VLM4VLA: REVISITING VISION-LANGUAGE-MODELS IN VISION-LANGUAGE-ACTION MODELS
视觉语言动作模型将预训练的大型视觉语言模型集成到其策略主干中,因其展现出有前景的泛化能力而受到广泛关注。本文重新审视了一个基础但鲜有系统研究的问题:视觉语言模型的选择和能力如何影响下游视觉语言动作策略的性能?我们提出了VLM4VLA,一个极简的适配流程,它仅使用一小部分新的可学习参数将通用视觉语言模型转换为视觉语言动作策略,以实现公平高效的比较。尽管设计简单,VLM4VLA在与更复杂的网络设计对比
第001/23页(英文原文)
VLM4VLA: REVISITING VISION-LANGUAGE-MODELS IN VISION-LANGUAGE-ACTION MODELS
Jianke Zhang 1^{1}1 , Xiaoyu Chen 1^{1}1 , Qiuyue Wang 2^{2}2 , Mingsheng Li 2^{2}2 , Yanjiang Guo 1^{1}1 , Yucheng Hu 1^{1}1 , Jiajun Zhang 2^{2}2 , Shuai Bai 2^{2}2 , Junyang Lin 2^{2}2 , Jianyu Chen 1^{1}1
1 Institute for Interdisciplinary Information Sciences, Tsinghua University
Qwen Team, Alibaba Inc.
ABSTRACT
Vision-Language-Action (VLA) models, which integrate pretrained large Vision-Language Models (VLMs) into their policy backbone, are gaining significant attention for their promising generalization capabilities. This paper revisits a fundamental yet seldom systematically studied question: how VLM choice and competence translate to downstream VLA policies performance? We introduce VLM4VLA, a minimal adaptation pipeline that converts general-purpose VLMs into VLA policies using only a small set of new learnable parameters for fair and efficient comparison. Despite its simplicity, VLM4VLA proves surprisingly competitive with more sophisticated network designs. Through extensive empirical studies on various downstream tasks across three benchmarks, we find that while VLM initialization offers a consistent benefit over training from scratch, a VLM’s general capabilities are poor predictors of its downstream task performance. This challenges common assumptions, indicating that standard VLM competence is necessary but insufficient for effective embodied control. We further investigate the impact of specific embodied capabilities by fine-tuning VLMs on seven auxiliary embodied tasks (e.g., embodied QA, visual pointing, depth estimation). Contrary to intuition, improving a VLM’s performance on specific embodied skills does not guarantee better downstream control performance. Finally, modality-level ablations identify the visual module in VLM, rather than the language component, as the primary performance bottleneck. We demonstrate that injecting control-relevant supervision into the vision encoder of the VLM yields consistent gains, even when the encoder remains frozen during downstream fine-tuning. This isolates a persistent domain gap between current VLM pretraining objectives and the requirements of embodied action-planning.
1 INTRODUCTION
Vision-Language-Action (VLA) models (Brohan et al., 2023) have recently emerged as a central research focus, as they leverage the extensive visual-language knowledge from Vision-Language Models (VLMs) as a prior for enhancing the generalization of robotic strategies (Kim et al., 2024; Black et al., 2024; Zhang et al., 2024; Chen et al., 2025c). The majority of existing VLA methods have focused on developing more advanced network architectures (Li et al., 2023; Shi et al., 2025), incorporating additional training paradigms or modalities (Zheng et al., 2024; Chen et al., 2024; Zhang et al., 2025a), and refining action decoding schemes (Zhao et al., 2023; Pertsch et al., 2025; Wen et al., 2025). However, limited attention (Liu et al., 2025) has been given to a fundamental question at the core of VLA: how do the choice and specific capabilities of the underlying VLM affect the performance of VLA policies?
In this paper, we revisit this crucial problem. To provide a fair and clean test interface that evaluates the capabilities of VLMs without introducing extraneous variables, we first build the generic VLM4VLA pipeline to convert general-purpose VLMs into VLAs, as shown in Figure 2. VLM4VLA is a carefully designed network plug-in, introducing fewer than 1%1\%1% new parameters. To enhance the stability of inference and the robustness of evaluation, we use a simple MLP head with L1/L2 loss rather than a diffusion-based (flow-matching) approach, thus controlling stochasticity and reducing
第001/23页(中文翻译)
VLM4VLA: 重新审视视觉语言动作模型中的视觉语言模型
张健科1, 陈晓宇1, 王秋月2, 李明生2, 郭炎江1, 胡玉成1, 张家俊2, 白帅2, 林俊旸2, 陈健宇11 清华大学交叉信息研究院2, Qwen团队,阿里巴巴集团
摘要
视觉语言动作模型将预训练的大型视觉语言模型集成到其策略主干中,因其展现出有前景的泛化能力而受到广泛关注。本文重新审视了一个基础但鲜有系统研究的问题:视觉语言模型的选择和能力如何影响下游视觉语言动作策略的性能?我们提出了VLM4VLA,一个极简的适配流程,它仅使用一小部分新的可学习参数将通用视觉语言模型转换为视觉语言动作策略,以实现公平高效的比较。尽管设计简单,VLM4VLA在与更复杂的网络设计对比中展现出惊人的竞争力。通过在三个基准测试的多种下游任务上进行广泛的实证研究,我们发现,虽然视觉语言模型初始化相比从头训练能带来一致的优势,但视觉语言模型的通用能力是其下游任务性能的较差预测指标。这挑战了常见的假设,表明标准的视觉语言模型能力对于有效的具身控制是必要但不充分的。我们进一步研究了特定具身能力的影响,方法是在七个辅助具身任务(例如,具身问答、视觉指向、深度估计)上微调视觉语言模型。与直觉相反,提升视觉语言模型在特定具身技能上的表现并不能保证获得更好的下游控制性能。最后,模态级别的消融实验表明,视觉语言模型中的视觉模块,而非语言组件,是主要的性能瓶颈。我们证明,即使编码器在下游微调期间保持冻结,将控制相关的监督信息注入视觉语言模型的视觉编码器中也能带来一致的性能提升。这揭示了当前视觉语言模型预训练目标与具身动作规划需求之间存在一个持续的领域差距。
1引言
视觉-语言-动作(VLA)模型(Brohan等,2023)最近已成为一个核心研究焦点,因为它们利用来自视觉语言模型(VLMs)的广泛视觉语言知识作为先验,以增强机器人策略的泛化能力(Kim等,2024;Black等,2024;Zhang等,2024;Chen等,2025c)。现有的大多数VLA方法都集中在开发更先进的网络架构(Li等,2023;Shi等,2025)、整合额外的训练范式或模态(Zheng等,2024;Chen等,2024;Zhang等,2025a)以及改进动作解码方案(Zhao等,2023;Pertsch等,2025;Wen等,2025)。然而,对于VLA核心的一个基本问题,即底层VLM的选择及其具体能力如何影响VLA策略的性能,关注却相对有限(Liu等,2025)。
在本文中,我们重新审视这一关键问题。为了提供一个公平且干净的测验接口,在不引入额外变量的情况下评估视觉语言模型的能力,我们首先构建了通用的VLM4VLA流程,将通用视觉语言模型转换为视觉语言动作模型,如图2所示。VLM4VLA是一个精心设计的网络插件,引入的新参数少于 1%1\%1% 。为了增强推理的稳定性和评估的鲁棒性,我们使用了一个简单的带L1/L2损失的多层感知机头,而非基于扩散(流匹配)的方法,从而控制随机性并降低
第002/23页(英文原文)
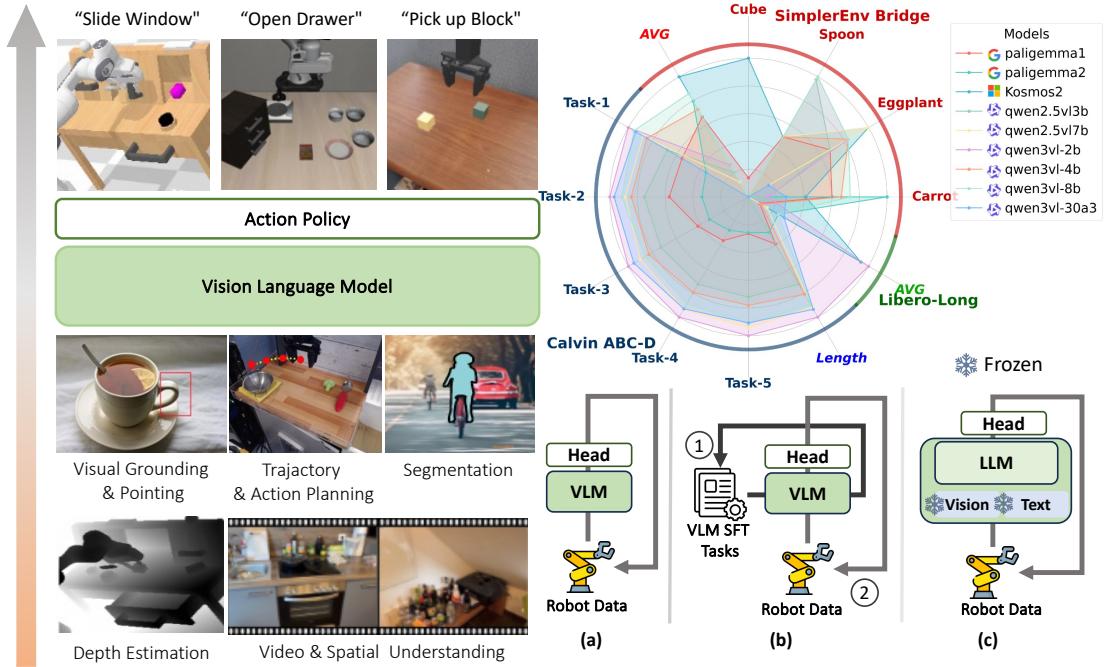
Figure 1: An overview of our VLM4VLA framework. (Left) The evaluation pipeline for testing different VLM backbones, which are evaluated on downstream tasks after an optional fine-tuning stage on auxiliary embodied tasks. (Bottom Right) We systematically investigate three factors influencing VLM-to-VLA transfer: the choice of VLM backbone, the impact of fine-tuning on auxiliary embodied tasks, and the influence of different training strategies (frozen vs. fine-tuned different VLM modules, training from scratch). (Top Right) A visualization of inconsistent performance of various VLM backbones across downstream tasks.
tuning complexity. This network allows us to train the modified VLMs directly using downstream robot data, facilitating alignment between the VLM’s capabilities and the demands of robotic tasks. Despite its simplicity, VLM4VLA proves effective, demonstrating competitive performance against more advanced network designs, such as the flow-matching action expert (Black et al., 2024), on benchmark tests. This provides a solid foundation for conducting fair and scalable experiments across various VLMs, aligning their capabilities with the demands of embodied tasks.
Based on the VLM4VLA pipeline, we conduct a large-scale empirical study across various downstream tasks on three commonly used benchmarks, evaluating 24 different VLMs that are either zero-shot or fine-tuned. Specifically, we investigate the VLM capabilities across three dimensions:
- General capability. We first quantify the benefit of VLM pretraining by comparing VLM-initialized policies against each other and training-from-scratch baselines. We then examine whether a VLM’s general-purpose strength (as measured by standard VLM evaluations) predicts its downstream embodied control performance.
- Embodied-specific capability. Recent works have sought to enhance VLAs by improving the VLM backbone on a series of VLM tasks. We examine how the embodied-specific capabilities of VLMs correlate with performance on downstream control tasks.
- Modality-level Analysis. Finally, we disentangle the contributions of each modality by independently ablating the vision and language encoders. We compare freezing versus fine-tuning each module to assess whether further aligning pretrained representations with control-relevant information improves downstream VLA performance.
For general capability, we select nine open-sourced VLMs as the backbone. As shown in Figure 1 (a), we apply the VLM4VLA pipeline directly to these VLMs together with the training from scratch baselines and fine-tune them with robot data. For embodied-specific capability, we collect seven commonly used embodied tasks or pretrained models based on the Qwen2.5-VL (Bai et al., 2025b) backbone to conduct ablation studies. As shown in Figure 1 (b), we either fine-tune the
第002/23页(中文翻译)
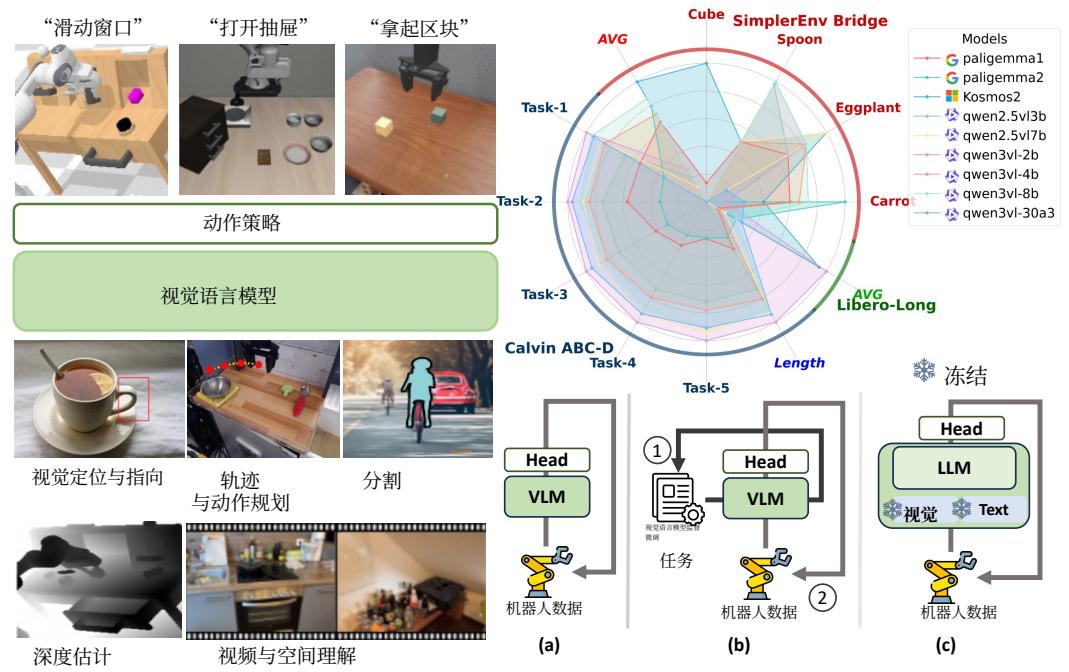
图1:我们的VLM4VLA框架概览。(左)用于测验不同VLM主干网络的评估流水线,这些主干网络在辅助具身任务上进行可选微调后,于下游任务进行评估。(右下)我们系统性地研究了影响VLM到VLA迁移的三个因素:VLM主干网络的选择、在辅助具身任务上微调的影响,以及不同训练策略(冻结与微调不同VLM模块、从头训练)的作用。(右上)展示了各种VLM主干网络在不同下游任务中表现不一致的可视化结果。
调优复杂度。该网络使我们能够直接使用下游机器人数据训练修改后的视觉语言模型,促进视觉语言模型能力与机器人任务需求之间的对齐。尽管结构简单,VLM4VLA被证明是有效的,在基准测试中展现出与更先进的网络设计(如流匹配动作专家(Black等,2024))相竞争的性能。这为在各种视觉语言模型之间进行公平且可扩展的实验提供了坚实基础,使其能力与具身任务的需求对齐。
基于VLM4VLA流水线,我们在三个常用基准测试的各类下游任务上进行了大规模实证研究,评估了24种不同的视觉语言模型,这些模型采用零样本或微调方式。具体而言,我们从三个维度探究了VLM的能力:
- 通用能力。我们首先通过比较VLM初始化的策略与从头训练的基线,量化了视觉语言模型预训练的收益。接着,我们检验了VLM的通用能力强度(通过标准VLM评估衡量)是否能预测其下游具身控制性能。
- 具身智能专用能力。近期研究试图通过在一系列VLM任务上改进VLM主干网络来增强视觉语言动作模型。我们探讨了视觉语言模型的具身智能专用能力如何与下游控制任务的性能相关联。
- 模态层面分析。最后,我们通过独立消融视觉和语言编码器,解耦了每种模态的贡献。我们比较了冻结与微调每个模块的情况,以评估将预训练表征进一步与任务控制相关信息对齐是否能提升下游视觉语言动作模型性能。
在通用能力方面,我们选择了九个开源视觉语言模型作为骨干。如图1(a)所示,我们直接将VLM4VLA流水线应用于这些视觉语言模型,并与从头开始训练的基线模型一起,使用机器人数据进行微调。在具身特定能力方面,我们基于Qwen2.5-VL(Bai等,2025b)骨干网络,收集了七个常用的具身任务或预训练模型来进行消融研究。如图1(b)所示,我们或者
第003/23页(英文原文)
VLM using auxiliary datasets or directly use the released fine-tuned models. We then apply the VLM4VLA pipeline to adapt these models to the embodied policies. Lastly, we conduct modality-level ablations to disentangle the contributions of vision and language components (Figure 1 ©). This involves selectively freezing or fine-tuning the vision and text encoders. Furthermore, we investigate the efficacy of injecting control-specific knowledge directly into the vision encoder via the FAST tokenizer (Pertsch et al., 2025). We evaluate the fine-tuned models on a range of tasks across three benchmarks including Calvin (Mees et al., 2022), SimplerEnv (Li et al., 2024), and Libero (Liu et al., 2023) to assess their embodied capabilities.
To our suprise, our findings reveal that while VLM initialization offers a consistent benefit over training from scratch, a VLM’s general capabilities are poor predictors of its downstream task performance, contrary to common assumptions. For instance, we observe that Kosmos (Peng et al., 2023) outperforms Qwen2.5-VL (Bai et al., 2025b) and Paligemma (Steiner et al., 2024) in certain environments. Inconsistencies across benchmarks suggest that VLA policies require capabilities beyond those currently pursued by VLMs. Furthermore, the gains by fine-tuning VLMs on specific auxiliary embodied tasks do not transfer to the downstream control tasks. Lastly, our modality-level analysis identifies the vision encoder, rather than the language component, as the primary performance bottleneck. We find that fine-tuning the vision encoder is essential for strong control performance, whereas the language encoder is less critical. The significant performance gains observed after injecting action-relevant information into the vision modules within the VLM confirm the existence of a critical domain gap between standard VLM pretraining and the visual representation requirements of embodied tasks.
Taken together, these results indicate a significant gap between current VLM research and the practical demands of VLA models. We believe this work highlights the fundamental question of the VLM’s role in embodied agents and can help guide future exploration in this area.
2 RELATED WORKS
Vision-Language-Action Models Recent works are increasingly focusing on introducing Vision-Language-Models (VLMs) (Dai et al., 2024; Touvron et al., 2023; Wang et al., 2025a; Bai et al., 2025b) into robot policies to enhance their generalization capabilities (Brohan et al., 2023; Guo et al., 2025; Hu et al., 2024; Guo et al., 2024), which are known as Vision-Language-Action (VLA) models. Early methods like RT-2 (Brohan et al., 2023) and OpenVLA (Kim et al., 2024) discretized actions into language tokens, enabling action learning through the VLM’s autoregressive framework. Subsequent works have utilized policy heads to decode continuous actions, gradually evolving the VLA design into a hierarchical structure that combines a VLM with a policy head (Black et al., 2024; Zhang et al., 2024; Cui et al., 2025). However, most prior works focused on constructing complex policy networks, while overlooking the impact of the VLM backbone itself on the overall VLA performance. Though RoboVLMs (Liu et al., 2025) compared the influence of a few early VLM backbones, it did not ensure consistency in its implementations. In contrast, we design a fairer experimental framework to comprehensively test the impact of various advanced VLMs across multiple environments. By employing the simplest and a consistent additional action policy, we minimize the influence of the policy head component on the experimental results.
