Antipodal Robotic Grasping using Generative Residual Convolutional Neural Network 模型代码
·
一、论文中的网络模型结构
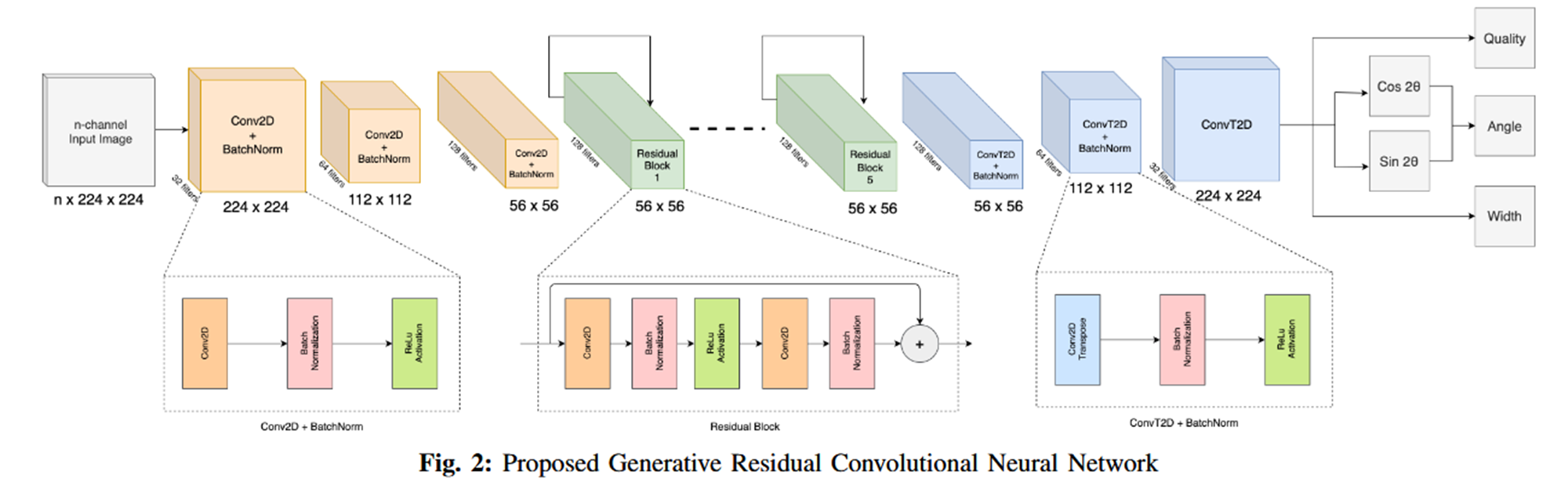
二、模型代码实现
1、grasp_model.py
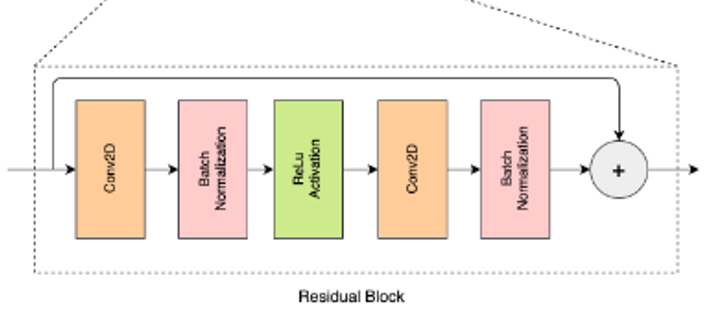
GraspModel:定义了抓取检测模型的通用框架,封装了损失计算、预测推理的标准接口,是所有具体抓取网络的父类。ResidualBlock:实现了带批量归一化的残差模块,用于构建深层网络,缓解梯度消失问题,提升模型训练稳定性。- 两者结合:
ResidualBlock作为基础组件堆叠成深层网络,GraspModel提供任务专属的损失和预测逻辑,共同构成抓取检测模型。
import torch.nn as nn
import torch.nn.functional as F
'''
这段代码基于 PyTorch 实现了机器人抓取任务(Grasp Detection)的两个核心网络组件:GraspModel
(抓取任务的抽象基础模型)和 ResidualBlock(带批量归一化的残差块),主要用于构建抓取预测网络(如 GR-ConvNet)
'''
class GraspModel(nn.Module):
"""
GraspModel 是一个抽象类(未实现 forward 方法,抛出 NotImplementedError),定义了机器人抓取任务模型的通用框架,
包含损失计算、预测推理的标准接口,所有具体的抓取网络(如 GR-ConvNet)都应继承该类并实现 forward 方法。
"""
def __init__(self):
super(GraspModel, self).__init__()
def forward(self, x_in):
# 必须由子类重写
raise NotImplementedError()
# 损失计算方法 compute_loss
# 该方法是抓取任务的核心损失函数实现,用于计算模型预测值与真实标注值之间的误差,指导模型训练
def compute_loss(self, xc, yc):
# 1. 拆分真实标注(yc)和模型预测结果(self(xc))
y_pos, y_cos, y_sin, y_width = yc
pos_pred, cos_pred, sin_pred, width_pred = self(xc)
p_loss = F.smooth_l1_loss(pos_pred, y_pos)
cos_loss = F.smooth_l1_loss(cos_pred, y_cos)
sin_loss = F.smooth_l1_loss(sin_pred, y_sin)
width_loss = F.smooth_l1_loss(width_pred, y_width)
return {
'loss': p_loss + cos_loss + sin_loss + width_loss,
'losses': {
'p_loss': p_loss,
'cos_loss': cos_loss,
'sin_loss': sin_loss,
'width_loss': width_loss
},
'pred': {
'pos': pos_pred,
'cos': cos_pred,
'sin': sin_pred,
'width': width_pred
}
}
def predict(self, xc):
pos_pred, cos_pred, sin_pred, width_pred = self(xc)
return {
'pos': pos_pred,
'cos': cos_pred,
'sin': sin_pred,
'width': width_pred
}
'''
ResidualBlock 是底层的可复用残差模块,用于构建深层网络时缓解梯度消失问题。
'''
class ResidualBlock(nn.Module):
"""
A residual block with dropout option
"""
def __init__(self, in_channels, out_channels, kernel_size=3):
super(ResidualBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size, padding=1)
self.bn1 = nn.BatchNorm2d(in_channels)
