ICLR 2026中稿工作VLASER: 究竟哪些多模态能力和数据对提升机器人的控制表现最关键?
本研究提出了 Vlaser,一种协同具身推理与端到端控制的基础视觉-语言-动作模型,并通过构建 Vlaser-6M 数据集在 13 项具身推理基准中实现了 SOTA 性能。通过系统性的消融实验,我们揭示了 VLM 向 VLA 迁移的关键定律:通用的多模态具身推理能力与底层控制性能无显著正相关,而缩短感知数据与真实机器人视角之间的域差距才是提升控制成功率的决定性因素。
一、背景和研究动机
在具身智能(Embodied AI)的浪潮中,研究界致力于将强大的视觉-语言模型(VLM)转化为具备机器人操控能力的 Vision-Language-Action (VLA) 模型 。然而,这一转化过程面临着一道巨大的“鸿沟”:上游 VLM 通常依托海量互联网数据预训练,拥有卓越的通用推理能力;而下游 VLA 却需要在具体的物理环境中实现精准的动作控制 。
目前的现状是:即便 VLM 的通用推理能力很强,在迁移至机器人控制任务时,效果往往不如人意 。这引发了一个核心问题:究竟哪些多模态能力和数据对提升机器人的控制表现最关键? 是堆砌更多的通用问答数据,还是专注于特定的域内(机器人第一视角)的多模态推理数据 ?
为解答这一疑问,来自中国科学技术大学、上海人工智能实验室、上海交通大学等机构的研究团队,在 ICLR 2026 发表了最新成果:Vlaser (Vision-Language-Action Model with Synergistic Embodied Reasoning) 。