通过预言来强化动作策略
25年11月来自复旦、上海创新研究院和ASU Logos Robotics Lab 的论文“Reinforcing Action Policies by Prophesying”。视觉-语言-动作(VLA)策略在协调语言、感知和机器人控制方面表现出色。然而,大多数VLA策略仅通过模仿进行训练,这会导致过拟合演示数据,并且在分布偏移的情况下稳定性较差。强化学习(RL)直接优化任务奖励,从而解决这种协
25年11月来自复旦、上海创新研究院和ASU Logos Robotics Lab 的论文“Reinforcing Action Policies by Prophesying”。
视觉-语言-动作(VLA)策略在协调语言、感知和机器人控制方面表现出色。然而,大多数VLA策略仅通过模仿进行训练,这会导致过拟合演示数据,并且在分布偏移的情况下稳定性较差。强化学习(RL)直接优化任务奖励,从而解决这种协调性问题,但真实机器人交互成本高昂,且传统的模拟器难以构建和迁移。通过学习世界模型和针对基于流动作头定制的强化学习程序,解决VLA后训练的数据效率和优化稳定性问题。具体而言,提出Prophet,这是一个统一的动作-到-视频机器人驱动模型,它基于大规模异构机器人数据进行预训练,以学习可重用的动作-结果(action-outcome)动态。Prophet能够以少量样本适应新的机器人、物体和环境,从而生成一个可立即部署的模拟器。在 Prophet 的基础上,用 Flow-action-GRPO (FA-GRPO) 强化动作策略。FA-GRPO 改进 Flow-GRPO 以适应 VLA 动作,并使用 FlowScale 进行逐步重加权,从而重新调整流头中每一步的梯度。Prophet、FA-GRPO 和 FlowScale 共同构成 ProphRL,这是一种实用且数据和计算效率高的 VLA 后训练方法。实验表明,在公开基准测试中,该方法可提升 5% 至 17% 的成功率;在真实机器人上,针对不同的 VLA 变型,该方法可提升 24% 至 30% 的成功率。
如图所示:ProphRL 使用世界模型作为面向真实世界的模拟器,对 VLA 策略进行后训练。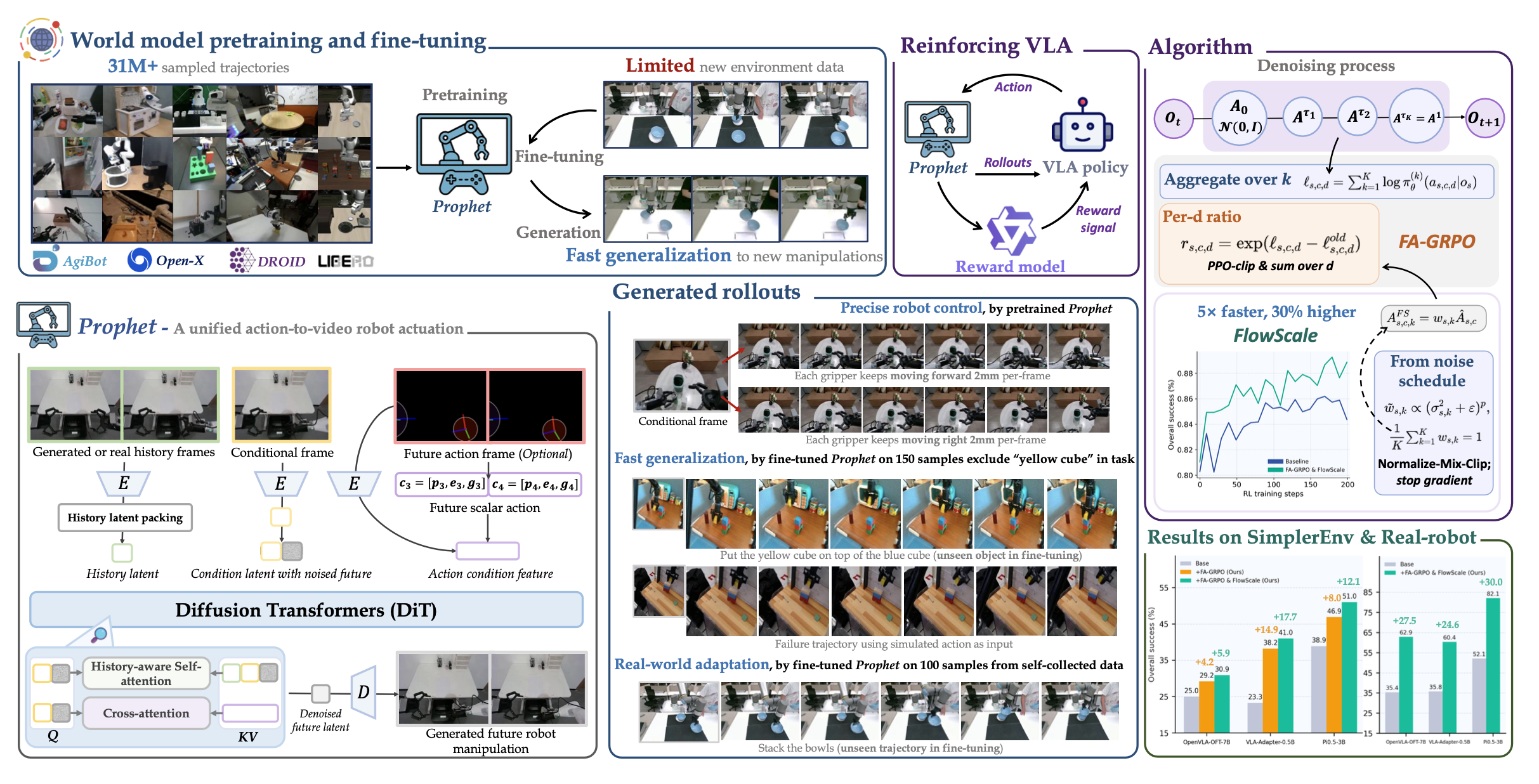
训练范式
如图所示,整体的训练范式 ProphRL 将 Prophet 与 VLA 后训练相结合。在每个外部步骤中,策略根据指令和初始图像预测一个动作块。Prophet 生成一个基于该动作块和初始图像的片段。该片段被反馈给策略和 Prophet,从而实现长时域闭环展开。一个基于冻结 VLM 的奖励模型 [4] 使用提示模板对每次展开进行评分,以生成组奖励。最后,用 FA-GRPO 利用组归一化优势优化策略,同时 FlowScale对去噪步骤进行重加权以稳定梯度。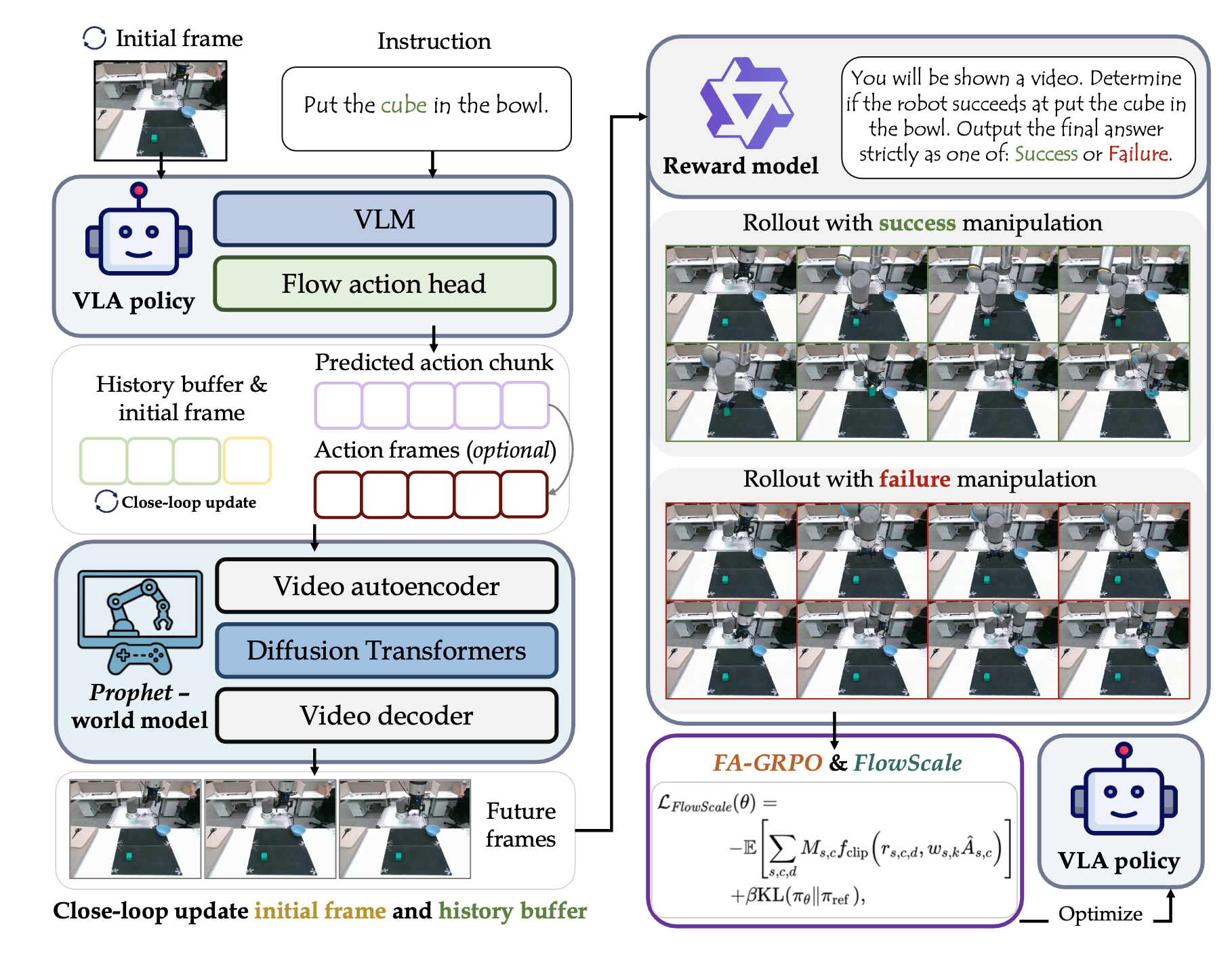
