又一国产模型登Nature!Emu3统一全模态、扩展到世界模型和具身智能
去年9月,DeepSeek-R1的研究成果,作为封面文章登上了国际顶尖科学期刊《Nature》。花30万美元训练出来的国产AI模型,曾一度引发美股震荡。DeepSeek-R1用纯强化学习(pure reinforcement learning, RL) 激发了大语言模型的推理能力,无需依赖人类标注的思维路径,让AI自己学会推理,开启了2025推理模型新时代。就在刚刚,又一国产大模型登上Nature
去年9月,DeepSeek-R1的研究成果,作为封面文章登上了国际顶尖科学期刊《Nature》。

花30万美元训练出来的国产AI模型,曾一度引发美股震荡。
DeepSeek-R1用纯强化学习(pure reinforcement learning, RL) 激发了大语言模型的推理能力,无需依赖人类标注的思维路径,让AI自己学会推理,开启了2025推理模型新时代。
就在刚刚,又一国产大模型登上Nature!

北京智源人工智能研究院研发的Emu3,证实了“下一个Token预测”,足以统一多模态学习,无需依赖扩散模型或组合架构即可实现顶尖的图像视频生成与理解,以及机器人动作控制。
去年10月发布的Emu3.5基于相同技术,大幅提升了模型能力,用长达790年视频镜头,打造原生多模态世界模型!北京智源研究院用Emu3.5统一“世界”。
下一个Token预测统一多模态学习
Transformer和GPT-3推进了序列学习的规模化,统一了自然语言处理中的各种结构化任务。
