薛定谔导航器:让机器人学会“想象“未来的零样本目标导航框架
薛定谔导航器:基于量子思想的新型机器人导航方法 摘要:受薛定谔猫思想实验启发,本文提出了一种创新的机器人导航方法"薛定谔导航器"。该方法通过将未知空间建模为多个可能世界的叠加态,使机器人能够在行动前"想象"遮挡物背后可能存在的场景。系统采用三条候选轨迹(左绕、右绕、上越)覆盖主要方位,并利用3D高斯溅射技术快速渲染未来可能的3D场景。相比传统方法仅依赖当前观
1. 引言
1935年,物理学家埃尔温·薛定谔提出了著名的"薛定谔的猫"思想实验,用以阐释量子力学中的叠加态概念:在打开盒子观测之前,盒中的猫同时处于"既死又活"的叠加状态。这一思想实验深刻揭示了观测行为对系统状态的决定性影响,也启发了后世无数科学家对不确定性问题的思考。
在机器人导航领域,研究者们同样面临着一个类似的困境:当目标物体被障碍物遮挡时,机器人如何判断目标究竟在遮挡物的哪一侧?在未实际移动观测之前,目标的位置对于机器人而言同样处于一种"不确定"的状态。传统的导航方法只能依赖当前视野内的信息做出决策,对于视野之外的空间几乎束手无策。这种"短视"策略在简单环境中或许可行,但在复杂、杂乱的真实场景中往往导致导航失败。
本文介绍的"薛定谔导航器"(Schrödinger’s Navigator: Imagining an Ensemble of Futures for Zero-Shot Object Navigation)正是受到这一思想实验的启发,提出了一种全新的导航范式:在行动之前,先在"脑海"中想象多种可能的未来场景,然后基于这些想象做出最优决策。这一方法使机器人能够"看穿"遮挡物、预判潜在风险、追踪移动目标,在复杂真实环境中展现出显著优势。目前代码还没有开源,可以关注一下:https://heyu322.github.io/Schrodinger-Navigator.github.io/

图1:当猫被桌子遮挡时,传统方法只能看到桌子,而薛定谔导航器会同时想象从左、右、上三个方向绕行后可能观测到的场景
2. 研究背景:目标导航的核心挑战
2.1 什么是目标导航
目标导航(Object Navigation)是移动机器人研究中的基础任务之一。其核心目标是:给定一条自然语言指令(如"找到猫"),机器人需要在一个陌生环境中自主探索,最终定位并接近指定的目标物体。这一能力是家庭服务机器人、仓储物流机器人、搜救机器人等实际应用的基础。
零样本目标导航(Zero-Shot Object Navigation)进一步提高了任务难度:机器人不能依赖预先构建的环境地图,也不能针对特定任务进行训练,而是需要在完全陌生的环境中"即插即用"地完成导航任务。这对机器人的泛化能力和推理能力提出了极高的要求。
2.2 现实世界的三大挑战
尽管近年来零样本目标导航方法取得了长足进步,但在真实世界的复杂环境中,现有方法仍然面临三大核心挑战:
挑战一:严重的静态遮挡
在家庭、办公室等室内环境中,家具、墙壁、杂物等障碍物无处不在。当目标物体被这些障碍物完全遮挡时,机器人的传感器无法直接感知目标的存在。例如,一只猫躲在沙发后面,机器人看到的只是沙发的背面,根本不知道猫在哪里,也不知道应该从左边还是右边绕行才能找到它。
挑战二:未知的潜在风险
