【论文阅读】RoboRefer: Towards Spatial Referring with Reasoning in Vision-Language Models for Robotics
设计了指标敏感的过程奖励函数(Metric-sensitive Process Reward),不仅关注最终预测点的准确性(结果奖励),还通过过程奖励(Accuracy Reward)对中间推理步骤的感知精度进行评估和激励。尽管现有的视觉语言模型(VLM)很强大,但在处理复杂的3D场景和根据指令动态推理交互位置方面仍存在不足。结论:实验证明,通过结合专用深度编码器(SFT)和指标敏感的过程奖励(R
【论文阅读】RoboRefer: Towards Spatial Referring with Reasoning in Vision-Language Models for Robotics
1 发表时间与团队
发表时间:该论文发表于 NeurIPS 2025(第39届神经信息处理系统大会) 。
团队:主要由北京航空航天大学、北京大学和北京通用人工智能研究院 (BAAI) 的研究人员共同完成,包括 Enshen Zhou、Jingkun An、Cheng Chi、Lu Sheng 和 Shanghang Zhang 等 。
2 问题背景与核心思路

-
背景:空间指代(Spatial Referring)是机器人与物理世界交互的基础能力 。尽管现有的视觉语言模型(VLM)很强大,但在处理复杂的3D场景和根据指令动态推理交互位置方面仍存在不足 。现有方法往往只关注单步空间理解,且在处理深度信息时可能导致模态干扰 。
- 空间指代指的是根据任务预测具体的2D坐标点(图像坐标系下),体现空间理解能力。
-
核心思路:提出 RoboRefer,这是一个具备3D意识的推理型VLM 。它通过两个阶段实现:首先通过有监督微调(SFT)引入专用深度编码器以增强单步空间理解,随后通过强化微调(RFT)和显式的推理过程来提升多步空间推理能力 。
3 具体设计
3.1 模型设计
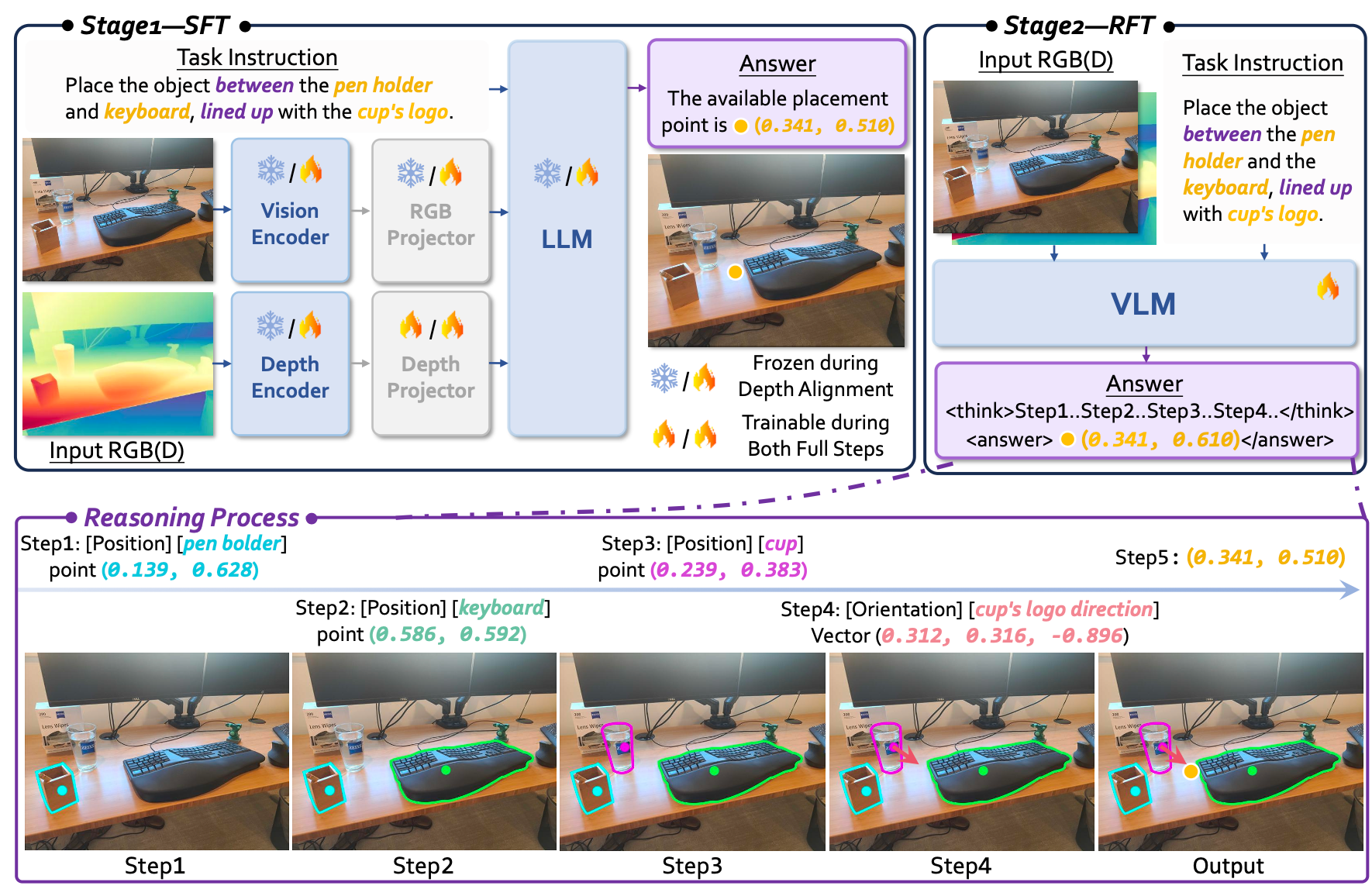
架构:采用 NVILA 作为基础VLM,并引入了独立的 RGB 编码器 和 专用深度编码器。这种设计避免了深度输入对RGB分支的干扰,保留了通用的视觉问答(VQA)能力 。
