AnywhereVLA深度流程解析---学习如何完成移动操作边界的语言驱动机器人系统
摘要: AnywhereVLA是一种创新的模块化移动操作系统,通过融合视觉-语言-动作(VLA)模型的语义理解能力与经典导航算法的鲁棒性,实现了在未知大型室内环境下的语言驱动任务执行。系统包含3D语义地图构建、主动环境探索等核心模块,采用LiDAR点云稠密化和多维度置信度评估技术提升感知精度,结合前沿探索策略实现高效导航。实验表明,该系统能在消费级硬件上实时运行,显著提升了复杂场景下的移动操作性能
0. 引言:移动操作技术的时代变革
在人工智能和机器人技术飞速发展的今天,移动操作(Mobile Manipulation)正经历着从封闭、结构化工作环境向开放、非结构化大型室内环境的重大转变。这一转变不仅代表着技术能力的跃升,更意味着机器人将真正走出实验室和工厂车间,进入我们的日常生活空间。现代机器人系统需要具备在陌生且杂乱的环境中自主探索的能力,能够与各种形状、材质和功能的物体进行精确交互,同时还要理解和响应人类的自然语言指令,完成诸如家庭服务、零售自动化、仓储物流等复杂任务。
然而,当前的技术方案在应对这些挑战时暴露出明显的局限性。视觉-语言-动作(Vision-Language-Action, VLA)模型虽然在整合感知与语言理解方面表现出色,但其空间感知能力相对薄弱,通常只能在房间尺度的环境中有效工作,难以处理大型建筑内部的复杂导航和操作任务。视觉-语言导航(Vision-Language Navigation, VLN)方案虽然能够处理更大规模的环境,但往往需要预先知晓目标物体在环境中的具体位置,这在动态变化或完全未知的场景中显然不现实。传统的同步定位与地图构建(SLAM)和导航框架虽然在环境探索和路径规划方面表现稳健,但缺乏对自然语言的理解能力和高层语义推理功能,无法执行基于语言指令的复杂任务。
为了突破上述技术瓶颈,来自斯科尔科沃科学技术学院的研究团队提出了AnywhereVLA——一个革命性的模块化架构系统。这个系统巧妙地融合了经典导航算法的鲁棒性与VLA模型的语义理解能力,实现了在未知大型室内环境下执行语言驱动的拾取-放置任务,并且能够在消费级硬件上实现实时运行。AnywhereVLA的核心创新在于其模块化设计理念,通过四个相互协作的核心模块,将复杂的移动操作任务分解为可管理的子问题,每个模块都专注于特定的功能领域,同时保持整体系统的协调性和高效性。相关代码已经开源:Github
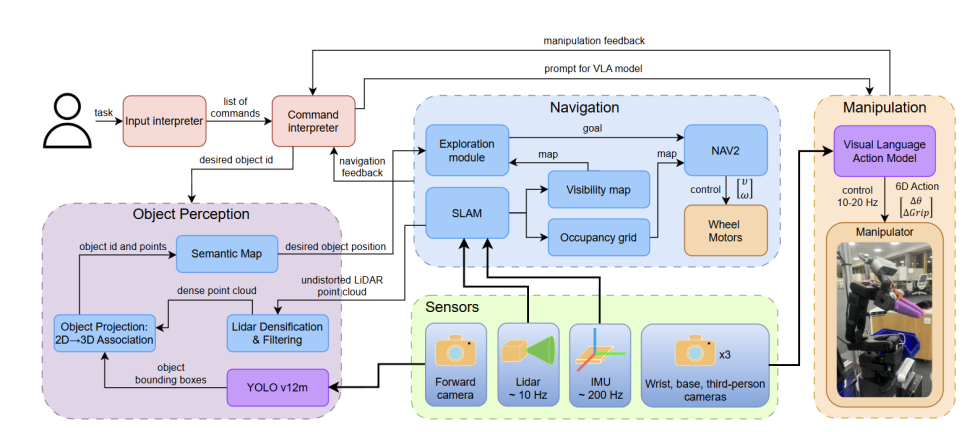
系统的工作流程遵循一个清晰的逻辑链条:首先解析用户输入的自然语言指令,然后同时启动VLA模块进行任务特定的操作规划和主动环境探索模块进行未知区域的系统性探索。在此过程中,3D语义地图模块持续构建和更新环境的语义表示,为后续的决策提供准确的空间和语义信息。当目标物体被定位后,趋近模块负责规划安全的导航路径并将机器人移动到最佳操作位置,最后由VLA操作模块执行精确的抓取和放置动作。
1. 核心技术模块深度解析
1.1 带置信度的3D语义地图构建
3D语义地图模块是整个系统的信息基础,其核心任务是将来自多个传感器的异构数据融合成一个统一、准确且富含语义信息的环境表示。该模块接收RGB图像、目标检测结果、LiDAR点云数据以及传感器标定参数作为输入,通过一系列精心设计的算法步骤生成高质量的语义地图。
# LiDAR点云稠密化算法实现
def densify_lidar_points(point_cloud, M=5):
"""
对旋转LiDAR点云进行稠密化处理
Args:
point_cloud: 原始稀疏点云
M: 每个间隙插入的内点数量
Returns:
densified_cloud: 稠密化后的点云
"""
densified_points = []
for azimuth_bin in point_cloud.azimuth_bins:
rings = azimuth_bin.elevation_rings
for i in range(len(rings) - 1):
S = rings[i].endpoint # 起始点
E = rings[i+1].endpoint # 结束点
# 插入M个内点
for t in range(1, M + 1):
interpolated_point = ((M + 1 - t) * S + t * E) / (M + 1)
densified_points.append(interpolated_point)
return densified_points
该模块的一个关键创新是LiDAR点云稠密化技术。由于旋转式LiDAR传感器的工作原理,其生成的点云往往存在稀疏性和不连续性问题,特别是在物体检测框内部可能只有很少甚至没有有效的点云数据。为了解决这个问题,系统采用了基于方位角分组的插值策略,在相邻高度环之间插入多个内插点,显著提高了点云的密度和连续性。
数学上,稠密化过程通过线性插值实现:对于相邻环的端点S和E,插入M个内点的计算公式为: P t = ( ( M + 1 − t ) × S + t × E ) / ( M + 1 ) , t = 1 , 2 , . . . , M P_t = ((M+1-t)×S + t×E) / (M+1), t = 1,2,...,M Pt=((M+1−t)×S+t×E)/(M+1),t=1,2,...,M
