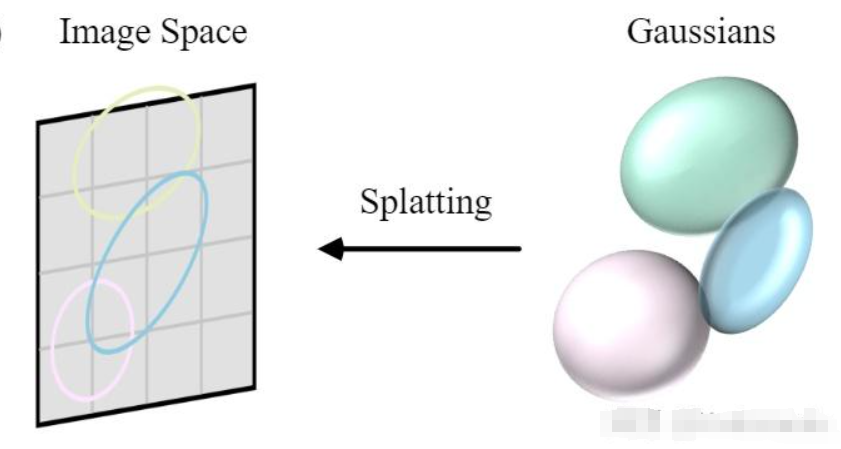
第三步:自适应密度控制 (Adaptive Density Control)
这是 3DGS 的“进化”过程。在优化过程中,算法会观察:
- 克隆 (Clone): 如果某个地方太平滑,点不够用,就在那复制一个点。
- 分裂 (Split): 如果某个椭球体太大、太模糊,就把它拆成两个小的。
- 修剪 (Culling): 如果某个椭球体不透明度极低,基本看不见,就把它删掉。
为什么 3DGS 能在 2023 年引爆技术圈?
- 渲染速度起飞: NeRF 渲染一张图需要几秒钟,而 3DGS 可以在普通的 GPU 上实现 100+ FPS(每秒帧数)的实时渲染。
- 训练时间极短: 一个中等复杂的场景,NeRF 可能要训练几小时,3DGS 只需要 5-10 分钟。
- 显式存储: 因为它是数百万个点,你可以直接在 3D 软件里看到这些点,甚至可以手动删除、移动或缩放其中的一部分,这在 NeRF 的神经网络权重里是几乎做不到的。
- 视觉效果惊艳: 3DGS 捕捉精细细节(如树叶、毛发、薄雾)的能力极强,画面边缘比 NeRF 更加锐利。
5. 目前的瓶颈与挑战
- 显存压力大 (VRAM Intensive): 渲染虽然快,但要在显存里存储数百万个高斯参数,非常吃显存(通常需要 8GB 以上的显存才能流畅运行大型场景)。
- 存储空间巨大: 一个高质量场景的模型文件可能高达 数百 MB 甚至几个 GB,而 NeRF 只需要几 MB 的神经网络权重。
- 依赖初始化: 如果 SfM 出来的初始点云太差(比如在光滑平面上没取到点),3DGS 很难凭空生成高质量的椭球体,会出现明显的“破洞”。
- 伪影 (Artifacts): 在视角变化剧烈时,有时会看到椭球体像“彩色雪花”一样漂浮。
6. 参考文献
- Kerbl, B., Kopanas, G., Leimkühler, T., & Drettakis, G. (2023). 3D Gaussian Splatting for Real-Time Radiance Field Rendering. ACM Transactions on Graphics (SIGGRAPH).
(3DGS 的开山鼻祖,目前该领域引用量最高的论文)。 - Zwicker, M., Pfister, H., van Baar, J., & Gross, M. (2001). Surface Splatting. SIGGRAPH.
(3DGS 核心思想“Splatting”的早期理论来源)。 - Luan, F., et al. (2024). GPS-Gaussian: Generalizable Pixel-wise 3D Gaussian Splatting for Real-time Human Novel View Synthesis.
(将 3DGS 应用于人体动态建模的前沿工作)。 - Niedermayr, S., et al. (2023). Compressed 3D Gaussian Splatting for Highly Accessible Novel View Synthesis.
