GigaWorld-0:以世界模型驱动具身智能的数据引擎
GigaWorld-0是由GigaAI团队提出的统一世界模型框架,旨在解决具身智能训练中的数据稀缺问题。该框架整合视频生成与3D建模技术,通过双模块协同架构(GigaWorld-0-Video和GigaWorld-0-3D)生成多样化且物理一致的数据。核心采用扩散模型和3D Transformer架构,支持高分辨率视频生成与几何约束校验。技术实现包括潜在空间编码、参考帧条件机制等创新设计,为视觉-
0. 摘要
GigaWorld-0 是由 GigaAI 团队提出的统一世界模型框架,核心定位是视觉-语言-动作(VLA)学习的数据引擎。该框架整合大规模视频生成与三维几何建模,解决具身智能训练中数据稀缺与多样性不足的关键瓶颈。本文从技术架构、核心组件、实现细节等多维度对 GigaWorld-0 进行系统性分析。 项目主页:https://giga-world-0.github.io/
1. 研究背景与问题动机
1.1 具身智能的数据困境
具身智能(Embodied AI)是**能在物理世界中感知、决策并执行动作的智能系统。**与语言模型或图像识别不同,具身智能需理解三维空间、物理规律及动作与环境的交互关系。然而训练这类系统面临根本性挑战:高质量机器人交互数据极其稀缺且采集成本高昂。
传统方法中,研究者通过遥操作(teleoperation)或仿真环境收集训练数据。前者依赖人类操作员逐帧记录动作,效率低下且难以规模化;后者虽可大规模生成数据,但仿真与真实世界存在显著域差距(sim-to-real gap),导致模型真实环境中表现不佳。
1.2 世界模型的新思路
世界模型(World Model)为解决上述问题提供新思路。其核心思想是:通过学习环境内在动态规律,能在给定当前状态和动作条件下预测未来状态。这使模型可在"想象"中规划和学习,无需与真实环境大量交互。
近年来扩散模型在视频生成领域取得突破,研究者开始探索将视频生成模型作为世界模型。Sora、Runway Gen-3 等模型展示了开放域场景中生成高质量视频的能力,为具身智能数据生成提供全新技术路径。
1.3 GigaWorld-0 的设计目标
GigaWorld-0 正是在这一背景下提出。与现有工作不同,它不仅是视频生成模型,而是专门为 VLA 学习设计的数据引擎。其设计目标是生成具有以下特性的训练数据:
- 多样性:覆盖不同场景、物体、任务的丰富变化
- 可控性:支持对外观、视角、动作语义的精细控制
- 物理一致性:生成的数据符合基本的物理规律
- 几何准确性:三维空间关系正确无误
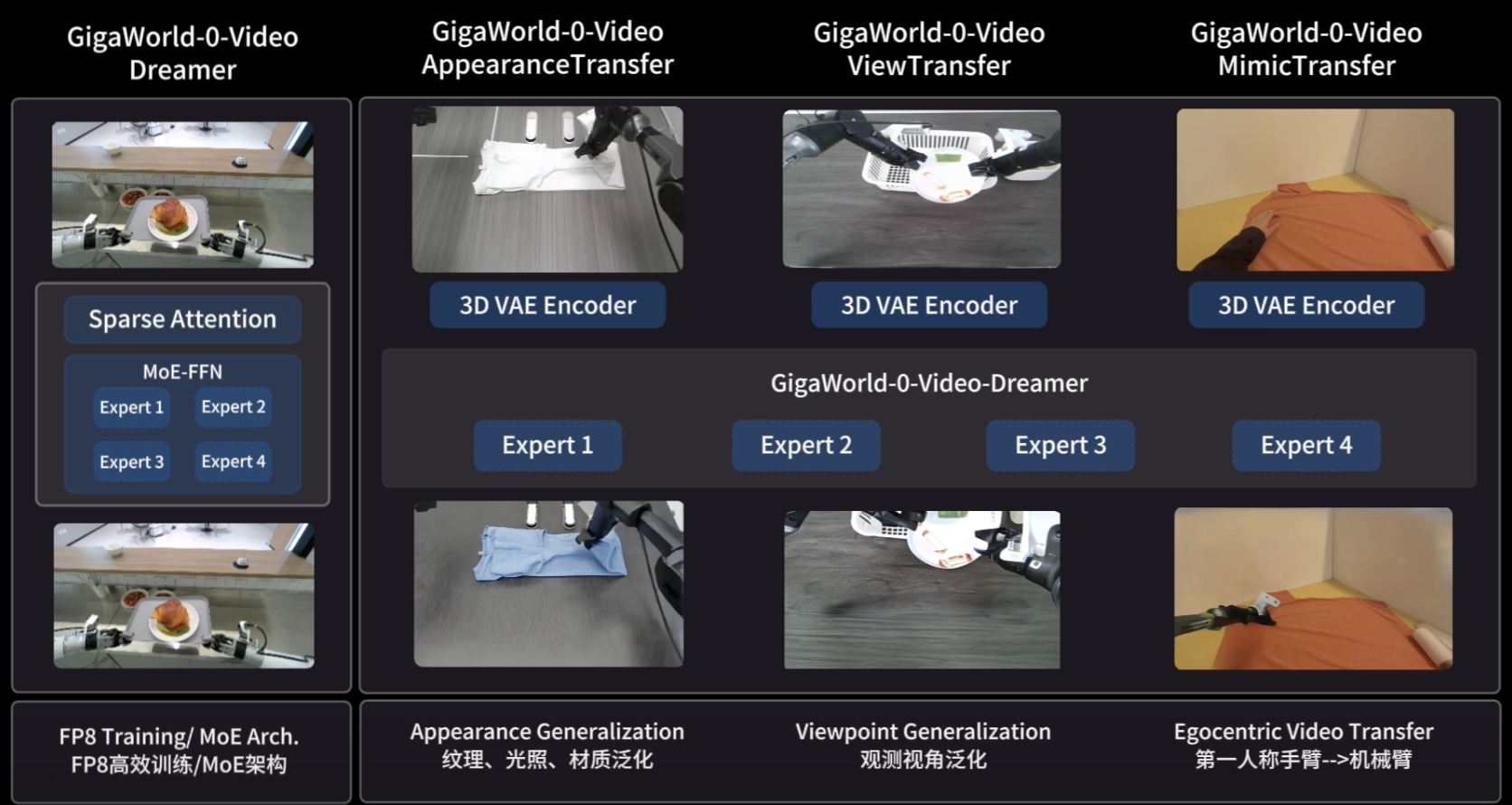
2. 整体架构设计
GigaWorld-0 采用双模块协同的架构设计,由两个互补的核心组件构成。系统先在世界模型中生成大规模候选交互序列,这些序列不直接进入策略训练,而是被不断拆解、重组、过滤;只有同时满足视觉可用、几何自洽、物理可执行三个条件的数据,才会进入 VLA 训练分布。
2.1 GigaWorld-0-Video
GigaWorld-0-Video 是框架的视频生成模块,基于扩散模型架构构建。其核心是 GigaWorld-0-Video-Dreamer,支持图像-文本到视频(IT2V)生成的基础模型。该模块主要特点包括:
- 大规模预训练:在海量互联网视频和机器人操作视频上预训练,学习丰富视觉先验
- 细粒度控制:支持通过文本描述控制生成内容的外观、相机视角和动作语义
- 时序一致性:采用专门架构设计确保生成视频的时序连贯性
- 高分辨率输出:支持 480×640 至 480×768 分辨率的视频生成
2.2 GigaWorld-0-3D
GigaWorld-0-3D 是框架的三维建模模块,负责确保生成数据的几何一致性和物理真实性。该模块整合多项技术:
- 3D 生成建模:从二维图像或视频重建三维场景表示
- 3D 高斯泼溅:采用最新神经渲染技术实现高效三维重建
- 物理可微系统辨识:学习物体和场景的物理参数,确保动态行为符合物理规律
- 可执行运动规划:生成可直接在机器人上执行的动作序列
2.3 模块协同机制
