RAG技术全面解析:解决大模型幻觉、知识滞后与私有知识难题!
本文详细解析了RAG(检索增强生成)技术,解释了它如何解决大模型的三大短板:幻觉、知识滞后和缺乏私有知识。文章拆解了RAG的四个工作流程步骤(数据准备、检索、增强、生成)和四大核心组件(Langchain文本分割、向量数据库、Embedding模型、LLM)。RAG通过"外部知识检索+大模型逻辑推理"的组合模式,使大模型从聊天机器人进化为专业助手,是企业知识库和AI搜索的底层技术。
RAG (Retrieval-Augmented Generation,检索增强生成)是目前大模型(LLM)落地应用中最核心、最热门的技术方案之一。简单来说,RAG 就是给大模型配上了一个“外部知识库”或“搜索引擎”。
接下来我会从我们“为什么需要它”、“它是怎么工作的”以及“它的优势”三个维度来详细拆解。
一、 为什么要用 RAG?
虽然 GPT-4、Claude 等大模型很强大,但它们有三个致命的短板:
-
幻觉问题 (Hallucination):大模型本质上是概率预测机器,当它不知道答案时,会一本正经地胡说八道。
-
知识滞后 (Knowledge Cutoff):大模型的知识停留在训练结束的那一刻。比如你问它“今天早上的新闻”,它无法回答。
-
缺乏私有知识:大模型没读过你公司的内部文档、你的私人笔记或未公开的代码库。
解决办法有两种:
微调 (Fine-tuning):像让学生去考研深造,这样的做法代价高、更新慢。
RAG (检索增强):像给学生考试时发一本《开卷参考资料》,让他查完资料再回答。
二、 RAG 的工作流程(四个核心步骤)
- 数据准备 (Indexing)
在用户提问之前,我们要先处理数据:
清洗与切块 (Chunking):把长文档(如PDF、Word)切成一个个小段落(比如每段300字)。
向量化 (Embedding):利用“嵌入模型”把文字转成一串数字(向量)。这些数字代表了文字的语义。
存入向量数据库:把这些数字存在专门的数据库(如 Pinecone, Milvus, FAISS)中。
- 检索 (Retrieval)
当用户提一个问题(比如:“我公司的报销标准是什么?”):
* 系统先把这个问题也转成一串数字(向量)。
* 在向量数据库中进行“语义匹配”,找到与这个问题最相关的几个段落。
- 增强 (Augmentation)
系统把“用户的问题”和“搜到的相关段落”拼在一起,组成一个巨大的提示词(Prompt)。
提示词模板:
“你是一个助手。请根据以下参考资料回答问题:
【参考资料:公司报销标准是单日餐补50元…】
【用户问题:我公司的报销标准是什么?】”
- 生成 (Generation) —— 写出回答
大模型读完这段带资料的 Prompt 后,总结出准确的答案。因为它看到了资料,所以不再胡说八道。
三、 RAG 的核心组件
- Langchain智能文本分割工具: RecursiveCharacterTextSplitter 是 LangChain 中最常用的文本分割器,核心逻辑是递归地按指定分隔符拆分文本,直到所有分片长度都符合设定的 chunk_size。
它的核心工作流程和特点如下:
-
预设分隔符优先级:默认按 [“\n\n”, “\n”, " ", “”] 的顺序尝试拆分,优先用双换行符(段落分隔),再用单换行符(行分隔),以此类推,保证拆分后的文本语义更完整。
-
递归拆分逻辑:如果用当前分隔符拆分后的文本块长度仍超过 chunk_size,就用下一级优先级的分隔符继续拆分,直到所有文本块都满足长度要求。
-
支持重叠窗口:通过 chunk_overlap 参数设置分片间的重叠长度,避免因拆分导致上下文断裂,提升后续向量检索的准确性。
举个例子:拆分一篇 2000 字符的财报文本,设定 chunk_size=500、chunk_overlap=50,它会先按双换行符拆成几个大段,若某段有 600 字符,就再按单换行符拆成 500+100 两部分,最后把 100 字符的片段和下一段拼接,保证重叠 50 字符。
2.向量数据库 (Vector DB):RAG 的大脑,存储语义信息。我们最常用的工具是Milvus,它是专为海量向量数据的高效存储、索引与相似度检索设计的工具,是AI应用中实现非结构化数据(文本、图像、音频等)语义匹配的核心组件。
四、核心原理
-
向量输入:将非结构化数据通过模型(如BERT、CLIP)转为固定维度的稠密向量。
-
索引优化:提供FLAT(暴力检索)、IVF(倒排索引)、HNSW(图索引)等多种索引算法,在检索速度与精度间做平衡。
-
相似度查询:支持欧氏距离、余弦相似度等多种度量方式,快速召回与目标向量最相似的结果集。
五、核心优势
-
高性能:支持万亿级向量的毫秒级查询,单节点可处理百万级向量,分布式部署可线性扩容。
-
云原生架构:存储与计算分离,组件无状态,适配Kubernetes,支持弹性伸缩与高可用部署。
-
混合查询能力:支持向量相似度 + 标量过滤(如时间、标签、权限),满足复杂业务的多条件检索需求。
-
生态友好提供Python/Java/Go等多语言SDK,无缝集成LangChain、Hugging Face等主流AI框架。
-
