西湖大学强化学习第一讲——基本概念
入职新公司,主要做具身智能,因为之前对强化学习了解的比较少,所以现在开始系统性地学习强化学习。之所以要记笔记,是因为授课老师的PPT都是英文,复习的时候很难快速把知识点装回到脑袋里,只有把学到的知识用自己语言整理一遍,并记录成文档,才更方便复习。
基本概念
0 前言
入职新公司,主要做具身智能,因为之前对强化学习了解的比较少,所以现在开始系统性地学习强化学习。之所以要记笔记,是因为授课老师的PPT都是英文,复习的时候很难快速把知识点装回到脑袋里,只有把学到的知识用自己语言整理一遍,并记录成文档,才更方便复习。
1 课程示例与基本概念
1.1 贯穿课程的网格示例
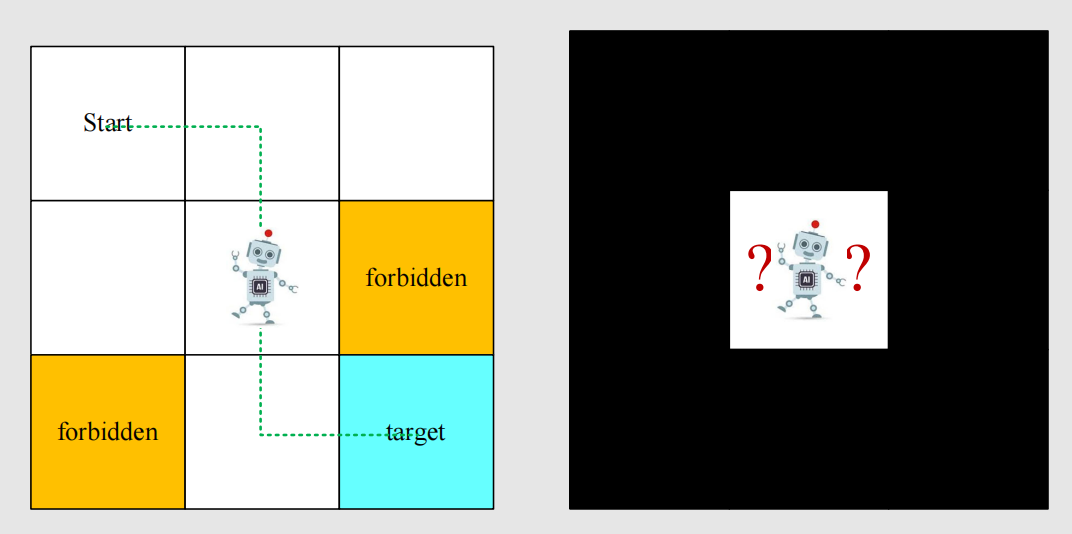
上面左图是一个九宫格,有三种格子,分别是可到达(Accessible)、禁止(Forbidden)、目标(Target),四周是边界(Boundary),这个九宫格就是智能体(图中的机器人)的所有活动范围,即“世界”(Grid-World)。智能体从 start 的位置出发,找到一条移动到 target 的路径,这是智能体要完成的任务。
强化学习研究的内容是:(1)找到从 start 到 target 的路径;(2)评价路径的好坏。
1.2 关于状态(State)
状态是智能体相对于环境而言的,在上面的图示中,状态就是智能体所在的位置。网格世界有9个格子,因此有9种状态,状态用小写字母 s s s 表示,对不同状态进行标号,比如在 start 位置,可以用 s 1 s_1 s1 表示,在 target 位置,可以用 s 9 s_9 s9 表示。 我们把状态符号填写到对应的网格中,则如下所示: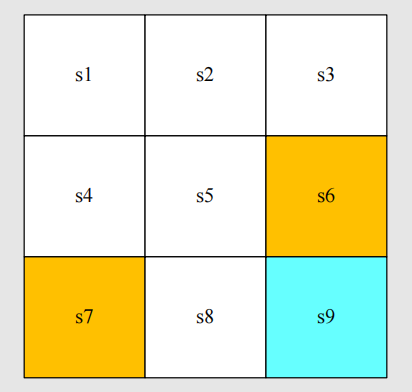
把所有可能的状态放到一个集合中,则构成了一个状态空间(State space),用符号表示为: S = { s i } i = 1 9 S=\{s_i\}^{9}_{i=1} S={si}i=19。
1.3 动作(Action)
智能体会基于当前状态,做出动作,如果把上图中,每一个状态下的所有可能动作都列出来,那么就有5种,即上、下、左、右和静止。动作也可以用小写字母 a a a 表示,对不同动作进行编号(按顺时针标号),那么有: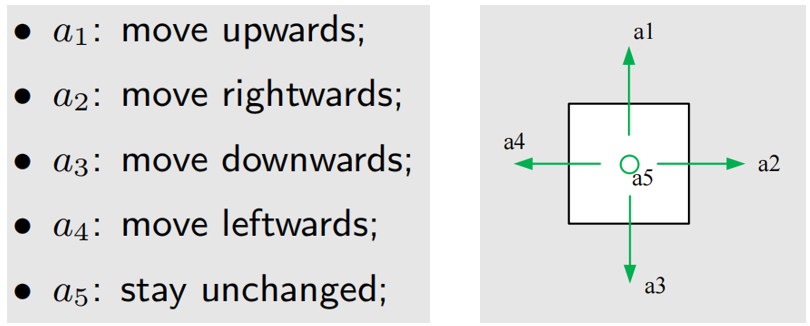
