国产VLA模型开源!35000小时训练数据,全球最大规模
Being-H0.5的推出,为具身智能领域提供了一种新的技术范式思路:高质量训练数据并非必须源于自建的高成本机器人集群。针对“如何高效适配多元本体、低成本获取优质训练数据”这一核心行业挑战,Being-H0.5将视角转向人类本身这一最丰富、最自然的数据源泉。这一技术路径在一定程度上降低了具身智能技术的研发门槛,使得企业无需投入巨额资金构建数据“护城河”,便可依托以人为中心的学习范式,开发适配多元本
国产VLA模型开源!35000小时训练数据,全球最大规模
许丽思 许丽思 机器人前瞻 2026年1月20日 17:06 广东

超30种机器人本体通用。
作者 | 许丽思
编辑 | 漠影
机器人前瞻1月20日报道,今天,Being Beyond团队发布跨本体VLA模型Being-H0.5,并已在GitHub、HuggingFace上完整开源。
Being Beyond团队不仅公开了预训练与后训练的全部模型参数,还提供完整的训练与评估代码,以及一套可复现1000+GPU小时训练的详细配方。未来,其还将逐步开源真机部署代码与接口。
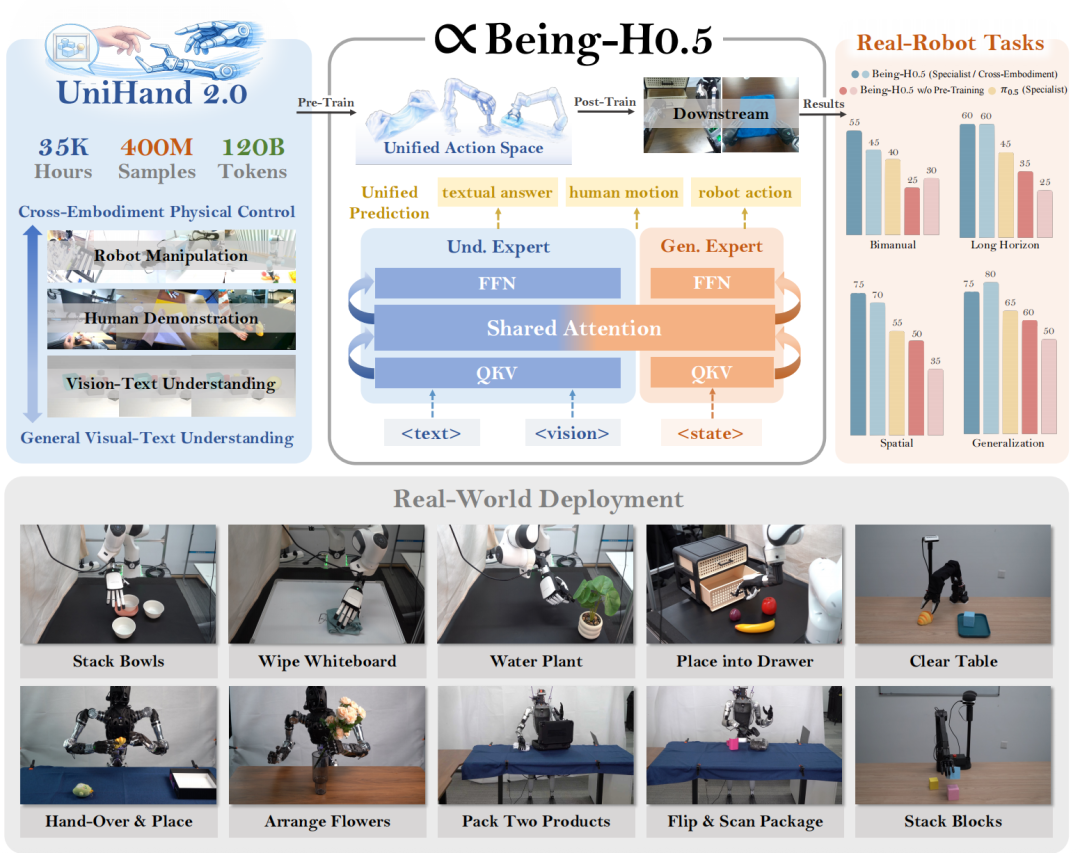
Being-H0.5通过整合数万小时人类视频以及当前全球几乎所有主流机器人构型的操作数据,在视觉‑语言‑动作(VLA)任务中展现出较强的跨本体泛化能力——无论硬件形态存在何种差异,模型皆能快速适应、稳定执行。
Being-H0.5基于human-centric learning,涵盖30种不同本体(是π0.5的5倍),能够实现超强跨本体泛化,对同样一批任务,只需训练一次,就能部署在5个不同本体上。
性能方面,Being-H0.5在大规模预训练加持下,即使只微调2%的模型参数也能达到90%以上的相对performance;其在LIBERO和RoboCasa达到SoTA,还实现了全球最快的端侧部署速度,在Orin-NX上达到实时。
