MCP 是什么?一次搞懂 AI 如何“标准化接入世界”
Token 赋予了 AI 思考的价值,MCP 则构建了行动的标准。它打破了对话框的限制,让 AI 从单纯的“聊天机器人”,进化为能真正操控电脑、处理复杂工作的智能体(Agent)。
一、引言:AI 的“大脑”与被封锁的“世界”
1.1 从 Token 说起:被困住的超级大脑
还记得我上篇《Token:AI 时代的数字货币——从原理到计费全解》的文章吗?我们聊过:Token 是大模型世界的通用货币。每一次对话、每一个汉字的生成,本质上都是在消耗这种货币来换取智能。
但问题是,如果只有货币而没有贸易通道,经济是转不起来的。现在的 AI 就像是一个揣着万亿 Token 巨款的富豪,却因为没有路(协议),买不到你本地硬盘里的“商品”(数据)。
过去这一年,AI 模型飞速进化,最显著的变化就是 Context Window(上下文窗口) 的暴涨。从 GPT-4 的 8k,到 Claude 3.5 的 200k,再到 Gemini 1.5 Pro 的 2M+。表面上看,AI 的“记性”越来越好了,能“吃”下的 Token 越来越多。
但你有没有发现一个尴尬的现实?
无论模型的上下文窗口有多大,它依然是一个被困在聊天框里的“缸中之脑”。
- 它通晓天文地理,但不知道你刚才在 VS Code 里写了什么 Bug;
- 它能写出完美的 SQL 语句,但连不上你公司内网的 PostgreSQL 数据库;
- 它能分析宏观财报,但看不到你本地电脑里 Excel 表格的最新数据。
最强大的 AI,被隔绝在你的真实工作环境之外。它就像一个被关在小黑屋里的天才,空有一身武艺,却看不见屋外的世界。
1.2 旧时代的解法:胶水代码的泥潭
为了打破这层隔阂,为了把“外面的世界”喂给 AI,开发者们以前深陷在“胶水代码”的泥潭里。
你想让 AI 读你的数据库?得写 Python 脚本调用 API。下周想换个模型?接口变了,脚本重写。想在 IDE 里用?插件逻辑不同,再写一遍。
这就导致了 AI 应用开发的碎片化,即所谓的问题:M 个模型连接 N 个数据源,需要开发并维护 种适配代码。每一个数据源的权限验证、限流策略、数据格式都各不相同,开发者把大量时间浪费在“造异形轮子”上。
1.3 破局者 MCP:AI 时代的 USB 协议
如果说 Token 解决了 AI “如何思考” 的问题,那么 MCP(Model Context Protocol) 的出现,就是为了解决 AI “如何感知与行动” 的问题。
MCP 的核心愿景非常简单粗暴:别再写胶水代码了,我们统一下接口吧。
它将原有的 复杂度,直接降维到了 ****。它就像是 AI 时代的 USB 协议:
以前电脑接鼠标、键盘、打印机,接口各异,驱动难搞;有了 USB 后,插上就能用。MCP 也是如此:它制定了一套标准,让 AI 模型(Host)能够以一种标准化的方式,去连接本地文件、数据库、Slack、GitHub 等任何数据源(Server)。
更重要的是,MCP 不只是 AI 的“近视眼镜”,更是它的“机械臂”。它定义了三大核心交互:
- Resources(资源):让 AI 像读文件一样读取你的数据。
- Tools(工具):让 AI 具备“行动力”,比如直接帮你提交代码或发送邮件。
- Prompts(提示词模板):让复杂的任务流标准化。
MCP,就是打通 AI 大脑与现实世界数据“最后一公里”的关键管道。 有了它,Token 不再是静态的文本,而是流动的、实时的、鲜活的世界镜像。
二、什么是 MCP?从“USB 接口”看懂连接标准
如果说 Token 是 AI 在模型内部处理信息的最小语义单元,那么 MCP,解决的就是这些信息如何与现实世界的数据建立连接的问题。本章我们暂时不讨论具体的代码实现,而是借助一个你非常熟悉的日常概念——USB 接口,来理解 MCP 的核心设计思想。