Vlaser 不仅是一个具备协同具身推理能力的 VLA 模型,更是一项关于“如何高效构建机器人大脑”的系统性研究 。团队通过构建高质量的 Vlaser-6M 数据集,在 13 个上游具身推理(Embodied Reasoning)基准测试中取得了最优效果 。
同时,通过将 VLM 在不同配比的 Vlaser-6M 数据集上微调并作为 VLA 训练的初始化权重,研究团队揭示了一个关键洞见:相比于通用的多模态推理数据,缩短感知与推理数据与真实机器人视角的‘‘域差距(Domain Gap)”,才是提升 VLA 性能的核心 。特别地,针对特定具身第一视角的域内(In-domain)数据进行预训练的 VLM,对下游 VLA 的后训练收敛和成功率提升有显著增益 。
由于利用自动化标注管线,针对域内机器人场景生成的 VQA 数据具有低成本、标准化的优势,这一发现很大程度上缓解了 VLA 后训练对大量真机遥操轨迹数据的依赖,为从 VLM 预训练到 VLA 后训练的迁移提供了一种高效的数据范式 。训练数据、自动化标注管线、模型和代码均已开源或即将开源 。
- 论文链接:https://arxiv.org/pdf/2510.11027v2
- 项目主页:https://internvl.github.io/blog/2025-10-11-Vlaser/
- 代码开源:https://github.com/OpenGVLab/Vlaser
二、核心设计与数据引擎
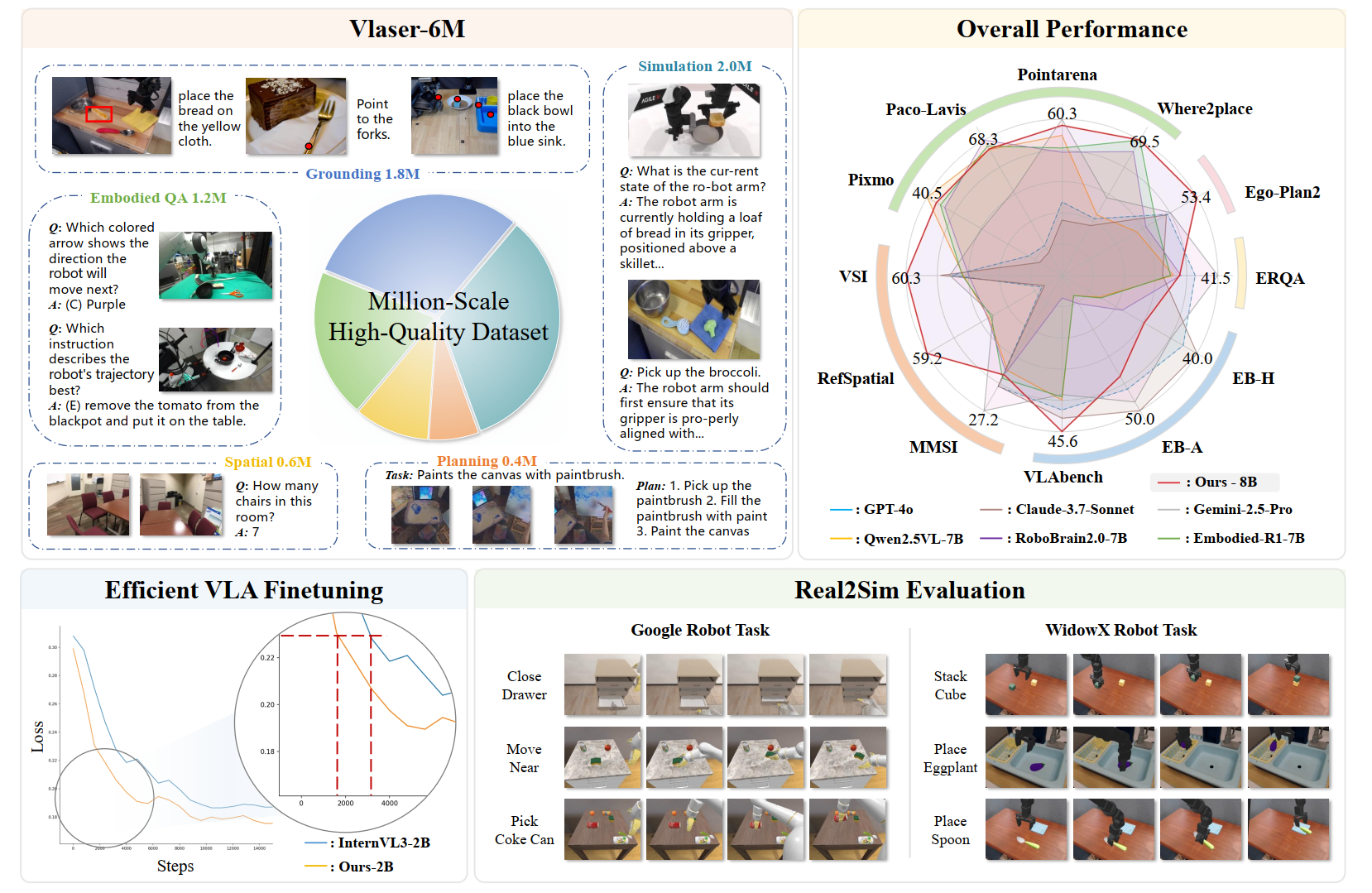
1. Vlaser-6M 数据引擎:百万级高质量数据