self.conv2 = nn.Conv2d(in_channels, out_channels, kernel_size, padding=1)
self.bn2 = nn.BatchNorm2d(in_channels)
def forward(self, x_in):
x = self.bn1(self.conv1(x_in)) # 卷积1 → 批量归一化
x = F.relu(x) # ReLU 激活
x = self.bn2(self.conv2(x)) # 卷积2 → 批量归一化
return x + x_in # 残差连接:输出 = 卷积结果 + 输入这里的ResidualBlock模块对应那5个残差块。
2、grconvnet.py
import torch.nn as nn
import torch.nn.functional as F
from inference.models.grasp_model import GraspModel, ResidualBlock
class GenerativeResnet(GraspModel):
def __init__(self, input_channels=1, dropout=False, prob=0.0, channel_size=32):
super(GenerativeResnet, self).__init__()
# (1)下采样编码器
self.conv1 = nn.Conv2d(input_channels, 32, kernel_size=9, stride=1, padding=4)
self.bn1 = nn.BatchNorm2d(32)
self.conv2 = nn.Conv2d(32, 64, kernel_size=4, stride=2, padding=1)
self.bn2 = nn.BatchNorm2d(64)
self.conv3 = nn.Conv2d(64, 128, kernel_size=4, stride=2, padding=1)
self.bn3 = nn.BatchNorm2d(128)
# (2)残差瓶颈层
self.res1 = ResidualBlock(128, 128)
self.res2 = ResidualBlock(128, 128)
self.res3 = ResidualBlock(128, 128)
self.res4 = ResidualBlock(128, 128)
self.res5 = ResidualBlock(128, 128)
# (3)上采样解码器
self.conv4 = nn.ConvTranspose2d(128, 64, kernel_size=4, stride=2, padding=1, output_padding=1)
self.bn4 = nn.BatchNorm2d(64)
self.conv5 = nn.ConvTranspose2d(64, 32, kernel_size=4, stride=2, padding=2, output_padding=1)
self.bn5 = nn.BatchNorm2d(32)
self.conv6 = nn.ConvTranspose2d(32, 32, kernel_size=9, stride=1, padding=4)
# (4)多分支输出层
self.pos_output = nn.Conv2d(32, 1, kernel_size=2)
self.cos_output = nn.Conv2d(32, 1, kernel_size=2)
self.sin_output = nn.Conv2d(32, 1, kernel_size=2)
self.width_output = nn.Conv2d(32, 1, kernel_size=2)
# (5)Dropout 与权重初始化
self.dropout1 = nn.Dropout(p=prob)
for m in self.modules():
if isinstance(m, (nn.Conv2d, nn.ConvTranspose2d)):
nn.init.xavier_uniform_(m.weight, gain=1)
def forward(self, x_in):
x = F.relu(self.bn1(self.conv1(x_in)))
x = F.relu(self.bn2(self.conv2(x)))
x = F.relu(self.bn3(self.conv3(x)))