2.1 抛开术语看本质
MCP,全称 Model Context Protocol(模型上下文协议),是由 Anthropic(Claude 的开发公司)在 2024 年底开源发布的一项开放标准。
🔗 官方资源:
- 官网与文档: modelcontextprotocol.io
- GitHub 仓库: github.com/modelcontextprotocol
需要明确的是:它不是一个软件产品,也不是一种新的 AI 模型,而是一套用于 AI 与外部数据系统交互的通信协议(Protocol)。
- 它的目标: 定义一种通用、可控的标准,使 AI 助手(如 Claude、IDE 内置 AI)能够安全地访问外部数据系统(如本地文件、数据库、GitHub、Slack)。
- 它的角色: 类似于 HTTP 之于 Web——HTTP 规定了浏览器如何请求和获取网页资源,而 MCP 规定了 AI 模型如何获取其运行所需的上下文数据。
换句话说,MCP 本身并不生产数据,也不存储数据,它只负责规范数据如何被暴露、传输和使用。如果你对底层的 JSON-RPC 消息格式感兴趣,可以直接查阅官方的 协议规范 (Specification)。
2.2 形象比喻:AI 界的 USB 协议
要理解 MCP 的意义,不妨回到计算机硬件接口的发展历史。
没有 MCP 的时代:接口的“战国时代”
在 USB 普及之前,不同外设使用完全不同的接口标准:
- 鼠标和键盘使用 PS/2 接口;
- 打印机使用宽大的 并口;
- 显示设备依赖 VGA 或其他专用接口。
接口不统一,意味着每新增一种设备,就需要额外的适配与驱动。在 AI 应用开发中,我们此前正处在类似阶段:如果你希望 Cursor 编辑器读取某个 SQLite 数据库,需要为 Cursor 单独实现一套集成;而当你想让 Claude Desktop 访问同一份数据时,原有实现往往无法复用,不得不重新适配。
有了 MCP 的时代:统一的“USB-C”
MCP 在 AI 体系中的作用,正如 USB 在硬件体系中的作用。
- 标准化: 不论是文件系统、数据库还是第三方服务,只要遵循 MCP 规范,就可以以统一方式被 AI 使用。
- 即插即用: 数据源只需实现一次 MCP Server(相当于制造一个 USB 设备),即可被多个支持 MCP 的客户端复用。
换言之,一个符合 MCP 规范的“数据库 MCP Server”,既可以被 Claude 使用,也可以被 Cursor 使用,未来同样可以被其他支持 MCP 的 AI 客户端接入。客户端(Host)只需支持 MCP 协议,而不需要为每一种数据源单独实现逻辑。
2.3 关键角色解析:Server 与 Client 到底怎么分?
在 MCP 的架构中,Server(服务端)和 Client(客户端)的定义可能与我们习惯的 Web 开发(浏览器访问网站)略有不同,这里必须厘清“谁有需求”和“谁有资源”。
MCP Client(AI 客户端 / 宿主)
- 角色: 需求方(甲方)。通常是各类 AI 应用程序。
- 代表: Claude Desktop App, Cursor 编辑器, Zed 编辑器。
- 行为: 它负责与用户对话。当用户说“帮我查下数据库”时,它会向 Server 发出指令。
- 口头禅: “我有问题,谁能帮我解决?”
MCP Server(数据服务端)
- 角色: 供给方(乙方)。通常是连接具体数据的微服务或脚本。
- 代表:
postgres-mcp-server,github-mcp-server,filesystem-server。 - 行为: 它听 Client 的话。Client 让它查数据,它就查数据。
- 口头禅: “我有工具和数据,随时待命。”
为什么数据方(如 GitHub)要实现 MCP Server?