两个模块存在紧密协同关系。GigaWorld-0-Video 负责生成视觉上丰富多样的视频内容,GigaWorld-0-3D 则对这些内容进行几何约束和物理校验。这种分工使最终生成的数据既具有足够多样性,又保持必要的物理一致性。
世界模型不参与实时决策,也不在部署阶段动态修正动作。它的全部价值都被压缩在离线阶段:生成足够多、但不至于把系统带偏的数据候选。
3. 核心技术实现
3.1 扩散模型基础
GigaWorld-0-Video 的技术基础是扩散模型(Diffusion Model)。扩散模型通过两个过程实现生成:前向过程逐步向数据添加高斯噪声,直至数据变为纯噪声;反向过程则学习逐步去除噪声,从随机噪声中恢复真实数据。
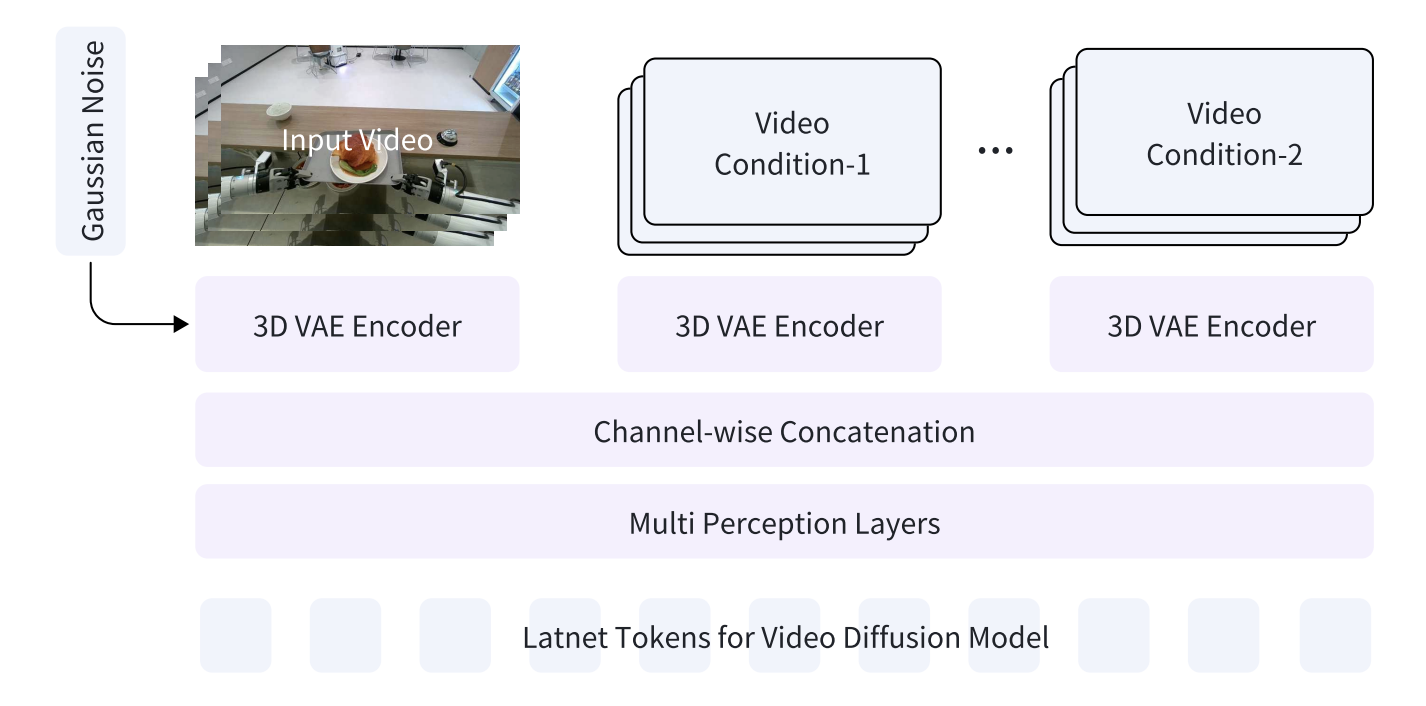
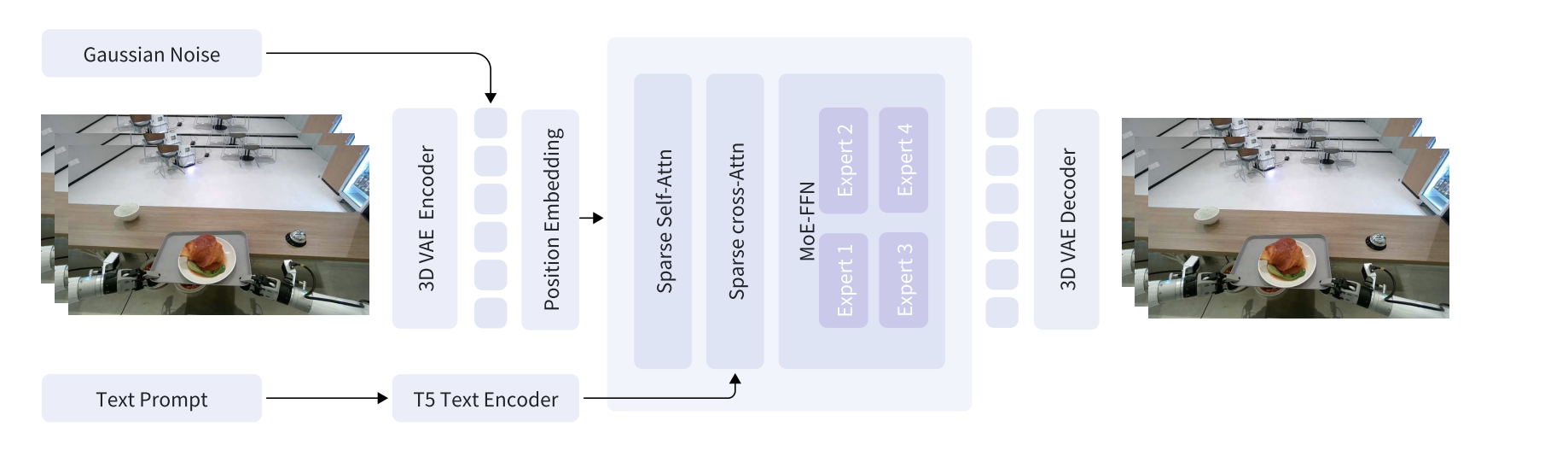
图2:GigaWorld-0-Video-Dreamer的框架
在数学形式上,前向过程可表示为:
q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β t ⋅ x t − 1 , β t ⋅ I ) q(x_t | x_{t-1}) = \mathcal{N}(x_t; \sqrt{1-\beta_t} \cdot x_{t-1}, \beta_t \cdot I) q(xt∣xt−1)=N(xt;1−βt⋅xt−1,βt⋅I)
其中 β t \beta_t βt 是预定义的噪声调度参数。反向过程由神经网络 ϵ θ \epsilon_\theta ϵθ 参数化,学习预测添加的噪声:
p θ ( x t − 1 ∣ x t ) = N ( x t − 1 ; μ θ ( x t , t ) , Σ θ ( x t , t ) ) p_\theta(x_{t-1} | x_t) = \mathcal{N}(x_{t-1}; \mu_\theta(x_t, t), \Sigma_\theta(x_t, t)) pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))
GigaWorld-0 采用 EDM(Elucidated Diffusion Model)框架,使用 Flow Matching 范式,该框架对扩散模型各设计选择进行系统性分析和优化,提供更稳定的训练过程和更高质量的生成结果。
3.2 3D Transformer 架构
GigaWorld-0-Video-Dreamer 的核心是专门设计的 3D Transformer 架构 GigaWorld0Transformer3DModel。该架构针对视频生成任务优化,主要特点包括:
- 时空注意力机制:同时建模空间维度(图像内)和时间维度(帧间)的依赖关系
- 交叉注意力条件:通过交叉注意力机制引入文本条件,实现语义控制
- 位置编码:采用可学习的位置编码处理不同分辨率和帧数的输入
以下是模型调用的核心代码:
model_pred = transformer(
x=input_latents, # 输入潜在表示 (B, C_z+1, T, H/8, W/8)
timesteps=timesteps, # 扩散时间步
crossattn_emb=prompt_embeds, # 文本嵌入(交叉注意力)
padding_mask=padding_mask, # 填充掩码
fps=fps, # 帧率信息
)
3.3 VAE 潜在空间编码
为提高计算效率,GigaWorld-0 不直接在像素空间进行扩散,而是在 VAE 的潜在空间中操作。VAE 来源于 Wan-AI/Wan2.1-T2V-1.3B-Diffusers,实现空间 8 倍、时间 4 倍的压缩。具体实现如下:
def forward_vae(self, images):
"""将图像编码到潜在空间
Args:
images: 输入图像张量,形状 (batch, time, channels, height, width)
Returns:
latents: 编码并归一化后的潜在表示
"""
images = images.to(self.vae.dtype)
with torch.no_grad():
