踩遍VLN开源项目的坑后,最推荐新手复现的是这4个……(亲测复现率100%)
回过头看这四篇工作,其实并不难发现一条非常清晰的演进脉络:VLFM 展示了 VLN 最“原始”的样子:地图、前沿、语义代价函数,逻辑直观、模块清晰,非常接近经典机器人导航的思路;NavGPT 把导航决策显式地交给大语言模型:通过 prompt 进行高层推理,展示了语言推理在导航中的潜力;NoMaD 代表了端到端学习路线:用统一的扩散策略同时处理探索与到达;Uni-NaVid 则进一步走向统一的VL

一切不能运行的VLN智能,都是“虚构”的方法论
——从arXiv到python run.py
目录
03 NoMaD:端到端扩散策略下的统一导航与探索(2024 ICRA最佳论文奖)
04 Uni-NaVid:走向统一 Vision-Language-Action 的导航范式(RSS 2025)
Uni-NaVid 的推理入口:视频 + 语言,直接输出动作序列
视觉语言导航(Vision-Language Navigation, VLN)这两年发展得非常快——
从早期的模块化系统,到端到端策略,再到今天统一VLA的大模型路线,论文数量和方法复杂度都在迅速膨胀。
但对刚涉足该方向的初学者而言,真正的难点往往不是“看不看得懂论文”,而是一个更现实的问题:
哪些工作是我现在真的能复现的?哪些值得作为入门的第一步?
很多 VLN 论文在方法上非常前沿,但复现成本也同样不低:复杂的依赖配置、冗长的训练流程、多模型协作的调试成本……
本文无意罗列所有前沿进展,也不以性能对比为目标,而是聚焦一个更切实的问题:
有哪些VLN领域的关键工作,是真正可上手、可运行、可理解的?
我们筛选了VLN发展历程中四种代表性范式下的4个项目(都是小编真实复现过的),从项目定位、设备要求、关键代码、复现思路等方面,尽量给出一个对初学者友好的理解和复现路径。
01 VLFM:从“语义代价地图”理解 VLN 的最初形
为什么要先看 VLFM?
在众多 VLN 方法中,VLFM 非常适合作为新手入门的第一篇。
原因很简单:它几乎完整呈现了 VLN 最初、也最直观的形态。
VLFM 并不追求端到端地“直接输出动作”,而是沿用经典机器人导航中的 value map / frontier exploration 思路,将导航过程拆解为清晰的几个阶段:
从方法上看,VLFM 是一个典型的基于 2D 代价地图的模块化 VLN 框架。

▲图2|前沿地图和价值地图示例
它不依赖任务相关训练,整体逻辑清楚、假设明确,也没有复杂的时序建模或端到端黑箱决策——
非常接近很多人对“机器人如何在陌生环境中找东西”的第一直觉理解。
也正因为这种结构清晰、思路直接的设计,VLFM 常被视为语义导航领域中一个非常扎实的 baseline:
即便后续方法不断演进,它依然是理解 VLN 问题本身的一个很好切入点。
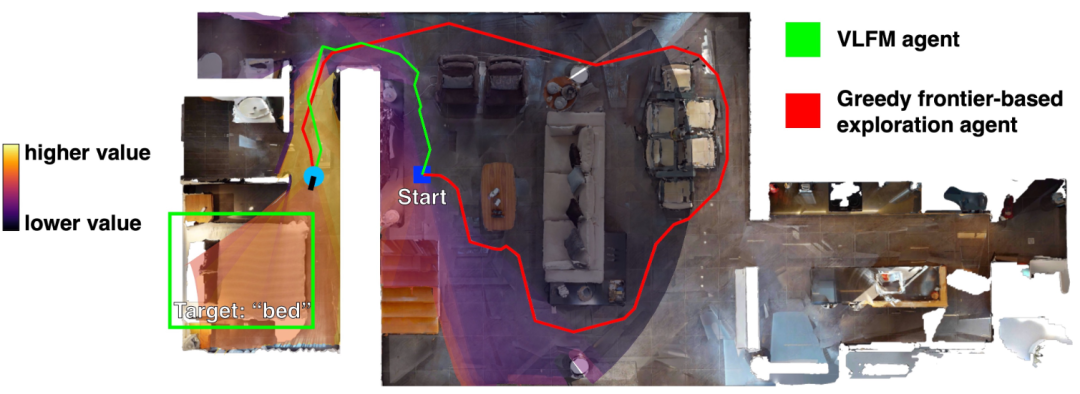
▲图1|VLFM 在未知环境中的语义目标导航示意。
复现 VLFM,需要做哪些准备?