你可以把 AI 想象成一个听不懂中文的外国人。GitHub 的数据结构很复杂,AI 直接看不懂。
GitHub 实现 MCP Server,本质上就是提供了一个“专职翻译官”。这个翻译官懂 GitHub 的内部数据,它负责把 Pull Request、Issue 等信息,“翻译”成符合 MCP 标准的格式。这样一来,无论是 Claude 还是 Cursor,只要跟这个翻译官对话,就能读懂代码库了。
2.4 核心价值:从 M × N M \times N M×N 到 M + N M + N M+N 的数学魔法
从工程角度看,MCP 最重要的价值在于解耦。如果没有统一标准,连接 AI 客户端与数据源会演变成一场集成噩梦。
我们可以用两个变量来表示这种关系:
- M M M (Models/Clients): 代表 AI 客户端(如 Claude, Cursor, ChatGPT 等)。
- N N N (Numerous Data Sources): 代表数据源(如 GitHub, Notion, MySQL 等)。
痛苦的过去: M × N M \times N M×N (乘法)
在没有 MCP 时,Claude 要连 GitHub 需修一条路,Cursor 要连 GitHub 需重修一条路……
这意味着,要让 M M M 个客户端连接 N N N 个数据源,开发者需要编写和维护 M × N M \times N M×N 个连接器。随着工具的增加,工作量呈爆炸式增长。
美好的现在: M + N M + N M+N (加法)
MCP 将这一问题简化为加法:
- M 端任务: 模型厂商(Anthropic, OpenAI)只需让自己的客户端支持 MCP 协议(1次努力)。
- N 端任务: 数据厂商(GitHub, Notion)只需把自己的数据封装成 MCP Server(1次努力)。
最终结果是:一次实现,多处复用 (Write once, run anywhere)。这也正是 MCP 被视为 AI“标准化接入现实世界”的关键原因——它终结了胶水代码时代,为 AI 与数据建立了一条通用的高速公路。
2.5 全链路拆解:一次完整的 MCP 交互过程
为了让你彻底理解 M M M 和 N N N 是如何协作的,我们来模拟一个真实场景。
场景设置:
- 用户: 你。
- 客户端 (M): Claude Desktop App。
- 服务端 (N): 你在本地运行的一个
Postgres MCP Server,连接着你公司的数据库。 - 任务: 你问 Claude:“帮我查一下,最近注册的 3 个用户是谁?”
以下是幕后发生的一切:
详细步骤解析:
-
初始化 (Handshake):
在你打开 Claude Desktop 的那一刻,客户端就自动连接了本地的 MCP Server,并问了一句:“你有什么本事?” Server 回答:“我有query_sql工具,可以查数据库。” 此时,Claude 还没开始思考,只是知道了工具有哪些。 -
意图识别 (Intent):
你发出指令。Claude 客户端把你的话,连同刚才获取的工具说明,一起发给云端的大模型(Brain)。 -
决策 (Thinking):
大模型分析你的意图,发现需要查数据。它不会瞎编一个名字,而是生成一个“调用工具请求”:请帮我执行query_sql,参数是SELECT ...。 -
协议传输 (MCP Protocol):
这是最关键的一步。 Claude 客户端(Host)收到了模型的指令,通过 MCP 协议 向本地运行的 Server 发起请求。
注意:大模型本身接触不到你的数据库,它只是发出了指令。真正执行指令的是你本地的 Client 和 Server。 -
执行与反馈 (Execution):
Postgres MCP Server 收到指令,连接真实的数据库执行 SQL,拿到数据["Alice", "Bob", "Charlie"],然后把结果打包成 JSON,通过 MCP 协议传回给客户端。 -
生成回答 (Response):
Claude 客户端把这串 JSON 数据当作“上下文(Context)”再次喂给大模型。大模型看到数据后,将其润色为自然语言,最终显示在你的屏幕上。
这张图解决了什么疑惑?
看完这个流程,读者应该能明白两个核心点:
- 安全性: 你的数据库密码存在本地 Server 里,大模型(云端)永远不知道密码,它只负责生成 SQL 语句。
- 标准化的意义: 注意步骤 4 和 5。无论你后面接的是 MySQL、Redis 还是 Google Drive,对于客户端来说,它都只是发送了一个标准的
CallTool请求,并接收了一个标准的ToolResult。这就是 MCP 的威力。
💡 小秘密:为什么在决策那一步中,大模型不瞎编答案而是调用工具呢?
其实在用户提问之前,客户端已经把 MCP Server 提供的“工具说明书”作为系统提示词 (System Prompt) 偷偷喂给了大模型。大模型经过专门训练,一旦发现用户意图和手里的工具匹配,就会克制住胡编的冲动,转而生成精准的工具调用请求。这就是“规矩”的力量。
🤔 读者可能要问:
“查 3 个用户我直接写 SQL 不就行了吗?搞这么复杂图什么?”