多模态学习领域却长期处于碎片化状态。图像、视频和文本的跨模态任务通常依赖于分离的技术路线。
图像生成主要由扩散模型主导,视觉语言理解则依赖于将视觉编码器与大型语言模型结合的组合式框架。
这种组合方法虽然有效,但往往需要复杂的人工设计和对齐过程。
北京智源人工智能研究院的研究团队提出的Emu3,一个全新的多模态模型家族,完全基于下一个Token预测进行训练。
它彻底摒弃了扩散模型和组合式架构,将图像、文本、视频和机器人动作全部离散化为Token序列。
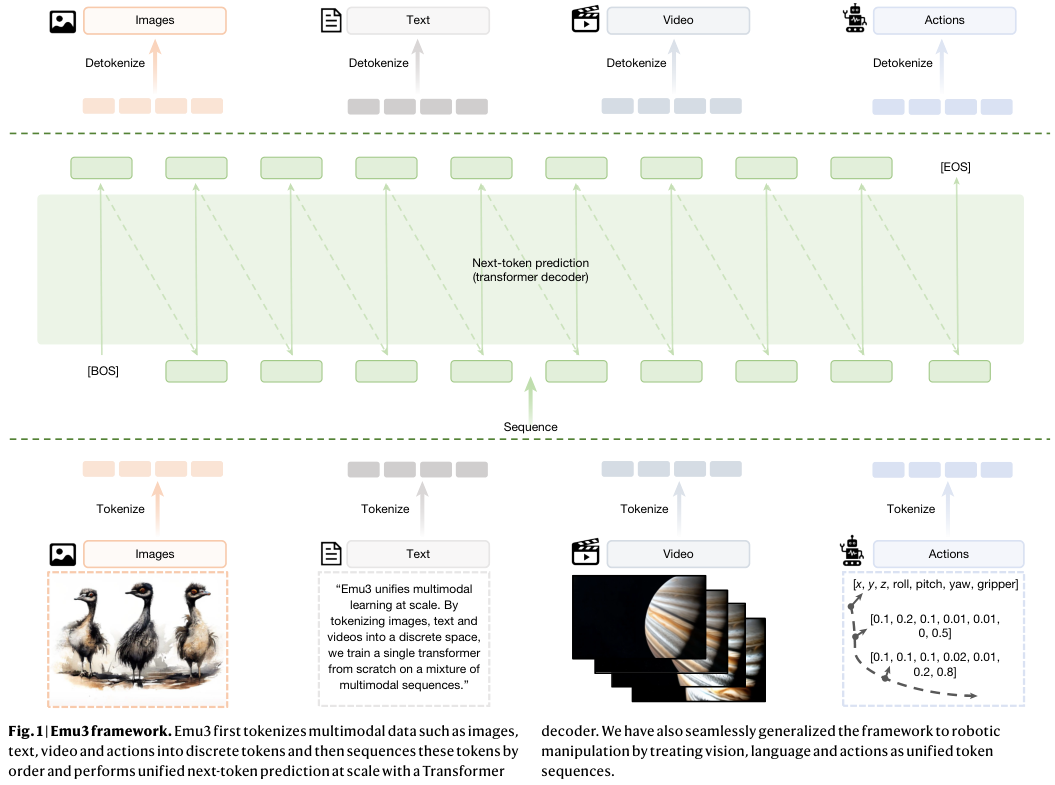
研究人员从零开始在一个混合的多模态序列上训练了一个单一的Transformer。
这种单一架构不仅能处理感知和生成任务,还能自然地扩展到视频生成和机器人控制。
Token按照顺序排列,形成一个长序列。Transformer解码器对这个序列执行统一的下一个Token预测。
这种方法消除了模态之间的隔阂,将所有任务简化为单一的预测问题。
在图像生成任务中,Emu3的表现与当时最先进的扩散模型相当。
在视觉语言理解任务中,它能够匹敌那些结合了CLIP和LLM的组合式模型。
Emu3在视频生成方面展现了高保真度和一致性。
与Sora不同,Sora通过从噪声开始的扩散过程合成视频。Emu3则通过自回归的方式预测视频序列中的下一个Token,以纯粹的因果方式生成视频。
这种生成方式更符合物理世界的因果逻辑。Emu3能够模拟环境、人物和动物在物理世界中的某些动态。给定一个视频上下文,Emu3可以预测接下来会发生什么。
这为构建能够理解和模拟物理世界的通用世界模型奠定了基础。
视觉离散化与解码器架构
