CycleVLA:基于子任务回溯和最小贝叶斯风险解码的主动自校正视觉-语言-动作模型
26年1月来自牛津和剑桥的论文“CycleVLA: Proactive Self-Correcting Vision-Language-Action Models via Subtask Backtracking and Minimum Bayes Risk Decoding”。目前机器人故障检测和纠正方法通常采用事后分析的方式,仅在故障发生后才进行错误分析和纠正。本文提出一种名为 CycleVL
26年1月来自牛津和剑桥的论文“CycleVLA: Proactive Self-Correcting Vision-Language-Action Models via Subtask Backtracking and Minimum Bayes Risk Decoding”。
目前机器人故障检测和纠正方法通常采用事后分析的方式,仅在故障发生后才进行错误分析和纠正。本文提出一种名为 CycleVLA 的系统,该系统赋予视觉-语言-动作模型 (VLA) 主动自纠正能力,使其能够预测即将发生的故障并在故障完全显现之前进行恢复。CycleVLA 通过集成以下组件来实现这一目标:一个进度-觉察的 VLA,用于标志故障最常发生的关键子任务转换点;一个基于视觉-语言模型 (VLM) 的故障预测器和规划器,用于在预测故障时触发子任务回溯;以及一种基于最小贝叶斯风险 (MBR) 解码的测试-时扩展策略,用于提高回溯后的重试成功率。大量实验表明,CycleVLA 能够提升训练良好和训练不足的 VLA 的性能,并且 MBR 可以作为一种有效的 VLA 零样本测试-时规模化策略。
本文旨在为通用机器人基础模型,特别是视觉-语言-动作模型(VLA)[13]–[15],赋予主动自纠错能力,如图所示。CycleVLA的灵感来源于以下观察:许多机器人任务失败发生在子任务转换阶段[16]–[20],而子任务接近完成时的进展情况能够为预测此类失败提供强有力的线索(例如,在插入过程中卡住之前,可以判断出插销未对准)。基于此,CycleVLA首先引入一个微调流程,使VLA能够显式感知子任务的进展情况,从而解决现有VLA缺乏停止或进度估计机制的一个关键局限性[19]。通过将演示分解为对齐的子任务,并使用扩展的动作维度对VLA进行微调来实现这一点,这些扩展动作维度能够预测停止信号和子任务的进展情况。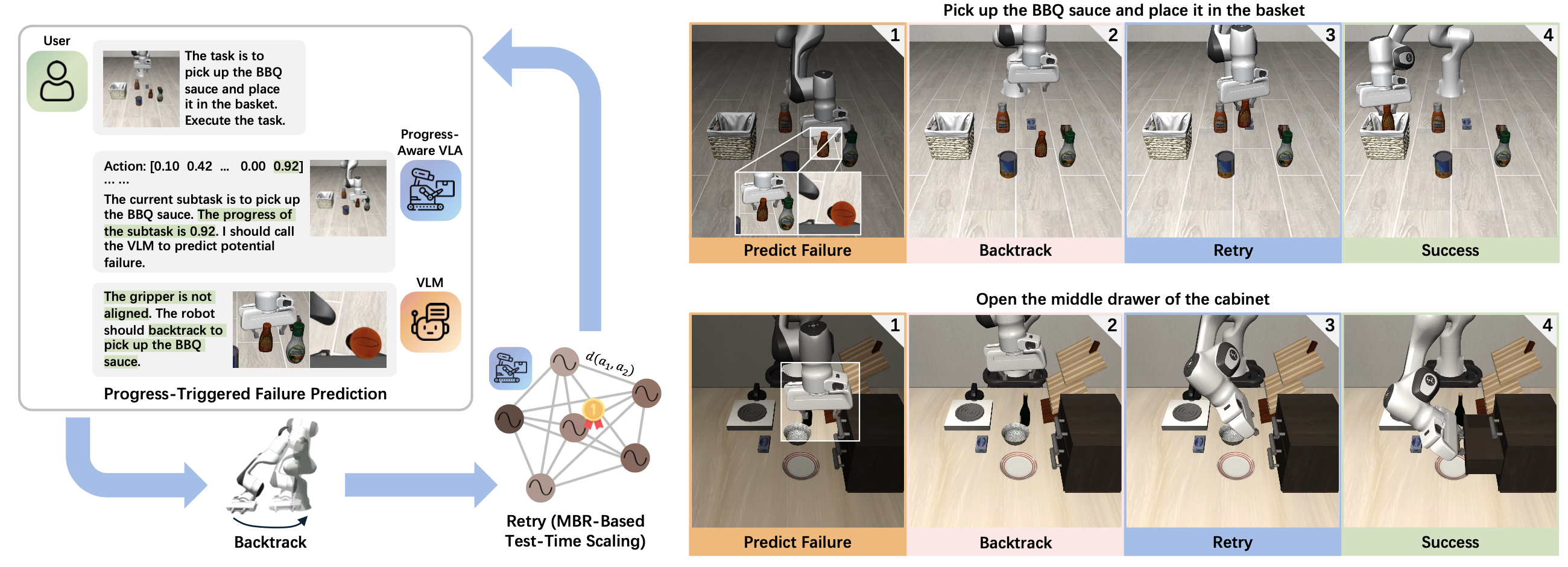