# 重排维度:(batch, time, channels, height, width) -> (batch, channels, time, height, width)
images = rearrange(images, 'b t c h w -> b c t h w')
latents = self.vae.encode(images).latent_dist.sample()
# Z-normalization:标准化到均值0、标准差1
latents = (latents - self.latents_mean) * self.latents_std
return latents
这种设计将原始 480×640 的视频帧压缩到更小的潜在空间表示,显著降低 Transformer 计算复杂度。潜在空间维度通常比原始像素空间小 8 倍或更多,使模型能处理更长的视频序列。
3.4 参考帧条件机制
GigaWorld-0 支持图像到视频(IT2V)生成,这通过参考帧条件机制实现。训练时模型随机选择视频前几帧作为参考帧,学习基于这些参考帧生成后续内容。
参考帧掩码生成的核心逻辑如下:
class MaskGenerator:
"""生成参考帧的二值掩码
用于控制训练时哪些帧被视为参考(条件)帧。
"""
def __init__(self, max_ref_frames: int, factor: int = 8, start: int = 1):
"""初始化掩码生成器
Args:
max_ref_frames: 最大参考帧数(需满足: (max_ref_frames - 1) % factor == 0)
factor: 帧空间与潜在空间的下采样因子(默认8,匹配VAE时间压缩率)
start: 最小参考潜在数(默认1)
"""
assert max_ref_frames > 0 and (max_ref_frames - 1) % factor == 0
self.max_ref_frames = max_ref_frames
self.factor = factor
self.start = start
# 根据因子计算最大参考潜在数
self.max_ref_latents = 1 + (max_ref_frames - 1) // factor
assert self.start <= self.max_ref_latents
def get_mask(self, num_frames: int):
"""生成帧空间和潜在空间的掩码
Args:
num_frames: 序列中的总帧数
Returns:
ref_masks: 帧空间的二值掩码张量,形状 (num_frames,)
参考帧为1.0,非参考帧为0.0
ref_latent_masks: 潜在空间的二值掩码张量,形状 (num_latents,)
参考潜在为1.0,非参考潜在为0.0
"""
# 验证输入维度
assert num_frames > 0 and (num_frames - 1) % self.factor == 0 and num_frames >= self.max_ref_frames
# 根据下采样因子计算潜在数
num_latents = 1 + (num_frames - 1) // self.factor
# 随机选择参考潜在数量
num_ref_latents = random.randint(self.start, self.max_ref_latents)
# 计算对应的参考帧数
if num_ref_latents > 0:
num_ref_frames = 1 + (num_ref_latents - 1) * self.factor
else:
num_ref_frames = 0
# 创建帧空间的二值掩码
ref_masks = torch.zeros((num_frames,), dtype=torch.float32)
ref_masks[:num_ref_frames] = 1 # 前N帧标记为参考帧
# 创建潜在空间的二值掩码
ref_latent_masks = torch.zeros((num_latents,), dtype=torch.float32)
ref_latent_masks[:num_ref_latents] = 1 # 前N个潜在标记为参考潜在