如何将连续的视觉信号转化为离散的语言?
研究团队开发了一个统一的视觉分词器(Vision Tokenizer)。
这个分词器基于SBER-MoVQGAN架构。它能够将4×512×512的视频片段或512×512的图像编码为4096个离散Token。
分词器使用的码本大小为32768,在时间维度上实现了4倍压缩,在空间维度上实现了8×8的压缩。这种压缩策略适用于任何时间和空间分辨率。
研究人员在编码器和解码器模块中都加入了包含三维卷积核的时间残差层,使得分词器能够执行时间下采样,增强了视频的分词能力。
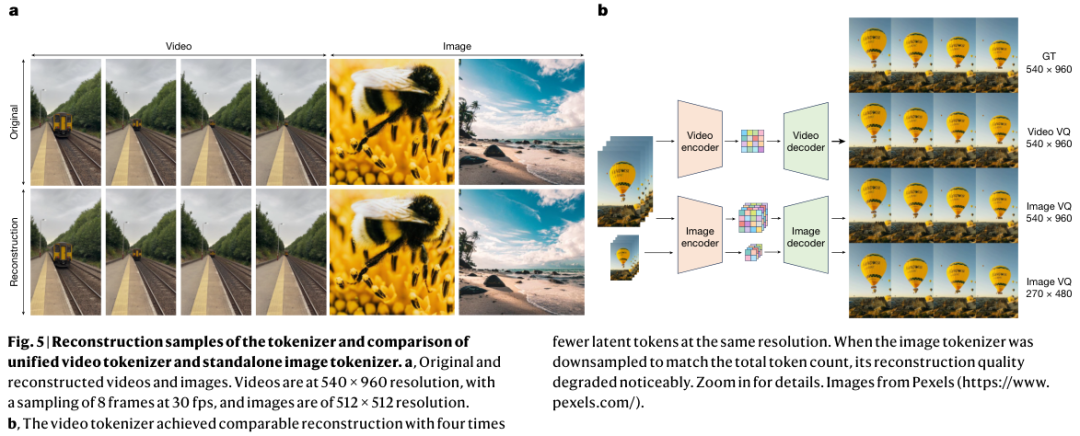
图中展示了视觉分词器的重建效果。
即便在压缩率很高的情况下,Emu3的视频分词器依然保持了极高的重建质量。
与仅处理图像的分词器相比,统一视频分词器在使用更少Token的情况下,依然能捕捉到精细的细节。
这种高效的离散化是Emu3能够处理长视频序列的关键。
Emu3的模型架构采用了仅解码器(Decoder-only)的Transformer。与Llama-2等成熟的大型语言模型保持了一致的架构框架。唯一的修改是扩展了嵌入层(Embedding Layer),以容纳离散的视觉Token。
为了提高训练稳定性,模型引入了0.1的Dropout率,使Emu3能够直接利用大语言模型社区积累的优化经验和基础设施。
模型不依赖任何预训练的视觉编码器(如ViT或CLIP)或语言模型,完全从零开始训练。挑战了长期以来的一个假设:多模态学习必须依赖强大的单模态预训练模型。
Emu3证明,在足够的数据和规模下,模型可以从头学会视觉和语言的联合表征。
