14倍速效率狂飙!不再把想法说出来,机器人或许想的更快……
Action Expert 并不会反向修改 latent CoT,而是将其视作一个随时间缓慢变化的上下文,从而在不反复触发完整推理的情况下,保持动作生成的连续性与稳定性。▲图7 | 三个VLA模型最后一层的注意力热力图可视化:(a) LaST0(无CoT推理)(b) CoT-VLA中的显式CoT (c) 带有LaST CoT的LaST0。在真实物理世界中,许多对操作至关重要的信息,并不天然适合被离

机器人控制中,CoT 应该以什么形式存在,才不会成为负担?
——毫秒级实时交互
目录
受大语言模型中Chain-of-Thought(CoT)推理成功的启发,研究者尝试将CoT引入VLA,以提升机器人在复杂任务中的表现。
然而现有方法陷入两难:
- 语言CoT逻辑清晰但脱离物理细节且延迟高;
- 基于图像或状态预测的CoT更“物理”,却计算繁重、难以实时。
结果往往是——推理越清晰,动作越慢;控制越快,规划越短视。
对此,北京大学等机构提出LaST₀:不追求在“说清楚”和“动得快”之间折中,而是换个思路——
如果机器人不再“把想法说出来”,能否想得更快?LaST₀的核心目标正是:保留“先想再动”的能力,但彻底摒弃显式推理。
01 模型架构
从整体数据流来看:
LaST0 围绕 Latent Spatio-Temporal CoT 构建了一套双专家架构,将推理过程从语言空间中解耦出来,并在时间尺度上与高频动作生成分离。
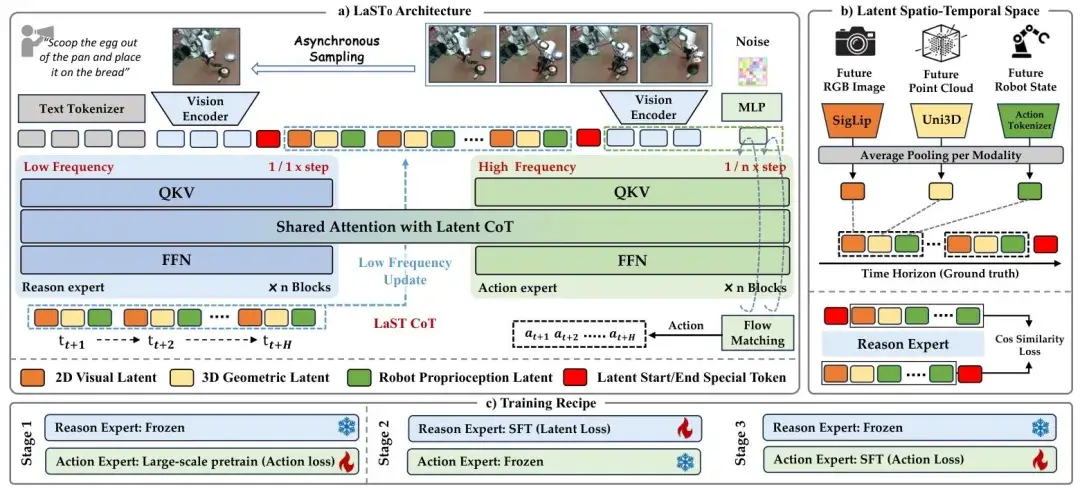
▲图2| 模型整体框架。a) LaST0,这是一个具有双系统架构的统一VLA模型。b) 时空潜在空间为监督推理专家的真实潜在CoT目标。c) 训练过程包括三个阶段
模型接收三类输入:
- 任务指令文本:经 Tokenizer 编码,仅作为全局任务约束参与注意力计算;
- 当前视觉观测:通过 Vision Encoder 转换为视觉 token,提供环境感知信息;
- 机器人本体状态:描述关节与运动状态,补充控制相关约束。
这些多模态 token 不直接用于动作生成,而是统一送入隐空间,作为 Latent Spatio-Temporal CoT 的初始条件。
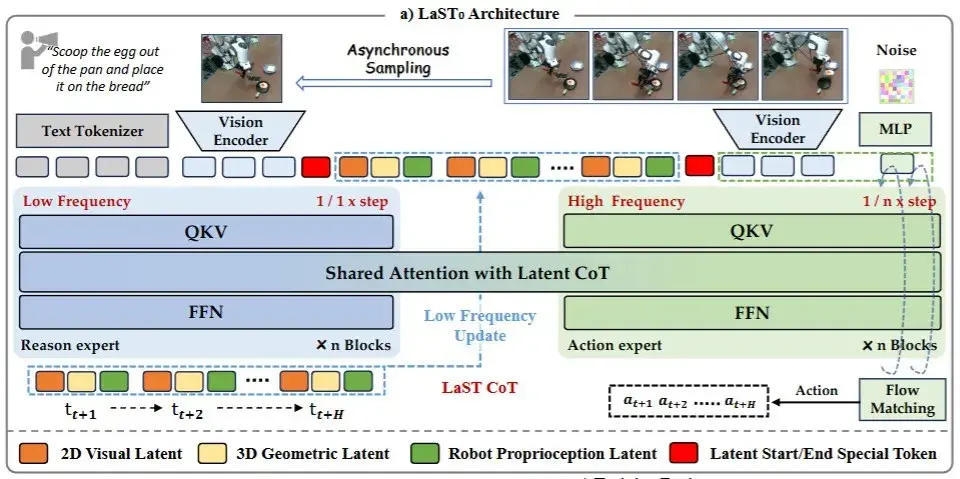
▲图4 模型整体架构
随后,低频运行的 Reason Expert 开始在隐空间中进行推理更新。
与传统方法不同,这一阶段并不预测具体动作,而是生成一段跨时间展开的 latent CoT 序列,用以刻画未来多个时间步的整体行动趋势。