return ref_masks, ref_latent_masks
在训练过程中,参考帧的潜在表示会与待生成帧的噪声潜在表示混合,使模型学会根据参考帧内容预测后续帧:
# 参考帧使用极小噪声(σ=0.0001),模拟"已知条件"
augment_sigma = torch.tensor([0.0001], device=ref_latents.device, dtype=latents.dtype)
# 参考帧与噪声帧的融合
input_latents = ref_masks * ref_latents + (1 - ref_masks) * input_latents
# 拼接mask作为额外通道(告诉模型哪些是参考帧)
input_masks = ref_masks.repeat(1, 1, 1, input_latents.shape[-2], input_latents.shape[-1])
input_latents = torch.cat([input_latents, input_masks], dim=1) # (B, C_z+1, T, H/8, W/8)
# 调整timesteps(参考帧用接近0的时间步)
t_conditioning = augment_sigma / (augment_sigma + 1)
timesteps = ref_masks * t_conditioning + (1 - ref_masks) * timesteps
3.5 逆动力学动作恢复
直接生成动作在真机上风险极高,任何细微不一致都会被控制器放大。反过来先生成"看得过去"的交互,再用 IDM(Inverse Dynamics Model)去恢复动作,相当于在动作层前面加了一层缓冲,避免策略被噪声动作带偏。
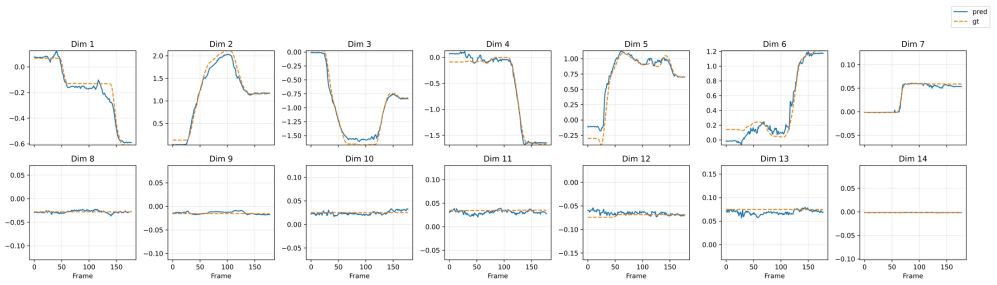
图3:在测试集上进行的动作推断的定性比较。来自GigaWorld-0-IDM的预测关节轨迹与所有12个手臂关节和2个夹持器自由度的真实动作高度一致,展示了仅通过视觉输入恢复物理上合理的操作策略的高保真度。
给定生成的视频序列 V = { v 1 , v 2 , … , v T } \mathbf{V} = \{\mathbf{v}_1, \mathbf{v}_2, \dots, \mathbf{v}_T\} V={v1,v2,…,vT},其中 v t ∈ R H × W × 3 \mathbf{v}_t \in \mathbb{R}^{H \times W \times 3} vt∈RH×W×3 表示时间 t t t 的 RGB 帧,GigaWorld-0-IDM 估计关节角度轨迹:
θ 1 : T = f IDM ( V ) \boldsymbol{\theta}_{1:T} = f_{\text{IDM}}(\mathbf{V}) θ1:T=fIDM(V)
其中 θ t = [ θ t ( 1 ) , θ t ( 2 ) , … , θ t ( D ) ] ⊤ ∈ R D \boldsymbol{\theta}_t = [\theta_t^{(1)}, \theta_t^{(2)}, \dots, \theta_t^{(D)}]^\top \in \mathbb{R}^D θt=[θt(1),θt(2),…,θt(D)]⊤∈RD 表示时间步 t t t 机械臂所有 D D D 个关节的旋转角度。
与现有 IDM 不同,GigaWorld-0-IDM 采用掩码训练策略。使用 SAM2 从输入视频中分割机械臂,训练时仅将分割的臂区域输入 IDM,从而减少杂乱背景对预测精度的不利影响:
注意:以下为基于论文描述的概念伪代码,用于说明算法原理,非项目实际实现。
def inverse_dynamics_model(video_frames, arm_segmenter):
"""逆动力学模型:从视频帧推断机械臂动作
Args:
video_frames: 视频帧序列 (T, H, W, 3)
arm_segmenter: SAM2 分割器
Returns:
joint_angles: 关节角度轨迹 (T, D)
"""