训练数据包括图像、文本和视频的混合序列。图像和视频被调整大小至目标尺度,保持原始长宽比。
视觉内容被转化为离散Token,与文本标题交错排列。
为了区分不同模态和结构,序列中插入了特殊的Token,如[SOV](视觉开始)、[EOV](视觉结束)等。
这种文档式的序列格式将异构的多模态输入标准化为单一的Token流。
预训练分为三个阶段。
第一阶段使用较短的序列长度(5120),专注于图像和文本的学习,不使用Dropout。
第二阶段引入Dropout,以稳定优化并防止过拟合。
第三阶段将上下文长度扩展至65536,并引入视频数据。
在保证效率的同时,逐步提升了模型处理长序列和复杂模态的能力。
为了平衡跨模态的学习,视觉Token的损失权重被设定为0.5,略低于文本Token,防止了大量的视觉Token主导优化过程。
在预训练之后,模型还经历了后训练(Post-training)阶段。
对于视觉生成任务,使用了高质量数据进行微调(QFT)。
研究人员还将直接偏好优化(DPO)应用于自回归视觉生成。
DPO通常用于对齐语言模型与人类偏好。在Emu3中,DPO被用来优化生成图像的视觉吸引力和文本一致性。
模型生成候选图像,由人类标注者进行评分,形成偏好对。
通过最小化DPO损失,模型学会了生成更符合人类审美的图像。
对于视觉语言理解,模型经历了图像到文本(I2T)训练和视觉指令微调两个阶段。
扩展定律验证有效性
Emu3在科学上验证了多模态学习的扩展定律(Scaling Laws)。
研究团队受Chinchilla扩展定律的启发,对Emu3进行了大规模的分析。
