为什么扩散策略在操作任务上表现良好,很难与在线RL结合?
该综述不仅构建了 Online DPRL 的理论体系与分类标准,更通过统一基准的实证分析,揭示了不同算法的核心 trade-off(样本效率 vs 扩展性、性能 vs 泛化性)。其提出的分类框架、五大评估维度与算法选择指南,为机器人学习研究者提供了清晰的技术路线图,推动扩散策略从实验室演示走向真实世界的规模化应用,加速通用自主机器人的落地进程。
在机器人学习领域,扩散策略凭借对多模态动作分布的卓越建模能力,在复杂操纵任务中展现出超越传统策略网络的性能,但如何将其与在线强化学习(RL)有效融合,一直受限于训练目标不兼容、梯度不稳定等核心难题。
韩国大邱庆北科学技术院团队发表的综述论文,以 “算法分类 - 实证分析 - 应用指导” 为核心逻辑,首次系统梳理了在线扩散策略强化学习(Online DPRL)的研究现状,构建了统一的算法 taxonomy 与基准测试体系,为规模化机器人控制提供了全新的理论框架与实践指南。
- 论文题目:A Review of Online Diffusion Policy RL Algorithms for Scalable Robotic Control
- 论文链接:https://arxiv.org/abs/2601.06133
核心亮点:首个 Online DPRL 全面综述、四大家族算法分类、NVIDIA Isaac Lab 统一基准、五大关键维度实证分析
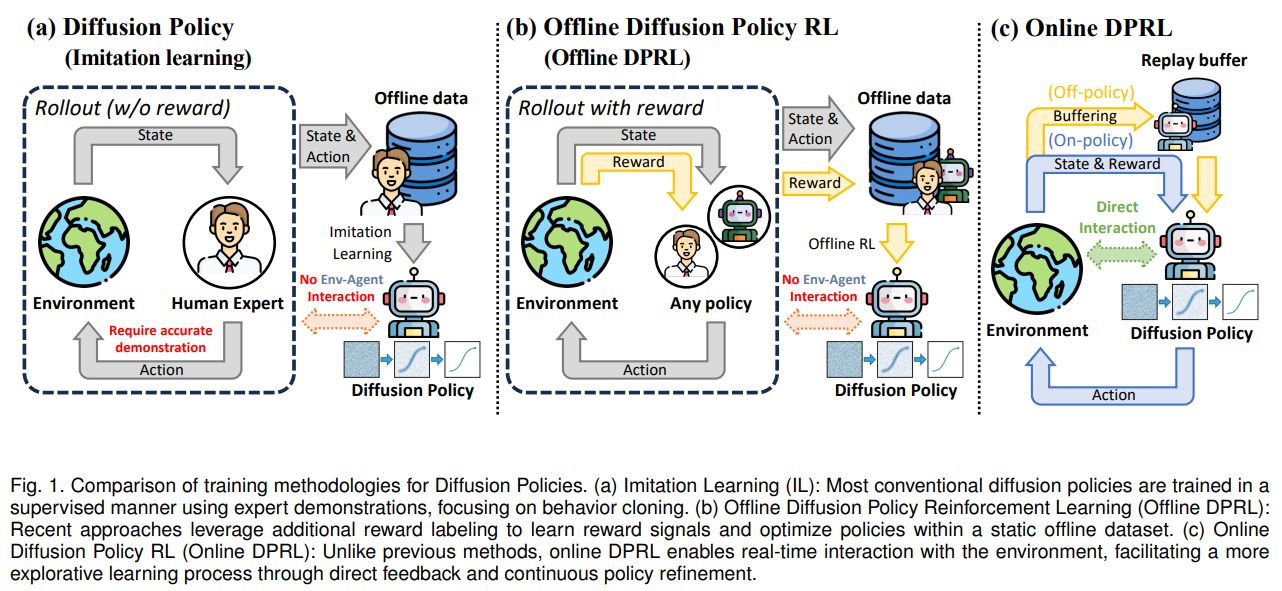
问题根源:扩散策略与在线 RL 融合的核心挑战
Online DPRL 的技术突破源于对现有方法痛点的深度拆解,三大核心矛盾构成研究的起点:
- 训练目标冲突:扩散模型的去噪训练目标与在线 RL 的策略优化机制存在本质 incompatibility,难以直接复用传统 RL 的梯度更新逻辑。
- 计算与梯度难题:扩散模型的多步反向去噪过程需通过长链反向传播计算梯度,不仅计算成本极高,还易引发梯度消失或爆炸问题。
- 泛化与鲁棒性不足:离线扩散策略受限于固定数据集,无法自主探索新动作;而在线学习需兼顾环境适应性、跨机器人形态迁移能力,现有方法难以平衡。
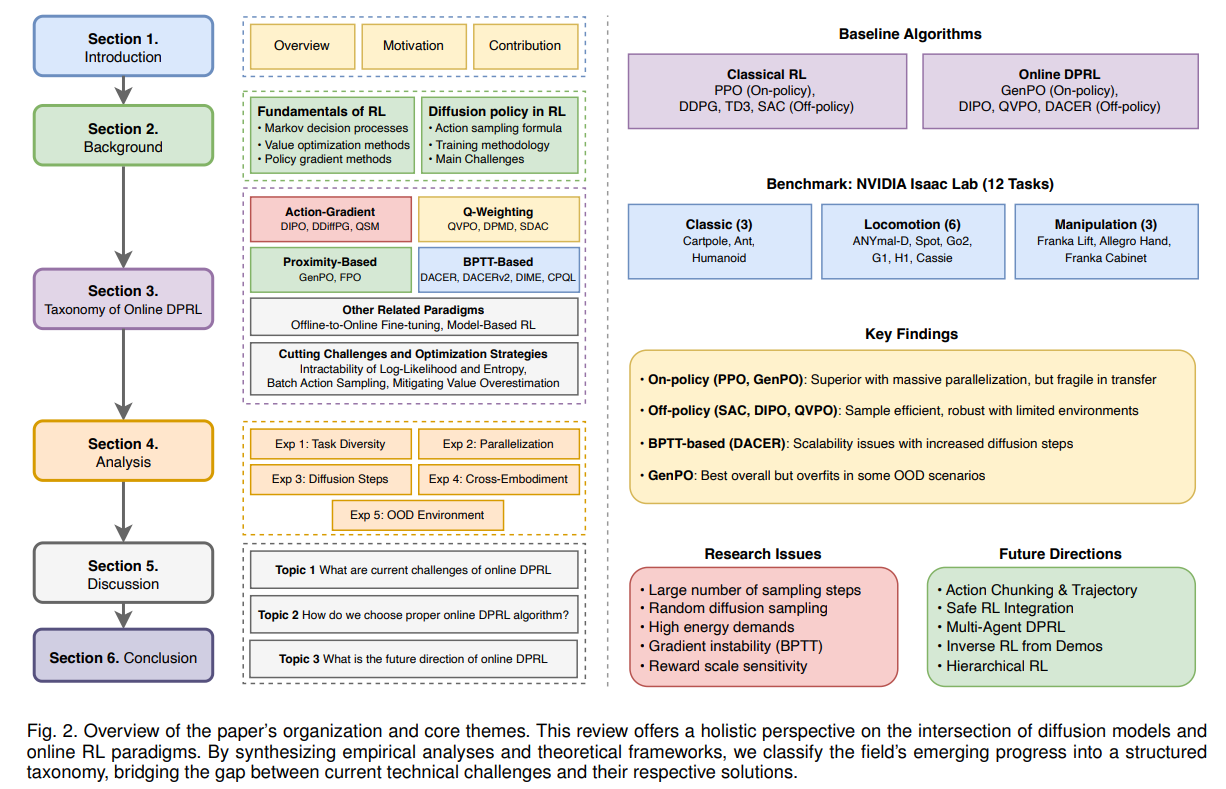
方案设计:Online DPRL 的四大家族算法体系
针对上述挑战,论文基于策略改进机制的差异,提出首个 Online DPRL 算法分类框架,将现有方法划分为四大核心家族,形成完整的技术图谱(如图 3):
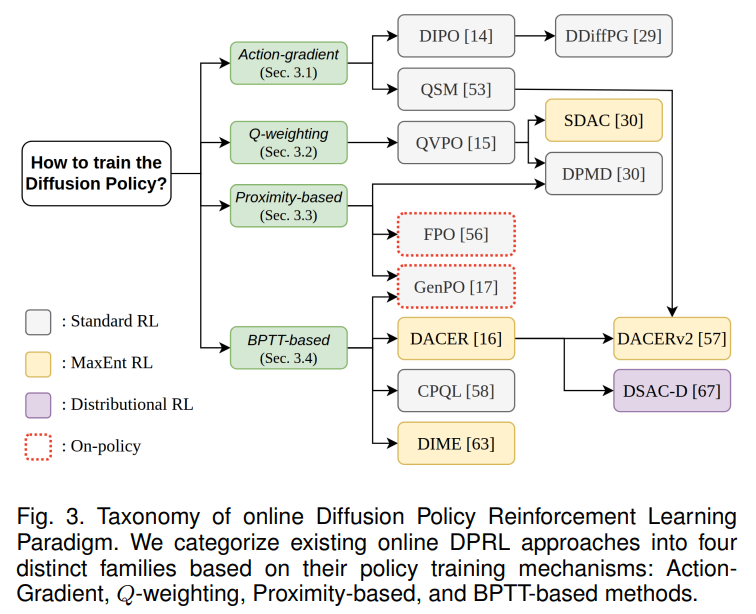