世界模型
基于潜视频扩散(LVD)流水线构建 Prophet。视频自编码器将真实视频片段 x_1:T 编码为潜变量 z_0 = E(x_1:T ),并通过 xˆ_1:T ≈ D(z_0) 近似重构视频。然后,DiT 去噪器学习 z_0 的条件扩散模型:在步骤 t,添加高斯噪声得到 z_t,去噪器接收 (z_t, t, f),其中 f 表示条件数,迭代地预测干净的潜变量 zˆ_0,最终将其解码回视频。去噪器使用标准的潜空间噪声预测目标进行优化。
动作定义
对于每条轨迹,将底层控制指令表示为 c,其中 T 是时间范围,N 是末端执行器的数量,D 是动作维度。为了实现跨数据集预训练,将 N 固定为所有数据集中末端执行器的最大数量(例如,在 AgiBot [10] 中为 2),并在末端执行器维度上用零填充末端执行器数量较少的轨迹。这些填充的条目不对应于任何实际的末端执行器,但允许保持单一的、共享的动作参数化。每个步骤、每个末端执行器的动作都是一个 7 维向量。
在大规模预训练期间,将运动参数化为相对于前一个末端执行器坐标系的局部位姿变化量。令 ξ_t−1,n 表示末端执行器 n 在时间 t − 1 时在世界坐标系中的变换。动作 c_t,n 对应于目标变换 ξ_t,n,该变换是通过在 ξ_t−1,n 的局部坐标系中施加一个小的刚体运动 ∆ξ_t,n 而获得的。这种增量式方法使得动作空间在不同任务和数据集之间更加均匀。
为了进行微调,保留相同的 7 维结构,但调整增量的语义,以匹配每个环境中使用的底层控制器。例如,在基于模拟器的 LIBERO 中,动作被解释为环境直接接收的伺服指令;而在真实机器人和 BRIDGE 中,动作对应于连续绝对位姿之间的差异(即位置和欧拉角分别为 ξ_t,n − ξ_t−1,n)。在所有情况下,夹爪 g_t,n 仍然是一个归一化标量,表示期望的张开度。
构建动作坐标系
为了向 Prophet 提供简洁且几何感知的机器人运动表示,构建一个动作坐标系,方法是将末端执行器的动作投影到相机图像平面上,并在黑色背景上渲染二维可视化图像,具体方法参见文献 [28, 39]。对于每个时间步 t,假设可以访问以下信息:(i) 相机内参 K;(ii) 将 3D 点从世界坐标系转换到相机坐标系的相机外参 E_t;(iii) 每个末端执行器 j 的位置 p_t,j 和旋转 R_t,j;(iv) 用于编码动作幅度的标量控制信号 g_t,j(即夹爪张开角度)。
令 {nx,ny,nz} 表示末端执行器坐标系中三个轴对齐的单位向量,并按恒定轴长 l 缩放。世界坐标系中对应的 3D 点包括 末端执行器原点和三个轴的端点,这些点被变换到相机坐标系,然后投影到图像平面上。
