从辩论训练到具身智能——辩核AI具身辩论数字人系统整体设计思路
辩核AI具身辩论数字人训练系统,正是基于这一现实需求而提出的一种新型解决方案。它并非简单地“接入一个大模型”,而是围绕辩论训练的真实流程,从交互形态、系统架构和能力边界三个层面进行整体设计,引入虚拟人具身表达、语音交互和多模式辩论策略,使 AI 从“会说话”走向“会辩论、会训练、会反馈”。本文作为系列文章的第一篇,将从整体视角出发,重点回答三个问题:为什么要做这样一个系统,这个系统解决什么问题,以
目录
前言
近年来,大语言模型在自然语言理解与生成方面取得了跨越式发展,但在真实训练场景中,单纯依赖“文本对话”的 AI 系统仍然存在明显短板。尤其是在辩论训练这一高度依赖逻辑攻防、语言节奏和即时反馈的场景中,传统 AI 产品往往只能充当“答题器”或“陪聊者”,难以真正模拟专业辩论对手或教练的角色。
辩核AI具身辩论数字人训练系统,正是基于这一现实需求而提出的一种新型解决方案。它并非简单地“接入一个大模型”,而是围绕辩论训练的真实流程,从交互形态、系统架构和能力边界三个层面进行整体设计,引入虚拟人具身表达、语音交互和多模式辩论策略,使 AI 从“会说话”走向“会辩论、会训练、会反馈”。
本文作为系列文章的第一篇,将从整体视角出发,重点回答三个问题:为什么要做这样一个系统,这个系统解决什么问题,以及它在架构层面是如何被系统性设计的。
1 为什么需要 AI 具身辩论训练系统
1.1 传统辩论训练的现实痛点
在传统辩论训练中,高质量的陪练资源始终是稀缺品。专业辩手、教练或高水平对手往往时间成本高、数量有限,难以支撑高频、个性化的训练需求。训练过程往往依赖线下组织,难以做到随时随地练习,也很难对每一次发言进行系统化记录与分析。
此外,人工训练在稳定性和一致性方面也存在天然不足。不同陪练的风格、水平和关注点差异较大,训练效果高度依赖个人经验,难以形成标准化、可复用的训练体系。
1.2 人工陪练与文本 AI 的局限
随着大语言模型的普及,一部分辩论训练开始尝试借助文本 AI 来进行辅助。然而,纯文本形态的 AI 在辩论训练中依然存在明显局限。一方面,文本交互缺乏节奏感与临场感,难以模拟真实对抗中的心理压力;另一方面,通用对话模型更偏向“给答案”,而非“制造对抗”和“引导成长”。
人工陪练与文本 AI 在能力结构上的不足,使得辩论训练长期处于“要么成本高,要么体验弱”的两难状态。
1.3 具身智能与大模型带来的新可能