动作梯度类方法(Action-Gradient)
通过动作梯度直接优化策略,规避扩散链反向传播的复杂度,代表算法包括 DIPO、DDiffPG、QSM。核心逻辑是利用 Q 函数梯度指示动作改进方向,将优化后的动作作为扩散模型的训练目标,实现策略更新与去噪过程解耦。其关键优势为计算效率高,无需遍历完整扩散步骤,适合资源受限场景,但依赖 Q 函数的梯度准确性,易受价值估计偏差影响。
Q 加权类方法(Q-Weighting)
通过 Q 值加权调制扩散损失,引导策略向高回报区域收敛,代表算法包括 QVPO、DPMD、SDAC。核心逻辑是设计与动作价值相关的加权函数,对高优势(A 值)动作赋予更高训练权重,过滤次优行为。其关键优势是保留扩散模型的多模态表达能力,同时利用 RL 反馈优化策略,但对奖励尺度敏感,难以处理负奖励场景,性能易饱和。
近邻类方法(Proximity-Based)
借鉴 PPO 等近邻策略优化思路,解决扩散策略对数似然难以计算的问题,代表算法包括 GenPO、FPO。核心逻辑是通过可逆流变换、条件流匹配等技术,近似计算策略概率密度,适配传统 RL 的优势加权更新。其关键优势是在大规模并行环境中性能突出,收敛稳定性强,但架构约束严格,泛化能力受限于并行化规模。