项目官网:https://research.beingbeyond.com/being-h05
论文链接:https://research.beingbeyond.com/projects/being-h05/being-h05.pdf
GitHub代码开源:https://github.com/BeingBeyond/Being-H
HuggingFace模型开源:https://huggingface.co/BeingBeyond/Being-H05-2B
01.
构建全球规模最大的训练数据集,
总时长超3.5万小时
Being-H0.5的训练数据集——UniHand2.0,总时长超过3.5万小时,囊括14000小时的机器人操作数据,16000小时的人类视频数据,以及5000小时通用多模态数据,总训练token数突破 1200亿。这是全球首次在机器人领域进行如此大规模、跨本体的数据整合尝试。

与以往仅基于“轮式底盘+双臂夹爪”范式的研究(如π系列工作)不同,UniHand2.0首次实现了跨本体的大规模数据融合,汇集了超过30种不同硬件构型的多样化数据,涵盖了从桌面机械臂到双足机器人在内几乎所有已知的机器人形态。
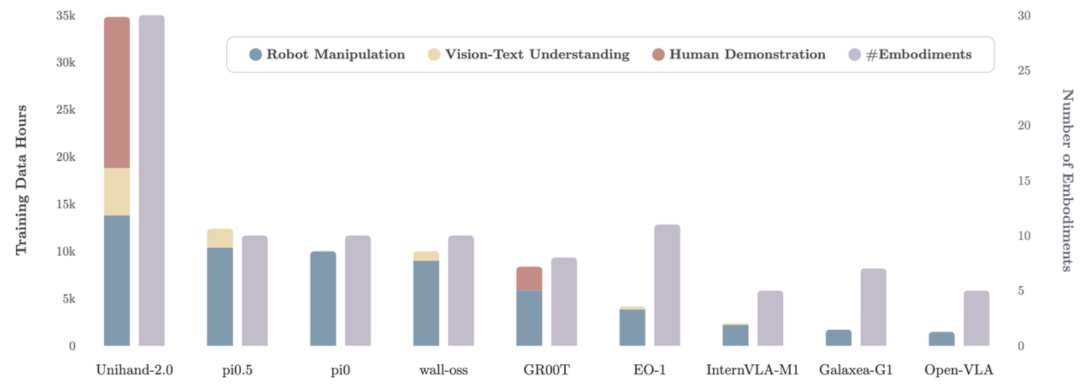
▲UniHand与现有VLA数据集规模对比:超3.5万小时和30余本体,在规模和多样性上提升了3倍以上
在Being‑H0.5之前,尚未有研究尝试将这么多异构本体数据统一用于训练——其核心挑战在于,不同机器人的状态空间与动作空间差异巨大,直接混合训练极易引发“数据冲突”,导致模型难以收敛或泛化。
为解决上述难题,Being Beyond团队提出了统一动作空间框架,将双足人形、轮式底盘、桌面机械臂、夹爪、灵巧手等形态各异的机器人,映射到同一特征表示空间中,从而有效支撑跨本体联合训练与知识迁移。
02.