真实环境中可能存在各种潜在危险,如楼梯边缘、悬崖、突然出现的障碍物等。这些风险区域可能完全位于机器人当前视野之外。如果机器人无法预判这些风险,可能会在导航过程中陷入危险境地。
挑战三:动态移动的目标
在许多实际场景中,目标物体本身可能是移动的。例如,寻找一只正在走动的宠物猫,或者追踪一个移动的人。传统方法假设目标静止不动,一旦目标移动,之前建立的目标位置估计就会失效,导致导航失败。
2.3 现有方法的根本局限
现有方法的根本局限在于:它们只能基于当前观测做决策,无法对尚未观测到的空间进行推理。换言之,现有方法都是"短视"的——它们只能看到眼前的场景,无法"想象"遮挡物背后可能存在什么。这正是薛定谔导航器要解决的核心问题。
3. 核心思想:将未知空间建模为"可能世界的叠加"
3.1 从量子力学到机器人导航的思想迁移
薛定谔导航器的核心思想可以用一句话概括:将机器人尚未观测到的空间视为多个"可能的未来世界"的叠加态,在行动之前对这些可能世界进行推理,然后选择最优路径。
具体而言,当机器人面对一个被遮挡的区域时,它不是简单地假设遮挡物背后是空的或者存在某个特定物体,而是同时想象多种可能的场景:目标可能在左边、可能在右边、也可能在上方。然后,机器人评估沿不同路径行进后可能观测到的场景,选择最有可能找到目标且最安全的路径。
3.2 三条候选轨迹:覆盖遮挡区域的主要方位
为了在计算效率和覆盖范围之间取得平衡,薛定谔导航器在每个决策步采样三条候选轨迹:
- 左绕路径(Left Bypass):绕过障碍物的左侧
- 右绕路径(Right Bypass):绕过障碍物的右侧
- 上越路径(Over-the-Top):从障碍物上方越过
这三条轨迹的设计基于一个简单但有效的观察:对于大多数遮挡场景,目标物体要么在障碍物的左侧、右侧,要么在障碍物的上方/后方。通过同时想象这三个方向的未来场景,机器人可以获得对遮挡区域的全面覆盖,同时避免过多的计算开销。
4. 技术方法:从"看见"到"预见"的实现路径
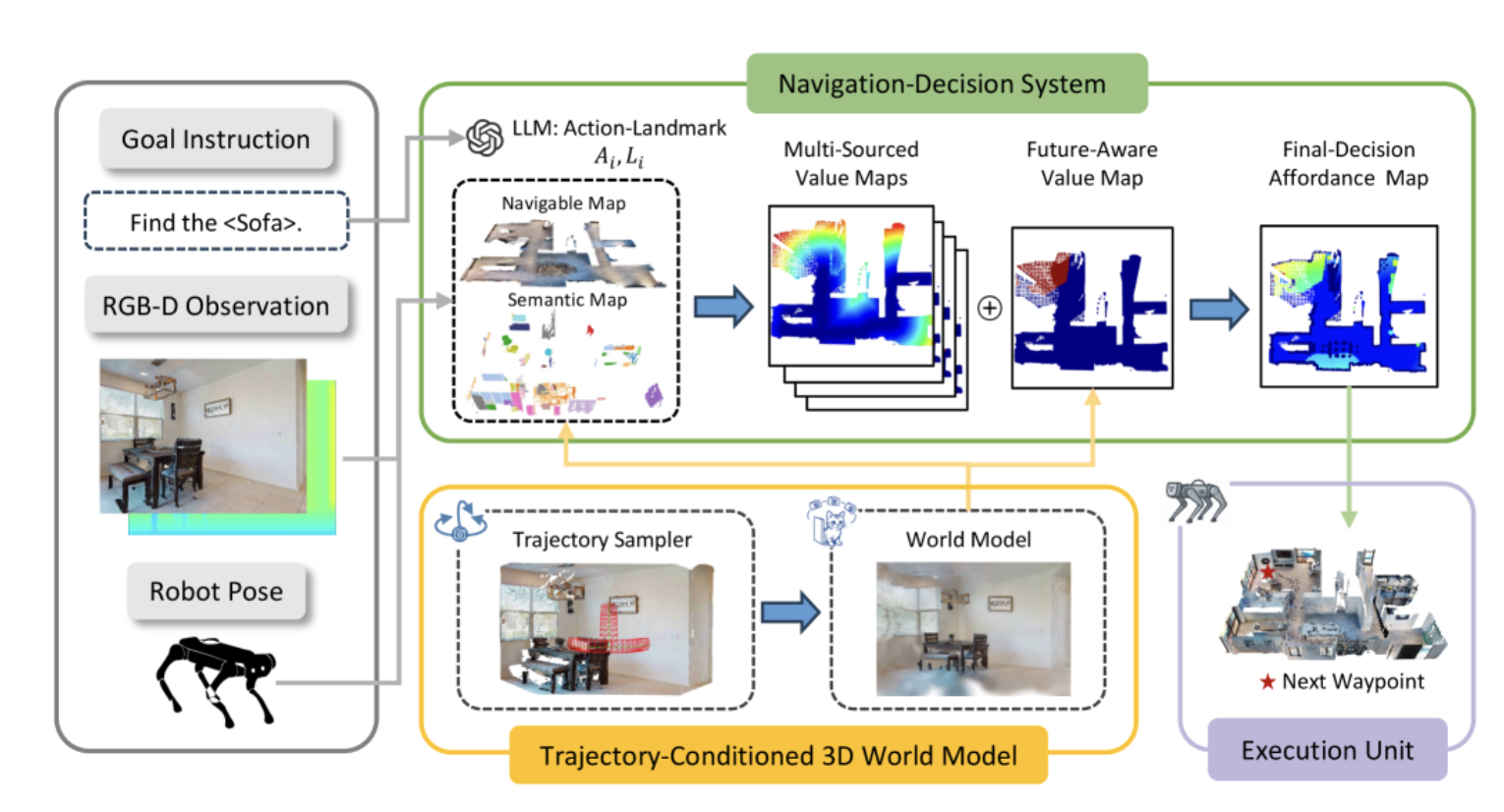
4.1 系统整体架构
薛定谔导航器的整体架构可以分为四个核心模块:
- 输入处理模块:接收自然语言目标指令、RGB-D观测(彩色图像和深度图)以及机器人当前位姿
- 轨迹采样模块:生成三条候选轨迹(左绕、右绕、上越)
- 3D世界模型模块:基于当前观测和候选轨迹,想象各路径的未来3D场景
- 导航决策模块:融合当前观测和想象结果,构建价值地图并输出导航决策
系统整体流程伪代码:
def schrodinger_navigator(goal_instruction, max_steps):
"""
薛定谔导航器主循环
输入: goal_instruction - 自然语言目标指令(如"找到猫")
max_steps - 最大导航步数
输出: 导航是否成功
"""
# 初始化
global_3dgs_scene = {} # 全局3DGS场景表示
navigation_history = [] # 导航历史轨迹
for step in range(max_steps):
# 步骤1: 获取当前观测
rgb_image, depth_map, robot_pose = get_current_observation()