# 使用 SAM2 分割机械臂区域
arm_masks = arm_segmenter.segment(video_frames)
# 仅保留臂区域,减少背景干扰
masked_frames = video_frames * arm_masks[:, :, :, None]
# 通过 IDM 网络推断关节角度
joint_angles = idm_network(masked_frames)
return joint_angles
3.6 多视角一致性
工程里最头疼的是:同一个动作,在一个视角下是合理的,在另一个视角下已经越界。作者没有指望模型自己学会"空间感",而是通过多视角一致性强行补齐状态信息,减少策略在真机上因为观测缺失做出激进决策。

图5:GigaWorld-0-Video-ViewTransfer的训练数据对
GigaWorld-0-Video-ViewTransfer 从现有单视角机器人交互视频合成多样的新视角,同时转换相关机器人动作以保持任务一致性。
设机器人在世界坐标系 W A \mathcal{W}_A WA 中操作,捕获自我中心视频 V A \mathbf{V}_A VA 以及末端执行器位姿序列 { T t ee → base } t = 1 T \{\mathbf{T}_t^{\text{ee} \rightarrow \text{base}}\}_{t=1}^T {Ttee→base}t=1T。目标是合成新观测 V B \mathbf{V}_B VB,如同从不同世界坐标系 W B \mathcal{W}_B WB 捕获。关键是世界坐标系中的绝对末端执行器位姿必须保持不变以保留任务语义:
T t ee → W = T base → W A ⋅ T t ee → base = T base → W B ⋅ K t \mathbf{T}_t^{\text{ee} \rightarrow \mathcal{W}} = \mathbf{T}^{\text{base} \rightarrow \mathcal{W}_A} \cdot \mathbf{T}_t^{\text{ee} \rightarrow \text{base}} = \mathbf{T}^{\text{base} \rightarrow \mathcal{W}_B} \cdot \mathbf{K}_t Ttee→W=Tbase→WA⋅Ttee→base=Tbase→WB⋅Kt
求解 K t \mathbf{K}_t Kt 得到:
K t = ( T base → W B ) − 1 ⋅ T base → W A ⋅ T t ee → base \mathbf{K}_t = \left(\mathbf{T}^{\text{base} \rightarrow \mathcal{W}_B}\right)^{-1} \cdot \mathbf{T}^{\text{base} \rightarrow \mathcal{W}_A} \cdot \mathbf{T}_t^{\text{ee} \rightarrow \text{base}} Kt=(Tbase→WB)−1⋅Tbase→WA⋅Ttee→base
视角转换采用双重投影策略构建自监督训练对:
注意:以下为基于论文描述的概念伪代码,用于说明算法原理,非项目实际实现。
def view_transfer(video_A, depth_estimator, target_pose):
"""视角转换:从单视角视频生成新视角
Args:
video_A: 原始视角视频
depth_estimator: 深度估计器 (MoGe)
target_pose: 目标相机位姿
Returns:
video_B: 新视角视频
actions_K: 转换后的动作序列
"""
# 1. 估计原始视角的深度
depth_A = depth_estimator.estimate(video_A)
# 2. 使用 SAM2 分割并掩码机械臂
arm_mask = sam2.segment_arm(video_A)
background_A = video_A * (1 - arm_mask)
# 3. 将背景投影到目标视角再投影回来(双重投影)
warped_background = warp_to_target_and_back(