为了使可视化具有深度-觉察能力,将渲染圆盘的半径设置为深度的单调递减函数,还使用定义在 [g_min, g_max] 范围内的固定颜色映射 CM(·) 将标量控制信号 g_t,j 映射到颜色。
最后,将动作帧渲染到黑色画布 c_t 上。对于每个末端执行器 j,绘制一个半径为 r(z0_t,j)、中心为 u0_t,j 的实心圆盘,并在圆盘中心叠加一个小白点,以及从 u0_t,j 到 uk_t,j 的三条彩色线段,其中 k ∈ {x, y, z},表示局部方向。
实际上,将彩色圆盘绘制在一个单独的图层上,并将其与线段进行 alpha 混合,以获得平滑的外观。如图展示在 AgiBot [10] 上构建的动作帧。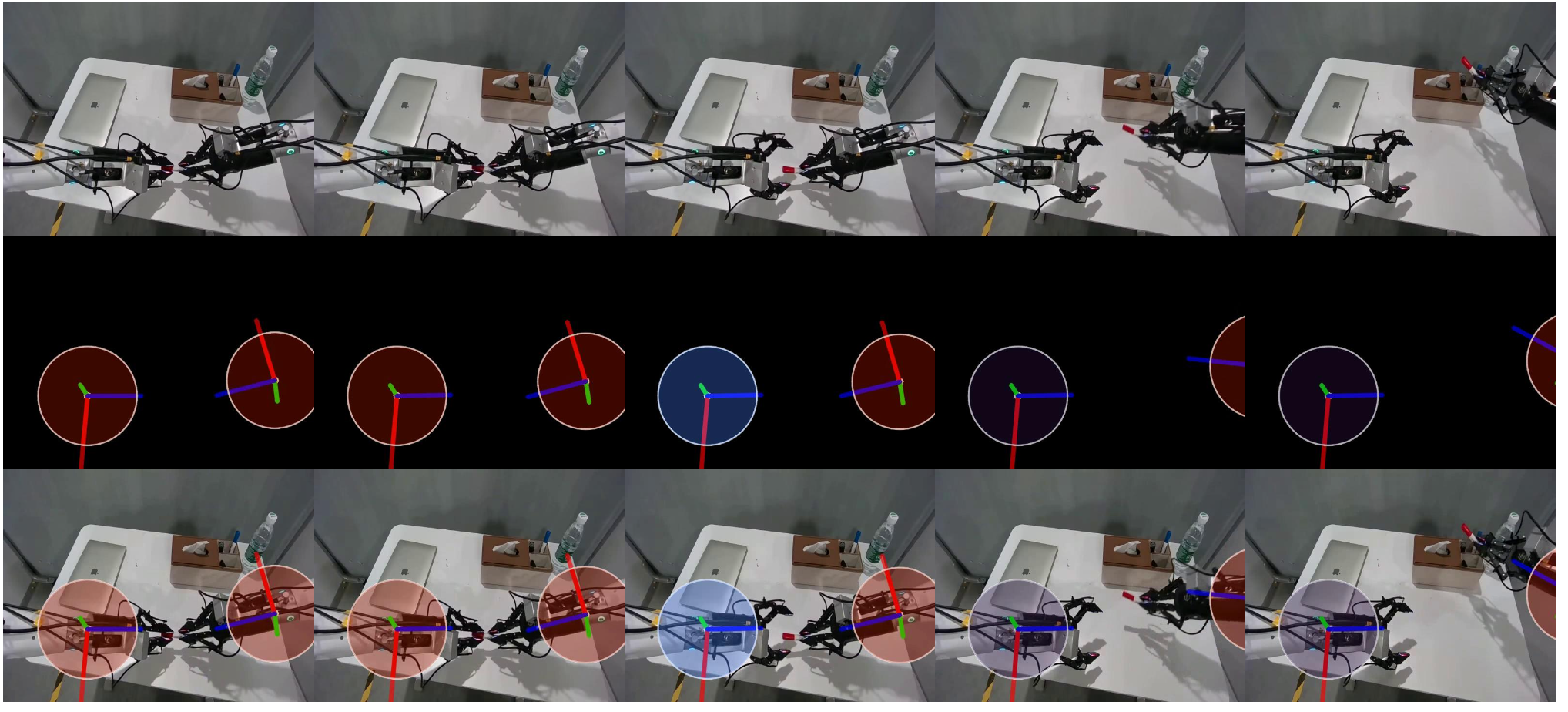
动作条件化
Prophet 模型在两个层面上对动作进行条件化:(i) 标量动作流的全局块(chunk)级嵌入,以及 (ii) 动作帧的可选潜嵌入。
符号说明:在实践中,每一步的每个动作都是一个形状为 (N,D) 的张量,包含 N 个末端执行器,将 N 填充到数据集中末端执行器的最大数量。为了简化符号,折叠末端执行器维度,并将动作写成 c_1:T。为了保持动作条件化公式的简洁性,省略显式的末端执行器索引。
标量动作流:给定一个每一步的动作序列 c_1:T,首先将整个块展平为一个形状为 [T × D] 的向量,并通过 MLP 将其映射到全局嵌入 f_sa = φ(c_1:T),其中 D_m 是 DiT 通道的维度。
令 t̃ 表示 DiT 时间嵌入器生成的标准时间步嵌入。简单地添加全局动作嵌入来注入标量动作条件,即 t̃ = t̃ + f_sa。在实践中,采用时间维度的广播。
动作帧流:当存在动作帧 c_1:T ∈ RT ×H ×W ×3 时,还会对其潜表示进行条件化。
历史-觉察机制
用 FramePack 风格的 [70, 71] 模块维护过去潜在帧的低分辨率记忆。
给定视频自编码器从历史缓冲区 h_−T_h:0 计算出的历史潜在值 zhist,历史-觉察模块应用多个 3D 平均池化和 1 × 1 × 1 投影块,并采用不同的时空步长,将所有生成的token连接成一个记忆矩阵 M。两个线性层将 M 映射到额外的K向量和 V向量 (K_mem, V_mem),这些向量作为外部连接记忆 Q̃ = Attn(Q, [K_mem; K], [V_mem; V ]) 输入到所有 DiT 块中。
历史-觉察机制为稳定的几何形状和接触演化提供长程时间上下文,同时保持计算的可预测性。
长展开生成
以分块的方式自回归生成长视频。从观测到的第一帧开始,用该帧初始化历史缓冲区。给定第一个片段的动作展开,模型生成一个短片段。然后,将最后生成的帧用作下一个片段的起始帧,并将新生成的片段压缩到历史缓冲区中。重复此过程以在扩展到长时域的同时保持时间连续性。算法 1 详细展示使用历史缓冲区更新的长时域展开生成过程。