Embodied Tasks for VLM Many prior works have explored introducing embodiment-related tasks into Vision-Language Models to enhance their spatial understanding (Yang et al., 2025; Feng, 2025) and task execution capabilities (Intelligence et al., 2025; Zhou et al., 2025b). These tasks include dense prediction (Wang et al., 2025b; Zhang et al., 2025b) and autoregressive VQA tasks (Rana et al., 2023; Yuan et al., 2024; Sermanet et al., 2024). Recently, inspired by the hierarchical System 1 and System 2 design paradigm (Zhang et al., 2024; Shentu et al., 2024), much research focused on using VLMs to build a general-purpose “robot brain”—a large language model capable of planning or completing real-world tasks via language. For instance, Robo2v1m (Chen et al., 2025b) annotated datasets like Open-X for VQA tasks, while Robobrain (Team, 2025) constructed affordance and visual trace tasks from RoboVQA (Sermanet et al., 2024) and video datasets. Additionally, many VLA studies leverage auxiliary post-training or co-training tasks of VLM (Intelligence et al., 2025; Zhang et al., 2025a) to obtain better backbone networks. In our subsequent experiments, we fine-tune VLM on various post-training tasks and compare its performance as a VLA backbone against the
第003/23页(中文翻译)
使用辅助数据集对视觉语言模型进行微调,或者直接使用已发布的微调模型。然后,我们应用VLM4VLA流水线来使这些模型适应具身策略。最后,我们进行了模态层面的消融实验,以分离视觉和语言组件的贡献(图1(c))。这包括选择性地冻结或微调视觉编码器和文本编码器。此外,我们研究了通过FAST分词器(Pertsch等,2025)将控制特定知识直接注入视觉编码器的有效性。我们在三个基准测试(包括Calvin(Mees等,2022)、SimplerEnv(Li等,2024)和Libero(Liu等,2023))的一系列任务上评估了微调后的模型,以评估它们的具身能力。
令我们惊讶的是,我们的研究结果表明,虽然视觉语言模型初始化相比从零开始训练能带来一致的益处,但视觉语言模型的通用能力并不能很好地预测其下游任务性能,这与普遍假设相悖。例如,我们观察到在某些环境中,Kosmos(Peng等,2023)的表现优于Qwen2.5-VL(Bai等,2025b)和Paligemma(Steiner等,2024)。跨基准测试的不一致性表明,视觉语言动作模型策略所需的能力超出了当前视觉语言模型所追求的范围。此外,在特定辅助具身任务上微调视觉语言模型所带来的增益,并不能迁移到下游控制任务中。最后,我们的模态层面分析指出,视觉编码器而非语言组件是主要的性能瓶颈。我们发现,微调视觉编码器对于获得强大的控制性能至关重要,而语言编码器则不那么关键。在视觉语言模型的视觉模块中注入与动作相关的信息后观察到的显著性能提升,证实了标准视觉语言模型预训练与具身任务对视觉表征需求之间存在关键领域差距。
综上所述,这些结果表明,当前视觉语言模型研究与视觉语言动作模型的实际需求之间存在显著差距。我们相信这项工作凸显了视觉语言模型在具身智能体中的根本作用问题,并有助于指导该领域的未来探索。
2相关工作
视觉语言动作模型近期的研究越来越关注将视觉语言模型(VLMs)(Dai等,2024;Touvron等,2023;Wang等,2025a;Bai等,2025b)引入机器人策略中,以增强其泛化能力(Brohan等,2023;Guo等,2025;Hu等,2024;Guo等,2024),这类模型被称为视觉语言动作(VLA)模型。早期的方法如RT-2(Brohan等,2023)和OpenVLA(Kim等,2024)将动作离散化为语言词元,从而通过视觉语言模型的自回归框架实现动作学习。后续的研究则利用策略头来解码连续动作,逐渐将视觉语言动作模型的设计演变为一个结合了视觉语言模型主干网络与策略头的分层结构(Black等,2024;Zhang等,2024;Cui等,2025)。然而,大多数先前的工作侧重于构建复杂的策略网络,却忽视了视觉语言模型主干网络本身对整体视觉语言动作模型性能的影响。尽管RoboVLMs(Liu等,2025)比较了少数早期视觉语言模型主干网络的影响,但其实现并未确保一致性。相比之下,我们设计了一个更公平的实验框架,以全面测试各种先进视觉语言模型在多个环境中的影响。通过采用最简单且一致的外部动作策略,我们最大限度地减少了策略头组件对实验结果的影响。
面向视觉语言模型的具身任务许多先前的研究探索了将具身相关任务引入视觉语言模型,以增强其空间理解(Yang等,2025;Feng,2025)和任务执行能力(Intelligence等,2025;Zhou等,2025b)。这些任务包括密集预测(Wang等,2025b;Zhang等,2025b)和自回归视觉问答任务(Rana等,2023;Yuan等,2024;Sermanet等,2024)。最近,受分层系统1和系统2设计范式(Zhang等,2024;Shentu等,2024)的启发,许多研究聚焦于使用视觉语言模型构建一个通用“机器人大脑”——一个能够通过语言规划或完成真实世界任务的大型语言模型。例如,Robo2vlm(Chen等,2025b)为视觉问答任务标注了如Open-X等数据集,而Robobrain(Team,2025)则基于RoboVQA(Sermanet等,2024)和视频数据集构建了可供性和视觉轨迹任务。此外,许多视觉语言动作模型研究利用视觉语言模型的辅助后训练或协同训练任务(Intelligence等,2025;Zhang等,2025a)来获得更好的骨干网络。在后续实验中,我们在多种后训练任务上对视觉语言模型进行微调,并将其作为视觉语言动作模型骨干的性能与
第004/23页(英文原文)
corresponding VLM baselines, thereby validating the effectiveness of these auxiliary VLM tasks for VLA performance.
3 STUDY DESIGN
To create a comprehensive and fair benchmark of VLM performance on manipulation tasks, we designed the VLM4VLA framework around three core principles:
- Fairness and Reproducibility We employ a consistent model architecture and training/testing settings across multiple simulation environments to ensure fair and reproducible comparisons.
- Minimalist Design We encapsulate VLMs within a simple yet effective VLA framework, thereby minimizing the influence of complex, extraneous policy designs on the comparison.
- Isolating Core VLM Capabilities To directly evaluate the VLM’s intrinsic knowledge, our framework relies exclusively on visual-language inputs. We format input sequences to match each VLM’s native instruction-tuning format and deliberately exclude other modalities like proprioceptive state or tactile feedback. This isolates the VLM’s contribution and directly tests how its intrinsic capabilities translate to manipulation.
In the following sections, we will detail the VLM4VLA research framework. In Sec 3.1 we introduce the basic experimental design. We then describe the model architecture within VLM4VLA in Sec 3.2, and Sec 3.3 explains the experiment setup and evaluation protocol.
3.1 BASIC EXPERIMENT DESIGN
As shown in Figure 1, our objective is to investigate the impact of different VLMs, as well as VLM-specific fine-tuning tasks, on the performance of the resulting VLA. Our experiments primarily focus on VLMs ranging from 1B to 10B parameters, as well as various embodiment-related auxiliary tasks and different training settings of transferring VLM to VLA. Beyond fundamental vision-language alignment, the general capabilities of VLMs relevant to embodied tasks include visual grounding, trajectory and action prediction, task planning, video understanding, and spatial reasoning. Some models also possess image rendering capabilities, such as depth prediction and semantic segmentation, as seen in works like Beyer et al. (2024); Chen et al. (2025a); Deng et al. (2025). To compare the effectiveness of these models and tasks, we encapsulate each VLM—both in its original form and after being fine-tuned on a specific auxiliary task—into a VLA, following the methodology described in Sec 3.2. All VLAs, despite their different backbones, share an identical action encoding and decoding scheme and introduce a minimal number of additional trainable parameters (less than 1%1\%1% ).
Subsequently, these VLM4VLA models are trained on robotic datasets using a consistent training setup. During this process, we fine-tune all model parameters, as our studys in Sec 4.3 demonstrate that freezing parts of the model leads to significant performance degradation. The fine-tuned models are then deployed for rollouts in the target environments, where we measure the success rates on various tasks. The VLA performance is assessed according to the protocol detailed in Sec 3.3.
3.2 VLM4VLA NETWORK DESIGN
In this section, we detail the method for constructing a consistent VLA from various VLMs within the VLM4VLA framework, as illustrated in Figure 2. Our objective is to build a VLA architecture that is generic across different VLMs, lightweight, and capable of fully leveraging the VLM’s intrinsic knowledge.
We introduce a learnable action query token to extract embodiment-related knowledge from the VLM. The representation of this token is then decoded into an action chunk. To align with the pre-training input format of each model, we adapt a unique token concatenation scheme for each VLM4VLA instance. We take the
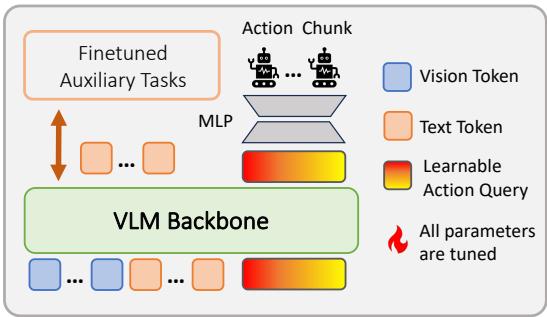
Figure 2: VLA Network in VLM4VLA
第004/23页(中文翻译)
相应的视觉语言模型基线进行比较,从而验证了这些辅助视觉语言模型任务对视觉语言动作模型性能的有效性。
3研究设计
为了创建一个全面且公平的视觉语言模型在操作任务上的性能基准,我们围绕三个核心原则设计了VLM4VLA框架:
- 公平性与可复现性我们在多个模拟环境中采用一致的模型架构和训练/测试设置,以确保公平且可复现的比较。
- 极简设计我们将视觉语言模型封装在一个简单而有效的视觉语言动作模型框架内,从而将复杂、冗余的策略设计对比较结果的影响降至最低。
- 隔离核心视觉语言模型能力 为了直接评估视觉语言模型的内在知识,我们的框架完全依赖于视觉-语言输入。我们将输入序列格式化为匹配每个视觉语言模型原生的指令微调格式,并刻意排除其他模态,如本体感知状态或触觉反馈。这隔离了视觉语言模型的贡献,并直接测试了其内在能力如何转化为操控能力。
在接下来的章节中,我们将详细阐述VLM4VLA研究框架。在3.1节中,我们介绍基本的实验设计。然后在3.2节中描述VLM4VLA内的模型架构,3.3节则解释实验设置和评估协议。
3.1基础实验设计
如图1所示,我们的目标是研究不同视觉语言模型,以及视觉语言模型特定的微调任务,对最终视觉语言动作模型性能的影响。我们的实验主要关注参数量从10亿到100亿的视觉语言模型,以及各种与具身任务相关的辅助任务和将视觉语言模型迁移到视觉语言动作模型的不同训练设置。除了基础的视觉-语言对齐,视觉语言模型与具身任务相关的通用能力包括视觉定位、轨迹与动作预测、任务规划、视频理解和空间推理。一些模型还具备图像渲染能力,例如深度预测和语义分割,正如Beyer等(2024)、Chen等(2025a)、Deng等(2025)等研究中所见。为了比较这些模型和任务的有效性,我们遵循3.2节中描述的方法,将每个视觉语言模型——无论是其原始形态还是在特定辅助任务上微调后的版本——封装成一个视觉语言动作模型。所有视觉语言动作模型,尽管拥有不同的骨干网络,但共享相同的动作编码和解码方案,并且只引入了极少量的额外可训练参数(少于 1%1\%1% )。
随后,这些VLM4VLA模型在机器人数据集上使用一致的训练设置进行训练。在此过程中,我们微调所有模型参数,因为我们在第4.3节的研究表明,冻结模型的某些部分会导致性能显著下降。微调后的模型随后被部署到目标环境中进行rollout,我们在其中测量各种任务的成功率。VLA性能根据第3.3节详述的协议进行评估。
3.2 VLM4VLA网络设计
在本节中,我们将详细介绍在VLM4VLA框架内,从各种视觉语言模型构建一致的视觉语言动作模型的方法,如图2所示。我们的目标是构建一个能够跨不同视觉语言模型通用、轻量级,并能充分利用视觉语言模型内在知识的VLA架构。
我们引入了一个可学习的动作查询代币,以从视觉语言模型中提取与具身化相关的知识。该代币的表征随后被解码成一个动作块。为了与每个模型的预训练输入格式对齐,我们为每个VLM4VLA实例适配了独特的代币拼接方案。我们取
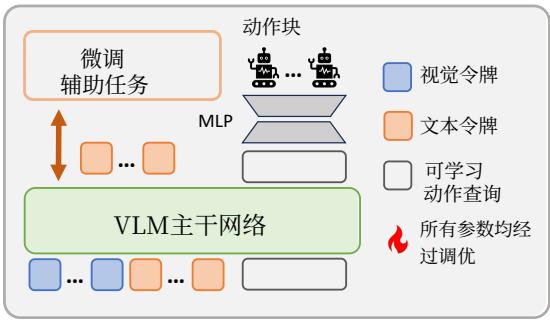
图2:VLM4VLA中的VLA网络
第005/23页(英文原文)
of the token, as encoded by the VLM, and decode it into an action chunk using a small MLP-based policy head. The overall action output can be formulated as:
action=MLP(VLM([⟨img⟩…⟨img⟩⟨t e x t⟩…⟨t e x t⟩⟨A c t i o n Q u e y⟩]))) \operatorname {a c t i o n} = \operatorname {M L P} (\operatorname {V L M} ([ \langle \mathrm {i m g} \rangle \dots \langle \mathrm {i m g} \rangle \langle \text {t e x t} \rangle \dots \langle \text {t e x t} \rangle \langle \text {A c t i o n Q u e y} \rangle ]))) action=MLP(VLM([⟨img⟩…⟨img⟩⟨t e x t⟩…⟨t e x t⟩⟨A c t i o n Q u e y⟩])))
where ⟨img⟩\langle \mathrm{img}\rangle⟨img⟩ represents the visual embeddings from the vision encoder, ⟨text⟩\langle \mathrm{text}\rangle⟨text⟩ corresponds to the language embeddings containing the instruction and any additional prompts, and ⟨ActionQuery⟩\langle \mathrm{ActionQuery}\rangle⟨ActionQuery⟩ is the learnable action query token. The token sequence above omits VLM-specific special tokens (e.g. ⟨PAD⟩\langle \mathrm{PAD}\rangle⟨PAD⟩ or ⟨EOS⟩\langle \mathrm{EOS}\rangle⟨EOS⟩ …) for brevity. Further details can be found in Appendix A.2.
Training Objective During training, we finetune all parameters of the VLM, including the LLM, the vision encoder, and the word embeddings. We deliberately avoid widely-used objectives like diffusion loss and flow-matching loss. Our preliminary experiments revealed that these losses introduce significant stochasticity during inference, requiring a much larger number of rollouts for accurate evaluation. They also cause substantial performance fluctuations between different checkpoints late in training, which is not conducive to the fair comparison we aim to achieve. As a result, we utilize a maximum likelihood imitation learning objective. The desired relative position aposa^{\mathrm{pos}}apos of the end-effector (or continuous joint action) is optimized via a modified MSE loss (Huber loss). The discrete status aenda^{\mathrm{end}}aend of the end-effector is optimized with a binary cross-entropy loss:
L=1∣B∣∑B(∥ap o s−a^p o s∥22+BCE(ae n d,a^e n d))(1) \mathcal {L} = \frac {1}{| \mathcal {B} |} \sum_ {\mathcal {B}} \left(\left\| \boldsymbol {a} ^ {\text {p o s}} - \hat {\boldsymbol {a}} ^ {\text {p o s}} \right\| _ {2} ^ {2} + \operatorname {B C E} \left(a ^ {\text {e n d}}, \hat {a} ^ {\text {e n d}}\right)\right) \tag {1} L=∣B∣1B∑(∥ap o s−a^p o s∥22+BCE(ae n d,a^e n d))(1)
where a^pos\hat{a}^{\mathrm{pos}}a^pos and a^end\hat{a}^{\mathrm{end}}a^end denote the demonstration data for the relative position and status of the end-effector in a sampled mini-batch B\mathcal{B}B .
3.3 EXPERIMENT SETTINGS AND EVALUATION PROTOCOL
We fine-tune the VLM and the action policy for each model using identical hyperparameters and model configurations for fair comparisons. We conduct a learning-rate sweep and select a unified hyperparameter configuration to ensure that all models reached convergence at evaluation time (details can be found in Appendix A.2.2). Specifically, the model uses a single-view image of the current frame as its visual input and does not take proprioceptive information; this prevents the model from directly learning actions from the state. To handle inconsistent input image sizes across different VLMs, we standardize the input to 224×224224 \times 224224×224 resolution for all training (an ablation on different image resolutions can be found in Appendix A.2.4). If a VLM requires a different input size, we first process the image at 224×224224 \times 224224×224 and then resize it to the model-specific dimensions. During training, all parameters of VLM are trained, including the vision encoder, word embeddings, LLM, and small policy head. For each VLM, we use a simple instruction prompt consistent with its pre-training format (detailed prompts format for each model can be found in Appendix A.2.3).
To ensure the reproducibility and fairness of our experiments, we do not use real-world tasks for evaluation. A direct consequence of this choice is that it prevents other researchers from directly comparing their own models against our findings on physical robots. We test different models in three simulation environments: Calvin (Mees et al., 2022), SimplerEnv (Li et al., 2024), and Libero (Liu et al., 2023). Since each environment requires separate training and testing, to improve the efficiency and rigor of our evaluation, we select the most challenging scenarios as our evaluation benchmarks. During tests, we experiment with executing the full action chunk, half of the action chunk, and a single step over all validation checkpoints. We report the best-performing result. More details about the settings of different environments can be found in the Appendix A.1.
Calvin ABC-D We evaluate on the Calvin ABC-D task. We train the model for 30k steps on the ABC splits and evaluate it on 1000 task sequences, each with a length of 5. During testing, the policy is required to complete a sequence of 1-5 tasks. This setup challenges the VLM’s ability to generalize to novel visual scenes. We report the average number of successfully completed tasks per sequence.
SimplerEnv Bridge To better differentiate the performance of various VLM-based policies, we choose the WindowX (Bridge V2) task suite, which is more challenging than the Fractal suite. We train for 50k steps on Bridge-V2 (Walke et al., 2023). During evaluation, we run 24 trials with random initializations for each of the four scenes (Pick Carrot, Pick Eggplant, Pick Spoon, and Stack Cube) and calculate the success rate.
第005/23页(中文翻译)
<最后一个隐藏状态>的动作查询>代币,该代币由视觉语言模型编码,并使用一个基于MLP的小型策略头将其解码成一个动作块。整体动作输出可以表述为:
action=MLP(VLM([⟨img⟩…⟨img⟩⟨t e x t⟩…⟨t e x t⟩⟨A c t i o n Q u e y⟩]))) \mathbf {a c t i o n} = \mathrm {M L P} (\mathrm {V L M} ([ \langle \mathrm {i m g} \rangle \dots \langle \mathrm {i m g} \rangle \langle \text {t e x t} \rangle \dots \langle \text {t e x t} \rangle \langle \text {A c t i o n Q u e y} \rangle ]))) action=MLP(VLM([⟨img⟩…⟨img⟩⟨t e x t⟩…⟨t e x t⟩⟨A c t i o n Q u e y⟩])))
其中(img)代表来自视觉编码器的视觉嵌入,(text)对应包含指令和任何附加提示的语言嵌入,而(ActionQuery)是可学习的动作查询代币。为简洁起见,上述词元序列省略了视觉语言模型特定的特殊词元(例如(PAD)或(EOS)…)。更多细节请参见附录A.2。
训练目标在训练期间,我们微调视觉语言模型的所有参数,包括大语言模型、视觉编码器和词嵌入。我们有意避免使用像扩散损失和流匹配损失这样广泛使用的目标。我们的初步实验表明,这些损失在推理过程中会引入显著的随机性,需要多得多的 rollout 才能进行准确评估。它们还会导致训练后期不同检查点之间的性能出现大幅波动,这不利于我们旨在实现的公平比较。因此,我们采用最大似然模仿学习目标。末端执行器(或连续关节动作)的期望相对位置 aposa^{\mathrm{pos}}apos 通过修正的 MSE 损失(Huber 损失)进行优化。末端执行器的离散状态 aenda^{\mathrm{end}}aend 则使用二元交叉熵损失进行优化:
L=1∣B∣∑B(∥ap o s−a^p o s∥22+BCE(ae n d,a^e n d))(1) \mathcal {L} = \frac {1}{| \mathcal {B} |} \sum_ {\mathcal {B}} \left(\left\| \boldsymbol {a} ^ {\text {p o s}} - \hat {\boldsymbol {a}} ^ {\text {p o s}} \right\| _ {2} ^ {2} + \operatorname {B C E} \left(a ^ {\text {e n d}}, \hat {a} ^ {\text {e n d}}\right)\right) \tag {1} L=∣B∣1B∑(∥ap o s−a^p o s∥22+BCE(ae n d,a^e n d))(1)
其中 a^pos\hat{\pmb{a}}^{\mathrm{pos}}a^pos 和 a^end\hat{a}^{\mathrm{end}}a^end 表示小批量 BBB 中采样得到的末端执行器相对位置和状态的演示数据。
3.3实验设置与评估协议
为了进行公平比较,我们使用相同的超参数和模型配置对每个模型的视觉语言模型和动作策略进行微调。我们进行了学习率搜索,并选择了一套统一的超参数配置,以确保所有模型在评估时都能达到收敛(详情见附录A.2.2)。具体而言,模型使用当前帧的单视角图像作为其视觉输入,并且不接收本体感知信息;这防止了模型直接从状态中学习动作。为了处理不同视觉语言模型之间输入图像尺寸不一致的问题,我们将所有训练的输入标准化为 224×224224 \times 224224×224 分辨率(关于不同图像分辨率的消融研究见附录A.2.4)。如果某个视觉语言模型需要不同的输入尺寸,我们会先在 224×224224 \times 224224×224 分辨率下处理图像,然后将其调整至该模型特定的尺寸。在训练期间,视觉语言模型的所有参数都会被训练,包括视觉编码器、词嵌入、大语言模型以及小的策略头。对于每个视觉语言模型,我们使用与其预训练格式一致的简单指令提示(每个模型的详细提示格式见附录A.2.3)。
为确保我们实验的可复现性与公平性,我们未使用真实世界任务进行评估。这一选择的直接后果是,它使得其他研究人员无法将其自身模型与我们在物理机器人上的发现进行直接比较。我们在三个模拟环境中测试不同模型:Calvin(Mees等,2022年)、SimplerEnv(Li等,2024年)和Libero(Liu等,2023年)。由于每个环境都需要独立的训练与测验,为提高评估效率与严谨性,我们选取最具挑战性的场景作为我们的评估基准。在测验过程中,我们尝试在所有验证检查点上执行完整动作块、一半动作块以及单一步骤。我们报告性能最佳的结果。关于不同环境设置的更多细节,请参见附录A.1。
Calvin ABC-D我们在Calvin ABC-D任务上进行评估。我们在ABC划分上对模型进行30k步训练,并在1000个任务序列(每个序列长度为5)上对其评估。在测验期间,策略需要完成一个包含1-5个任务的序列。此设置挑战了视觉语言模型对新视觉场景的泛化能力。我们报告每个序列中平均成功完成的任务数。
- SimplerEnv 跨链桥 为了更好地区分各种基于视觉语言模型的策略性能,我们选择了更具挑战性的 WindowX(跨链桥 V2)任务套件,它比Fractal套件更困难。我们在Bridge-V2(Walke等,2023)上训练了5万步。在评估期间,我们对四个场景(Pick Carrot、Pick Eggplant、Pick Spoon和Stack Cube)分别运行24次随机初始化的试验,并计算成功率。
第006/23页(英文原文)
Libero-Long (-10) Among the five task suites in Libero, we evaluate different models on the most challenging suite Libero-Long, which consists of 10 tasks involving a variety of objects and skills. All models are trained for 50k steps on the training split and evaluated with 50 trials with random initializations for each task.
