通用工业 AMR 的分布式状态控制系统设计原理
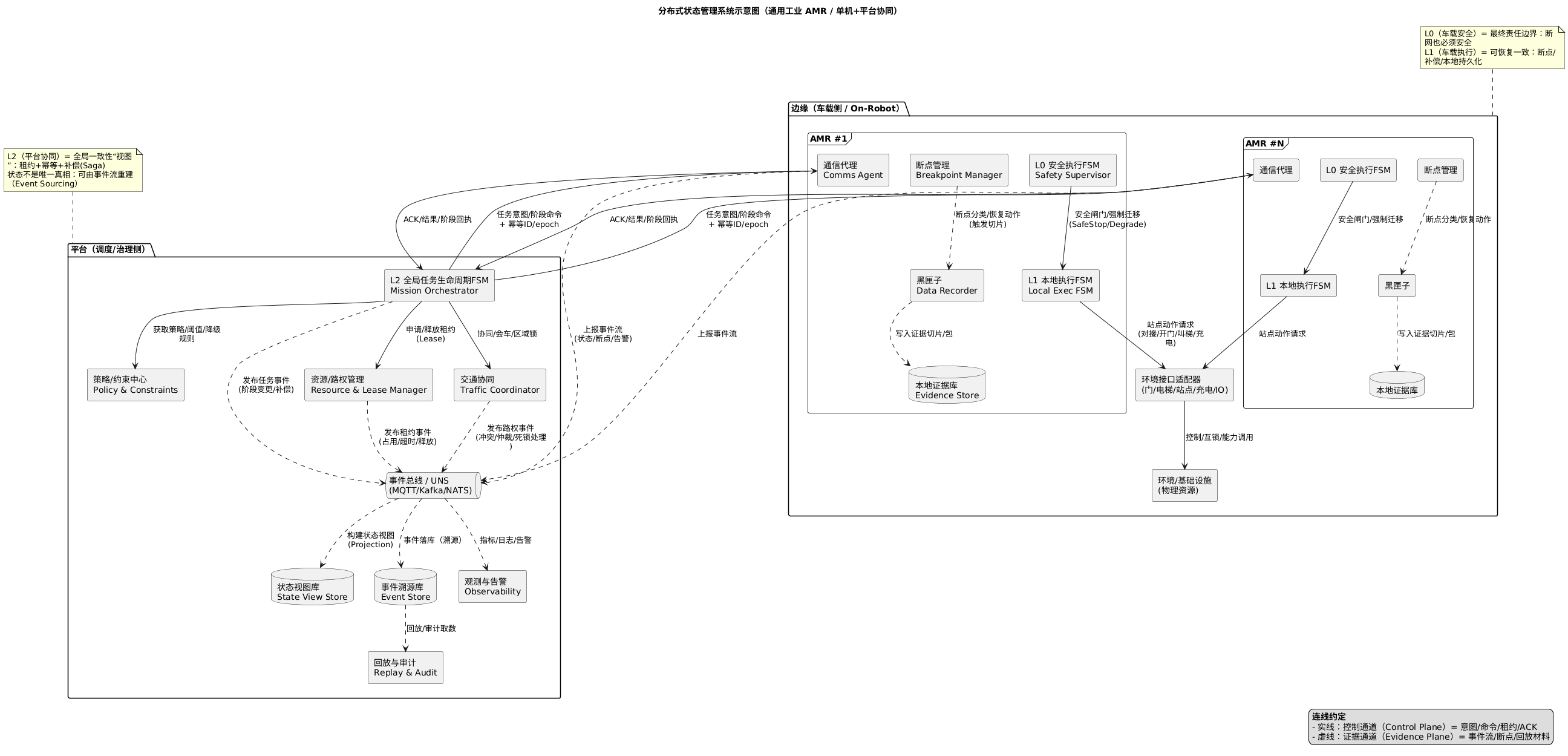
工业AMR分布式状态控制系统的核心在于确保网络分裂、设备退化等现实条件下状态仍可控、可恢复、可审计。系统需协同管理四类状态:任务状态、机器人状态、资源状态和安全约束状态。采用三层状态机(本地安全执行、任务执行、全局协同)和两条通道(控制通道、证据通道)的分层架构,通过租约、幂等命令、补偿机制和事件溯源等策略实现"可恢复一致"。系统设计需包含结构化断点对象和最小核心实体模型,确保
把一个当作通用工业 AMR 的分布式状态控制系统一个可复用的工程对象来分析:它的核心不是“把状态机放哪”,而是在网络分裂、设备退化、并发竞争的现实里,如何让状态仍然可控、可恢复、可审计。
一、系统到底在“控制什么状态”
一个工业 AMR 场景里,至少同时存在四类状态对象(它们必须协同演化):
- 任务状态(Mission / Job)从“创建→分解→分配→执行→交接→完成/失败/补偿”。
- 机器人状态(Robot Capability & Execution)不是“在跑/没跑”这么简单,而是:可用能力、风险等级、局部执行阶段、本地断点、降级模式。
- 资源状态(Resource / Reservation)路段、区域锁、门、电梯、充电桩、工位、对接站等,每一个都需要“占用/释放/超时/仲裁”的状态机。
- 安全与约束状态(Safety / Constraints)急停、限速区、禁行区、互锁、人员近距、视觉退化……这些状态要能“闸门化”其它状态的跃迁。
分布式状态控制系统的目标是:让这四类状态的合成行为在故障和并发下仍然稳定。
二、通用的分布式状态控制分层
最稳的通用结构是“三层状态机 + 两条通道”:
A. 三层状态机
L0|本地安全执行状态机(必须在车上)
• 关心“能不能动、怎么停、怎么降级、怎么恢复”
• 典型状态:Ready / Executing / LocalPaused / SafeStop / Recovering / Fault / Degraded
• 这是最后责任边界:外部指令只能给“意图”,不能越过它的闸门。
L1|任务执行状态机(可车载也可外置,但要双写)
• 关心“任务阶段”与“可回滚断点”
• 它需要与本地断点管理器绑定:定位丢失、路阻塞、对接失败、资源不可用都要进入结构化恢复路径。
L2|全局协同状态机(通常外置:调度/交通/资源编排)
• 关心多车、多资源、一致性与公平性
• 典型状态:任务分派、资源预约、会车协商、拥堵消解、换车补偿。
B. 两条通道
控制通道(Control Plane):意图/阶段/预约/释放/补偿命令
证据通道(Evidence Plane):状态事件流 + 断点上下文 + 回放材料(黑匣子切片)
控制做“让系统动起来”,证据做“让系统活得久、可交付”。
三、 一致性:不要追求“强一致”,要追求“可恢复一致”
AMR 的现实是:网络会抖、机器人会断联、环境会不可信。因此通用做法不是强一致事务,而是这套组合拳:
关键一致性策略
1、租约 Lease(时间边界一致性)
• 任务、资源预约、控制权都用 Lease。
• 失联=租约过期=车上进入 SafeStop/Degraded,外置进入“待恢复/待接管”。
2、幂等命令 + 单调版本号(Monotonic Epoch)
• 每条命令带 command_id + mission_epoch + stage_version
• 车上“最多执行一次”,重复只回 ACK,不重复动作。
3、Saga / 补偿(而不是分布式事务)
• “预约区域→进入区域→释放区域”任何一步失败,都走补偿路径(释放、回滚、换路、换车)。