时序反向传播类方法(BPTT-Based)
通过端到端反向传播遍历完整扩散过程,代表算法包括 DACER、DACERv2、DIME、CPQL。核心逻辑类似循环神经网络训练,直接优化扩散链的整体奖励,部分方法结合一致性模型减少扩散步骤。其理论上能充分利用扩散过程的时序信息,但扩展性差,扩散步骤增加时计算成本呈指数增长,易出现梯度不稳定。
实证分析:五大维度统一基准测试
为公平对比不同算法的性能,论文在 NVIDIA Isaac Lab 平台构建了涵盖 12 个机器人任务的统一基准(如表 3),从五大关键维度开展系统性评估:

任务多样性
覆盖经典控制(Cartpole)、移动(Ant、Humanoid)、操纵(Franka Lift)三大类任务,测试算法的普适性。核心发现:GenPO(近邻类)在 6/12 任务中排名第一,峰值性能突出;DIPO(动作梯度类)在离线策略中表现最优,平均排名 3.58(如表 4、图 4)。
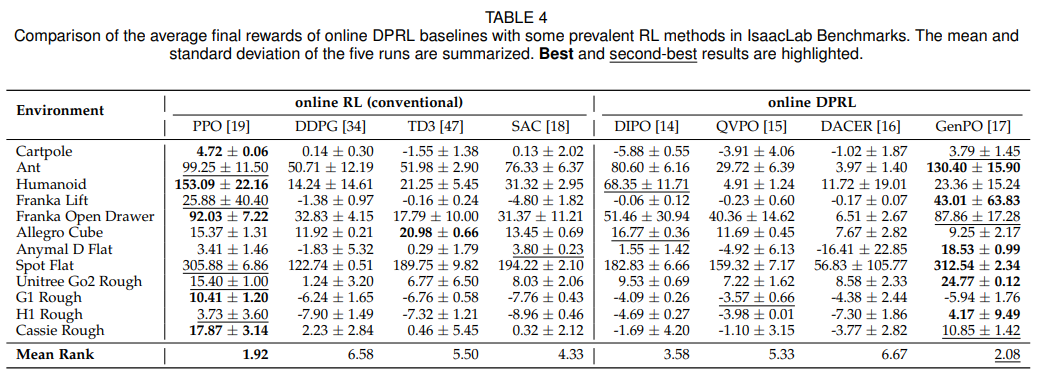
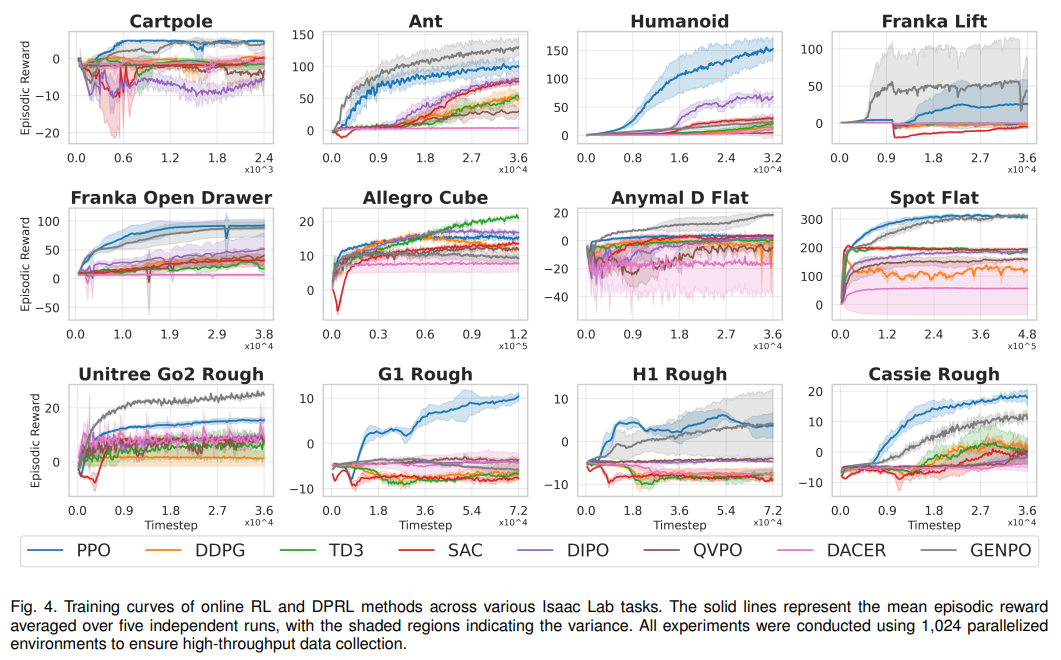
并行化能力
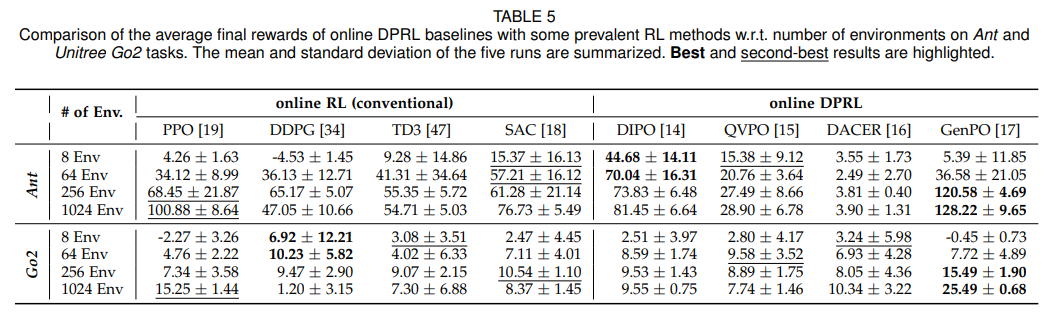