基于光流的评估协议
以往的动作条件世界模型通常仅使用视频指标(例如,PSNR)进行评估,这些指标可以捕捉感知保真度,但无法判断动作是否正确执行或物理交互是否遵循预期控制。为了解决这个问题,引入一种基于光流的协议,该协议比较真实视频和动作条件展开之间的运动场。给定一个真实视频 x_1:T 和一个展开 xˆ_1:T,在灰度转换后,使用 Farnebäck 估计器 [17] 计算连续帧之间的密集光流:u_t = Flow(x_t, x_t+1), uˆ_t = Flow(xˆ_t, xˆ_t+1)。
通过末端误差来衡量幅度一致性,并通过余弦相似度来衡量方向一致性。这些指标比较的是运动场而非外观,从而得出与外观无关且与控制相关的评估,以判断条件反射动作是否能诱发正确的末端执行器和接触动力学。
基于强化学习的VLA后训练
轨迹布局。将一批情景式展开表示为形状为[B, S, K, CH, D]的张量,其中B是批次大小,S索引外部模型推理步骤(沿轨迹的环境步骤和策略调用),K是基于流动作头中的去噪步骤数,CH是每次策略调用发出的动作块数,D是每个动作块的维度。对于每个情景 i ∈ {1, …,B} 和外部步骤s ∈ {1, …,S},策略接收一个观测值o^(i)_s并输出一个分块动作 {a^(i)_s,c,d},c=1, …,CH;d=1, …,D。每对 (s, c) 对应于两次策略调用之间按顺序执行的一条底层控制命令,在所有的实验中,D = 7,编码末端执行器的平移、旋转和一个标量夹爪命令。块索引 c 允许策略针对每个观测值 o(i)_s 发出一个短的开环命令序列,这在经验上稳定长时域控制。
流动作头和内部步骤。基于流的动作头将每个块、每个维度的对数似然log π_θ(a_s,c,d | o_s 分解到内部步骤。索引 k 是流头内部的,并且不会随环境时间推进:对于固定的 (s, c),K 去噪更新 o_s 上的所有条件,并联合参数化单个环境级动作 a_s,c。在强化学习目标中,首先对 k 进行聚合,保持维度 d 的分解,并将每对 (s, c) 视为一个环境动作。 PPO 风格的比率是针对每个三元组 (s, c, d) 计算的。
可变长度episodes和掩码。注意,episodes的长度是可变的。令 T_i 表示episode i 在外层步长中的视野。将轨迹存储在固定长度 S 的张量中,并用虚拟转换填充剩余的槽位。提前终止由二进制掩码 M^(i)_s,c 处理。
在实践中,将 M^(i)_s,c 广播到 k 和 d,并将策略损失和优势都乘以该掩码。如果episode在数据块之间终止,保守地在第一个终止数据块之后设置所有数据块 c 的 M(i)_s,c = 0,以确保梯度不会传播到第一个无效动作之后。
流-动作-GRPO (FA-GRPO)