为了武装机器人的大脑,研究团队构建了包含 600 万条数据的数据引擎,覆盖了具身智能所需的三大核心能力 :
-
具身定位(Embodied Grounding): 包含 150 万条高质量问答对,支持 Bounding Box 和中心点定位,让机器人“看得准” 。
-
空间智能(Spatial Intelligence): 整合了 120 万条 RoboVQA 和 50 万条空间推理数据,增强机器人对三维空间关系的理解 。
-
任务规划(Planning): 包含 40 万条规划数据,训练机器人将复杂指令拆解为可执行的子步骤 。
-
仿真域内数据(In-Domain Data):关键! 针对 WidowX、Google Robot 和 RoboTwin2.0 三个仿真平台,利用 Qwen2.5VL-7B 构建自动化标注管线,生成了 200 万条基于机器人第一视角(In-domain)的 VQA 数据(涵盖具身定位、空间关系与任务规划),用于 VLM 的有监督微调(SFT)。其中一个实例的system prompt和所产生的域内数据如下:

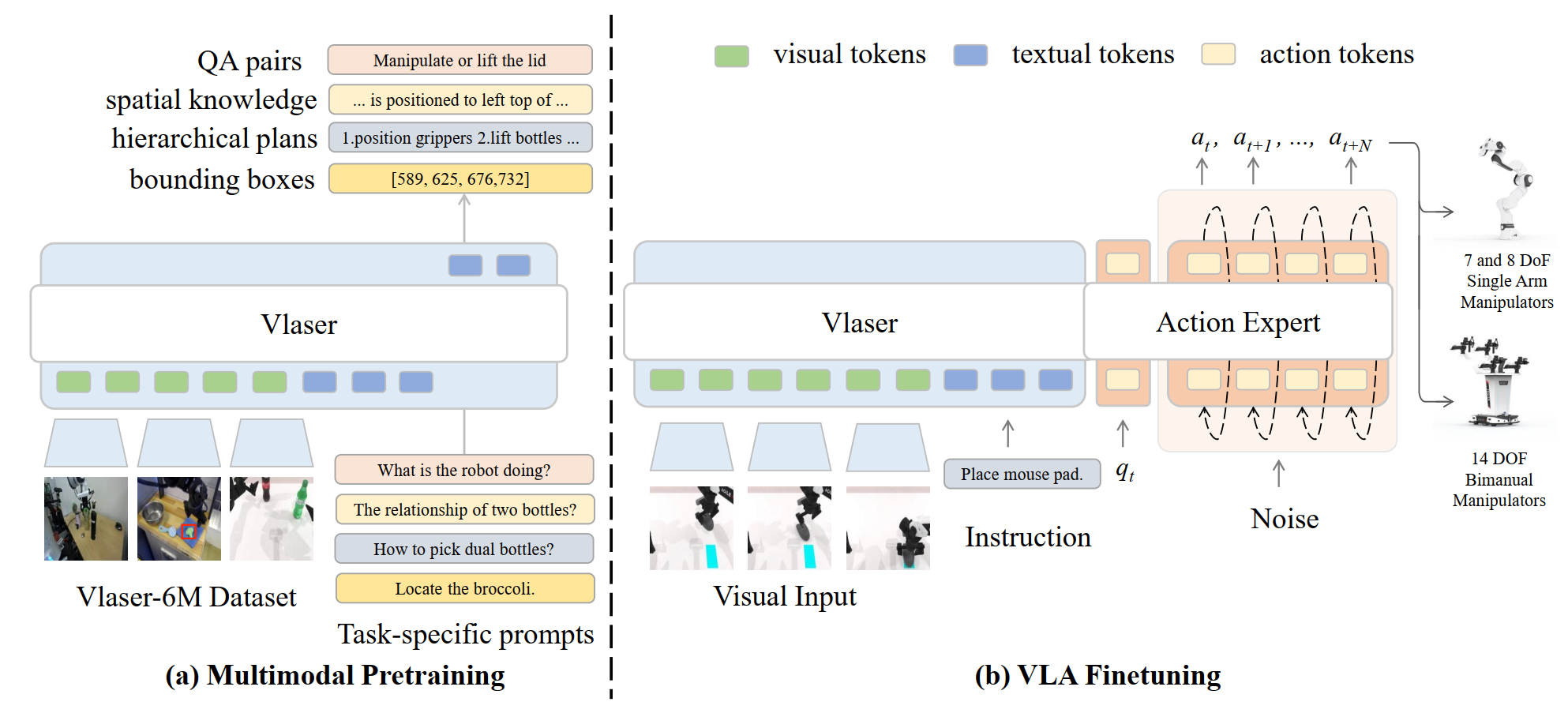
2. 模型架构:Flow Matching 强力驱动
Vlaser 采用了经典的VLM Backbone + Action Expert架构 :
- VLM Backbone: 基于 InternVL3(2B 和 8B 版本),负责处理视觉和语言输入,提供强大的感知特征 。