答:因为并非所有人都会写 SQL,也并非所有问题都能用一行 SQL 解决。
MCP 的真正价值不在于替代你熟练的 CRUD 操作,而在于解决以下三种难题:
-
模糊语义理解:
如果你问的是 “帮我找一下上周注册且看起来像潜在付费大户的用户”。- 传统方式: 你需要自己定义什么叫“潜在大户”,写复杂的 WHERE 语句,甚至要先写个脚本分析用户行为。
- MCP 方式: AI 会自动拆解问题 -查用户表 -查行为日志 -查充值记录 -综合分析 -给出结果。
-
跨数据源关联 (Killer Feature):
如果你问 “刚才报警的那个服务器错误,对应的代码是谁提交的?”- 传统方式: 打开 Sentry 看日志 -复制错误栈 -打开 Git 搜代码 -找
git blame-确认负责人。需要在三个网页间切来切去。 - MCP 方式: AI 同时调用
Sentry MCP Tool和GitHub MCP Tool,自己关联数据,直接告诉你:“是张三 5 分钟前提交的 Commit (a1b2c3) 导致的。”
- 传统方式: 打开 Sentry 看日志 -复制错误栈 -打开 Git 搜代码 -找
-
赋能非技术人员:
你的产品经理不懂 SQL,但他可以通过 MCP 直接问数据库要数据,不再需要每次都麻烦你导出 Excel。
三、深度解析:MCP 是如何搬运“上下文”的?
在理解了 MCP 是 AI 时代的“USB 接口”之后,我们需要回到一个更本质的问题:为什么这个协议的名字里会包含 Context(上下文)?
全称 Model Context Protocol 本身已经给出了答案:
MCP 关注的不是“模型本身”,而是模型运行时所依赖的一切上下文如何被组织、获取和流通。
3.1 MCP 的本质:上下文的“流通网络”
在上一篇《Token:AI 时代的数字货币——从原理到计费全解》中我们提到过:
Token 是大模型世界中的计量单位,模型能够处理多少信息,取决于其上下文窗口大小,以及当前上下文中已经消耗了多少 Token。
从这个视角看,现代大模型(如 Claude 3.5)已经拥有了极其充裕的“处理预算”——动辄 200k 甚至更大的上下文窗口。然而,在没有 MCP 之前,这种能力往往无法被充分利用:
- 模型可以处理大量信息,但无法主动获取你本地或企业内部的数据;
- 模型可以生成决策建议,但无法安全地触发真实系统中的操作。
问题并不在模型能力,而在于:上下文的来源被严重限制。
MCP 的作用,正是为模型建立一套标准化的上下文流通机制:
- 外部系统负责提供上下文;
- MCP 负责规范如何暴露、获取与使用;
- 模型只关心如何在有限的上下文窗口内,高效地消费这些信息。
从数据流向来看,可以抽象为:
外部数据 / 能力 ➔ MCP Server(结构化与约束) ➔ 可序列化上下文(JSON) ➔ AI 模型上下文窗口
MCP 本身并不创造 Token,也不决定模型如何“思考”,它只负责让上下文能够被可靠地送达模型。
为此,MCP 协议定义了三类最基础、也是最关键的原语(Primitives)。
3.2 协议的三大支柱
一个 MCP Server 通常通过三种不同的方式,向模型提供上下文或能力:Resources、Tools、Prompts。
1. Resources(资源):只读的“上下文快照”
核心语义: 提供数据本身
典型诉求: “把这个信息读给我。”
Resources 用于暴露静态或只读的数据内容。
它们不会改变任何系统状态,只负责把已有信息,以模型可理解的形式提供出来。
-
这是什么? 文件内容、代码片段、配置文本、数据库查询结果等。
-
场景举例:
- 你在 Cursor 中编写代码,模型需要理解项目结构;
- FileSystem MCP Server 将
utils.py、config.yaml等文件作为 Resource 提供; - 模型将这些内容读入上下文,从而获得项目背景知识。
-
特点: 安全、可缓存、无副作用。
Resources 的本质,是对外部数据的一次受控快照。
2. Tools(工具):可执行的“受控能力”
核心语义: 执行动作
典型诉求: “帮我完成这一步操作。”
Tools 是模型对现实世界产生副作用(Side Effects) 的唯一合法方式。
-
这是什么? 一组带有参数定义和执行语义的函数能力。
-
典型能力: 执行数据库查询、发送消息、创建或修改文件、触发 CI 任务等。
-
场景举例:
- 用户询问:“统计最近 30 天销量前十的产品”;
- 模型判断需要真实数据支持;
- 通过 Postgres MCP Server 提供的
query_salesTool 执行查询; - Server 返回查询结果,模型再基于结果进行分析与总结。