测试不同并行环境数量(8-1024 个)下的性能变化,模拟大规模仿真与真实场景差异。核心发现:GenPO、PPO 等在线策略在 1024 个并行环境下性能显著提升,但在 8 个环境的受限场景中性能暴跌 95% 以上;DIPO 等离线策略对并行化规模不敏感,鲁棒性更强(如表 5、图 5)。
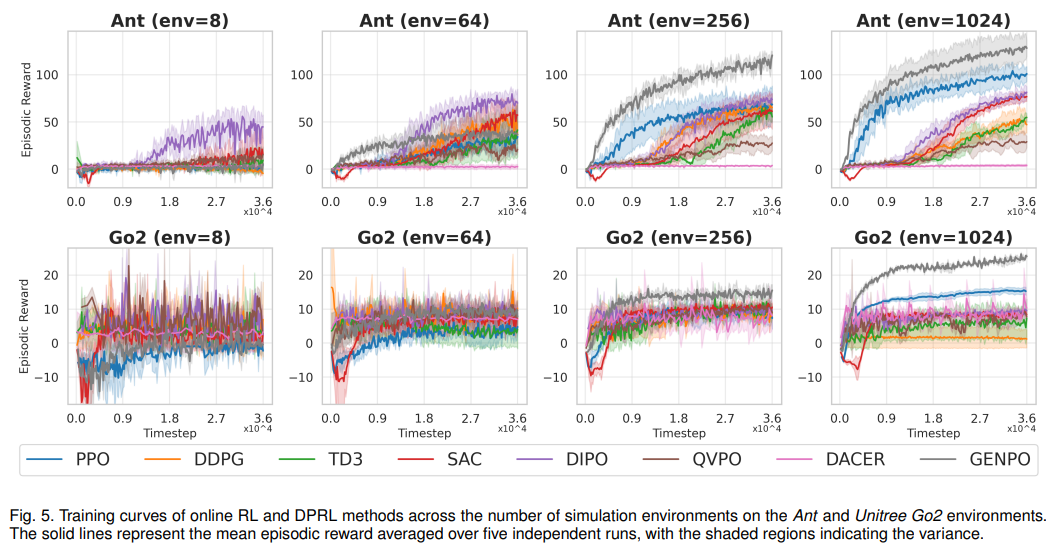
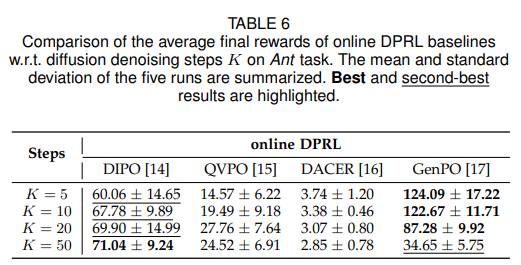
扩散步骤扩展性
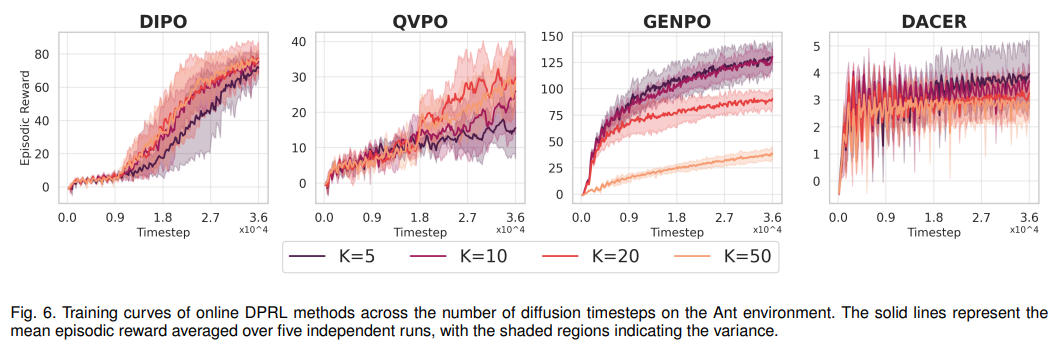
分析扩散步数(K=5-50)对性能与 latency 的影响。核心发现:动作梯度类、Q 加权类方法随 K 值增加性能提升;BPTT 类方法(如 DACER)在 K>20 后性能急剧下降,梯度不稳定问题凸显(如表 6、图 6)。
跨机器人形态泛化
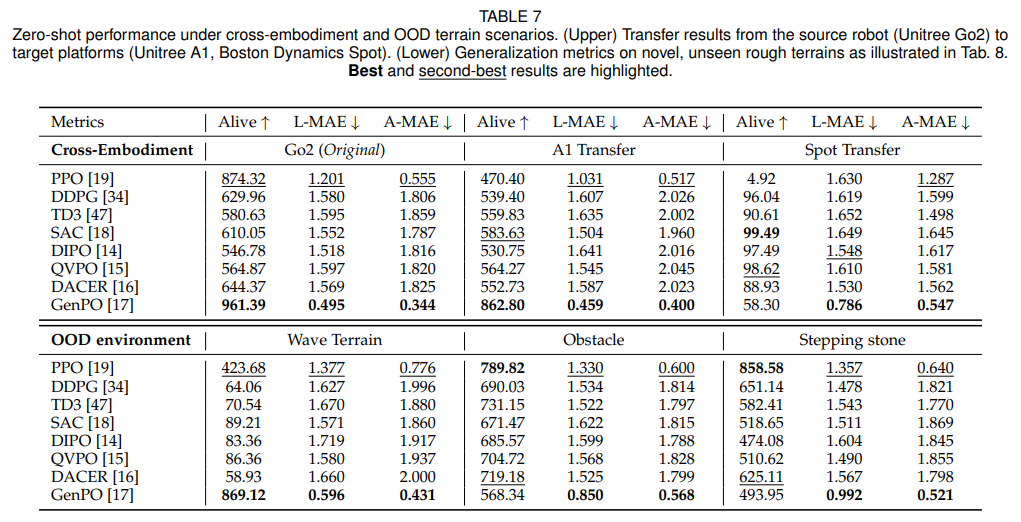
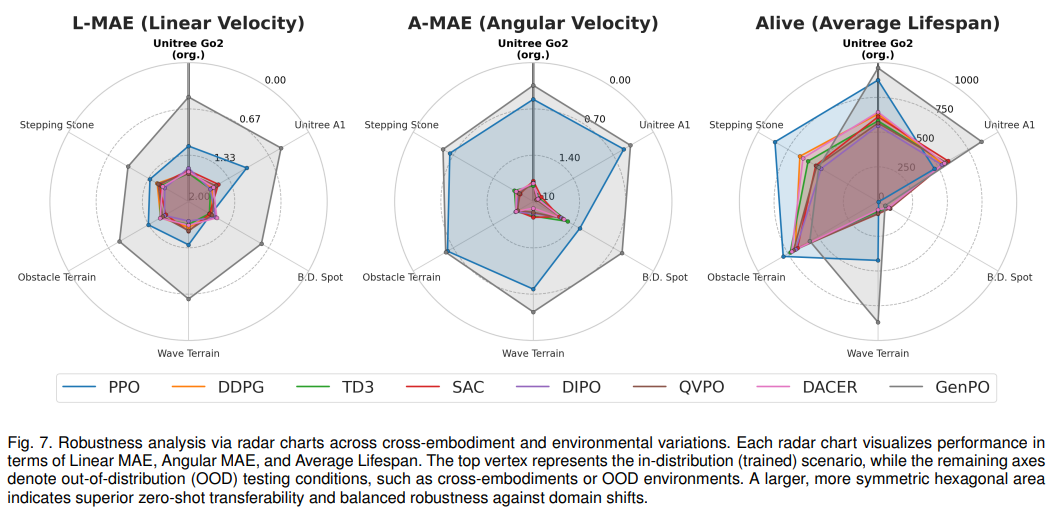
测试从源机器人(Unitree Go2)到目标机器人(Unitree A1、Boston Dynamics Spot)的零样本迁移能力。核心发现:离线策略(如 DIPO、QVPO)迁移鲁棒性更强,在线策略在机器人硬件差异较大时易出现稳定性崩溃(如表 7、图 7)。