把某一状态下的所有可能动作放到一个集合种,就构成了一个动作空间(Action space),上图的环境,每个状态都有5种可能动作,用符号表示为: A ( s i ) = { a k } k = 1 5 A(s_i)=\{a_k\}^{5}_{k=1} A(si)={ak}k=15。
1.4 状态转移(State transition)
智能体每执行一个动作,就有可能发生状态转移,从一个状态变成另一个状态,用符号表示如下:
s 1 → a 2 s 2 s_1 \overset{a_2}{\rightarrow} s_2 s1→a2s2
当然,也存在做出动作后,状态不发生转移的情况,如:
s 1 → a 1 s 1 s_1 \overset{a_1}{\rightarrow} s_1 s1→a1s1
对于禁止区域,我们定义其是可以进入,但会收到惩罚,所以有:
s 5 → a 2 s 6 s_5 \overset{a_2}{\rightarrow} s_6 s5→a2s6
在 Grid-World 中,我们可以用表格来表示状态迁移,用行表示所处状态,用列表示接下来准备执行的动作,并把迁移的结果输入到表格中,表格如下: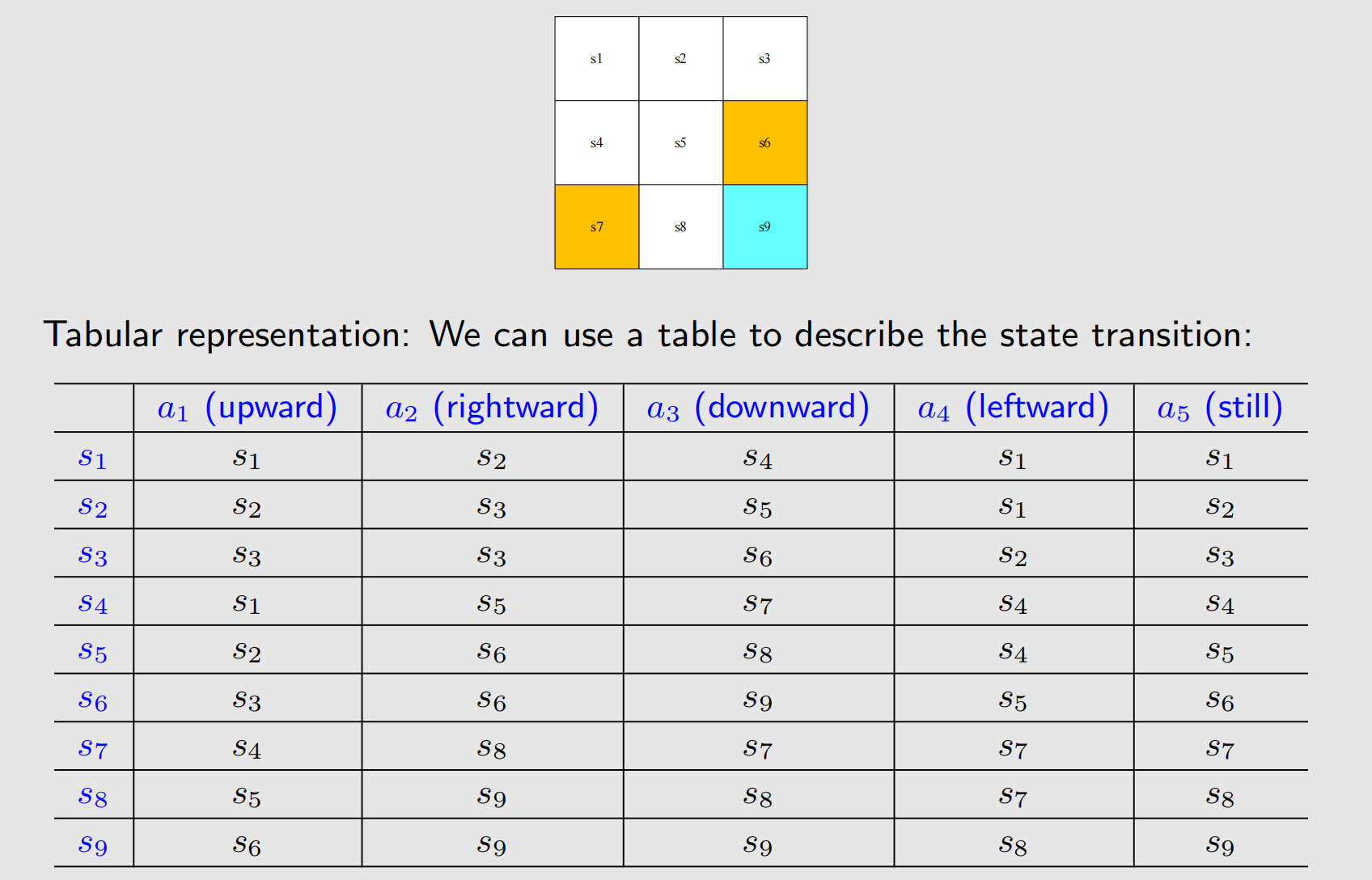
当然,能用表格展示的案例,一般都是比较简单,并且是确定性的。
对于非确定性的状态迁移,你在当前状态下执行一个确定性动作,下一个状态是随机的,假如我们定义撞墙后会反弹,反弹一个格子的概率是0.5,反弹两个格子的概率是0.3,原地不动的概率是0.2,那么这种情况下就无法用表格来表示。此时可以用公示表示:
p ( s 2 ∣ s 1 , a 4 ) = 0.5 p ( s 3 ∣ s 1 , a 4 ) = 0.3 p ( s 1 ∣ s 1 , a 4 ) = 0.2 p(s_2\mid s_1, a_4)=0.5 \\ p(s_3\mid s_1, a_4)=0.3 \\ p(s_1\mid s_1, a_4)=0.2 \\ p(s2∣s1,a4)=0.5p(s3∣s1,a4)=0.3p(s1∣s1,a4)=0.2