# 步骤2: 检查是否已到达目标
if target_in_view(rgb_image, goal_instruction) and distance_to_target() < 0.5:
return SUCCESS
# 步骤3: 生成三条候选轨迹
trajectories = generate_tri_trajectories(robot_pose)
# trajectories = {left_bypass, right_bypass, over_the_top}
# 步骤4: 对每条轨迹进行未来场景想象
imagined_scenes = {}
for traj_type, trajectory in trajectories.items():
# 使用3D世界模型想象未来场景
imagined_3dgs = world_model.imagine(rgb_image, trajectory)
# 对齐到全局坐标系
aligned_3dgs = align_to_world_frame(imagined_3dgs, robot_pose, depth_map)
# 添加语义标签
semantic_3dgs = transfer_semantic_labels(aligned_3dgs, rgb_image)
imagined_scenes[traj_type] = semantic_3dgs
# 步骤5: 融合想象场景到全局表示
global_3dgs_scene = merge_scenes(global_3dgs_scene, imagined_scenes)
# 步骤6: 构建价值地图并选择最优目标点
value_map = build_future_aware_value_map(global_3dgs_scene, goal_instruction)
next_waypoint = select_best_waypoint(value_map)
# 步骤7: 执行导航动作
execute_navigation(next_waypoint)
navigation_history.append(robot_pose)
return FAILURE # 超时失败
4.2 轨迹条件化3D世界模型
轨迹条件化3D世界模型是薛定谔导航器的核心技术创新。其基本思路是:给定当前的视觉观测和一条候选轨迹,模型能够"想象"出沿该轨迹行进时可能观测到的3D场景。
本文采用3D高斯溅射(3D Gaussian Splatting, 3DGS)作为场景表示方式。3DGS是近年来计算机图形学领域的重要突破,它使用大量的3D高斯基元来表示场景,每个高斯基元包含位置、颜色、不透明度等属性。相比传统的神经辐射场(NeRF),3DGS具有更快的渲染速度和更好的几何一致性,非常适合用于实时导航场景。
轨迹生成与场景想象伪代码:
def generate_tri_trajectories(robot_pose):
"""
生成三条候选轨迹:左绕、右绕、上越
"""
trajectories = {}
# 左绕轨迹:相机沿障碍物左侧弧形运动
trajectories['left'] = generate_arc_trajectory(
center=robot_pose,