Embedding 模型:翻译官,把人类语言转成机器理解的数学向量。Embedding(嵌入) 是将离散、高维的对象(如文本、图像、音频)映射为低维、稠密的实数向量的过程,这些向量能保留原始对象的语义或特征关联,是连接非结构化数据与机器学习/AI模型的核心桥梁。详细的Word embedding讲解请翻阅本公众号之前的文章。
核心特点与价值
-
降维与稠密化:把原本高维稀疏的表示(比如文本的one-hot编码)压缩成低维稠密向量,大幅降低计算成本。
-
语义保留:语义相似的对象,对应的Embedding向量在空间中的距离也更近。例如“猫咪”和“小猫”的向量距离,会远小于“猫咪”和“汽车”。
-
跨模态兼容:通过特定模型(如CLIP),可以将文本和图像映射到同一向量空间,实现“以文搜图”“以图搜文”。
常见生成方式
• 文本Embedding:用预训练模型(如BERT、Sentence-BERT、text-embedding-ada-002)直接生成句子/段落的向量。
• 图像Embedding:用CNN模型(如ResNet)或多模态模型(如CLIP)提取图像特征向量。
• 自监督训练:通过对比学习等方式,让模型自主学习到更具区分度的Embedding。
举个简单的例子:
假设我们用一个 3维向量 来表示句子的 embedding,向量的三个维度分别代表「动物属性」「体型大小」「情感倾向」,数值越接近 1 表示特征越明显:
• 句子1:柯基是可爱的小型犬 → embedding 向量:[0.95, 0.3, 0.9]
• 句子2:小短腿柯基很讨人喜欢 → embedding 向量:[0.92, 0.28, 0.91]
• 句子3:金毛是大型犬 → embedding 向量:[0.9, 0.85, 0.6]
• 句子4:今天天气很好 → embedding 向量:[0.05, 0.1, 0.7]
embedding之后我们就计算不同语句之间的余弦相似度:
• 句子1和句子2的相似度 接近 0.98(语义几乎一致)
• 句子1和句子3的相似度 约 0.7(同属犬类但体型不同)
• 句子1和句子4的相似度 仅 0.1(完全无关)
这就是 embedding 的核心作用:把文字的语义转化为可计算的向量,语义越近,向量距离越近。
- LLM (大模型):发声器官,负责阅读、理解并组织语言。LLM 是 Large Language Model(大语言模型) 的缩写,指基于海量文本数据训练、具备理解和生成人类语言能力的深度学习模型。
它的核心逻辑和特点如下:
-
核心原理:基于Transformer架构,通过自监督学习(如预测下一个词)从海量语料中学习语言规律、知识和逻辑,能实现上下文理解和连贯文本生成。
-
核心能力:覆盖文本生成、翻译、摘要、问答、代码编写等多种任务,无需针对单一任务重新训练(即零样本/少样本学习)。
-
典型代表:通用类有GPT系列、Claude、文心一言、通义千问;开源类有Llama、Falcon、ChatGLM等。
-
局限性:存在幻觉(生成错误信息)、上下文长度限制、对复杂逻辑推理支持有限等问题,常需结合外部知识库或工具(如LangChain+Milvus)弥补短板。
六、 总结
RAG 是大模型从“聊天机器人”进化为“专业助手”的必经之路。
它通过“外部知识检索 + 大模型逻辑推理”**的组合模式,有效解决了大模型实时性差、专业领域知识匮乏、容易胡言乱语的难题。目前市面上的企业知识库、AI 搜索(如 Perplexity, 秘塔搜索)底层全都是 RAG 技术。
最后唠两句
为什么AI大模型成为越来越多程序员转行就业、升职加薪的首选
很简单,这些岗位缺人且高薪
智联招聘的最新数据给出了最直观的印证:2025年2月,AI领域求职人数同比增幅突破200% ,远超其他行业平均水平;整个人工智能行业的求职增速达到33.4%,位居各行业榜首,其中人工智能工程师岗位的求职热度更是飙升69.6%。
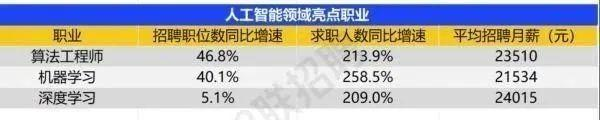
AI产业的快速扩张,也让人才供需矛盾愈发突出。麦肯锡报告明确预测,到2030年中国AI专业人才需求将达600万人,人才缺口可能高达400万人,这一缺口不仅存在于核心技术领域,更蔓延至产业应用的各个环节。
那0基础普通人如何学习大模型 ?
深耕科技一线十二载,亲历技术浪潮变迁。我见证那些率先拥抱AI的同行,如何建立起效率与薪资的代际优势。如今,我将积累的大模型面试真题、独家资料、技术报告与实战路线系统整理,分享于此,为你扫清学习困惑,共赴AI时代新程。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
-
✅从入门到精通的全套视频教程
-
✅AI大模型学习路线图(0基础到项目实战仅需90天)
-
✅大模型书籍与技术文档PDF
-
✅各大厂大模型面试题目详解
-
✅640套AI大模型报告合集
-
✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线

③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 6
6 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)