这些 latent 表示由三部分组成:
- 表征场景外观与布局的 2D 视觉 latent;
- 编码空间关系的 3D 几何 latent;
- 以及反映关节状态与运动约束的机器人本体 latent。
它们在时间维度上被串联起来,形成一个连续演化的隐式推理轨迹。
在此基础上,高频运行的 Action Expert 在每一个控制步中,从当前的 latent CoT 状态中读取与当下最相关的信息,并生成连续动作输出。
Action Expert 并不会反向修改 latent CoT,而是将其视作一个随时间缓慢变化的上下文,从而在不反复触发完整推理的情况下,保持动作生成的连续性与稳定性。
两者通过共享的注意力机制进行协同,但更新频率不同:推理以低频跨时间演化,动作以高频实时执行。
这种设计使得 LaST0 不再要求机器人在每一步动作前都显式完成一次完整推理,而是实现了“想得慢、动得快”的协同模式。
核心思想:把 CoT 从“语言”里拿走
Chain-of-Thought 的本质并不是语言,而是一种中间态。
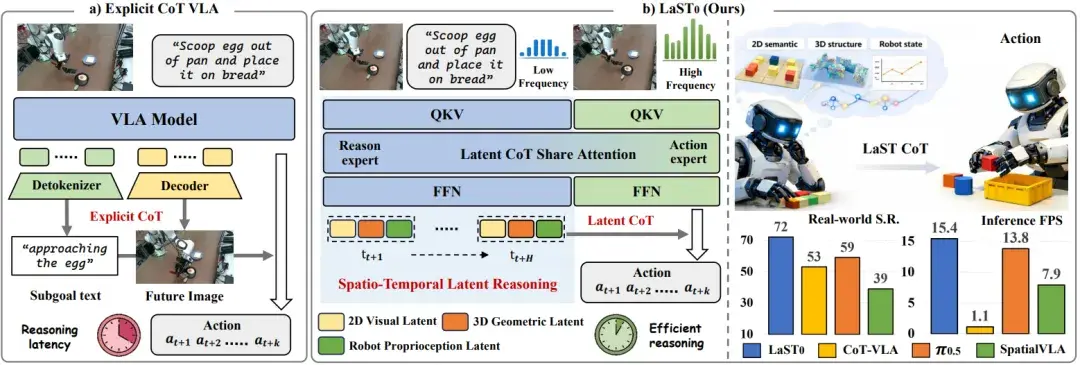
▲图5 | 不同于以往的VLA方法通过显式生成语言推理轨迹或未来视觉观测来改进操作,LaST0通过潜在时空思维链(Latent Spatio-Temporal CoT)实现行动前高效推理的框架。
语言只是人类理解推理过程的一种载体,但对机器人而言,它反而构成了明显的表达瓶颈。
在真实物理世界中,许多对操作至关重要的信息,并不天然适合被离散化为语言 token,当推理被强制投射到语言空间中时,这些信息要么被粗略抽象,要么被完全忽略,最终导致“推理看起来很合理,但动作并不稳定”。
基于这一判断,LaST0 选择保留 CoT 的“结构性”,但彻底放弃其“可读性”。
具体而言,研究提出了 Latent Spatio-Temporal Chain-of-Thought,将推理过程从语言 token 空间中移除,转而在隐空间中进行建模。
这一隐式 CoT 具有三个关键特征:
- Latent:推理不再表示为显式的语言序列,而是隐空间中的连续向量表示,用于承载难以语言化的物理与控制信息;
- Spatio-Temporal:推理同时建模空间结构与时间演化,不仅关心“当前状态是什么”,也显式刻画“状态将如何变化”;
- Chain-of-Thought:推理不是一次性决策,而是一个随时间展开的中间状态序列,形成跨多个时间步的隐式推理轨迹。