当然,确定性的状态转移也是可以用概率公示表示,例如: p ( s 2 ∣ s 1 , a 2 ) = 1 p(s_2\mid s_1, a_2)=1 p(s2∣s1,a2)=1。
1.5 策略与轨迹(Policy and Trajectory)
所谓策略,指的是在什么状态下执行什么动作,比如,在 s 1 s_1 s1 的状态下,有5个动作可选,你选哪个,这个就是你的策略,说白了,就是“从多个选项中选择一个”。在强化学习中,策略是“行为的准则”,而轨迹则是“经历的过程”,一个是逻辑法则,一个是既成事实。
假如已经给智能体在所有状态下,都提前设定好了策略,那么一旦知道了智能体的起点,就可以得到智能体的轨迹,如下图所示: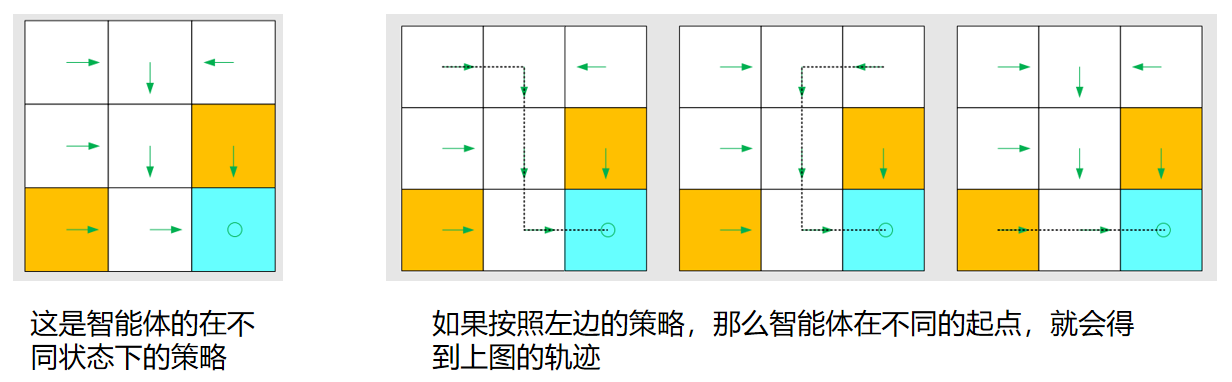
上面的情况是确定性策略,有些情况下,我们给智能体制定的策略有可能是随机的,比如:在 s 1 s_1 s1 的状态下,智能体既可以往右,也可以向下,两个方向的概率各为0.5,那么最后得到的轨迹如下图所示:
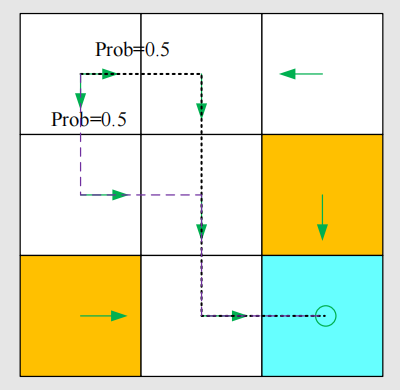
此时可以用公示表示:
π ( a 1 ∣ s 1 ) = 0 π ( a 2 ∣ s 1 ) = 0.5 π ( a 3 ∣ s 1 ) = 0.5 π ( a 4 ∣ s 1 ) = 0 π ( a 5 ∣ s 1 ) = 0 \pi(a_{1}|s_{1})=0 \\ \pi(a_{2}|s_{1})=0.5 \\ \pi(a_{3}|s_{1})=0.5 \\ \pi(a_{4}|s_{1})=0 \\ \pi(a_{5}|s_{1})=0 π(a1∣s1)=0π(a2∣s1)=0.5π(a3∣s1)=0.5π(a4∣s1)=0π(a5∣s1)=0
对于不同状态下的策略,也是可以使用表格来表示的,无论是确定性策略,还是随机策略: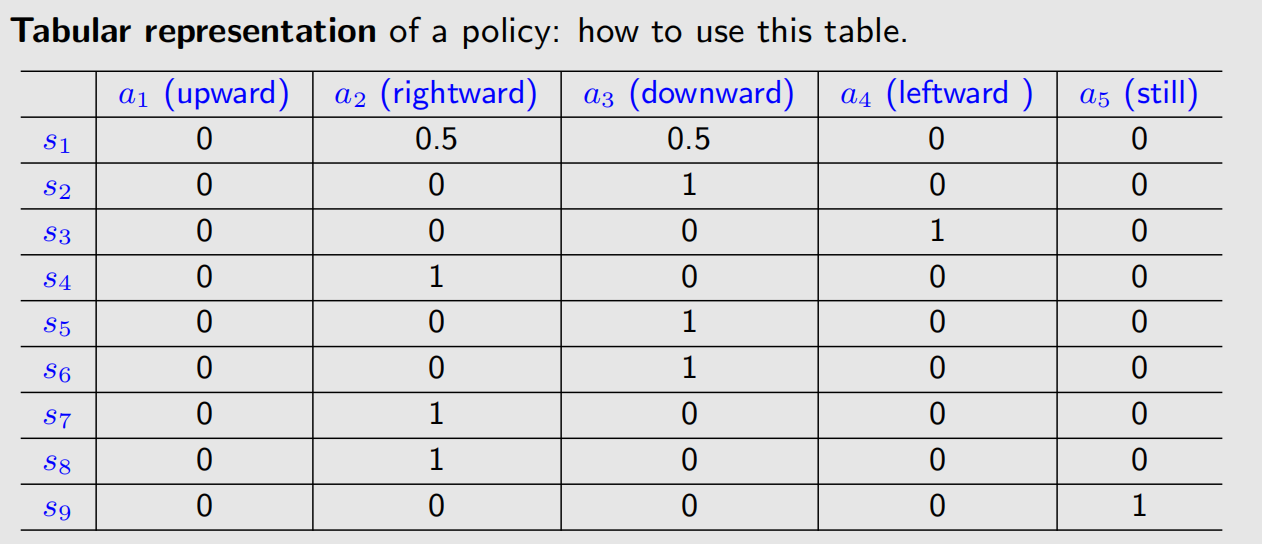
1.6 奖励与回报(Reward and Return)
当智能体做出了行动之后,就会获得奖励(Reward),一般用小写字母 r r r 表示,奖励有可能是正的,也有可能是负的。