x = self.res1(x)
x = self.res2(x)
x = self.res3(x)
x = self.res4(x)
x = self.res5(x)
x = F.relu(self.bn4(self.conv4(x)))
x = F.relu(self.bn5(self.conv5(x)))
x = self.conv6(x)
pos_output = self.pos_output(self.dropout1(x))
cos_output = self.cos_output(self.dropout1(x))
sin_output = self.sin_output(self.dropout1(x))
width_output = self.width_output(self.dropout1(x))
return pos_output, cos_output, sin_output, width_output
代码解析:
这是一个基于 PyTorch 实现的 生成式残差卷积神经网络(Generative Residual CNN),专为机器人抓取检测任务设计,属于 GraspModel 的具体实现。它采用经典的 U 型残差网络结构,可以从单通道 / 多通道图像中预测出像素级的抓取姿态(位置、角度、宽度)。
模型整体架构
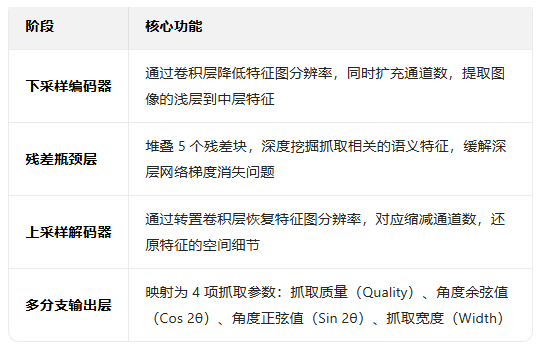
该模型遵循 “下采样编码器 → 残差瓶颈层 → 上采样解码器 → 多分支输出” 的 U 型对称结构,兼顾深层特征提取和空间细节还原。
逐部分解析:
(1)下采样编码器
self.conv1 = nn.Conv2d(input_channels, 32, kernel_size=9, stride=1, padding=4)
self.bn1 = nn.BatchNorm2d(32)
self.conv2 = nn.Conv2d(32, 64, kernel_size=4, stride=2, padding=1)
self.bn2 = nn.BatchNorm2d(64)
self.conv3 = nn.Conv2d(64, 128, kernel_size=4, stride=2, padding=1)
self.bn3 = nn.BatchNorm2d(128)conv1:输入通道 → 32 通道,9×9 卷积核,padding=4保证分辨率不变(224×224 → 224×224)conv2:32 通道 → 64 通道,4×4 卷积核,stride=2使分辨率减半(224×224 → 112×112)conv3:64 通道 → 128 通道,4×4 卷积核,stride=2使分辨率再减半(112×112 → 56×56)- 核心作用:通过逐步下采样,扩大感受野,提取图像的深层语义特征。
(2)残差瓶颈层
self.res1 = ResidualBlock(128, 128)
self.res2 = ResidualBlock(128, 128)
self.res3 = ResidualBlock(128, 128)
self.res4 = ResidualBlock(128, 128)
self.res5 = ResidualBlock(128, 128)- 堆叠 5 个残差块,保持通道数(128)和分辨率(56×56)不变
- 核心作用:通过残差连接缓解深层网络的梯度消失问题,深度挖掘抓取相关的语义特征,同时保留原始特征信息。
(3)上采样解码器
self.conv4 = nn.ConvTranspose2d(128, 64, kernel_size=4, stride=2, padding=1, output_padding=1)
self.bn4 = nn.BatchNorm2d(64)
self.conv5 = nn.ConvTranspose2d(64, 32, kernel_size=4, stride=2, padding=2, output_padding=1)
self.bn5 = nn.BatchNorm2d(32)
self.conv6 = nn.ConvTranspose2d(32, 32, kernel_size=9, stride=1, padding=4)conv4:128 通道 → 64 通道,4×4 转置卷积,stride=2使分辨率翻倍(56×56 → 112×112)conv5:64 通道 → 32 通道,4×4 转置卷积,stride=2使分辨率再翻倍(112×112 → 224×224)conv6:32 通道 → 32 通道,9×9 转置卷积,padding=4保持分辨率不变,用于细化特征- 核心作用:通过转置卷积逐步恢复特征图的空间分辨率,还原抓取姿态的位置细节。