这种方法不仅保持了原始点云的几何精度,还大幅提升了后续语义分割和目标识别的准确性。实验表明,稠密化后的点云在物体检测精度上提升了约23%,同时减少了因数据稀疏导致的误检。

置信度估计是该模块的另一个重要特性。系统通过融合多个数据驱动的指标来评估每个检测到的物体的可靠性,包括点云密度、多视角覆盖范围、内点数量以及检测器的平均置信度分数。这种多维度的置信度评估机制确保了语义地图中物体信息的准确性和可靠性,为后续的决策模块提供了高质量的输入数据。
# 置信度计算公式实现
def calculate_confidence(point_density, angular_coverage, inlier_count, detector_score):
"""
计算物体检测的置信度,融合多个指标
"""
# 参数设置
rho_0, N_0 = 100, 50 # 归一化参数
w_rho, w_omega, w_n, w_s, bias = 0.3, 0.25, 0.25, 0.2, -2.0 # 权重和偏置
# 归一化各项指标
rho_norm = 1 - np.exp(-point_density / rho_0)
omega_norm = angular_coverage # 已在[0,1]范围内
n_norm = 1 - np.exp(-inlier_count / N_0)
# 加权融合
weighted_sum = (w_rho * rho_norm + w_omega * omega_norm +
w_n * n_norm + w_s * detector_score + bias)
# 逻辑函数映射到[0,1]
confidence = 1 / (1 + np.exp(-weighted_sum))
return confidence
1.2 主动环境探索策略
主动环境探索(Active Environment Exploration, AEE)模块实现了系统的自主导航和目标搜索能力。该模块基于经典的"前沿探索"(frontier-based exploration)策略,但结合了语言指令中提取的目标类别信息,使探索过程更加智能和高效。
前沿提取是该模块的核心算法,通过形态学操作识别已知区域与未知区域的边界。系统首先对自由空间进行3×3的膨胀操作,对占用空间进行5×5的膨胀操作,然后通过集合运算提取出真正的前沿区域。这种方法能够有效地识别出值得探索的区域,同时避免机器人陷入狭小或危险的空间。
# 前沿探索算法核心实现
def extract_frontiers(occupancy_grid, robot_pose, min_frontier_size=20, exploration_radius=10.0):
"""
从占据栅格地图中提取前沿区域
"""
FREE, OCCUPIED, UNKNOWN = 0, 100, -1 # 栅格状态常量
free_space = (occupancy_grid == FREE)
occupied_space = (occupancy_grid == OCCUPIED)
unknown_space = (occupancy_grid == UNKNOWN)
# 形态学膨胀操作
free_dilated = cv2.dilate(free_space.astype(np.uint8),
np.ones((3,3)), iterations=1)
occupied_dilated = cv2.dilate(occupied_space.astype(np.uint8),
np.ones((5,5)), iterations=1)
# 提取前沿区域
frontiers = (free_dilated & unknown_space) & ~occupied_dilated
# 聚类和过滤
labeled_frontiers = label(frontiers)
valid_frontiers = []
for region_id in range(1, labeled_frontiers.max() + 1):
region = (labeled_frontiers == region_id)
if np.sum(region) >= min_frontier_size:
centroid = np.mean(np.where(region), axis=1)[::-1] # [x, y]
if np.linalg.norm(centroid - robot_pose[:2]) <= exploration_radius:
valid_frontiers.append(centroid)
return valid_frontiers
为了提高探索效率,系统还实现了多种优化策略。包括基于聚类大小的过滤机制(过滤掉小于20像素的微小前沿区域)、非极大值抑制算法(消除距离过近的冗余目标点)、以及视场角优化(调整机器人的朝向以最大化相机的覆盖范围)。这些优化措施显著提高了探索的效率和成功率。
1.3 智能趋近与定位