background_A, depth_A, target_pose)
# 4. 在模拟器中渲染转换后的机械臂动作
actions_K = transform_actions(original_actions, target_pose)
arm_render = simulator.render_arm(actions_K)
# 5. 条件生成新视角视频
video_B = view_transfer_model(
condition_1=warped_background, # 背景几何
condition_2=arm_render # 臂动作
)
return video_B, actions_K
3.9 3D 资产生成的多重质检
坏资产比没有资产更危险——错误的尺寸、质量或摩擦,会让策略在真机上持续做出错误补偿。无论是前景物体还是背景重建,系统都默认"生成一定会失败",因此设计了反复检测、回滚、重试的机制,把不稳定性挡在数据源头。
GigaWorld-0-3D-FG 管线接受真实世界照片或文本生成的合成图像作为输入。在 3D 生成之前,自动预处理阶段执行质量控制:
- 美学评估模块(Aesthetic-Checker):基于 HPS v3,与纹理丰富度正相关
- 图像分割检查器(ImageSegChecker):由 GPT-4o 驱动,评估分割可靠性
- 多分割后端:集成 SAM2、RemBG 等三个分割后端确保鲁棒性
- 网格几何检查器(MeshGeoChecker):从四个正交视角渲染资产评估几何完整性
注意:以下为基于论文描述的概念伪代码,用于说明算法原理,非项目实际实现。
class Asset3DPipeline:
"""3D 资产生成管线,包含多重质检"""
def __init__(self):
self.aesthetic_checker = AestheticChecker() # HPS v3
self.seg_checker = ImageSegChecker() # GPT-4o
self.segmenters = [SAM2(), RemBG(), RemBG14()]
self.mesh_checker = MeshGeoChecker()
self.generator = Trellis3DGenerator()
def generate(self, input_image, max_retries=3):
"""生成 3D 资产,失败时自动重试
Args:
input_image: 输入图像或文本生成的图像
max_retries: 最大重试次数
Returns:
urdf_asset: URDF 格式的 3D 资产
"""
for attempt in range(max_retries):
# 1. 美学评估
if not self.aesthetic_checker.check(input_image):
input_image = self.regenerate_image()
continue
# 2. 前景分割(尝试多个后端)
segmentation = None
for segmenter in self.segmenters:
seg_result = segmenter.segment(input_image)
if self.seg_checker.validate(seg_result):
segmentation = seg_result
break
if segmentation is None:
input_image = self.regenerate_image()
continue
# 3. 图像到 3D 转换
mesh, gaussians = self.generator.generate(
input_image, segmentation)
# 4. 几何完整性检查(四视角渲染)
renders = self.mesh_checker.render_orthogonal(mesh)
if not self.mesh_checker.validate_geometry(renders):
continue # 使用新随机种子重试
# 5. 导出 URDF 格式
urdf_asset = self.export_urdf(mesh, gaussians)