以人为中心的训练范式
针对人类视频普遍缺乏高质量标注的痛点,Being Beyond团队还设计了一套名为UniCraftor的便携、可扩展、低成本的人类视频采集系统。
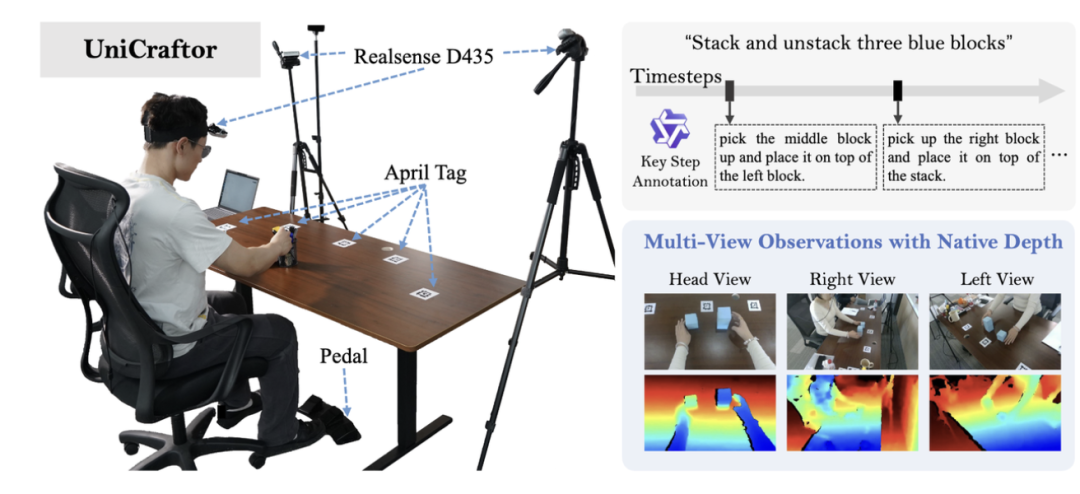
在统一动作空间的基础上,Being‑H0.5提出了一套完整的以人为中心的预训练范式。具体包括:
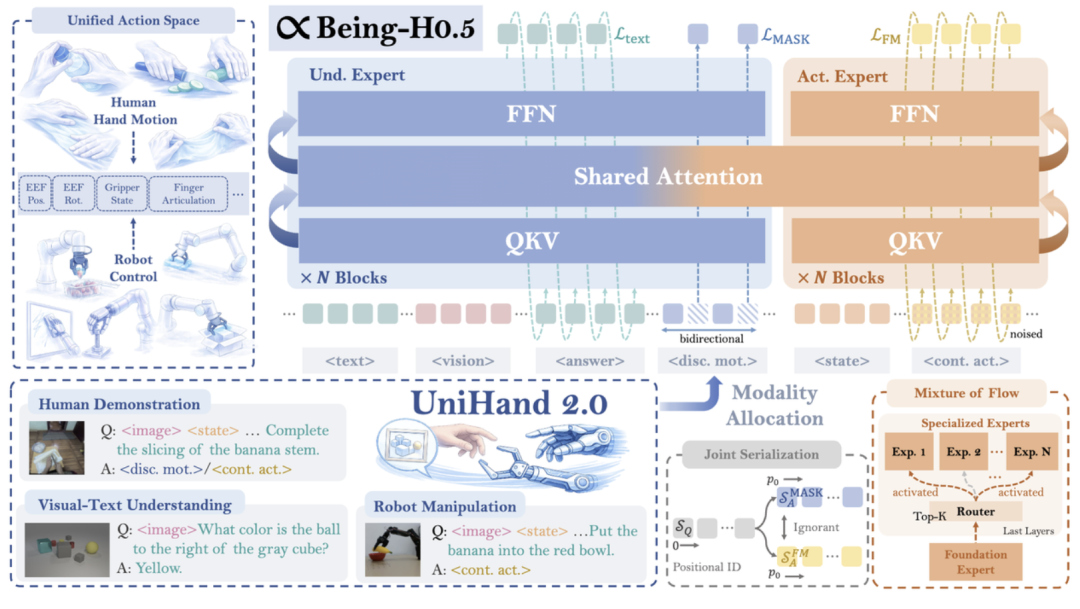
统一序列化建模:不再为人类演示、机器人轨迹和视觉文本数据设立独立的训练流水线,而是将它们转化成统一的多模态token序列。在这个序列中,视觉和文本负责提供背景信息,而统一的“状态/动作”Token则承载物理交互信号。
混合监督(多目标优化):在同一个序列上根据数据特点应用不同的损失函数。如针对文本数据(如VQA、运动描述)的Next-token Prediction;针对离散人类动作的Masked Token Prediction,针对连续人类和机器人数据,则在统一空间内进行动作预测(Action Prediction)等。
这种融合的预训练方式能让模型从人类行为中提取高层级的、可迁移的交互逻辑(先验)的同时,从机器人数据中提炼高精度的运动控制知识。
03.