在形式上,LaST0 将 latent CoT 表示为一段时间展开的隐变量序列:
其中每一个 都是多模态信息的融合,包括视觉、几何以及机器人本体相关的状态表示。
这些 latent token 在时间维度上连续演化,构成一条隐式推理轨迹——
用来刻画机器人“接下来一段时间内应该如何行动”的整体趋势,而非直接预测某一个瞬时动作。
值得强调的是,这些隐式 CoT 并不需要被解码成人类可读的语言或中间规划结果,它们存在的唯一目标,是为动作生成提供充分且与物理世界一致的中间表征。
对机器人控制任务而言,推理的有效性不再取决于人类是否能理解其过程,而取决于它能否支撑稳定、可靠的动作执行。
低频推理与高频动作如何协同
在 LaST0 中,核心挑战并不在于分别设计推理与动作模块,而在于如何让二者在不同时间尺度下稳定协同。
如果协调方式不当,低频推理要么成为高频控制的瓶颈,要么被动作过程完全忽略。
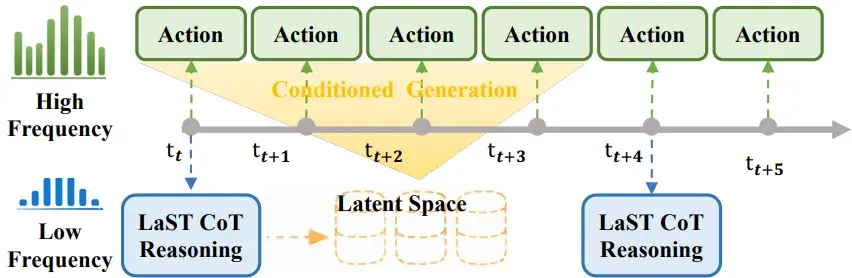
▲图6 | 慢推理专家执行低频潜在思维链推理,以捕捉长时程时空依赖关系,而快速行动专家则基于高频观测和定期更新的潜在知识生成行动。得益于在快慢操作比率混合下的训练,该模型在测试时能够灵活调整推理-行动频率比。
LaST0 采用的解决思路是:通过共享隐空间状态进行异步协同,而非显式指令传递。
具体而言,推理与动作共享同一组 Latent Spatio-Temporal CoT 表示,但对其采取不同的更新策略。推理阶段以较低频率更新隐状态:
其中 表示来自视觉、本体等多模态观测的输入。该更新并不对应单一步动作,而是刻画跨多个时间步的整体行动趋势。
与之对应,动作生成在每一个控制步上运行:
其中当前动作 以最新的 latent CoT 状态
作为条件,但不会反向修改
。
这使得 latent CoT 在多个控制步之间保持相对稳定,仅在推理阶段被更新。
这种设计在时间维度上明确区分了状态更新与状态使用:latent CoT 以低频跨时间演化,而动作生成以高频连续展开。
两者通过共享注意力结构在隐空间中对齐,但更新节奏彼此独立,从而避免了高频控制过程中反复触发完整推理。
在训练阶段,这种异步协同被显式强化。模型被约束在多个时间步内复用同一 latent CoT 状态,同时通过动作监督确保控制输出的稳定性。
这一过程促使 latent CoT 逐渐演化为一种跨时间的行动上下文,而非瞬时决策结果。
02 实验
研究进行了多组真机实验。
- 在“将鸡蛋放到面包上”这一三阶段长时任务中
LaST₀在真实机器人环境中显著优于基线方法,尤其表现突出。

▲表1 | 标准的单臂和双臂任务(左),以及一个在三个连续步骤中评估的长时任务(右)。
前两步各方法成功率相近,但至第三步,和SpatialVLA成功率骤降至0.07和0,而LaST₀仍保持0.33,较基线提升近5倍。
这验证了LaST₀的核心优势:
latent CoT作为持续演化的隐式上下文 ,有效维持推理状态的跨时间一致性, 克服了显式CoT-VLA在长时任务中推理不一致的问题 ,显著提升了多阶段任务的执行稳定性。

