PUMA:基于感知驱动的统一落脚点先验,用于增强移动性的四足跑酷
26年1月来自浙大和中国电信的论文“PUMA: Perception-driven Unified Foothold Prior for Mobility Augmented Quadruped Parkour”。四足机器人的跑酷任务已成为敏捷运动能力的一个极具潜力的基准。人类运动员能够有效地感知环境特征,从而选择合适的落脚点(Foothold)来跨越障碍,但赋予腿式机器人类似的感知推理能力仍然是
26年1月来自浙大和中国电信的论文“PUMA: Perception-driven Unified Foothold Prior for Mobility Augmented Quadruped Parkour”。
四足机器人的跑酷任务已成为敏捷运动能力的一个极具潜力的基准。人类运动员能够有效地感知环境特征,从而选择合适的落脚点(Foothold)来跨越障碍,但赋予腿式机器人类似的感知推理能力仍然是一个巨大的挑战。现有方法通常依赖于遵循预计算落脚点的分层控制器,这限制机器人的实时适应能力和强化学习的探索潜力。为了克服这些挑战,提出PUMA,一个端到端的学习框架,它将视觉感知和落脚点先验信息整合到一个单阶段的训练过程中。该方法利用地形特征来估计以自我为中心的极坐标落脚点先验信息(由相对距离和航向组成),从而指导机器人主动调整姿态以完成跑酷任务。
近年来,四足机器人展现出卓越的运动性能:低成本的四足机器人能够跨越长距离的障碍,攀爬高大的障碍物,并穿越由踏脚石和倾斜平台组成的复杂离散地形[1]–[6]。为了在跑酷任务中应对复杂地形,许多研究利用外部传感器(例如摄像头、激光雷达)来获取地形信息。通常将这些感觉数据与本体感觉融合,通过基于学习的方法训练动态运动策略。这些方法包括分离控制和感知模块的解耦分层框架[7]、[8]以及端到端的视觉辅助策略[9]、[10],为敏捷的腿式运动奠定了坚实的基础。
然而,即使集成了外部感知,机器人仍然难以完全理解或利用地形特征。人类跑酷运动员可以利用环境特征突破自身固有的物理极限,例如利用墙面蹬地获得额外高度,到达原本无法企及的高度。这种策略性地利用地形特征完成超出执行器限制的运动任务的能力,仍然是当前腿式机器人面临的一项关键挑战。
为了使机器人能够穿越具有复杂几何特征的地形,近期的研究主要集中在运动过程中的落脚点规划上。这些方法通常采用分层框架,其中使用高层轨迹优化或基于学习的方法来根据地形信息规划所需的落脚点位置。规划好的落脚点随后作为底层跟踪策略的执行目标。这些方法已证明其能够在复杂的离散地形和可变形地形上实现稳健的运动能力[1]、[11]、[12]。然而,严格的落脚点跟踪本质上限制机器人的运动范围,并阻碍探索性策略学习。此外,对精确落脚点追踪的依赖需要高保真度的感知,这提出严格的感知要求,在高度动态且接触频繁的跑酷任务中,会显著加剧模拟与现实之间的差距,并阻碍其在现实世界中的应用。