传统的Flow-GRPO [43] 将每个内部流步骤 k 视为一个原子动作,并在对 k 求和之前,针对每个 (s, c, k) 构建 PPO 比率。为了更好地匹配环境,FA-GRPO 将所有内部流步骤聚合为一个动作级别的对数概率,然后针对每个动作块的每个维度(即 (s, c, d) 级别)构建比率,同时仍然将每个 (s, c) 视为一个环境动作。
之前基于流的动作头将每个动作块、每个维度的对数似然分解到内部步骤中。对于每个环境步骤 s、动作块 c 和动作维度 D,定义当前策略和行为策略下的动作级别对数概率以及每个维度的PPO比率。
给定动作级别优势函数 Aˆ_s,c(每个外部步骤和块有一个优势函数,在 d 上广播),用 KL 正则化器优化一个裁剪-比率目标 L_FA-GRPO(θ)。KL 项在相同的因子化逐维动作分布上进行评估,即在所有 (s,c,d) 上进行评估,并使用掩码 M_s,c 进行聚合。
与 Flow-GRPO 目标函数相比,这里仅改变内部流程步骤的处理方式:不再将每个 (s,c,k) 视为具有自身比率和优势的独立动作,而是将 k 上的对数似然贡献求和为对数似然 l_s,c,d,并对相同的 (s, c) 使用一个在所有 d 和 k 上共享的单一优势 Aˆ_s,c。这使得动作的底层随机策略保持不变;它仅改变内部流程步骤梯度聚合的方式,即通过向所有维度和内部步骤广播每个环境动作的标量优势。
内在逐步重加权(FlowScale)
基于随机微分方程(SDE)的流头在内部步骤 k 中表现出高度不均匀的梯度幅度:早期噪声步骤和后期细化步骤对整体作用对数似然的影响方式截然不同。在没有任何校正的情况下,低噪声步(较大的 k,较小的 t)往往会主导更新。
FlowScale 引入一个与状态和步骤相关的权重 w_s,k,该权重可以调节每个流步骤的贡献,同时在目标函数L_FA-GRPO(θ) 中保持动作为中心的代理(surrogate)不变。在标量目标层面,构建 FlowScale 损失函数 L_FlowScale(θ)。
每步噪声尺度。对于每个外部步骤 s 和内部流步骤 k,从扩散/流时间序列中获得一个标量噪声尺度,而不是通过网络预测。采用一个噪声序列 {σ_j} 和一个归一化时间变量 t_s,k ∈ [0, 1]。注入噪声的标准差计算对应于一个常数,通过将 σ 值查找表与当前时间 t_s,k 相结合来实现。
权重构建。给定 σ2_,s,k,FlowScale 使用简单的归一化-混合-裁剪规则,构建归一化和裁剪的权重 w_s,k。由于 σ_s,k 随时间递减,早期噪声较大的步骤权重相对提高,而后期噪声较小的细化步骤权重相对降低,从而平衡每个步骤在不同 k 值下的梯度贡献。最终的 w_s,k 在反向传播(停止梯度)过程中被视为常数,因此 FlowScale 仅对梯度进行重新缩放,而不会改变优化目标。