- Action Expert: 引入流匹配(Flow Matching)技术作为动作生成模块。该模块作为独立的 Action Expert,处理机器人状态与动作 Token,实现端到端的动作预测 。
三、实验结果:全方位的 SOTA 与数据范式验证
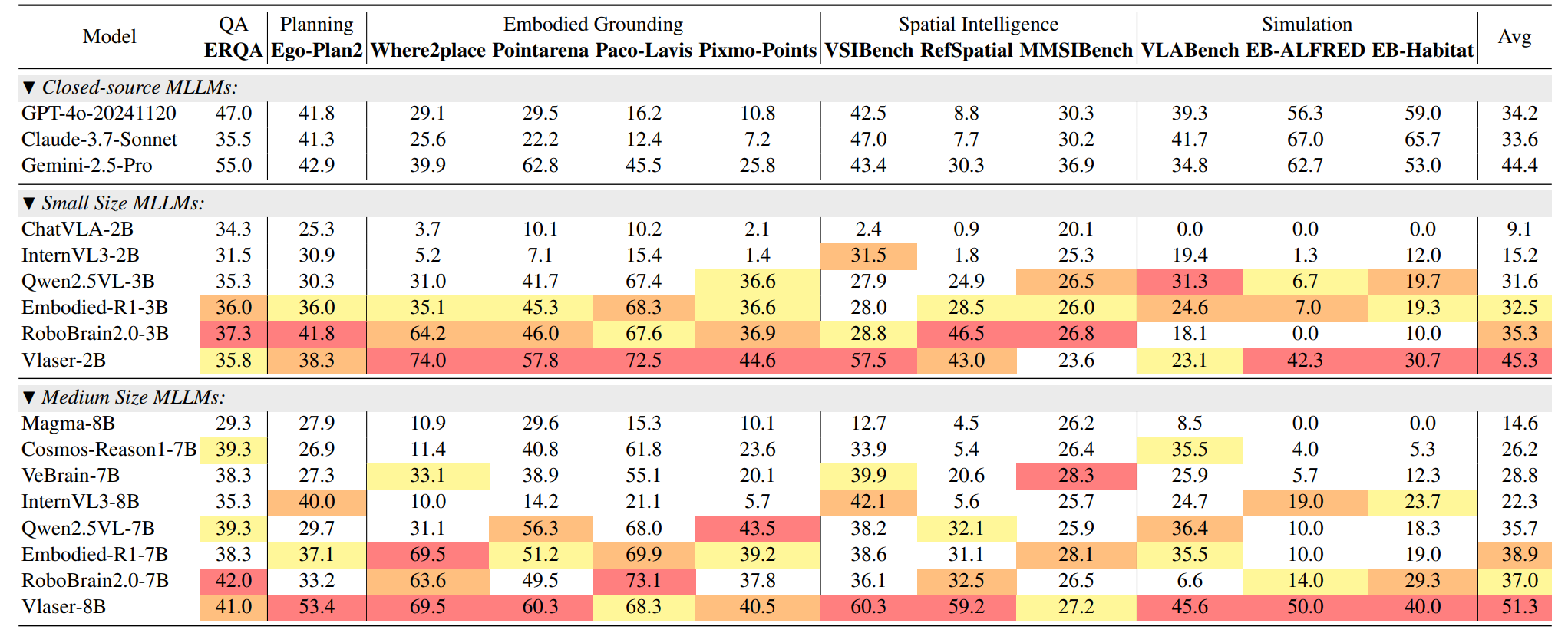
1. 上游具身推理能力(Embodied Reasoning)评估
Vlaser 模型基于 InternVL3 底座,利用构建的 Vlaser-6M 数据集进行了全参数微调(SFT)。在涵盖 Embodied QA、任务规划(Planning)、具身定位(Embodied Grounding)、空间推理(Spatial Reasoning)及仿真模拟(Simulation) 等 13 个主流具身推理基准的综合评估中,Vlaser 展现了令人瞩目的效果。
- Vlaser-8B (SOTA): 在同等规模模型中,Vlaser-8B 平均分高达 51.3。这一成绩显著超越了 GPT-4o (34.2)、Gemini-2.5-Pro (44.4) 等闭源模型,以及 RoboBrain2.0-7B (37.0) 和 Embodied-R1-7B (38.9) 等同类具身多模态大脑大模型。
- Vlaser-2B (高效能): 即便是轻量级的 Vlaser-2B,也取得了 45.3 的 SOTA 平均分。值得注意的是,其在具身定位(Embodied Grounding)能力上已与 8B 模型相当。考虑到下游 VLA 模型对推理效率的追求,我们将 Vlaser-2B 选定为探索下游 VLA 迁移规律的基座模型。
2. 下游机器人控制仿真评测:揭秘“域内数据”的决定性作用