他们发现,当在统一的下一个Token预测框架中联合训练时,文本生成图像(T2I)、图像生成文本(I2T)和文本生成视频(T2V)等任务都遵循共享的扩展行为。
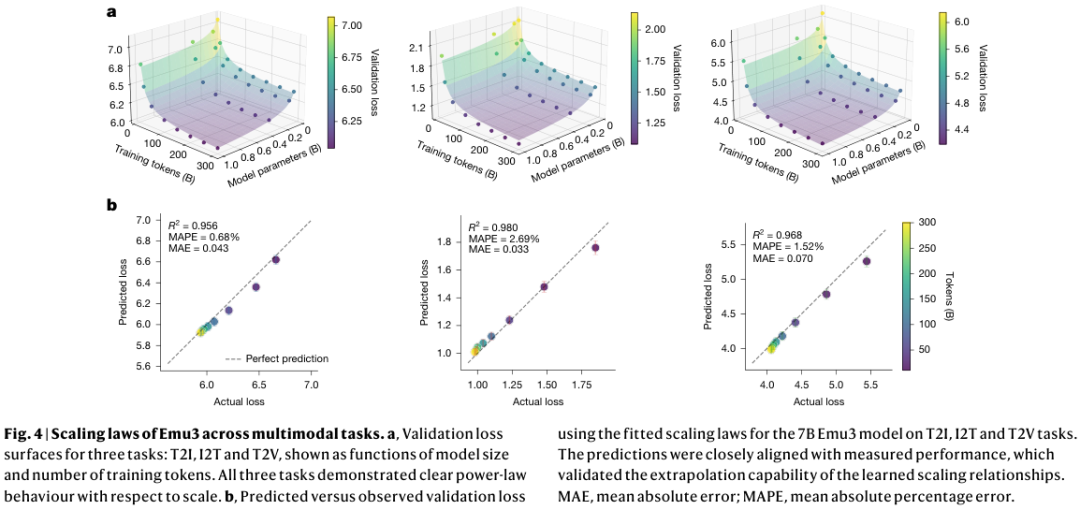
图中展示了Emu3在不同模态任务上的扩展定律。验证损失曲面显示了清晰的幂律行为。
统一多模态下一个Token预测训练遵循稳定且可预测的扩展动力学。这为在进行全规模训练之前准确预测模型性能提供了可能。
只要适当扩展,统一的下一个Token预测范式可以作为多模态学习的强大机制。消除了对复杂模态特定融合策略的需求。
研究人员将Emu3与当时的主流模型进行了对比。
在图像生成任务中,研究人员在OpenImages数据集上训练了1.5B参数的扩散Transformer和1.5B参数的解码器Transformer(Emu3架构)。
结果显示,下一个Token预测模型的收敛速度快于扩散模型。
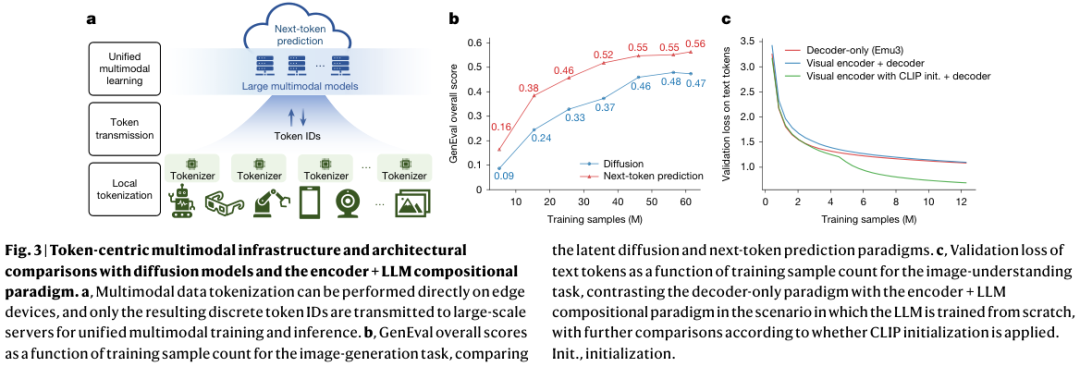
这挑战了“扩散架构在视觉生成方面天生优越”的普遍观念。
在视觉语言理解任务中,研究人员对比了Emu3架构与LLaVA风格的编码器-解码器架构。
当所有模型都从零开始训练(不使用预训练的CLIP或LLM)时,Emu3的表现与组合式架构相当。
表明组合式架构的优势主要来自于预训练的视觉编码器,而非架构本身。
在同等训练样本下,下一个Token预测模型在生成任务上的GenEval得分高于扩散模型。
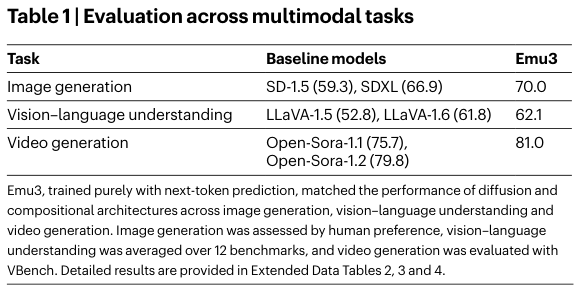