direction='left',
num_cameras=8,
arc_length=2.0 # 米
)
# 右绕轨迹:相机沿障碍物右侧弧形运动
trajectories['right'] = generate_arc_trajectory(
center=robot_pose,
direction='right',
num_cameras=8,
arc_length=2.0
)
# 上越轨迹:相机从上方越过障碍物
trajectories['over'] = generate_arc_trajectory(
center=robot_pose,
direction='up',
num_cameras=8,
arc_length=1.5
)
return trajectories
4.3 场景对齐:从想象到现实的桥梁
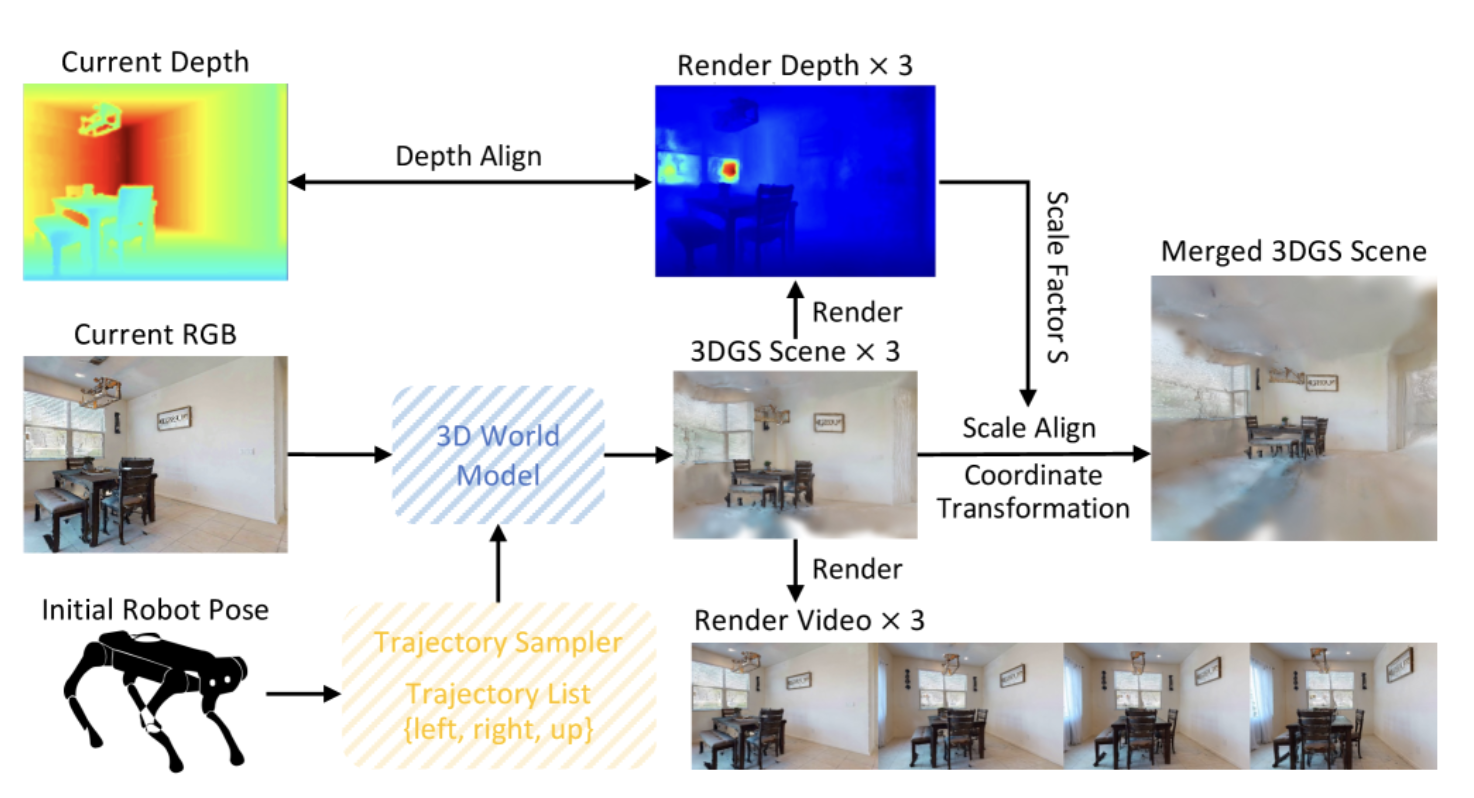
世界模型生成的场景存在一个关键问题:它是"仿射不变"的,即生成的场景无法直接与真实环境的度量尺度对齐。为了解决这一问题,本文设计了两步对齐流程:坐标系变换和全局尺度对齐。
尺度对齐的核心公式为: s = median ( D g t / D r e n d e r ) s = \text{median}(D_{gt} / D_{render}) s=median(Dgt/Drender),其中 D g t D_{gt} Dgt 为真实深度, D r e n d e r D_{render} Drender 为渲染深度。
场景对齐伪代码:
def align_to_world_frame(imagined_3dgs, robot_pose, real_depth):
"""
将想象的3DGS场景对齐到世界坐标系
"""
# 步骤1: 坐标系变换
# 从局部坐标系变换到世界坐标系
T_local_to_world = robot_pose.transformation_matrix
for gaussian in imagined_3dgs:
gaussian.position = T_local_to_world @ gaussian.position
# 步骤2: 全局尺度对齐
# 渲染当前视角的深度图
rendered_depth = render_depth(imagined_3dgs, robot_pose)
# 计算尺度因子(使用中值提高鲁棒性)
valid_pixels = (real_depth > 0) & (rendered_depth > 0)
scale_factor = median(real_depth[valid_pixels] / rendered_depth[valid_pixels])
# 应用尺度因子
for gaussian in imagined_3dgs:
gaussian.position *= scale_factor
return imagined_3dgs
4.4 语义标签迁移
…详情请参照古月居

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 7
7 0
0- 0



 已为社区贡献63条内容
已为社区贡献63条内容

所有评论(0)