机器人跑酷
四足机器人已通过基于模型的方法展现出敏捷的运动技能[13][14]。然而,这些方法依赖于精确的环境建模,并且在复杂、动态变化的场景中存在局限性。近年来,强化学习(RL)在跑酷任务中取得显著进展。Hoeller[7]采用一种分层框架,将运动控制和感知模块分开,从而实现在高度复杂地形上的导航。Cheng[3]和Zhuang[4]利用深度图信息,通过两阶段的师生结构来估计特权信息并提炼跑酷运动策略。Luo[2]进一步将双阶段方法集成到单阶段框架中,利用非对称的Actor-Critic网络来学习能够隐式地想象特权观测的跑酷策略。尽管取得这些进展,但在缺乏先验知识的情况下,仅仅依赖强化学习探索会限制对地形特征的策略性利用。
基于先验的运动
为了提高强化学习在运动任务中的探索效率,将运动先验融入学习框架已成为一种关键方法。一种常见的范式是利用参考轨迹结合模仿学习,使四足机器人能够获得敏捷和动态的行为[15][16]。然而,这些方法严重依赖于高质量的专家演示,这些演示通常通过运动捕捉系统或人工整理的数据集获得[17][18]。实际上,收集此类数据成本高昂且与特定任务相关,并且通常需要额外的处理或优化,例如轨迹滤波、重定向或基于优化的平滑处理[19][20]。这种依赖性限制可扩展性,并降低对新环境或任务的适应性。
基于落脚点的运动
近年来,一些研究方法直接将策略目标与明确的落脚点作为特定任务的目标。例如,Kim [1] 利用分层框架,结合基于采样的落脚点规划和基于学习的跟踪模块,实现在离散地形上的高速导航。Coholich [12] 利用高层策略,通过底层策略的值函数优化落脚点目标,无需额外训练。Jenelten [11] 利用轨迹优化生成优化的落脚点,并结合强化学习实现鲁棒跟踪。这些方法表明,落脚点可以有效提升机器人在复杂地形上的运动性能。然而,这种解耦框架通常需要高保真度的地形感知才能执行精确的落脚点跟踪,这使得实际部署变得复杂。
PUMA