如果从“能不能真的跑起来”的角度看,VLFM 对初学者是相对友好的,但仍然需要一些基础准备。
这里并不是给出完整教程,而是帮助新手建立一个现实预期(完整教程可以再文末的链接中找到)。
基础能力与环境要求
在复现 VLFM 之前,读者最好具备以下背景:
在复现 VLFM 之前,读者最好具备以下背景:
-
基本的 Python 使用经验,能够创建和管理 Conda 环境
-
对 PyTorch 有最基本的了解(无需训练模型)
-
对机器人导航中的“地图”“前沿”“仿真环境”有基础概念即可
从硬件角度看,VLFM 并不要求大规模训练算力:
-
一张支持 CUDA 的 GPU 即可(主要用于视觉-语言模型推理)
-
显存需求中等,更接近“跑推理”而非“训大模型”
-
实验可以完全在 Habitat 仿真中完成,不依赖真实机器人
在VLFM中,以下方法值即为导航部分的核心实现。
代码链接:https://github.com/bdaiinstitute/vlfm/tree/main/vlfm/vlm
def reset(self, goal: Any, relative: bool = True, *args: Any, **kwargs: Any) -> Dict[str, np.ndarray]:
# 将目标位置从相对坐标转换为全局坐标
def step(self, action: Dict[str, Any]) -> Tuple[Dict, float, bool, Dict]:
# 计算机器人应该执行的线性和角度的变化
def _compute_displacements(self, action: Dict[str, Any]) -> Tuple[float, float]:
# 计算线性和角度的位移
def _get_obs(self) -> Dict[str, np.ndarray]:
# 获取机器人当前的深度图像和目标位置通过以上代码获取了目标位置和机器人的当前位置即环境观信息后,即可通过路径规划的方式引导机器人前往目标点,完成最终的导航任务,至此即可实现一个VLN的完整架构。
一个新手友好的复现思路
如果将 VLFM 的复现流程压缩成一个“新手视角的路线图”,可以概括为三步:
第一步:环境与代码准备
创建 Python 环境,安装 PyTorch,并按 README 将 VLFM 项目以可编辑方式安装到环境中。
第二步:数据与模型权重下载
根据官方说明下载 HM3D 数据集,以及 MobileSAM、GroundingDINO、YOLOv7 等所需的预训练权重,并放置到指定目录。
第三步:启动模型并运行评测
启动视觉-语言模型服务,随后执行评测脚本,在 Habitat 仿真环境中观察导航行为和评测指标。
整个流程的关键并不在于“调参”或“训练”,而是在于理解每一步在系统中的作用:
地图是如何构建的、语义信息如何影响探索决策、以及这种影响最终如何反映在机器人的运动轨迹上。
之前我们深入剖析过VLFM的核心框架和实现原理,完整部署了VLFM,感兴趣的朋友可以阅读:【硬核教程】从0实现VLN导航:以波士顿动力VLFM为例,原理+代码全面解析「视觉-语言」模型
02 NavGPT:用显式语言推理驱动导航决策的 VLN 路线
为什么要看 NavGPT?
