【论文自动阅读】Action-Sketcher: From Reasoning to Action via Visual Sketches for Long-Horizon Robotic Manip
本文提出了一种名为Action-Sketcher的机器人框架,通过在“看”和“动”之间增加“思考”和“画草图”的步骤,让机器人能更可靠地完成复杂的长程任务。
·
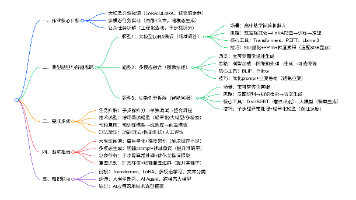
快速了解部分
基础信息(英文):
- 题目: Action-Sketcher: From Reasoning to Action via Visual Sketches for Long-Horizon Robotic Manipulation
- 时间: 2026.01
- 机构: Peking University, Beijing Academy of Artificial Intelligence, University of Sydney, Institute of Automation, Chinese Academy of Sciences
- 3个英文关键词: Visual Sketch, Long-Horizon Planning, Human-in-the-Loop
1句话通俗总结本文干了什么事情
本文提出了一种名为Action-Sketcher的机器人框架,通过在“看”和“动”之间增加“思考”和“画草图”的步骤,让机器人能更可靠地完成复杂的长程任务。
研究痛点:现有研究不足 / 要解决的具体问题
- 空间模糊性:现有的视觉语言动作(VLA)模型通常依赖文本线索,缺乏显式的视觉中间表示,导致在杂乱场景中难以准确指代物体(例如“把茶倒进杯子”在有多个杯子时会困惑)。
- 时间脆弱性:缺乏持久的全局意图建模,难以进行有效的长程任务分解,且无法在动态交互中进行实时修正。
- 缺乏可解释性:计划意图通常嵌入在潜在空间中,人类无法直观理解或干预机器人的决策过程。
核心方法:关键技术、模型或研究设计(简要)
提出了一种“看-思-画-动(See-Think-Sketch-Act)”的循环框架。模型首先进行时空推理,然后生成包含点、框、箭头的显式视觉草图(Visual Sketch),最后基于草图生成动作。
深入了解部分
相比前人创新在哪里
- 显式视觉中间表示:引入了Visual Sketch作为高阶推理与低阶控制之间的可验证接口,将语言与场景几何结构结合。
- 人机协同的可编辑性:视觉草图不仅是机器的中间步骤,也是人类可以直观干预和修正的界面(Human-in-the-Loop)。
- 自适应令牌门控机制:模型能自主决定何时进行推理(生成草图)和何时直接执行动作,平衡了实时性与复杂任务的处理能力。
解决方法/算法的通俗解释
想象你教一个新手整理房间。
- 以前的方法:你只告诉他“去整理桌子”,他得自己猜怎么动,容易搞错。
- 本文的方法:他先看一眼房间(See),然后停下来想一下(Think),接着在桌子上用手指画出路线图(Sketch)——比如圈出要拿的笔,画个箭头指向垃圾桶。最后他根据这个“路线图”动手(Act)。如果画错了,你也能一眼看出来并帮他改,改完他再动。
解决方法的具体做法
- 视觉草图定义:定义了三种几何原语——框(定位目标物体)、点(关键接触点)、箭头(运动轨迹或旋转方向)。
- 双模式推理:
- 推理模式:生成< BOR >令牌,输出子任务文本和对应的视觉草图。
- 动作模式:生成< BOA >令牌,利用流匹配(Flow Matching)模型根据草图生成动作序列。
- 三阶段课程学习:
- 阶段1:基础时空学习(预训练)。
- 阶段2:推理到草图增强(学习生成正确的草图)。
- 阶段3:草图到动作及模式适应(学习根据草图执行动作并切换模式)。
基于前人的哪些方法
- π0 (pi0):作为本文的VLA模型骨干(Backbone),用于处理视觉和语言输入以及动作生成。
- Flow Matching:用于在动作模式下生成连续的动作块。
- GPT-4o:用于辅助生成训练数据中的推理链和草图标注。
实验设置、数据、评估方式、结论
- 实验设置:在RoboTwin 2.0(仿真)和真实机械臂(Aloha AgileX, Galaxea R1)上进行测试。
- 数据:结合了合成数据(LIBERO, RoboTwin 2.0)和真实世界数据(整理桌面、倒茶、抓取放置),包含多视角图像、文本指令、视觉草图监督和动作序列。
- 评估方式:任务成功率(Success Rate)、子任务完成率、与SOTA模型(如OpenVLA, π0等)的对比。
- 结论:
- 在长程和复杂空间任务(如倒茶、叠方块)上显著优于现有SOTA模型。
- 人类通过修正草图能大幅提高任务成功率(例如在整理桌面任务中从27.6%提升至75.0%)。
- 消融实验证明了视觉草图和分阶段训练的重要性。
提到的同类工作
- RT-SKETCH:利用手绘草图在模糊和干扰物下进行目标条件模仿学习。
- TRACEVLA:注入视觉轨迹提示以增强空间时间意识。
- π0 (pi0):具有开放世界泛化能力的分层VLA模型(本文基于此改进)。
- OpenVLA:开源的视觉语言动作模型(作为基准对比)。
- RT-2:视觉语言动作模型,将网络知识迁移到机器人控制。
和本文相关性最高的3个文献
- π0:本文直接采用了π0作为基础模型架构和骨干网络,是本文方法实现的基础。
- RT-SKETCH:本文在“利用视觉草图引导机器人动作”这一思路上与RT-SKETCH有直接的继承和对比关系,但本文强调的是模型自动生成的可编辑草图。
- GPT-4o:本文利用GPT-4o生成了训练所需的推理链数据和部分标注,是其数据构建流程中的关键技术。
我的
感觉弄的有点复杂,要是能在隐空间进行应该好一些。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 5
5 0
0- 0



 已为社区贡献53条内容
已为社区贡献53条内容

所有评论(0)