本文提出一种名为PUMA的感知驱动统一落脚点先验框架,用于增强移动性的四足跑酷。与之前提到的方法不同,该方法并不显式地强制执行落脚点追踪。相反,采用以自我为中心极坐标落脚点作为速度追踪的运动先验,将显式坐标分解为相对距离和航向。通过融合深度感知和本体感知,PUMA估计极坐标落脚点并将其直接输入到执行器网络中。为了确保在这个统一的单阶段框架内稳定收敛,采用概率退火选择(PAS)方法,在训练过程中逐步从真实落脚点过渡到预测落脚点。在配备车载深度摄像头的模拟机器人和物理机器人上进行的大量实验表明,PUMA 能够稳健地穿越具有挑战性的离散地形,例如不平坦的踏脚石,并且允许机器人通过策略性地利用倾斜的墙壁来清除宽阔的缝隙,如图所示。
目标是训练一个端到端的速度跟踪低运动策略,该策略将来自机载深度摄像头的几何特征与本体感觉相结合,以在复杂地形上完成跑酷任务。为了解决部分可观测性问题,采用非对称的 Actor-Critic 架构 [21]、[22],如图所示。训练流程中的所有模块均并行优化,从零开始训练,不依赖预训练组件。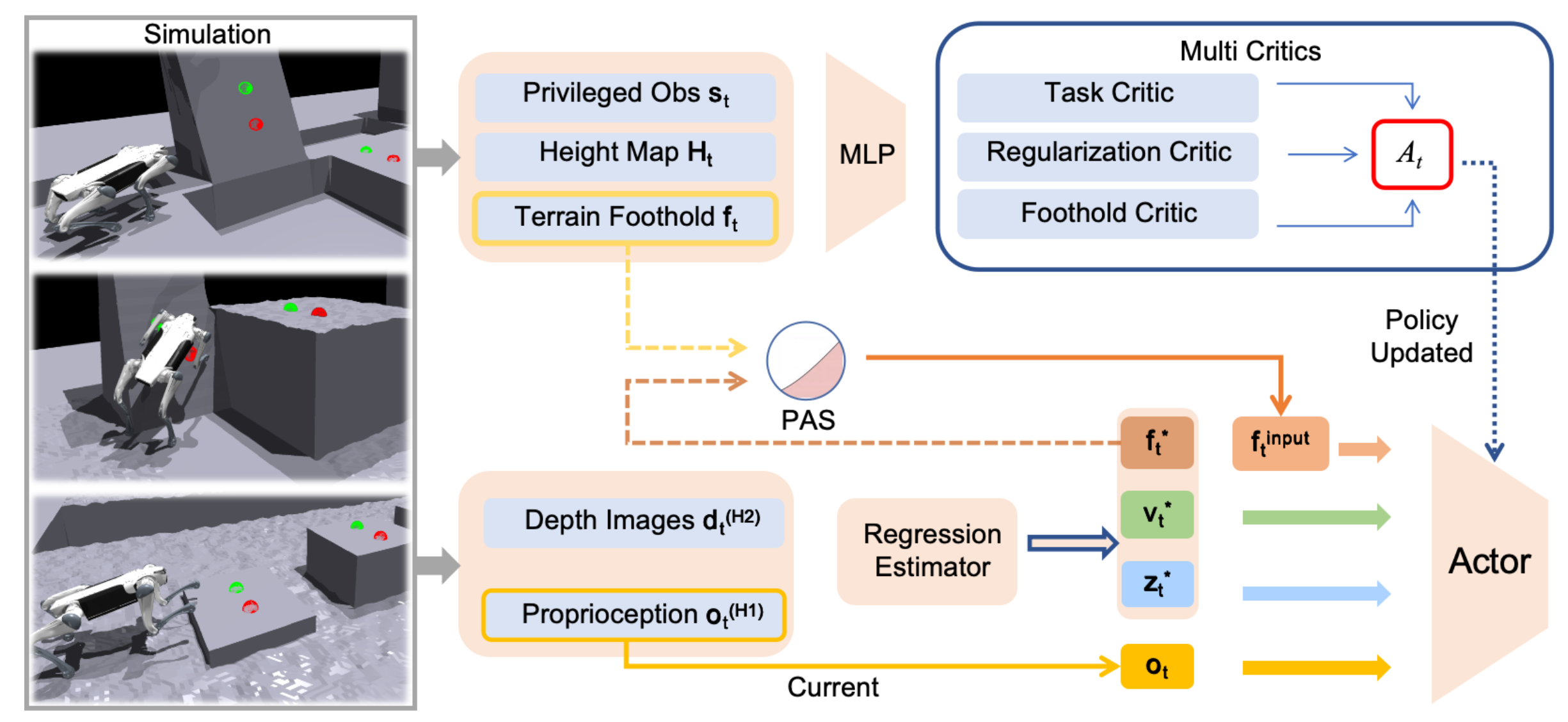
以自我为中心的落脚点先验设计
为了缓解在高维动作空间中探索效率低下的问题,以自我为中心的方式引入落脚点作为运动先验,而不是将其作为显式跟踪目标。
将候选落脚点序列表示为 {p_i},其中每个 p_i 表示世界坐标系中的笛卡尔坐标。这些候选落脚点沿机器人的指令方向以 1 米的间隔进行采样,覆盖平坦地形和可利用的倾斜墙壁的中心。由于立足点被用作引导先验信息而非明确的跟踪目标,因此无需进行复杂的运动学可行性检查。相反,过滤掉过于靠近危险边缘的点来确保安全性。
为了避免过多的足部引导影响策略学习方向,仅关注前脚。生成的序列中的坐标点被转换为极坐标表示,从而形成提出的以自我为中心立足点先验。
训练流程
与现有工作[11][12]通常采用分层框架分别处理落脚点生成和运动不同,本文采用一种基于非对称Actor-Critic架构[21][22]的统一单阶段方法。在该框架下,策略利用所提出的以自我为中心落脚点,直接学习复杂地形上的跑酷技能。策略网络使用近端策略优化(PPO)进行优化。
- 网络输入:策略网络接收本体感觉历史记录和深度图像缓冲区作为输入。每个本体感觉观测值包含角速度、重力矢量、指令、关节位置、关节速度和先前的关节目标位置。
critics网络拥有特权信息的访问权限,接收特权观测值、周围高度场和以自我为中心的真实立足点先验作为输入。
- 回归估计器:基于 Luo [2] 提出的隐式-显式估计器,扩展该架构,使其能够从部分观测数据中联合推断机器人的内部状态、环境特征和以自我为中心的立足点先验信息。
具体而言,首先使用卷积神经网络 (CNN) 对深度图像缓冲区进行编码。然后,将提取的视觉特征与本体感觉历史连接起来,形成一个token序列,并通过自注意机制进行处理。生成的序列被输入到门控循环单元 (GRU) 网络中进行时间建模,随后由多个独立的多层感知器 (MLP) 头进行回归,以估计以自我为中心的落脚点先验信息、基座速度和环境潜信息。