如果说 VLFM 代表的是 “地图 + 语义代价”的经典机器人导航思路,那么 NavGPT 则走向了几乎相反的一端:
它尝试完全抛开传统导航模型,用大语言模型直接完成导航决策——
NavGPT 是一个纯 LLM 驱动的 VLN 框架。
在这个系统中,模型不再接收原始图像,而是基于对当前视觉观测的文本描述,结合历史轨迹和可探索方向,通过语言推理来预测下一步动作。
从方法范式上看,NavGPT 具有非常鲜明的特征:
-
不做端到端视觉建模
-
不训练导航策略网络
-
不构建显式地图
所有决策都交由 LLM 通过 prompt 进行推理(作者借此展示了大语言模型在具身场景中的一种可能性):
LLM 不只是“说话”,而是可以显式地进行高层规划、子目标分解、地标识别和计划调整。
也正因如此,NavGPT 并不是一个追求性能的 VLN 方法,而更像是一次关于“LLM 能不能当导航大脑”的探索性尝试。
对于刚进入 VLN 领域的读者来说,它非常适合用来理解:当导航系统的“中枢”完全变成语言推理,会发生什么?
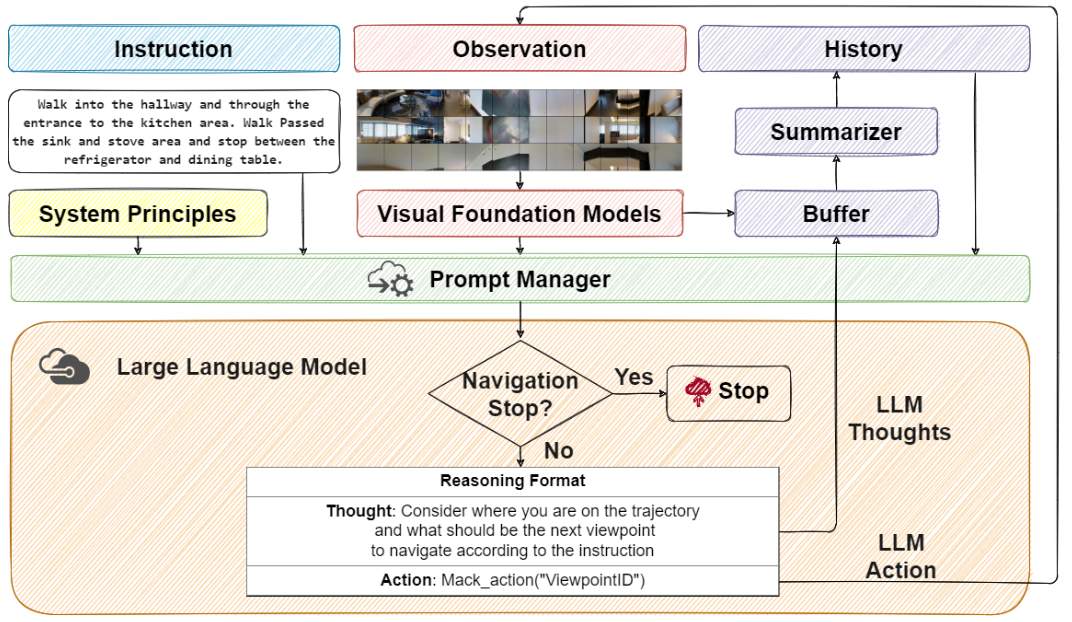
▲图2|NavGPT 将大语言模型的推理能力与导航动作决策相结合,在不进行任务训练的前提下,实现零样本的视觉-语言导航。
复现 NavGPT,需要建立怎样的预期?