前期知识
考虑基于当前观测值 o_t(例如,RGB 图像和本体感觉)和自然语言目标 g 的序列决策。VLA 策略 π_θ 将 (o_t,g) 映射到机器人动作。采用连续末端执行器 delta 动作表示 a_t = [∆x_t, ∆y_t, ∆z_t, ∆u_t, ∆v_t, ∆w_t, γ_t],其中 (∆x_t,∆y_t,∆z_t) 和 (∆u_t, ∆v_t, ∆w_t) 分别表示平移和旋转位移,γ_t ∈ {0, 1} 表示夹爪状态。与自回归模型不同,假设 VLA 采用并行解码,在单次前向传播中生成连续的未来动作块,即对于大小为 H 的块,π_θ(a_t:t+H−1 | o_t, g)。
在推理阶段,进一步假设该策略支持随机解码,从而能够通过重复前向传播(例如,随机潜变量、基于扩散的噪声采样)生成有限集动作序列假设 A = {a(1)_ t:t+H-1, . . . , a(N)_ t:t+H-1}。
目标是为 VLA 赋予主动式自我纠错能力。CycleVLA(如图所示)基于这样的观察:任务失败通常发生在子任务转换处,而接近完成的进展为预测失败提供强有力的线索。首先引入一个微调流程,该流程从演示中构建子任务分解数据集,并训练 VLA 通过轻量级修改来显式预测停止和进展信号。在推理阶段,使用现成的 VLM 作为失败预测器和规划器,以决定在子任务边界处是转换还是回溯。最后,应用 MBR 解码作为一种零样本测试时间缩放策略,以提高回溯后的重试成功率。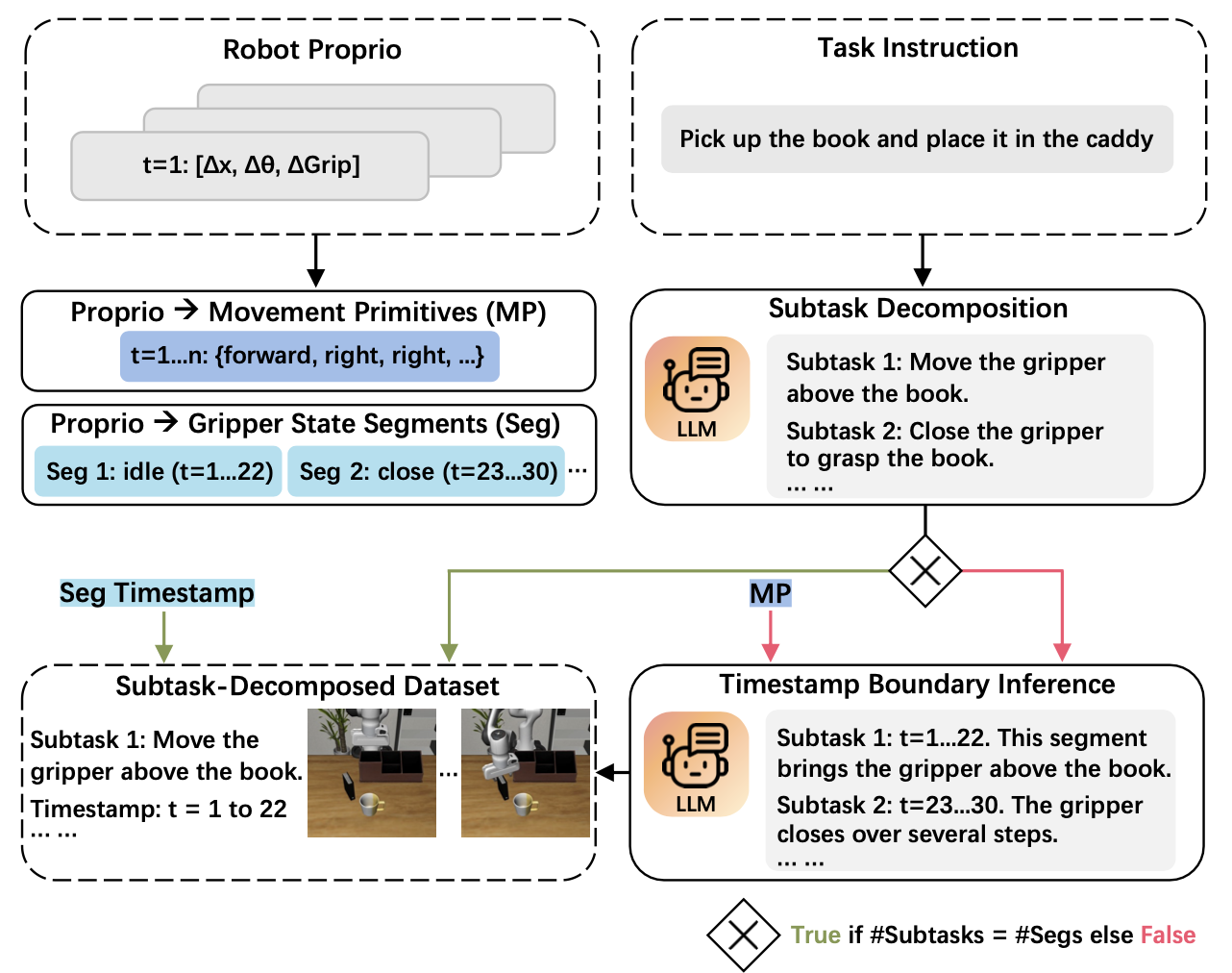
学习子任务执行的停止和进度信号
构建子任务分解数据集。引入一个流水线,该流水线使用大语言模型(LLM)将演示分解为具有精确的开始/结束时间戳和语言指令的子任务(如图所示),其灵感来源于先前的工作 [16]、[51]。
给定一个任务指令 g,首先指示 LLM 使用受限的动作词汇表(例如,移动、旋转、打开、关闭)将其分解为最小的原子子任务序列 (g_1,…,g_K)。同时,通过计算滑动窗口上的状态差异,从机器人的固有属性中提取每一步的夹爪状态(打开、关闭或空闲)和运动基元(例如,向前移动、顺时针旋转、停止)[51]。