- 落脚点先验中的概率退火选择(PAS):当 Actor 网络从回归估计器接收估计的落脚点时,训练初期不可靠的先验会破坏策略的探索,显著阻碍学习过程。为了克服这一挑战,对落脚点输入应用 PAS 方法 [23],其中 Actor 以概率方式接收真实落脚点或估计器的预测值。关键在于,随着训练的进行,使用真实值的概率逐渐降低。在每个训练步骤中,根据退火概率采样一个均匀分布的随机变量,以决定是使用真实落脚点还是估计器的输出。
奖励与多评价
基于所提出的以自我为中心的极坐标立足点先验,设计一种复合奖励结构,该结构融合航向对齐、密集距离跟踪和稀疏到达分量。除了提供方向引导外,前足的参考落脚点还可以隐式地引导机器人调整其身体姿态,从而与地形建立有效的接触。只有当机器人左右前爪到各自预期落脚点的距离同时落在阈值ε内时,才会给予固定的稀疏奖励。
为了提高对混合稀疏和密集奖励的预期收益的估计[24],根据奖励类型将其分为不同的组,并采用多评价方法[25]–[27]独立估计每个奖励组的收益。每个critic网络都针对其对应的组独立进行优化,并使用时间差分(TD)损失函数。
为了适应多个奖励分量,采用了多critics(MuC))架构,其中每个critic估计与特定奖励项相关的优势。然后,将这些优势合并为一个统一的优势,用于策略优化。
地形与课程设计
如图所示,设计三种不同的地形,并在模拟中建立相应的课程。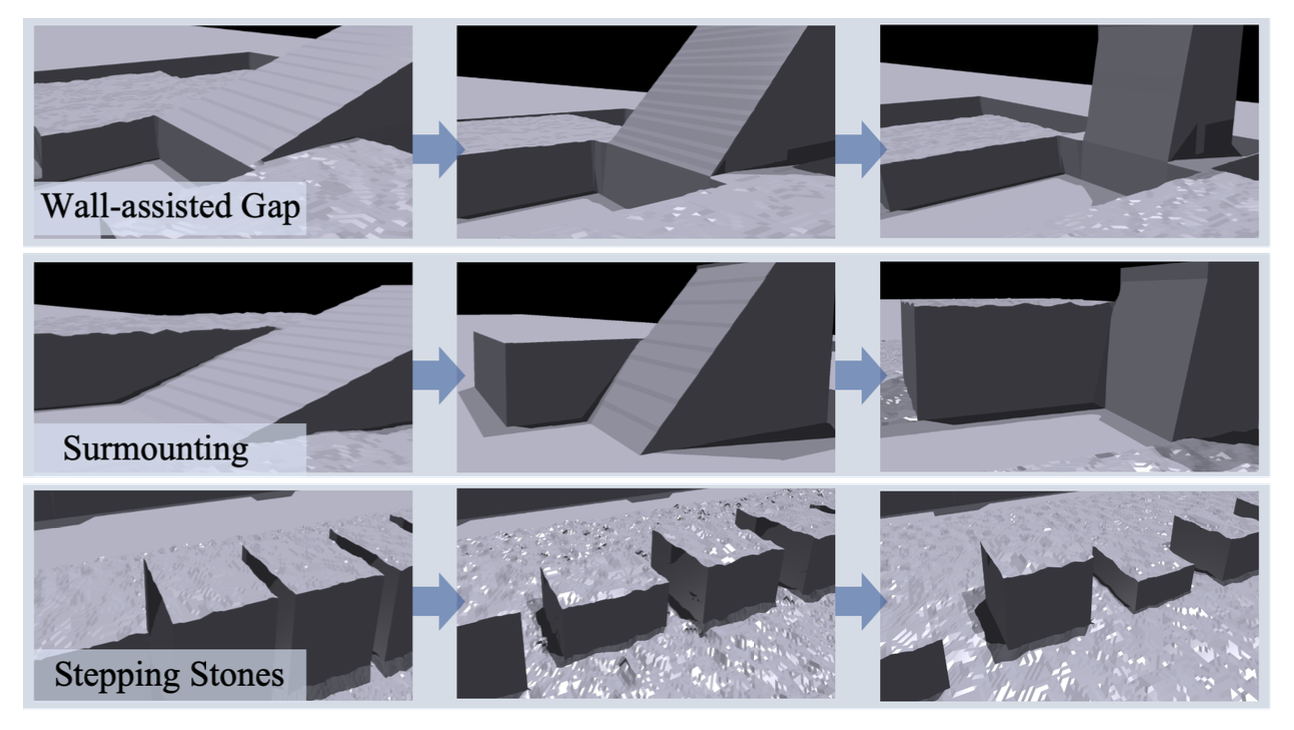
墙体辅助间隙:这种地形的特点是随机分布的间隙,每个间隙边缘都设有倾斜的踏步墙。随着课程的推进,间隙的宽度和踏步墙的倾斜度都会增加。
攀爬:这种地形由带有踏步墙的架高平台组成。平台的高度和踏步墙的倾斜度在整个课程中逐渐增加。
踏步石:这种地形由尺寸和高度各异的踏步石组成。随着课程级别的提升,踏步石之间的水平间距和垂直落差会增加,而长度和宽度则会减小。
实验设置
仿真训练。用 Isaac Gym 在单个 NVIDIA RTX 4090 GPU 上,对 12 自由度 DeepRobotics Lite3 机器人进行训练,训练环境涵盖 2048 个场景。整个强化学习过程无需任何预训练即可完成。为了在部署过程中最大限度地提高 GPU 内存效率,实现一个基于 NVIDIA Warp 的轻量级光线追踪深度渲染器。为了促进稳健的仿真-到-真实迁移,进一步对观测值和物理参数应用域随机化,并在视觉输入流中引入随机延迟。