奖励的相对值比绝对值更重要,假设智能体在某个状态下只有两个动作,那么 r = { 1 , − 1 } r=\{1, -1\} r={1,−1} 和 r = { 2 , 0 } r=\{2, 0\} r={2,0} 不影响最后得到的策略。
在网格世界(Grid-World)示例中,可以奖励设计如下:
- 若智能体试图越出边界,令 r bound = − 1 r_{\text{bound}} = -1 rbound=−1
- 若智能体试图进入禁止单元格,令 r forbid = − 1 r_{\text{forbid}} = -1 rforbid=−1
- 若智能体到达目标单元格,令 r target = + 1 r_{\text{target}} = +1 rtarget=+1
- 其他情况下,智能体获得的奖励为 r = 0 r = 0 r=0
奖励可被理解为人机交互界面,通过它我们可以引导智能体按照我们的期望行事。例如,通过上述设计的奖励,智能体会尽量避免越出边界或踏入禁止单元格。
奖励也可以用数学表达式表示:
p ( r = − 1 ∣ s 1 , a 1 ) = 1 a n d p ( r ≠ − 1 ∣ s 1 , a 1 ) = 0 p(r=-1\mid s_1, a_1)=1 \quad and \quad p(r\ne-1\mid s_1, a_1)=0 p(r=−1∣s1,a1)=1andp(r=−1∣s1,a1)=0
当然,如果奖励也有可能是概率,也就是说,当你在某个确定状态下做出某个确定动作,奖励有可能是不确定的。
轨迹可以用“状态-动作-奖励”三元组构成的链条来表示:
s 1 → r = 0 a 2 s 2 → r = 0 a 3 s 5 → r = 0 a 3 s 8 → r = 1 a 2 s 9 s_{1} \xrightarrow[r=0]{a_{2}} s_{2} \xrightarrow[r=0]{a_{3}} s_{5} \xrightarrow[r=0]{a_{3}} s_{8} \xrightarrow[r=1]{a_{2}} s_{9} s1a2r=0s2a3r=0s5a3r=0s8a2r=1s9
回报(return)是整个轨迹上的奖励之和,例如上述轨迹的回报是: r e t u r n = 0 + 0 + 0 + 1 = 1 return = 0 + 0 + 0 + 1 = 1 return=0+0+0+1=1