4 EXPERIMENTS AND ANALYSIS
To comprehensively evaluate how VLM capabilities transfer to robot manipulation, our experimental analysis is four-fold. First, in Sec 4.1, we benchmark various open-source VLMs on a challenging set of tasks across three simulators to assess the relationship between general capability and the downstream performance. Second, in Sec 4.2, we investigate whether improvements gained from fine-tuning on specific auxiliary embodied tasks translate to better final performance. Then, in Sec 4.3, we analyze the importance of the different modules within VLM by comparing the outcomes of freezing versus fine-tuning it during VLA adaptation. Through the above experiments, we observe a clear gap between VLMs and VLAs, particularly a misalignment in the features produced by the vision encoder. To further investigate the factors underlying this gap, we conduct additional experiments in Sec. 4.4, which indicate that the gap may stem from a mismatch between visual-language tasks and low-level action control tasks. Additionally, in Appendix A.2.5, we report results where the VLA is trained from scratch without any pretrained VLM, providing a lower-bound reference for VLA performance.
4.1 PERFORMANCE OF DIFFERENT VLMS ON VLM4VLA
4.1.1 BASELINES
VLM Baselines We evaluate several Vision-Language Models commonly used in open-source VLAs, with model sizes generally ranging from 1B to 10B parameters (we also incorporate a large 30B-MoE-based VLM to diversify the types of backbone architectures), which ensures the feasibility of extensive action-learning finetuning and rollout testing. We test a variety of VLM models from the VLA domain, including the Paligemma series (paligemma-1 (Beyer et al., 2024) and paligemma-2 (Steiner et al., 2024)), the QwenVL series (Qwen2.5VL-3B, Qwen2.5VL-7B, Qwen3VL-2B, Qwen3VL-4B, Qwen3VL-8B, Qwen3VL-30B-A3B) (Bai et al., 2025b;a) and Kosmos-2 (Peng et al., 2023). Among these, the QwenVL series are top-tier general-purpose open-source VLMs, Paligemma is designed for better adaptability to downstream finetuning, and the Kosmos series excels at grounding tasks. These models cover a range of multimodal LLMs with diverse architectures and strengths, allowing us to compare their action-learning capabilities comprehensively. Also, to estimate the lower bound of current VLAs, we evaluate several models trained from scratch without any pretrained VLM, providing a lower-bound reference for VLA performance (detailed results can be found in Appendix A.2.5.
VLA Baselines For comparison, we select several expert VLAs as reference baselines, which use different VLMs as their backbones:
- OpenVLA (Kim et al., 2024): Uses Llama2-7B with DINOv2/SigLIP as its VLM backbone. It differs from our VLM4VLA framework by decoding actions into a discrete space. The total model size is approximately 7.7B. For the Calvin environment, we report our reproduced OpenVLA results, while for the Simpler and Libero environments, we report the official results. Similar to our VLM4VLA setup, this model uses only a single image as input and does not leverage proprioceptive state.
- pi0 (Black et al., 2024): Based on Paligemma-1, with a total size of approximately 3.1B. We modify the code provided by open/pi-zero to train and test within our setups, ensuring consistent settings with other backbones. We remove the proprioceptive expert and use a single image as input. More details can be found in Appendix A.3.
- ThinkAct (Huang et al., 2025): A recent VLA model enhanced with reinforcement learning, based on Qwen2.5VL-7B. We report its official results on Simpler and Libero for comparison against our Qwen2.5VL-7B baseline. Unlike other baselines, ThinkAct takes use of proprioceptive state as an input.
第006/23页(中文翻译)
Libero-Long(-10)在Libero的五个任务套件中,我们在最具挑战性的套件Libero-Long上评估不同模型,该套件包含10个涉及多种对象和技能的任务。
所有模型均在训练集上训练5万步,并在每项任务中通过50次随机初始化的试验进行评估。
4 实验与分析
为了全面评估视觉语言模型能力向机器人操控的迁移效果,我们的实验分析分为四个部分。首先,在第4.1节中,我们在三个模拟器上的一系列具有挑战性的任务上对多种开源视觉语言模型进行基准测试,以评估其通用能力与下游性能之间的关系。其次,在第4.2节中,我们探究在特定辅助具身任务上进行微调所获得的改进是否能转化为更好的最终性能。接着,在第4.3节中,我们通过比较在VLA适配期间冻结与微调视觉语言模型不同模块的结果,分析这些模块的重要性。通过上述实验,我们观察到视觉语言模型与视觉语言动作模型之间存在明显差距,尤其是视觉编码器生成的特征存在错位。为了进一步探究这一差距背后的因素,我们在第4.4节进行了补充实验,结果表明该差距可能源于视觉语言任务与底层动作控制任务之间的不匹配。此外,在附录A.2.5中,我们报告了视觉语言动作模型在没有任何预训练视觉-语言模型的情况下从头开始训练的结果,为VLA性能提供了一个下限参考。
4.1 不同视觉语言模型在VLM4VLA上的性能
4.1.1基线
VLM基线我们评估了开源视觉语言动作模型中常用的几种视觉语言模型,其模型尺寸通常在1B到100亿参数之间(我们还引入了一个基于MoE的大型300亿参数视觉语言模型以丰富骨干架构类型),这确保了进行广泛动作学习微调和推演测验的可行性。我们测试了来自VLA领域的多种视觉语言模型,包括Paligemma系列(paligemma-1 (Beyer等,2024)和paligemma-2(Steiner等,2024))、QwenVL系列(Qwen2.5VL-3B、Qwen2.5VL-7B、Qwen3VL-2B、Qwen3VL-4B、Qwen3VL-8B、Qwen3VL-30B-A3B)(Bai等,2025b;a)以及Kosmos-2(Peng等,2023)。其中,QwenVL系列是顶级的通用开源视觉语言模型,Paligemma旨在更好地适应下游微调,而Kosmos系列则在定位任务上表现出色。这些模型涵盖了具有不同架构和优势的一系列多模态大语言模型,使我们能够全面比较它们的动作学习能力。此外,为了估计当前视觉语言动作模型性能的下限,我们还评估了几个从头开始训练、未使用任何预训练视觉-语言模型的模型,为VLA性能提供了下限参考(详细结果见附录A.2.5)。
视觉语言动作模型基准为便于比较,我们选取了几种专家视觉-语言-动作模型作为参考基准,它们使用不同的视觉语言模型作为其骨干:
-
OpenVLA (Kim等,2024):使用Llama2-7B与DINOv2/SigLIP作为其VLM主干网络。它与我们的VLM4VLA框架的不同之处在于将动作解码到一个离散空间。模型总尺寸约为 7.7B7.7\mathrm{B}7.7B 。对于Calvin环境,我们报告了我们复现的OpenVLA结果;而对于Simpler和Libero环境,我们报告了官方结果。与我们的VLM4VLA设置类似,该模型仅使用单张图像作为输入,且不利用本体感知状态。
-
pi0 (Blacketal., 2024): 基于 Paligemma-1, 总尺寸约为 3.1B。我们修改了 open-pi-zero 提供的代码, 以在我们的设置中进行训练和测试, 确保与其他主干网络设置一致。我们移除了本体感知专家, 并使用单张图像作为输入。更多细节请参见附录 A.3。
-
ThinkAct (Huang et al., 2025): 一个基于Qwen2.5VL-7B、通过强化学习增强的最新VLA模型。我们报告了其在Simpler和Libero上的官方结果,以与我们的Qwen2.5VL-7B基线进行比较。与其他基线不同,ThinkAct将本体感知状态作为输入加以利用。
第007/23页(英文原文)
4.1.2 MAIN RESULTS
The performance of different VLMs on robotics tasks is presented in Tables 1 and 2. In addition to success rates, we report the number of finetuned parameters for each model in the size column. In Table 8 (Appendix A.2.5), we report results where the VLA is trained from scratch without any pretrained VLM, indicating that VLM pre-training is fundamental to the ability of VLA models.
Table 1: Results on Calvin ABC-D. Entries marked with * are expert VLAs modified and reproduced with our training and test settings.
| Model (VLM Backbone) | Size | Task-1 | Task-2 | Task-3 | Task-4 | Task-5 | Calvin↑ |
| Expert Vision-Lanugage-Action Models | |||||||
| OpenVLA* (Llama-2) | 7.7B | 0.792 | 0.644 | 0.499 | 0.368 | 0.245 | 2.548 |
| pi0* (Paligemma-1) | 3.1B | 0.896 | 0.785 | 0.786 | 0.610 | 0.532 | 3.509 |
| VLM with VLM4VLA Models | |||||||
| Qwen2.5VL-3B | 3.8B | 0.922 | 0.842 | 0.766 | 0.700 | 0.626 | 3.856 |
| Qwen2.5VL-7B | 8.3B | 0.935 | 0.864 | 0.807 | 0.758 | 0.693 | 4.057 |
| Qwen3VL-2B | 2.1B | 0.943 | 0.882 | 0.831 | 0.776 | 0.710 | 4.142 |
| Qwen3VL-4B | 4.4B | 0.933 | 0.857 | 0.790 | 0.719 | 0.644 | 3.943 |
| Qwen3VL-8B | 8.8B | 0.940 | 0.868 | 0.797 | 0.746 | 0.684 | 4.035 |
| Qwen3VL-30B-A3B | 31.1B | 0.939 | 0.877 | 0.820 | 0.757 | 0.682 | 4.075 |
| Paligemma-1 | 2.9B | 0.914 | 0.813 | 0.692 | 0.599 | 0.488 | 3.506 |
| Paligemma-2 | 3.0B | 0.901 | 0.775 | 0.669 | 0.575 | 0.486 | 3.406 |
| KosMos-2 | 1.7B | 0.878 | 0.721 | 0.591 | 0.498 | 0.408 | 3.096 |
As shown in Table 1 for the Calvin ABC-D task, QwenVL series models significantly outperform other VLMs. Notably, the average of completed tasks using single view image by Qwen2.5VL-7B, Qwen3VL-2B, Qwen3VL-8B is nearly on par with state-of-the-art VLAs. Furthermore, VLMs that perform better on QA-benchmarks, such as the QwenVL series, also exhibit superior performance on Calvin, suggesting a correlation between the capabilities tested by Calvin and other VQA benchmarks. Concurrently, we observe that pi0, which is based on Paligemma-1 and does not use state information, performs similarly to the base Paligemma-1 model. This indicates that the additional action expert is constrained by the inherent capabilities of VLM backbone itself and fails to yield performance improvements in the Calvin environment.
Table 2: Results on SimplerEnv-Bridge and Libero-10. Entries marked with * are expert VLAs modified and reproduced with our training and test settings.
| Model (VLM Backbone) | Size | Carrot | Eggplant | Spoon | Cube | Simpler↑ | Libero↑ |
| Expert Vision-Lanugage-Action Models | |||||||
| OpenVLA (Llama-2) | 7.7B | 4.2 | 0.0 | 0.0 | 12.5 | 4.2 | 53.7 |
| pi0* (Paligemma-1) | 3.1B | 62.5 | 100.0 | 54.2 | 25.0 | 60.4 | 46.0 |
| ThinkAct (Qwen2.5VL-7B) | 7.4B | 37.5 | 70.8 | 58.3 | 8.7 | 43.8 | 70.9 |
| VLM with VLM4VLA Models | |||||||
| Qwen2.5VL-3B | 3.8B | 20.8 | 91.7 | 79.2 | 0.0 | 48.0 | 43.0 |
| Qwen2.5VL-7B | 8.3B | 12.5 | 100.0 | 75.0 | 0.0 | 46.8 | 45.0 |
| Qwen3VL-2B | 2.1B | 20.8 | 95.8 | 79.2 | 0.0 | 49.0 | 55.8 |
| Qwen3VL-4B | 4.4B | 54.2 | 95.8 | 75.0 | 0.0 | 56.3 | 44.4 |
| Qwen3VL-8B | 8.8B | 58.3 | 95.8 | 79.2 | 0.0 | 58.3 | 46.2 |
| Qwen3VL-30B-A3B | 31.1B | 29.2 | 79.2 | 70.8 | 0.0 | 44.8 | 46.8 |
| Paligemma-1 | 2.9B | 50.0 | 91.7 | 75.0 | 4.2 | 55.3 | 44.2 |
| Paligemma-2 | 3.0B | 75.0 | 75.0 | 79.2 | 0.0 | 57.3 | 46.2 |
| KosMos-2 | 1.7B | 37.5 | 100.0 | 75.0 | 29.2 | 60.4 | 55.0 |
Table 2 displays the performance of the models on the Simpler-Bridge and Libero-10 (long) tasks. We find that KosMos-2, the smallest model, achieves the highest success rate on both tasks. On the Simpler-Bridge task, the Paligemma series models outperform the Qwen2.5VL series, whereas on Libero-10, the performance across different VLM categories is comparable. It is worth noting that
第007/23页(中文翻译)
4.1.2 主要结果
不同视觉语言模型在机器人任务上的性能如表1和表2所示。除了成功率,我们还在尺寸列中报告了每个模型的微调参数数量。在表8(附录A.2.5)中,我们报告了视觉语言动作模型在没有任何预训练视觉-语言模型的情况下从头开始训练的结果,这表明视觉-语言模型预训练是视觉语言动作模型能力的基础。
表1: Calvin ABC-D上的结果。标有 * 的条目是经过修改、并采用我们的训练和测试设置复现的专家视觉-语言-动作模型。
| 模型(视觉语言模型主干) | Size | 任务-1 | 任务-2 | 任务-3 | 任务-4 | 任务-5 | Calvin↑ |
| 专家级视觉语言动作模型 | |||||||
| OpenVLA* (Llama-2) | 7.7B | 0.792 | 0.644 | 0.499 | 0.368 | 0.245 | 2.548 |
| pi0* (Paligemma-1) | 3.1B | 0.896 | 0.785 | 0.786 | 0.610 | 0.532 | 3.509 |
| 采用VLM4VLA模型的视觉语言模型 | |||||||
| Qwen2.5VL-3B | 3.8B | 0.922 | 0.842 | 0.766 | 0.700 | 0.626 | 3.856 |
| Qwen2.5VL-7B | 8.3B | 0.935 | 0.864 | 0.807 | 0.758 | 0.693 | 4.057 |
| Qwen3VL-2B | 2.1B | 0.943 | 0.882 | 0.831 | 0.776 | 0.710 | 4.142 |
| Qwen3VL-4B | 4.4B | 0.933 | 0.857 | 0.790 | 0.719 | 0.644 | 3.943 |
| Qwen3VL-8B | 8.8B | 0.940 | 0.868 | 0.797 | 0.746 | 0.684 | 4.035 |
| Qwen3VL-30B-A3B | 31.1B | 0.939 | 0.877 | 0.820 | 0.757 | 0.682 | 4.075 |
| Paligemma-1 | 2.9B | 0.914 | 0.813 | 0.692 | 0.599 | 0.488 | 3.506 |
| Paligemma-2 | 3.0B | 0.901 | 0.775 | 0.669 | 0.575 | 0.486 | 3.406 |
| KosMos-2 | 1.7B | 0.878 | 0.721 | 0.591 | 0.498 | 0.408 | 3.096 |
如表1所示,针对Calvin ABC-D任务,QwenVL系列模型显著优于其他视觉语言模型。值得注意的是,Qwen2.5VL-7B、Qwen3VL-2B和Qwen3VL-8B使用单视图图像完成的平均任务数量与最先进的视觉语言动作模型近乎持平。此外,在问答基准测试中表现更好的视觉语言模型(例如QwenVL系列)在Calvin环境上也表现出更优异的性能,这表明Calvin测试的能力与其他视觉问答基准测试的能力存在相关性。同时,我们观察到基于Paligemma-1且不使用状态信息的pi0,其表现与基础的Paligemma-1模型相似。这表明额外的动作专家受限于视觉语言模型主干网络本身的内在能力,无法在Calvin环境中带来性能提升。
表2:SimplerEnv-Bridge和Libero-10上的结果。标有*的条目是经过我们训练和测试设置修改并复现的专家视觉-语言-动作模型。
| 模型(视觉语言模型主干) | Size | 胡萝卜 | 茄子 | 勺子 | Cube | Simpler↑ | Libero↑ |
| 专家级视觉语言动作模型 | |||||||
| OpenVLA (Llama-2) | 7.7B | 4.2 | 0.0 | 0.0 | 12.5 | 4.2 | 53.7 |
| pi0* (Paligemma-1) | 3.1B | 62.5 | 100.0 | 54.2 | 25.0 | 60.4 | 46.0 |
| ThinkAct (Qwen2.5VL-7B) | 7.4B | 37.5 | 70.8 | 58.3 | 8.7 | 43.8 | 70.9 |
| 视觉语言模型与VLM4VLA模型 | |||||||
| Qwen2.5VL-3B | 3.8B | 20.8 | 91.7 | 79.2 | 0.0 | 48.0 | 43.0 |
| Qwen2.5VL-7B | 8.3B | 12.5 | 100.0 | 75.0 | 0.0 | 46.8 | 45.0 |
| Qwen3VL-2B | 2.1B | 20.8 | 95.8 | 79.2 | 0.0 | 49.0 | 55.8 |
| Qwen3VL-4B | 4.4B | 54.2 | 95.8 | 75.0 | 0.0 | 56.3 | 44.4 |
| Qwen3VL-8B | 8.8B | 58.3 | 95.8 | 79.2 | 0.0 | 58.3 | 46.2 |
| Qwen3VL-30B-A3B | 31.1B | 29.2 | 79.2 | 70.8 | 0.0 | 44.8 | 46.8 |
| Paligemma-1 | 2.9B | 50.0 | 91.7 | 75.0 | 4.2 | 55.3 | 44.2 |
| Paligemma-2 | 3.0B | 75.0 | 75.0 | 79.2 | 0.0 | 57.3 | 46.2 |
| KosMos-2 | 1.7B | 37.5 | 100.0 | 75.0 | 29.2 | 60.4 | 55.0 |
表2展示了各模型在Simpler-Bridge和Libero-10(长)任务上的性能。我们发现,最小的模型KosMos-2在这两项任务上都取得了最高的成功率。在Simpler-Bridge任务上,Palgemma系列模型的表现优于Qwen2.5VL系列;而在Libero-10任务上,不同视觉语言模型类别之间的性能表现则较为接近。值得注意的是,
第008/23页(英文原文)
ThinkAct, finetuned from Qwen2.5VL-7B, performs similarly to the base Qwen2.5VL-7B on Simpler-Bridge. However, its performance on Libero-10 is substantially better than all other models. This may be caused by the proprioceptive state information utilized by ThinkAct, which can be a useful input for Libero environment.