然后,用夹爪状态转换片段将子任务与轨迹对齐。这些片段在操作任务中提供可靠的子任务边界(例如,连续的开/关片段对应于抓取或释放物体,而空闲片段通常表示机器人平移或旋转运动期间夹爪没有动作)。如果LLM提出的子任务数量与夹爪状态片段的数量匹配,将每个子任务直接与相应的片段时间戳配对。否则,用提取的运动基元序列(下采样到固定的最大长度以减少上下文长度)来提示LLM推断子任务时间戳边界,从而强制执行连续分配,避免出现间隙,同时过滤掉虚假的停止或不一致的基元。
利用扩展动作维度进行子任务微调。用子任务分解后的数据集,通过扩展动作维度对 VLA 进行微调,以预测停止信号和进度信号——现有 VLA [19] 并未明确建模这些功能。将 7 维动作 a_t 扩展为 9 维:a_t = [∆x_t, ∆y_t, ∆z_t, ∆u_t, ∆v_t, ∆w_t, γ_t, s_t, p_t],其中 s_t ∈ {0, 1} 表示停止信号,指示子任务结束;p_t ∈ [0, 1] 表示子任务进度,并根据每个子任务内的归一化时间步长离散化为 0.1 的区间。显式地分离这两个信号,因为停止信号必须足够精确才能支持正确的子任务转换,而进度信号只需指示子任务接近完成即可。参照 NaVILA [63],在训练过程中对每个子任务的最后一个动作步骤进行过采样,以增强终止检测。在推理阶段,通过阈值处理对 s_t 进行二值化,与机械臂信号 γ_t 的处理方式相同。
将停止和前进状态与末端执行器位移量(delta)动作联合预测,作为标量输出,而不是引入单独的分类头。这种设计符合 VLA 动作空间的连续性:末端执行器位移是浮点值,而机械臂信号 γ_t 是有界标量。因此,在同一输出空间中预测 s_t 和 p_t 无需进行任何架构更改,只需扩展动作维度即可。
基于子任务回溯和 MBR 解码的测试-时规模化
VLM 作为故障预测器和规划器。利用现成的 VLM,结合感知进度的 VLA,在子任务边界处预测故障并规划恢复方案。当 VLA 预测的进度达到 τ_p 时,用同步的第三人称视角和腕戴式摄像头视角、当前子任务以及子任务列表来查询 VLM。VLM 输出以下两个决策之一:直接进入下一个子任务,或者回溯到最早能够恢复缺失前提条件的子任务(例如,如果抓取的物体在中途掉落,则回溯到抓取子任务)。同时考虑两种视角,以便VLM能够利用第三人称视角提供的全局上下文信息(例如,物体标识、夹爪姿态、是否正在执行正确的子任务)以及腕部视角提供的细粒度线索(例如,夹爪与物体的对齐情况、接触质量),并输出融合两种视角证据的“思维链”推理结果[64]。