基于策略可以得到轨迹,基于轨迹可以得到回报,而回报可以用来评估轨迹的好坏,从而评估策略的优劣。
1.7 折扣回报(Discounted return)
如果你同学欠你一万块钱,他现在提出两种还款方案,方案一:每个月还一千,分十个月还清;方案二:一次性还完一万。我想,绝大多数人都会考虑方案二,因为在总收益不变的情况下,大家都想落袋为安,防止夜长梦多。
对于未来的收益,需要考虑一定的风险,所以需要对未来的收益乘以一个风险系数,比如0.8、0.9。拖得时间越久,不确定性也就越大,风险也就越高,所以一个月后还你一千,和两个月后还你一千,虽然表面上看,收益是一样的,但风险却完全不同。
假设每期的风险系数是0.9,如果你同学今天先还你一千,剩下的钱每个月还你一千,直至还款结束。那么今天还你的一千不需要考虑风险,一个月后的一千需要考虑一个月的风险,也就是说,下个月的一千,折算到今天的收益是900;而两个月后的一千,需要考虑两个月的风险,你要先折算到下个月(折算后的值为900),再折算到这个月,也就把下个月的折算值再折算一下,那么就是810,以此类推。
那么你的总收益的数学期望是:
1000 + 0.9 × 1000 + 0.9 2 × 1000 + 0.9 3 × 1000 + . . . + 0.9 9 × 1000 ≈ 6513.22 1000+0.9 \times 1000+0.9^2 \times 1000+0.9^3\times 1000+ ... +0.9^9\times 1000 \approx 6513.22 1000+0.9×1000+0.92×1000+0.93×1000+...+0.99×1000≈6513.22
在强化学习中,风险系数被称为折扣率(Discount rate),使用折扣率计算得到的回报(数学期望)被称为折扣回报(Discount return)。
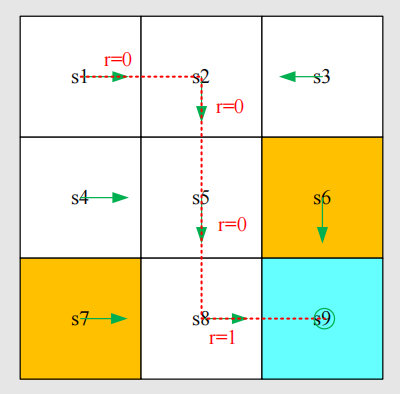
假设折扣率为0.9,那么上面的策略(轨迹)的折扣回报为 0 + 0.9 × 0 + 0.9 2 × 0 + 0.9 3 × 1 = 0.729 0+0.9\times0+0.9^2\times0+0.9^3\times1=0.729 0+0.9×0+0.92×0+0.93×1=0.729