训练策略
阶段1:SFT(有监督微调):包括深度对齐(训练深度投影仪以对齐文本空间)和空间理解增强(在 RefSpatial 数据集上进行全参数微调,涵盖单步和显式多步推理数据) 。
阶段2:RFT(强化微调):使用 GRPO(组相对策略优化) 算法 。设计了指标敏感的过程奖励函数(Metric-sensitive Process Reward),不仅关注最终预测点的准确性(结果奖励),还通过过程奖励(Accuracy Reward)对中间推理步骤的感知精度进行评估和激励 。
3.2 数据设计
-
RefSpatial 数据集:包含 250万个高质量样本 和 2000万个问答对,规模是此前数据集的两倍 。
- 数据特点:
- 涵盖 31种空间关系(显著多于之前的15种) 。
- 支持长达5步的复杂推理过程 。
- 数据来源多样,包括2D网络图像(提供基础概念)、3D具身视频(细化室内场景理解)和带有真实推理过程的模拟数据 。
- 数据特点:
-
RefSpatial-Bench:一个全新的基准测试,包含200张真实世界图像,专门用于评估具备多步推理的空间指代任务 。
4 实验
单步表现:在 CV-Bench 和 BLINK 等现有基准上达到 SOTA,平均成功率为 89.6% 。
多步推理:在 RefSpatial-Bench 上,RFT 训练后的 RoboRefer 大幅领先其他基线,平均准确率比 Gemini-2.5-Pro 高出 17.4% 。
真实世界应用:RoboRefer 已成功集成到多种机器人(如 UR5 机械臂、G1 人形机器人)的控制策略中,能够处理凌乱场景下的长程动态任务,如导航和复杂抓取放置 。
5 结论
主要贡献:提出了 RoboRefer 模型、大规模 RefSpatial 数据集以及 RefSpatial-Bench 评测基准 。
结论:实验证明,通过结合专用深度编码器(SFT)和指标敏感的过程奖励(RFT),RoboRefer 在空间指代和推理方面具有极强的泛化能力和精准度,是实现具身智能的关键一步 。\

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 15
15 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)