(针对 3DGS 存储体积过大问题的早期优化研究)。 - Chen, Z., et al. (2023). MCMC-GS: Multi-Scale 3D Gaussian Splatting for Large-Scale Scene Reconstruction.
(针对大规模城市场景的 3DGS 改进算法)。
二. 主动视觉(Active Vision)—— 自带光源
这类方法通过向物体发射特定光线来辅助测量。
- 结构光(Structured Light):
- 原理: 投影仪向物体投射特定的光栅图案,相机拍摄被物体表面畸变后的图案,通过数学计算得出深度。
- 代表: iPhone的前置FaceID。
如果说 SfM 和双目视觉是利用“自然的眼睛”去观察世界,那么**结构光(Structured Light)**则是给机器装上了一台“主动测量尺”。
它是目前高精度 3D 扫描、人脸识别(如 iPhone FaceID)和工业精密检测领域最核心的技术。
A. 结构光技术
####定义:
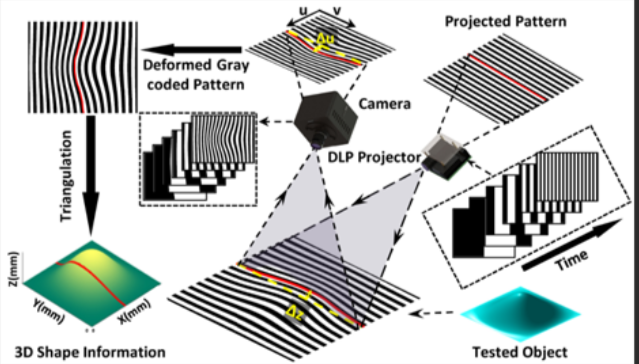
结构光是一种主动视觉测量技术。它通过投影仪向物体表面投射特定的已知图案(如格点、条纹、编码图),再由相机捕捉这些图案在物体表面发生的几何畸变,通过三角测量原理计算出物体的三维空间坐标。
形象比喻:
想象你在黑暗中面对一面凹凸不平的墙。你打开一支手电筒,手电筒的光罩上画着整齐的方格。
- 如果墙是平的,你在墙上看到的方格也是整齐的。
- 如果墙上有个坑或者凸起,方格线就会变得弯曲。
- 通过观察方格线“弯了多少”,你就能推算出墙面的起伏。这就是结构光。
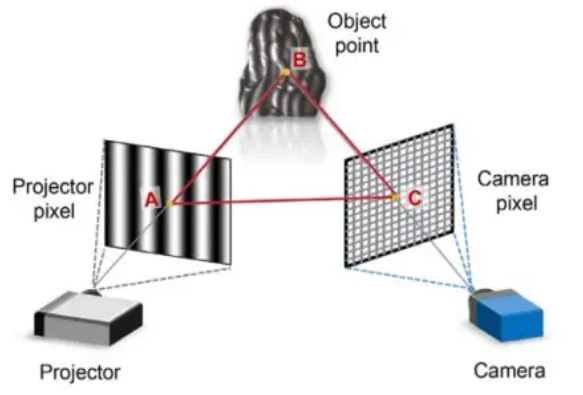
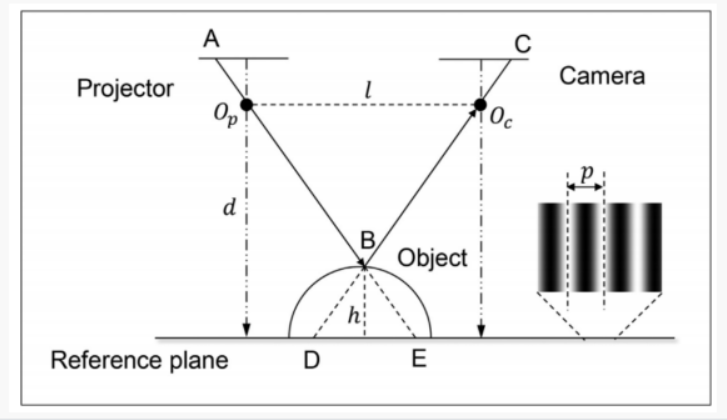
2. 核心数学原理:变形的三角测量
结构光本质上是双目视觉的变种。
- 在双目视觉中,我们需要两个相机从不同角度看同一个点。
- 在结构光中,我们用一个投影仪替代了其中一个相机。
数学逻辑:
- 已知条件: 投影仪投射出的光束角度是已知的,相机与投影仪之间的距离(基线 B B B)是固定的。