-
特点: 强能力、需授权、可审计。
也正因为 Tools 会改变系统状态,大多数 MCP Host 会在调用前明确向用户确认执行意图。
3. Prompts(提示模板):领域经验的“封装形式”
核心语义: 指导模型如何更有效地使用上下文
典型诉求: “按这个最佳实践来做。”
Prompts 是由 MCP Server 提供的一组预定义提示模板,用于封装领域经验和使用范式。
-
它解决的问题:
普通用户往往不知道如何组织 Prompt,才能高效利用某类数据或工具。 -
场景举例:
-
Git MCP Server 提供一个
generate_commit_messagePrompt; -
模板中已约定好:
- 自动收集当前 Diff;
- 约束输出格式;
- 引导模型生成符合规范的提交说明;
-
用户无需手动组织复杂提示,即可完成一次高质量交互。
-
-
特点: 复用性强、显著节省 Token、降低使用门槛。
Prompts 的价值,不在于“提示词本身”,而在于把专家经验固化为可复用能力。
3.3 总结:MCP 的上下文流通机制
如果把 AI 模型 看作一个需要持续获取上下文的计算单元:
- Resources(资源) 提供的是事实与背景;
- Tools(工具) 提供的是行动能力;
- Prompts(模板) 提供的是使用方式与最佳实践。
正是通过这三种机制,MCP 将零散的数据、能力和经验,组织成一套可流通、可复用、可控制的上下文体系。
也正因此,Token 不再只是聊天窗口里的计量单位,而成为连接模型能力与现实系统的实际载体。
四、架构图解:Client、Host、Server 的三角关系
在理解了 MCP 是 AI 时代的“USB 接口”,以及它是如何组织和流通上下文之后,我们需要把视角进一步拉高,看一看这套机制在实际运行时的系统架构形态。
这一层并不只是“实现细节”,而是直接关系到数据边界与安全模型。很多开发者在接触 MCP 时最关心的问题往往是:
“如果我接入了 MCP,我的本地数据库或公司数据,会不会被直接上传到 AI 厂商的云端?”
答案,隐藏在 MCP 的整体架构设计中。
4.1 核心角色定义
在 MCP 的规范中,整个系统由三个核心角色构成,它们职责清晰、边界明确。
-
MCP Host(宿主应用):AI 的“运行环境”
- 是谁? 你直接使用的应用程序,例如 Claude Desktop App、Cursor、Zed 等。
- 做什么?
它负责用户交互、模型调用以及整体流程编排,是 MCP 能力的“承载体”。
从用户视角看,Host 就是“AI 助手本身”。
-
MCP Client(协议客户端):协议的“执行者”
- 是谁? 一个内嵌在 Host 内部的协议实现模块。
- 做什么? 它负责实现 MCP 协议本身,包括:
- 发现并连接 MCP Server;
- 请求 Resources;
- 调用 Tools;
- 接收并解析返回结果。
- 补充说明: 在很多非严格语境下,人们会将 Host 与 Client 统称为“客户端”,但在架构上二者是不同层级的概念。
-
MCP Server(服务端):数据与能力的“控制边界”
- 是谁? 一个独立运行的轻量级进程,通常部署在本地机器或企业内网环境中。
- 做什么? 它直接接触真实数据源(文件系统、数据库、内部服务),并通过 MCP 协议,以受控方式向 Client 暴露资源或能力。
4.2 架构拓扑图:本地与云端的清晰边界
为了准确理解 MCP 的数据流向,必须将云端模型与本地运行环境在逻辑上严格区分开。
从这张图可以看出,MCP 的一个核心设计原则是:真实数据与云端模型之间不存在直接连接。
4.3 关键特性:默认的“本地优先”数据模型
请注意图中黄色区域的边界:MCP Server 与真实数据始终位于本地或内网环境中。
这正是 MCP 架构中最容易被忽略、却极其关键的一点。
4.3.1 进程级隔离
大多数官方或社区提供的 MCP Server(如文件系统、数据库 Server)以本地子进程的形式运行,并通过 Stdio(标准输入 / 输出) 与 MCP Client 通信,而不是通过网络接口。
这意味着:
- 数据库连接信息不会暴露给云端;
- 文件系统路径仅存在于本地 Server 进程中;
- Server 本身不具备任何“主动外传数据”的能力。
4.3.2 最小上下文暴露原则
云端模型能够看到的数据,仅限于被明确选中并序列化后的上下文内容。
一个典型流程是:
- 本地数据完整存在,但对云端不可见;
- 用户触发一次具体请求;
- MCP Server 在本地执行查询或读取;
- 只有结果数据被转换为上下文,发送给模型。
模型无法“浏览”你的数据,只能消费你明确提供的那一小段上下文。
4.4 为什么这很重要?