面向跨本体的模型架构升级
传统的VLA,尤其是近期流行的基于flow-matching架构的模型,其模型容量受限于参数规模,这导致VLA在混合异构数据进行预训练时的性能下降,同时也阻碍了模型泛化到各种复杂下游任务的能力。为了克服这个问题,Being Beyond团队针对性地进行了一系列架构创新。
首先,受大模型MoE架构启发,Being Beyond团队设计了 Mixture-of-Flow(MoF)架构,将动作专家(action expert)解耦为负责学习通用的运动原语(如:物体如何运动)的共享专家,以及通过机器人感知路由,负责特定形态精准执行的特化专家。
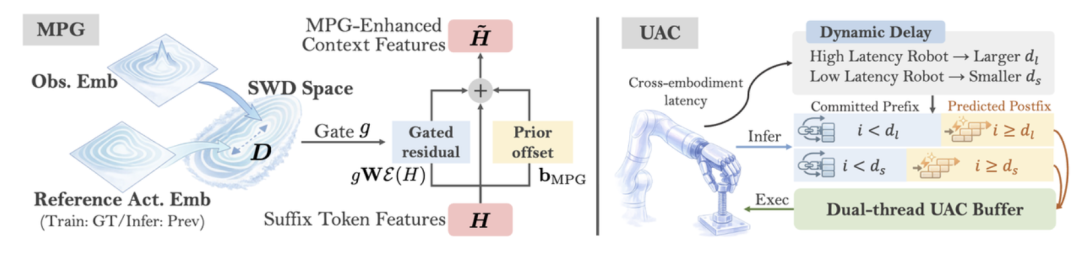
▲MPG和UAC模块示意图
此外,针对现实部署中的抖动和延迟问题,Being Beyond团队引入了流形保持门控(Manifold-Preserving Gating, MPG)以确保在感知模糊时模型能退回到鲁棒的先验分布;以及通用异步分块(Universal Async Chunking, UAC)技术,使同一个模型能适配不同控制频率和延迟的机器人硬件。
04.