- 寻找匹配: 投影仪投出的每一个光点(或线条)都有一个唯一的“编码”。相机拍到这个点后,立刻就能知道它是从投影仪的哪个角度射出来的。
- 几何求解: 投影仪发出的射线与相机接收到的射线在空间中相交。根据正弦定理或简单的三角函数,即可解算出该交点的三维坐标 ( X , Y , Z ) (X, Y, Z) (X,Y,Z)。
3. 编码方式:结构光的“语言”
结构光最核心的竞争力在于如何设计投射的“图案”。目前主流有三种:
A. 空间编码 (Spatial Coding) —— 代表:iPhone FaceID
- 做法: 一次性投射一个复杂的散斑图案(类似满天星)。
- 特点: 只需拍摄一张图片即可完成重建,速度极快,适合动态物体(如人脸)。
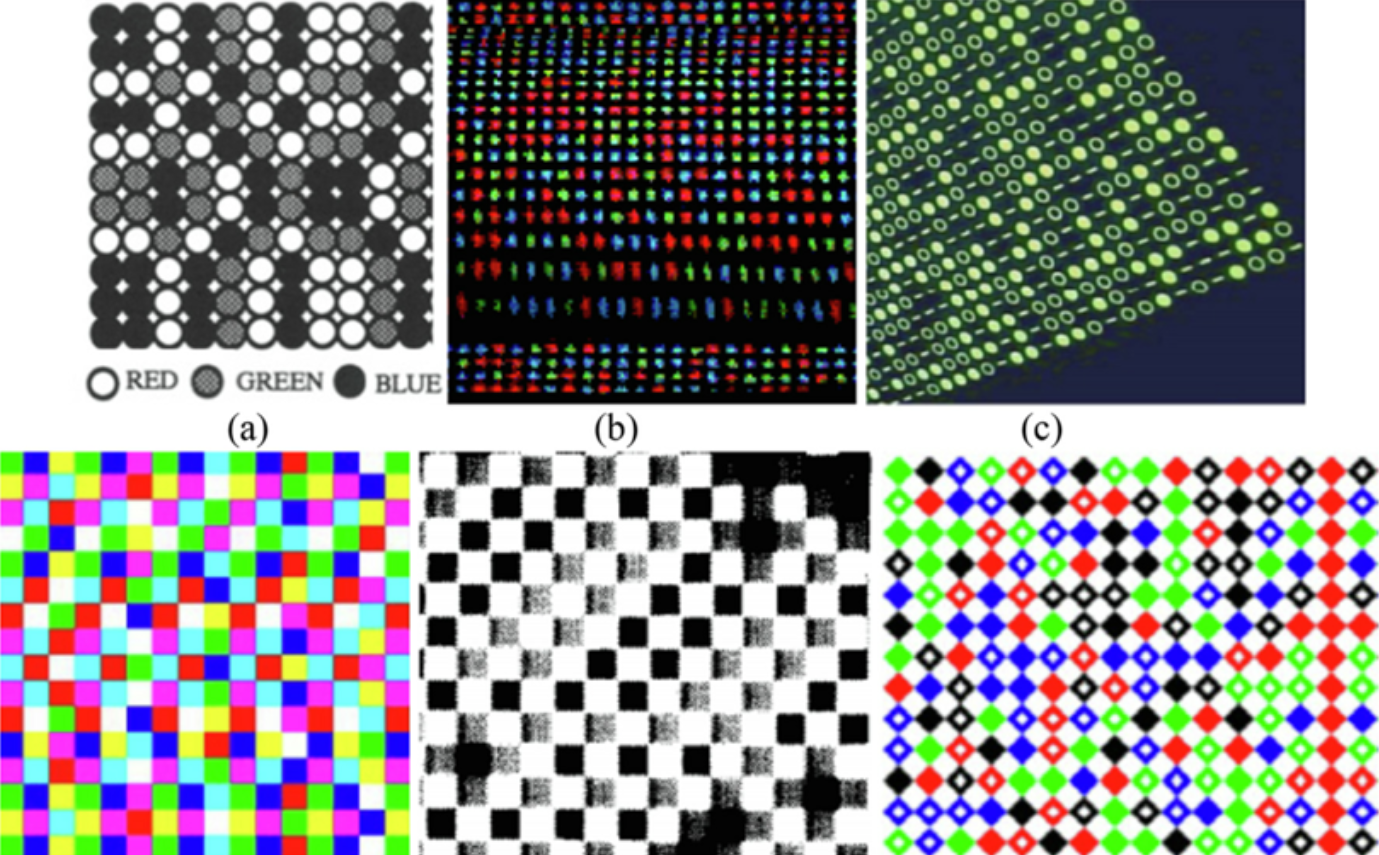
B. 时间编码 (Temporal Coding) —— 代表:工业 3D 扫描仪
- 做法: 连续投射多张不同频率的黑白条纹(如格雷码 + 正弦条纹)。
- 特点: 精度极高(可达微米级),但物体必须保持静止,因为需要拍摄多张照片。
C. 相移法 (Phase Shifting)
- 做法: 投射周期性的正弦光栅,通过分析光波相位的偏移来提取高度信息。
4. 深度解析:iPhone FaceID 是如何工作的?
FaceID 是结构光技术小型化、消费级应用的巅峰。它包含三个核心组件:
- 点阵投影器 (Dot Projector): 向你的脸部投射超过 30,000 个肉眼不可见的红外散斑点。
- 红外摄像头 (Infrared Camera): 读取这些散斑在脸部起伏下形成的畸变图像。
- 泛光感应元件 (Flood Illuminator): 确保在全黑环境下也能照亮脸部,供红外相机识别。
为什么它安全?
因为它不是在对比“照片”,而是在对比你脸部的三维地形图。照片是平面的,无法产生结构光的畸变效果,因此无法欺骗 FaceID。
5. 结构光的优缺点
优点:
- 无需环境纹理: 即使是纯白色的墙,结构光也能重建(因为它自己投射了纹理),这弥补了双目视觉的短板。
- 精度极高: 在近距离(1米以内),结构光的精度可以轻松达到毫米甚至微米级。
- 主动补光: 在全黑的环境下依然能工作。
缺点:
- 怕强光: 在室外强光(如阳光)下,投影仪的光会被阳光淹没,导致失效。
- 距离限制: 投影仪功率有限,通常只适用于近距离(如手机解锁、桌面扫描)。
- 材质敏感: 面对镜面反光物体或全黑吸光物体,投射的光会消失或乱射,导致无法成像。
6. 参考文献
- Geng, J. (2011). Structured-light 3D surface imaging: a tutorial. Advances in Optics and Photonics.
(最经典的结构光综述性教程)。 - Scharstein, D., & Szeliski, R. (2003). High-accuracy stereo depth maps using structured light. CVPR.
(探讨了如何利用结构光获取极高精度的深度图)。 - Salvi, J., et al. (2004). Pattern codification strategies in structured light systems. Pattern Recognition.
(详细对比了各种编码图案的优劣)。 - Apple Inc. About Face ID advanced technology. Support Documentation.
(虽然不是学术论文,但揭示了消费级结构光系统的硬件架构)。 - Zuo, C., et al. (2016). Micro-structured-light 3D surface profiling: A review. Measurement.
(聚焦于微观领域高精度结构光测量的综述)。
飞行时间法(ToF, Time of Flight)
原理: 发射红外脉冲,测量光线反射回来的时间。
代表: 激光雷达(LiDAR)、Kinect 2.0。
如果说结构光是利用“几何畸变”来测量,那么**飞行时间法(ToF, Time of Flight)**就是利用“绝对速度”来测量。
ToF 是目前 3D 感知领域中速度最快、延迟最低的技术。它广泛应用于自动驾驶的激光雷达(LiDAR)、手机后置深度摄像头(如 iPhone 的 LiDAR 扫描仪)以及早期的体感游戏设备。
1. 什么是 ToF (飞行时间法)?