▲表2 | LaST0 与基线在RLBench上的比较。
- 在不同模型的推理速度实验上
显式 CoT-VLA 由于需要自回归生成语言推理轨迹,推理速度仅 1.1 Hz;
作为纯动作模型,无显式推理,速度提升至 13.8 Hz。
相比之下,LaST₀ 达到 15.4 Hz,在精度显著优于显式 CoT-VLA 的同时,推理速度已接近甚至超过纯动作模型。
- 在注意力分布实验中
无CoT时注意力分散,依赖局部线索,难以持续聚焦任务关键区域;
显式语言CoT虽扩大关注范围,但注意力嘈杂,频繁切换非关键区域,体现推理与动作脱节;
LaST CoT则显著集中于当前操作的核心物体与接触点,且跨时间步保持稳定。
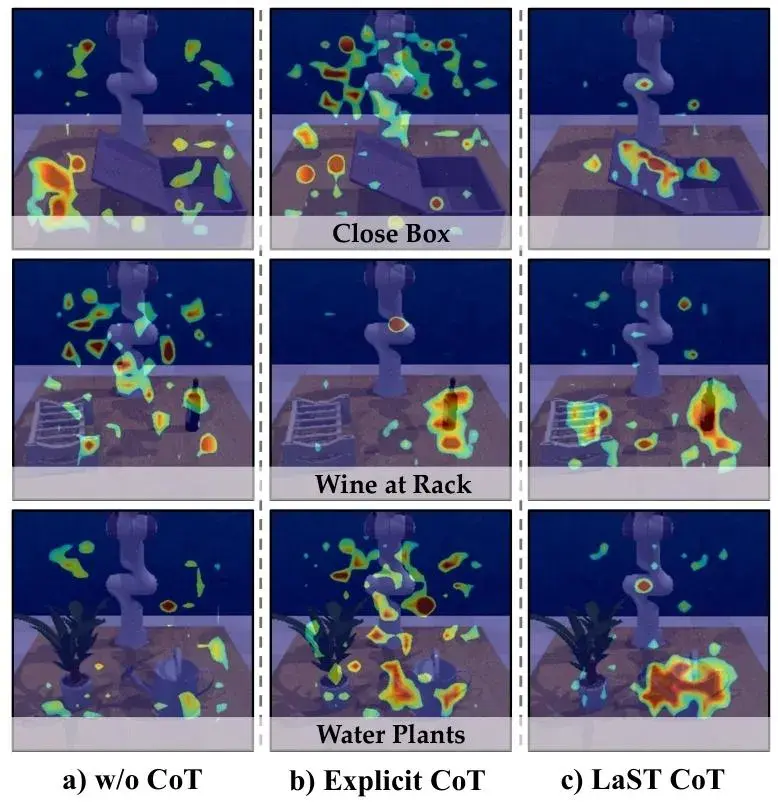
▲图7 | 三个VLA模型最后一层的注意力热力图可视化:(a) LaST0(无CoT推理)(b) CoT-VLA中的显式CoT (c) 带有LaST CoT的LaST0。
这表明LaST通过隐式推理在潜空间中持续约束感知与动作,使模型“看得更对、看得更久”,而非简单增加信息量。
该机制有效提升了长时多阶段任务中的行为一致性与稳定性,验证了其在复杂操作中维持任务焦点的关键优势。
03 结语
从本质上看,LaST₀ 仍然是一项关于 CoT 技术在 VLA 领域中的研究。
不同之处在于,它并未继续沿着“如何把推理说得更清楚”的方向前进,而是系统性地回答了另一个更现实的问题:
在机器人控制中,CoT 应该以什么形式存在,才不会成为负担?
这项研究结果表明,CoT 的价值并不依赖于语言化或可解释性——当推理以隐式、时空一致的中间状态存在,并与高频动作生成在时间尺度上解耦时,CoT 不仅不会拖慢控制,反而能够在长时、多阶段任务中持续发挥约束作用。
换言之,LaST₀ 给出的不是一个“更复杂的推理模型”,而是一个更明确的结论:在 VLA 中,CoT 是否有用,取决于它是否被放在了适合动作的空间里。
Ref:
论文题目:LaST0: Latent Spatio-Temporal Chain-of-Thoughtfor Robotic Vision–Language–Action Mode
论文作者:Zhuoyang Liu, Jiaming Liu, Hao Chen, Ziyu Guo, Chengkai Hou, Chenyang Gu, Jiale Yu, Xiangju Mi, Renrui Zhang, Zhengping Che, Jian Tang, Pheng-Ann Heng, Shanghang Zhang
论文地址:https://arxiv.org/pdf/2601.05248v1

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 13
13 0
0- 0



 已为社区贡献87条内容
已为社区贡献87条内容

所有评论(0)