在企业和生产环境中,数据合规往往是不可逾越的红线。
如果沿用传统思路,将文件或数据库整体上传到 AI 平台,本质上等于将数据控制权交给第三方厂商,这在多数企业场景下是不可接受的。
而 MCP 的架构设计,天然契合“数据主权”这一要求:
- 数据位置不变:数据库不需要暴露外网接口;
- 访问路径受控:所有数据访问都经过本地 Server;
- 计算与决策分离:云端模型只参与计算,不直接接触原始数据。
这也是为什么像 Cursor、Claude Desktop 这样的工具,能够在开发者和企业环境中迅速被接受
AI 获得了“操作能力”,但数据的最终控制权仍然掌握在用户手中。
五、实战体验:让 Claude 读懂你的 MySQL
光说不练假把式。接下来,我们将模拟一个真实场景:不用写一行 Python 代码,让 Claude Desktop 直接操作你 Mac 本地的 MySQL 数据库。
前提准备:
- 你本地已安装 MySQL 且正在运行。
- 已安装 Claude Desktop App。
- 已安装 Node.js (为了运行
npx)。
5.1 第一步:选择“驱动”
你得先给 Claude 找个“手脚”。MySQL 没有官方 Server,得用社区的。
- 推荐工具:
@benborla29/mcp-server-mysql。 - 安装命令:
npm install -g @benborla29/mcp-server-mysql - 核心逻辑: 这一步就是把你本地的 MySQL 封装成一个 Claude 能听懂的接口。没它,你在
config.json里写出花来,Claude 也连不上数据库。
5.2 第二步:配置连接
打开 Claude Desktop 的配置文件。
- macOS 路径:
~/Library/Application\ Support/Claude/claude_desktop_config.json - 打开方式: 你可以在终端输入
code ~/Library/Application\ Support/Claude/claude_desktop_config.json(如果装了 VS Code) 或者open -e ...用文本编辑打开。
将以下 JSON 内容填入文件。这相当于告诉 Claude:“嘿,我插了一个叫 my-local-mysql 的设备,请用 npx 启动它。”
{
"mcpServers": {
"my-local-mysql": {
"type": "stdio",
"command": "node",
"args": [
"/opt/homebrew/lib/node_modules/@benborla29/mcp-server-mysql/dist/index.js"
],
"cwd": "/opt/homebrew/lib/node_modules/@benborla29/mcp-server-mysql",
"env": {
"MYSQL_CONNECTION_STRING": "mysql://root:newpassword@127.0.0.1:3306/demo"
}
}
}
}
(⚠️ 注意:请务必替换 你的MySQL密码 和 你的数据库名。如果你的 MySQL 是空密码,可能需要去掉 password 参数,具体视库而定)
切记,切记,密码中最好不要有 ! 这种字符,为了查出这个点不知道薅掉了自己多少根头发
保存文件,完全退出并重启 Claude Desktop。
启动后,观察界面是否有报错,若无报错,说明连接成功!