当回溯触发时,通过反向执行已记录的增量动作[23]将机器人状态恢复到目标子任务的起始状态。
通过MBR进行动作采样和排序。回溯恢复有效的子任务前提条件后,VLA会从相同的起始状态重试该子任务。通过采样多个动作块假设,并利用MBR解码[29]选择一个共识假设,来实现测试-时规模化。基于当前观测值 o_t 和子任务 g_k,从随机策略 π_θ(· | o_t, g_k) 中抽取 N 个假设 A = {a(1)_t:t+H −1,…, a(N)_t:t+H−1}。
MBR 选择在策略分布下最小化预期风险的假设。用从策略 π_θ(· | o_t, g_k) 中采样得到的假设集 A,通过蒙特卡罗方法近似期望值。用预测末端执行器运动中的距离来实例化 d。
对于每个采样假设 a(n)_t:t+H−1,累加平移和旋转增量以获得预测轨迹,该轨迹由特征向量 φ(a(n)_t:t+H−1) 表示,其中包含每一步的位置 (x, y, z) 和方向 (u, v, w)。MBR 选择这个共识轨迹: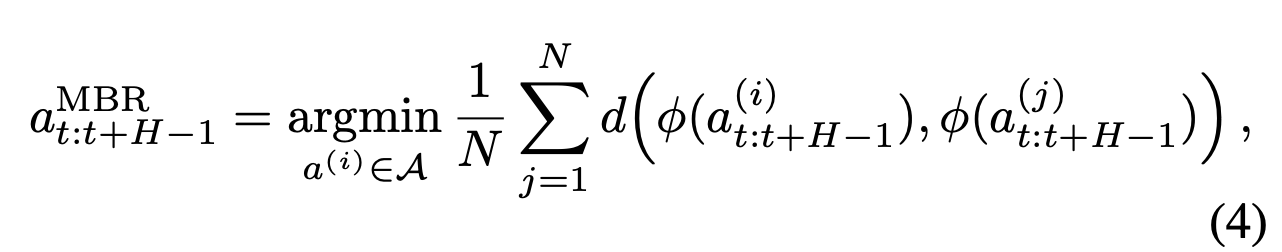
总体推理过程。在算法 1 中总结完整的 CycleVLA 推理过程。该算法在每个子任务中交替执行两个阶段:监控进度直至触发 VLM 检查,然后完成执行直至停止信号确认子任务终止。
实现细节
子任务分解。用 GPT-4.1 [65](温度 0.2)来生成子任务并推断其时间戳边界。每个子任务的最后一个动作步骤均过采样 8 倍。
训练与推理。VLA 骨干网络为 Open-VLA [66],并采用基于扩散的动作专家。随机采样通过改变随机种子来实现,从而改变扩散过程中的噪声采样。除非另有说明,所有模型均在 4 个 NVIDIA A100 GPU(40GB 显存)上进行训练,并在 1 个 NVIDIA A10 GPU(24GB 显存)上进行评估。用 GPT-5.2 [67](温度 1.0)作为基于 VLM 的故障预测器和规划器,并在子任务进度达到 τ_p = 0.9 时进行查询。对于 MBR 解码,用 L2 距离度量 (d),并采样 N = 8 个假设。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 12
12 0
0- 0



 已为社区贡献103条内容
已为社区贡献103条内容

所有评论(0)