定义:
ToF 是一种通过测量光波在传感器与目标物体之间“飞行”的时间,来计算目标距离的技术。因为光的传播速度 c c c 是已知的常数,只要知道了时间 t t t,距离 d d d 也就迎刃而解。
形象比喻:
想象你对着一口深井大喊一声,然后开始计时。当你听到回声时,停止计时。
- 声纳/雷达: 利用声波或无线电波的反射。
- ToF: 利用光波(通常是 850nm-940nm 的近红外光)。由于光速极快(每秒 30 万公里),ToF 芯片需要具备“皮秒级”(万亿分之一秒)的计时精度。
2. 核心数学原理:极速公式
ToF 的基本原理非常直观,但实现方法分为两种主要流派:dToF 和 iToF。
A. dToF (Direct ToF,直接测量) —— 代表:激光雷达 (LiDAR)
这是最硬核的方式。传感器直接发射一个极短的光脉冲,并启动一个超高精度的“秒表”,记录光子飞出去并跳回来的确切时间 Δ t \Delta t Δt。
- 公式: d = c ⋅ Δ t 2 d = \frac{c \cdot \Delta t}{2} d=2c⋅Δt
- 难点: 光速太快,光走 1 厘米只需要约 33 皮秒。这就要求传感器(通常是 SPAD,单光子雪崩二极管)具有极其恐怖的响应速度。
B. iToF (Indirect ToF,间接测量) —— 代表:Kinect 2.0
由于精确计时太难且贵,iToF 采用了“曲线救国”的方法:它发射的是连续的正弦调制光波,通过测量发射波与反射波之间的**相位差(Phase Shift)**来推算时间。
- 逻辑: 相位偏移了多少度,就代表时间过去了多久。
- 优点: 硬件成本较低,像素分辨率可以做得很高(类似手机摄像头)。
3. ToF 的工作流程
- 发射单元 (Emitter): 发出经过调制的红外激光或脉冲。
- 反射 (Reflection): 光线触碰物体表面后发生弥散反射。
- 接收单元 (Sensor): 一个特殊的 CMOS 图像传感器捕捉返回的光信号。
- 处理单元 (Processor):
- 对于 dToF:统计光子到达的直方图,确定峰值时间。
- 对于 iToF:计算每个像素点的电荷差异,转换成相位,再换算成深度值。
- 输出: 生成一张深度图(Depth Map),每个像素代表该点的物理距离。
4. ToF vs. 结构光:有什么区别?
| 特性 | ToF (飞行时间法) | 结构光 (Structured Light) |
|---|---|---|
| 计算量 | 极低(硬件直接输出结果) | 高(需要复杂的图像对比分析) |
| 工作距离 | 远(激光雷达可达数百米) | 短(通常 1 米以内) |
| 抗干扰性 | 较强(尤其 dToF 适合室外) | 较弱(强光下图案会被淹没) |
| 分辨率 | 较低(通常是 QVGA 级) | 较高(可以达到百万像素) |
| 应用场景 | 扫地机器人、自动驾驶、AR 建模 | 手机面部解锁、精密扫描、活体检测 |
5. 目前的瓶颈与挑战
- 多径干扰 (Multi-path Interference):
如果光线在墙角经过多次反射才回到传感器,ToF 会误以为物体比实际更远,产生“深度重影”。 - 飞点效应 (Flying Pixels):
在物体的边缘,一个像素可能同时接收到物体表面和背景墙的反射信号,导致边缘出现一圈莫须有的“飞点”。 - 环境光干扰:
虽然 iToF 在室内表现优异,但在太阳光下,红外光噪声巨大,会导致精度大幅下降(dToF 通过单光子技术缓解了这一问题)。 - 功耗问题:
因为要不断地主动发射光,ToF 传感器通常比普通摄像头更耗电。
6. 参考文献
- Hansard, M., Lee, S., Choi, O., & Horaud, R. P. (2012). Time-of-Flight Cameras: Principles, Methods and Applications. Springer Briefs in Computer Science.