真实部署。训练好的策略部署在 Lite3 机器人上,使用 RK3588 计算单元,推理频率为 50 Hz。网络输出关节级指令,这些指令通过增益 P = 20 和 D = 0.5 的 PD 控制转换为电机扭矩。深度观测由板载 Intel RealSense D435i 摄像头提供,深度帧更新频率为 10 Hz。
设计一系列实验来展示框架的有效性和改进之处,详情如下:
(a) 对落脚点设计的消融实验
无落脚点先验:机器人不接收任何落脚点先验作为输入。
无相对距离:落脚点先验仅包含偏航角分量,省略距离估计。
显式笛卡尔坐标先验:网络直接回归机器人坐标系中所需落脚点的显式笛卡尔坐标。
隐式笛卡尔坐标先验:机器人接收一个压缩的隐式落脚点潜信息,该信息由 MLP 解码器重构为笛卡尔坐标。
(b) 对概率退火选择(PAS)迭代的消融实验
• 无 PAS:在训练过程中移除 PAS 过程。
© critic 消融
• 无多critics(MuC):使用单个critic网络来估计所有奖励函数。
(d) 基线
PIE [2]:一个单阶段跑酷框架,使机器人能够穿越高台和缝隙。
Extreme Parkour [3]:一个两阶段跑酷训练框架,从教师策略中提炼出学生策略。在此直接使用教师策略,以绕过学生模仿学习的局限性。
为了确保在几种地形中对两个基线进行公平评估,在应用地形课程时,保留它们原始的奖励函数。
仿真实验
在几种地形上进行仿真实验,机器人的指令速度恒定为 1.5 m/s。使用以下两个指标来衡量不同策略的运动性能。
成功率 (SR):成功穿越整个地形段的概率。
穿越率 (TR):单次尝试中到达的最远距离与地形总长度的比值。
真实世界实验
在真实场景中评估提出方法的零样本迁移性能和消融效果。评估在每种地形上进行,每种方法均进行了 10 次试验。
此外,分析真实世界实验中遇到的失败案例。由于真实世界环境中存在多种噪声,踏步方法中显式笛卡尔先验和隐式笛卡尔先验的落脚点估计精度仍然不稳定,经常导致错误的起跳。这些误差主要表现为错误的身体姿态和接触墙壁时的相对高度不正确。虽然不考虑相对距离的方法无法调整身体姿态以利用地形特征,但值得注意的是,它在踏脚石地形上表现尚可。
不考虑多参数控制(MuC)的方法在实际应用中表现不佳:尽管它可以调整身体姿态,但始终无法与踏脚石墙建立有效的接触力,经常导致接触无效或擦碰。相比之下,本文方法成功地缓解了这些问题,展现出卓越的稳定性和鲁棒性。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 30
30 0
0- 0



 已为社区贡献209条内容
已为社区贡献209条内容

所有评论(0)