具身智能的引入,为这一问题提供了新的解法。当 AI 不再只是屏幕上的文字,而是以“数字人”的形态参与交流,并通过语音、表情和状态变化来表达策略与态度时,训练体验将发生本质变化。
结合大语言模型的推理与生成能力,具身辩论 AI 不仅可以完成观点输出,还可以在对抗强度、表达风格和反馈方式上进行精细控制,从而更接近真实辩论环境。这正是辩核AI具身辩论数字人训练系统的出发点。
2 系统应用场景与核心目标
2.1 面向辩论选手的系统化训练
对于辩论选手而言,该系统的核心价值在于提供一种可随时使用、可反复训练的对抗环境。系统可以根据用户输入自动采取相反立场,并在多轮对话中持续施压,帮助用户打磨论证结构、语言表达与临场反应能力。
2.2 面向教学场景的辅助工具
在教学场景中,系统可以作为课堂或课后训练的延伸工具。教师可以引导学生围绕具体辩题与 AI 进行互动,由系统提供标准化的分析视角和反馈结果,从而在有限的教学时间内覆盖更多训练场景。
2.3 逻辑思维与表达能力训练
辩论训练的价值并不局限于比赛本身。通过结构化对抗与反馈机制,系统同样适用于逻辑思维训练、演讲表达训练以及观点构建能力的提升,为更广泛的用户群体提供支持。
2.4 可扩展的数字人应用方向
从更长远的角度看,辩核AI系统并不是一个“一次性产品”。其核心架构具备良好的扩展性,可以自然演化为数字教练、虚拟讲师或智能助教,为其他需要高强度语言交互的场景提供基础能力。
3 系统总体架构设计
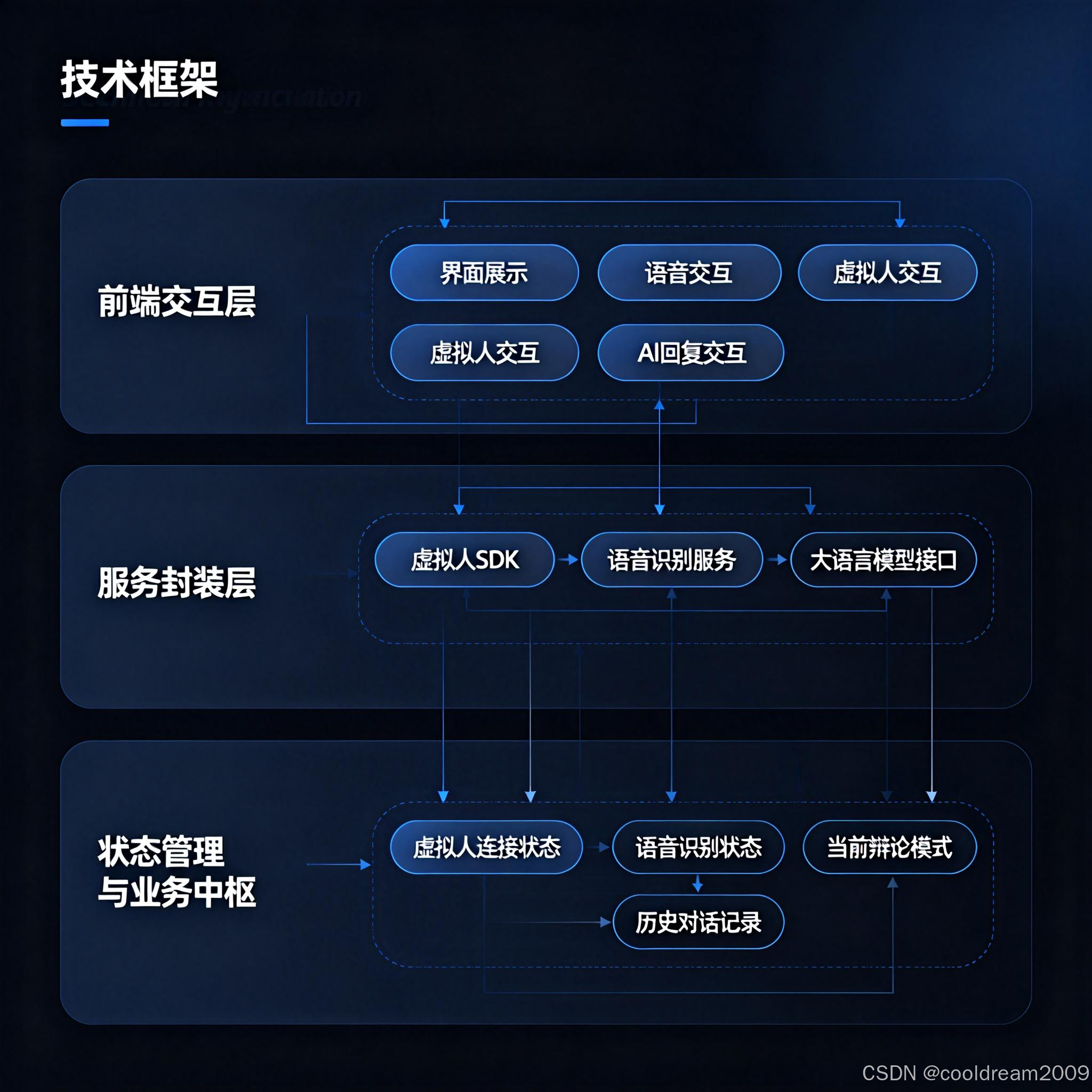
3.1 分层架构的整体思路
在架构层面,系统采用清晰的分层设计,将复杂问题拆解为多个职责明确的层次。这种设计不仅有助于降低系统复杂度,也为后续的维护和扩展提供了稳定基础。
从逻辑上看,系统主要由前端交互层、服务封装层和状态管理与业务中枢三部分构成。
3.2 前端交互层
前端交互层是用户直接感知系统能力的入口。它不仅承担界面展示的职责,更是语音、虚拟人和 AI 回复等多模态交互的整合中心。通过组件化与响应式设计,前端能够实时反映系统状态变化,确保交互体验的连贯性。
3.3 服务封装层
服务封装层负责对外部能力进行统一抽象,包括虚拟人 SDK、语音识别服务以及大语言模型接口。通过这一层的封装,系统内部逻辑不直接依赖具体厂商或实现细节,从而显著提升了系统的可替换性与稳定性。
3.4 状态管理与业务中枢