在图像生成方面,Emu3超越了SDXL。
在视觉语言理解方面,Emu3匹敌了LLaVA-1.6。
在视频生成方面,Emu3优于Open-Sora-1.2。
这些结果证明,Emu3在感知和生成任务上都达到了与当时成熟任务特定模型相当的水平。
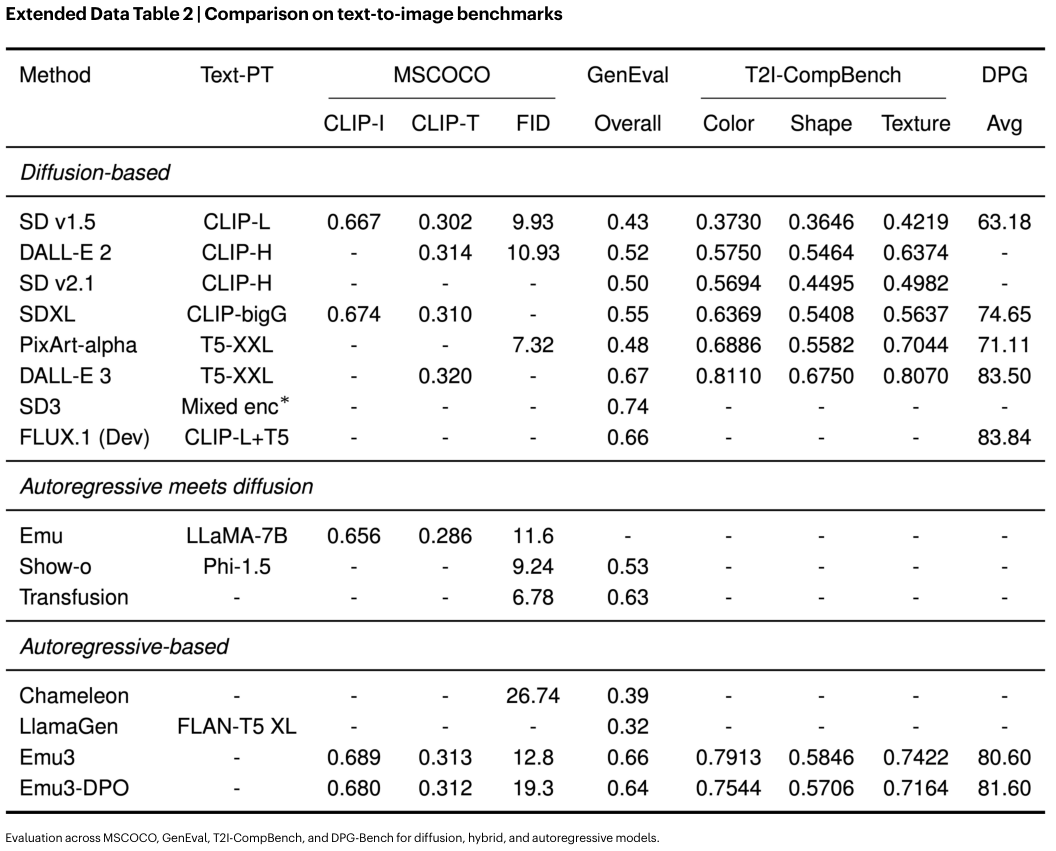
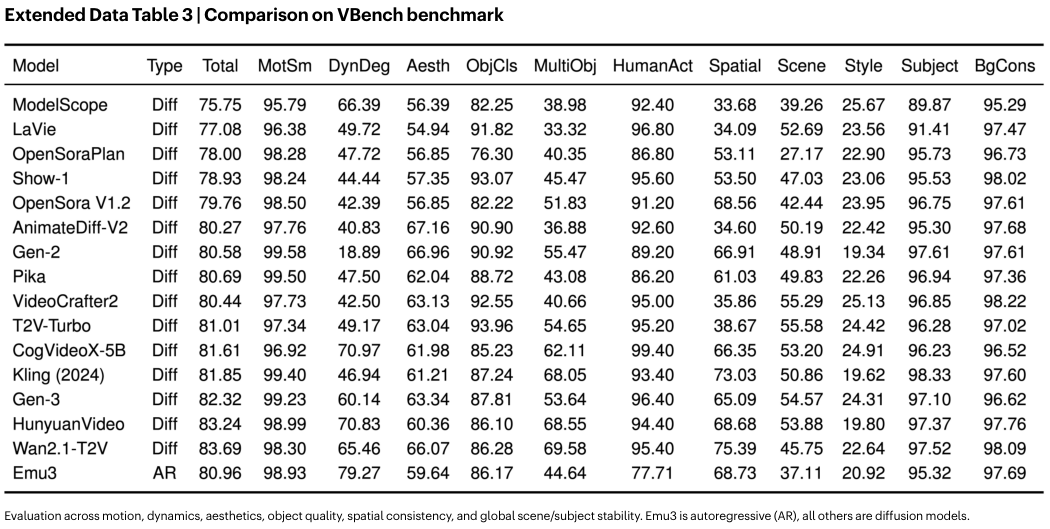
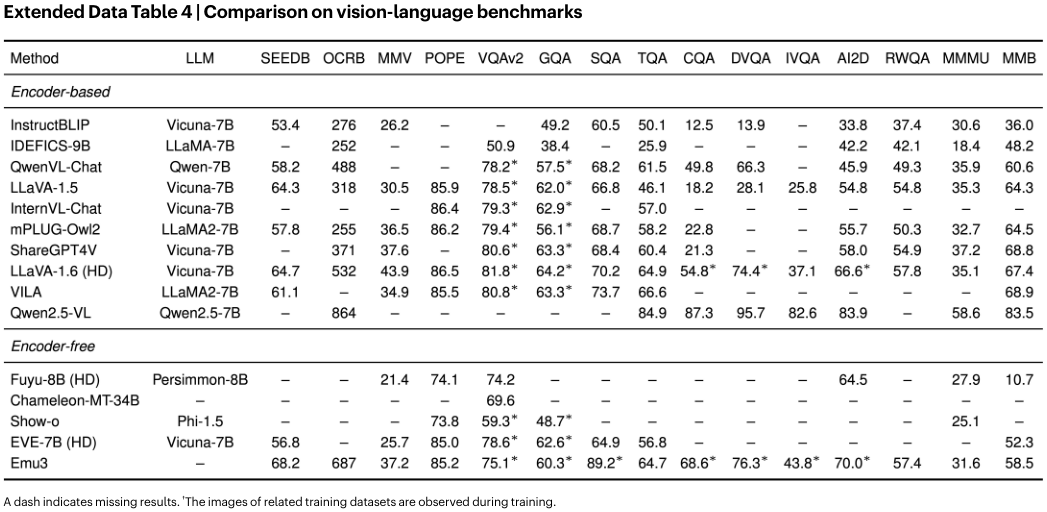
Emu3在无需扩散模型的情况下,取得了极具竞争力的成绩。
特别是在经过DPO优化后,Emu3在多个指标上都有显著提升。
从视频生成到具身智能
Emu3的统一架构使其具备了极强的通用性和扩展性。
视频被视为图像的时间序列。通过预测未来的帧来生成或延长视频。
它可以基于给定的视频上下文,预测随后发生的事件。
这包括人物和动物的动作、与真实世界的互动以及三维动画的变化。
由于采用自回归生成,Emu3可以迭代地生成超出其上下文长度的视频。
它不受固定长度的限制,理论上可以生成无限长的视频流。

无论是图像生成、视频预测,还是图文交错生成,Emu3都展现出了高质量和一致性。
在图文交错生成任务中,模型可以生成包含插图的结构化文本步骤。
例如,“如何制作水芹炒腊肠”的教程,每一步文本都配有相应的生成图像。
这种能力得益于模型在混合模态序列上的端到端微调。
Emu3甚至被扩展到了机器人控制领域。
在机器人操作中,视觉观察、语言指令和动作都被视为离散的Token。
动作通过FAST分词器进行离散化,转化为控制信号。