在实现中,将 w_s,k 广播到形状 [B, S, K, CH, D],并将其乘以优势 Aˆ_s,c 或每步对数概率 log π(k)_θ,然后再对 k 进行聚合。在分解之后,这两种视图是等价的。算法 2 以 PyTorch 风格的伪代码总结计算过程。

理论基础和推导
FlowScale 是对每步流梯度进行启发式重加权。这里基于每步似然的高斯视图以及得分范数如何随噪声水平 σ_s,k 缩放,画出一个简单的理论基础草图。
得分范数与噪声尺度的关系。固定外层步骤 s 和内层流步骤 k,并抑制索引 (s,c,d)。在动作空间中,用均值为 μ_s,k、方差为 σ2s,k 的各向同性高斯分布来近似每步似然因子 π(k)。σ_s,k 视为由噪声调度固定,并关注相对于均值 μ_s,k 的梯度。
跨流步的梯度分解。为简单起见,忽略裁剪项和 KL 项,可以写出具有 FlowScale 梯度的 FA-GRPO 的线性化视图。
权重的方差平衡选择。考虑一个方差平衡准则:对于固定的 (s, c),选择权重 w_s,k,使得每个流步骤对梯度范数的预期贡献相当。
归一化-混合-裁剪作为对角预条件子。归一化-混合-裁剪规则。 权重计算对 w⋆_s,k 进行三项实用修改:(i) 归一化强制每个 (s, batch) 满足 sum(w̄_s,k)/K = 1,从而保持策略梯度在流步骤上的平均尺度不变,仅改变步骤间的相对差异。(ii) 强度为 α 的均匀混合通过将所有权重拉向 1 来防止崩溃到单个主导步骤。(iii) 将权重裁剪到 [w_min, w_max] 限制每个步骤的有效步长变化。这些操作可以看作是沿流-步维度的简单对角预处理器:FlowScale 在不改变整体学习率或动作级别代理(surrogate)的情况下,对来自不同内部步骤的梯度进行重新缩放。此分析仅为近似值,仅作为启发式方法。在实践中,完整的训练动态还取决于裁剪、KL 正则化以及流程步骤之间的相关性。
奖励模型
从 RM 输出到优势函数。奖励模型 (RM) 在轨迹层面运行,给定一个包含观测值和动作 τ(i) = {o^(i)_s, a^(i) ^_s,c} 的展开 i 以及任务文本 text_i,RM 会生成一个标量分数。
按照 GRPO 的方法,对一批 G 展开应用分组归一化R ̃_i 。将归一化分数 R ̃_i 广播到轨迹 i 内的所有块 (s, c),并用作优势。这些优势被引入到 FA-GRPO 和 FlowScale 目标函数中,以代替 GRPO 中的标量 Aˆ_t。
Prophet 训练设置