1.8 回合(Episode)
在某些状态下,智能体将停止做出新动作的状态,被称为终止状态(terminal state),从起始状态到终止状态,形成的轨迹被称为一个“回合”(Episode)。
有些任务没有终止状态,意味着智能体与环境的交互会一直进行下去,不会结束,这种任务被称为持续性任务(continuing tasks)。与持续性任务相对的,则是回合性任务(episode tasks)。
在网格世界(Grid-World)中,当智能体到达 target 的位置时,若停止发出新的动作,则为回合性任务,若继续发出新的动作(比如 a 5 a_5 a5,即一直原地打转,同时假设在 target 原地打转的奖励为 r=1),则是持续性任务。本课程的后续内容,将网格任务当成持续性任务。
2 马尔可夫决策过程
马尔可夫决策过程(Markov decision process,MDP)是研究如何在部分随机、部分受控的环境中进行序贯决策的数学模型,是强化学习领域的核心框架。
2.1 组件要素
马尔可夫决策过程包含的组件要素包括:状态( S S S)、动作( A ( s ) A(s) A(s))和奖励( r r r)。
2.2 随机性来源
当智能体处于状态 s k s_k sk 时,随机性存在于三个方面(下面黑体加粗部分表示向量):
(1)策略,即下一步该采取什么动作,这个是随机的,概率分布为 π ( a ∣ s k ) \boldsymbol \pi(\boldsymbol a|s_k) π(a∣sk),这里 a \boldsymbol a a 不是一个标量,而是一个向量,表示每种动作的概率;
(2)状态转移,并不是说你在什么状态下采取了什么动作,就能预知结果了,它也可能时随机性的,概率分布为 p ( s ′ ∣ s k , a ) \boldsymbol p(\boldsymbol s'\mid s_k, a) p(s′∣sk,a),这里 a a a 是标量,表示某一确定的动作,而 p ( s ′ ∣ s k , a ) \boldsymbol p(\boldsymbol s'\mid s_k, a) p(s′∣sk,a) 是向量,表示每个状态的概率;