跨本体复杂任务执行能力强,
基准测试超越π0.5、GR00T
为验证Being‑H0.5的跨本体能力,Being Beyond团队在PND、G1、Franka等不同构型的人形机器人、机械臂本体上进行了大量真机实验。

▲Being-H0.5在不同构型本体上均进行了广泛验证实验
在海量、多源数据的加持下,模型展现出较强的跨本体与复杂任务执行能力,甚至能够完成“用按压喷壶浇花”这类以往夹爪式机器人难以实现的操作。

▲跨本体真机任务
在四组任务上展开的定量评测实验中,Being-H0.5无论是generalist(多本体数据混合训练,难度更大)还是specialist(单一本体数据分开训练,较简单),性能表现都远优于仅能依托单一本体训练的π0.5模型。
同时,Being-H0.5-generalist模型在平均性能表现上和specialist持平,展现出其跨本体维度上较强的泛化能力。
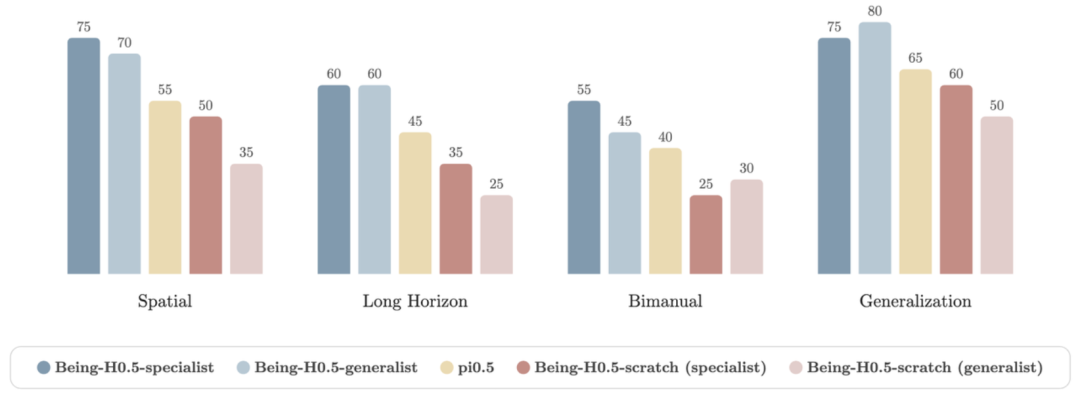
▲真机实验性能对比
为定量评估模型性能,Being-H0.5还在LIBERO、RoboCasa等广泛使用的评测基准上进行了测试。在仅依赖模仿学习与纯RGB视觉输入的条件下,模型平均取得了98.9% 与54%的成功率,不仅超越了π0.5、GR00T等所有已知VLA模型,甚至优于部分借助强化学习与3D模态的方案,展现出SOTA性能和竞争力。
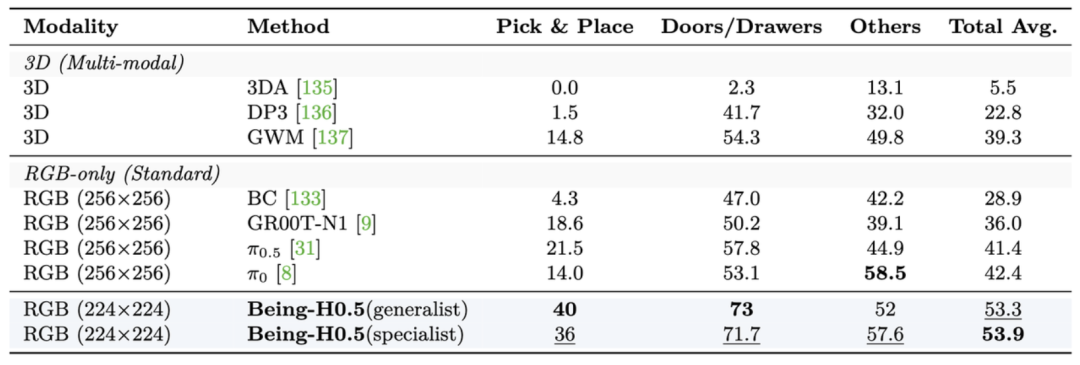
▲RoboCasa对比结果,Being-H显著超过π0.5、GR00T等先进VLA
05.
结语:依托以人为中心的技术范式,
降低具身智能研发门槛
Being-H0.5的推出,为具身智能领域提供了一种新的技术范式思路:高质量训练数据并非必须源于自建的高成本机器人集群。针对“如何高效适配多元本体、低成本获取优质训练数据”这一核心行业挑战,Being-H0.5将视角转向人类本身这一最丰富、最自然的数据源泉。
这一技术路径在一定程度上降低了具身智能技术的研发门槛,使得企业无需投入巨额资金构建数据“护城河”,便可依托以人为中心的学习范式,开发适配多元本体的通用算法。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 1
1 0
0- 0



 已为社区贡献73条内容
已为社区贡献73条内容

所有评论(0)