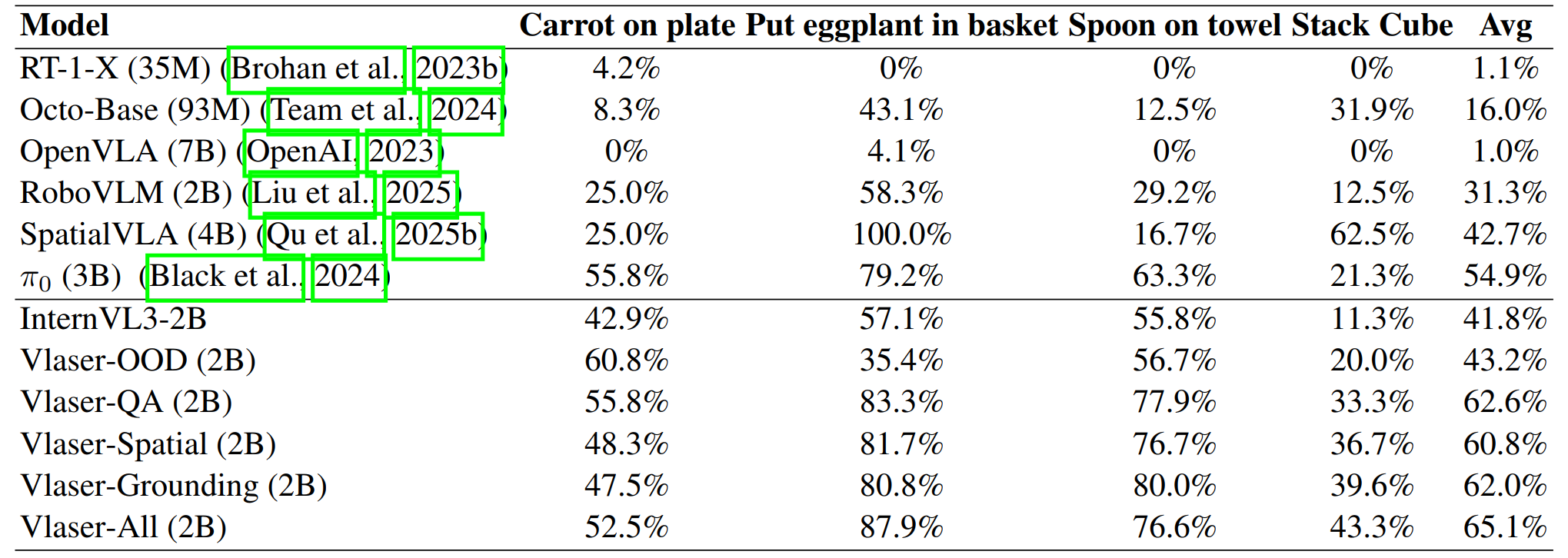
为了探究何种数据能真正提升机器人的操控能力,我们基于 Vlaser-2B 设计了一项严谨的自对比消融研究。我们构建了不同的预训练数据配比,并保持下游 VLA 后训练的配方一致,以此剥离出不同数据源的净贡献。
实验设置:
- 基线模型:
InternVL3-2B(无具身数据微调)与Vlaser-OOD(仅使用 Vlaser-6M 中的域外通用推理数据微调,不含任何仿真域内数据)。 - 域内数据变体: 针对仿真平台生成的域内(In-Domain)数据,我们细分为三类:具身问答(含规划)、具身空间智能与具身定位 (打点、框),分别对应模型
Vlaser-QA、Vlaser-Spatial和Vlaser-Grounding。 - 全量模型:
Vlaser-All,整合上述三种域内数据进行全量微调。
我们在 Bridge (SimplerEnv)、Fractal (SimplerEnv) 以及 RoboTwin2.0 三大仿真平台上进行了广泛验证,结果不仅一致且极具启发性:
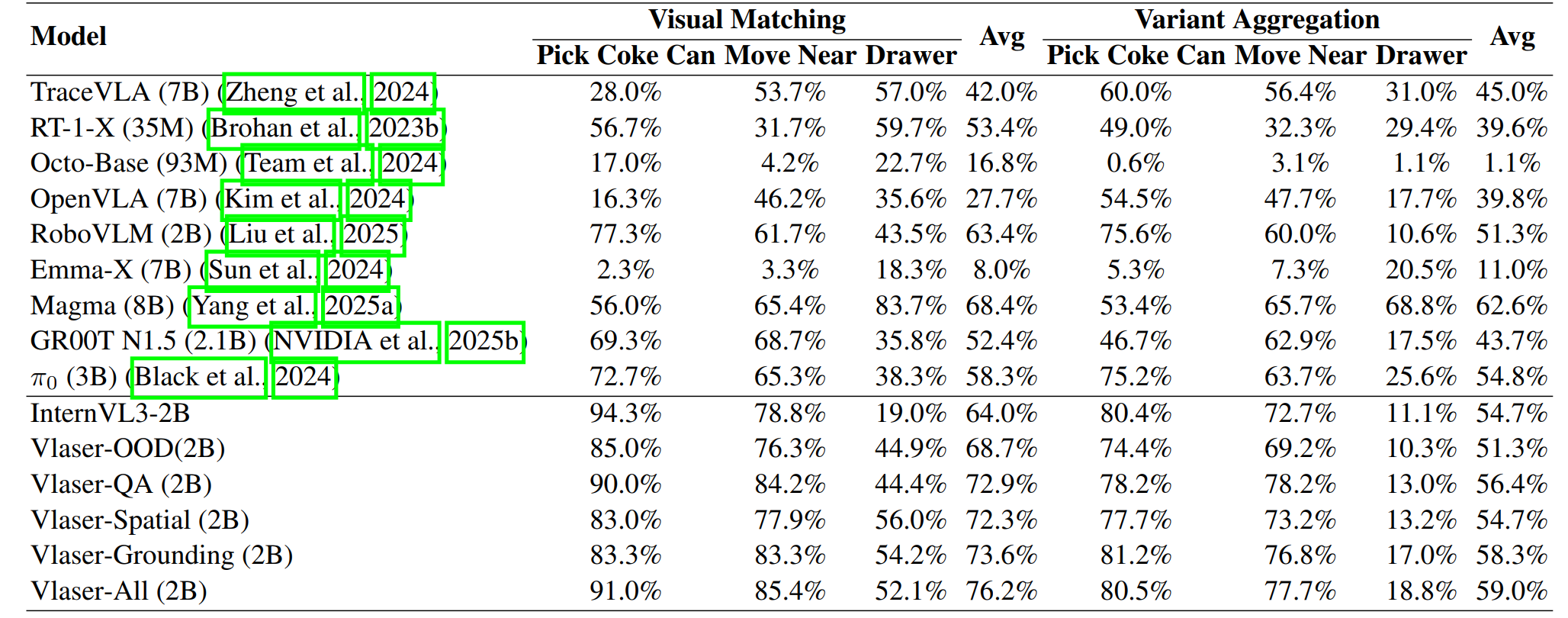
- WidowX 机器人任务:
Vlaser-All (2B)模型的平均成功率飙升至 65.1%,相比于基线InternVL3-2B(41.8%) 和仅使用通用推理数据的Vlaser-OOD(43.2%),实现了质的飞跃。
- Google Robot 任务: 引入域内数据微调的模型展现出全面优势,成功率分别达到 72.9%、72.3%、73.6%,而全量模型