(3)奖励,与状态转移类似,并不是说你在什么状态下采取了什么动作,就能得到确定的奖励,即便你知道了当前状态、下一步采取的动作、状态会转移成什么,你也无法知道奖励是多少,概率分布为:概率分布为 p ( r ∣ s k , a ) \boldsymbol p(\boldsymbol r\mid s_k, a) p(r∣sk,a),奖励与下一时刻的状态无关。
2.3 马尔可夫的遗忘特性
所谓遗忘特性,指的是下一步的概率,只和当前时步的状态和动作有关,和前面时步的状态和动作无关,用条件概率公示表示如下:
p ( s t + 1 ∣ a t , s t , … , a 0 , s 0 ) = p ( s t + 1 ∣ a t , s t ) p ( r t + 1 ∣ a t , s t , … , a 0 , s 0 ) = p ( r t + 1 ∣ a t , s t ) p\left(s_{t+1} \mid a_{t}, s_{t}, \ldots, a_{0}, s_{0}\right)=p\left(s_{t+1} \mid a_{t}, s_{t}\right) \\ p\left(r_{t+1} \mid a_{t}, s_{t}, \ldots, a_{0}, s_{0}\right)=p\left(r_{t+1} \mid a_{t}, s_{t}\right) p(st+1∣at,st,…,a0,s0)=p(st+1∣at,st)p(rt+1∣at,st,…,a0,s0)=p(rt+1∣at,st)
2.4 马尔可夫决策过程与马尔可夫过程(Markov decision process & Markov process)
如果用圆圈表示状态,用箭头表示状态迁移,那么可以将网格世界按照如下图所示进行抽像: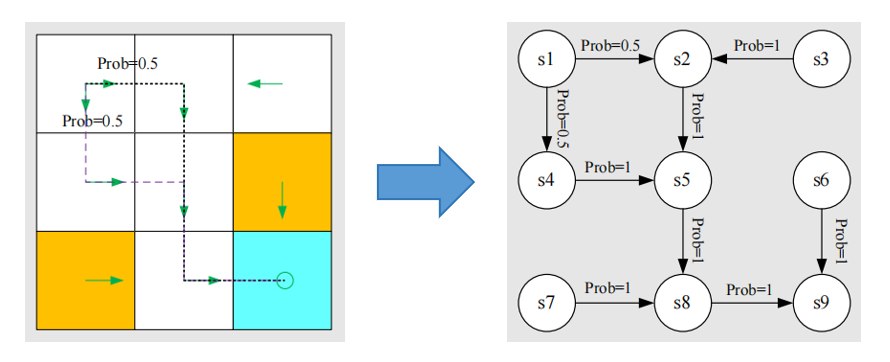
上面右图所示,即为马尔可夫过程。马尔可夫过程只有状态和状态转移概率,没有动作和奖励。
马尔可夫过程(Markov Process, MP)相比于马尔可夫决策过程(Markov decision process, MDP),没有决策,即你只能观察它从一个状态跳到另一个状态,而无法干预。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)