相比 VLFM 这类模块化系统,NavGPT 的复现逻辑完全不同。
它并不依赖复杂的仿真环境配置,也不需要训练模型,但高度依赖外部大语言模型服务。
从新手视角来看,NavGPT 的“可复现性”主要体现在:代码结构清晰、实验入口明确、推理过程完全可观察。
在复现 NavGPT 之前,需要具备以下条件:
-
基本的 Python 使用能力,能够运行脚本与管理依赖
-
对 VLN 任务(如 R2R)的基本了解
-
能够申请并使用 OpenAI API(或替换为自定义 LLM)
在硬件方面,NavGPT 几乎不依赖本地算力:
-
不需要 GPU 训练
-
本地计算主要是环境交互与数据处理
-
主要成本来自 LLM API 的调用
因此,它非常适合在没有高算力设备的情况下,快速复现 LLM-VLN 思路。
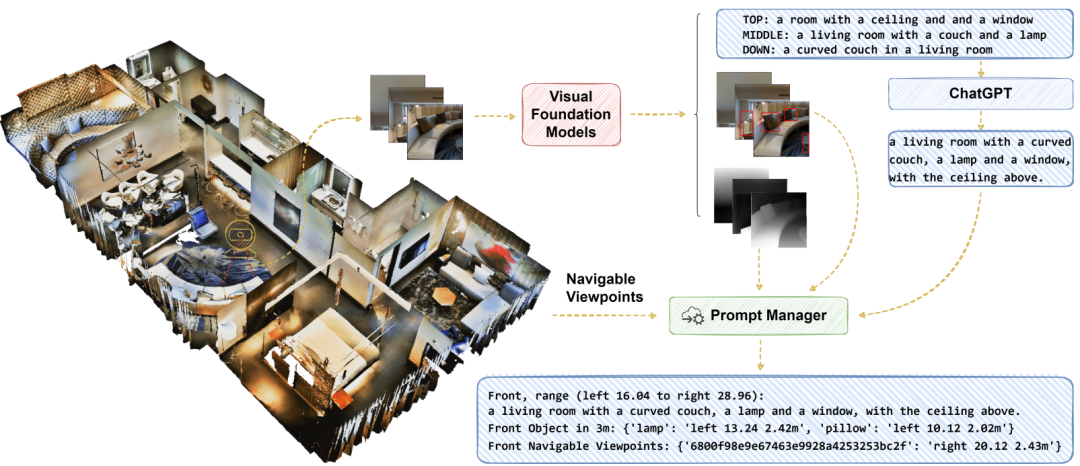
NavGPT 的运行主线:从语言描述到导航决策
下面选取了项目中最核心的验证入口代码,展示 NavGPT 如何组织环境、调用语言模型代理,并完成一次完整的导航推理流程。
def main():
args = parse_args()
# 构建验证环境(R2R)
val_envs = build_dataset(args)
# 创建导航智能体
agent = NavAgent(next(iter(val_envs.values())), args)
for env_name, env in val_envs.items():
agent.env = env
# 执行基于语言模型的导航推理
agent.test(iters=args.iters)
# 获取导航轨迹结果
preds = agent.get_results(detailed_output=False)
# 评估导航性能(如成功率、路径长度等)
if 'test' not in env_name:
score_summary, _ = env.eval_metrics(preds)
for metric, val in score_summary.items():
print(f"{metric}: {val:.2f}")
# 保存预测结果
json.dump(
preds,
open(os.path.join(args.pred_dir, f"submit_{env_name}.json"), 'w'),
indent=4
)这段代码体现了 NavGPT 的核心运行逻辑:
-
首先,系统根据 R2R 数据集构建导航环境;
-
然后,创建一个 NavAgent,它内部封装了与大语言模型(如 GPT-3.5 / GPT-4)的交互逻辑;
-
在每一步导航中,智能体会将当前的视觉描述、历史轨迹和可探索方向组织成 prompt,交由语言模型进行推理;
-
最终,语言模型生成的“思考与动作”被解析为具体的导航决策,并在环境中执行。
从代码层面可以看到,NavGPT 并没有复杂的几何建图或显式规划模块,而是以“语言推理驱动决策”为核心,这也使得该方法在复现时门槛相对较低,因此非常适合作为“LLM + VLN”范式的入门案例。
一个新手可执行的复现路径
从 README 给出的说明来看,NavGPT 的最小复现流程可以概括为:
第一步:安装环境与依赖
创建 Python 3.9 的 Conda 环境,并安装项目所需依赖。
第二步:准备 VLN 数据
下载 R2R 数据集,并放置到项目指定的 datasets 目录中。
第三步:配置大语言模型接口
申请 OpenAI API Key,并通过环境变量或代码方式配置到系统中。
第四步:运行验证脚本
使用指定的 LLM(如 GPT-4 或 GPT-3.5),在 R2R 验证集上运行 NavGPT,观察生成的动作序列和导航结果。
值得一提的是,对于新入门的朋友在复现时还有一个更经济的运行方式——
使用 GPT-3.5,仅在少量样本上运行验证,用于快速理解整个推理流程。
03 NoMaD:端到端扩散策略下的统一导航与探索(2024 ICRA最佳论文奖)
为什么要看 NoMaD?