return urdf_asset
raise AssetGenerationError("超过最大重试次数")
对于物理属性估计,GigaWorld-0-3D-Phys 采用基于物理信息神经网络(PINNs)的可微物理框架,实现高效的基于梯度的参数估计。管线分三个阶段:
- 真实世界轨迹 ( a t − 1 , s t − 1 ) (\mathbf{a}_{t-1}, \mathbf{s}_{t-1}) (at−1,st−1) 与随机采样的物理参数 ( f , p , d ) (f, p, d) (f,p,d)(摩擦、刚度、阻尼)配对,用于生成模拟展开
- 训练代理模型 M f , p , d \mathcal{M}_{f,p,d} Mf,p,d 近似模拟器动力学,最小化预测与模拟下一状态之间的 MSE
- 固定代理模型,通过梯度下降优化物理参数,最小化模拟与真实轨迹之间的差异
注意:以下为基于论文描述的概念伪代码,用于说明算法原理,非项目实际实现。
class DifferentiablePhysics:
"""可微物理系统辨识"""
def __init__(self, simulator):
self.simulator = simulator
self.surrogate_model = PhysicsNN()
def system_identification(self, real_trajectories, num_iterations=1000):
"""系统辨识:学习物理参数
Args:
real_trajectories: 真实世界轨迹列表
num_iterations: 优化迭代次数
Returns:
optimal_params: 最优物理参数 (f*, p*, d*)
"""
# 初始化可学习的物理参数
friction = torch.nn.Parameter(torch.tensor(0.5))
stiffness = torch.nn.Parameter(torch.tensor(100.0))
damping = torch.nn.Parameter(torch.tensor(10.0))
optimizer = torch.optim.Adam([friction, stiffness, damping], lr=1e-3)
for iteration in range(num_iterations):
total_loss = 0.0
for traj in real_trajectories:
actions, states = traj['actions'], traj['states']
for t in range(len(states) - 1):
# 使用代理模型预测下一状态
pred_next_state = self.surrogate_model(
states[t], actions[t],
friction, stiffness, damping
)
# 计算与真实下一状态的差异
loss = F.mse_loss(pred_next_state, states[t + 1])
total_loss += loss
optimizer.zero_grad()
total_loss.backward()
optimizer.step()
# 约束参数在物理合理范围内
with torch.no_grad():
friction.clamp_(0.01, 1.0)
stiffness.clamp_(10.0, 1000.0)
damping.clamp_(1.0, 100.0)
return {
'friction': friction.item(),
'stiffness': stiffness.item(),
'damping': damping.item()
}
4. 数据处理流程
4.1 数据组织结构
GigaWorld-0 对训练数据有明确的组织要求。原始数据需按照以下结构组织:
raw_data/
├── 0.mp4 # 视频文件 0
├── 0.txt # 视频 0 对应的文本描述
├── 1.mp4 # 视频文件 1
├── 1.txt # 视频 1 对应的文本描述
├── ...