4、事件溯源(Event Sourcing)用于证据与重建
• 外置生命周期状态不是“最终真相”,它是“可从事件重建的视图”。
• 视图挂了可以重放,避免“平台重启后状态丢失卡死”。
四、“断点”在分布式里怎么设计才通用
断点不是简单异常码,它应该是一个结构化对象,至少包含:
• breakpoint_type(LocalizationLost / PathBlocked / ResourceTimeout / DockFailed / SafetyTrigger …)
• scope(local-only / needs-global / needs-human)
• recoverability(auto / semi-auto / manual / non-recoverable)
• required_evidence(需要哪些切片/日志/传感器窗口)
• suggested_actions(重定位、改道、释放资源、降级模式、请求人工放行…)
• time_budget(超时策略:继续等?回退?换车?)
并且断点必须触发两件事:
• 状态机跃迁(进入 Recovering / Degraded / SafeStop / Fail)
• 证据切片固化(否则你无法交付与治理)
五、一个“通用 AMR 分布式状态控制”的最小对象模型
你可以用这几个核心实体做任何行业形态的映射:
• Mission:任务主对象(含 stage graph / SLA / priority)
• Robot:能力与健康(capabilities, risk_level, mode)
• Resource:可预约资源(zone/segment/door/lift/dock/charger)
• Reservation(Lease):资源租约(holder, epoch, ttl, fences)
• Breakpoint:断点对象(类型、范围、恢复性、证据要求)
• EvidenceBundle:证据包(事件流指针+黑匣子切片+版本基线)
• Policy:约束策略(速度区、禁行、互锁、降级阈值)
六、 典型失败场景下,系统如何“保持可控”
场景 A:平台/调度挂了
• 车载 L0/L1 继续保证安全;控制租约过期后进入 Degraded 或 SafeStop
• 平台恢复后通过事件与车载断点重建视图(而不是“猜当前状态”)
场景 B:机器人断网但仍在移动
• 这是高风险:必须靠车载安全闸门
• 断网触发策略:限速→就近安全点停车→等待人工/恢复链路
场景 C:资源竞争导致死锁(多车会车/电梯)
• 全局资源状态机必须支持:超时、抢占策略、公平队列、撤销与重约
• 任何“等待”都要有 time_budget 和补偿路径,否则就会僵死
场景 D:定位质量退化
• 这是典型断点:车载立刻降级(限速/停)、请求重定位策略
• 外置只看到“断点类型+范围”,做宏观重调度(换车/换路线/暂停区域)
七、 交付与治理视角的“硬指标”
一个分布式状态控制系统是否可交付,通常看这几条:
• 可恢复性:平台/车/网络任一重启后,能否在不人工清库的前提下恢复任务与资源一致性
• 可审计性:任一事故能否用 EvidenceBundle 回放“状态跃迁链 + 触发原因”
• 可降级性:传感器/环境能力缺失时能否进入可控的 Degraded 模式
• 可解释的边界:外置意图 vs 车载许可,谁有最终否决权,必须清晰

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 8
8 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)