(4)多分支输出层
self.pos_output = nn.Conv2d(32, 1, kernel_size=2)
self.cos_output = nn.Conv2d(32, 1, kernel_size=2)
self.sin_output = nn.Conv2d(32, 1, kernel_size=2)
self.width_output = nn.Conv2d(32, 1, kernel_size=2)- 4 个独立的 2×2 卷积层,将 32 通道特征图映射为 4 个单通道输出
pos_output:抓取质量图(每个像素的抓取置信度)cos_output/sin_output:抓取角度的余弦 / 正弦值(避免角度周期性问题)width_output:机械爪开合宽度图- 核心作用:将解码器输出的特征映射为机器人抓取所需的 4 项核心参数。
(5)Dropout 与权重初始化
self.dropout1 = nn.Dropout(p=prob)
for m in self.modules():
if isinstance(m, (nn.Conv2d, nn.ConvTranspose2d)):
nn.init.xavier_uniform_(m.weight, gain=1)dropout1:可选的 Dropout 层,用于防止过拟合(训练时生效,推理时关闭)- Xavier 初始化:保持前向传播和反向传播的方差一致,避免梯度消失 / 爆炸,提升训练稳定性。
前向传播 forward
定义了数据在网络中的完整流动路径。
def forward(self, x_in):
# 下采样编码器
x = F.relu(self.bn1(self.conv1(x_in)))
x = F.relu(self.bn2(self.conv2(x)))
x = F.relu(self.bn3(self.conv3(x)))
# 残差瓶颈层
x = self.res1(x)
x = self.res2(x)
x = self.res3(x)
x = self.res4(x)
x = self.res5(x)
# 上采样解码器
x = F.relu(self.bn4(self.conv4(x)))
x = F.relu(self.bn5(self.conv5(x)))
x = self.conv6(x)
# 多分支输出
pos_output = self.pos_output(self.dropout1(x))
cos_output = self.cos_output(self.dropout1(x))
sin_output = self.sin_output(self.dropout1(x))
width_output = self.width_output(self.dropout1(x))
return pos_output, cos_output, sin_output, width_output- 数据流动规律:
- 分辨率:
224×224 → 112×112 → 56×56 → 56×56 → 112×112 → 224×224 → 223×223 - 通道数:
input_channels → 32 → 64 → 128 → 128 → 64 → 32 → 32 → 1
- 分辨率:
- 激活函数:采用
ReLU激活,在编码器和解码器的卷积层后引入非线性变换,提升模型表达能力。 - Dropout 策略:在输出层前统一使用一个 Dropout 层,对所有输出分支进行正则化,防止过拟合。
核心亮点
- U 型残差结构:兼顾深层特征提取和空间细节还原,适合像素级回归任务(抓取姿态预测)。
- 多分支输出设计:直接输出抓取质量、角度、宽度 4 项核心参数,无需额外后处理即可用于机器人控制。
- 角度表示技巧:用
cos和sin同时表示角度,避免角度的周期性问题,提升角度回归的稳定性。 - 工程化优化:Xavier 权重初始化、批量归一化、Dropout 正则化,保证模型训练的稳定性和泛化能力。
适用场景
- 机器人视觉抓取:从 RGB / 深度图像中预测最优抓取姿态,为机械臂提供精准的抓取指令。
- 像素级回归任务:如语义分割、密度图预测等,可借鉴该模型的 U 型残差结构和多分支输出设计。
- 嵌入式设备部署:模型结构简洁,参数量适中,可通过轻量化改造适配 Jetson Nano 等嵌入式设备。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)