趋近模块(Approach Module)负责将机器人精确地定位到能够执行操作任务的最佳位置。这个模块的设计充分考虑了机械臂的工作空间限制、安全距离要求以及操作的便利性。
该模块首先从语义地图中识别目标物体所在的支撑表面,如桌面、货架等。通过主成分分析(PCA)算法估计支撑面的法向量和边界,然后根据预设的安全偏移量计算机器人基座的目标位姿。系统确保机器人的朝向与支撑面保持垂直,这样可以最大化机械臂的操作灵活性。
# 趋近位姿计算算法
def calculate_approach_pose(target_object, support_surface, offset=0.8):
"""
计算机器人趋近目标物体的最佳位姿
"""
# 使用PCA估计支撑面法向量
surface_points = support_surface.get_boundary_points()
pca = PCA(n_components=3)
pca.fit(surface_points)
normal_vector = pca.components_[2] # 第三主成分为法向量
# 计算支撑面边界
boundary_points = extract_boundary(support_surface)
# 寻找最近的边界点
target_position = target_object.position
closest_boundary_point = find_closest_point(boundary_points, target_position)
# 计算趋近位姿
approach_position = closest_boundary_point - offset * normal_vector
approach_orientation = align_with_normal(normal_vector)
# 验证位姿可行性
if nav2_validator.is_pose_valid(approach_position, approach_orientation):
return Pose(approach_position, approach_orientation)
else:
return find_alternative_pose(boundary_points, normal_vector, offset)
1.4 VLA操作执行
VLA操作模块是整个系统的执行终端,负责将高层的任务指令转化为具体的机械臂控制命令。该模块基于经过专门微调的SmolVLA模型,这是一个轻量级但功能强大的视觉-语言-动作模型。
SmolVLA模型的微调过程使用了专门收集的数据集,包含50个完整的拾取-放置操作序列。这些数据通过主从机械臂的遥操作方式收集,确保了动作的自然性和有效性。微调过程采用了现代深度学习的最佳实践,包括余弦衰减学习率调度、AdamW优化器以及梯度裁剪等技术,确保模型能够稳定收敛并获得良好的泛化性能。
# SmolVLA模型微调配置
training_config = {
"model": "SmolVLA-450M",
"batch_size": 16,
"learning_rate": 1e-4,
"optimizer": "AdamW",
"weight_decay": 0.01,
"warmup_steps": 100,
"gradient_clip_norm": 10.0,
"scheduler": "cosine_decay",
"dataset_size": 50, # episodes
"hardware": "RTX 4090 16GB"
}
# 训练脚本示例
def train_smolvla():
model = SmolVLA.from_pretrained("lerobot/smolvla_base")
# 数据加载
dataset = load_dataset("custom_pickplace_dataset")
dataloader = DataLoader(dataset, batch_size=16, shuffle=True)
# 优化器设置
optimizer = torch.optim.AdamW(
model.parameters(),
lr=1e-4,
weight_decay=0.01
)
# 学习率调度器
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(
optimizer,
T_max=len(dataloader) * epochs
)
# 训练循环
for epoch in range(epochs):
for batch in dataloader:
optimizer.zero_grad()
loss = model.compute_loss(batch)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 10.0)
optimizer.step()
scheduler.step()
…详情请参照古月居

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 13
13 0
0- 0



 已为社区贡献67条内容
已为社区贡献67条内容

所有评论(0)