在 VLN 发展过程中,一个长期存在的分裂是:
“找目标”和“走到目标”往往由两套不同的系统来完成。
传统方法通常需要:
-
一个模块负责探索和搜索未知环境;
-
另一个模块在目标被发现后负责精确到达;
-
中间还可能夹杂子目标生成、规划或切换策略。
NoMaD 的核心贡献,正是试图用一个统一的端到端策略,同时解决这两件事。
它提出了一种基于扩散模型(Diffusion Policy)的导航策略,通过“目标掩码(goal masking)”机制,在同一个模型中灵活切换两种行为模式:
-
目标驱动导航:当目标已知或可见时,直接向目标前进;
-
无目标探索:当目标未知时,主动探索新环境。
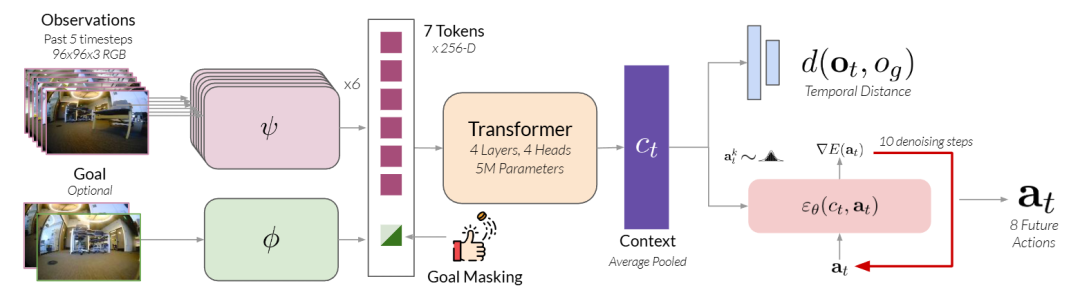
▲图3|NoMaD 是首个能够在未知环境中同时执行目标条件导航与无目标探索的扩散式动作模型。
从方法范式上看,NoMaD 是一个非常典型的 e2e 风格方法:
-
输入是连续的视觉观测;
-
输出是连续的机器人动作;
-
中间不显式构建地图,也不进行符号级规划;
-
所有行为都由一个统一的策略模型生成。
这使得 NoMaD 成为理解“现代视觉导航如何走向端到端学习”的一个关键代表。
复现 NoMaD,新手需要做好哪些准备?