As illustrated in Figure 3, we conducted a linear regression analysis to examine the relationship between VLA performance and the general capabilities of the underlying VLMs. We plot the performance of various VLMs on several general-purpose VQA benchmarks against their performance on VLA tasks.
For Paligemma and Kosmos, we approximated their general capabilities using results from their proprietary tasks. For Qwen-VL, we used the average scores from multiple general-purpose VQA benchmarks. A linear regression line is fitted to visualize the correlation between these two sets of metrics. The results indicate that different evaluation environments exhibit varying degrees of linear correlation with these general VLM capabilities. We found that the results on the Calvin benchmark exhibit a high correlation with performance on VQA benchmarks. In contrast, for the Simpler and Libero environments, there is no apparent correlation between a VLM’s QA performance and its VLA performance. This suggests a significant gap exists between the capabilities required for VLA manipulation tasks and those measured by exist-
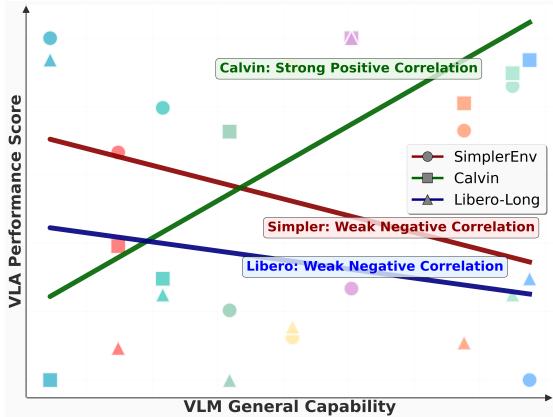
Figure 3: Comparison of the linear relationship between general VLM capabilities and VLA performance.
ing VQA benchmarks. More details about Figure 3 can be found in Appendix A.4.
4.2 IMPACT OF DIFFERENT VLM AUXILIARY TASKS ON VLA PERFORMANCE
Recent works have proposed using robotic data to construct VQA datasets for improving VLM backbones, e.g., Robobrain (Team, 2025). However, few studies have investigated whether this additional continual finetuning actually benefits VLAs in downstream tasks. In this section, we construct or collect several SFT tasks for VLM, including VQA datasets and a generation task. We first finetune the Qwen2.5VL model and subsequently, we employ each finetuned VLM as the backbone for our VLM4VLA framework and evaluate its performance on the Calvin benchmark. Specifically, we compare the following finetuned VLMs (more details about SFT datasets can be found in Appendix A.6):
Robopoint (Yuan et al., 2024) A pointing task dataset collected in simulator. Given an image and a target location, the model is required to output the 2D coordinates that satisfy the target requirement. This finetuning dataset contains 1.432M samples. After finetuning, the performance of Qwen2.5VL-3B on the pointing task improved by ∼20%\sim 20\%∼20% on the test split.
Vica-332k (Feng, 2025) A spatial understanding dataset constructed from RGB-D datasets. It covers a wide range of capabilities, including size estimation, position understanding, distance estimation, and so on. After finetuning Qwen2.5VL-3B on this dataset, we achieve a performance improvement of ∼15%\sim 15\%∼15% on VSI-Bench Yang et al. (2025).
Bridgevqa We used VQASynth to annotate data from Bridge-v2, Fractal, and Calvin ABC, combining them into a spatial understanding question-answering dataset. The main QA content includes judging the distance, size, and depth between two objects.
Robo2v1m (Chen et al., 2025b) An action-oriented question-answering dataset built from 176k real robot trajectories, containing 667k VQA pairs. It involves tasks such as multi-view understanding, success prediction, position management, and trajectory judgment. After finetuning Qwen2.5VL-3B on this dataset, we achieved a 60%60\%60% performance improvement on its test set.
第008/23页(中文翻译)
从Qwen2.5VL-7B微调而来的ThinkAct,在Simpler-Bridge任务上的表现与基础版Qwen2.5VL-7B相似。然而,它在Libero-10任务上的性能则显著优于所有其他模型。这可能是由于ThinkAct利用了本体感知状态信息,该信息对于Libero环境而言可能是一种有用的输入。
如图3所示,我们进行了线性回归分析,以研究VLA性能与底层视觉语言模型的通用能力之间的关系。我们绘制了多种视觉语言模型在几个通用视觉问答基准上的性能与其在VLA任务上的性能对比图。
对于PaliGemma和Kosmos,我们使用其专任务的结果来近似评估其通用能力。对于Qwen-VL,我们使用了多个通用视觉问答基准的平均得分。拟合了一条线性回归线来可视化这两组指标之间的相关性。结果表明,不同的评估环境与这些通用视觉语言模型能力呈现出不同程度的线性相关性。我们发现,Calvin基准上的结果与视觉问答基准的性能表现出高度相关性。相比之下,在Simpler和Libero环境中,视觉语言模型的问答性能与其VLA性能之间没有明显的相关性。这表明,VLA操作任务所需的能力与现有基准所衡量的能力之间存在显著差距。
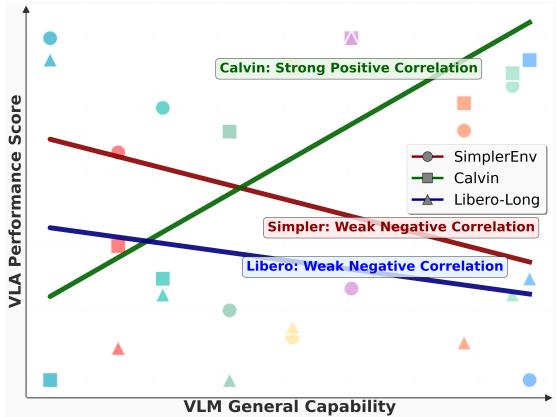
图3:通用视觉语言模型能力与VLA性能之间线性关系的比较。
ing 视觉问答基准。关于图3的更多细节可参见附录A.4。
4.2 不同VLM辅助任务对VLA性能的影响
近期研究提出利用机器人数据构建视觉问答数据集以改进视觉语言模型主干网络,例如Robobrain(Team,2025)。然而,很少有研究探讨这种额外的持续微调是否真正有利于视觉语言动作模型在下游任务中的表现。在本节中,我们为视觉语言模型构建或收集了若干监督微调任务,包括视觉问答数据集和一个生成任务。我们首先微调Qwen2.5VL模型,随后将每个微调后的视觉语言模型作为我们VLM4VLA框架的主干网络,并在Calvin基准上评估其性能。具体而言,我们比较了以下微调后的视觉语言模型(关于监督微调数据集的更多细节可参见附录A.6):
Robopoint(Yuan等,2024)一个在模拟器中收集的指向任务数据集。给定一幅图像和一个目标位置,模型需要输出满足目标要求的二维坐标。此微调数据集包含143.2万个样本。微调后,Qwen2.5VL-3B在指向任务测试集上的性能提升了 ∼20%\sim 20\%∼20%
Vica-332k(Feng,2025)一个从RGB-D数据集构建的空间理解问答数据集。它涵盖了广泛的能力,包括尺寸估计、位置理解、距离估计等。在此数据集上对Qwen2.5VL-3B进行微调后,我们在VSI-Bench(Yang等,2025)上取得了 ∼15%\sim 15\%∼15% 的性能提升。
Bridgevqa 我们使用VQASynth对来自Bridge-v2、Fractal和Calvin ABC的数据进行标注,并将其组合成一个空间理解问答数据集。主要的问答内容包括判断两个对象之间的距离、尺寸和深度。
Robo2v1m(Chen等,2025b)一个基于17.6万条真实机器人轨迹构建的面向动作的问答数据集,包含66.7万视觉问答对。它涉及多视角理解、成功预测、位置管理和轨迹判断等任务。在该数据集上微调Qwen2.5VL-3B后,我们在其测验集上实现了 60%60\%60% 的性能提升。
第009/23页(英文原文)
Robobrain2 (Team, 2025) A large-scale embodied VQA dataset and a VLM finetuned on Qwen2.5VL-7B. The tasks include pointing, planning, and marking trajectory. We directly use their finetuned VLM as the backbone for our VLM4VLA.
Omni-Generation We integrate a diffusion model into Qwen2.5VL-7B and train on both image generation, depth map generation, and semantic segmentation map generation tasks together with general VQA tasks (refer to Qwen-VLo). We use the resulting VLM part as the backbone for VLM4VLA.
VQA-Mix We mix the aforementioned VQA datasets with other large-scale general data to finetune Qwen2.5VL-7B.
Figure 4 presents the performance of the various finetuned VLMs. Overall, all models underperform the original baseline, with most exhibiting a slight degradation in performance and an obvious increase in variance. For Qwen2.5VL-3B, the model finetuned on Vica332k performs better than those finetuned on other datasets. This could be attributed to the dataset’s broad data coverage and diverse task types, which may prevent the model from overfitting to a narrow set of capabilities and consequently degrading others. For Qwen2.5VL-7B, the VQA-Mix model shows the least performance degradation, achieving results nearly identical to the baseline. This suggests that general-purpose VQA data plays a crucial role during embodiment-focused finetuning, further implying that VLAs may require broad, general capabilities, beyond just embodied skills, to perform well on downstream tasks.
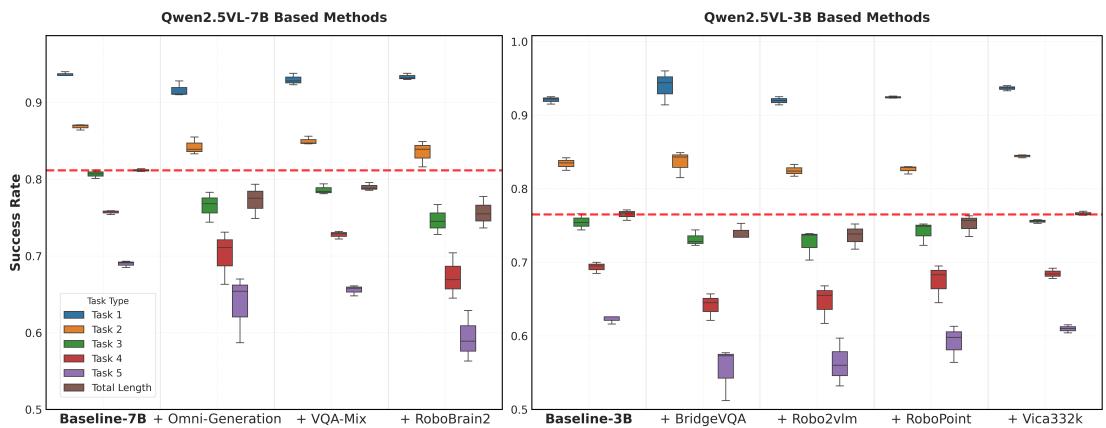
Figure 4: Performance of different auxiliary VLM finetune tasks. The Total Length dimension is scaled by a factor of 5 to normalize it to the range [0, 1]. The results for the VLAs trained under each task and for each gradient steps (10k, 15k, 20k, 25k and 30k) are rendered as box plots to provide a view of the impact of different tasks on the VLA’s performance and stability.
It is also worth noting that finetuning with generation tasks (i.e., Omni-Generation on Qwen2.5VL-7B), such as depth and semantic map prediction, did not yield performance benefits. This may indicate that simply introducing generation tasks or dense 3D-aware tasks into VLM finetuning process does not provide a tangible advantage for the VLA. Similarly, Robobrain2, positioned as a general-purpose embodied brain, also underperformed the baseline in our VLM4VLA tests. This suggest that existing embodied VQA-style tasks do not offer a clear benefit for training end-to-end VLAs to execute downstream manipulation tasks. A more in-depth experimental analysis can be found in Sec. 4.4.
4.3 IMPORTANCE OF DIFFERENT VLM MODULES
Table 3 shows the performance of three models when the vision encoder and word embeddings are frozen during VLM4VLA training. We observe a significant performance degradation for all models on both the Calvin and Simpler benchmarks after freezing the vision encoder, with this drop being particularly pronounced for the Paligemma models. In the case of Qwen2 .5VL-7B, the vision encoder accounts for 0.7B parameters. When it is frozen, the total number of tunable parameters is still a substantial 7.6B, which is much larger than 3.8B in Qwen2 .5VL-3B. However,
第009/23页(中文翻译)
Robobrain2(Team,2025)一个大规模具身视觉问答数据集以及一个基于Qwen2.5VL-7B微调的视觉语言模型。任务包括指向、规划和标记轨迹。我们直接使用他们微调后的视觉语言模型作为我们VLM4VLA的骨干模型。
Omni-Generation 我们将一个扩散模型集成到 Qwen2.5VL-7B 中,并同时在图像生成、深度图生成、语义分割图生成任务以及通用视觉问答任务(参见 Qwen-VLo)上进行训练。我们将得到的视觉语言模型部分用作 VLM4VLA 的骨干。
VQA-Mix 我们将上述 VQA 数据集 与其他大规模通用数据混合,以对 Qwen2.5VL-7B 进行微调。
图4展示了各种经过微调的视觉语言模型的性能。总体而言,所有模型的表现均不及原始基线,大多数模型性能略有下降,且方差明显增加。对于Qwen2.5VL-3B,在Vica332k上微调的模型表现优于在其他数据集上微调的模型。这可能归因于该数据集广泛的数据覆盖面和多样化的任务类型,这或许能防止模型过度适应狭窄的能力集,从而导致其他能力下降。对于Qwen2.5VL-7B,VQA-Mix模型显示出最小的性能下降,其结果几乎与基线相同。这表明通用目的的视觉问答数据在以具身化为重点的微调过程中起着至关重要的作用,进一步暗示视觉语言动作模型可能需要广泛、通用的能力,而不仅仅是具身技能,才能在下游任务中表现出色。
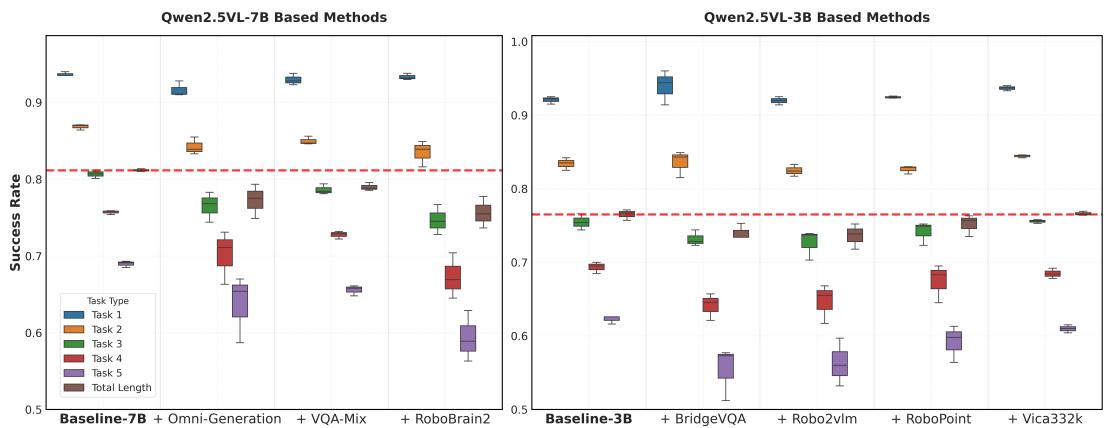
图4:不同辅助视觉语言模型微调任务的性能。总长度维度按5倍缩放以归一化至[0,1]范围。每个任务下训练的视觉语言动作模型及其每个梯度步数(10k、15k、20k、25k和30k)的结果均以箱线图呈现,以展示不同任务对视觉语言动作模型性能和稳定性的影响。
同样值得注意的是,使用生成任务(例如在Qwen2.5VL-7B上进行的Omni-Generation,如深度和语义图预测)进行微调并未带来性能优势。这可能表明,仅仅在视觉语言模型微调过程中引入生成任务或密集的3D感知任务,并不能为视觉语言动作模型提供实质性的优势。类似地,定位为通用具身大脑的Robobrain2,在我们的VLM4VLA测试中也表现不及基线。这表明现有的具身视觉问答式任务,并未为训练端到端视觉语言动作模型以执行下游操作任务提供明显益处。更深入的实验分析见第4.4节。
4.3 不同视觉语言模型模块的重要性
表3展示了在VLM4VLA训练期间冻结视觉编码器和词嵌入时,三种模型的性能表现。我们观察到,在冻结视觉编码器后,所有模型在Calvin和Simpler基准测试上的性能均显著下降,这一下降对于Paligemma模型尤为明显。以Qwen2.5VL-7B为例,其视觉编码器占用了0.7B参数。当它被冻结时,可训练参数总数仍有7.6B之多,远高于Qwen2.5VL-3B的3.8B。然而,
第010/23页(英文原文)
the performance of the frozen Qwen2.5VL-7B is not only significantly worse than its fully finetuned counterpart but also substantially underperforms the fully finetuned Qwen2.5VL-3B.
Table 3: Influence of freezing vision encoder and word embeddings of VLMs
| Size | Calvin ABC-D↑ | SimplerBridge↑ | |
| Qwen2.5VL-3B | 3.8B | 3.856 | 48.00 |
| + freeze vision encoder | 3.1B | 2.855 (-1.001) | 23.95 (-24.05) |
| + freeze word embedding | 3.4B | 3.849 (-0.007) | 46.88 (-1.12) |
| Qwen2.5VL-7B | 8.3B | 4.057 | 46.75 |
| + freeze vision encoder | 7.6B | 2.823 (-1.234) | 25.50 (-21.25) |
| + freeze word embedding | 7.8B | 3.874 (-0.183) | 48.96 (+2.21) |
| Paligemma-1 | 2.9B | 3.506 | 55.25 |
| + freeze vision encoder | 2.5B | 0.495 (-3.011) | 13.25 (-42.00) |
| + freeze word embedding | 2.7B | 3.485 (-0.021) | 52.25 (-3.00) |
In contrast to the vision-related findings, the ablation on word embeddings shows a different pattern: whether the word embeddings are trained or kept fixed has no noticeable impact on VLA performance.
This finding strongly suggests that finetuning the vision encoder is crucial when adapting a VLM into a VLA, and that the impact of this module can be more significant than merely increasing the number of trainable parameters in the language model. A potential reason for this phenomenon is that the VLM’s pre-trained vision encoder is not well-aligned with the visual domain of embodied scenes. The model likely requires significant adaptation of its vision module to effectively process and align with the visual signals from these novel environments. In the next section (Sec. 4.4), we present additional experiments to hypothesize and validate why the vision component is crucial—an inquiry we also view as a promising direction for future research.
4.4 ANALYSIS OF THE VISUAL GAP BETWEEN VLM AND VLA
In Sec. 4.3, we observe that, relative to other VLM components, the vision encoder has an especially pronounced impact on VLA performance. This indicates a substantial mismatch between the intrinsic visual representations learned by VLMs pretrained on large-scale web image-text corpora and the visual signals required in manipulation settings. By analyzing the characteristics of these two task families, we hypothesize that the visual gap may stem from the following two factors:
- Real images vs. simulated renderings (Real to Sim): During pretraining, VLMs are exposed to relatively few tabletop simulation renderings. As a result, the vision encoder (e.g., ViT) may lack effective high-level semantic representations for simulated images encountered in manipulation.
- Vision-language understanding vs. low-level action control: The visual features encoded by the VLM’s vision encoder are better aligned with language-output objectives typical of QA-style tasks, whereas low-level action control in robotics requires different visual cues and representations.
The existence of the real-to-sim gap in point (1) is evident, but it does not fully explain our results across the three simulation-based experiments. Specifically, consider the findings on Simpler-Bridge: we fine-tune the VLA on the real-world BridgeV2 Walke et al. (2023) dataset and evaluate in simulation, yet freezing the vision encoder still leads to a marked drop in performance. This suggests that factor (2) is also likely a key contributor—namely, the need to learn control-specific information (such as low-level actions) that is not captured during general web-scale pretraining. Therefore, we conduct a new experiment to address this question: Does the vision encoder require fine-tuning merely to bridge the visual gap (Real →\rightarrow→ Sim), or is there a mismatch between VLM understanding features and robot control features?