Prophet 模型基于 Cosmos-Predict2-2B-Video2World [2] 初始化,并增强历史-觉察机制和双重动作条件化。Prophet 模型以第一帧观测数据为条件,给定一个 20 步的动作块,生成接下来的 20 帧。动作帧构建参数设置为:l = 0.15,r_ref = 40,z_ref = 1.0,r_min = 8,r_max = 140。在所有数据集中,将机械臂信号归一化到 [g_min, g_max] = [0, 1] 区间,其中 0 表示完全闭合,1 表示完全打开。对于视频自编码器 E,采用 Wan2.1 视频自编码器 [62](Cosmos-Predict2 [2] 也使用该自编码器),它将视频的时空维度压缩为 4×8×8,得到大小分别为 H_l = H/8、W_l = W/8、T_l = 1+T/4 和 C_l = 16 的潜输入。对于Prophet 算法,参数总数为 20.58 亿,DiT 通道数 D_m = 1024。对于历史-觉察机制,设置 T_h = 60,即维护一个包含最近 60 帧的固定长度缓冲区作为历史潜输入。
用混合机器人操作数据集对 Prophet 模型进行预训练,这些数据集包括 AgiBot [10]、DROID [31]、LIBERO [41] 以及从 Open-X [50] 中筛选出的高质量子集,总共包含超过 3100 万条采样轨迹。由于并非所有 Open-X 子数据集都适用于设置(部分视频分辨率极低,部分机器人末端执行器性能较差,部分子集无法提供可靠的末端执行器姿态或夹爪状态),仅使用经过筛选的子集进行预训练。具体而言,选择 Austin Sailor [47]、DLR Wheelchair Shared Control [53, 60]、BC-Z [26]、CMU Stretch [3, 46]、Stanford HYDRA [5]、USC Jaco Play [15]、Furniture Bench [22]、NYU Franka Play [14] 和 RT-1 风格数据集 [8]。对于下游强化学习,在 BRIDGE [61]、LIBERO [41] 以及自行收集的真实机器人数据集上对 Prophet 模型进行微调,这些数据集均提供用于评估的仿真或真实机器人环境。
预训练和微调的数据严格分离。预训练时,在 64 个 H200 GPU 上训练所有模型参数,训练 2 个 epoch,每个 GPU 的批大小为 16,梯度累积为 4。微调时,在 8 个 H200 GPU 上应用 LoRA [23](排名 16),批大小为 24,运行步数取决于任务。两个阶段均使用融合 Adam 优化器,学习率为 1 × 10⁻⁴,权重衰减为 0.1。
在 Prophet 的预训练和微调过程中,保持数据集特定的输入分辨率。在 AgiBot [10] 和自定义的真实机器人数据集上,用 240 × 320 的分辨率;在 DROID [31] 上,用 240 × 416 的分辨率;在 LIBERO [41] 和 BRIDGE [61] 上,用 256 × 256 的分辨率。对于 Open-X 数据集,也将其标准化为 240 × 320:首先将高度调整为 240 像素,然后如果宽度小于 320 像素,则在左右两侧填充黑色边框;如果宽度大于 320 像素,则进行中心裁剪至 320 像素。由于预训练跨越多个数据源,而只有部分数据集提供构建动作帧所需的相机参数,因此批量采样器始终从单个数据集中抽取每个小批量数据。这避免分辨率和条件信号的冲突,并稳定多数据集预训练。