和 VLFM、NavGPT 不同,NoMaD 的复现并不是“跑一个脚本就能看到结果”的类型。
但它的优势在于:代码完整、工程路径清晰,而且提供了预训练模型和真实机器人部署示例。

从新手角度看,NoMaD 的“可复现性”主要体现在两个层面:
-
你可以不训练模型,直接加载官方权重运行推理或部署;
-
所有关键步骤都已经被作者拆解成脚本,而不是隐藏在论文假设中。
基础能力与设备要求
在尝试复现 NoMaD 之前,需要具备比前两篇稍高一些的工程基础:
-
熟悉 Python 和 PyTorch 的基本使用
-
能够管理 Conda 环境,并理解 YAML 配置文件
-
对 ROS 有基本概念(如果希望跑真实机器人或完整部署流程)
在硬件方面,NoMaD 对算力的要求明显高于 VLFM 和 NavGPT:
-
训练阶段需要 GPU(CUDA 10+)
-
推理和部署可以使用较小模型
-
官方示例基于真实移动机器人平台(如 LoCoBot)
不过,对于初学者而言,完全可以跳过训练阶段,直接使用研究团队提供的预训练权重来理解系统行为。
NoMaD 的运行逻辑:从连续观测到可执行动作
相比基于地图或语言推理的导航方法,NoMaD 更接近“纯策略”的范式:
机器人直接根据近期的视觉观测,预测接下来应该执行的动作序列。
下面选取了 NoMaD 在真实机器人部署中的核心推理代码片段,更好理解这一过程。
# 接收来自相机的连续图像,维护一个时间窗口
def callback_obs(msg):
obs_img = msg_to_pil(msg)
if len(context_queue) < context_size + 1:
context_queue.append(obs_img)
else:
context_queue.pop(0)
context_queue.append(obs_img)
# NoMaD 的主推理循环(ROS 节点)
while not rospy.is_shutdown():
chosen_waypoint = np.zeros(4)
# 当积累了足够的历史观测后,开始推理
if len(context_queue) > model_params["context_size"]:
# 将最近的多帧图像编码为视觉特征
obs_images = transform_images(
context_queue,
model_params["image_size"],
center_crop=False
).to(device)
# 基于扩散模型采样一组候选动作轨迹
with torch.no_grad():
noisy_action = torch.randn(
(args.num_samples,
model_params["len_traj_pred"], 2),
device=device
)
naction = noisy_action
noise_scheduler.set_timesteps(num_diffusion_iters)
for t in noise_scheduler.timesteps:
noise_pred = model(
'noise_pred_net',
sample=naction,
timestep=t,
global_cond=obs_images
)
naction = noise_scheduler.step(
model_output=noise_pred,
timestep=t,
sample=naction
).prev_sample
# 从采样得到的轨迹中选择一个 waypoint 作为当前控制指令
naction = to_numpy(get_action(naction))
chosen_waypoint = naction[0][args.waypoint]
# 将 waypoint 发布给机器人控制器
waypoint_msg = Float32MultiArray()
waypoint_msg.data = chosen_waypoint
waypoint_pub.publish(waypoint_msg)
rate.sleep() 从这段代码可以看出 NoMaD 的核心运行方式:
-
系统不构建显式地图,也不进行符号化规划;
-
而是维护一个短时间窗口的视觉上下文(recent observations);
-
基于该上下文,通过扩散模型一次性生成多种可能的未来动作序列;
-
最终从这些候选动作中选取一个 waypoint,直接发送给机器人执行。
这种设计使 NoMaD 能够在 “是否有明确目标” 两种情况下自然切换:
当目标存在时执行目标导向导航,当目标缺失时则退化为探索行为。
从复现角度来看,NoMaD 的代码结构高度工程化:
推理逻辑、ROS 接口和模型调用彼此解耦,非常适合作为:理解“端到端策略如何真正落地”的进阶参考。
一个“新手友好”的复现切入方式
如果从“最少踩坑”的角度出发,复现 NoMaD 更合理的顺序是:
第一步:只关注 NoMaD 的模型推理能力
使用官方发布的预训练模型权重,不自行训练模型,避免数据处理和长时间训练成本。
第二步:理解两种行为模式的切换
通过 goal masking,观察模型在“有目标 / 无目标”条件下生成的动作差异,这是 NoMaD 的核心设计。
第三步:再考虑部署或扩展
在理解模型行为后,再决定是否进入 ROS 部署流程,或将其适配到其他机器人平台。
从 README 提供的脚本来看,项目已经将导航(navigate.sh)和探索(explore.sh)明确区分,这对新手理解模型行为非常有帮助。
04 Uni-NaVid:走向统一 Vision-Language-Action 的导航范式(RSS 2025)
为什么要看 Uni-NaVid?