We utilize the BridgeV2 dataset, which consists entirely of real-world images. Following the procedure in Sec. 4.2, we introduce a new VLM fine-tuning task to inject the control-related information into the VLM backbone on real-world images. Inspired by Intelligence et al. (2025); Driess et al. (2025), we encode BridgeV2 actions into discrete tokens using Fast-Token Pertsch et al.
第010/23页(中文翻译)
冻结版的Qwen2.5VL-7B的性能不仅显著低于其完全微调的版本,也大幅落后于完全微调的 Qwen2.5VL-3B。
表3:冻结视觉语言模型的视觉编码器与词嵌入的影响
| Size | Calvin ABC-D↑ | SimplerBridge↑ | |
| Qwen2.5VL-3B | 3.8B | 3.856 | 48.00 |
| +冻结视觉编码器 | 3.1B | 2.855 (-1.001) | 23.95 (-24.05) |
| +冻结词嵌入 | 3.4B | 3.849 (-0.007) | 46.88 (-1.12) |
| Qwen2.5VL-7B | 8.3B | 4.057 | 46.75 |
| +冻结视觉编码器 | 7.6B | 2.823 (-1.234) | 25.50 (-21.25) |
| +冻结词嵌入 | 7.8B | 3.874 (-0.183) | 48.96 (+2.21) |
| Paligemma-1 | 2.9B | 3.506 | 55.25 |
| +冻结视觉编码器 | 2.5B | 0.495 (-3.011) | 13.25 (-42.00) |
| +冻结词嵌入 | 2.7B | 3.485 (-0.021) | 52.25 (-3.00) |
与视觉相关的发现相反,词嵌入的消融实验显示出不同的模式:词嵌入是否经过训练或保持固定,对VLA性能没有明显影响。
这一发现有力地表明,在将视觉语言模型适配为视觉语言动作模型时,微调视觉编码器至关重要,并且该模块的影响可能比仅仅增加语言模型中的可训练参数更为显著。造成此现象的一个潜在原因是,视觉语言模型预训练的视觉编码器与具身场景的视觉领域没有很好地对齐。模型很可能需要对其视觉模块进行重大调整,以有效处理并与这些新环境中的视觉信号对齐。在下一节(第4.4节)中,我们将展示额外的实验来假设并验证为何视组件如此关键——我们认为这一探究也是未来研究的一个有前景的方向。
4.4 VLM与VLA之间的视觉差距分析
在第4.3节中,我们观察到,相对于其他VLM组件,视觉编码器对VLA性能的影响尤为显著。这表明,在大规模网络图像-文本语料库上预训练的VLM所习得的内在视觉表示,与操控场景中所需的视觉信号之间存在严重的不匹配。通过分析这两类任务家族的特征,我们假设视觉差距可能源于以下两个因素:
- 真实图像 vs. 模拟渲染(真实到模拟):在预训练期间,视觉语言模型接触到的桌面模拟渲染相对较少。因此,视觉编码器(例如 ViT)可能缺乏针对操控任务中遇到的模拟图像的有效高层语义表示。
- 视觉语言理解 vs. 低层动作控制:由视觉语言模型的视觉编码器编码的视觉特征,更契合问答式任务典型的语言输出目标,而机器人学中的低层动作控制则需要不同的视觉线索和表示。
第(1)点中现实到仿真差距的存在是显而易见的,但它并不能完全解释我们在三个基于模拟的实验中的结果。具体来说,考虑关于 Simpler-Bridge 的发现:我们在真实世界的 BridgeV2 Walke 等(2023)数据集上对视觉语言动作模型进行微调,并在模拟环境中评估,但冻结视觉编码器仍然会导致性能显著下降。这表明因素(2)很可能也是一个关键原因——即需要学习在通用网络规模预训练期间未捕获的、控制特定的信息(例如低层动作)。因此,我们进行了一项新的实验来解决这个问题:视觉编码器需要微调仅仅是为了弥合视觉差距(真实 →\rightarrow→ 模拟),还是说 VLM 理解特征与机器人控制特征之间存在不匹配?
我们使用完全由真实世界图像组成的BridgeV2数据集。遵循第4.2节中的流程,我们引入了一个新的VLM微调任务,以将控制相关信息注入到真实世界图像上的VLM主干网络中。受Intelligence等(2025);Driess等(2025)的启发,我们使用Fast-Token Pertsch等的方法将BridgeV2动作编码为离散词元。
第011/23页(英文原文)
Table 4: Impact of injecting action information during VLM fine-tuning on VLA performance. We compare three settings of VLM finetuning: 1. Baseline: without finetuning the VLM at all; 2. Freeze Vision FT: Fine-tuning only the LLM (keeping the vision encoder frozen); 3. Unfreeze Vision FT: Fine-tuning both the LLM and the vision encoder. These modified VLM backbones are then trained into a standard VLM4VLA policy with frozen or unfrozen vision encoder.
| Qwen3VL-4B | SimplerBridge↑ | Qwen3VL-4B | SimplerBridge↑ |
| Freeze vision encoder during training VLA | Unfreeze vision encoder during training VLA | ||
| Baseline | 27.6 | Baseline | 56.3 |
| Freeze Vision FT | 28.0 (+0.4) | Freeze Vision FT | 56.3 (+0.0) |
| Unfreeze Vision FT | 45.7 (+18.1) | Unfreeze Vision FT | 59.4 (+3.1) |
(2025) and fine-tuned Qwen3VL-4B to predict these action tokens autoregressively (formatting it as a QA task). We then either freeze or unfreeze the vision encoder during VLM fine-tuning, and use the fine-tuned VLM as the backbone initialization for VLA training (also freeze or unfreeze the vision encoder). The test results are shown in the table below.
The results reveal a critical insight. Even when training on real-world images (where there is no sim-to-real visual gap), keeping the vision encoder frozen (Row Freeze Vision FTFTFT ) fails to improve downstream performance. The VLM’s native visual features—despite being real-world are insufficient for control. When we allow the vision encoder to update on real-world control data (Row Unfreeze Vision FTFTFT ), performance improves dramatically. This demonstrates that the necessity of fine-tuning the vision encoder is not primarily a confounding variable caused by simulation artifacts. Instead, we consider it be driven by a semantic gap: the visual features optimized for multimodal understanding or reasoning are not inherently aligned with the fine-grained representations required for low-level manipulation, regardless of whether the images are real or simulated.
Interestingly, this conclusion also partially explains the phenomena observed in Sec. 4.2—namely, why various embodied VQA tasks, whether designed in simulation or in the real world, fail to improve a VLM’s performance on VLA.
However, the visual gap between VLMs and VLAs does not imply that VLM pretraining is unhelpful for VLAs. In Table 8 of the Appendix A.2.5, we observe that training VLAs from scratch leads to performance collapse on Calvin and Simpler, indicating that VLM pretraining is crucial for VLA generalization. Integrating the above analysis, we arrive at the conclusion illustrated in Figure 5. From a feature-learning perspective, the overall spatial direction of representation learning in VLM training broadly aligns with that of VLA training. Nevertheless, around a certain point in training, the two trajectories diverge into different regions, which gives rise to the latent gap currently observed between VLMs and VLAs. This explains
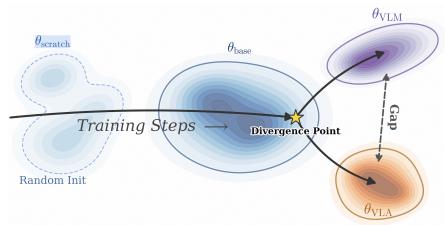
Figure 5: During learning, VLMs and VLAs initially follow the same trajectory. At a certain timestep, they diverge into different regions that cause the gap.
why VLM pretraining is indispensable for VLAs, yet a pronounced gap persists between the two.
5 CONCLUSIONS
In this paper, we investigated the impact of various VLMs—including the effect of auxiliary fine-tuning tasks—on the performance of VLA models. Through over 100 training and evaluation experiments conducted across three distinct environments, we assessed the capabilities of nine models and eight categories of auxiliary data for executing manipulation tasks. Our findings offer practical recommendations and a performance reference for the community. A core insight from our study is the significant gap between the capabilities of current VLMs and the demands of VLA embodied tasks. Specifically, we observe a notable discrepancy between a VLM’s performance on standard VQA benchmarks and its actual effectiveness when deployed in a VLA.
第011/23页(中文翻译)
表4:在视觉语言模型微调期间注入动作信息对视觉语言动作模型性能的影响。我们比较了视觉语言模型微调的三种设置:1. 基线:完全不微调视觉语言模型;2. 冻结视觉微调:仅微调大语言模型(保持视觉编码器冻结);3. 解冻视觉微调:同时微调大语言模型和视觉编码器。这些修改后的VLM主干网络随后被训练成标准的VLM4VLA策略,视觉编码器处于冻结或解冻状态。
| Qwen3VL-4B | SimplerBridge↑ | Qwen3VL-4B | SimplerBridge↑ |
| 冻结视觉编码器在训练视觉语言动作模型期间 | 解冻视觉编码器在训练视觉语言动作模型期间 | ||
| 基线 | 27.6 | 基线 | 56.3 |
| 冻结视觉微调 | 28.0 (+0.4) | 冻结视觉微调 | 56.3 (+0.0) |
| 解冻视觉编码器微调 | 45.7 (+18.1) | 解冻视觉编码器微调 | 59.4 (+3.1) |
(2025) 并微调Qwen3VL-4B以自回归地预测这些动作词元(将其格式化为一个问答任务)。随后,我们在VLM微调期间冻结或解冻视觉编码器,并将微调后的VLM用作VLA训练的主干网络初始化(同样冻结或解冻视觉编码器)。检查结果如下表所示。
结果揭示了一个关键洞察。即使在真实世界图像上进行训练(此时不存在仿真到现实视觉差距),保持视觉编码器冻结(行冻结视觉编码器微调)也无法提升下游性能。视觉语言模型的原生视觉特征——尽管是真实世界的——对于控制任务来说仍然不足。当我们允许视觉编码器在真实世界控制数据上更新时(行解冻视觉编码器微调),性能得到显著提升。这表明,对视觉编码器进行微调的必要性并非主要由仿真伪影这一混淆变量所导致。相反,我们认为其驱动力在于语义差距:为多模态理解或推理而优化的视觉特征,与底层操控所需的细粒度表征之间,天生就存在不对齐,无论图像是真实的还是模拟的。
有趣的是,这一结论也部分解释了第4.2节中观察到的现象——即为什么各种具身视觉问答任务,无论是在模拟中还是现实世界中设计的,都未能提升视觉语言模型在视觉语言动作模型上的性能。
然而,视觉语言模型与视觉语言动作模型之间的视觉差距并不意味着视觉语言模型预训练对视觉语言动作模型没有帮助。在附录A.2.5的表8中,我们观察到,从头开始训练视觉语言动作模型会导致其在Calvin和Simpler上的性能崩溃,这表明视觉语言模型预训练对于视觉语言动作模型的泛化至关重要。综合以上分析,我们得出了如图5所示的结论。从特征学习视角来看,视觉语言模型训练中的表征学习总体空间方向与视觉语言动作模型训练的方向大体一致。然而,在训练到某个阶段附近,这两条轨迹会分叉进入不同的区域,从而产生了当前在视觉语言模型与视觉语言动作模型之间观察到的潜在差距。这就解释了为什么视觉语言模型预训练对视觉语言动作模型不可或缺,但纯
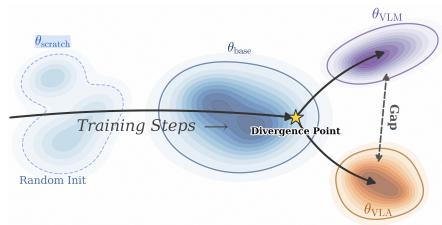
图5:在学习过程中,视觉语言模型和视觉语言动作模型最初遵循相同的轨迹在某个时间步,它们会分叉进入不同的区域,从而导致了差距。
两者之间依然存在明显的差距。
5结论
在本文中,我们研究了各种视觉语言模型——包括辅助微调任务的影响——对视觉语言动作模型性能的影响。通过在三个不同的环境中进行了超过100次训练和评估实验,我们评估了九个模型和八类辅助数据执行操作任务的能力。我们的发现为社区提供了实用的建议和性能参考。我们研究的一个核心见解是,当前视觉语言模型的能力与视觉语言动作模型具身任务的需求之间存在显著差距。具体来说,我们观察到视觉语言模型在标准视觉问答基准上的表现与其在视觉语言动作模型中实际部署时的有效性之间存在明显差异。
第012/23页(英文原文)
A limitation of our work is the absence of experiments on physical robots. This decision was motivated by challenges related to fairness and reproducibility, as well as difficulties in ensuring test efficiency and fairness across physical hardware setups. We conducted an in-depth experimental analysis of the Real-to-Sim gap and found that the visual discrepancy between VLMs and VLAs likely arises from the inherent heterogeneity between vision-language tasks and low-level action control tasks, rather than merely from a simple image-level sim-to-real gap. This issue is universal across both simulation and real-robot settings. From this perspective, while real-world deployment remains the ultimate goal, we believe that our comprehensive results across multiple, diverse simulation benchmarks provide valuable insights that can inspire and guide future research in this area.
REFERENCES
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report. arXiv preprint arXiv:2511.21631, 2025a.
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923, 2025b.
Lucas Beyer, Andreas Steiner, André Susano Pinto, Alexander Kolesnikov, Xiao Wang, Daniel Salz, Maxim Neumann, Ibrahim Alabdulmohsin, Michael Tschannen, Emanuele Bugliarello, et al. Paligemma: A versatile 3b vlm for transfer. arXiv preprint arXiv:2407.07726, 2024.
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. pi_0pi\_0pi_0 : A vision-language-action flow model for general robot control. arXiv preprint arXiv:2410.24164, 2024.
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choromanski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. arXiv preprint arXiv:2307.15818, 2023.
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brain Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. Spatialvlm: Endowing vision-language models with spatial reasoning capabilities. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 14455-14465, 2024.
Jiuhai Chen, Zhiyang Xu, Xichen Pan, Yushi Hu, Can Qin, Tom Goldstein, Lifu Huang, Tianyi Zhou, Saining Xie, Silvio Savarese, et al. Blip3-o: A family of fully open unified multimodal models-architecture, training and dataset. arXiv preprint arXiv:2505.09568, 2025a.
Kaiyuan Chen, Shuangyu Xie, Zehan Ma, and Ken Goldberg. Robo2vlm: Visual question answering from large-scale in-the-wild robot manipulation datasets, 2025b. URL https://arxiv.org/abs/2505.15517.
Xiaoyu Chen, Hangxing Wei, Pushi Zhang, Chuheng Zhang, Kaixin Wang, Yanjiang Guo, Rushuai Yang, Yucen Wang, Xinquan Xiao, Li Zhao, et al. Villa-x: enhancing latent action modeling in vision-language-action models. arXiv preprint arXiv:2507.23682, 2025c.
Can Cui, Pengxiang Ding, Wenxuan Song, Shuanghao Bai, Xinyang Tong, Zirui Ge, Runze Suo, Wanqi Zhou, Yang Liu, Bofang Jia, et al. Openhelix: A short survey, empirical analysis, and open-source dual-system via model for robotic manipulation. arXiv preprint arXiv:2505.03912, 2025.
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale N Fung, and Steven Hoi. Instructclip: Towards general-purpose vision-language models with instruction tuning. Advances in Neural Information Processing Systems, 36, 2024.
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, et al. Emerging properties in unified multimodal pretraining. arXiv preprint arXiv:2505.14683, 2025.
第012/23页(中文翻译)
我们工作的一个局限是缺少在物理机器人上的实验。这一决定是出于对公平性和可复现性相关挑战的考量,以及难以确保跨物理硬件配置的测验效率和公平性。我们对现实到仿真差距进行了深入的实验分析,发现视觉语言模型与视觉语言动作模型之间的视觉差异,很可能源于视觉语言任务与底层动作控制任务之间固有的异质性,而不仅仅是简单的图像级仿真正做到现实差距。这个问题在模拟和真实机器人环境中是普遍存在的。从这个角度来看,虽然现实世界部署仍是最终目标,但我们相信,我们在多个多样化的模拟基准上获得的全面结果,提供了宝贵的见解,能够启发和指导该领域的未来研究。
参考文献
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report. arXiv preprint arXiv:2511.21631, 2025a.
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923, 2025b.
Lucas Beyer, Andreas Steiner, André Susano Pinto, Alexander Kolesnikov, Xiao Wang, Daniel Salz, Maxim Neumann, Ibrahim Alabdulmohsin, Michael Tschannen, Emanuele Bugliarello, et al. Paligemma: A versatile 3b vlm for transfer. arXiv preprint arXiv:2407.07726, 2024.
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. pi_0pi\_0pi_0 : A vision-language-action flow model for general robot control. arXiv preprint arXiv:2410.24164, 2024.
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choromanski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. arXiv preprint arXiv:2307.15818, 2023.
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brain Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. Spatialvlm: Endowing vision-language models with spatial reasoning capabilities. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 14455-14465, 2024.
Jiuhai Chen, Zhiyang Xu, Xichen Pan, Yushi Hu, Can Qin, Tom Goldstein, Lifu Huang, Tianyi Zhou, Saining Xie, Silvio Savarese, et al. Blip3-o: A family of fully open unified multimodal models-architecture, training and dataset. arXiv preprint arXiv:2505.09568, 2025a.
Kaiyuan Chen, Shuangyu Xie, Zehan Ma, and Ken Goldberg. Robo2vlm: Visual question answering from large-scale in-the-wild robot manipulation datasets, 2025b. URL https://arxiv.org/abs/2505.15517.
Xiaoyu Chen, Hangxing Wei, Pushi Zhang, Chuheng Zhang, Kaixin Wang, Yanjiang Guo, Rushuai Yang, Yucen Wang, Xinquan Xiao, Li Zhao, et al. Villa-x: enhancing latent action modeling in vision-language-action models. arXiv preprint arXiv:2507.23682, 2025c.
Can Cui, Pengxiang Ding, Wenxuan Song, Shuanghao Bai, Xinyang Tong, Zirui Ge, Runze Suo, Wanqi Zhou, Yang Liu, Bofang Jia, et al. Openhelix: A short survey, empirical analysis, and open-source dual-system via model for robotic manipulation. arXiv preprint arXiv:2505.03912, 2025.
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale N Fung, and Steven Hoi. Instructclip: Towards general-purpose vision-language models with instruction tuning. Advances in Neural Information Processing Systems, 36, 2024.
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, et al. Emerging properties in unified multimodal pretraining. arXiv preprint arXiv:2505.14683, 2025.
第013/23页(英文原文)
Danny Driess, Jost Tobias Springenberg, Brian Ichter, Lili Yu, Adrian Li-Bell, Karl Pertsch, Allen Z Ren, Homer Walke, Quan Vuong, Lucy Xiaoyang Shi, et al. Knowledge insulating vision-language-action models: Train fast, run fast, generalize better. arXiv preprint arXiv:2505.23705, 2025.
Mengfei Du, Binhao Wu, Zejun Li, Xuanjing Huang, and Zhongyu Wei. Embsspatial-bench: Benchmarking spatial understanding for embodied tasks with large vision-language models. arXiv preprint arXiv:2406.05756, 2024.
Qi Feng. Towards visuospatial cognition via hierarchical fusion of visual experts. arXiv preprint arXiv:2505.12363, 2025.
Yanjiang Guo, Yucheng Hu, Jianke Zhang, Yen-Jen Wang, Xiaoyu Chen, Chaochao Lu, and Jianyu Chen. Prediction with action: Visual policy learning via joint denoising process. arXiv preprint arXiv:2411.18179, 2024.
Yanjiang Guo, Jianke Zhang, Xiaoyu Chen, Xiang Ji, Yen-Jen Wang, Yucheng Hu, and Jianyu Chen. Improving vision-language-action model with online reinforcement learning. arXiv preprint arXiv:2501.16664, 2025.
Yucheng Hu, Yanjiang Guo, Pengchao Wang, Xiaoyu Chen, Yen-Jen Wang, Jianke Zhang, Koushil Sreenath, Chaochao Lu, and Jianyu Chen. Video prediction policy: A generalist robot policy with predictive visual representations. arXiv preprint arXiv:2412.14803, 2024.
Chi-Pin Huang, Yueh-Hua Wu, Min-Hung Chen, Yu-Chiang Frank Wang, and Fu-En Yang. Thinkact: Vision-language-action reasoning via reinforced visual latent planning. arXiv preprint arXiv:2507.16815, 2025.
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. pi0.5: a vision-language-action model with open-world generalization. arXiv preprint arXiv:2504.16054, 2025.
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. Openvla: An open-source vision-language-action model. arXiv preprint arXiv:2406.09246, 2024.