分布外环境鲁棒性
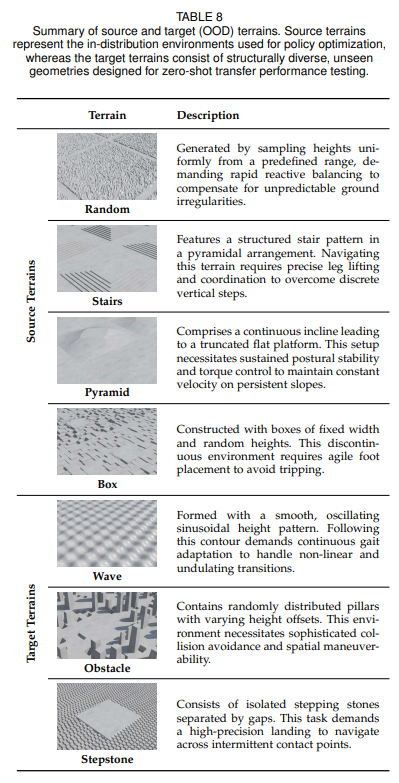
评估在未见过的地形(波浪地形、障碍地形、踏步石)中的适应能力(如表 8)。核心发现:GenPO 在部分场景中表现优异,但存在过度拟合源环境的风险,易出现冒险行为;多模态融合有助于提升环境适应性。
核心结论与应用指南
算法选择原则
- 大规模并行仿真场景(如集群训练):优先选择 GenPO 等近邻类方法,追求峰值性能;
- 真实机器人、资源受限场景:优先选择 DIPO 等动作梯度类方法,平衡效率与鲁棒性;
- 高精度长时程任务:选择动作梯度类或 Q 加权类方法,避免 BPTT 类的扩展性瓶颈。
未来研究方向
- 动作块与轨迹规划:将单步动作预测扩展为多步轨迹生成,桥接受控与规划的鸿沟;
- 安全 RL 融合:加入约束优化、障碍函数,解决仿真到真实迁移中的冒险行为问题;
- 多智能体 DPRL:利用扩散模型建模复杂联合动作分布,适配大规模多智能体协作场景;
- 逆强化学习整合:从演示数据中学习奖励函数,超越单纯行为克隆,提升泛化能力;
- 分层 RL 架构:通过高层策略选择扩散子策略,降低动作空间探索复杂度。
总结:Online DPRL 的规模化价值
该综述不仅构建了 Online DPRL 的理论体系与分类标准,更通过统一基准的实证分析,揭示了不同算法的核心 trade-off(样本效率 vs 扩展性、性能 vs 泛化性)。其提出的分类框架、五大评估维度与算法选择指南,为机器人学习研究者提供了清晰的技术路线图,推动扩散策略从实验室演示走向真实世界的规模化应用,加速通用自主机器人的落地进程。
具身求职内推来啦
国内最大的具身智能全栈学习社区来啦!
推荐阅读
从零部署π0,π0.5!好用,高性价比!面向具身科研领域打造的轻量级机械臂
工业级真机教程+VLA算法实战(pi0/pi0.5/GR00T/世界模型等)
具身智能算法与落地平台来啦!国内首个面向科研及工业的全栈具身智能机械臂
VLA/VLA+触觉/VLA+RL/具身世界模型等!具身大脑+小脑算法与实战全栈路线来啦~
MuJoCo具身智能实战:从零基础到强化学习与Sim2Real
Diffusion Policy在具身智能领域是怎么应用的?为什么如此重要?
1v1 科研论文辅导来啦!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 14
14 0
0- 0



 已为社区贡献106条内容
已为社区贡献106条内容

所有评论(0)