Vlaser-All更是达到了 76.2%,显著优于基线的 64.0% 和 68.7%。
- RoboTwin2.0 双臂任务: 在覆盖短、中、长程的 12 个双臂操作任务中,使用域内数据微调的模型相比 Baseline 取得了 +10% 的成功率增益,有力证明了该数据范式对不同机器人实体和任务类型的强大泛化性。
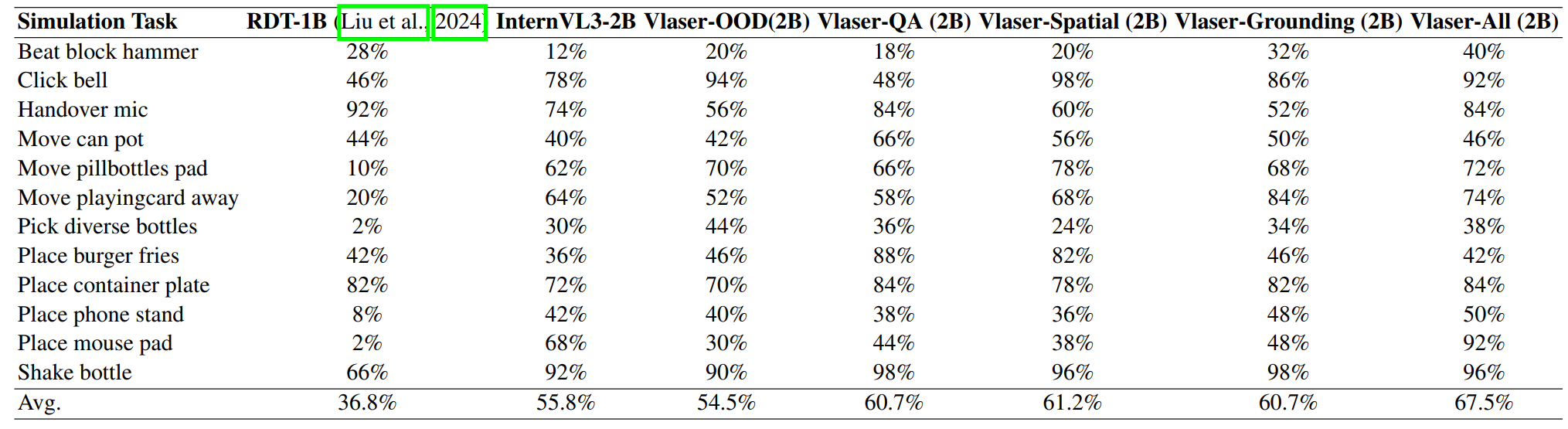
实验结果揭示了一个反直觉但至关重要的规律:
- 通用推理 ≠ \neq = 控制能力: 仅使用通用具身推理数据(Vlaser-OOD)虽然提升了上游 VQA 分数,但并未在下游控制任务中带来明显的性能提升,其成功率与基线模型持平。这表明,常见的具身推理基准测试与底层闭环控制性能之间不存在显著的正相关。
- 域内感知是核心: 相反,所有引入域内数据(In-Domain)的模型 — 无论是 QA、空间还是定位数据,都带来了显著的性能提升。这说明,互联网数据与机器人实体之间的“域差距(Domain Gap)”是限制性能的瓶颈。通过在同一观察域内增强模型对特定的具身第一视角图片的感知能力,可以有效打破这一瓶颈。
- 全能数据配方: 整合所有类型的域内数据(
Vlaser-All)能进一步推高成功率天花板。这表明,一个涵盖通用问答、精细定位和空间智能的多元化域内数据组合,是促进 VLA 策略迁移、提升任务成功率的最佳实践。
四、总结