Xinghang Li, Minghuan Liu, Hanbo Zhang, Cunjun Yu, Jie Xu, Hongtao Wu, Chilam Cheang, Ya Jing, Weinan Zhang, Huaping Liu, et al. Vision-language foundation models as effective robot imitators. arXiv preprint arXiv:2311.01378, 2023.
Xuanlin Li, Kyle Hsu, Jiayuan Gu, Karl Pertsch, Oier Mees, Homer Rich Walke, Chuyuan Fu, Ishikaa Lunawat, Isabel Sieh, Sean Kirmani, Sergey Levine, Jiajun Wu, Chelsea Finn, Hao Su, Quan Vuong, and Ted Xiao. Evaluating real-world robot manipulation policies in simulation. arXiv preprint arXiv:2405.05941, 2024.
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning. arXiv preprint arXiv:2306.03310, 2023.
Huaping Liu, Xinghang Li, Peiyan Li, Minghuan Liu, Dong Wang, Jirong Liu, Bingyi Kang, Xiao Ma, Tao Kong, and Hanbo Zhang. Towards generalist robot policies: What matters in building vision-language-action models. arXiv preprint arXiv:2412.14058, 2025.
Oier Mees, Lukas Hermann, Erick Rosete-Beas, and Wolfram Burgard. Calvin: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks. IEEE Robotics and Automation Letters (RA-L), 7(3):7327-7334, 2022.
Kun Ouyang, Yuanxin Liu, Haoning Wu, Yi Liu, Hao Zhou, Jie Zhou, Fandong Meng, and Xu Sun.
Spacer: Reinforcing mllms in video spatial reasoning. arXiv preprint arXiv:2504.01805, 2025.
Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, and Furu Wei. Kosmos-2: Grounding multimodal large language models to the world. arXiv preprint arXiv:2306.14824, 2023.
第013/23页(中文翻译)
Danny Driess, Jost Tobias Springenberg, Brian Ichter, Lili Yu, Adrian Li-Bell, Karl Pertsch, Allen Z Ren, Homer Walke, Quan Vuong, Lucy Xiaoyang Shi, et al. Knowledge insulating vision-language-action models: Train fast, run fast, generalize better. arXiv preprint arXiv:2505.23705, 2025.
Mengfei Du, Binhao Wu, Zejun Li, Xuanjing Huang, and Zhongyu Wei. EmbSpatial-bench: Benchmarking spatial understanding for embodied tasks with large vision-language models. arXiv preprint arXiv:2406.05756, 2024.
Qi Feng. Towards visuospatial cognition via hierarchical fusion of visual experts. arXiv preprint arXiv:2505.12363, 2025.
Yanjiang Guo, Yucheng Hu, Jianke Zhang, Yen-Jen Wang, Xiaoyu Chen, Chaochao Lu, and Jianyu Chen. Prediction with action: Visual policy learning via joint denoising process. arXiv preprint arXiv:2411.18179, 2024.
Yanjiang Guo, Jianke Zhang, Xiaoyu Chen, Xiang Ji, Yen-Jen Wang, Yucheng Hu, and Jianyu Chen. Improving vision-language-action model with online reinforcement learning. arXiv preprint arXiv:2501.16664, 2025.
Yucheng Hu, Yanjiang Guo, Pengchao Wang, Xiaoyu Chen, Yen-Jen Wang, Jianke Zhang, Koushil Sreenath, Chaochao Lu, and Jianyu Chen. Video prediction policy: A generalist robot policy with predictive visual representations. arXiv preprint arXiv:2412.14803, 2024.
Chi-Pin Huang, Yueh-Hua Wu, Min-Hung Chen, Yu-Chiang Frank Wang, and Fu-En Yang. Thinkact: Vision-language-action reasoning via reinforced visual latent planning. arXiv preprint arXiv:2507.16815, 2025.
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. pi0.5: a vision-language-action model with open-world generalization. arXiv preprint arXiv:2504.16054, 2025.
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. Openvla: An open-source vision-language-action model. arXiv preprint arXiv:2406.09246, 2024.
Xinghang Li, Minghuan Liu, Hanbo Zhang, Cunjun Yu, Jie Xu, Hongtao Wu, Chilam Cheang, Ya Jing, Weinan Zhang, Huaping Liu, et al. Vision-language foundation models as effective robot imitators. arXiv preprint arXiv:2311.01378, 2023.
Xuanlin Li, Kyle Hsu, Jiayuan Gu, Karl Pertsch, Oier Mees, Homer Rich Walke, Chuyuan Fu, Ishikaa Lunawat, Isabel Sieh, Sean Kirmani, Sergey Levine, Jiajun Wu, Chelsea Finn, Hao Su, Quan Vuong, and Ted Xiao. Evaluating real-world robot manipulation policies in simulation. arXiv preprint arXiv:2405.05941, 2024.
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning. arXiv preprint arXiv:2306.03310, 2023.
Huaping Liu, Xinghang Li, Peiyan Li, Minghuan Liu, Dong Wang, Jirong Liu, Bingyi Kang, Xiao Ma, Tao Kong, and Hanbo Zhang. Towards generalist robot policies: What matters in building vision-language-action models. arXiv preprint arXiv:2412.14058, 2025.
Oier Mees, Lukas Hermann, Erick Rosete-Beas, and Wolfram Burgard. Calvin: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks. IEEE Robotics and Automation Letters (RA-L), 7(3):7327-7334, 2022.
Kun Ouyang, Yuanxin Liu, Haoning Wu, Yi Liu, Hao Zhou, Jie Zhou, Fandong Meng, and Xu Sun.
Spacer: Reinforcing mllms in video spatial reasoning. arXiv preprint arXiv:2504.01805, 2025.
Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, and Furu Wei. Kosmos-2: Grounding multimodal large language models to the world. arXiv preprint arXiv:2306.14824, 2023.
第014/23页(英文原文)
Karl Pertsch, Kyle Stachowicz, Brian Ichter, Danny Driess, Suraj Nair, Quan Vuong, Oier Mees, Chelsea Finn, and Sergey Levine. Fast: Efficient action tokenization for vision-language-action models. arXiv preprint arXiv:2501.09747, 2025.
Krishan Rana, Jesse Haviland, Sourav Garg, Jad Abou-Chakra, Ian Reid, and Niko Suenderhauf. Sayplan: Grounding large language models using 3d scene graphs for scalable task planning. arXiv preprint arXiv:2307.06135, 2023.
Pierre Sermanet, Tianli Ding, Jeffrey Zhao, Fei Xia, Debidatta Dwibedi, Keerthana Gopalakrishnan, Christine Chan, Gabriel Dulac-Arnold, Sharath Maddineni, Nikhil J Joshi, et al. Robovqa: Multimodal long-horizon reasoning for robotics. In 2024 IEEE International Conference on Robotics and Automation (ICRA), pp. 645-652. IEEE, 2024.
Yide Shentu, Philipp Wu, Aravind Rajeswaran, and Pieter Abbeel. From llms to actions: Latent codes as bridges in hierarchical robot control. In 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 8539-8546. IEEE, 2024.
Hao Shi, Bin Xie, Yingfei Liu, Lin Sun, Fengrong Liu, Tiancai Wang, Erjin Zhou, Haoqiang Fan, Xiangyu Zhang, and Gao Huang. Memoryvla: Perceptual-cognitive memory in vision-language-action models for robotic manipulation. arXiv preprint arXiv:2508.19236, 2025.
Andreas Steiner, André Susano Pinto, Michael Tschannen, Daniel Keysers, Xiao Wang, Yonatan Bitton, Alexey Gritsenko, Matthias Minderer, Anthony Sherbondy, Shangbang Long, et al. Paligemma 2: A family of versatile vlms for transfer. arXiv preprint arXiv:2412.03555, 2024.
BAAI RoboBrain Team. Robobrain 2.0 technical report. arXiv preprint arXiv:2507.02029, 2025.
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothee Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
Homer Walke, Kevin Black, Abraham Lee, Moo Jin Kim, Max Du, Chongyi Zheng, Tony Zhao, Philippe Hansen-Estruch, Quan Vuong, Andre He, Vivek Myers, Kuan Fang, Chelsea Finn, and Sergey Levine. Bridgedata v2: A dataset for robot learning at scale. In Conference on Robot Learning (CoRL), 2023.
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265, 2025a.
Yuqi Wang, Xinghang Li, Wenxuan Wang, Junbo Zhang, Yingyan Li, Yuntao Chen, Xinlong Wang, and Zhaoxiang Zhang. Unified vision-language-action model. arXiv preprint arXiv:2506.19850, 2025b.
Junjie Wen, Yichen Zhu, Jinming Li, Zhibin Tang, Chaomin Shen, and Feifei Feng. Denvla: Vision-language model with plug-in diffusion expert for general robot control. arXiv preprint arXiv:2502.05855, 2025.
Jihan Yang, Shusheng Yang, Anjali W Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. Thinking in space: How multimodal large language models see, remember, and recall spaces. In Proceedings of the Computer Vision and Pattern Recognition Conference, pp. 10632-10643, 2025.
Wentao Yuan, Jiafei Duan, Valts Blukis, Wilbert Pumacay, Ranjay Krishna, Adithyavairavan Murali, Arsalan Mousavian, and Dieter Fox. Robopoint: A vision-language model for spatial affordance prediction for robotics. arXiv preprint arXiv:2406.10721, 2024.
Jianke Zhang, Yanjiang Guo, Xiaoyu Chen, Yen-Jen Wang, Yucheng Hu, Chengming Shi, and Jianyu Chen. Hirt: Enhancing robotic control with hierarchical robot transformers. arXiv preprint arXiv:2410.05273, 2024.
Jianke Zhang, Yanjiang Guo, Yucheng Hu, Xiaoyu Chen, Xiang Zhu, and Jianyu Chen. Up-vla: A unified understanding and prediction model for embodied agent. arXiv preprint arXiv:2501.18867, 2025a.
第014/23页(中文翻译)
Karl Pertsch, Kyle Stachowicz, Brian Ichter, Danny Driess, Suraj Nair, Quan Vuong, Oier Mees, Chelsea Finn, and Sergey Levine. Fast: Efficient action tokenization for vision-language-action models. arXiv preprint arXiv:2501.09747, 2025.
Krishan Rana, Jesse Haviland, Sourav Garg, Jad Abou-Chakra, Ian Reid, and Niko Suenderhauf. Sayplan: Grounding large language models using 3d scene graphs for scalable task planning. arXiv preprint arXiv:2307.06135, 2023.
Pierre Sermanet, Tianli Ding, Jeffrey Zhao, Fei Xia, Debidatta Dwibedi, Keerthana Gopalakrishnan, Christine Chan, Gabriel Dulac-Arnold, Sharath Maddineni, Nikhil J Joshi, et al. Robovqa: Multimodal long-horizon reasoning for robotics. In 2024 IEEE International Conference on Robotics and Automation (ICRA), pp. 645-652. IEEE, 2024.
Yide Shentu, Philipp Wu, Aravind Rajeswaran, and Pieter Abbeel. From llms to actions: Latent codes as bridges in hierarchical robot control. In 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 8539-8546. IEEE, 2024.
Hao Shi, Bin Xie, Yingfei Liu, Lin Sun, Fengrong Liu, Tiancai Wang, Erjin Zhou, Haoqiang Fan, Xiangyu Zhang, and Gao Huang. Memoryvla: Perceptual-cognitive memory in vision-language-action models for robotic manipulation. arXiv preprint arXiv:2508.19236, 2025.
Andreas Steiner, André Susano Pinto, Michael Tschannen, Daniel Keysers, Xiao Wang, Yonatan Bitton, Alexey Gritsenko, Matthias Minderer, Anthony Sherbondy, Shangbang Long, et al. Paligemma 2: A family of versatile vlms for transfer. arXiv preprint arXiv:2412.03555, 2024.
BAAI RoboBrain Team. Robobrain 2.0 technical report. arXiv preprint arXiv:2507.02029, 2025.
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothee Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
Homer Walke, Kevin Black, Abraham Lee, Moo Jin Kim, Max Du, Chongyi Zheng, Tony Zhao, Philippe Hansen-Estruch, Quan Vuong, Andre He, Vivek Myers, Kuan Fang, Chelsea Finn, and Sergey Levine. Bridgedata v2: A dataset for robot learning at scale. In Conference on Robot Learning (CoRL), 2023.
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265, 2025a.
Yuqi Wang, Xinghang Li, Wenxuan Wang, Junbo Zhang, Yingyan Li, Yuntao Chen, Xinlong Wang, and Zhaoxiang Zhang. Unified vision-language-action model. arXiv preprint arXiv:2506.19850, 2025b.
Junjie Wen, Yichen Zhu, Jinming Li, Zhibin Tang, Chaomin Shen, and Feifei Feng. Denvla: Vision-language model with plug-in diffusion expert for general robot control. arXiv preprint arXiv:2502.05855, 2025.
Jihan Yang, Shusheng Yang, Anjali W Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. Thinking in space: How multimodal large language models see, remember, and recall spaces. In Proceedings of the Computer Vision and Pattern Recognition Conference, pp. 10632-10643, 2025.
Wentao Yuan, Jiafei Duan, Valts Blukis, Wilbert Pumacay, Ranjay Krishna, Adithyavairavan Murali, Arsalan Mousavian, and Dieter Fox. Robopoint: A vision-language model for spatial affordance prediction for robotics. arXiv preprint arXiv:2406.10721, 2024.
Jianke Zhang, Yanjiang Guo, Xiaoyu Chen, Yen-Jen Wang, Yucheng Hu, Chengming Shi, and Jianyu Chen. Hirt: Enhancing robotic control with hierarchical robot transformers. arXiv preprint arXiv:2410.05273, 2024.
Jianke Zhang, Yanjiang Guo, Yucheng Hu, Xiaoyu Chen, Xiang Zhu, and Jianyu Chen. Up-vla: A unified understanding and prediction model for embodied agent. arXiv preprint arXiv:2501.18867, 2025a.
第015/23页(英文原文)
Jianke Zhang, Yucheng Hu, Yanjiang Guo, Xiaoyu Chen, Yichen Liu, Wenna Chen, Chaochao Lu, and Jianyu Chen. Unicod: Enhancing robot policy via unified continuous and discrete representation learning. arXiv preprint arXiv:2510.10642, 2025b.
Tony Z Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manipulation with low-cost hardware. arXiv preprint arXiv:2304.13705, 2023.
Ruijie Zheng, Yongyuan Liang, Shuaiyi Huang, Jianfeng Gao, Hal Daume III, Andrey Kolobov, Furong Huang, and Jianwei Yang. Tracevla: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies. arXiv preprint arXiv:2412.10345, 2024.
Enshen Zhou, Jingkun An, Cheng Chi, Yi Han, Shanyu Rong, Chi Zhang, Pengwei Wang, Zhongyuan Wang, Tiejun Huang, Lu Sheng, et al. Roborefer: Towards spatial referring with reasoning in vision-language models for robotics. arXiv preprint arXiv:2506.04308, 2025a.
Zhongyi Zhou, Yichen Zhu, Minjie Zhu, Junjie Wen, Ning Liu, Zhiyuan Xu, Weibin Meng, Ran Cheng, Yaxin Peng, Chaomin Shen, et al. Chatvla: Unified multimodal understanding and robot control with vision-language-action model. arXiv preprint arXiv:2502.14420, 2025b.
第015/23页(中文翻译)
Jianke Zhang, Yucheng Hu, Yanjiang Guo, Xiaoyu Chen, Yichen Liu, Wenna Chen, Chaochao Lu, and Jianyu Chen. Unicod: Enhancing robot policy via unified continuous and discrete representation learning. arXiv preprint arXiv:2510.10642, 2025b.
Tony Z Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manipulation with low-cost hardware. arXiv preprint arXiv:2304.13705, 2023.
Ruijie Zheng, Yongyuan Liang, Shuaiyi Huang, Jianfeng Gao, Hal Daume III, Andrey Kolobov, Furong Huang, and Jianwei Yang. Tracevla: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies. arXiv preprint arXiv:2412.10345, 2024.
Enshen Zhou, Jingkun An, Cheng Chi, Yi Han, Shanyu Rong, Chi Zhang, Pengwei Wang, Zhongyuan Wang, Tiejun Huang, Lu Sheng, et al. Roborefer: Towards spatial referring with reasoning in vision-language models for robotics. arXiv preprint arXiv:2506.04308, 2025a.
Zhongyi Zhou, Yichen Zhu, Minjie Zhu, Junjie Wen, Ning Liu, Zhiyuan Xu, Weibin Meng, Ran Cheng, Yaxin Peng, Chaomin Shen, et al. Chatvla: Unified multimodal understanding and robot control with vision-language-action model. arXiv preprint arXiv:2502.14420, 2025b.
第016/23页(英文原文)
A APPENDIX
A.1 MORE DETAILS ABOUT TESING ENVIRONMENTS
Calvin ABC-D Calvin is a simulation benchmark for various tabletop manipulation tasks. Its dataset consists of four splits (A, B, C, and D), each with different scene configurations (primarily changes in object and scene colors). During testing, the policy is required to complete a sequence of 1-5 tasks. To prevent larger models from merely overfitting to seen color schemes, we adopt the ABC-D setup, where the model is trained on scenes A, B, and C, and tested on scene D. This setup challenges the VLM’s ability to generalize to novel visual scenes. We train the model for 30k steps on the ABC splits and evaluate it on 1000 task sequences, each with a length of 5. We report the average number of successfully completed tasks per sequence.
SimplerEnv Bridge SimplerEnv is a suite of real-to-sim evaluation environments where the policy is trained on real-world data and tested in simulation. The test scenarios are divided into two categories based on the data source: Google Robot (Fractal) and WindowX (Bridge V2). The former has a smaller visual gap between the training and testing domains, where most policies perform well. To better differentiate the performance of various VLM-based policies, we choose the more challenging Bridge split as our evaluation metric. We train for 50k steps on BridgeV2, with validation every 5k steps (for a total of 10 checkpoints). During evaluation, we run 24 trials with random initializations for each of the four scenes (Pick Carrot, Pick Eggplant, Pick Spoon, and Stack Cube) and calculate the success rate. We report the best result from the validation checkpoints.
Libero-Long (-10) Libero is a simulation benchmark for multi-category manipulation tasks on a fixed tabletop, which contains five task suites. We select the most challenging suite, Libero-Long (also known as Libero-10), which consists of 10 long-horizon tasks involving a variety of objects, scenes, and manipulation types.
A.2 MORE IMPLEMENTATION DETAILS
A.2.1 TRAINING SETUPS
To ensure a fair comparison, we fine-tune the Vision-Language Model (VLM) and the action policy with identical hyperparameters and model configurations in each test environment. Specifically, all experiments of dense VLMs are conducted on 8 NVIDIA A100 GPUs. For Qwen3VL-30B-A3B, we take use of 32 NVIDIA A100 GPUs. All models use a single-view image of the current frame as its visual input and does not take state information as input, which prevents the model from directly learning actions from the state. We fine-tune all parameters of the VLM, including the vision encoder, token embeddings, and the LLM part. The detailed training hyperparameters are as follows:
- Calvin: We use a batch size of 128, a learning rate of 2×10−52 \times 10^{-5}2×10−5 for all models, and an action chunk size of 10.
- Simpler & Libero: We use a batch size of 512, a uniform learning rate of 5×10−55 \times 10^{-5}5×10−5 , and an action chunk size of 4.
A.2.2 ABOUT CHOICE OF HYPERPARAMETERS
Here, we provide additional details on hyperparameter choices (action chunk, learning rate, and batch size) and discuss the implications of using exactly the same hyperparameters across all methods.
For all reported results, we perform a sweep on different action chunk sizes during evaluation. We also use different checkpoints to mitigate the training instability. We report the best performance among these runs. In most cases, the best performance was achieved before the final checkpoint, indicating that the models had already converged. The protocol that uses the same hyperparameters ensures that our results reflect each model’s peak capability (convergence), effectively decoupling performance from training proficiency or randomness.