每个视频文件需配对一个同名文本文件,包含对该视频内容的自然语言描述。这种描述将用于训练模型的条件生成能力。
4.2 数据打包流程
原始数据需经过打包处理才能用于训练。打包过程使用 T5-11B 模型对文本描述进行预编码,避免训练时重复计算文本嵌入,显著提高训练效率。
def pack_data(
video_dir: str,
save_dir: str,
text_encoder_model_path: str | None = None,
device: str = 'cuda',
):
"""将视频、提示词和提示词嵌入打包为训练或评估数据集
Args:
video_dir: 包含.mp4视频和对应.txt提示词文件的目录
save_dir: 保存打包数据集的目录
text_encoder_model_path: T5文本编码器路径(如果为None则自动下载)
device: 文本编码器使用的设备
"""
if text_encoder_model_path is None:
text_encoder_model_path = download_from_huggingface('google-t5/t5-11b')
# 1. 加载T5文本编码器(google-t5/t5-11b)
text_encoder = T5TextEncoder(text_encoder_model_path)
text_encoder.to(device)
# 2. 查找所有.mp4文件
video_paths: List[str] = glob(os.path.join(video_dir, '*.mp4'))
# 3. 创建写入器(标签、视频、提示词嵌入)
label_writer = PklWriter(os.path.join(save_dir, 'labels'))
video_writer = FileWriter(os.path.join(save_dir, 'videos'))
prompt_writer = FileWriter(os.path.join(save_dir, 'prompts'))
# 4. 处理每个视频
for idx in tqdm(range(len(video_paths))):
# 读取对应的.txt文件作为提示词
anno_file = video_paths[idx].replace('.mp4', '.txt')
prompt = open(anno_file, 'r').read().strip()
# 使用T5编码提示词获取嵌入
prompt_embeds = text_encoder.encode_prompts(prompt)[0].cpu()
# 保存数据
label_dict = dict(data_index=idx, prompt=prompt)
label_writer.write_dict(label_dict)
video_writer.write_video(idx, video_paths[idx])
prompt_writer.write_dict(idx, dict(prompt_embeds=prompt_embeds))
# 5. 完成并关闭写入器
label_writer.write_config()
video_writer.write_config()
prompt_writer.write_config()
label_writer.close()
video_writer.close()
prompt_writer.close()
# 6. 加载数据集并合并为单一Dataset对象
label_dataset = load_dataset(os.path.join(save_dir, 'labels'))
video_dataset = load_dataset(os.path.join(save_dir, 'videos'))
prompt_dataset = load_dataset(os.path.join(save_dir, 'prompts'))
dataset = Dataset([label_dataset, video_dataset, prompt_dataset])
dataset.save(save_dir)
打包后的数据结构:
packed_data/
├── labels/ # 元数据(索引、prompt文本)
├── videos/ # 视频文件
├── prompts/ # T5编码的prompt嵌入
└── dataset.json # 数据集索引
4.3 数据变换
在训练时,视频数据会经过一系列变换处理,包括帧采样、尺寸调整、归一化和参考帧生成等步骤:
@TRANSFORMS.register
class GigaWorld0Transform:
"""GigaWorld0训练的视频变换类
处理视频采样、缩放、裁剪、归一化和参考帧生成。
"""
def __init__(self, num_frames: int, height: int, width: int, image_cfg: dict, fps: int = 16):
"""初始化变换
Args:
num_frames: 从视频中采样的帧数
height: 输出帧的目标高度
width: 输出帧的目标宽度
image_cfg: 包含掩码生成器设置的配置字典
fps: 视频帧率(默认16)
"""
self.num_frames = num_frames
self.height = height
self.width = width
self.fps = fps
# 归一化变换:将[0, 1]转换为[-1, 1]
self.normalize = transforms.Normalize([0.5], [0.5])
self.mask_generator = MaskGenerator(**image_cfg['mask_generator'])
def __call__(self, data_dict):
"""对输入数据应用变换
Args:
data_dict: 包含'video'和'prompt_embeds'的字典
Returns:
new_data_dict: 包含处理后图像和掩码的变换数据字典
"""
video = data_dict['video']
video_length = len(video)
# 1. 等间隔采样帧
sample_indexes = np.linspace(0, video_length - 1, self.num_frames, dtype=int)
input_images = video_utils.sample_video(video, sample_indexes, method=2)
# 2. 转换为Tensor并调整维度: (T, H, W, C) -> (T, C, H, W)
input_images = torch.from_numpy(input_images).permute(0, 3, 1, 2).contiguous()
image_height = input_images.shape[2]
image_width = input_images.shape[3]
dst_width, dst_height = self.width, self.height
# 3. 计算新尺寸以保持宽高比
if float(dst_height) / image_height < float(dst_width) / image_width:
new_height = int(round(float(dst_width) / image_width * image_height))
new_width = dst_width
else:
new_height = dst_height
new_width = int(round(float(dst_height) / image_height * image_width))
# 4. 随机裁剪坐标
x1 = random.randint(0, new_width - dst_width)
y1 = random.randint(0, new_height - dst_height)
# 5. 应用缩放和裁剪
input_images = F.resize(input_images, (new_height, new_width), InterpolationMode.BILINEAR)
input_images = F.crop(input_images, y1, x1, dst_height, dst_width)
# 6. 归一化:[0, 255] -> [0, 1] -> [-1, 1]
input_images = input_images / 255.0
input_images = self.normalize(input_images)
# 7. 生成参考帧掩码
ref_masks, ref_latent_masks = self.mask_generator.get_mask(input_images.shape[0])
# 扩展维度用于广播: (T,) -> (T, 1, 1, 1)
ref_masks = ref_masks[:, None, None, None]
# 扩展潜在空间维度: (T_latent,) -> (1, T_latent, 1, 1)
ref_latent_masks = ref_latent_masks[None, :, None, None]
# 通过掩码创建参考图像
ref_images = copy.deepcopy(input_images)
ref_images = ref_images * ref_masks
new_data_dict = dict(
fps=self.fps,
images=input_images,
ref_images=ref_images,
ref_masks=ref_latent_masks,
prompt_embeds=data_dict['prompt_embeds'],
)
return new_data_dict
…详情请参照古月居

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 11
11 0
0- 0



 已为社区贡献67条内容
已为社区贡献67条内容

所有评论(0)