本研究提出了 Vlaser,一种协同具身推理与端到端控制的基础视觉-语言-动作模型,并通过构建 Vlaser-6M 数据集在 13 项具身推理基准中实现了 SOTA 性能 。通过系统性的消融实验,我们揭示了 VLM 向 VLA 迁移的关键定律:通用的多模态具身推理能力与底层控制性能无显著正相关,而缩短感知数据与真实机器人视角之间的域差距才是提升控制成功率的决定性因素 。基于此,本工作证明了**利用自动化管线生成的标准化、低成本的机器人第一视角 VQA 数据(In-Domain Data),能够有效替代部分昂贵的真机遥操数据用于模型预热 。**这意味着未来的具身智能 Scaling 不应仅依赖于堆砌通用的互联网数据,研究重心应转向构建低成本、自动化的域内数据生成管线,通过对齐感知域来弥合基础模型与物理世界之间的鸿沟,从而实现从 VLM 到 VLA 的高效迁移 。
具身求职内推来啦
国内最大的具身智能全栈学习社区来啦!
推荐阅读
从零部署π0,π0.5!好用,高性价比!面向具身科研领域打造的轻量级机械臂
工业级真机教程+VLA算法实战(pi0/pi0.5/GR00T/世界模型等)
具身智能算法与落地平台来啦!国内首个面向科研及工业的全栈具身智能机械臂
VLA/VLA+触觉/VLA+RL/具身世界模型等!具身大脑+小脑算法与实战全栈路线来啦~
MuJoCo具身智能实战:从零基础到强化学习与Sim2Real
Diffusion Policy在具身智能领域是怎么应用的?为什么如此重要?
1v1 科研论文辅导来啦!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 7
7 0
0- 0



 已为社区贡献87条内容
已为社区贡献87条内容

所有评论(0)