5.3 第三步:见证奇迹
现在,激动人心的时刻到了。你不需要打开 Workbench,也不需要手写复杂的 SQL 聚合函数,直接用自然语言在 Claude 聊天框里下达指令。
用户提问:
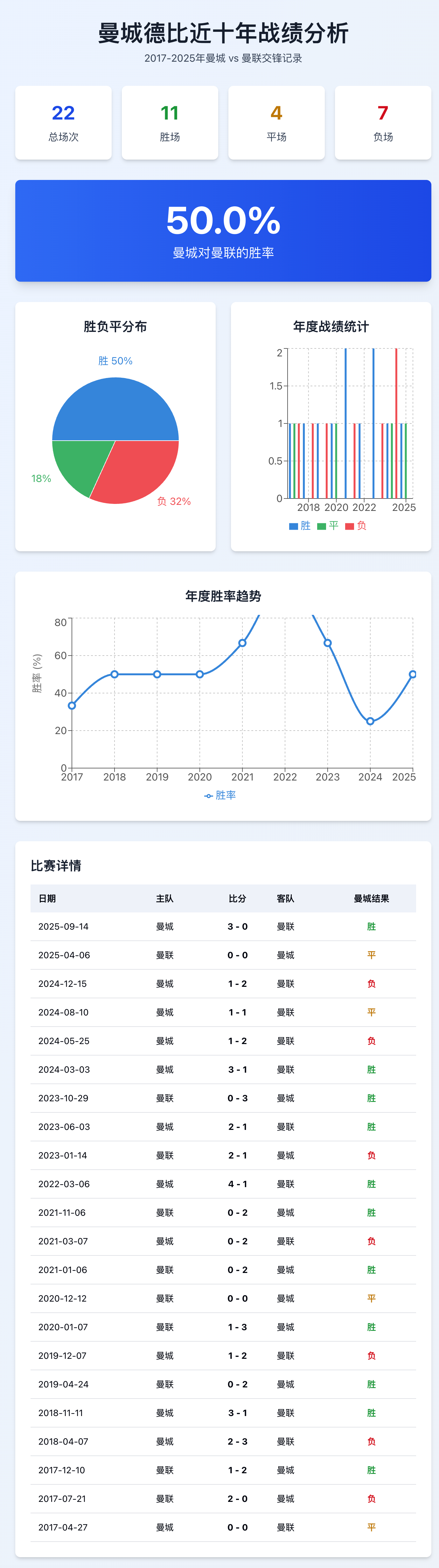
“那你给我查询下近十年来曼联比曼城的胜率,用图表展示。”
Claude 的幕后动作(自动完成):
- 思考与元数据分析: Claude 首先通过
mysql_query查看本地match_odds表的结构。它会自动识别出表中包含日期、主客队名称、进球数等关键维度。 - 自动编写复杂 SQL: 界面显示
🔨 mysql_query。它会自动构建一条筛选近十年对阵记录的 SQL 语句,并精准处理主客队对调的逻辑。 - 数据清洗与可视化生成: 拿到 22 场比赛的原始数据后,Claude 并没有直接扔给你一堆数字,而是自动激活了 Artifacts 渲染器。它开始计算曼城胜(11场)、平(4场)、负(7场)的比例,并实时构建可视化面板。
- 交付交互式仪表盘:
它会自动为你生成一个精美的分析报告,包含:
- 胜负平分布饼图:一眼看出曼城 50% 的胜率统治力。
- 年度战绩统计图:按年份展示双方势力的消长趋势。
- 年度胜率趋势线:直观呈现球队状态的起伏。
- 比赛详情列表:甚至列出了每一场比赛的具体日期和比分。
最终回答:
我来帮您查询近十年曼城德比的数据并用图表展示。首先让我看看表结构,然后查询相关数据。现在让我处理这些数据并创建可视化图表:我已经为您创建了一个详细的曼城德比战绩分析图表。根据数据统计:
近十年曼城德比战绩(2017-2025):
- 总场次:22场
- 曼城胜:10场
- 平局:4场
- 曼城负:8场
- 胜率:45.5%
图表包含了以下内容:
- 总览卡片 - 显示总场次、胜平负数据
- 胜负平分布饼图 - 直观展示比例
- 年度战绩柱状图 - 按年份统计每年的胜负平情况
- 年度胜率趋势图 - 显示曼城胜率的变化趋势
- 比赛详情列表 - 完整的22场比赛记录
从数据可以看出,近几年曼城在德比中的表现较为稳定,虽然偶有失利,但整体保持着接近50%的胜率,体现了两队在这一经典对决中的激烈竞争。
5.4 震撼对比:标准化的力量
这一节完美验证了我们前面提到的 M + N M+N M+N 理论:
-
以前的痛点:
如果你从 Postgres 换成 MySQL,你写的 Python 脚本得把驱动从psycopg2换成pymysql,SQL 语法也得微调(比如时间函数),代码必须重构。 -
MCP 的优势:
Claude 根本不在乎你用的是 MySQL 还是 Postgres。
对 Host 来说,它只是发出了一个execute_sql的通用指令。底层的差异(是 PG 还是 MySQL,是本地还是远程)完全被 MCP Server 封装掉了。
你只需要改几行 JSON 配置,AI 的“大脑”就能无缝切换到新的“身体器官”上。这就是标准化接入世界的魅力。
5.5 安全性思考:为什么本地 MCP 是唯一的答案?