如果把前面几篇放在一条技术演进线上:
-
VLFM 代表了模块化、地图驱动的经典 VLN;
-
NavGPT 把“决策中枢”推到了显式语言推理层;
-
NoMaD 进一步走向端到端,用学习到的策略统一探索与到达;
那么 Uni-NaVid 所代表的,是当前导航研究中最激进、也最前沿的一条路线——
直接将导航建模为 Vision-Language-Action(VLA)序列预测问题。
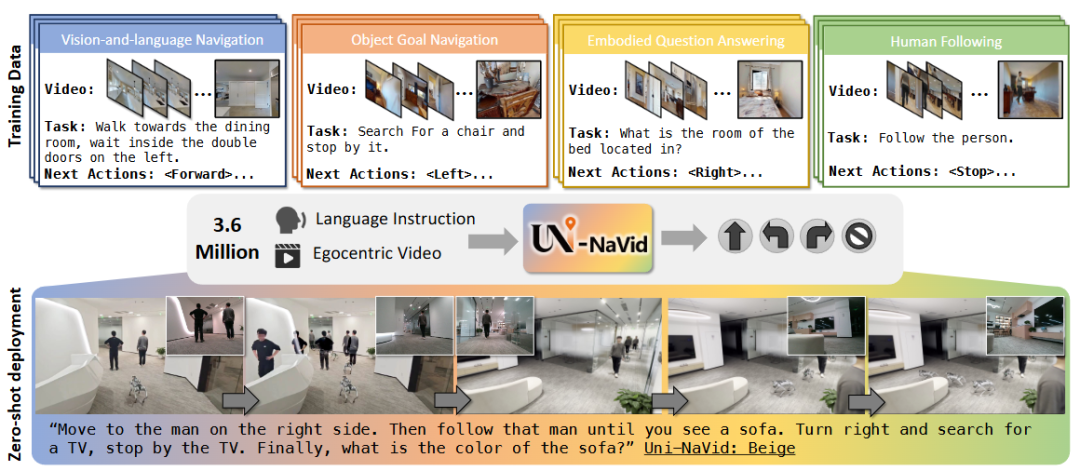
▲图4|Uni-NaVid 通过大规模、多任务的导航数据学习通用导航能力
Uni-NaVid 不再区分“指令跟随”“目标搜索”“问答导航”“目标跟踪”等具体任务类型。
而是试图用一个统一的 VLA 模型,覆盖多种导航子任务,并通过它们之间的协同来提升整体能力。
在模型形式上,Uni-NaVid 不再是“感知 → 建图 → 规划 → 控制”的流水线,而是一种跨模态的序列生成问题:
-
在线 RGB 视频流+自然语言指令作为输入,端到端地输出底层机器人动作;
-
中间不显式构建地图,也不引入单独的规划模块。
从研究角度看,Uni-NaVid 的意义并不只在于性能本身,而在于它展示了一种可能性:
当多种导航任务被统一到同一表示空间中时,模型可以通过共享经验获得更强的泛化能力。
复现 Uni-NaVid,能力与算力要求
和前面几篇不同,Uni-NaVid 并不是“轻量级可快速跑通”的项目。
但它的价值在于:即使不完整复现论文规模的实验,新手也可以通过它直观感受到 VLA 方法的真实形态。
在尝试 Uni-NaVid 之前,需要做好如下准备:
-
熟悉 Python 与 PyTorch 的基本训练与推理流程
-
对 Transformer、视觉编码器与大语言模型有基础认知
-
能够管理较新的依赖环境(Python 3.10、flash-attention 等)
在硬件方面,Uni-NaVid 对算力的要求明显高于前面三篇:
-
推理阶段在单张 A100 上可达到约 5 Hz
-
训练或微调阶段需要较强 GPU 资源
-
不适合在低算力设备上完整复现论文规模实验
因此,从新手角度出发,更合理的目标是:“跑通推理或离线评估流程,而不是从头训练一个 Uni-NaVid。”
Uni-NaVid 的推理入口:视频 + 语言,直接输出动作序列
Uni-NaVid 代表了当前 VLN 领域最前沿的一类方法:
不再区分“感知—规划—控制”模块,而是直接学习从视频和语言到动作的映射。
下面选取了 Uni-NaVid 在离线评测中使用的核心推理逻辑,更好理解这种 VLA 系统在代码层面是如何运行的。
class UniNaVid_Agent():
def __init__(self, model_path):
# 加载预训练的 VLA 模型(视觉编码器 + 语言模型)
self.tokenizer, self.model, self.image_processor, _ = \
load_pretrained_model(model_path, None, model_path)
self.rgb_list = []
self.reset()
def act(self, data):
# 累积在线视频帧
rgb = data["observations"]
self.rgb_list.append(rgb)
# 构造导航指令 prompt
prompt = self.promt_template.format(data["instruction"])
# 调用 VLA 模型进行推理
navigation = self.predict_inference(prompt)
# 将语言模型输出解析为动作序列
action_list = navigation.split(" ")