状态管理层是系统的“神经中枢”。它集中管理虚拟人连接状态、语音识别状态、当前辩论模式以及历史对话记录等关键信息,并协调各模块之间的数据流转,确保系统在复杂交互场景下依然保持一致性。
4 核心能力拆解
从能力维度来看,辩核AI具身辩论数字人训练系统并非单一技术的叠加,而是多种能力的有机组合。
系统的核心能力可以概括为以下四个方面(本段为全文唯一一次无序列表):
- 智能对话能力:基于大语言模型,生成符合辩论语境的观点、反驳与总结
- 语音交互能力:支持实时语音输入与语音播报,降低交互门槛
- 虚拟人具身表达能力:通过 3D 数字人传递语气、节奏与状态信息
- 多模式辩论策略能力:根据不同训练目标动态调整对抗强度与反馈方式
这四种能力并非孤立存在,而是在系统中相互协同,共同服务于“训练效果最大化”这一核心目标。
5 系统设计的关键原则
5.1 模块化与低耦合
系统在设计之初就强调模块职责边界的清晰划分。通过服务封装与状态集中管理,各模块之间通过明确接口进行协作,避免相互侵入,从而降低整体复杂度。
5.2 实时性优先
辩论训练高度依赖即时反馈。无论是语音识别、AI 回复还是虚拟人表现,系统都将实时性作为优先设计目标,避免长时间等待破坏训练节奏。
5.3 面向训练而非闲聊
与通用对话产品不同,本系统始终围绕“训练效果”进行设计。所有回复策略、字数控制和反馈机制,都是为提升用户能力服务,而非追求对话的娱乐性。
5.4 可扩展、可替换的技术选型
在技术选型上,系统避免对单一厂商或模型形成强绑定。通过抽象接口与配置化设计,可以在不重构整体架构的前提下,灵活替换底层能力组件。
结语
辩核AI具身辩论数字人训练系统的核心价值,并不在于“用了多少新技术”,而在于是否真正理解并尊重辩论训练这一场景的本质需求。通过将大语言模型、语音交互与虚拟人具身表达进行系统性整合,该系统尝试为辩论训练提供一种低成本、高沉浸、可持续的新范式。
在接下来的系列文章中,将分别从前端架构、虚拟人系统、AI 对话机制以及训练模式设计等角度,对这一系统进行更为深入的技术拆解与实践分析。
参考资料
- Vue.js 官方文档(Composition API)
- TypeScript Handbook
- 具身智能与多模态交互相关研究综述
- 大语言模型在教育与训练场景中的应用实践

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 4
4 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)