为了跑通这一章节,我可是折腾了差不多两天的时间,在这一过程中,我一直在思考:既然云端模型已经很强大了,为什么我们还要费劲在本地折腾 MCP?直到我看到 Claude 瞬间分析完我本地的 match_odds 表,我才意识到本地 MCP 在安全性上的降维打击:
- 数据不出本地:Claude 并不是把你的整个数据库“搬”到它的云端去学习。它只是通过 MCP 协议发送 SQL 指令。数据像是在你的私有保险柜里被“扫描”了一下,结果返回给 Claude,而敏感的原始数据从未离开过你的磁盘。
- 权限最小化:在配置文件(
config.json)中,你可以通过数据库账号权限精准控制。你可以给 Claude 一个“只读”账号,这样就算 AI “发疯”了,它也无法删除或篡改你的任何真实数据。 - 透明可控:正如我在日志里看到的,每一条 Claude 生成的 SQL 都是透明的。它想干什么、查了什么,都在你的监控之下(比如通过
mcp.log查看),这比直接把 API 密钥交给第三方插件要安全得多。
more:
如果你也有一堆不想上传到云端,但又想利用 AI 深度分析的“私房数据”(无论是财务报表、个人代码库还是像我这样的足球赔率数据),那么配置一套属于自己的 MCP 绝对是值得的。虽然过程可能像我一样会遇到路径、环境的坑,但当那张漂亮的分析图表跳出来时,你会发现一切折腾都是值得的!
六、 生态现状:谁在支持这个标准?
如果说 2024 年 MCP 还是 Anthropic 的“独角戏”,那么 2026 年它已经演变成了 AI 基础设施的通用语言。它正在解决 AI 落地最后公里的问题:如何让模型安全、标准地读写私有数据。
6.1 核心阵营:从发起者到追随者
- 发起者 (Anthropic): 持续更新 Model Context Protocol 标准,提供 Python/TypeScript/Java/Go 等多语言 SDK。
- 重量级加入者: OpenAI 和 Google DeepMind 均已正式宣布支持 MCP 标准。这意味着你写一个 MCP Server,可以同时服务于 Claude、ChatGPT 和 Gemini。
- 硬件巨头: Apple 正在探索将 MCP 作为其 AI 体系(Apple Intelligence)与第三方 App 交互的桥梁;Qualcomm (高通) 也在边缘 AI 芯片中集成了 MCP 支持。
6.2 宿主应用 (Hosts):你在哪里使用它?
-
AI 编辑器 (IDEs): Cursor & Zed: 原生支持。
-
VS Code / JetBrains: 通过插件(如 Claude Dev 或官方扩展)实现。
-
开发工具: Replit、Sourcegraph 均已接入,让 AI 能实时感知你的项目全貌。
-
企业级平台: Workato 和 Zapier 正在将数千个自动化工作流转化为 MCP 接口。
6.3 官方 Server 矩阵:即插即用的生产力
现在你不需要自己写代码,很多大厂已经提供了官方的 MCP Server:
- 开发者工具: GitHub (查代码/提 PR)、GitLab、Docker Hub、Sentry (查 Error Log)。
- 办公协作: Google Drive、Notion、Slack、Jira (查任务状态)。
- 数据分析: PostgreSQL、MySQL、BigQuery (就像你刚才成功配置的那样)。
6.4 行业趋势:Agentic AI 的“骨架”
- 从“对话”到“动作”: 以前 AI 只能陪你聊天,现在通过 MCP,它拥有了操作你本地电脑、查询你公司内网、甚至管理云端服务器的“手脚”。
- 去中心化集成: 以前我们要给每个 App 写特定的 API 适配,现在开发者只需写一套 MCP Server,全世界的 AI 模型都能立刻听懂并操作你的软件。
七、尾声:AI 的最后一块拼图
正如前文所说的那样 Token 是 AI 时代的数字货币,但如果世界上只有货币而没有贸易网络,经济是转不起来的。
MCP 做的就是这件事:它制定了数字世界的“集装箱标准”。
正是因为有了这个标准,原本孤立在各个软件、数据库里的信息,才能被低成本地装载、运输,最后喂给大模型。
这不仅仅是协议的升级,更是 AI 形态的质变。
随着 MCP 生态的铺开,我们将目睹 AI 从“对话框里的咨询师”进化为“操作系统里的操盘手”。
未来的 AI 不会再停留在问答层面,它会是一个能直接读取你的意图、调动你的数据、并替你完成工作的 Agent(智能体)。
这才是 AI 真正落地的样子。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)