traj = [[0.0, 0.0, 0.0]]
for action in action_list:
if action == "forward":
traj.append([traj[-1][0] + 0.5, 0.0, 0.0])
elif action == "left":
traj.append([0.0, 0.0, -np.deg2rad(30)])
elif action == "right":
traj.append([0.0, 0.0, np.deg2rad(30)])
elif action == "stop":
break
return {"path": [traj], "actions": action_list}这段代码体现了 Uni-NaVid 的典型 VLA 推理流程:
-
系统持续接收来自机器人视角的 RGB 视频帧;
-
将历史视频与当前观测统一编码,并与自然语言指令一起输入模型;
-
大模型直接生成一串高层动作(如 forward / left / right / stop);
-
最终,这些动作被转换为可执行的轨迹或 waypoint,用于机器人控制。
与前面介绍的 VLFM、NavGPT、NoMaD 不同——
Uni-NaVid 不再显式区分“导航策略”和“控制逻辑”,而是通过大规模多任务数据训练,让模型在一个统一框架下完成多种导航任务。
这也使它成为理解 VLA 方向的一个非常直观的参考实现。
一个更现实的新手复现切入点
结合作者提供的代码与数据,较为友好的复现路径可以概括为三步:
第一步:环境与模型准备
搭建官方 Conda 环境,下载预训练好的 Uni-NaVid 权重、视觉编码器和语言模型,无需自行从头训练。
第二步:使用作者提供的小规模数据或示例视频
项目提供了精简的数据子集与真实视频示例,可用于快速验证模型的推理能力。
第三步:进行离线评估或推理测试
通过离线评估脚本,让模型在真实导航视频或跟踪场景中生成动作序列,直观观察其多任务泛化能力。
这一流程避免了大规模数据处理和长时间训练,更适合初学者理解模型的输入输出形式,以及 VLA 方法在导航中的实际表现。
05 总结与延伸
回过头看这四篇工作,其实并不难发现一条非常清晰的演进脉络:
-
VLFM 展示了 VLN 最“原始”的样子:地图、前沿、语义代价函数,逻辑直观、模块清晰,非常接近经典机器人导航的思路;
-
NavGPT 把导航决策显式地交给大语言模型:通过 prompt 进行高层推理,展示了语言推理在导航中的潜力;
-
NoMaD 代表了端到端学习路线:用统一的扩散策略同时处理探索与到达;
-
Uni-NaVid 则进一步走向统一的VLA建模,体现了当前最前沿的 VLA 思路。
如果只从“代表性”来看,这四篇都各自站在一条重要的技术分支上。
换句话说,这四篇并不是并列的“推荐列表”,而更像是一条由浅入深、由模块化走向统一建模的学习路径。
对于 VLN 的初学者而言,真正重要的不是一开始就追逐最前沿的模型,而是先跑通一条完整、可理解、可修改的系统。
以上项目均已实际复现过,欢迎留言你遇到的难题,与我交流讨论。
Ref
1. VLFM:https://github.com/bdaiinstitute/vlfm
2. NavGPT:https://github.com/GengzeZhou/NavGPT
3. NoMaD:https://github.com/adith-m-dharan/NoMaD
4. UniNavid:https://github.com/jzhzhang/Uni-NaVid

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 35
35 0
0- 0



 已为社区贡献89条内容
已为社区贡献89条内容

所有评论(0)