Embedding嵌入模型是什么?为什么需要 Embedding?
Embedding模型是连接自然语言与算法系统的枢纽。任何接触过RAG技术的从业者,都耳熟能详“Embedding嵌入模型”这一术语,但真正深入理解其价值的人却寥寥无几;在多数人认知中,它不过是一个“边缘工具”——只需将文本分块后,调用一次Embedding模型,生成向量便万事大吉。然而,Embedding模型远非简单的“词向量编码器”,它实质是驱动当代AI系统(如搜索引擎、推荐引擎与对话机器人
Embedding模型是连接自然语言与算法系统的枢纽。
任何接触过RAG技术的从业者,都耳熟能详“Embedding嵌入模型”这一术语,但真正深入理解其价值的人却寥寥无几;在多数人认知中,它不过是一个“边缘工具”——只需将文本分块后,调用一次Embedding模型,生成向量便万事大吉。
然而,Embedding模型远非简单的“词向量编码器”,它实质是驱动当代AI系统(如搜索引擎、推荐引擎与对话机器人)运转的底层动力核心。
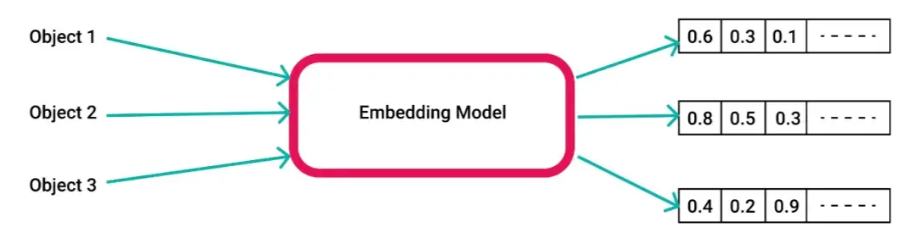
Embedding模型
Embedding 是实现语义理解与应用的核心技术,其本质是将文本等信息编码为向量,并借助向量间的相似度计算达成语义层面的推理与匹配。
Embedding 模型属于一种人工智能方法,用于将离散对象(如词汇、句子或图像)映射至连续的向量空间。在自然语言处理(NLP)领域,其最典型的应用形态为文本 Embedding——即将语言单元转换为高维数值表示(例如,一个 768 维的浮点数组)。此类向量结构能够有效编码文本的语义内涵、句法结构与上下文依赖关系。
想象语言如一张地理图卷,词汇便是其中的城池。Embedding 就如同 GPS 的经纬定位——语义相近的“城池”(如 “猫” 与 “狗”)在坐标上彼此邻近,而语义相异的(如 “猫” 与 “汽车”)则遥隔千里。
为什么需要 Embedding?
因为计算机无法直接解析语言与图像的语义,而向量能够表征这些内容:
便于通过距离或相似度判断语义接近程度
支持模糊匹配(表达不同,含义一致)
实现高效检索(向量数据库可实现毫秒级相似度搜索)
构成众多 AI 应用的基础特征表示

传统计算机在处理文本时,仅能识别字符序列(如 “apple”),无法感知其背后的意义。Embedding 技术正是为此而生:
语义捕捉:它使机器能够识别语义关联——同义词(如 “happy” 与 “joyful”)在向量空间中彼此邻近,而多义词(如 “bank”)则根据上下文呈现出不同的向量表征。
维度降维:从庞大的词汇集合中提炼出核心语义特征,大幅压缩表示空间,显著提升计算效率。
核心作用与优势:语义分析的“利刃”
Embedding 的核心作用在于 向量表示与相似度计算,它在 AI 系统中的优势体现在多个层面:
语义相似度度量:

高效过滤与分类:
在海量数据处理场景中,Embedding 充当轻量级预筛选机制,迅速剔除低相关性内容,显著降低后续计算负载。
优势:向量生成耗时仅为毫秒级,相较完整神经网络推理效率提升数个数量级。
多模态扩展:
当前 Embedding 架构已实现文本、图像与音频信号在统一向量空间中的对齐(如 CLIP 模型),支撑跨模态语义对齐任务。
优势:可直接完成“以图搜文”“以文搜音”等跨域检索,打破模态边界。
下游任务支持:
作为 AI 系统的基础表征层,Embedding 为聚类分析、个性化推荐及检索增强生成(RAG)等应用提供可优化的输入表征。
优势:具备可微分特性,能无缝嵌入端到端神经网络训练流程,支持梯度反向传播与联合优化。

工作原理拆解:从训练到应用的完整链条
分词/编码:句子被拆解为 token(字、词或子词单元)
向量化表示:借助词嵌入(word embeddings)或上下文感知嵌入(contextual embeddings)实现语义数字化
模型处理:主流采用 Transformer 架构(如 BERT、RoBERTa、SimCSE)进行语义建模
池化(Pooling):将各 token 的向量聚合为统一维度的句级表示(常用 CLS token 或均值池化)
归一化:可选步骤,对向量进行 L2 归一化,以优化余弦相似度计算效率
3.1 训练阶段:语义关系建模
数据输入:依赖大规模文本语料库(如维基百科、学术著作等)
模型架构:基于 Transformer(如 BERT)或 Skip-Gram(Word2Vec),通过自监督任务学习上下文依赖,如掩码语言建模或下一句预测
输出结果:生成嵌入矩阵,每个词或句子映射为固定长度的稠密向量
示例:训练过程中,“The cat sits on the mat” → 模型捕捉 “cat” 与 “mat” 的语义关联,向量中隐含语法角色与空间关系
关键技术:负采样(提升训练效率)与注意力机制(建模远距离依赖)
3.2 推理阶段:向量生成
流程:输入文本 → Tokenization → 模型前向传播 → 输出句向量
示例代码(Python + Hugging Face):
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
sentence = "Embedding models are powerful."
embedding = model.encode(sentence)
输出:[0.12, -0.34, ..., 0.56](384 维)
耗时:单句推理通常低于 10 毫秒
3.3 应用阶段:相似度判定与检索
向量比较:采用欧氏距离或余弦相似度衡量语义相近性
阈值决策:相似度超过 0.7 判定为语义相关
扩展应用:KNN(K-近邻)搜索用于高效大规模向量检索
该流程构建了文本嵌入从预处理到落地的完整闭环,确保语义表达精准、计算高效、系统可扩展。
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 20
20 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)