(最系统讲解 ToF 原理的经典书籍)。 - Li, L. (2014). Time-of-flight camera – An introduction. Technical report, Texas Instruments.
(TI 发布的官方技术报告,深入讲解了 iToF 的电子学实现)。 - Horaud, R., et al. (2016). An overview of gradient-based 3D reconstruction methods for Time-of-Flight RGB-D cameras. Journal of Mathematical Imaging and Vision.
(探讨了如何优化 ToF 的深度图质量)。 - Bamji, C. S., et al. (2015). A 0.13μm CMOS System-on-Chip for a 512×424 Time-of-Flight Image Sensor with Multi-Frequency Photo-Demodulation. ISSCC.
(Kinect 2.0 背后芯片的技术细节论文)。 - Niclass, C., et al. (2005). A CMOS single photon avalanche diode array for 3D imaging. IEEE International Solid-State Circuits Conference.
(dToF 核心组件 SPAD 传感器的奠基性研究)。
4. 适用场景
3D重建技术已经深入到各行各业:
- 工业自动化: 高精度零件的尺寸检测、缺陷扫描、机器人抓取引导。
- 自动驾驶与机器人: 避障、环境建模(SLAM)、高精地图制作。
- 文化遗产保护: 对古建筑物、文物进行数字化建模,实现永恒保存。
- 医疗成像: 牙科扫描建模、手术前3D模拟。
- 数字孪生与元宇宙: 将现实世界的物体快速建模并导入游戏或虚拟空间。
- 电子商务: 手机扫描商品实现3D预览(如宜家家具试摆)。
5. 目前的瓶颈与问题
尽管技术发展迅速,但3D重建仍面临以下严峻挑战:
- 弱纹理与重复纹理:
面对洁白的墙壁、纯色桌面或玻璃表面,算法很难找到可靠的特征匹配点,导致重建失败或出现“破洞”。 - 反光与透明物体:
金属表面的高光和玻璃的折射会误导相机,使算法计算出错误的深度。 - 计算复杂度与实时性:
高精度的稠密重建需要巨大的算力,在移动设备或嵌入式平台上难以实现超高精度的实时重建。 - 遮挡问题:
当物体的一部分被挡住时,算法需要通过先验知识(AI猜想)来补全,这往往会导致精度下降。 - 光照敏感性:
过强或过暗的光线都会严重影响被动视觉方法的特征提取质量。
总结
通过机器视觉实现3D重建是计算机视觉领域的“圣杯”之一。从经典的三角几何到现代的深度学习(NeRF/3DGS),我们正处于从“拍出好看的照片”向“构建完美的数字世界”跨越的时代。随着算力的提升和算法的优化,未来的3D重建将变得像拍照一样简单且精准。
参考文献
为了保证信息的真实性与学术严谨性,以下是本博客参考的核心文献与经典教材:
- Hartley, R., & Zisserman, A. (2004). Multiple View Geometry in Computer Vision. Cambridge University Press.
(计算机视觉领域的圣经,详细讲解了多视图几何和相机模型)。 - Mildenhall, B., et al. (2020). NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. ECCV.
(神经辐射场奠基之作)。 - Kerbl, B., et al. (2023). 3D Gaussian Splatting for Real-Time Radiance Field Rendering. ACM Transactions on Graphics.
(当前最前沿的实时3D重建算法)。 - Schonberger, J. L., & Frahm, J. M. (2016). Structure-from-Motion Revisited. CVPR.
(COLMAP算法的理论基础)。 - Newcombe, R. A., et al. (2011). KinectFusion: Real-time 3D reconstruction and interaction using a moving depth camera. ISMAR.
(结构光与ToF实时重建的经典文献)。
作者提示: 如果你对具体的某个算法(如如何配置COLMAP或如何训练NeRF)感兴趣,欢迎在评论区留言,我将在下一期详细讲解!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 31
31 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)