To verify the robustness of our Learning Rate (LR) choice, we performed a sweep using values {1e−5,2e−5,5e−5,1e−4}\{1e - 5,2e - 5,5e - 5,1e - 4\}{1e−5,2e−5,5e−5,1e−4} on representative models (Qwen2.5-VL-3B, Qwen2.5-VL-7B, and PaliGemma-1). As shown in the table below, while minor fluctuations exist, the downstream
第016/23页(中文翻译)
A附录
A.1 测试环境更多细节
Calvin ABC-D Calvin 是一个针对多种桌面操作任务的模拟基准。其数据集包含四个划分(A、B、C 和 D),每个划分都有不同的场景配置(主要是物体和场景颜色的变化)。在测验期间,策略需要完成一个包含 1 到 5 个任务的序列。为了防止更大的模型仅仅对见过的配色方案过拟合,我们采用 ABC-D 设置,即模型在场景 A、B 和 C 上进行训练,并在场景 D 上进行测试。此设置挑战了视觉语言模型泛化到新颖视觉场景的能力。我们在 ABC 划分上对模型进行 30k30 \mathrm{k}30k 步的训练,并在 1000 个任务序列(每个序列长度为 5)上对其进行评估。我们报告每个序列成功完成的任务的平均数量。
- SimplerEnv 跨链桥 SimplerEnv 是一套真实到模拟评估环境,其中策略在真实世界数据上进行训练,并在模拟中进行测试。测试场景根据数据来源分为两类:Google Robot (Fractal) 和 WindowX (跨链桥 V2)。前者在训练和测试领域之间的视觉差距较小,大多数策略在此表现良好。为了更好地区分各种基于视觉语言模型的策略的性能,我们选择更具挑战性的 Bridge 划分作为我们的评估指标。我们在 BridgeV2 上进行 50k 步的训练,每 5k 步进行一次验证(总共 10 个检查点)。在评估期间,我们对四个场景(Pick Carrot、Pick Eggplant、Pick Spoon 和 Stack Cube)分别运行 24 次随机初始化的试验,并计算成功率。我们报告验证检查点中的最佳结果。
Libero-Long(-10)Libero是一个用于固定桌面多类别操作任务的模拟基准,包含五个任务套件。我们选择了最具挑战性的套件Libero-Long(也称为Libero-10),它包含10个涉及多种对象、场景和操控类型的长视界任务。
A.2 更多实现细节
A.2.1 训练设置
为确保公平比较,我们在每个测试环境中使用相同的超参数和模型配置对视觉语言模型和动作策略进行微调。具体而言,所有稠密视觉语言模型的实验均在8块NVIDIA A100 GPU上进行。对于Qwen3VL-30B-A3B,我们使用了32块NVIDIA A100 GPU。所有模型均使用当前帧的单视角图像作为其视觉输入,并且不将状态信息作为输入,这防止了模型直接从状态中学习动作。我们微调了视觉语言模型的所有参数,包括视觉编码器、词元嵌入和大语言模型部分。详细的训练超参数如下:
- Calvin:我们使用128的批大小、 2×10−52 \times 10^{-5}2×10−5 的学习率(适用于所有模型),以及10的动作块大小。尺寸为10。
- Simpler & Libero:我们使用512的批大小、统一的 5×10−55 \times 10^{-5}5×10−5 学习率,以及4的动作块大小。
A.2.2关于超参数的选择
在此,我们提供关于超参数选择(动作块、学习率和批大小)的更多细节,并讨论在所有方法中使用完全相同超参数的意义。
对于所有报告的结果,我们在评估期间对不同动作块大小进行了扫描。我们还使用了不同的检查点以减轻训练不稳定性。我们报告这些运行中的最佳性能。在大多数情况下,最佳性能在最终检查点之前就已达成,这表明模型已经收敛。使用相同超参数的协议确保我们的结果反映了每个模型的峰值能力(收敛性),从而有效地将性能与训练熟练度或随机性解耦。
为验证我们选择的学习率(LR)的稳健性,我们使用 {1e−5,2e−5,5e−5,1e−4}\{1e - 5,2e - 5,5e - 5,1e - 4\}{1e−5,2e−5,5e−5,1e−4} 值在代表性模型(Qwen2.5-VL-3B、Qwen2.5-VL-7B和PaliGemma-1)上进行了扫描。如下表所示,虽然存在微小波动,但其下游
第017/23页(英文原文)
performance remains highly stable across this range, and the relative ranking of models remains consistent.
| Learning Rate | 1e-5 | 2e-5 | 5e-5 | 1e-4 |
| Qwen2.5VL-3B | 3.844 | 3.856 | 3.832 | 3.792 |
| Qwen2.5VL-7B | 4.050 | 4.057 | 4.027 | 3.986 |
| Palgemma-1 | 3.506 | 3.506 | 3.487 | 3.492 |
Table 5: Performance across learning rates on Calvin ABC-D.
Regarding batch size, we maximized this parameter uniformly across all models and make sure this stays the same. We believe that larger batch sizes benefit all architectures by stabilizing gradients; therefore, enforcing a large, identical batch size prevents any model from being disadvantaged by gradient noise.
A.2.3 LANGUAGE PROMPTS AND FORMAT
For fair comparison between different VLMs, we prompt all models with the simplest format of prompts while keeping consistent with the VLM’s pretraining prompt format. The detailed prompts for the different VLMs used in VLM4VLA are as follows (including special tokens). For convenience, here we use the robotic instruction pick up cube as an example of an input encoded in this manner.
Paligemma-1 & Paligemma-2
The Paligemma model employs a prefix-suffix encoding scheme during its pre-training. In this scheme, the prefix part is processed with bidirectional attention, while the suffix part uses unidirectional (causal) attention for generative tasks. The two parts are demarcated by a token. For our implementation, we adopt the prefix encoding scheme for image tokens and the suffix encoding scheme for text tokens, as this aligns with the model’s generative training objective.
⟨img⟩…⟨img⟩⟨bos⟩p i c k u p c u b e\n⟨A c t i o n Q u e r y⟩ \langle \mathrm {i m g} \rangle \dots \langle \mathrm {i m g} \rangle \langle \mathrm {b o s} \rangle \text {p i c k u p c u b e} \backslash \mathrm {n} \langle \text {A c t i o n Q u e r y} \rangle ⟨img⟩…⟨img⟩⟨bos⟩p i c k u p c u b e\n⟨A c t i o n Q u e r y⟩
Kosmos-2
Kosmos is a VLM optimized for grounding tasks, where its training sequences contain multiple task-specific tokens. Since the action output of a VLA is not a grounding task, we do not include these additional task tokens in our input. The expectation is that the model will automatically learn to leverage its skills acquired from other tasks during the fine-tuning process.
⟨s⟩⟨i m a g e⟩⟨img⟩…⟨img⟩⟨/i m a g e⟩⟨p⟩p i c k u p c u b e\n⟨/p⟩⟨A c t i o n Q u e r y⟩ \langle \mathrm {s} \rangle \langle \text {i m a g e} \rangle \langle \mathrm {i m g} \rangle \dots \langle \mathrm {i m g} \rangle \langle / \text {i m a g e} \rangle \langle \mathrm {p} \rangle \text {p i c k u p c u b e} \backslash \mathrm {n} \langle / \mathrm {p} \rangle \langle \text {A c t i o n Q u e r y} \rangle ⟨s⟩⟨i m a g e⟩⟨img⟩…⟨img⟩⟨/i m a g e⟩⟨p⟩p i c k u p c u b e\n⟨/p⟩⟨A c t i o n Q u e r y⟩
Qwen2.5VL (2 models) & Qwen3VL (4 models)
For the Qwen series of models, which are instruction-fine-tuned, general-purpose conversational models, an input format that closely mirrors their training would necessitate the inclusion of both system and user prompts. We therefore compared two distinct token concatenation schemes:
- Scheme 1 (Full Compliance): This approach strictly adheres to the instruction-SFT format. While this ensures maximum alignment with the model’s pre-training, it results in a longer input token sequence:
⟨∣im_start∣⟩\langle |\mathrm{im\_start}|\rangle⟨∣im_start∣⟩ system\nYou are a helpful assistant. ⟨∣im_end∣⟩\n\langle |\mathrm{im\_end}|\rangle \backslash \mathbf{n}⟨∣im_end∣⟩\n
⟨∣im_start∣⟩\langle |\mathrm{im\_start}|\rangle⟨∣im_start∣⟩ user\n<|vision_start|>img>What action should the robotic arm take to pick up cube<|im_end|>n
<|im_start|>assistant\t<n
- Scheme 2 (Simplified Consistency): This scheme aligns with the simplified approach we used for Kosmos and Paligemma. It omits the extraneous conversational prompts (e.g., system and user roles) and includes only the most essential special tokens required for sequence construction:
⟨∣im_start∣⟩⟨∣vision_start∣⟩⟨img⟩…⟨img⟩⟨∣vision_end∣⟩\langle |\mathrm{im\_start}|\rangle \langle |\mathrm{vision\_start}|\rangle \langle \mathrm{img}\rangle \dots \langle \mathrm{img}\rangle \langle |\mathrm{vision\_end}|\rangle⟨∣im_start∣⟩⟨∣vision_start∣⟩⟨img⟩…⟨img⟩⟨∣vision_end∣⟩ pick up cube\n
第017/23页(中文翻译)
性能在此范围内保持高度稳定,且各模型的相对排名保持一致。
| 学习率 | 1e-5 | 2e-5 | 5e-5 | 1e-4 |
| Qwen2.5VL-3B | 3.844 | 3.856 | 3.832 | 3.792 |
| Qwen2.5VL-7B | 4.050 | 4.057 | 4.027 | 3.986 |
| Paligemma-1 | 3.506 | 3.506 | 3.487 | 3.492 |
表5:不同学习率在Calvin ABC-D上的性能表现
关于批大小,我们将其在所有模型中统一最大化,并确保其保持不变。我们相信,更大的批尺寸通过稳定梯度使所有架构受益;因此,强制执行一个较大且相同的批大小可以防止任何模型因梯度噪声而处于劣势。
A.2.3 语言提示与格式
为了公平比较不同的视觉语言模型,我们使用最简单的提示格式来提示所有模型,同时保持与视觉语言模型预训练提示格式的一致性。VLM4VLA中使用的不同视觉语言模型的详细提示如下(包括特殊词元)。为方便起见,这里我们以机器人指令“拾取立方体”为例,说明以此方式编码的输入。
Paligemma-1与Paligemma-2
Paligemma 模型在其预训练期间采用前缀-后缀编码方案。在此方案中,前缀部分使用双向注意力处理,而后缀部分则使用单向(因果)注意力进行生成任务。两部分由 词元分隔。在我们的实现中,我们采用前缀编码方案处理图像代币,并采用后缀编码方案处理文本代币,因为这符合模型的生成训练目标。
<img>... <img><bos>pick up cube\n<ActionQuery>
Kosmos-2
Kosmos 是一个专为基础定位任务优化的视觉语言模型,其训练序列包含多个特定于任务的代币。由于视觉语言动作模型的输出不是基础定位任务,我们不在输入中包含这些额外的任务代币。期望模型能在微调过程中自动学会利用从其他任务中习得的技能。
$\langle \mathrm{s}\rangle$ <image> <img> . . . <img> </image> <p> pick up cube\n</p> <ActionQuery>
Qwen2.5VL(2个模型)与Qwen3VL(4个模型)
对于 Qwen 系列模型(它们是经过指令微调的通用对话模型),一个严格模仿其训练的输入格式需要同时包含系统和用户提示。因此,我们比较了两种不同的代币拼接方案:
- 方案1(完全合规):此方法严格遵守指令监督微调格式。虽然这确保了与模型预训练的最大对齐,但也导致了更长的输入代币序列:
<|im_start|>system\nYou are a helpful assistant. <|im_end|> \n
<|im_start|>user\n<|vision_start|> \langle img \rangle ... <img> <|vision_end|> What action should the 机械臂拿起立方体<|im end|> \n-
<|im_start|>assistant\n<动作查询>
- 方案2(简化一致性): 此方案与我们为Kosmos和PaliGemma使用的简化方法保持一致。它省略了多余的对话提示(例如,系统与用户角色),仅包含序列构建所需的最基本的特殊词元:
<|我启动|><|视觉开始|><图像>… <图像><|视觉结束|>拾取立方体\n<动作查询>
第018/23页(英文原文)
| Prompt | Calvin ABC-D↑ | SimplerBridge↑ | |
| Qwen2.5VL-3B | Long | 3.856 | 48.00 |
| Qwen2.5VL-3B | Short | 3.844 (-0.012) | 46.75 (-1.25) |
| Qwen2.5VL-7B | Long | 4.057 | 46.75 |
| Qwen2.5VL-7B | Short | 3.947 (-0.110) | 44.00 (-2.75) |
The comparison in Table 6 indicates that prompts perfectly matching the Supervised Fine-Tuning (SFT) format perform marginally better than their minimal counterparts. Consequently, we consistently apply the Scheme 1 prompt style to the QwenVL series in our remaining experiments to maintain alignment with their original training formats.
A.2.4 INFLUENCE OF IMAGE RESOLUTION
We investigate the impact of image resolution on the final performance. Besides the default settings of 224x224, we conduct higher-resolution experiments on Qwen2.5VL-3B and Qwen2.5VL-7B. Specifically, during VLA training, we set the input image resolution to 224, 512, and 768, respectively, and evaluated on the Calvin ABC-D task under both settings: freezing and not freezing the vision encoder. The results are as follows.
Table 6: Comparison between different prompt formats. Long prompt denotes Scheme 1, while the Short prompt denote the Scheme 2.
| 224x224 | 512x512 | 768x768 | |
| Qwen2.5VL-3B | 3.856 | 3.832 | 3.836 |
| + freeze vision encoder | 2.855 (-1.001) | 2.749 (-1.083) | 2.715 (-1.121) |
| Qwen2.5VL-7B | 4.057 | 4.062 | 3.998 |
| + freeze vision encoder | 2.823 (-1.234) | 2.746 (-1.316) | 2.693 (-1.305) |
Table 7: Comparison between different image resolution under freezing or unfreezing vision encoder.
As shown in the table, simply increasing the input resolution (from 224 to 768) did not significantly improve VLA performance when the encoder is fine-tuned. These results suggest that the necessity of fine-tuning is not merely a compensation for low resolution. However, the performance degradation caused by freezing the encoder became more pronounced at higher resolutions (e.g., the gap widens from -1.00 to -1.12 for the 3B model). A plausible explanation is that higher resolution and more frozen visual tokens may lead to spurious correlation, which incurs additional performance losses.
A.2.5 LOWER BOUND OF TRAINING FROM SCRATCH
To isolate the contribution of the VLM backbone, we establish a lower-bound baseline by training VLM4VLA variants entirely from random initialization. This clarifies whether the observed generalization stems from the architecture alone or from VLM pre-training. We train Qwen2.5-VL (3B and 7B) and PaliGemma from scratch on the Calvin ABC-D and Simpler-Bridge benchmarks. We strictly match the training hyperparameters and evaluation protocols reported in the main paper for all from-scratch runs.
As shown in Table 8, models trained from scratch exhibit substantial degradation across both benchmarks and all model sizes. This gap indicates that VLM pre-training is fundamental to the generalization ability of the VLA model, beyond architectural design. Training from scratch yields markedly lower performance, confirming that VLM pre-training is a prerequisite for strong downstream generalization in VLM4VLA.
A.2.6 IMPLEMENTATION DETAILS ABOUT VLM4VLA ARCHITECTURE
We provide the detailed model architecture in Table 9. We maintain a consistent architecture for the action-specific modules across all models, including a fixed number of learnable tokens and a
第018/23页(中文翻译)
| 提示 | Calvin ABC-D↑ | SimplerBridge↑ | |
| Qwen2.5VL-3B | Long | 3.856 | 48.00 |
| Qwen2.5VL-3B | 简短 | 3.844 (-0.012) | 46.75 (-1.25) |
| Qwen2.5VL-7B | Long | 4.057 | 46.75 |
| Qwen2.5VL-7B | 短文本 | 3.947 (-0.110) | 44.00 (-2.75) |
表6:不同提示格式的对比。长提示指方案1,而短提示指方案2。
表6中的比较表明,与监督微调(SFT)格式完全匹配的提示比其最简版本的表现略好。因此,在后续实验中,我们始终对QwenVL系列采用方案1的提示风格,以保持与其原始训练格式的一致性。
A.2.4 图像分辨率的影响
我们研究了图像分辨率对最终性能的影响。除了默认的224x224设置外,我们在Qwen2.5VL-3B和Qwen2.5VL-7B上进行了更高分辨率的实验。具体来说,在VLA训练期间,我们将输入图像分辨率分别设置为224、512和768,并在冻结和未冻结视觉编码器两种设置下,对Calvin ABC-D任务进行评估。结果如下。
| 224x224 | 512x512 | 768x768 | |
| Qwen2.5VL-3B | 3.856 | 3.832 | 3.836 |
| +冻结视觉编码器 | 2.855 (-1.001) | 2.749 (-1.083) | 2.715 (-1.121) |
| Qwen2.5VL-7B | 4.057 | 4.062 | 3.998 |
| +冻结视觉编码器 | 2.823 (-1.234) | 2.746 (-1.316) | 2.693 (-1.305) |
表7:视觉编码器冻结与未冻结状态下不同图像分辨率的比较。
如表所示,当编码器被微调时,仅仅增加输入分辨率(从224到768)并未显著提升VLA性能。这些结果表明,微调的必要性并不仅仅是为了补偿低分辨率。然而,冻结编码器导致的性能下降在更高分辨率下变得更加明显(例如,对于3B模型,差距从-1.00扩大到-1.12)。一个合理的解释是,更高的分辨率和更多被冻结的视觉令牌可能导致虚假相关性,从而带来额外的性能损失。
A.2.5从头开始训练的下限
为了分离VLM主干网络的贡献,我们通过完全从随机初始化开始训练VLM4VLA变体,建立了一个下限基线。这明确了观察到的泛化能力是仅源于架构本身,还是源于视觉-语言模型预训练。我们在Calvin ABC-D和Simpler-Bridge基准测试上,从头开始训练Qwen2.5-VL(3B和7B)和PaliGemma。对于所有从头开始的运行,我们严格匹配主论文中报告的训练超参数和评估协议。
如表8所示,从头开始训练的模型在两种基准测试和所有模型尺寸上都表现出显著的性能下降。这一差距表明,视觉-语言模型预训练对于VLA模型的泛化能力至关重要,超越了架构设计本身。从头训练会导致性能显著降低,这证实了视觉-语言模型预训练是VLM4VLA实现强大下游泛化能力的前提条件。
A.2.6 VLM4VLA 架构实现细节
我们在表9中提供了详细的模型架构。我们在所有模型中为动作特定模块保持了一致的架构,包括固定数量的可学习代币和一个
第019/23页(英文原文)
Table 8: Performance of training from scratch compared to pretrained initialization. We report absolute scores and the change (in parentheses) relative to pretrained models on Calvin ABC-D and Simpler-Bridge.
| Model | Calvin ABC-D | Simpler-Bridge |
| Qwen2.5VL-3B | 3.856 | 48.00 |
| + from scratch | 1.381 (-2.475) | 15.75 (-32.25) |
| Qwen2.5VL-7B | 4.057 | 46.75 |
| + from scratch | 1.769 (-2.288) | 18.20 (-28.75) |
| PaliGemma-1 | 3.506 | 55.25 |
| + from scratch | 1.129 (-2.377) | 14.50 (-40.75) |
uniform hidden size for the action head. Consequently, the variation in the number of additional trainable parameters is solely dependent on the VLM’s native hidden_size. The Policy Head architecture presented here omits the final linear layer, which maps the features to the action space (i.e., Linear(1024, 7)).
| VLM | Backbone Size | Policy Head Size | Learnable Tokens | LLM Hidden Size | Policy Head |
| Qwen2.5VL-3B | 3755M | 6.58M | 1 | 2048 | Linear(2048,1024)ReLULinear(1024,1024) |
| Qwen2.5VL-7B | 8292M | 11.69M | 1 | 3584 | Linear(3584,1792)ReLULinear(1792,1024) |
| Qwen3VL-2B | 2128M | 6.58M | 1 | 2048 | Linear(2048,1024)ReLULinear(1024,1024) |
| Qwen3VL-4B | 4437M | 8.02M | 1 | 2560 | Linear(2560,1280)ReLULinear(1280,1024) |
| Qwen3VL-8B | 8767M | 13.92M | 1 | 4096 | Linear(4096,2048)ReLULinear(2048,1024) |
| Qwen3VL-30B-A3B | 31071M | 6.58M | 1 | 2048 | Linear(2048,1024)ReLULinear(1024,1024) |
| Paligemma-1 | 2923M | 6.58M | 1 | 2048 | Linear(2048,1024)ReLULinear(1024,1024) |
| Paligemma-2 | 3032M | 7.27M | 1 | 2304 | Linear(2304,1502)ReLULinear(1502,1024) |
| KosMos-2 | 1664M | 6.58M | 1 | 2048 | Linear(2048,1024)ReLULinear(1024,1024) |
Table 9: Detailed architecture of different VLM4VLA backbones.