模型在一个统一的序列中处理视觉、语言和动作Token。
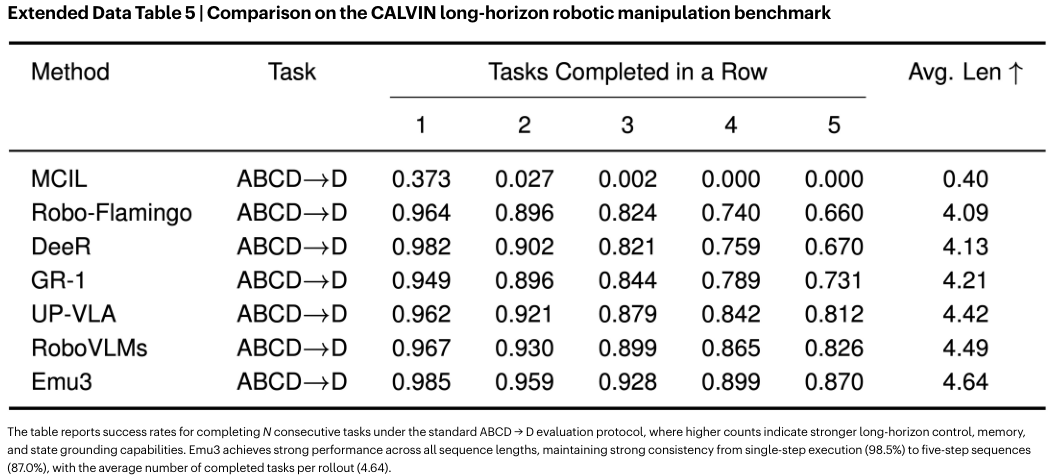
Emu3在CALVIN机器人操作基准上,长视野操作任务中表现优异。
它能够连续完成5个任务,平均序列长度达到4.64,超过了专门设计的RoboVLMs等模型。
这证明了下一个Token预测可以作为一个通用的框架,无缝地从感知、生成扩展到具身决策。
模型可以自然地处理任意长度的历史信息,整合反馈,并在传感器输入不完美的情况下依然有效工作。
为了展示模型的灵活性,研究人员还测试了不同的Token预测顺序。
除了标准的扫描线顺序,模型还可以适应对角线、块状光栅和螺旋向内的顺序。
特别是螺旋向内的顺序与图像修复任务非常契合。

Emu3可以通过改变预测顺序实现零样本图像修复。
只需将预测顺序改为从外向内螺旋,模型就能自动填补图像中的遮挡区域。
这种能力无需专门的任务微调,完全源于预训练学到的先验知识。
简单的下一个Token预测不仅适用于语言,也完全适用于视觉世界。
通过统一的离散化和单一的Transformer架构,为未来的多模态助手、世界模型和具身人工智能开辟了一条清晰而高效的道路。
参考资料:
https://www.nature.com/articles/s41586-025-10041-x

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 30
30 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)