真实世界实验环境设置
用 UR30e 机械臂采集自定义操作数据集,从而提供一个物理评估环境,用于评估 Prophet 算法在真实世界的适应性以及强化学习算法的通用性。采集 4 个任务的 800 条轨迹。对于所有任务,固定摄像头、底层控制器和策略接口,仅根据预定义的桌面网格布局改变初始物体配置。对于每个策略-任务组合,进行三次评估运行,并报告所有试验中成功率的平均值和标准差。
为了使强化学习算法在真实机器人上稳定运行,用低维状态向量增强视觉输入。对于每次展开操作,策略接收第一帧 RGB 图像以及初始机器人状态(末端执行器位姿和夹爪状态)。动作头预测增量动作,通过对这些增量进行时间积分来更新后续动作输入的状态,而不是在每一步都查询机器人。因此,在所有真实世界的强化学习实验中,训练数据由单个初始图像和预测的增量动作所诱导的状态轨迹组成。
数据采集:这些任务的真实世界数据使用通过 GELLO [65] 界面远程操控的 UR30e 机械臂采集。固定的第三人称视角 Intel RealSense D455 RGB-D 相机提供视觉观测,其外参使用 EasyHandEye 工具包校准到机器人基座。在数据采集过程中,物体均匀放置在工作空间中以捕捉不同的初始配置,每次演示都包含从第一帧到任务完成的完整成功执行过程。采集四个任务的数据,分别是:抓取瓶子、放置立方体、拉出纸巾和放置碗。
监督式微调 (SFT) 策略和强化学习 (RL) 设置
评估三种不同规模的策略,即 VLA-Adapter-0.5B [63]、Pi0.5-3B [25] 和 OpenVLA-OFT-7B [32]。所有策略每步处理一张图像,并通过轻量级流动作头输出一个 7D delta 动作。在强化学习之前,对这些策略进行微调,使用 64 个批次大小、2.5e−5 的学习率和 AdamW 优化器,权重衰减为 0.1,微调 20 万步。对于真实机器人实验,使用相同的优化器,在四个任务(每个任务 200 条轨迹)上分别独立地对策略进行微调,每个任务的批次大小为 16,微调 5 万步。对于强化学习,设置 ngroup = 8,总批次大小为 256,小批次大小为 128,所有策略训练 100 步。所有与强化学习相关的实验均在 8 个 H200 GPU 上进行。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 9
9 0
0- 0



 已为社区贡献109条内容
已为社区贡献109条内容

所有评论(0)