第019/23页(中文翻译)
表 8:从头训练与预训练初始化性能对比。我们报告绝对分数以及与 Calvin ABC-D 和 Simpler-Bridge 上预训练模型相比的变化(括号内)。
| 模型 | Calvin ABC-D | Simpler-Bridge |
| Qwen2.5VL-3B | 3.856 | 48.00 |
| +从头训练 | 1.381 (-2.475) | 15.75 (-32.25) |
| Qwen2.5VL-7B | 4.057 | 46.75 |
| +从零开始 | 1.769 (-2.288) | 18.20 (-28.75) |
| Palgemma-1 | 3.506 | 55.25 |
| +从头开始训练 | 1.129 (-2.377) | 14.50 (-40.75) |
动作头采用统一的隐藏层尺寸。因此,额外可训练参数数量的变化完全取决于视觉语言模型自身的隐藏层尺寸。此处展示的策略头架构省略了将特征映射到动作空间的最终线性层(即 Linear(1024, 7))。
| VLM | 主干网络规模 | 策略头Size | 可学习代币 | 大语言模型隐藏层Size | 策略头 |
| Qwen2.5VL-3B | 3755M | 6.58M | 1 | 2048 | 线性层(2048,1024)ReLU |
| 线性层(1024,1024) | |||||
| Qwen2.5VL-7B | 8292M | 11.69M | 1 | 3584 | 线性层(3584,1792)ReLU |
| 线性层(1792,1024) | |||||
| Qwen3VL-2B | 2128M | 6.58M | 1 | 2048 | 线性层(2048,1024)ReLU |
| 线性层(1024,1024) | |||||
| Qwen3VL-4B | 4437M | 8.02M | 1 | 2560 | 线性层(2560,1280)ReLU |
| 线性层(1280,1024) | |||||
| Qwen3VL-8B | 8767M | 13.92M | 1 | 4096 | 线性层(4096,2048)ReLU |
| 线性层(2048,1024) | |||||
| Qwen3VL-30B-A3B | 31071M | 6.58M | 1 | 2048 | 线性层(2048,1024)ReLU |
| 线性层(1024,1024) | |||||
| Paligemma-1 | 2923M | 6.58M | 1 | 2048 | 线性层(2048,1024)ReLU |
| 线性层(1024,1024) | |||||
| Paligemma-2 | 3032M | 7.27M | 1 | 2304 | 线性层(2304,1502)ReLU |
| 线性层(1502,1024) | |||||
| KosMos-2 | 1664M | 6.58M | 1 | 2048 | 线性层(2048,1024)ReLU |
| 线性层(1024,1024) |
表 9: 不同 VLM4VLA 骨干网络的详细架构。
第020/23页(英文原文)
A.3 IMPLEMENTATION AND EVALUATION DETAILS FOR THE PIO
Reproducing pi0 In our experiments, we reproduced the pi0 model to serve as a strong comparative baseline. We leveraged the model implementation from the official code released by Allen but excluded its proprioceptive input module. Specifically, we integrated the pi0 model architecture into the VLM4VLA data-loading and training framework for fine-tuning and evaluation. This model-only migration was a deliberate choice, as we observed that the data preprocessing strategies and pretraining data used in the original pi0 implementation were inconsistent with those of OpenVLA and our VLM4VLA framework, thus ensuring a fairer comparison.
Modification of the Proprioceptive State Expert We modified the state expert in pi˙0\mathsf{p}\dot{\mathsf{i}} 0pi˙0 by directly concatenating the outputs of the VLM expert and the action expert. Since the state and action experts in the original pi˙0\mathsf{p}\dot{\mathsf{i}} 0pi˙0 architecture share the same parameters, our modification only alters the model’s input pathway without changing its underlying structure or parameter count.
Evaluation Protocol During our experiments, we discovered that the Flow-matching loss used in pi0 leads to significant performance instability. Specifically, multiple rollouts of the same pi0 policy in an identical starting environment could yield success rate fluctuations as high as ±20%\pm 20\%±20% . In stark contrast, our VLM4VLA approach is deterministic under the same conditions, producing identical outcomes for each run without stochasticity. This high variance necessitated a more extensive evaluation rollouts for pi0 to obtain a reliable estimate of its true performance. Consequently, when testing pi0, we performed a greater number of rollouts for each checkpoint under various settings:
- Calvin: We averaged the results over 3 evaluation runs per model.
- Simpler: We performed 240 evaluation runs for each model on every task.
- Libero: We performed 250 evaluation runs for each model on every task.
A.4 CORRELATION ANALYSIS BETWEEN VLM CAPABILITY AND VLA PERFORMANCE
Here we provide a detailed explanation of how the data points in Figure 3 are obtained and what each graphical element represents.
- The x-axis represents the general capability of different VLMs.
- Each set of three vertically aligned points with the same color corresponds to the results of the same VLM used as the VLM4VLA backbone across three benchmarks.
- Marker shapes denote benchmarks: circles for SimplerEnv, triangles for LIBERO, and squares for CALVIN (see the legend on the right).
- The three colored lines are linear fits to the points from each benchmark: red for Simpler (fit over circle markers), blue for LIBERO (fit over triangle markers), and green for CALVIN (fit over square markers).
Figure 3 uses VLMs from data sourced from the experiments reported in Tables 1 and 2. We elaborate how we evaluate different VLMs in terms of their general capabilities. QwenVL are general-purpose VLMs that have been evaluated across a wide range of multimodal understanding benchmarks. We take the average of their officially reported results on a set of multimodal general, reasoning, text, grounding, agentic, and embodied benchmarks as the x-axis value. This set includes: MMBench v1.1 (en), MMStar, BLINK, HallusionBench, AI2D, OCRBench, MVBench, VideoMME, MMMU, MathVista, MathVision, CountBenchQA, RefCOCO (all), GPQA, OmniSpatial, RealWorldQA, ERQA, and VSI-Bench. For PaliGemma and Kosmos, which are not trained for general-purpose tasks, we use their performance on their respective specialized evaluation suites as the metric. Specifically, PaliGemma is evaluated on RefCOCO (all), AI2D, CountBenchQA, and GQA; Kosmos is a grounding-focused VLM, which uses only RefCOCO results as its metric. Because the latter two models are evaluated on a subset of the tasks used for the former two (reflecting their lack of general-task capability), we apply a downweighting to their scores. This yields an approximate assessment of the “general capability of different types of VLMs” as a reference.
To quantify the strength of the linear relationship between each benchmark and VLM capability, we report the correlation metrics for the three fitted lines (Pearson correlation coefficient rrr and R2R^2R2 ):
第020/23页(中文翻译)
A.3 PIO的实现与评估细节
复现pi0在我们的实验中,我们复现了pi0模型,以作为一个强有力的比较基线。我们利用了Allen官方发布的代码中的模型实现,但排除了其本体感知状态输入模块。具体来说,我们将pi0模型架构集成到VLM4VLA的数据加载和训练框架中进行微调和评估。这种仅迁移模型的做法是经过深思熟虑的选择,因为我们观察到原始pi0实现中使用的数据预处理策略和预训练数据与OpenVLA及我们的VLM4VLA框架不一致,从而确保了更公平的比较。
修改本体感知状态专家我们修改了pi0中的状态专家,改为直接拼接视觉语言模型专家和动作专家的输出。由于原始pi0架构中的状态专家和动作专家共享相同的参数,我们的修改只改变了模型的输入路径,而没有改变其底层结构或参数数量。
评估协议在实验过程中,我们发现pi0中使用的流匹配损失会导致显著的性能不稳定。具体而言,在相同的初始环境中对同一pi0策略进行多次 rollout,其成功率波动可能高达 ±20%\pm 20\%±20% 。与此形成鲜明对比的是,我们的VLM4VLA方法在相同条件下是确定性的,每次运行都会产生完全相同的结果,没有随机性。这种高方差要求我们必须为pi0进行更广泛的评估 rollout,以获得对其真实性能的可靠估计。因此,在测验pi0时,我们在各种设置下为每个检查点执行了更多次数的 rollout:
- Calvin:我们对每个模型进行了3次评估运行,并取结果的平均值。
- Simpler:我们在每个任务上为每个模型执行了240次评估运行。
- Libero:我们在每个任务上为每个模型执行了250次评估运行。
A.4视觉语言模型能力与视觉语言动作模型性能的相关性分析
在此,我们详细说明图3中的数据点是如何获得的,以及每个图形元素代表什么。
- 横轴代表了不同视觉语言模型的通用能力。
- 每组三个垂直对齐且颜色相同的点,对应着同一个用作VLM4VLA骨干网络的视觉语言模型在三个基准测试上的结果。
- 标记形状代表基准测试:圆形代表SimplerEnv,三角形代表LIBERO,正方形代表CALVIN(参见右侧图例)。
- 三条彩色线条是各基准测试数据点的线性拟合:红色代表Simpler(基于圆形标记拟合),蓝色代表LIBERO(基于三角形标记拟合),绿色代表CALVIN(基于正方形标记拟合)。
图3中使用的视觉语言模型数据来源于表1和表2所报告的实验。我们将详细阐述如何评估不同视觉语言模型的通用能力。QwenVL是通用视觉语言模型,已在广泛的多模态理解基准上进行过评估。我们取其在多模态通用、推理、文本、定位、智能体以及具身基准测试集上官方报告结果的平均值作为横轴值。该测试集包括:MMBench v1.1(英文)、MMStar、BLINK、HallusionBench、AI2D、OCRBench、MVBench、VideoMME、MMMU、MathVista、MathVision、CountBenchQA、RefCOCO(全部)、GPQA、OmniSpatial、RealWorldQA、ERQA以及VSI-Bench。对于PaliGemma和Kosmos这两种并非为通用任务训练的模型,我们使用其各自专门的评估套件上的性能作为度量指标。具体来说,PaliGemma在RefCOCO(全部)、AI2D、CountBenchQA和GQA上进行评估;Kosmos是一个专注于定位的视觉语言模型,仅使用RefCOCO的结果作为其度量指标。由于后两种模型的评估任务集是前两种模型所用任务集的子集(这反映了它们缺乏通用任务能力),我们对它们的分数进行了降权处理。这便得到了一个关于“不同类型视觉语言模型的通用能力”的近似评估,作为参考。
为了量化每个基准与视觉语言模型能力之间线性关系的强度,我们报告了三条拟合线的相关性指标(皮尔逊相关系数 rrr 和 R2R^2R2 ):
第021/23页(英文原文)
| VLM4VLA Baseline | Task-1 | Task-2 | Task-3 | Task-4 | Task-5 | ALL↑ |
| Qwen2.5VL-3B | 0.922 | 0.842 | 0.766 | 0.700 | 0.626 | 3.856 |
| + Robopoint | 0.924 | 0.829 | 0.749 | 0.683 | 0.598 | 3.783 (-0.073) |
| + Vica332k | 0.940 | 0.842 | 0.758 | 0.692 | 0.615 | 3.847 (-0.009) |
| + Bridgeqva | 0.945 | 0.843 | 0.744 | 0.657 | 0.577 | 3.765 (-0.091) |
| + Robo2vlm | 0.925 | 0.833 | 0.737 | 0.668 | 0.597 | 3.760 (-0.096) |
| Qwen2.5VL-7B | 0.935 | 0.864 | 0.807 | 0.758 | 0.693 | 4.057 |
| + Robobrain2 | 0.938 | 0.849 | 0.767 | 0.704 | 0.629 | 3.887 (-0.170) |
| + Omni-Generation | 0.928 | 0.833 | 0.760 | 0.711 | 0.654 | 3.876 (-0.181) |
| + VQA-Mix | 0.938 | 0.856 | 0.794 | 0.732 | 0.658 | 3.978 (-0.079) |
Table 10: Comparison of different Embodied VQA finetuning on VLM4VLA (best results on each settings)
Calvin: r=0.839,R2=0.703r = 0.839, R^2 = 0.703r=0.839,R2=0.703
- SimplerEnv: r=−0.358,R2=0.128r = -0.358, R^2 = 0.128r=−0.358,R2=0.128
- Libero: r=−0.194r = -0.194r=−0.194 , R2=0.038R^2 = 0.038R2=0.038
A.5 DETAILED RESULTS OF AUXILIARY TASKS
The results on each finetuned VLM on VLA tasks (Calvin ABC-D) are shown in Table 10 (corresponding to Chart 4).
A.6 DETAILS ABOUT DATASETS USED FOR FINETUNING VLM
Robopoint (Yuan et al., 2024) A pointing task dataset collected in a simulator. Given an image and a target location, the model is required to output the 2D coordinates that satisfy the target requirement. This finetuning dataset contains 1.432M samples. As shown in the table, after finetuning, the performance of Qwen2.5VL-3B on the pointing task improved by ∼20%\sim 20\%∼20% on the test split.
Vica-332k (Feng, 2025) A spatial understanding dataset constructed from RGB-D datasets. It covers a wide range of capabilities, including size estimation, position understanding, distance estimation, and so on. After finetuning Qwen2.5VL-3B on this dataset, we achieve a performance improvement of ∼15%\sim 15\%∼15% on VSI-Bench Yang et al. (2025).
Bridgevqa We used VQASynth to annotate data from Bridge-v2, Fractal, and Calvin ABC, combining them into a spatial understanding question-answering dataset. The main QA content includes judging the distance, size, and depth between two objects.
Robo2v1m (Chen et al., 2025b) An action-oriented question-answering dataset built from 176k real robot trajectories, containing 667k VQA pairs. It involves tasks such as multi-view understanding, success prediction, position management, and trajectory judgment. After finetuning Qwen2.5VL-3B on this dataset, we achieved a 60%60\%60% performance improvement on its test set.
Robobrain2 (Team, 2025) A large-scale embodied VQA dataset and a VLM finetuned on Qwen2.5VL-7B. The tasks include pointing, planning, and marking trajectory. We directly use their finetuned VLM as the backbone for our VLM4VLA.
Omni-Generation Qwen-vlo integrates a diffusion model into VLM and trains on both image generation, depth map generation, and semantic segmentation map generation tasks. We use the resulting VLM part (Qwen2.5VL-7B as the backbone for VLM4VLA.
VQA-Mix We mix the aforementioned VQA datasets with other large-scale general VQA data to finetune Qwen2.5VL-7B. The embodied related tasks include approximately 620k image-text pairs, including Vica Feng (2025), SpaceR Ouyang et al. (2025), Embsspatial Du et al. (2024) and Refspatial Zhou et al. (2025a). The general VQA data consists of 360k QA pairs.
第021/23页(中文翻译)
| VLM4VLA基线 | 任务-1 | 任务-2 | 任务-3 | 任务-4 | 任务-5 | ALL↑ |
| Qwen2.5VL-3B | 0.922 | 0.842 | 0.766 | 0.700 | 0.626 | 3.856 |
| + Robopoint | 0.924 | 0.829 | 0.749 | 0.683 | 0.598 | 3.783 (-0.073) |
| + Vica332k | 0.940 | 0.842 | 0.758 | 0.692 | 0.615 | 3.847 (-0.009) |
| + Bridgeqvα | 0.945 | 0.843 | 0.744 | 0.657 | 0.577 | 3.765 (-0.091) |
| + Robo2vlm | 0.925 | 0.833 | 0.737 | 0.668 | 0.597 | 3.760 (-0.096) |
| Qwen2.5VL-7B | 0.935 | 0.864 | 0.807 | 0.758 | 0.693 | 4.057 |
| + Robobrain2 | 0.938 | 0.849 | 0.767 | 0.704 | 0.629 | 3.887 (-0.170) |
| + Omni-Generation | 0.928 | 0.833 | 0.760 | 0.711 | 0.654 | 3.876 (-0.181) |
| + VQA-Mix | 0.938 | 0.856 | 0.794 | 0.732 | 0.658 | 3.978 (-0.079) |
表 10: 在 VLM4VLA 上进行不同具身视觉问答微调的对比 (各设置下的最佳结果)
Calvin: r=0.839,R2=0.703r = 0.839, R^2 = 0.703r=0.839,R2=0.703
- SimplerEnv: r=−0.358,R2=0.128r = -0.358, R^2 = 0.128r=−0.358,R2=0.128
- Libero: r=−0.194,R2=0.038r = -0.194, R^2 = 0.038r=−0.194,R2=0.038
A.5辅助任务的详细结果
各微调VLM在VLA任务(Calvin ABC-D)上的结果展示于表10(对应图表4)。
A.6 用于微调VLM的数据集详情
Robopoint(Yuan等,2024)一个在模拟器中收集的指向任务数据集。给定一张图像和一个目标位置,模型需要输出满足目标要求的2D坐标。此微调数据集包含1.432M个样本。如表所示,微调后,Qwen2.5VL-3B在指向任务上的性能在测试集上提升了 ∼20%\sim 20\%∼20% 。
Vica-332k(Feng,2025)一个基于RGB-D数据集构建的空间理解数据集。它涵盖了广泛的能力,包括尺寸估计、位置理解、距离估计等。在此数据集上微调Qwen2.5VL-3B后,我们在VSI-Bench(Yang等,2025)上实现了 ∼15%\sim 15\%∼15% 的性能提升。
Bridgevqa 我们使用VQASynth对Bridge-v2、Fractal和Calvin ABC的数据进行标注,将其合并成一个空间理解问答数据集。主要的问答内容包括判断两个对象之间的距离、尺寸和深度。
Robo2v1m(Chen等,2025b)一个基于176k条真实机器人轨迹构建的面向动作的问答数据集,包含667k个视觉问答对。它涉及多视角理解、成功预测、位置管理和轨迹判断等任务。在此数据集上微调Qwen2.5VL-3B后,我们在其测验集上实现了 60%60\%60% 的性能提升。
Robobrain2(Team,2025)一个大规模具身视觉问答数据集以及一个基于Qwen2.5VL-7B微调的视觉语言模型。任务包括指向、规划和标记轨迹。我们直接使用其微调后的视觉语言模型作为我们VLM4VLA的骨干。
Omni-Generation Qwen-vlo 将扩散模型集成到视觉语言模型中,并在图像生成、深度图生成以及语义分割图生成任务上进行训练。我们使用得到的视觉语言模型部分(以 Qwen2.5VL-7B 为骨干)作为 VLM4VLA 的基础。
VQA-Mix 我们将上述VQA数据集与其他大规模通用视觉问答数据混合,以微调Qwen2.5VL-7B。具身相关任务包含约62万图像-文本对,包括Vica Feng (2025)、SpaceR Ouyang等人(2025)、Embspatial Du等人(2024)以及Refspatial Zhou等人(2025a)。通用视觉问答数据包含36万问答对。
第022/23页(英文原文)

Example of Robopoint Data
Question: Locate several points on an item situated beneath the bordered item.
Answer: [(0.56, 0.69), (0.53, 0.76), (0.45, 0.72), (0.43, 0.67)]

Example of Vica Data
Question: How large is this room in terms of square meters? If more than one room is shown, approximate the overall space.
Answer: 18.33

Example of Bridgevqa Data
Question: Who is positioned more to the left, the red spoon or the robot arm?
Answer: Red spoon is more to the left.

Example of Robo2VLM Data
Question: The robot task is to flip the switch of the extension cord. Which colored arrow correctly shows the direction the robot will move next? Choices: A. Yellow. B. Blue. C. None of the above. D. Purple. E. Green. Please answer directly with only the letter of the correct option and nothing else.
Answer: C

Example of Robobrain Data (ShareRobot)
Question: reach for the ketchup bottle
Answer: [[113.66,106.19],[153.30,111.42], [217.61,121.14],[248.27,135.35]]
第022/23页(中文翻译)

Robopoint数据示例
问题:定位位于带边框物品下方的某个物品上的若干点。
答案:[(0.56,0.69),(0.53, 0.76), (0.45,0.72),(0.43,0.67)]

Vica数据示例
问题:这个房间的面积大约是多少平方米?如果显示了多个房间,请估算整体空间。答案:18.33

Bridgevqa数据示例
问题:红色勺子和机械臂,哪个位置更靠左?
答案:红色勺子更靠左。

Robo2VLM数据示例
问题:机器人任务是翻转延长线上的Switch。哪个颜色的箭头正确显示了机器人下一步的移动方向?选项:A.黄色。B.蓝色。C.以上都不是。D.紫色。E.绿色。请直接回答,仅提供正确选项的字母,无需其他内容。
答案:C

Robobrain数据示例(ShareRobot)
问题:伸手去拿番茄酱瓶
答案:[[113.66,106.19],[153.30,111.42],[217.61,121.14],[248.27,135.35]]
第023/23页(英文原文)

Example of Omni-Generation Tasks
Question: Use a red mask to segment the edges of the banana in the image.
Answer: Generated mask in the image.
第023/23页(中文翻译)

全生成任务示例
问题:使用红色掩膜来分割图像中香蕉的边缘。
答案:图像中生成的掩码。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 18
18 0
0- 0



 已为社区贡献52条内容
已为社区贡献52条内容

所有评论(0)